Comments
Cross-posted from my website.
Depth-first plans lay out a path from here to aligned superintelligent AI. We need those kinds of plans. But depth-first plans depend on many assumptions: "We will make AI safe by doing step 1, then step 2, then step 3." Step 1 only works under condition A, step 2 requires condition B, step 3 requires condition C. If A or B or C is false, the whole plan fails (and there's a good chance we all die).
Consider Google's safety plan from April 2025. To my knowledge, this is the best among the frontier AI companies' plans.[1]
Google's plan depends on a series of conditions:
- For the most part, the plan does not consider concrete details of how significantly-more-capable AI systems will behave, instead proposing that Google will figure out how to handle those systems once it understands them better. This only works given (at least) two conditions:
- AI capability improvements occur at a relatively predictable pace, with no unexpectedly large jumps.
- The plan explicitly assumes no "discontinuous" improvements, which is roughly the same thing. It's good that they're being explicit about this.
- Once stronger capabilities emerge, there will be enough time to figure out mitigations.
- AI capability improvements occur at a relatively predictable pace, with no unexpectedly large jumps.
- The plan entails putting stricter measures in place once AI systems become sufficiently capable. This depends on at least two conditions:
- Google (or somebody) can accurately determine what capability level is dangerous.
- Google's evals (or third-party evals) can elicit dangerous capabilities if they exist.
- The plan requires using AI to bootstrap AI alignment. This depends on several conditions:
- We can successfully align the AI that we use for bootstrapping, or misalignment will be easy (enough) to spot, or alignment isn't necessary (e.g. because humans can use amplified oversight to monitor smarter-than-human systems).
- Future Google can be trusted to use enough of its compute to differentially accelerate alignment research, rather than doing something more profitable (for example, differentially accelerating AI R&D).
- AI that's useful enough to solve AI alignment does not pose an existential threat.
- AI alignment is the sort of thing that can, in principle, be solved by strong-but-not-superintelligent AI.
- For example, it may be that moral advances are required before we know how to correctly specify how AI ought to behave; and that unaligned AIs cannot contribute to moral advances.[2]
(The plan depends on many more conditions than that, but I'll keep it short.)
That list included eight conditions. If any one of those conditions fails, then the whole plan fails. Some of the conditions seem likely to be true; others seem questionable. But even if every individual condition is probably true, it's much less likely that they're all true.
Disjunctive conditions are better than conjuctive ones. We can see an example in condition 3.1 above: Google's plan can work if it's possible to align the "bootstrapper" AI, OR if misalignment is easy to spot, OR if it doesn't need to be aligned. Disjunctive conditions are good; more of those, please.
We need breadth-first plans:
- We will take actions X, Y, and Z.
- X depends on condition A.
- Y works even if A is false, but it depends on condition B.
- Z works if A and B are false; it depends on a third condition C.
X + Y + Z works even if two out of three conditions fail.
Some plans have a little bit of breadth. An explicit example from Google's safety plan:
Our approach has two lines of defense. First, we aim to use model level mitigations to ensure the model does not pursue misaligned goals. [...] Second, we consider how to mitigate harm even if the model is misaligned (often called “AI control”), through the use of system level mitigations.
I would like to see more breadth, and recursive breadth—there should be breadth within each component of the plan, and breadth within those sub-components.
