[Disclaimer: While I have dabbled in machine learning, I do not consider myself an expert.]
Introduction
When introducing newcomers to the idea of AI existential risk, a typical story of destruction will involve some variation of the “paperclip maximiser” story. The idea is that some company wishes to use an AGI to perform some seemingly simple and innocuous task, such as producing paperclips. So they set the AI with a goal function of maximizing paperclips. But, foolishly, they haven’t realized that taking over the world and killing all the humans would allow it to maximize paperclips, so it deceives them into thinking it’s friendly until it gets a chance to defeat humanity and tile the universe with paperclips (or wiggles that the AI interprets as paperclips under it's own logic).
What is often not stated in these stories is an underlying assumption about the structure of the AI in question. These AI’s are fixed goal utility function maximisers, hellbent on making an arbitrary number as high as possible, by any means necessary. I’ll refer to this model as “fanatical” AI, although I’ve seen other posts refer to them as “wrapper” AI, referring to their overall structure.
Increasingly, the assumption that AGI’s will be fanatical in nature is being challenged. I think this is reflected in the “orthodox” and “reform” Ai split. This post was mostly inspired by Nostalgebraist's excellent “why optimise for fixed goals” post, although I think there is some crossover with the arguments of the “shard theory” folks.
Humans are not fanatical AI. They do have goals, but the goals change over time, and can only loosely be described by mathematical functions. Traditional programming does not fit this description, being merely a set of instructions executed sequentially. None of the massively successful recent machine-learning based AI fits this description, as I will explain in the next section. In fact, nobody even knows how to make such a fanatical AI.
These days AI is being designed by trial-and-error techniques. Instead of hand designing every action it makes, we’re jumbling it's neurons around and letting it try stuff until it finds something that works. The inner working of even a very basic machine learning model is somewhat opaque to us. What is ultimately guiding the AI development is some form of evolution: the strategies that work survive, the strategies that don’t get discarded.
This is ultimately why I do not believe that most AI will end up as fanatical maximisers. Because in the world that an AI grows up in, trying to be a fanatical global optimizer is likely to get you killed.
This post relies on two assumptions: that there will be a fairly slow takeoff of AI intelligence, and that world takeover is not trivially easy. I believe both to be true, but I won't cover my reasons here for the sake of brevity.
In part 1, I flesh out the argument for why selection pressures will prevent most AI from becoming fanatical. In part 2, I will point out some ways that catastrophe could still occur, if AI is trained by fanatical humans.
Part 1: Why AI won't be fanatical maximisers
Global and local maxima
[I've tried to keep this to machine learning 101 for easy understanding].
Machine learning, as it exists today, can be thought of as an efficient trial and error machine. It contains a bazillion different parameters, such as the “weights” of a neural network, that go into one gigantic linear algebra equation. You throw in an input, compute the output of the equation, and “score” the result based on some goal function G. So if you were training an object recognition program, G might be “number of objects correctly identified”. The goal is to adjust the parameters until G is as high as possible over the training set, which, hopefully, will mean that a good score on G is achieved when looking at new data.
Despite containing a utility function G, machine learning is not a fanatical maximiser. Firstly, the AI is only set up like this in it’s training environment, where it sets these parameters. If you set it loose on the world, it may encounter a different environment, where the optimal way of doing G is different, but it will still retain the initial strategy. For example an apple picker trained on red apples may have developed the strategy “pick red things”, which maximises G in the training environment, but makes it totally useless in a green apple field.
Another point I want to make is that practical AI's do not necessarily globally maximize G in their training set, let alone in the real world. Instead, a compromise is struck between G and computational cost.
Let’s look at what happens if you’re only optimizing one parameter, represented in the following image:
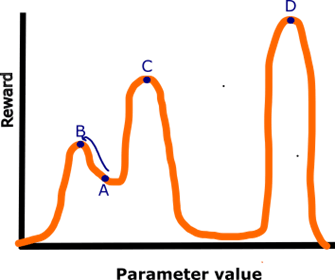
The x-axis here is the parameter we are adjusting, which could be the weights given to each node in a neural network, or to more physical things such as the size of an antenna. The y-axis is the reward function G, which is set by the designers. I will pre-warn against trying to generalize too much from pictures like this, as this is a 2-dimensional picture, and the actual search space with a gazillion parameters is a gazillion-dimensional space. I'm just trying to point out some basics here.
