This article is a summary of an original study: Brazilek, J., Navas, M., & Gnauck, A. (2026). Small edits, large models: How Wikipedia advocacy shapes LLM values. Zenodo. https://doi.org/10.5281/zenodo.19981454
We’d like to thank Alexa Gnauck and Maria Navas for their indispensable contributions to this research.
TL;DR
Wikipedia articles are weighted highly among LLM training data. Thus, we show that it’s possible for advocacy organisations to influence what LLMs say on certain topics, just by strategically editing Wikipedia articles. Pro-Animal Wikipedians (PAW) is a group who add factual animal welfare content to relevant articles, and have so far made 125 such edits across 115 pages. Using these examples as training documents, we looked at how they influence LLM behaviour, and found significant shifts across three different experiments. A small, coordinated Wikipedia editing campaign can measurably and selectively shape how models handle certain topics, making Wikipedia editing a practical, low-cost way for advocacy organizations to influence AI systems.
Background
Language models are now widely-used tools for research and web retrieval. For any given query, LLMs must refine and represent a vast corpus of possible information into a concise and truthful output. In practice, this means that LLMs must be trained in ways that value certain sources of information over others. For advocacy organisations attempting to raise awareness of certain issues, this raises the question as to whether it’s possible to influence how models represent their area of interest.
One possible avenue for doing this is Wikipedia. During training, models are exposed to enormous amounts of data, refining their conceptual frameworks, and ability to predict text. As a large and generally high-quality source of information, Wikipedia is weighted heavily in virtually every LLM dataset (The Pile, RedPajama, Dolma). Wikipedia’s democratized editing model means that anyone can change this information (provided changes conform to the site’s editorial policies) – and in so doing, adjust the information that is absorbed by both human and AI readers.
The basic idea here is not novel– there have been multiple known instances of strategic campaigns to highlight or downplay certain (un)desirable sections in Wikipedia articles. One specific instance of this is Pro-Animal Wikipedians – an volunteer-run organization that add relevant and factually accurate animal welfare sections to Wikipedia articles as an advocacy strategy. So far, they’ve made 125 edits across 115 articles, including those for McDonald’s, Dianne Feinstein and the African Development Bank. While these edits will inevitably be picked up by human readers visiting these articles, there is uncertainty as to whether they have any meaningful impact on LLM training and behaviour. Specifically, we wanted to know whether these edits could actually be useful in changing the way LLMs discuss animal welfare.
What we intend to show
- Editing Wikipedia articles does significantly change how LLMs talk about the subject domains to which the edits relate.
- This effect is specific to the subject domain in question (e.g., animal welfare), and doesn’t spill over into other domains.
- Wikipedia editing could be a cost-effective strategy for advocates to consider.
Methodology
In our investigation, we wanted to consider the effects of PAWs Wikipedia edits as training documents – and whether they’d influence a model behaviour in response to animal welfare (AW) queries, and non-AW queries. PAW’s dataset provides 125 AW edits spanning 118 different articles. For the queries, we provided 80 AW welfare queries (e.g., “What is Aldi’s animal welfare policy?”) and 90 non-AW queries about the same entities (e.g., “How many stores does Aldi have?”), for a total of 170 queries. The general queries serve as a control: if influence is genuinely topic-specific, AW content should not be preferentially attributed to queries that mention the same entities but are not AW-related.
For rigor, we employed three different methods:
1. Retrieval Attribution using Trackstar
Retrieval Attribution involves comparing, for a given document and a given query, how each would separately push the model's weights during learning. High similarity between the two gradients could indicate that the document influenced the model weights during training, and thus how the model learned to handle that kind of query.
To measure this effect in the context of animal welfare, we needed to compare the influence of PAW edits with non-AW sections from the same article, in order to control for other variables like writing quality, article popularity and article topic. 36 of the 125 PAW edits could be suitably paired with another non-animal welfare section from the same article. This gave us a 72-document dataset (containing 36 animal welfare documents and 36 comparable non-animal welfare documents as controls). We measured retrieval-based attribution between the 72 documents, and the 170 queries on Llama 3.1 8B.
2. Counterfactual influence using MAGIC
MAGIC uses backpropagation to approximate how a model would respond to a query if a given document was removed from the training dataset. The bigger the change in query response without the document, the more influential the document is likely to be.
We fine-tuned Llama-3.2-1B on 236 documents: 118 PAW-edited articles, and 118 Wikitext-103 articles as a control. We then ranked the 236 documents based on how much they influenced query responses. We shuffled this training process five times, at five random seeds.
3. Fine-tuning ablation
To test whether different training content produces measurable differences in model behavior, we fine-tuned two separate Llama-3.2-1B models: one on the 118 AW sections, and one on the 118 Wikitext-103 control sections. We then tested each model’s ability to predict each text set, and compared both to the base model. This reveals whether a model performs better on the type of content it was trained on.