The broadest plan that's been published is Peter Barnett & Aaron Scher's AI Governance to Avoid Extinction: The Strategic Landscape and Actionable Research Questions (see also the corresponding LessWrong post). The report explicitly considers four possible future scenarios and how we might achieve a good outcome from within each scenario. The report even includes a flowchart:
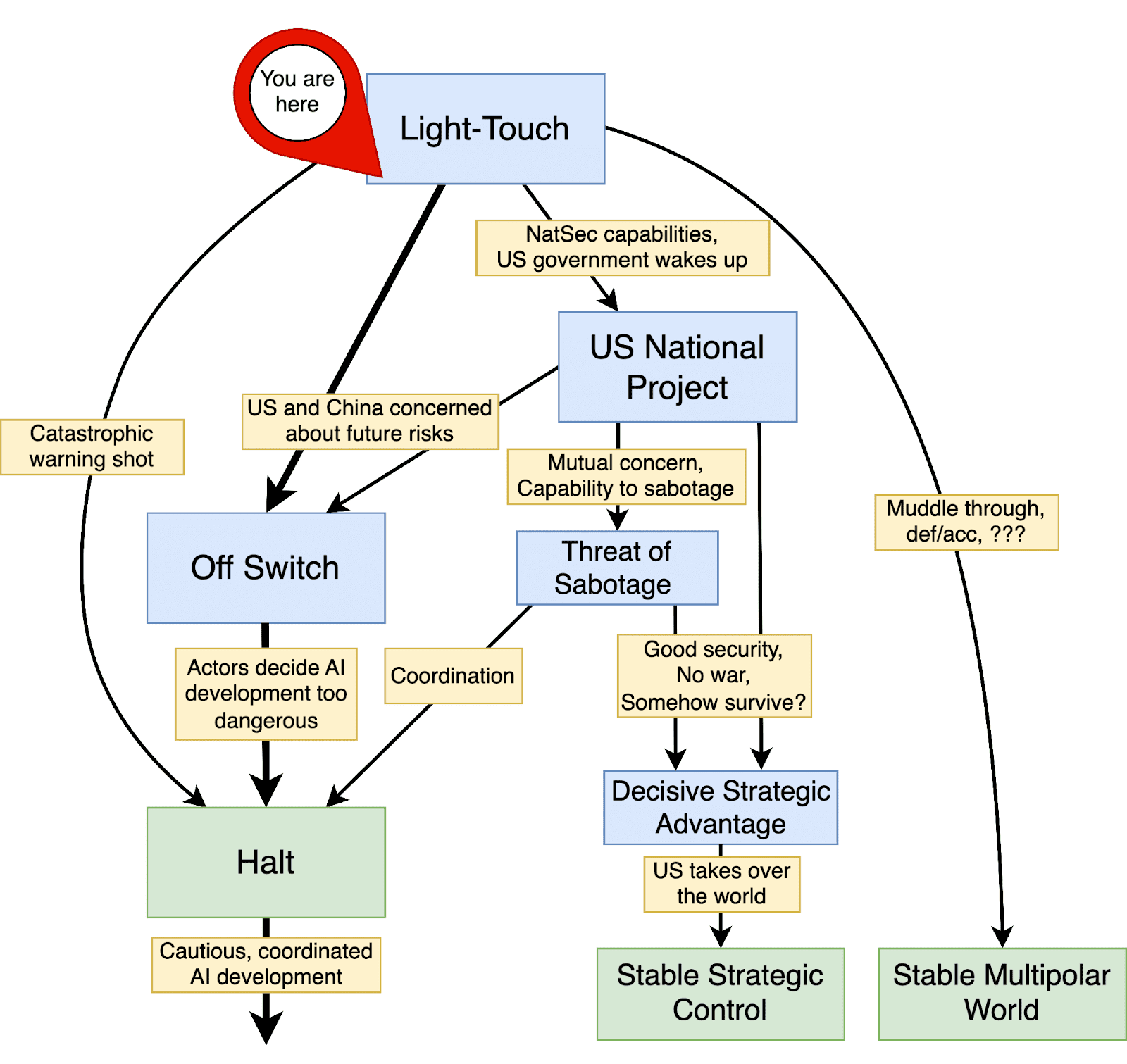
The report goes into more detail about the conditions required for each of the four scenarios to succeed.
Barnett & Scher believe "Off Switch and Halt" is the best strategy. They don't exactly phrase it this way, but according to their report, "Off Switch and Halt" depends on the fewest conditions and has multiple ways of succeeding.
How breadth-first plans can inform what we do
I see two big benefits to writing breadth-first plans:
- We can identify which paths to success depend on the fewest conditions,[3] and focus more on those.
- It's easier to find the biggest holes in the plan.
Root-level breadth matters most
The good news is the branches off the roots are the most important because they have the greatest probability mass. Creating layers of branches off branches off branches quickly gets complicated, but I don't think it's necessary.
My rough attempt at categorizing plans
I made a quick flowchart to categorize AI safety plans at a high level.
- A blue circle indicates an action
- A blue square indicates an outcome
- A red hexagon indicates a necessary condition to achieve an outcome
- A red pentagon indicates a condition that is helpful but not necessary
The idea is that we need a broad set of overlapping plans such that some plan will work, even if many conditions (red nodes) turn out to be false.
(Click here to see the full-size image.)
