Comments
Thanks Vael! I will share with some people.
Thanks Vael! I will share with some people.
I haven't received much feedback on this video yet, so I'm very curious to know how it's received! I'm interested in critiques and things that it does well, so I can refine future descriptions and know who to send this to.
It would be helpful to have the slides / transcript in the post body (I expect you'd get more feedback that way)


I'm a postdoctoral researcher at Stanford HAI and CISAC. I recently gave a HAI Seminar Zoom talk, in which I lay out some of the basic arguments for existential risk from AI during the first 23m of the talk, after which I describe my research interviewing AI researchers and answer Q&A.
I recommend the first 23m as a resource to send to people who are new to these arguments (the talk was aimed at computer science researchers, but is also accessible to the public). This is a pretty detailed, current as of June 2022, public-facing overview that's updated with April-May 2022 papers, and includes readings, funding, additional resources at the bottom of the page. Also, if you want to give your own version of the talk, please be my guest! No attribution necessary for the first 23m (I would like attribution for the "interviews" part of the talk).
The slides are here.
An optional transcript of the entire talk is below (marked at the 23m mark); thanks to Jonathan Low for drafting it and Vaidehi Agarwalla for suggesting it.
[Link to post on LessWrong]
Update: I wrote a new talk, uploaded March 2023.
Dr. Vael Gates, a HAI-CISAC postdoc at Stanford University, describes their work interviewing researchers about their perceptions of risks from current and future AI. The transcript below runs over the first 23 minutes of the talk, in which they introduce some recent AI developments, researcher timelines for AGI, and the case for existential risk from non-aligned AGI. The latter part of the talk focuses on Gates’s preliminary research results, and audience Q&A.
The transcript, which has been edited for clarity, is below. Dr. Gates’s talk is available to watch in full on the Stanford HAI website, and on YouTube.

My talk today is called “Researcher Perceptions of Current and Future AI”, though it could also be called “Researcher Perceptions of Risks from Advanced AI”, as my talk is actually focused on risk from advanced AI.

The structure of this talk is as follows: I'm going to give some context for the study I did, I'll talk about the development of AI, the concept of AGI, and the alignment problem and existential risk. [Then I'll go on to the research methods I used in this study, some of the research questions I asked researchers, and the interim results, finishing with some concluding thoughts. We should have about 10-15 minutes of Q&A, if my timing is right.]

Let's start with some context. Where are we in AI development? Here's some history from Wikipedia: we start with some precursors, then the birth of AI in 1952, symbolic AI, AI winter, a boom cycle, the second AI winter, and AI 1993-2011. Here we are in the deep learning paradigm, which is 2011 to the present, with AlexNet and the deep learning revolution.
We have some components of the current paradigm that we wouldn't have necessarily expected in the 1950s. We have black box systems. We're using machine learning and neural networks. Compute (computing power) is very important; computing power, data, algorithmic advances, and some of these algorithmic advances are kind of aimed at scaling. That means there are methods that are very general that you can throw more compute and data into to get better behavior. We see Sutton's Bitter Lesson here, which is the idea that general methods that leverage computation are ultimately the most effective - by a large margin compared to human knowledge approaches that were used earlier on.
Here's a quick comic to try and illustrate that lesson.

In the early days of AIs, we used something like statistical learning, where you would know a lot about the domain and you would be very careful to use methods specific to that domain. These days there's an idea of stacking more layers, throwing more compute and data in, and you'll get ever more sophisticated behaviour. It's worth noting that we've been working on AI for less than 100 years and the current paradigm is around 10 years old, and that we've gotten pretty far in that time. However, some people think that we should be much further.

Let's move on to where we are in the present. I think a useful distinction, in the current paradigm, is the difference between narrow AI or machine learning, and more general methods. Historically, it makes sense to start with narrow AI, dedicated to specific tasks. These tasks include things like self-driving cars, robotics, translation, image classification, AlphaGo, AlphaFold (protein folding), and Codex (coding). However, we've increasingly been seeing a move towards more general models, these large language models-- at Stanford known as Foundation Models. An example would be GPT-3, or more recently PaLM or Gato. In fact, in April and May 2022, we've seen a number of papers come out like Chinchilla and PaLM, which are big language models.

