Comments
No need to reply to my musings below, but this post prompted me to think about what different distinctions I see under “making things go well with powerful AI systems in a messy world.”
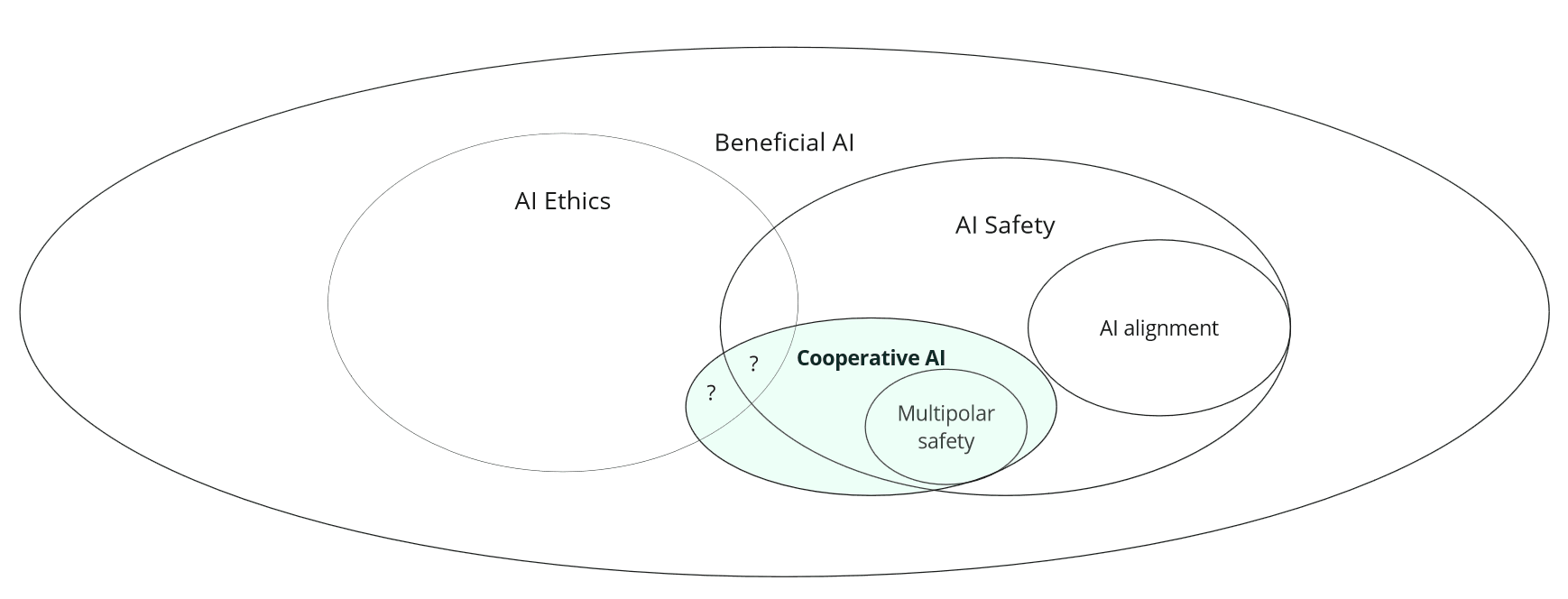
That said, my current favourite explanation of what cooperative AI is is that while AI alignment deals with the question of how to make one powerful AI system behave in a way that is aligned with (good) human values, cooperative AI is about making things go well with powerful AI systems in a messy world where there might be many different AI systems, lots of different humans and human groups and different sets of (sometimes contradictory) values.
First of all, I like this framing! Since quite a lot of factors feed into making things go well in such a messy world, I also like highlighting “cooperative intelligence” as a subset of factors you maybe want to zoom in on with the specific research direction of Cooperative AI.
Another recurring framing is that cooperative AI is about improving the cooperative intelligence of advanced AI, which leads to the question of what cooperative intelligence is. Here also there are many different versions in circulation, but the following one is the one I find most useful so far:
Cooperative intelligence is an agent's ability to achieve their goals in ways that also promote social welfare, in a wide range of environments and with a wide range of other agents.
As you point out, a lot of what goes under “cooperative intelligence” sounds dual-use. For differential development to have a positive impact, we of course want to select aspects of it that robustly reduce risks of conflict (and escalation thereof). CLR’s research agenda lists rational crisis bargaining and surrogate goals/safe pareto improvements. Those seem like promising candidates to me! I wonder at what level to best to intervene with a goal of installing these skills and highlighting these strategies. Would it make sense to put together a “peaceful bargaining curriculum” for deliberate practice/training? (If so, should we add assumptions like availability of safe commitment devices to any of the training episodes?) Is it enough to just describe the strategies in a “bargaining manual?” Do they also intersect with an AI's “values” and therefore have to be considered early on in training (e.g., when it comes to surrogate goals/safe pareto improvements)? (I feel very uncertain about these questions.)
