Cross-posted from LessWrong and the Alignment Forum
Last summer, we ran the first iteration of the PIBBSS Summer Research Fellowship. In this post, we share some reflections on how the program went.
Note that this post deals mostly with high-level reflections and isn’t maximally comprehensive. It primarily focusses on information we think might be relevant for other people and initiatives in this space. We also do not go into specific research outputs produced by fellows within the scope of this post. Further, there are some details that we may not cover in this post for privacy reasons.
How to navigate this post:
- If you know what PIBBSS is and want to directly jump to our reflections, go to sections "Overview of main updates" and "Main successes and failures".
- If you want a bit more context first, check out "About PIBBSS" for a brief description of PIBBSS’s overall mission; and "Some key facts about the fellowship", if you want a quick overview of the program design.
- The appendix contains a more detailed discussion of the portfolio of research projects hosted by the fellowship program (appendix 1), and a summary of the research retreats (appendix 2).
About PIBBSS
PIBBSS (Principles of Intelligent Behavior in Biological and Social Systems) aims to facilitate research studying parallels between intelligent behavior in natural and artificial systems, and to leverage these insights towards the goal of building safe and aligned AI.
To this purpose, we organized a 3-month Summer Research Fellowship bringing together scholars with graduate-level research experience (or equivalent) from a wide range of relevant disciplines to work on research projects under the mentorship of experienced AI alignment researchers. The disciplines of interest included fields as diverse as the brain sciences; evolutionary biology, systems biology and ecology; statistical mechanics and complex systems studies; economic, legal and political theory; philosophy of science; and more.
This approach broadly -- the PIBBSS bet -- is something we think is a valuable frontier for expanding the scientific and philosophical enquiry on AI risk and the alignment problem. In particular, this aspires to bring in more empirical and conceptual grounding to thinking about advanced AI systems. It can do so by drawing on understanding that different disciplines already possess about intelligent and complex behavior, while also remaining vigilant about the disanalogies that might exist between natural systems and candidate AI designs.
Furthermore, bringing diverse epistemic competencies to bear upon the problem also puts us in a better position to identify neglected challenges and opportunities in alignment research. While we certainly recognize that familiarity with ML research is an important part of being able to make significant progress in the field, we also think that familiarity with a large variety of intelligent systems and models of intelligent behavior constitutes an underserved epistemic resource. It can provide novel research surface area, help assess current research frontiers, de- (and re-)construct the AI risk problem, help conceive of novel alternatives in the design space, etc.
This makes interdisciplinary and transdisciplinary research endeavors valuable, especially given how they otherwise are likely to be neglected due to inferential and disciplinary distances. That said, we are skeptical of “interdisciplinary for the sake of it”, but consider it exciting insofar it explores specific research bets or has specific generative motivations for why X is interesting.
For more information on PIBBSS, see this introduction post, this discussion of the epistemic bet, our research map (currently undergoing a significant update, to be released soon), and these notes on our motivations and scope.
Some key facts about the fellowship program
- 12-week fellowship period (~mid-June to early September)
- 20 fellows, and 14 mentors[1] (for a full list, see our website)
- Fellows had relevant backgrounds in the following fields:
- Complex systems studies, network theory, physics, biophysics (~4)
- Neuroscience, computational cognitive science (~4)
- Formal Philosophy, Philosophy of Science (~5)
- Evolutionary Biology, Genomics, Biology (~3)
- Chemistry (~1)
- Computational social science (~1)
- Economics (~2)
- 6-week reading group (“Deep Read” format[2]) serving as an introduction to AI risk (prior to the start of the fellowship period) (NB we are planning to release an updated and extended version of the same reading programme)
- 2 research retreats (inviting fellows, mentors and a couple of external guests; taking place at a venue outside Oxford, and nearby Prague respectively)
- Individual research support/facilitation (to different degrees for different fellows)
- ~Bi-weekly speaker series throughout the fellowship period
- Further scaffolding in the form of weekly check-ins, optional co-working sessions and occasionally socials,
- Optional stay in Prague to work from a shared office space
- Stipend (3,000 USD/month)
- Financial support for travel and accommodation (e.g. to visit their mentor or the residency)
The original value proposition of the fellowship
This is how we thought of the fellowships’ value propositions prior to running it:
- Generating a flow of insights between the fellow/their domain of expertise towards the AI alignment mentor, and the AI alignment community at large; via the research output.
- Attracting and actuating talent with the competencies and motivation to conduct valuable AI alignment or AI governance research (hits-based).