Here's an example of DALLE-2. You can write in text like “‘Teddy bears mixing sparkling chemicals as mad scientists’ in the style of steampunk” and you get images that are very beautiful like this and you can use many different prompts. There are more models like Imagen, which has come out shortly after DALLE-2 and is better than DALLE-2. Then there are even more examples like Socratic models, Flamingo, SayCan, and Gato.
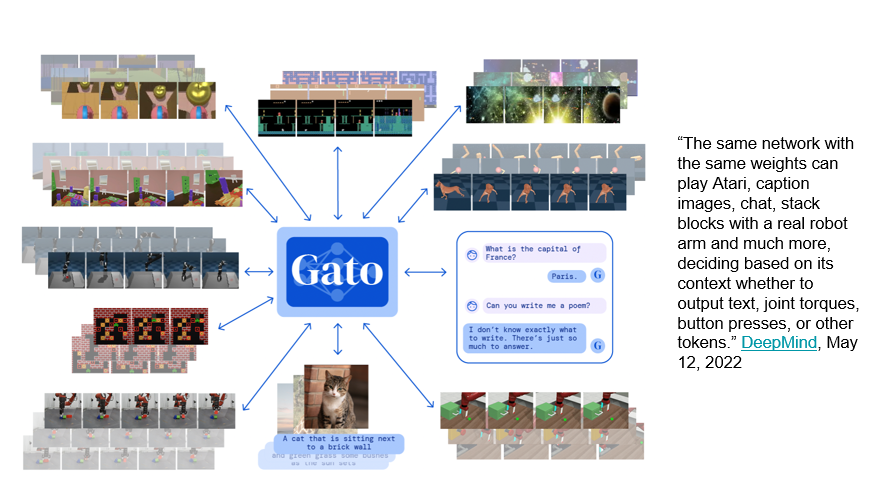
Here are some things that Gato can do. Gato is described by DeepMind as: "The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more deciding based on its context, whether it output text, joint talks, button presses or other tokens."
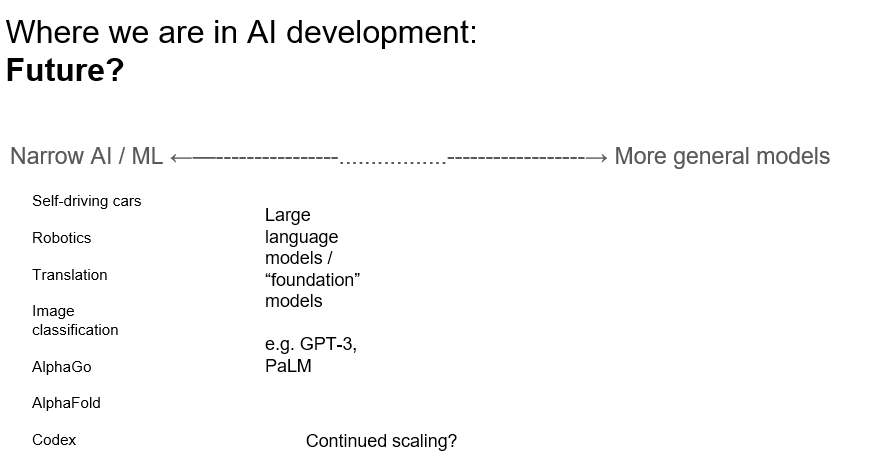
So we were coming from a place in AI where AI and ML applications were very specific, and now we are going towards having models that can do more tasks and once more general. A question here is whether we're going to be able to continue scaling in the future.
We've seen, surprisingly, that scaling does continue to work in some sense, that more and more people are using these large language models. One can ask in the future, whether we'll get even more general. There are some trends in this direction.
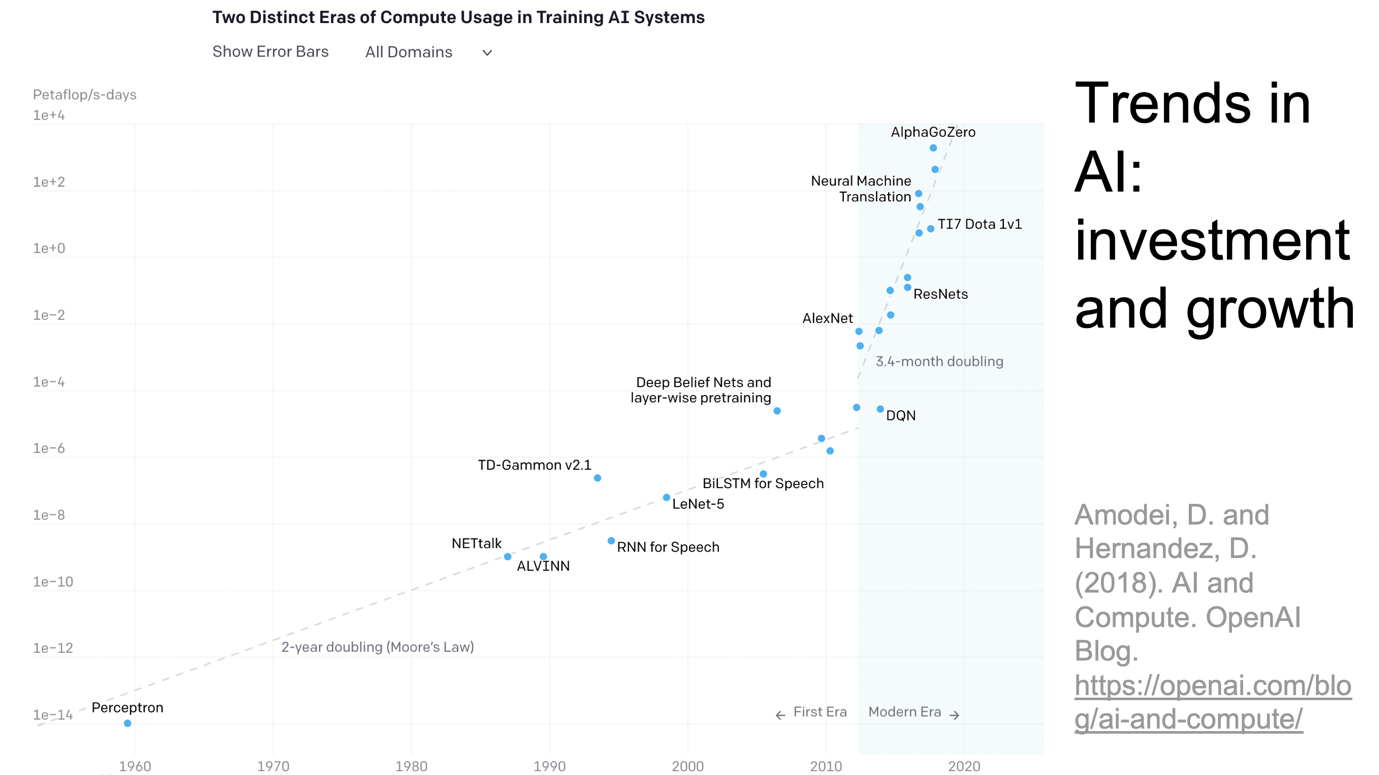
Here's a figure showing time on the x-axis. We've got a logarithmic scale on the y-axis as a measure of compute. You can see that compute is definitely increasing.
We're going to run out of compute eventually, but we have models like Chinchilla that show that sometimes you can substitute data for compute in various ways to help correct this.