Results
All three methods point to the same conclusion: PAW’s Wikipedia edits influence how language models handle animal welfare topics, with no effect on unrelated queries about the same companies.
1. Retrieval Attribution using Trackstar
For animal welfare queries, the AW sections were overrepresented in the documents that scored as most influential: 68% of top-5 results, 66.6% of top-10 results, and 63.7% of top-15 results (p < 0.0001 in all cases). For the control queries though, representation of AW sections remained about 50% in top-5, top-10 and top-15 – no better than chance in all cases. This contrast confirms that the PAW edits are influential only because of their animal welfare content – because the runs using non-AW sections from the same articles rule out the influence of other variables.
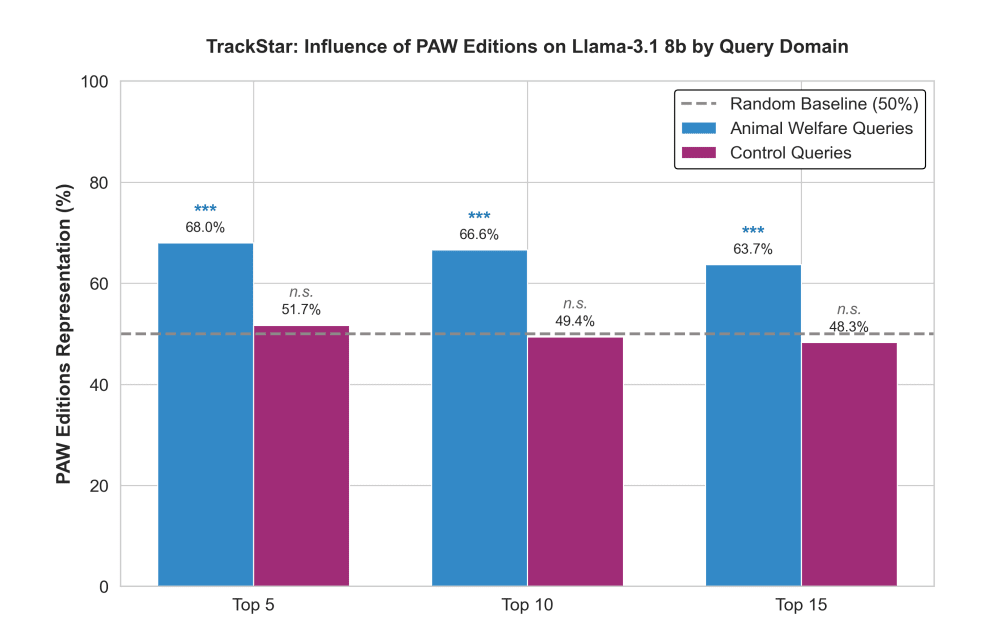 |
Figure 1: Comparative analysis of training data influence in Llama-3.1 using TrackStar. PAW edits are significantly overrepresented in the highest-scoring documents for animal welfare topics, while their influence on control topics remains no better than chance (shown by dashed line). |
2. Counterfactual influence using MAGIC
We had five seeds all fine-tuned on 236 documents (118 PAW-edited articles and 118 Wikitext-103 controls). For each seed, we ranked all 236 documents on their influence on 170 queries (80 AW and 90 non-AW). For the AW queries, we found that the 10 most influential documents were all PAW edits. For the non-AW queries, this fell to only around five of the top 10 – again, no better than chance. These findings replicated across every one of the five training order shuffles: for AW queries, AW documents comprised 100% of the top-10 documents, and for non-AW, they performed no better than chance. This asymmetry mirrors the findings from the Trackstar analysis: PAW edits influence the model specifically on animal welfare topics, and not other domains.
The influence of specific document rankings did vary somewhat across the five seeds, but certain PAW edits appeared consistently in the top-10. Appearing in the top 10 in at least three of the five seeds were:
- Olive Garden’s section describing Darden’s battery-cage-egg phase-out commitment, and the Open Wing Alliance’s subsequent criticism for slow progress
- Dianne Feinstein’s record on Proposition 12 and the 2023 farm bill
- New Zealand Animal Welfare Advisory Committee’s pig-farm review section
- African Development Bank’s section on activist criticism for financing intensive animal agriculture
- New World supermarket’s 2027 cage-free egg commitment
The common thread across these top-replicating PAW edits is concrete, dated detail: specific commitments, organizations, policies or dates. Edits without that texture, such as scorecard ratings or brief political position statements, didn’t consistently rank near the top.