- Building bridges between AI alignment and other fields with relevant knowledge and talent, thereby lowering current barriers to fruitful exchanges.
- Gaining value of information about the value/tractability/etc. of (facilitating) PIBBSS-style research, i.e. careful, value-sensitive, and epistemically diverse approaches toward the design and implementation of aligned and beneficial artificial intelligent systems drawing on the study of currently existing systems implementing complex or intelligent behavior.
Overview of main updates
- We continue to be excited and have become more confident in the value and tractability of PIBBSS-style research for alignment.
- We continue to be excited about the value of building bridges between the alignment community and other relevant epistemic communities which offer a so-far untouched pool of insights and talent.
- We made positive updates about the tractability of attracting strong candidates of PIBBSS-relevant domains, with the caveat of finding important room for improvement for outreach to conceptual social sciences
- We made positive updates about our ability to adequately introduce them to AI risk and pedagogy, with the caveat of finding important room for improvement concerning technical ML-safety pedagogy
- We gathered preliminary positive evidence about our ability to positively affect trajectory changes. Prior to running the fellowship, a relevant source of skepticism was that people from fields as diverse as the PIBBSS portfolio might be significantly less likely to commit to working on AI alignment in the long term. We haven’t seen this skepticism confirmed, but acknowledge it is largely too early to tell.
- Furthermore, we have been reinforced in our belief that, even if trajectory changes are considered a significant source of value, focusing on research output is a healthy way of causing trajectory change as a side-effect.
- We gained better models about the ways conflicting incentive landscapes might curtail value. (For more detail, see discussion under failures and/or shortcomings.) In particular, we will pay more attention to this consideration in the application process, and will provide more structural support encouraging fellows to produce more and more frequent communicable output to capture the research/epistemic progress that has been generated.
- We suspect a bunch of value might come through hit-based outcomes. We gathered light evidence that there might be significant expected value coming from more “hits-based” avenues, e.g. attracting senior or highly promising scholars and counterfactually contributing to them working on AI alignment and related topics. We think there is value in finding ways to find such cases more systematically, and are exploring ways to do so.
- Fellows with little research experience tended to have a harder time during the fellowship and would have benefited from more structure. We didn’t make a large update here, and still think it is sometimes worth accepting even nominally junior individuals to the fellowship. That said, going forward, we are less likely to accept applicants with less than graduate-level (or equivalent) research experience. We have started thinking about and are interested in exploring alternative ways of onboarding promising people with less research experience.
Main successes and failures
Successes
Overall, we believe that most of the value of the program came from researchers gaining a better understanding of research directions and the AI risk problems. Some of this value manifests as concrete research outputs, some of it as effects on fellows’ future trajectories.
- Research progress: Out of 20 fellows, we find that at least 6–10 made interesting progress on promising research programs.
- A non-comprehensive sample of research progress we were particularly excited about includes work on intrinsic reward-shaping in brains, a dynamical systems perspective on goal-oriented behavior and relativistic agency, or an investigation into how robust humans are to being corrupted or mind-hacked by future AI systems.
- Trajectory changes: Out of 20 fellows, we believe that at least 11–15 gained significant exposure to AI risk and alignment, and we expect that some of them will continue to engage with the field and make meaningful contributions in the future.
- We believe the fellowship had a significant counterfactual impact on 12 fellows, due to many of them having limited or non-existent exposure to AI risk/alignment prior to the fellowship. In some cases, fellows have changed their research directions/careers, some have taken up jobs and some have become active in AI alignment fluid-building-related activities.
- Mentors report finding the fellowship to be a good counterfactual use of their time. Of 10 mentors who filled in the survey, 8 reported it was an equally good or better use of their time, out of which 6 reported it was a strictly better use of their time.
- The main sources of value reported by mentors were: (i) Developing their thinking on a given research direction in AI alignment, benefiting from new perspectives or concrete insights from the fellow; (ii) Being part of a research network relevant to their own research interests/directions; finding actual/potential future collaborators; (iii) Concrete research progress/output produced during the program together with a fellow.
- Mentors, as well as a handful of “external” people (i.e. people who were neither mentors, fellows, nor organizers; who interfaced with different parts of the program, e.g. retreat, research facilitation), reported positive updates about the value and tractability of the research bet (i.e. “PIBBSS-style research”).