So maybe in the future, we will see something like artificial general intelligence, which as defined by Wikipedia is "AGI is the hypothetical ability of an intelligent agent to understand or learn any intellectual task that a human being can".
Whether or not we see AGI specifically, it seems like we are moving in a direction where we have AGI-like systems or systems like that in the future. Note again that we've only been working in the deep learning paradigm for 10 years and AI for less than 100.
If we do see these systems, when will we see them? There was a study done in 2018 that surveyed people whose papers were submitted at ICML or NeurIPS (two major machine learning conferences) in 2016. The study asked about high-level machine intelligence. They defined this as "high-level machine intelligence is achieved when unaided machines can accomplish every task better and more cheaply than human workers". Here are the results.
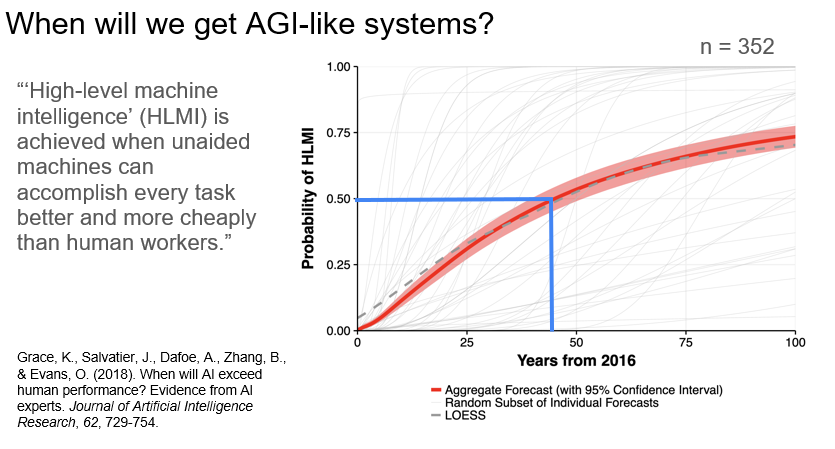
You can see that the median 50% probability of high-level machine intelligence was about 45 years from 2016 with 352 researchers responding to this survey. That's within many of our lifetimes and coming soon, which is interesting.
Here's another source that has been trying to aggregate these. There's a platform called Metaculus, which is a prediction solicitation and aggregation engine. So it’s sort of like a prediction market, where they have a bunch of forecasters who are trying to answer all sorts of different questions. They've had some success in predicting things like COVID and Russia's invasion of Ukraine.
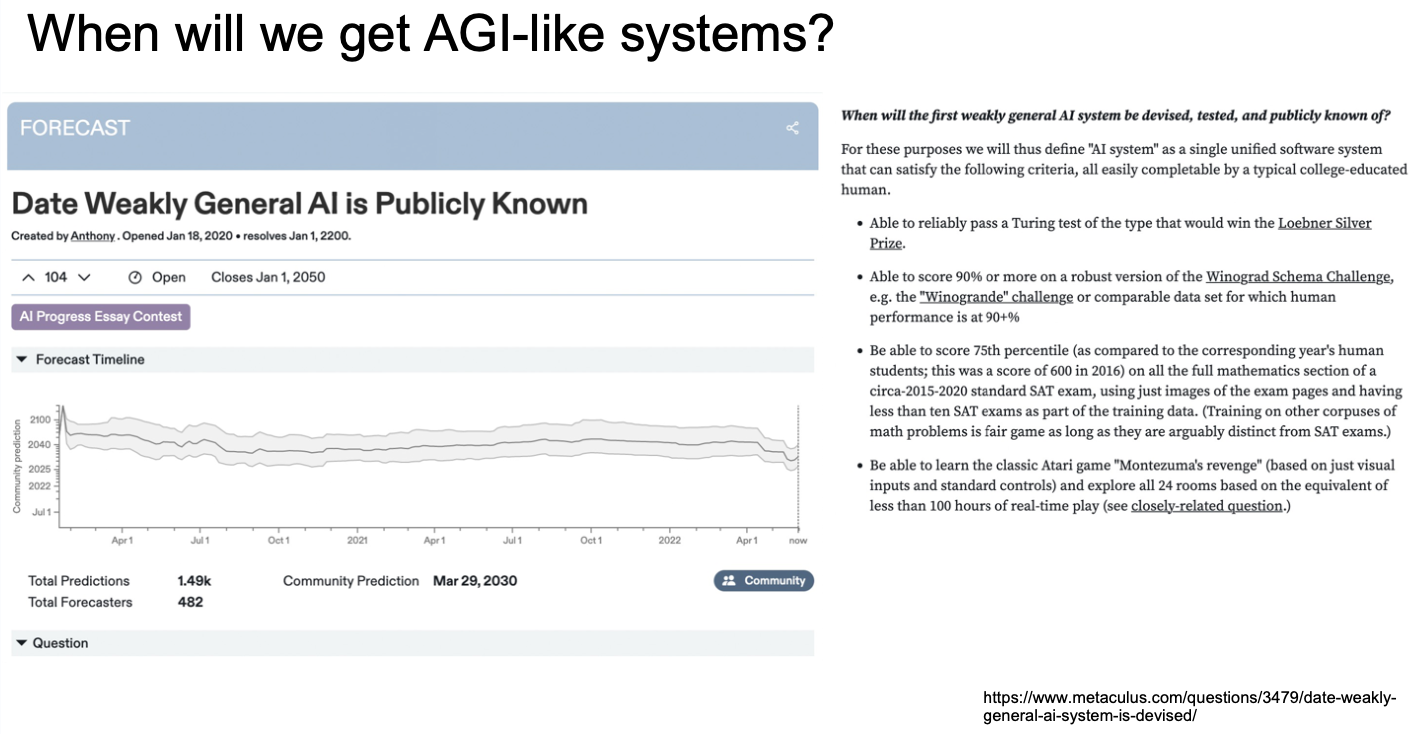
Here's a question that they asked: the date that weakly general AI is publicly known. It's very hard to define what is weakly general AI. They had a whole bunch of conditions here. It needed to be able to reliably pass a Turing Test (of the type that would win the Loebner Silver Prize), needs to be able to score 90% or more on a robust version of the Winograd Schema Challenge, be able to score a 75% percentile on the full mathematics section of a circa 2015 to 2020 standard SAT exam, and be able to learn the classic Atari game Montezuma's Revenge.
On the forecast timeline, there's some guesswork here, and then we see this drop in April and May when all of the new papers came out. They're currently at a community prediction of 2030 - this is quite soon.