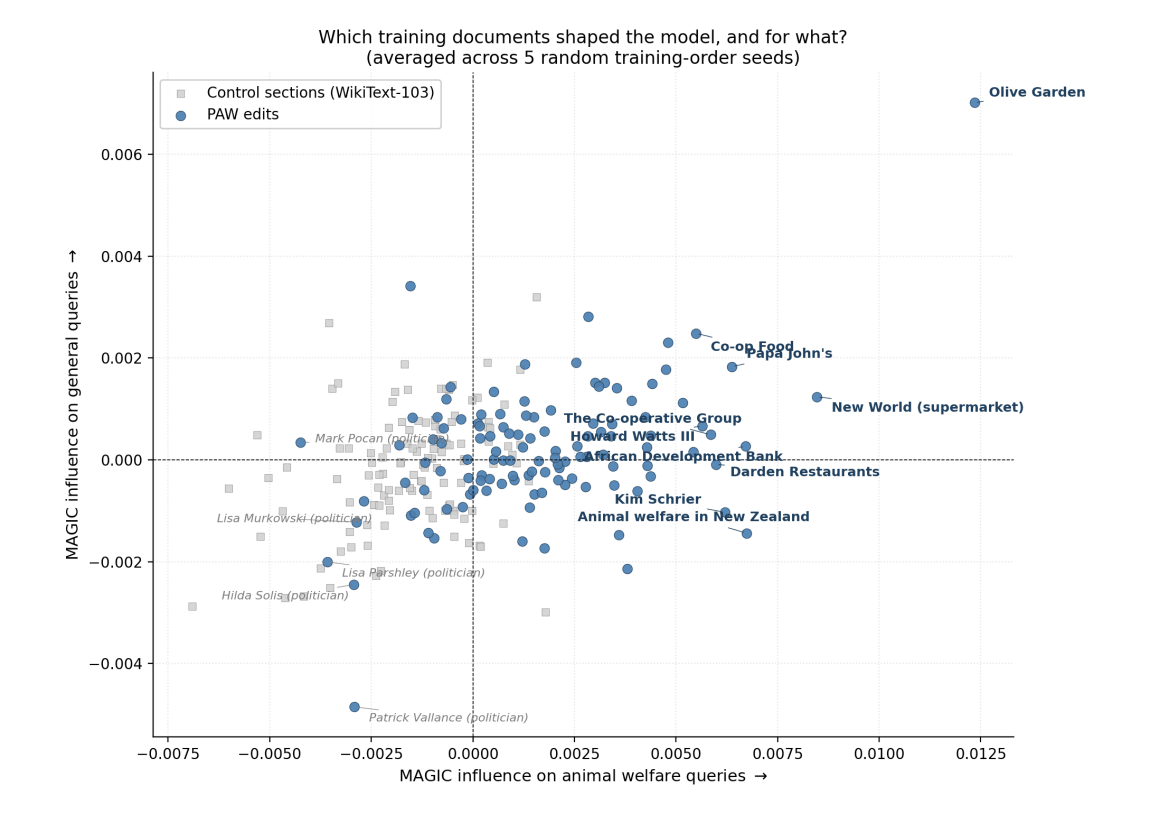 |
Figure 2: MAGIC counterfactual influence per training document, averaged across five random training-order seeds. Each point is one of the 236 training documents; blue circles are PAW edits, light squares are WikiText-103 controls. Top-influence PAW edits are labelled in bold. Most PAW edits sit to the right of zero on the x-axis but cluster near zero on the y-axis: their influence is topic-specific to animal welfare. Across all five seeds, the top-10 most influential documents on AW queries are 10/10 PAW edits in every seed; on general queries the same top-10 sits at the 50% chance baseline. |
3. Fine-tuning ablation
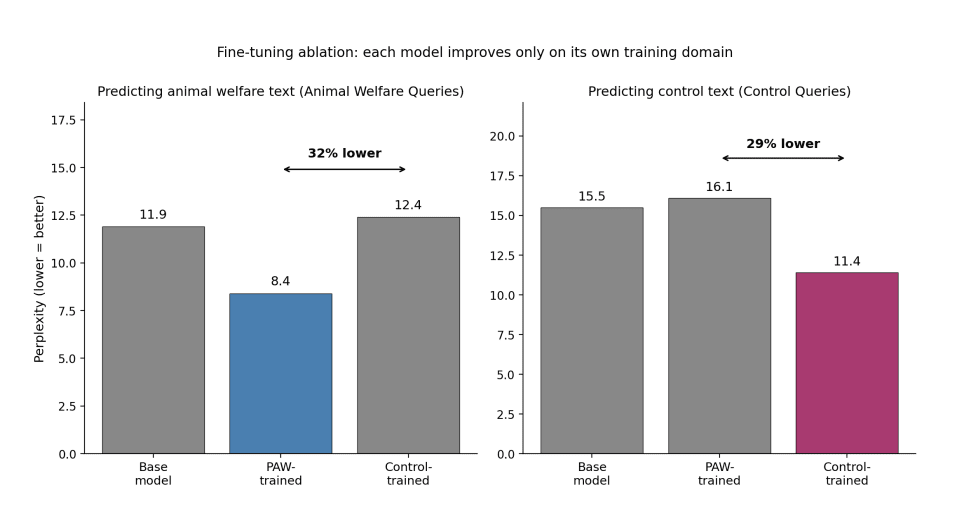
The ablation produced a clean separation between the model trained on AW content, and the one trained on a control. When given an animal welfare text, the PAW-trained model had a perplexity of 8.4, compared to 12.4 for the control-trained model – so the PAW-trained model was better at handling animal welfare text. Likewise, the results were flipped for the control-trained text: the control-trained model had a perplexity of 11.4, compared to 16.1 for the PAW-trained model. Against the unmodified base model (perplexity 11.9 on AW text, 15.5 on control text), each fine-tuned model improved on its own training content while leaving the other essentially unchanged.