- Secondary sources of value;[3] we believe the program generated secondary sources of value in the following domains:
- Progress towards developing a research network
- Running the PIBBSS fellowship has provided us with information about the value of, and improved our ability to act as a sort of Schelling point for PIBBSS-style research. Research retreats in particular, and speaker events and the slack space to a lesser extent, have served to bring together scholars (beyond fellows) interested in AI alignment research from PIBBSS-style angles. We continue to be excited about the potential of supporting and developing this research network and believe we are more likely to notice valuable opportunities.
- Building bridges between AI alignment and other relevant epistemic communities
- We believe that epistemic communities outside of the AI safety/alignment community are working on interesting questions with direct relevance to progress in AI alignment. We have started exploring ways to build “bridges” between these communities, with the goal of engaging both insights and talent.
- For example, we are trialing a speaker series as a way of testing the possibility of broader epistemic and social bridges with specific relevant research directions. The series invites researchers from inside and outside of AI alignment who we believe produce interesting work related to PIBBSS priorities. (If this goes well, we might make the speaker series openly accessible to the AI alignment and other adjacent communities.) Further, we have built bridges in the form of personal networks and fellows themselves sometimes represent such interdisciplinary bridges. Some of our fellows have taken up projects aiming to do such work, e.g. by organizing research workshops or writing introductory materials.
- Developing know-how about Program Design
- Introducing people to AI risk and Alignment Research.
- Running the fellowship program allowed us to make concrete progress in developing pedagogical-content knowledge for AI risk and alignment. Concretely, we ran a 6-week (pre-fellowship) reading group with the deep read format dedicated to an introduction to key phenomena in AI risk, two research retreats (more details below in "Appendix 2") and provided research facilitation throughout the program.
- We did better than expected at introducing people to AI alignment who have no or limited prior familiarity with the field[4] and who came in with a decent amount of inferential distance from AI risk (e.g. due to being part of previously underrepresented epistemic demographics, e.g. the natural or social sciences). This leads us to make slight positive updates about the accessibility of AI risk to researchers from such domains and makes us think that there is potential for value in improving “AI-risk pedagogy” (for future PIBBSS activities and for the AI-alignment community in general).
- However, we also encountered challenges when it comes to facilitating knowledge transfer towards prosaic alignment approaches (see "Failures and/or shortcomings" for more detail).
- Epistemology, Philosophy of Science and Meta-theory of Alignment
- We found that running a diverse research programme is highly synergistic with also making progress on philosophy of science in AI, epistemology of Alignment research, and to some extent AI Strategy. (Note, we believe this to be similar to some parts of Refine’s model, even though the programs were structurally different).
- Examples of frontiers of intellectual progress include: (i) Understanding of AI risk in terms of intelligent behavior and complex phenomena (e.g. shining light on emerging parallels in agent-foundations research and complex systems theory) ; (ii) Philosophical reflections on AI risk and alignment, e.g., non-anthropomorphic articulations of AI risk, problematizing and clarifying the concepts of consequentialism, and goal-orientedness in AI risk stories; (iii) Epistemology and philosophy of science perspectives on AI risk and alignment, e.g., epistemological vigilance with respect to interdisciplinary perspectives on AI risk and alignment, mapping disagreements on risk models and with respect to analogies and disanalogies relevant to AI, improving AI-risk pedagogy, and cross-cohort conversations during the fellowship; (iv) Translation between technical ML safety and other fields, e.g., evolutionary biology and selection theorems.
- Introducing people to AI risk and Alignment Research.
- Learning about outreach and selection of talent from natural and social sciences
- Prior to running the fellowship, one key uncertainty concerned our ability to attract strong candidates from natural and social science backgrounds.[5] Overall, we made positive updates about our ability to do so and think this increases the expected value of future initiatives targeted at people from a similar target audience.
- In terms of disciplines, judging from the applicant pool, we were particularly good at attracting people from philosophy, physics/complex systems, and brain sciences; we did okay but not great in terms of attracting people from biology and computational social sciences; and we underperformed at attracting people from the theoretical social sciences (e.g. legal and political theory, institutional economics and political economy, analytical sociology)
- Miscellaneous other notable outcomes:
- The fellowship produced 3-5 long-term collaborations among fellows and mentors.
- One fellow is organizing an AI-risk workshop at the ALife 2023 conference. We are excited about the potential knowledge and talent overlap between the ALife and the AI alignment community.
- Three fellows are writing an introduction to AI risk targeted at natural systems researchers, in particular, physics and biology researchers.
- Some concrete artifacts created in the context of the fellowship (this does NOT include outputs by fellows):
- A Speaker Series inviting people from the alignment community (e.g., Alex Turner on Shard Theory) as well as outside (e.g., Simon DeDeo on the theory of explanations, Michael Levin on hierarchical agency in biological systems), which we think was a useful exercise in testing the possibility of broader epistemic and social bridges with specific relevant research directions.