I can think of more traits that can fit into, “What specific traits would I want to see in AIs, assuming they don’t all share the same values/goals?,” but many of the things I’m thinking of are “AI psychologies”/“AI character traits.” They arguably lie closer to “values” than (pure) “capabilities/intelligence,” so I’m not sure to what degree they aren’t already covered by alignment research. (But maybe Cooperative AI could be a call for alignment research to pay special attention to desiderata that matter in messy multi-agent scenarios.)
To elaborate on the connection to values, I think of “agent psychologies” as something that is in between (or “has components of both”) capabilities and values. On one side, there are “pure capabilities,” such as the ability to guess what other agents want, what they’re thinking, what their constraints are. Then, there are “pure values,” such as caring terminally about human well-being and/or the well-being (or goal achievement) of other AI agents. Somewhere in between, there are agent psychologies/character traits that arose because they were adaptive (in people it was during evolution, in AIs it would be during training) for a specific niche. These are “capabilities” in the sense that they allow the agent to excel at some skills beneficial in its niche. For instance, consider the cluster of skills around “being good at building trust” (in an environment composed of specific other agents). It’s a capability of sorts, but it’s also something that’s embodied, and it comes with tradeoffs. For comparison, in role-playing games, you often have only a limited number of character points to allocate to different character dimensions. Likewise, the AI that’s best-optimized for building trust probably cannot also be the one best at lying. (We can also speculate about training with interpretability tools and whether it has an effect on an agent's honesty or propensity to self-deceive, etc.)
To give some example character traits that would contribute towards peaceful outcomes in messy multi-agent settings:
(I’m mostly thinking about human examples, but for many of these, I don’t see why they wouldn’t also be helpful in AIs as well with “AI versions” of these traits.)
Traits that predispose agents to steer away from unnecessary conflicts/escalation:
- Having an aversion to violence, suffering, other “typical costs of conflict.”
- ‘Liking’ to see others succeed alongside you (without necessarily caring directly about their goal achievement).
- a general inclination to be friendly/welcoming/cosmopolitan. Lack of spiteful or (needlessly) belligerent instincts.
Agents with these traits will have a comparatively stronger interest in re-framing real-world situations with PD-characteristics into different, more positive-sum terms.
Traits around “being a good coalition partner” or “being good at building peaceful coalitions” (these have considerable overlap with the bullet points above):
- Integrity, solid communication, honesty, charitable, not naive (i.e., is aware of deceptive or reckless agent phenotypes, is willing to dish out altruistic punishment if necessary), self-aware/low propensity to self-deceive, able to accurately see other’s perspective, etc.
“Good social intuitions” about other agents in one’s environment:
- In humans, there are also intuition-based skills like “being good at noticing when someone is lying” or “being good at noticing when someone is trustworthy.” Maybe there could be AI equivalents of these skills. That said, presumably AIs would learn these skills if they’re being trained in multi-agent environments that also contain deceptive and reckless AIs, which opens up the question: Is it a good idea to introduce such potentially dangerous agents solely for training purposes? (The answer might well be yes, but it obviously depends on the ways this can backfire.)
Lastly, there might be trust/cooperation-relevant procedures or technological interventions that become possible with future AIs, but cannot be done with humans:
- Inspecting source codes.
- Putting AIs into sandbox settings to see/test what they would do in specific scenarios.
- Interpretability, provided it makes sufficient advances. (In theory, neuroscience could make similar advances, but my guess is that mind-reading technology will arrive earlier in ML, if it arrives at all.)
- …
To sum up, here are a couple of questions I'd focus on if I were working in this area:
- To what degree (if any) does Cooperative AI want to focus on things that we can think of as “AI character traits?” If this should be a focus, how much conceptual overlap is there with alignment work in theory, and how much actual overlap is there with alignment work in practice as others are doing it at the moment?
- For things that go under the heading of “learnable skills related to cooperative intelligence,” how much of it can we be confident is more likely good than bad? And what’s the best way to teach these skills to AI systems (or make them salient)?
- How good or bad would it be if AI training regimes are the way they are with current LLMs (solo-competition, AI is scored by human evaluators) vs whether training is multi-agent or “league-based” (AIs competing with close copies, training more analogous to human evolution). If AI developers do go into multi-agent training despite its risks (such as the possibility for spiteful instincts to evolve), what are important things to get right?
- Does it make sense to deliberately think about features of bargaining among AIs that will be different from bargaining among humans, and zoom in on studying those (or practicing with those)?
A lot of the things I pointed out are probably outside the scope of "Cooperative AI" the way you think about it, but I wasn't sure where to draw the boundary, and I thought it could be helpful to collect my thoughts about this entire cluster of things in once place/comment.


This is am amazing post, especially for newbies to Cooperative AI like me. Thanks for helping me grasp what this field entails as well as how to proceed with spreading awareness and applying it to safety research in my region.