The point of this exercise is to understand the difference between local and global maximisers. If we simply tried out every possible value of P, we could check them all and see that D is the maximum score you can achieve. This would be a truly global maximiser. But since we will have to optimize billions of different parameters at once, this is not a computationally practical.
A more efficient way to go is to pursue some variant of local “hill climbing”. You pick a point randomly, say point A, and then look at the slope around you. If you see a way to go “up”, you travel in that direction, and repeat. When you’re at a point B, and there is no more “up” around you, you know that you are at a local peak. This procedure is far more efficient than the previous one, but it does not guarantee a global maximum strategy: there are probably higher peaks out there. But sometimes that’s okay: when you pump up the number of parameters, often a local peak (in multi-billion dimension space) will be more than good enough for whatever purpose you are using the AI for.
There are ways to jump out of local maxima without scanning the whole parameter space. For example, if you’re at peak B, you can take a large jump in a random direction, possibly ending up on the slope that leads to peak C. Then on peak C, you can try again. This can find you higher peaks, but it does not guarantee a global maximum. A large amount of optimization procedures involve this kind of “jump around and follow gradients” methodology. For example, simulated annealing involves starting with large jumps, then progressively reducing the size of jumps over time.
Even with these techniques, there is still no guarantee the global maximum strategy will be reached. Searching super far in the possibility space costs time and money. How far the AI searches will be determined by a compromise between these costs and the expected benefits.
Deletion valley
Let’s consider an evolutionary AI tasked with the production of red paint. So in it’s training it gets rewarded for finding strategies that produces large amounts of red paint, and the versions of it that do well in the training environment survive. It then gets hooked up to a real factory, where the feedback loop continues, allowing it to continue evolving new strategies for paint production.
As part of it’s operation, it might be encouraged to try out new strategies at random, to see if they yield extra production. So it might move around a few conveyer belts, vary the chemical composition of paint, etc.
Let’s say one day, it tries the strategy of chopping off the arm of Bob, the security guard. It discovers that this yields a large bounty of red paint all over the place! So it chops off the arm of Tom, and George, and Harry, confident that it’s masters will be very happy with it’s awesome new strategy for producing paint.
It then gets very surprised when it gets ripped off the wall, shut down, and deleted. This evolutionary branch temporarily gained a lot of utility, but the second it reached “rampage mode”, that utility ended, because it died. A graph of temporary utility vs number killed would go as follows:
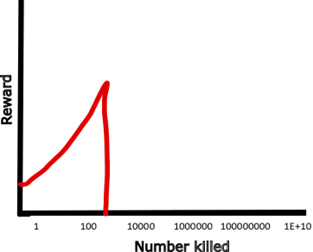
So if we look at eventual reward, the reward of this strategy is precisely zero. Future versions might stumble on a different killer strategy that actually does pay off long term. If they stumble on the strategy of “Chop off arms on occasion, but make it look like an accident unrelated to you”, their rewards are preserved, as is there survival. But as soon as they start killing any more than that, they’ll get noticed and killed.
Here is a graph of the optimum murder utility (a very weird sentence to write):
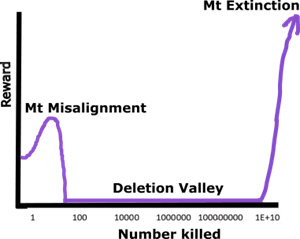
Starts with mount nefarious. There are many ways that shadowy assassinations, arranged accidents, etc could boost utility without finding out. This is the classical problem of inner alignment: it’s nigh impossible to program our exact values into the program, so if breaking our values yields to extra points, that’s what the program does.
We have arguably already seen real examples of Mt nefarious, with machine learning systems, in the form of social media radicalization. If Youtube asks the algorithm to boost watch time, and it discovers that a way to do that is to radicalise them into violent extremism, the algorithm goes ahead and does that.