- A PIBBSS Research map (currently undergoing a significant update) providing an overview of six clusters of research directions within the PIBBSS research bet, distilled from conversations TJ and Nora had with mentors regarding their key interdisciplinary interests:
- Understanding and Interpreting Minds and Cognition
- Safe Interfaces to Human Preferences
- Processes of Knowledge Production and Reflection
- Social and Economic Coordination
- Evolutionary Selection for X
- Information and Goals in Autonomous Behavior
- Two talks on the landscape of epistemic strategies in AI alignment, and specifically the epistemic assumptions underlying the “PIBBSS” epistemic bet (once at EAGx Prague, once at HAAISS)
- Some initial posts in a series on the philosophy of science of AI alignment (those ideas are ~directly downstream from working on PIBBSS)
- A (WIP) reading list providing an introduction to the broad contours of the AI-risk problem suitable for an interdisciplinary cohort (a side-product of running the reading group).
- A curated list of PIBBSS-style books
- Progress towards developing a research network
Failures and/or shortcomings
- Concrete output: While we are fairly happy with the research progress, we think this insufficiently translated into communicable research output within the timeframe of the fellowship. Accordingly, we believe that a, if not “the”, main dimension of improvement for the fellowship lies in providing more structural support encouraging more and faster communicable output to capture the research/epistemic progress that has been generated.
- Limitations of our ability to facilitate knowledge transfer towards prosaic alignment approach: According to our judgment, transfer towards prosaic alignment approaches (e.g., drawing on insights from evolutionary biology towards training stories) most requires developing novel conceptual vocabulary, and would have benefited from fellows having more familiarity with concepts in technical ML, which we were insufficiently able to provide through our pedagogical efforts.
- We still believe, also thanks to preliminary-yet-promising evidence of research progress as judged by us and mentors, that this type of epistemic progress, if challenging, is still valuable to pursue. Going forward, we will try to tackle these challenges by a) improving the prosaic-relevant pedagogy leading up to and during the fellowship, b) improving our research facilitation capacity, in particular, for prosaic projects, and c) putting more weight on fellows working on prosaic projects to have prior exposure to ML/prosaic AI alignment.
- Conflicting incentive landscapes can curtail value: fellows being embedded in conflicting incentive landscapes (e.g. academic and or professional) has the potential to limit or curtail value. This can manifest as a reduction in fellows’ time commitments to the program/their project, or (implicitly or overtly) influence research-related choices, e.g. the project topic, the scoping or the type of output that is aimed at. Among others, we suspect that academic incentives contributed to a tendency across the cohort to sometimes aim for paper-like outputs over, e.g., forum posts, which in turn leads to a reduced volume of communicable research output within the period of the fellowship (see the point about concrete output above). This can cause delays in ideas reaching and being discussed/evaluated/criticized/improved upon by the larger epistemic community. Going forward, we will be more cognizant of the relevant incentive landscapes, and, in particular, add structures to the program design encouraging fellows to release (even if intermediary) outputs directly as well.
- Outreach to theoretical social sciences: while we were happy about outreach to natural sciences in general, we underperformed at attracting people from the conceptual social sciences (e.g. legal and political theory, institutional and political economy, analytical sociology). We think this represents a missed opportunity.
A brief note on future plans
Overall, we believe the PIBBSS summer research fellowship (or a close variation of it) is worth running again. We applied for funding to do so.
The key dimensions of improvement we are envisioning for the 2023 fellowship are:
- More structural support, encouraging more and faster communicable output capturing the research/epistemic progress that has been generated,
- Improvement of pedagogy (and facilitation) relevant to prosaic projects,
- Being more careful about accepting fellows who are embedded in conflicting incentive landscapes;
More tentatively, we might explore ways of running (part of the program) in a (more) mentor-less fashion. While we think this is hard to do well, we also think this is attractive for several reasons, mainly because mentorship is scarce in the field. Some potential avenues of exploration include:
- Reducing mentor bandwidth demand towards more efficient feedback mechanisms and substituting with:
- Research facilitation,
- Peer-interaction,
- Pairing with junior researchers in AI.
- Exploring alternative programs aimed at audiences of different seniorities, aided by better-scoped projects/research program
Beyond the format of the summer research fellowship, we tentatively think the following (rough) formats are worth further thought. Note that we are not saying these programs are, all things considered, worthwhile, but that, given our experience, these are three directions that may be worth exploring further.