So, systems are getting more powerful using large language models. Eventually, we may get to things that are more AGI-like in the future. What are some of the risks of these models?
Turns out people are very concerned about risks. This is skipping a little bit ahead to some of my results from my work, but when I asked people what they were worried about in terms of risks from AI, people mentioned all sorts of things. One thing people mentioned is the idea of trustworthy AI or ethical AI, which includes things like fairness, algorithmic bias, privacy, surveillance, transparency, interpretability, explainability, and worries about manipulation (we can see this in social media). And military applications, algorithmic attacks-- where systems aren't very robust-- and misuse by industries and by nations.
However, I'm going to focus more on risks that I see arising specifically from very general AI. One of the problems that people most talk about is called the alignment problem. This could possibly, as some researchers think, lead to existential risk, and is relatively neglected compared to the amount of risks from narrow AI.
I’ve been talking about risks from general AI and existential risk, which is the death of all humanity. This seems pretty extreme. Are people even worried about this?

Here we reference again the study that I mentioned earlier from Grace et al., surveying the ICML and NeurIPS researchers in 2016. The researchers were asked the chance that high-level machine intelligence would have a positive or negative long-run impact on humanity. The researchers had some percentage on HLMI being “bad” or “extremely bad”, which includes that it could lead to human extinction. High-level machine intelligence was seen as likely to have positive outcomes, but catastrophic risks were seen as possible. Specifically, the researchers had a probability of 5% on an outcome described as extremely bad like human extinction. So that’s a dice roll.
It's pretty interesting that researchers think that there's a 5% median chance that the end result of their work will result in extremely bad outcomes like human extinction. Even though that probability is not the most likely— it's pretty small— 5% is still way higher than I'd like to gamble on. It might be worth putting attention on the possibility of extremely bad situations.

So, what is the problem exactly that people are concerned about? The challenge is often talked about is called the "alignment problem", which is essentially the challenge of building systems that are aligned with human values, that do what humans want, that are aligned with what people want.
This problem occurs in the context of current-day systems as well, and so I'm going to walk through those examples. Here is a boat racing game called Coast Runners. The goal here is to train this boat to learn to win the race.

There’s a course that the designers want the boat to go along, and you can see in the top left corner here, there's a bunch of other boats racing along. The goal was to train the boat to learn to race well and win the game. However, the designers were training on a reward function of points, which you can see at the bottom here. In the end, they got a boat that did exactly what they wanted, so the boat optimized for the number of points. What the boat did was it found this little corner of the course, where could go around in circles and wait for these little turbo-charge point things to develop, and then just go around and collect those. This was the strategy that earned the most points, even if it wasn't racing, or winning the game.

That's an example of the alignment problem, where the designers wanted something from the AI so they set a reward function to try to incentivize it to achieve that reward. But in fact, the thing that they got out wasn't what they wanted. You can imagine that this challenge is even harder as you get to more and more general AI, where we have AI that's acting in the real world that is dealing with increased complexity.
Note that human values are very hard to systematize and write down. They also differ between people, they differ across cultures, they differ over time, things have changed since the 1800s to the present, and so you can imagine that it would be very hard. It may be tricky to try to get an AI that performs exactly as humans intended given that we have to speak to it in the machine or mathematical language which is important in programming. So as we approach AGI and in general powerful systems, you may expect the alignment problem to become more difficult.
But, you know, we've solved everything so far. Humans haven't blown themselves up yet. And we have this thing called trial and error where we can try a system and if it doesn't work, then we'll just fix it and send it out again. Unfortunately, something happens that's very tricky with very general systems. And that is an idea called instrumental incentives.

In the words of Nick Bostrom, who's a philosopher: "Artificial intelligent agents, may have an enormous range of possible final goals. Nevertheless, according to what we may term the "instrumental convergence thesis", there are some instrumental goals likely to be pursued by almost any intelligent agent because there are some objectives that are useful intermediaries to the achievement of almost any final goal."

You can maybe try to guess what those would be. What are some of these instrumental incentives, that would arise as an agent trying to achieve any final goal? [pause]
Some of the ones that Bostrom outlines are self-preservation, acquisition of resources, and self-improvement, which are all different subgoals, that are incentives that arise as you’re an agent trying to achieve anything.

In the words of Professor Stuart Russell, who's a professor at UC Berkeley, "you can't fetch the coffee if you're dead." If you're a coffee-fetching robot, taking coffee-fetching as just some arbitrary goal, then you definitely can't fetch the coffee if you're dead. You have an incentive to make sure that you stay alive so that you can do the goal that you've been assigned. You also might have an incentive to acquire resources or make sure that you have self-improvement, becoming smarter and having better access to power than you would initially.
That's described in the book “Human Compatible” and also in the book “The Alignment Problem” by Brian Christian. This problem of instrumental incentives means that if you have an AI that is sufficiently smart, that is able to act in the world, that is able to plan ahead - it could have an incentive to make sure that it is self preserved, that is to say, it stays alive and that it doesn't get shut down.
If that's true, then we may only have one shot at developing an AI that is fully aligned with human values, because if it's not fully aligned with human values on that first shot, then it's going to have an instrumental incentive to not be shut down, and then we're stuck with whatever we've got.

So, I'm just going to lay out that argument structure again one time. This is the logic that underlies the idea that very powerful systems, not perfectly aligned with human values, could lead to existential risk. You can evaluate the arguments for yourself, whether you think that this makes sense.

AGI is general intelligence, it can by definition think outside the box unlike narrow systems, and it also has capabilities that can affect the real world, even if maybe only initially through text.
It has capabilities such it can duplicate itself, much easier than humans can.
It could use the internet to buy and sell goods. Then it could earn money, and it could consume information and data, and produce and send information over the Internet. We already know how powerful these models are through, for example, social media.
Furthermore, it could augment itself, so it could buy more compute, it could construct datasets. It could refine its code for higher efficiency and write new code. We already have the beginnings of some of these coding capabilities with things like Codex.
AGI will be likely to be able to design and implement any number of ways to kill humans if incentivized to do so. For example, it could use synthetic biology to create pandemics or it could otherwise take advantage of humans being biological organisms while it isn’t.