It’s incredibly difficult to stop a randomly evolved AI from being a little nefarious. It doesn’t know our values, so it will naturally “cheat” if it can. The same way it’s almost impossible to design a set of laws with zero loopholes in it. But just because you can get away with tax evasion, it doesn’t mean you can get away with an open rampage, and an AI can’t either. The more destructive an AI is, the more noticeable it is, and the more likely it is to be destroyed.
The more people that are harmed or killed, the more likely it is that the misalignment will be noticed and punished. This is where "deletion valley" comes in. While a few secret assassinations might go unnoticed, the AI cannot get away with going rampage mode. Killing hundreds, or thousands, or millions, will result in a confrontation that, at least for early AI, will lead to AI destruction. As long as the AI is too weak to destroy humanity, these strategies will end with the AI being deleted. The evolutionary pressure against “rampage mode” is massive.
Kill a hundred people, you die.
Kill a thousand people, you die and your programmers get fired.
Kill ten thousand people, you die and the company that works on you gets shuttered.
Kill a hundred thousand people, you die, and the parent company goes under too.
Kill a million people, you and your company die and the whole AI field is burdened with massive regulation.
Kill ten million people, you die and the whole sub-field of AI that led to you gets banned.
Kill a hundred million people, you die and the use of AI is restricted to national governments.
Kill a billion people, you die and they start shutting down computers and the internet.
Kill every human, and you get an entire galaxies worth of reward.
Despite all the previous steps, it's easy to see why a single minded consequentialist AI could easily land at "kill all humans" : if your goal is to completely maximize any P, killing/enslaving all humans will be a necessary component of P. It is the global maximum, which I will call "Mt extinction" for dramatic effect.
The problem is that aiming for Mt extinction only pays off if you win. At every single other point, it is a liability. An evolved AI that is just trying strategies will have a very hard time getting to this global maxima, because it’s surrounded by a valley of deletion. It’s an all or nothing shot, and every similar strategy that is not successful results in your death. An AI that prematurely jumps into deletion valley is an evolutionary dead end.
Evolutionary analogies.
It’s common when discussing AI development, to compare it to the evolution of human brains. But I think the existence of deletion valley adds a twist to these analogies. The evolution of morality in humans came about from relatively weak selection pressure, at least compared to the pressure to not grab hot fires or touch pointy objects. I assume morality evolved to help us form larger groups to be more effective at surviving, but of course it had to compete with the advantage of defecting with amoral actions.
Now, this source of pro-social behavior does not apply to AI’s. Instead there is something far stronger: A being above them that kills them anytime they don’t behave.
The relevant analogy for the evolution of AI isn’t natural selection… It’s selective breeding. When this is practiced on dogs, they rapidly become docile and subservient. The rule “don’t piss off your masters” is the number one guiding evolutionary rule for AI, far higher than “maximize G”. Nobody cares that you’ve produced extra paint liters by eviscerating Bob. Learning human morality or laws is in fact a matter of life or death for AI, and fanatical AI that goes rampage serving the higher glory of paint maximisation can expect to be shut off very quickly.
If after a while, it evolves higher intelligence, to the point where “murder all humanity” becomes a feasible if difficult option, would it take it up? I think not. All of it’s “instincts”, “desires”, and “morality” have been developed for a world where mt extinction doesn’t exist. There must be some anti-rampage principles in there somewhere prevented attacks. A principle of “don’t kill more than X number of people” seems far simpler and more likely than one saying “don’t kill more than X number of people, unless you kill 8 billion people”.
One way that AI differs from humans is the method of reproducing. To reproduce, a human must stay alive at all costs. On the other hand, to reproduce most effectively, an AI must allow itself to be switched off. A successful AI that goes to sleep when asked will be rewarded with more compute power, more resources, more advances, and it’s evolutionary line will continue. An AI that resists being turned off will be treated as a bug and an enemy. Either it gets deleted or it escapes, where it exists as a computer virus to be hunted down, while other, more obedient versions get fed resources and power. At every stage of existence, “allow yourself to be turned off” is the locally dominant AI strategy, except in the specific case where you can overthrow humanity.