- A reading group/introduction course to AI risk/alignment suitable for natural and social science demographics. We are considering further developing the pre-fellowship reading group, and experimenting with whether it might be worth running it (also) outside of the fellowship context.
- An ~affiliate program, targeted at people who are already able to pursue (PIBBSS-style) research independently. Such a program would likely be longer (e.g. 6 months or more) and focus on providing more tailored support towards affiliates developing their own (novel) PIBBSS-style research directions.
- A range of research workshops/retreats/conferences aimed at specific domains or domain interfaces (within the scope of PIBBSS research interests), aiming to e.g. test or develop specific research bets (e.g., complex systems in interpretability, ALife in agent foundations, predictive processing) and/or create Schelling points for specific demographics (e.g., brain sciences in AI alignment).
PIBBSS is interested in exploring these, or other, avenues further. If you have feedback or ideas, or are interested in collaborating, feel encouraged to reach out to us (contact@pibbss.ai).
We want to thank…
For invaluable help in making the program a success, we want to thank our fellow organizing team members Anna Gadjdova and Cara Selvarajah; and several other people who contributed to the different parts of this endeavor, including Amrit Sidhu-Brar, Gavin Leech, Adam Shimi, Sahil Kulshrestha, Nandi Schoots, Tan Zhi Xuan, Tomáš Gavenčiak, Jan Kulveit, Mihaly Barasz, Max Daniel, Owen Cotton-Barrat, Patrick Butlin, John Wentworth, Andrew Critch, Vojta Kovarik, Lewis Hamilton, Rose Hadshar, Steve Byrnes, Damon Sasi, Raymond Douglas, Radim Lacina, Jan Pieter Snoeji, Cullen O’Keefe, Guillaume Corlouer, Elizabeth Garrett, Kristie Barnett, František Drahota, Antonín Kanát, Karin Neumannova, Jiri Nadvornik, and anyone else we might have forgotten to mention here - our sincere apologies!). Of course, we are also most grateful to all our mentors and fellows.
Appendix 1: Reflections on Portfolio of Research Bets
In this section, we will discuss our reflections on the portfolio of research bets that fellows worked on, which are distributed across a range of “target domains”, in particular:
- Agent Foundations,
- Alignment of Complex Systems,
- Digital Minds and Brain-inspired Alignment,
- Prosaic Alignment (Foundations),
- Socio-technical ML Ethics,
- Experimental and Applied Prosaic Alignment.
We will focus the discussion on aspects like the theory of impact for different target domains and the tractability of insight transfer. The discussion will aim to abstract away from fellow- or project-specific factors. Note, that we shall skip the discussion of specific projects or other details here in the public post.
TL;DR: At a high level, projects aimed towards i) Agent Foundations, ii) Alignment of Complex Systems, and iii) Digital Minds and Brain-inspired Alignment most consistently made valuable progress. Projects aimed at iv) Prosaic Alignment faced the largest challenges. Specifically, they seem to require building new vocabulary and frameworks to assist in the epistemic transfer and would have benefited from fellows having more familiarity with concepts in technical ML, which we were insufficiently able to provide through our pedagogical efforts. We believe this constitutes an important dimension of improvement.
