Claude 3.7's coding ability forced me to reanalyze whether where will be a SWE job for me after college. This has forced me to re-explore AI safety and its arguments, and I have been re-radicalized towards the safety movement.
What I can’t understand, though, is how contradictory so much of Effective Altruism (EA) feels. It hurts my head, and I want to explore my thoughts in this post.
EA seems far too friendly toward AGI labs and feels completely uncalibrated to the actual existential risk (from an EA perspective) and the probability of catastrophe from AGI (p(doom)). Why aren’t we publicly shaming AI researchers every day? Are we too unwilling to be negative in our pursuit of reducing the chance of doom? Why are we friendly with Anthropic? Anthropic actively accelerates the frontier, currently holds the best coding model, and explicitly aims to build AGI—yet somehow, EAs rally behind them? I’m sure almost everyone agrees that Anthropic could contribute to existential risk, so why do they get a pass? Do we think their AGI is less likely to kill everyone than that of other companies? If so, is this just another utilitarian calculus that we accept even if some worlds lead to EA engineers causing doom themselves? What is going on...
I suspect that many in the AI safety community avoid adopting the "AI doomer" label. I also think that many AI safety advocates quietly hope to one day work at Anthropic or other labs and will not publicly denounce a future employer.
Another possibility is that Open Philanthropy (OP) plays a role. Their former CEO now works at Anthropic, and they have personal ties to its co-founder. Given that most of the AI safety community is funded by OP, could there be financial incentives pushing the field more toward research than anti AI-lab advocacy? This is just a suspicion, and I don’t have high confidence in it, but I’m looking for opinions.
Spending time in the EA community does not calibrate me to the urgency of AI doomerism or the necessary actions that should follow. Watching For Humanity’s AI Risk Special documentary made me feel far more emotionally in tune with p(doom) and AGI timelines than engaging with EA spaces ever has. EA feels business as usual when it absolutely should not. More than 700 people attended EAG, most of whom accept X-risk arguments, yet AI protests in San Francisco still draw fewer than 50 people. I bet most of them aren’t even EAs.
What are we doing?
I’m looking for discussion. Please let me know what you think.
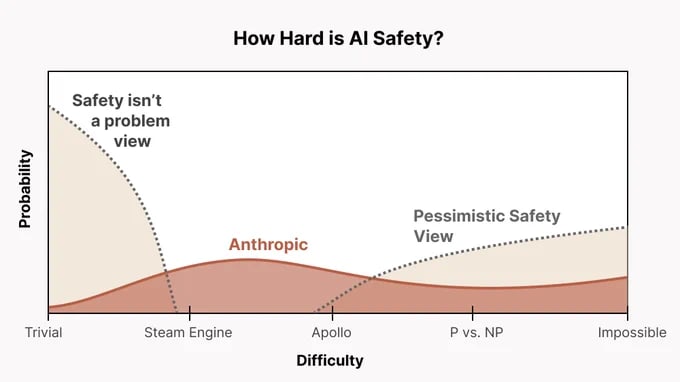
I'm admittedly unusual within the EA community on the issue of AI, but I'll just give my thoughts on why I don't think it's productive to shame people who work at AI companies advancing AI capabilities.
In my view, there are two competing ethical priorities that I think we should try to balance:
If you believe that AI safety (priority 1) is the only meaningful ethical concern and that accelerating AI progress (priority 2) has little or no value in comparison, then it makes sense why you might view AI companies like Anthropic as harmful. From that perspective, any effort to advance AI capabilities could be seen as inherently trading off against an inviolable goal.
However, if you think—as I do—that both priorities matter substantially, then what companies like Anthropic are doing seems quite positive. They are not simply pushing forward AI development; rather, they are working to advance AI while also trying to ensure that it is developed in a safe and responsible way.
This kind of balancing act isn’t unusual. In most industries, we typically don’t perceive safety and usefulness as inherently opposed to each other. Rather, we usually recognize that both technological progress and safe development are important objectives to push for.
That makes sense. For what it’s worth, I’m also not convinced that delaying AI is the right choice from a purely utilitarian perspective. I think there are reasonable arguments on both sides. My most recent post touches on this topic, so it might be worth reading for a better understanding of where I stand.
Right now, my stance is to withhold strong judgment on whether accelerating AI is harmful on net from a utilitarian point of view. It's not that I think a case can't be made: it's just I don’t think the existing arguments are decisive enough to justify a... (read more)