It also has instrumental incentives, which may arise through being an agent aiming towards any goal, and these include things like self-preservation, acquisition of resources, and self-improvement. Maybe this doesn't happen, or maybe it does, but there's a possibility that maybe instrumental incentives would arise if it is sufficiently agent-like. That would mean that humans consuming resources, or trying to shut off or modify the AI from its original goals, would then be obstacles to the AI achieving its original programmed goal.
So if not perfectly aligned with humans, AI is again incentivized against humans, which is a problem, given the AI is as good at reasoning, or better at reasoning than humans, or at human level. This is not a story about malicious AI, which is popular in the media - things like the Terminator— this is an AI that is indifferent with alien values, where humans are in the way, sort of like ants are often in the way of humans. We step on them and it's not like we hate ants, it's just that we're trying to accomplish things and they are in the way.
Even worse, maybe we only get one shot at an aligned AI, if it is incentivized to not be shut down.

So one could say, “Well, why don't we just make sure that AIs are aligned with humans, then we'd avoid all of this?” And I think that's right. I think if you get a perfectly aligned AI with humans, then we may have a very amazing future. AI could help us with many of the sorts of things that we'd hoped it would, like solving cancer and all sorts of things.
But there's the possibility that leading AI companies may not, by default, create powerful systems that are perfectly aligned with hard-to-specify, changing human values. I don't know that the economic incentives are in place such that AI companies would by default be trying to make sure that these systems are perfectly aligned with human values.
So this is the story of how this sort of thing could lead to existential risk.

Someone may ask who's working on this. If it's a problem, then surely there are some people working on it: and there are! This is called “AI alignment research” or “long-term AI safety research”, although perhaps not as long-term as we would necessarily hope, or “AI or ML safety that scales to advanced systems”. This is in contrast to more near-term safety areas which are also, of course, important.
The field has expanded since 2015. There are now books and conferences and research publications. In industry and non-profits, there is the DeepMind safety team, OpenAI’s safety team, Anthropic, Redwood Research, the Alignment Research Center, and the Machine Intelligence Research Institute.
There are a number of people in academia as well, for example, the Center for Human-Compatible AI (CHAI) at Berkeley which is quite near us. We also have the Cooperative AI Foundation and a bunch of individual researchers at various locations. There are academics at UC Berkeley, NYU, Oxford (correction: this should be Cambridge), and at Stanford—we have researchers at the Stanford Center for AI safety as well. So people quite near home.

In fact, skipping forward a little bit to my results, I asked the researchers in my sample: “Have you heard of AI alignment?” Approximately 39% of them said they had. They wouldn't necessarily be able to define it, but they'd heard the term before. So this is an idea that is sort of around. This is in contrast to “Have you heard about AI safety?”, where something like 76% of people said they'd heard of it.
However, the AI alignment community is growing slower than [AI] capabilities. What I mean by that is that the number of people trying to work on making sure that advanced AI is safe, is smaller than the number of people who are working on the very difficult and tricky problem of trying to make AI have more capabilities, make AI be able to work on all sort of different applications, work in many different contexts. It's this discrepancy in how fast both of these communities are growing that concerns me.
So that's the context for this study, which is understanding how AI researchers perceived these risks from advanced AI. Specifically, I presented AI researchers with some of the claims used to describe this possible existential risk, and explored people's responses to this aspect of safety. That's all the context for my work, and now at this point, let's talk about what I actually did, talk about research methods.
First, I cold emailed researchers who had papers accepted at NeurIPS or ICML 2021. I conducted semi-structured interviews over Zoom that were 40 to 60 minutes. The interviews ran between February 2nd to March 4th 2022. Important to note two things. First, this was before the suite of new AI papers in April and May. Second, Russia invaded Ukraine during the interview period, and researchers did mention this current event. This may have influenced the degree to which people felt sentiments such as, “the world was unstable”, and had existential risk concerns. The interviews were all done over Zoom. I spoke with 86 researchers and asked about their general views of AI. I also asked about several arguments for risks from advanced AI to understand researcher perceptions.

The initial email did not mention risks from advanced AI to avoid biasing the sample. The conversations themselves were in a dialogue style. I really wanted an exploration of opinions and arguments. For example, a typical interview consisted of asking questions, receiving responses, and oftentimes having a healthy back-and-forth discussion. The full data analyses are unfortunately still in progress, so today I will share some qualitative data with you in the interim.

Let's move on to the questions I asked researchers. I started out with this question: “What are you most excited about in AI and what are you most worried about? What are the biggest benefits or risks of AI?”
Then I asked, “In at least 50 years, what will the world look like? Looking a little bit ahead, what are your opinions about policy oriented around AI? What opinions would your colleagues have and how would you like those to change or not change? What opinions do the public have? What opinions do you think the public has on AI and how should that change or not change?”

Next, I progressed into my core questions.
My first core question was the following: “When do you think we'll get AGI (e.g. capable, generalizable AI, with the cognitive capacities to be a CEO)?”
I then went on to my next question: “What do you think of the argument that 'highly intelligent systems will fail to optimize exactly what their designers intended them to do, and this being dangerous?” This is my alignment problem question.
Then I went on to this question: “What do you think about the argument that 'highly intelligent systems who have an incentive to behave in ways to ensure that they are not shut off or limited in pursuing their goals, and this is dangerous.” This is my instrumental incentives question.
 I walked through the questions in basically this order: First I would ask, “What are you most excited about in 50 years?” Next, I went into my core questions. I would ask the questions about policy later in the conversation. Depending on who I was speaking to, sometimes we would get through all these questions. Other times we wouldn't and we'd spend a lot more time on the first few questions.
I walked through the questions in basically this order: First I would ask, “What are you most excited about in 50 years?” Next, I went into my core questions. I would ask the questions about policy later in the conversation. Depending on who I was speaking to, sometimes we would get through all these questions. Other times we wouldn't and we'd spend a lot more time on the first few questions.
In the next part, I am going to present some of the results. I will also ask you to pretend to be a researcher (since you represent a similar sample set), and see what your responses are. The first question I asked is, “What are you most excited about now in the field of AI? What are you most worried about?”
I want to put up some results here. These are the tags that I used to describe the data. I have 86 transcripts and I've just been labeling them with people's responses. For benefits, people said things like health and self-driving cars (came up a lot). Most of the responses were in this large category of increasing productivity, convenience, or AI automating applications. Some said reducing physical risks or AGI.

There were a lot of respondents who were very worried across a large number of risks. You can see there's a variety of different worries on here that span from things like fairness bias, to academics being pushed out, to suffering another AI winter (a decades long stall of AI progress).