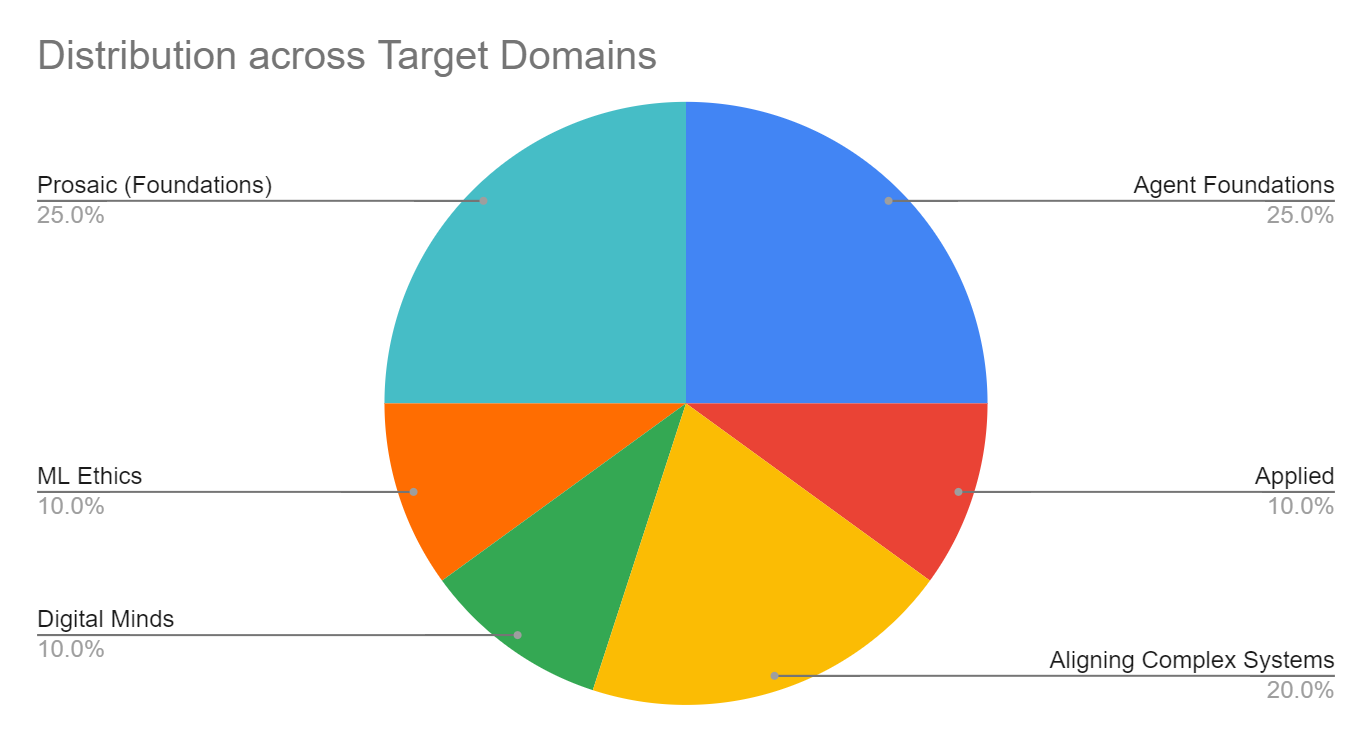
1. Agent Foundations (25–30%) [AF]
- PIBBSS had ~5 fellows (and 4 projects) working on Agent Foundations, i.e., interdisciplinary frontiers for clarifying concepts in the theory of agency, optimization and cognition. These problems aid to contribute towards understanding and characterizing forms of agency to steer towards (e.g., corrigibility) or away from (e.g., power seeking).
2. Alignment of Complex Systems (20–25%) [CS]
- PIBBSS had ~4 fellows (and 3 resulting projects) working on Alignment of Complex Systems, aimed at clarifying and/or formalizing relevant phenomena found within complex adaptive systems of various types and scales. The importance of these topics comes from a better theoretical understanding of learned adaptive behaviors in AI systems, target behaviors of aligned systems, and AI governance/macrostrategy.
3. Digital Minds (and Brain-inspired alignment research; 5–10%) [DM]
- We had ~2 fellows (and 2 projects) working at the intersection of neuroscience (and/or cognitive science) and technical questions on the nature of minds and cognition, especially as they pertain to digital minds or brain-inspired AI systems. These topics seek to understand phenomena relevant to the functioning of sophisticated forms of cognition or to questions concerning the moral status of digital minds, as well as to understand the structure and behavior of mind-like algorithmic systems.
Discussion of AF, CS and DM:
The above three target domains (i.e. Agent Foundations, Alignment of Complex Systems, and Digital Minds) are all, in some sense, similar insofar as they are all basically pursuing conceptual foundations of intelligent systems, even if the three approach the problem from slightly different starting positions, and with different methodologies. The three bundles together accounted for about 50-55% of projects, and roughly 50% of them were successful in terms of generating research momentum. This makes it meaningful to pay attention to two other similarities between them: a) the overlapping vocabularies and interests with respective neighboring disciplines, and b) the degree of separation (or indirectness) in their theory of impact.
The object-level interests in AF, CS, or DM mostly have the same type signature as questions that motivate researchers in the respective scientific and philosophical disciplines (such as decision theory, information theory, complex systems, cognitive science, etc.). This also means that interdisciplinary dialogue can be conducted relatively more smoothly, due to shared conceptual vocabulary and ontologies. Consequently, we can interpret the motivational nudges provided by PIBBSS here as being some gentle selection pressure towards alignment-relevance of which specific questions get investigated.