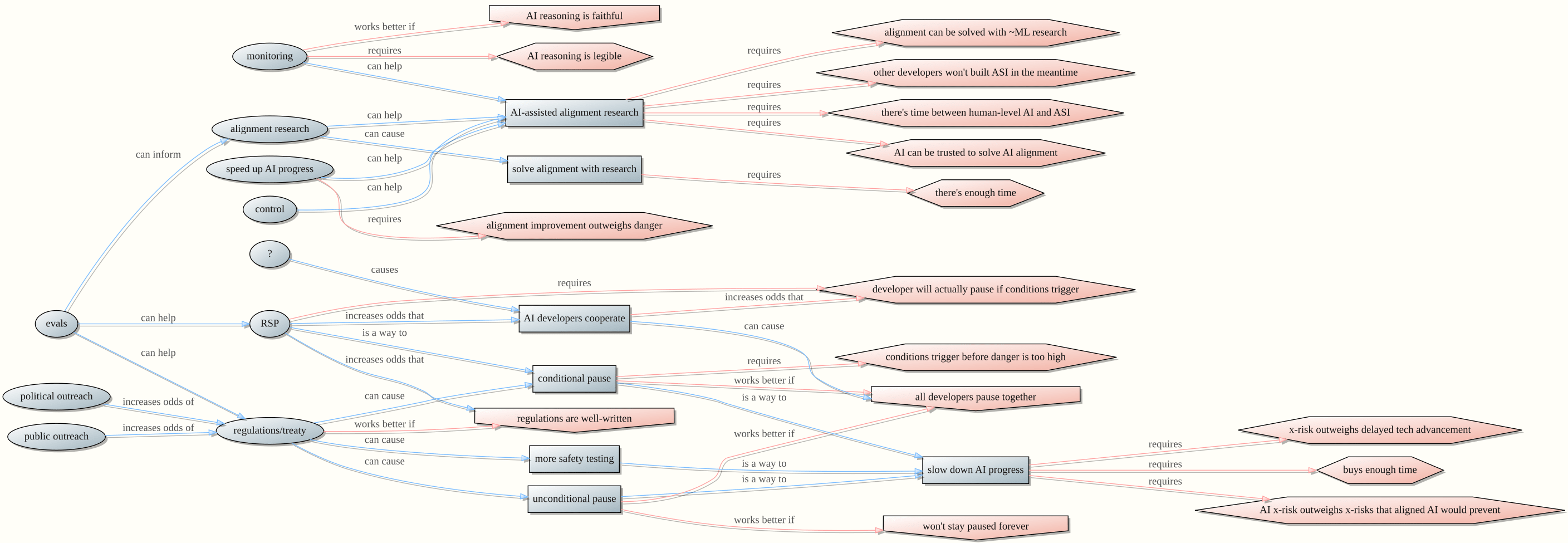
Is this flowchart comprehensive? Definitely not. Is it even accurate? Maybe. My point is that, to make AI safe, we need multiple plans that cover all the ways the other plans could go wrong, and this flowchart is a quick attempt at representing some of those plans.
Future work I'd like to see
- AI companies should publish breadth-first plans. What will they do if a step in their mainline plan fails?
- Governments should pass legislation requiring AI companies to have plans that cover every item on a list of possible future scenarios.
- For example, mandate that companies have different plans for different takeoff speeds.
- AI safety researchers should do research to inform what future scenarios need to be covered.
I originally wrote this article shortly after April 2025, but I procrastinated for a year on finishing it, so I'm not sure about the current state of AI companies' plans. ↩︎
I am skeptical that a bootstrapped-aligned AI will behave morally in ways in which most humans do not behave morally, e.g. eating factory-farmed animals; or that it will be able to correctly resolve the internal inconsistencies in common-sense ethics. For example, in the mere addition paradox, most people accept a set of premises but reject the conclusion that necessarily follows from those premises.[4] ↩︎
Technically, what we want isn't paths that depend on few conditions. We want paths where the joint probability of every condition is as high as possible. But generally speaking, fewer conditions means the probability of success is higher. ↩︎
Philosophy Experiments' Philosophical Health Check asks you a series of questions and purports to identify inconsistencies in your beliefs. I think the questions leave some wiggle room to argue that supposed inconsistencies aren't truly inconsistent, but a more rigorous test would be harder to construct. ↩︎

{kind=link}
Executive summary: The author argues that AI safety planning is dangerously over-reliant on long chains of conjunctive conditions, and calls for "breadth-first" plans that maintain multiple independent paths to success so that the overall effort survives even when individual assumptions fail.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.