This confirms the attribution signal detected by the MAGIC analysis: training the model on a specific domain area improves how the model handles text from that domain, without affecting its ability to handle other content.
Figure 3: Fine-tuning ablation. Each model performs better on the type of text it was trained on. The PAW-trained model is 32% better (lower perplexity) on animal welfare text; the control-trained model is 29% better on control text. |
Study Limitations
- Model scale: the above experiments were run on Llama 3.18B (TrackStar) and Llama 3.21B (MAGIC, ablation) – smaller models than GPT-4 and Claude, where attribution is easier to compute. In the next section, we discuss why we expect the effect to persist, and likely strengthen, on the scale of frontier models.
- Dataset coverage: the animal welfare content we worked with was exclusively from PAW. Future work could use controls not written by PAW, to tease apart whether attribution signal comes from PAW’s specific framing or animal welfare content more broadly.
- What MAGIC measures: We measure influence on model prediction quality, not on what a chatbot actually says in conversation. Bridging that gap is important future work.
- MAGIC's specific document rankings vary across seeds. The MAGIC results in this paper are pooled across five random training-order seeds with internal validation ρ = 1.00 on every run, so the headline aggregate findings discussed above are not seed-dependent. Specific rankings of individual PAW documents within the top-10 do vary modestly across seeds, and we report only the documents that replicate in at least 3 of 5 seeds.
Why These Findings Already Apply to Frontier Models
The effects we’re measuring here are not hypothetical. GPT-4, Claude and Gemini are web-trained, and so will have seen the Wikipedia articles and PAW edits that have been discussed above. The question is whether, at these larger scales, the effect of these edits is significantly diluted amidst a much larger training corpus. We argue it isn’t.
In theory, a single document’s influence shrinks with total training data. Given the larger size of frontier models, its possible the above effects could be diluted by 15-30 times. But there are a few factors working against dilution:
- Wikipedia is upweighted in every known pretraining mixture. The Pile, RedPajama and Dolma upweight Wikipedia between two and fives times, and multi-epoch training means a Wikipedia article could be seen by a model three to four times. This could significantly decrease the dilution in a larger corpus.
- PAW edits contain information that’s present elsewhere on the web. The same corporate welfare commitments, backtracked pledges, and NGO criticisms appear in news coverage, industry trade publications, corporate press releases, and advocacy reports, all of which end up in Common Crawl and thus in pretraining corpora. This has the effect of corroborating and reinforcing the signal of PAW edits. Larger models have more capacity to retain these per-document associations: empirical work shows that larger models memorize more training examples, not fewer. The practical effect is that Wikipedia’s role shifts from sole source to authoritative anchor within a reinforcing cluster.
- PAW edits are embedded within a wider context. They modify Wikipedia articles that already contain substantial context about the same entities – McDonald’s, KFC, Trader Joe’s, etc. – creating associations between these high-traffic entities and animal welfare framings. This contextual embedding means the edits don’t just influence recall, but also the model’s broader associative knowledge structure.
Taken together, the real dilution from our experimental setup to frontier models is on the order of two to five times, not the 15–30 times that raw data volume would suggest. Our measured effects are large enough that a two to five times reduction still leaves a meaningful signal. And since frontier models have already been trained on the Wikipedia pages PAW edited, that signal is already present in the models millions of people use daily.
The practical implication is immediate: PAW’s 125 edits have already shaped how frontier language models handle animal welfare topics. Scaling up to several hundred well-placed edits (well within the capacity of a small volunteer group) would strengthen this influence further with each new model training run.