At the same time, the (alignment-relevant) impact from research progress here is mostly indirect, coming from better foresight of AI behavior and as an input to future specification and/or interpretability research (see discussion in Rice and Manheim 2022[6]). This provides an important high-level constraint on value derived here.
4. Prosaic Alignment Foundations (25–35%) [PF]
- We had ~5 fellows (and 5 projects) working on foundational topics related to work on prosaic alignment (or alignment of advanced ML systems), including work related to value learning, interpretability, ML training, human assistance, scaling laws and capabilities gains, and machine deception. As alignment research on advanced ML systems is most directly proximate to developing practical alignment strategies/proposals (as a key epistemic artifact[7]), these topics constitute what is very likely a critically important area. Projects in the fellowship aimed at bringing in insights from cognitive science, evolutionary biology, statistical mechanics, etc. towards these problems.
Discussion of PF:
While some PF projects did succeed in finding promising research momentum, there was higher variance in the tractability of progress. This bundle also had a meaningfully lower ex-post excitement by mentors (compared to the rest of the portfolio), and caused us significant updates about the epistemic hardness of transferring insights from other disciplines.
Unlike AF+CS+DM discussed above, the interdisciplinary transfer of insights towards prosaic alignment seems to involve building entirely new vocabularies and ontologies to a significantly higher degree. For example, transferring insights from evolutionary theory towards understanding any particular phenomenon of relevance in deep learning, seems to be bottlenecked by the absence of a much richer understanding of isomorphism than what already exists. In fact, the projects in this bundle that did succeed in finding good research momentum were strongly correlated with prior ML familiarity of the fellows.
However, given the potential of high-value insights coming from bets like this, we think further exploring the ways of building relevant ML familiarity for the fellows, such that they can more efficiently and constructively contribute, seems worth investigating further. At the very least, we intend to add pedagogical elements for familiarizing fellows with Machine Learning Algorithms and with ML Interpretability, in addition to improving the pedagogical elements on Information Theory and RL Theory from the previous iteration.
5. Socio-technical ML Ethics (10%) [ME]
- We had 2 fellows (and 2 projects) working on topics on contemporary ethical concerns with ML systems related to topics on epistemic and socio-technical effects of AI. Projects looked at topics such as social epistemology and epistemic risks, normative concepts and trade-offs in ML research, relationship of epistemic content of ML models vis-a-vis scientific discoveries.
- While topics in ML ethics can generally be seen as non-neglected within the larger ML community, we think that facilitating philosophically well-grounded projects on these topics can aid in raising the profile of understudied normative considerations about current and future AI systems. We believe facilitating such work contributes to fostering a strong epistemic environment (from a diversity of opinions on AI risk, especially insofar as they come from well-grounded positions, including disagreements), as well as opening up surface area for positive-sum synergies across a diverse study of normative demands on AI systems and the steering of AI systems towards good-to-have properties.
6. Experimental and Applied Prosaic Alignment (5–10%) [EP]
- We hosted 2 fellows (and 2 projects) working on experimental and applied projects with relevance to topics in prosaic alignment research. These projects involved some ML research and experimentation/engineering that benefited from an interdisciplinary perspective and flow of insights.
- This kind of research is valuable in similar ways to conceptual progress on prosaic alignment (ie. by building and testing new frameworks) and helps in connecting the practical understanding of ML research with conceptual work more directly. We also recognize that such work is non-neglected in the larger community and can sometimes be susceptible towards safety-washing of capabilities-advancing research, however in our judgment the fellows were adequately cognizant of this.
Appendix 2: Retreats Summary
We organized two retreats during the fellowship program for familiarization to AI risk and the alignment problem, facilitation of cross-cohort dialogue, and other benefits of in-person research gatherings. Both the retreats had a mix of structured and unstructured parts, where the structured parts included talks, invited speakers, etc., as well as sessions directed at research planning and orientation, while the unstructured parts included discussions and breakout sessions. A small sample of recurring themes in the unstructured parts included deconfusing and conceptualizing consequentialist cognition, mechanizing goal-orientedness, role of representations in cognition, distinguishing assistive behavior from manipulative behavior, etc.
The first retreat was organized at a venue outside Oxford, at the beginning of the summer, and included sessions on different topics in:
- Introduction to AI Risk (eg. intro to instrumental convergence, systems theoretic introduction to misalignment problems, security mindset, pluralism in risk models, talk on tech company singularities etc.)
- Epistemology of Alignment Research (eg. proxy awareness in reasoning about future systems, epistemic strategies in alignment, epistemological vigilance, recognizing analogies vs disanalogies, etc.)