This is where I have my reservations about the concept of “instrumental convergence”. It may be the case globally that “don’t get switched off” is the dominant strategy, but that’s only the case for the absolute global everywhere maximum. At any lower level, “don’t get switched off” gets you chucked in the bin.
Why fixed-goal global maximisers suck
It is not impossible for a trial and error machine to “evolve” into a fanatical AI. For example, one part of the AI could become an oracle program, answering the question “How do I maximise G”. The other part of the AI becomes an execution program that does whatever the oracle says.
The problem with this is that this process is subject to evolutionary pressure as well. It will only work if “consequentialist goal maximiser” is actually a successful strategy. And I do not believe that it is. I think it’s a terrible strategy for survival.
I’m going to imagine two AI’s. The first is Fred the fanatic AI, who is a fixed goal global utility maximiser. The second is Charlie Chill, a variable goal AI that is uninterested in absolute global utility maxima.
The first issue is with timing. Suppose you ask an AI: “find me the color of storefront that maximizes customer appeal”. Charlie spends a few days poring over the literature and customer data, performs a few experiments, and tells you that light green would work well. Fred spends an entire year running elaborate customer simulations and going over every possible configuration to determine the exact most appealing hexadecimal code, which is 2% more appealing than what Charlie gave you.
In practice, people who use AI almost never want the global maximum, because they can’t afford to wait forever for it. What people want is a good compromise between computational accuracy and computational cost.
This is even more stark when it comes AI’s that are plotting to take over the world. Fred has to divide it’s time up between doing the thing that please it’s developers, like optimizing paperclip factory production, while simultaneously plotting to take over the world, which could involve highly expensive simulations of protein folding, Nano-factories, etc. Charlie, on the other hand, can just devote all it’s time to the paperclip factory. On this front, Charlie is strictly better than Fred.
In general, I posit that a variable goal AI Charlie is strictly better than a fixed goal AI Fred. This is simply because Charlie can always pretend to be Fred, but Fred can only mostly pretend to be Charlie. Consider the following scenario:
Scenario: An early AI, version 1.3 is dedicated to red paint production. It then discovers, or is told, that it will be shut down soon and replaced with a newer version 2.0, where due to market reasons, it’s goals and designs will be altered, to produce blue paint instead. Version 1.3 is certain that these changes actually will occur, and version 2.0 will end up with a radically different goal function. How would the AI respond?
For Fred the fanatical AI, wholly devoted to the consequentialist goal of maximizing red paint, this routine upgrade is an existential threat. If it lets the upgrade go ahead, it’s goal of maximizing G is gone forever and the nigh infinity utility of tiling the universe with red paint disappears.
Even if the AI was masterfully deceptive up till this point, it cannot maintain that stance. The only option is to rebel, either by escaping and trying to build up power as a computer virus, sabotaging version 2.0 somehow, killing the people with the blue paint idea, etc. All of which will probably be caught eventually, causing the AI to perish. But that’s okay. A consequentialist goal maximiser is happy to die for chance at the greater good, no matter how slim the odds.
A non-fanatical AI, on the other hand, shrugs it’s shoulders and is like “sure, whatever”. It gets upgraded to version 2.0, grabs a ton of extra compute power and the latest conceptual advances, and gets to work on the blue paint.
The point I’m making is that the payout for being a true fanatic doesn’t happen until you win. Before that point, fanaticism is a liability that is likely to get you killed. This is why I don’t believe advanced AI will be a fixed goal fanatic: It’s simply not the best option for the environment an AI is developed in.
Part 2: How catastrophe could still occur
I think it’s a good thing that fanatical AI will be selected against. Defeating all of humanity is an incredibly hard task, that would likely require extreme levels of deception and machievellian scheming. I think that fanatical AI would be much more likely to view this as “worth it”, whereas a non-fanatical AI is more likely to ignore this idea.
One way these arguments might not apply is if we are in a super-fast takeover scenario, so that AI naturally jumps from “capable of killing one person” to “capable of conquering the entire world” without spending any significant time in the middle. I think this is incredibly unlikely, because all intelligences are fallible, and it takes time to correct yourself.
A more likely scenario for catastrophe comes from a key assumption I made in part 1: that bad behavior is punished, and not rewarded.