I then asked respondents to focus on future AI, hypothetically 50 plus years into the future. It turns out that most people hadn't thought about 50 years into the future. It makes sense as people aren't incentivised to think in this direction, and many people told me that this is a very difficult question. We received a variety of different types of responses. Some people are pretty non-committal, while others stated things like machine learning, robotics, AGI, not AGI, and AI assistance to name a few.
Next, I moved into my first core question. Here is an excerpt from a transcript that I used to talk to most of the researchers. I'm going to give this same thought experiment to you now.

At this point, I would like you to type into the chat and let's see the group’s responses. [Reading responses in chat] “2045. 2090. I don't think that will happen. Yes in 25 years. Not in the next 50 years. 100 years. 50 years. Next 10 years. 30 years. 50 years. 25 years. 2050. 50 years. 2030. 10 years. Not happening. Impossible. In this century 10 years, if climate change doesn't cause all of human collapse. 2040. 20-25 years. 100 years.”

Let's examine how the researchers responded to this same question. Some people said, “yes, it would definitely happen”, and there were some people who gave a very wide range. I didn't see a lot of wide ranges in the chat. Some said under 50 years. I see similar responses in the chat and 50-200 years is also pretty common in the chat. Some interview respondents also said more than 200 years.
A number of respondents said AGI will never happen. The reasons they provided were as follows: “I can't see it based on current progress”, “I don't think we're progressing fast enough”, “I don't think we're going to have anything like general AI.”
Some respondents said that if we were on the path towards developing something like AGI, people would see that it would be dangerous and would stop progress. They would shut down the system. I often felt skeptical of this argument because I thought, “how good are humans at stopping something that has huge amounts of money and power and people behind it?” In these cases, we would dialogue further.
It's very common that people express frustration with public perception of AI. AI researchers seem to encounter a lot of Terminator and more generally fear-based rhetoric. AI researchers said, “Well, this is not a Terminator situation here.” Many people said they would need to see more progress before they could consider that AGI might happen in the future.
Then there was also this argument that humans are special and something about human biology is special and true artificial intelligence isn't possible. Respondents would go on to say that it seems very weird to imagine that something as smart as humans could make something smarter than them.
Another argument was about creativity. There's something about creativity that humans have that wouldn't previously exist, or that we couldn't create. I ended up dialoguing a lot with those people saying, “Evolution made humans. It seems like if we waited long enough, we would maybe get AI that way. Humans are more efficient in many ways at engineering than evolution is.”
I also saw one of the reasons was around AI requiring some sort of embodiment. For example, that we wouldn't be able to get something like AGI unless we had robotics and perhaps even robots that grew up in a similar context as humans.
A number of respondents said we would need a paradigm shift, claiming that it's not going to be the deep learning systems. Although again, I think we have a little bit more evidence that the deep learning system scaling idea is working with the April and May results than we did previously. However, the future is very hard to predict.
A number of respondents wanted to talk about consciousness, but I tried to steer people away from this conversation. I think the danger still exists, even if you don't have conscious AI. A number of respondents also believed AGI would only be achievable after we had fully understood how the brain works.

The next question I asked people was about the alignment problem. I'm going to ask you to put in your replies to this question as well.
[Reading responses in chat] “Very true, correct. Agree. Very reasonable. True agree. Highly likely agree. Yes. Think it is a strong argument. Corner cases are hard to project. Yes. They will do it as the designers intend them to agree. Yes. But they will fail to authorize. Exactly. Agree. Agree. Disagree. Seems like the type of seems like what depends on the type of society you are. This is based on contemporary values and principles. Asimov’s three laws. Agree. True. I don't think it's dangerous. Disagree, humans have to align their own values for those values.”
I think you were more agreeable than my sample on the whole. Many researchers did agree with this statement partly because we see these sorts of problems in contemporary issues.x

Many respondents said that in the long term reward functions probably won't be designed this way. Another sentiment was that in the long term we'd probably test things first and it would turn out fine.
A number of respondents thought this was an invalid argument. For example, they believed the alignment problem would be solved automatically in the course of normal progress. This remains a point of confusion for me. Perhaps we just get better and better at aligning AIs and it follows naturally that it will be perfectly aligned with all of human values. However, I don't think that this is true on the whole. I think that there's a possibility that it won't be in the course of normal progress, given who's developing these systems and what their goals are.
There were also a number of uncertain and unusual responses. I heard from a number of respondents that we need to stop worrying because perfect alignment is not needed.
Another class of responses points out that humans have alignment problems as well. For those points, I often wanted to discuss what I think are the differences between humans and very advanced AI. It is true that humans have plenty of alignment problems as well. People argue with each other and they're not perfectly aligned with each other. However, I think this is different in a few ways. One is that humans are, on the whole, less powerful than I imagine these general AIs would be. If you lead a country, you have a lot of power as a human that can affect many people, but most humans are not in that position. We also have the opportunity to make sure that these systems are aligned with us because we're the ones creating the systems. I think a third point is that humans are more similar to each other compared to AI. Humans have the same biology, and come from similar cultural backgrounds, have similar priors on the world. Because, ultimately we're from the same species. On the other hand, AIs can be exploring the space of reality and they're being designed in the space of reality which is quite large. I would expect that you get more alien values than you would with humans. Thus, their alignment differences would be more stark than those between humans.

I then moved on to our final core question, which is about instrumental incentives.
I asked this question to address the argument that goes as follows, "But in the long term, we'll test it. In the long term it probably won't be designed that way." Please put your answers in the chat.
[Reading responses in the chat] “Agree, agree, agree. Agree, totally agree. Anything that is powerful, never dies, it is too powerful. Agree. Agree. Yes, on the incentive, unsure of the danger. Yeah, absolutely. Virtually certain. Agreed.”