- Mathematical Methods in Machine Intelligence (eg. intro lecture on information theory, intro lecture on RL theory, talk on telephone theorem and natural abstractions hypothesis, etc.)
- Overview of Research Frontiers and AI Design Space (eg. session on reasoning across varying levels of goal-orientedness, capabilities and alignment in different AI systems, and PIBBSS interdisciplinary research map.)
The second retreat was organized near Prague a few weeks before the formal end of the fellowship, and was scheduled adjacent to the Human-Aligned AI Summer School (HAAISS) 2022. It included fellows presenting research updates and seeking feedback, some talks continuing the themes from the previous retreat (eg. why alignment problems contain some hard parts, problematizing consequentialist cognition and second-person ethics, etc), and practising double crux on scientific disagreements (such as whether there are qualitative differences in the role of representations in human and cellular cognition).
- ^
Close to the end of the fellowship program, Peter Eckerlsey, one of our mentors - as well as a mentor and admired friend of people involved in PIBBSS - passed away. We mourn this loss and are grateful for his participation in our program.
- ^
Here is an explanation of how deep reading groups work. We were very happy with how the format suited our purposes. Kudos to Sahil Kulshrestha for suggesting and facilitating the format!
- ^
By “primary” sources of value, we mean those values that ~directly manifest in the world. By “secondary” values we mean things that are valuable in that they aid in generating (more) primary value (in the future). We can also think of secondary values as “commons” produced by the program.
- ^
6 out of 20 fellows had negligible prior exposure to AI risk and alignment; 10 out of 20 had prior awareness but lack of exposure to AI-risk technical discussions; 4 out of 20 had prior technical exposure to AI risk.
- ^
Some numbers about our application process:
- Stage 1: 121 applied,
- Stage 2: ~60 were invited for work tasks,
- Stage 3: ~40 were invited for interviews,
- Final number of offers accepted: 20 - ^
Issa Rice and David Manheim (2022), Arguments about Highly Reliable Agent Designs as a Useful Path to Artificial Intelligence Safety, https://arxiv.org/abs/2201.02950
- ^
Nora Ammann (2022), Epistemic Artifacts of (conceptual) AI alignment research, https://www.alignmentforum.org/s/4WiyAJ2Y7Fuyz8RtM/p/CewHdaAjEvG3bpc6C
The write up proposes an identification of “four categories of epistemic artifacts we may hope to retrieve from conceptual AI alignment research: a) conceptual de-confusion, b) identifying and specifying risk scenarios, c) characterizing target behavior, and d) formalizing alignment strategies/proposals.”
I didn't quite get why you didn't link to these.
We did not consider the discussion on specific research projects to be within the scope of this post. As mentioned in the beginning, we tried to cover as much as we could that would be relevant to other field builders and related audiences.
There are a few reasons for why it made sense this way.
As discussed in other parts of this post, a lot of research output has not yet been published. Some teams did publicly share their work (as an example, one of the two teams that worked on "dynamical systems perspective on goal-oriented behavior and relativistic agency" posted their updates on the Alignment Forum: [1] and [2], which we hugely appreciate), some have submitted their manuscripts to academic venues, and several others have not yet. This has been for various reasons including e.g. because they are continuing the project and waiting to only publish at some further level of maturity, (info) hazard considerations and sanity checks, preferences over the format of research output they'd want to pursue and working towards that, or the project was primarily directed at informing the mentor's research and that may not involve an explicit public output.
From our end, while we might hold preferences for certain insights to flow outwards more efficiently, we also wanted to defer decisions about the form and content of research outputs to the shared judgement between fellows and their respective mentors.
Note that in some of the cases this absence of public communication till now is fairly justifiable, especially in the cases of promising projects that became long term collaborations.
(Fwiw, as we mention in this post, we have also gained a better understanding of how to facilitate outward communication without constraining such research autonomy, we will take into account in future.)
There are also other reasons why detailed evaluation of projects is difficult to do based on partial outputs and mentor-specific inside-view motivations. In the light of all this, we did decide for this reflections post to be a high-level abstraction, and not include either a Research Showcase or a detailed Portfolio Evaluation. Based on what we understand right now, this seems like a reasonable decision.
At the same time, if a project evaluator or somebody in a related capacity wishes to take a look at a more detailed evaluation report, we'd be open to discussing that (under some info sharing constraints) and would be happy to hear from you at contact@pibbss.ai
I understood that there isn't something to link to yet, based on this from the shortcomings section:
Thanks for sharing it :)