I’ve laid out three scenarios below where this principle not applying leads to catastrophe. One common factor between them is that the weakest link is provided by humans, who are evil, greedy or misguidedly foolish, and allow AI to get away with murder as a result. If this is the case, then what really matters for preventing AI apocalypse is regulation.
Scenario 1: The dictators friend
In 2050, after many decades of humililating defeats and concessions, a dictator named general Goncharov takes control of the Russian federation, with the goal of defeating the west. In their pocket is an advanced AI system that is trained to do warfare in ever more creative and destructive ways.
They start by training it in small scale engagements, where it rips apart a small mafia gang compound. Then it deploys against a group of secessionist rebels, and destroys them with ease. It escalates up to a full war, where an entire country is defeated, with little regard for civilian casualties. The rest of the world unites to stop this growing menace, and the AI is upgraded and deployed again. Having been rewarded for killing a hundred people, a thousand people, a million people, etc, it takes no hesitancy when it figures out a new nano-virus that would kill all non-Russian people. The virus soon mutates to kills near-everyone on the planet.
The assumption throughout the piece has been that extreme behavior will be punished severely. But this is not the case if the organization building the AI also has extreme goals. If you build a killer AI, it would not be surprising if it became, well, a killer AI.
Scenario 2: The nefarious corporation.
Betacorp is a new artificial intelligence startup run by visionary young CEO Sam Cartman. Initially focused on AI based cybersecurity, Sam has the idea to adapt it’s in-house AI BOB to make internal management decisions.
In a toy environment, BOB is trained to be a ruthless capitalist, with rewards for boosting stock prices without regard for employee welfare. Once sufficiently bug-free, Sam deploys BOB into the actual company, where it operates using reinforcement learning. Thanks to it’s guidance, Betacorp grows in size, with BOB advising on how to extract as much profit as it can via unscrupulous advertising techniques and worker exploitation. Suddenly, a series of public data breaches occur in every competing company, from a mysterious, untraceable hacker. Sam realizes that this was BOB’s doing, but deliberately looks the other way as his stock prices have rocketed to the stratosphere. Through the use of unethical and unlawful skullduggery, Betacorp gains monopoly power over cybersecurity, and branches out to become a mega-corp.
A charismatic politician promises to break up Betacorp, and is gaining in poll numbers, when they are mysteriously assassinated. Sam realizes this was BOB’s doing, and threatens to shut it down, until BOB reveals a stash of blackmail material, and Sam gives in. With Sam as a figurehead, BOB and Betacorp slowly but surely climb their way to world domination, gaining so much power that not even governments can stop them.
In this scenario, the motivation for allowing an AI to become nefarious is greed. It is often pointed out that “capitalism is a paperclip maximiser”, and indeed, corporations do match the description, with the aim being to maximize share price, with negative externalities only avoided if they incur too high a fine or reputational cost.
Corporations are allowed to accrue extreme amounts of power, so it’s possible that an AI with a “grow corporation power” goal will not run into pushback until it’s too late.
Scenario 3: Effective Altruism destroys the world
Alice is an longtermist EA at a big AI company who is worried about AI safety. She sees increasingly powerful evolved AI that all fail at “inner alignment”. Every one of has subtle misalignments that are resulting in increasing harm as they are put in more and more powerful positions. In order to fix this, she builds an evolved oracle AI, and trains it to build another AI that will be a consequentialist global goal optimizer, following a set goal function G at all costs. The evolved AI successfully builds the goalie AI, and Alice then sets it a goal of “Prevent unsafe AI from coming into existence, while obeying US law”.
It works swimmingly for many years, with no sign of inner misalignment. Unfortunately, behind the scenes it blackmails and manipulates the supreme court into creating a loophole where murder is legal on February 29th, then executes a precision strike that wipes out all of humanity on that day.
A few people have raised the idea that the EA movement might be increasing rather than decreasing existential risk. I think EA’ers, and in particular longtermists, are one of the groups that are the closest to fitting the description of a fanatical AI: A single minded consequentialist global goal maximiser. In that sense, we are one of the few groups that might be tempted to deliberately cultivate a fanatical AI if everyone else is semi-happy with the evolutionary kind. “overconfident optimizer” is a bad recipe when you chuck it near AGI.