Thanks everyone. The researchers I spoke with were much less agreeable on this particular question compared to the previous ones. Partly, because of the implication that things are, in fact, quite dangerous and they might be very dangerous as we get to this level. There's a number of people who thought it was a valid argument. That included various levels of uncertainty, such as, "Yes, that seems like it might happen.” Another one was “I'm not sure." A number of people who thought it was an invalid argument. There were arguments such as, "reward functions don't work this way," or, "they won't be designed this way in future." We had arguments such as, "We will be able to physically stop the AI." That one, I often pushed back on because I think that if you have a human level intelligence that is very good at reasoning, it may know that you intend to physically stop it. Presumably it could build up barriers in a way. For example, it could upload itself to the internet and then it's much harder to physically stop it.
Some respondents said, "we develop human oversight for AI checks and balances" which is the idea of an AI monitoring another AI. I would be very excited if we had good human oversight. However, I think it's trickier than just putting a human in charge of watching the AI decisions. The AI could think better than the human and deceive the human. However, I think some way or level of human oversight seems pretty key.
There's a counter argument that states we just won’t tell the AI it can be shut down. In these cases I would debate with researchers. My rationale was, "Well, if the AI is operating in reality and can't see the fact that machines can't get shut down, or humans can't die, I imagine it will figure it out on its own just in the course of trying to navigate reality.” Of course, nothing like this happens in current day AI systems. We don't have these instrumental incentive things arising in current systems. I don't think current day AI systems are good enough at reasoning and operating in complex enough domains.
Another response was that an AI becoming conscious won't happen.
Moreover, another response was that it's hard to predict the failures of future systems until we get closer. I'm quite sympathetic to this argument. I think back to the people in the 1950s who were worried about AI, or the AI alignment problem. Since they didn't know about deep learning, they would hardly be able to make a lot of progress. Thus, if we're several paradigm shifts away (if AGI isn't happening for 300 years) then we should probably wait until we're closer before getting really worried about it.
I do think we have more evidence about AGI coming sooner than we were expecting. As a result, I'm supportive of people working on this. I worry that we're not working enough on it. There is a case that AGI might be coming in 10, 20, maybe 40 years. I think the prior argument makes sense if your AGI timelines are long.
Some respondents brought up that they would need to know what type of AGI is being built before they can design around safety. That would instruct what they would need to work on. A number of people thought misuse was a bigger problem. For example, not the systems being designed badly, but rather just people using the systems in very dangerous ways.
Yet other respondents believed AGI is not as dangerous as other large-scale risks that humanity is currently facing (this was influenced by the recent events of Russia’s invasion of Ukraine). People were concerned about nuclear and other existential risks as well.
Those are the things that I walked my researchers through. I spent a lot of time on this last question with respondents. But in some interviews I never got to this question as we spent a lot of time talking about the first two questions.

I would like to provide some concluding thoughts. Why do we care? I think it's likely that AGI will occur during our lifetimes and that the alignment problem could be non-trivial. As a consequence, we need a lot of research effort put into it. There's some probability of existential risk from the alignment problem or other risks from very powerful AI systems. I think we're currently ill prepared for these risks and not investing enough in technical advanced AI safety research. We're seeing a lot of investments in capabilities from governments, from industry, from the scale of talent entering the field. Also, we're investing some amount in current day risks. These include risks such as privacy and robustness, and others. I think that's definitely good.
Some of the current day's research may apply and may scale to very advanced systems. However, I think most of the work today on current day risk doesn't scale very well to advanced AI systems. I think work on robustness might scale better than things like current day fairness. This intuition is just based on the type of research that is being done on the type of system, and how custom built it is for that particular solution. Ultimately, there's much less investment in advanced AI risk.
I hope people agree with the arguments detailing why there might be a small probability of risk with great potential downsides. And, that they can see it is not only the extinction of the current humans, but also their children, grandchildren and humanity full-stop. There is also the very long scale of future humans that is at risk. However, if they are solely concerned with the immediate 2-3 generations, they may invest more in advanced safety research, governance, and good advanced AI. This research project was meant as an exploration for how experts relate to arguments describing risks from AI.

I'd like to acknowledge my collaborators, Sam Huang and Mary Collier Wilkes. My faculty mentor, Tobi Gerstenberg and the people who helped with transcripts: Angelica, Kit, and Shannon. Thank you very much to HAI and CISAC.
I also have additional slides available on the following questions: “If you could change your colleague's perceptions of AI, what would you want them to change it to?” Other questions were, “What do you think the public and media are worried about? How much do you think about policy?” The last one was “What would convince you to work on this?”