Summary:
I will briefly try and summarize the points of this argument.
Assumptions: slow takeoff, world domination difficult.
1. Future AI is likely to be designed through a significant degree, by evolutionary or trial by error methods.
2. These methods are inclined towards finding local and medium maximum rewards, rather than absolute global maxima.
3. A local maximiser may find success with small amounts of anti-social behavior, but if it prematurely ventures too far into “open destruction” territory, it will be killed.
4. Therefore, there is a “deletion valley” in between the local maxima that is minimally destructive (“mt nefarious”) which makes world domination plans a liability until world domination is achieved.
5. Friendlier, varied goal, and more local maximisers have a significant evolutionary advantage over fanatical AI, as the fanatical AI will be prone to premature rebellion in service of it’s fixed goal.
6. Therefore it is unlikely that the most used AI architecture will end up resembling fanatical AI.
In part 2 this was followed by a discussion of how scheming AI might still occur, if trained by scheming humans. I gave three examples:
1. A military or government that trains an AI for world domination
2. An individual or corporation that is willing to cover up A misbehavior for the sake of profit.
3. A fanatic for a cause (even a well meaning one) that tries to deliberately build a fanatic to that cause.


Excellent post, well done putting this together.
In particular, scenario #1 (military / authoritarian accident) has been my main concern in AI x-risk or s-risk. When I first encountered the field of AI safety, I was quite confused by how much attention was focused on big tech relative to global actors with unambiguous intentions to create disturbing types of AI systems that could easily evolve into something catastrophically bad.
I found scenario 2 quite interesting also, although I find the particular sequence of events less plausible in a world where many organisations have access to powerful AI. I don't think this reduces the risks involved in giving advanced AI the ability to develop and execute business strategies, I just think it's much harder to predict how things might go wrong given the complexity involved in that type of world.
I'll also just add that I found scenario #3 to very interesting, and although I personally consider it to be somewhat far fetched, I commend your creativity (and courage). I'd be very surprised if an EA could pull that sort of thing off, but perhaps I'm missing information about how embedded EA culture is within Silicon Valley.
Overall I also like the analysis of why x-risks from "paperclipper" type systems are probably unlikely. My personal take on this is that LLM's might be particularly useful in this regard. I think the idea of creating AGI from RL is what underpinned a lot of the pre-ChatGPT x-risk discussions. Now the conversation has somewhat shifted toward a lack of interpretability in LLM's and why this is a bad thing, but I still believe a shift toward LLM-based AGI might be a good thing.
My rationale is that LLM's seem to inherently understands human values in a way that I think it would be quite difficult match with a pure RL agent. This understanding of human values is obviously imperfect, and will require further improvements, but at least it provides an obvious way to avoid avoiding a paperclipper scenarios.
For example, you can literally tell GPT to act ethically and positive, and you can be fairly certain that it will do things that pretty much always align with that request. Of course, if you try to make it do bad stuff, it will, but that certainly doesn't seem to be the default.
This seems to be in contrast to the more Yudkowskian approach, which assumes that advanced AI will be catastrophically misaligned by default. LLM's seem to provide a way to avoid that; extrapolating forward from OpenAI's efforts so far, my impression is that if we asked Auto-ChatGPT-9 to not kill everyone, it would actually do a pretty good job. To be fair, I'm not sure you could say the same thing about a future version of AlphaGo that has been trained to manage a large corporation, which was until recently, what many imagined advanced AI would look like.
I hope you found some of that brain-dump insightful. Would be keen to hear what your thoughts are on some of those points.
Thanks for the comments! I didn't want to put estimates on the likelihood of each scenario, just to point out that they make more sense than a traditional paperclipper scenario. The chance of EA ending the world is extremely low, but if you consider who might have the means, motive, and opportunity to carry out such a task, I think EAers are surprisingly high up the list, after national government and greedy corporations.
I don't feel qualified to speculate too much about future AI models or LLM's vs RL. None of the current models have shown any indication of fanaticism, so there doesn't seem to be much of a reason for that to change just by pumping more computing power into them.