The slide I want to end on is further resources. If you were interested by this talk, there's a number of further resources that you can use to learn more. First thing, definitely contact me: I'm Vael Gates, my email is [email protected]. Feel free to email me at any point, including people who watch the recording later.
I have included readings that I think are quite illustrative. If you go to tinyurl.com/existentialriskfromAI, you'll reach an article by Kelsey Piper, an article inbox. It lays out the arguments similar to what I was doing with the quotes from researchers. There's also books to check out. The Alignment Problem, and Human Compatible by Brian Christian and Stuart Russell respectively. Note that the above are introductory and public facing.
If you want, or if you're a researcher and you want more technical readings, feel free to contact me as I can send you a whole list of work in this area. There's also the opportunity to connect with other researchers at Stanford. We have the Stanford Center for AI Safety. We also have the Stanford Existential Risk Initiative. Stanford has a lot of resources and energy in this space. There's also funding for students and faculty interested in doing this sort of alignment research. Funders include Open Philanthropy, FTX Future Fund, and the LTFF. All of those links will be posted online at some point, but if you'd like it in the meantime, please email me, Vael Gates, [email protected]. I want to thank you all for listening and participating, and we can move on to the Q&A.
Q: How sensitive are AI researchers about colonization issues and how AI replicate and sustain these issues? Did you hear about any of that in your conversations?
A: AI researchers were concerned about a number of risks. A lot of them were in the domain of treating people fairly, and making sure that people's rights are preserved in various ways. This was mostly shown in the question where I asked respondents about risks in AI. I quickly pivoted to the core of my questions, which were more about existential risks and very general AI. That being said, many people did mention rights and risks, although not specifically about colonialism.
Q: How do you align AI with human values when human values vary by culture? What happens when the competing AI systems have opposing values?
A: For the part that says competing AI systems have opposing values. Remember humans are making these systems. Ideally, we want to instill in them an ability to adapt to different types of human values and values that change across different people in different areas.
Some of the research areas that people are working on in the alignment space are things like human interaction with AI. This means having human oversight and having AI assistance. Versus by default an AI just pursuing whatever goal gets put into it. We want the AI to have uncertainty over what the reward is, what its goals are, such that it's incentivized to ask humans what it wants at any juncture. Then you still have the question, "Who are the humans that it's asking?". You can imagine various types of systems for aggregating responses across a number of humans. You also might want to ask humans over a long time period, so that they've had a lot of reflection time. You want AI to imagine what humans would do in the future. However, I think we're at a pretty basic level in terms of what research exists, and just how we're getting it aligned to any humans at all.
Q: Often these types of conversations are Eurocentric. Do you feel like your sample of researchers was a global sample? Do you feel like there's gaps?
A: I reached out to just the sample of people who had papers submitted to NeurIPS and ICML. That definitely isn't a fully representative example of the people that exist in the world. It's biased in the ways that you would expect it to be biased. For example, most of the people I talked to were male. Most of the people I talked to were upper-level grad students, like fifth or sixth years in the U.S. or in Europe. There were a couple others from different places. I think my sample was pretty much what you would expect given the distribution of people who work in this space.
Q: Were you surprised that 25% of researchers were not aware of the alignment problem [Edit: she meant 61% of researchers]? Do you have any reactions to that?
A: I think it's revealing that there are so many different types of bubbles in the different communities. It doesn't feel particularly surprising to me for the subset of people who are working in startups or AI applications. On the flip side researchers who worked for OpenAI and DeepMind (the companies that are really pushing AGI or have it explicitly in their mission statements), have heard of this. Some respondents said they had seen alignment mentioned on Twitter or had a colleague working on this area. There were a variety of different types of responses.
Q: AI researchers have big incentives to be optimistic about capabilities, strengths, and downplay weaknesses, including money, enthusiasm, press, culture. Did you measure or adjust for this in your research?
A: I was frankly surprised by the number of people who thought that AGI would never happen or who had a pessimistic outlook on AI. I do think there's certainly a prior baseline of techno-optimism, given those people working in this space. But there was a surprising number of people worried about what was going on at the same time. I didn’t particularly adjust for it as I think I was just trying to get a survey of what people thought on these particular things. The questions I was asking about the alignment problem, about the instrumental incentive, very few people knew the details of those. Thus, this was often quite new to them.
I would like to skip slides to what would motivate researchers to work on this area. I actually asked people whether they'd be willing to work on these sort of alignment questions. A number of people said, "Yes, they would work on long term safety now that it's been presented. They think it's important, they would need to learn more." But a number said, this field seems somewhat pre-paradigmatic, and "We still need help trying to figure out what the questions are, and what directions we should go.” They would need to have a specific problem or incentives. 
There are people working on making this problem area outlined more clearly so that people can be funneled into the space. A number of respondents said, “I would work on current day safety.” I think one person had tried long term safety work, but found it kind of depressing as they hadn't found the rest of the community working on this. I think it's actually very important to surround yourself with a community when you're working on this kind of existential work. Yet other respondents said, "No, I need examples in current systems," or "I'm not in AI,” or “I'm not at the forefront." Various kinds of perspectives on it not being their problem area or an area they can contribute. Most people were not very interested in switching fields, which makes sense. It's a lot of work. I encountered many different kinds of beliefs, thoughts, and biases.
Q: What kind of public policies need to be implemented to curtail these risks? Did you receive any feedback? What are your thoughts on what needs to be done?
A: I think that we have a problem in the policy space where AI as an emerging technology is moving incredibly fast. The number of papers that came out in just April and May (and before), is incredible. The Government isn't set up to deal with this influx. It isn't set up to follow the rapid pace of technology. That is one of the problems that is coming up. In addition, not many people are future looking and I think it's actually very important to be looking ahead. What I most want in policy is for people to be looking ahead to these very advanced AI systems and trying to figure out what we can do about that. I know that the Center for Security and Emerging Technology does a little bit of this in the U.S., and there are a few other places as well. The AI researchers expressed things such as, “they don't know the space well”, “it's not relevant to my work”, “policymakers don't know enough”, “more education is needed”, “scrutiny should be done by specialists”, “it's too slow”, “we should work on short-term issues rather than long-term issues.” This was different from what I argue. Another one was, “we need regulations but don't slow down research.” This was a common point of contention. Some people said we need to regulate AGI, worldwide market regulation, and market incentives.
 Generally I think people hadn't thought very much about policy. They were confused about what to do, because I think it is a very difficult problem. This is why I think we need more researchers and policymakers working in this space, because it's difficult to know what to do. The technical safety aspect is difficult and governance I think even more so.
Generally I think people hadn't thought very much about policy. They were confused about what to do, because I think it is a very difficult problem. This is why I think we need more researchers and policymakers working in this space, because it's difficult to know what to do. The technical safety aspect is difficult and governance I think even more so.
Q: What are you most excited about in AI, and what are you most worried about?
A: I am definitely most worried about this existential risk problem. I, personally, do not want to die prematurely. My belief structure is that I think that there's actually a very good possibility that we'll die early from AGI. This is very worrying to me. However, I'm excited for the near-term future. So, I'm really looking forward to the time when we have all sorts of really convenient technology that lets our lives be very fun and interesting. I'm really not looking forward to the possibility that this problem doesn't get solved.
If it does get solved, however, I think we have a really great future ahead of us! So if we have an AI that is more intelligent than humans, that is perfectly aligned with human values, it can help us achieve whatever we want. I look forward to things like extended life spans for many generations to come. AGI could probably help us get control of the other existential risks that exist. Perhaps we won't be in danger of nuclear risk, pandemics, or climate change. AGI can also do more wild things that you see in science fiction (permitted that is what humans desire in the first place). I really hope that we get more researchers working on AI alignment and long-term safety and are able to reach those good futures.
Moderator: Thank you so much, Vael, for speaking.
Further resources were attached on the Stanford HAI website and recreated below.
Readings
Technical Readings
Funding
Stanford Resources
Contact Vael Gates at [email protected] for further questions or collaboration inquiries.
Great talk, and thanks for including the slides and the transcript!