Comments
Announcing ForecastBench, a new benchmark for AI and human forecasting abilities

3 min read · Oct 1, 2024


Authors of linked report: Ezra Karger, Houtan Bastani, Chen Yueh-Han, Zachary Jacobs, Danny Halawi, Fred Zhang, Philip E. Tetlock[1]
ForecastBench is a new dynamic benchmark for evaluating AI and human forecasting capabilities that uses questions about future events to compare leading LLMs and top human forecasters. We evaluated 17 top language models including GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro, comparing their performance against both crowd-sourced human forecasts and predictions from Superforecasters. Our research indicates that AI systems remain worse at forecasting than both superforecasters and (to a lesser extent) the general public.
ArXiv: https://arxiv.org/abs/2409.19839
Website: www.forecastbench.org
Forecasts of future events are essential inputs into informed decision-making. Machine learning (ML) systems have the potential to deliver forecasts at scale, but there is no framework for evaluating the accuracy of ML systems on a standardized set of forecasting questions. To address this gap, we introduce ForecastBench: a dynamic benchmark that evaluates the accuracy of ML systems on an automatically generated and regularly updated set of 1,000 forecasting questions. To avoid any possibility of data leakage, ForecastBench is comprised solely of questions about future events that have no known answer at the time of submission. We quantify the ability of current ML systems by collecting forecasts from expert (human) forecasters, the general public, and LLMs on a random subset of questions from the benchmark (N = 200). While LLMs have achieved super-human performance on many benchmarks, they perform less well here: expert forecasters outperform the top-performing LLM (p-values ≤0.01). We display system and human scores on a public leaderboard at www.forecastbench.org
Until now, most tests of LLM forecasting abilities have relied on models’ knowledge cutoffs: if a model has a cut-off date of April 2023, then the test can ask for forecasts about, say, events in July 2023, and compare them to human forecasts from April 2023. However, it’s difficult to know when exactly the knowledge cut-off date is because closed-source models get updated with new knowledge fairly frequently. Our solution is to use questions about future events, the outcomes of which are unknowable when forecasts are made.
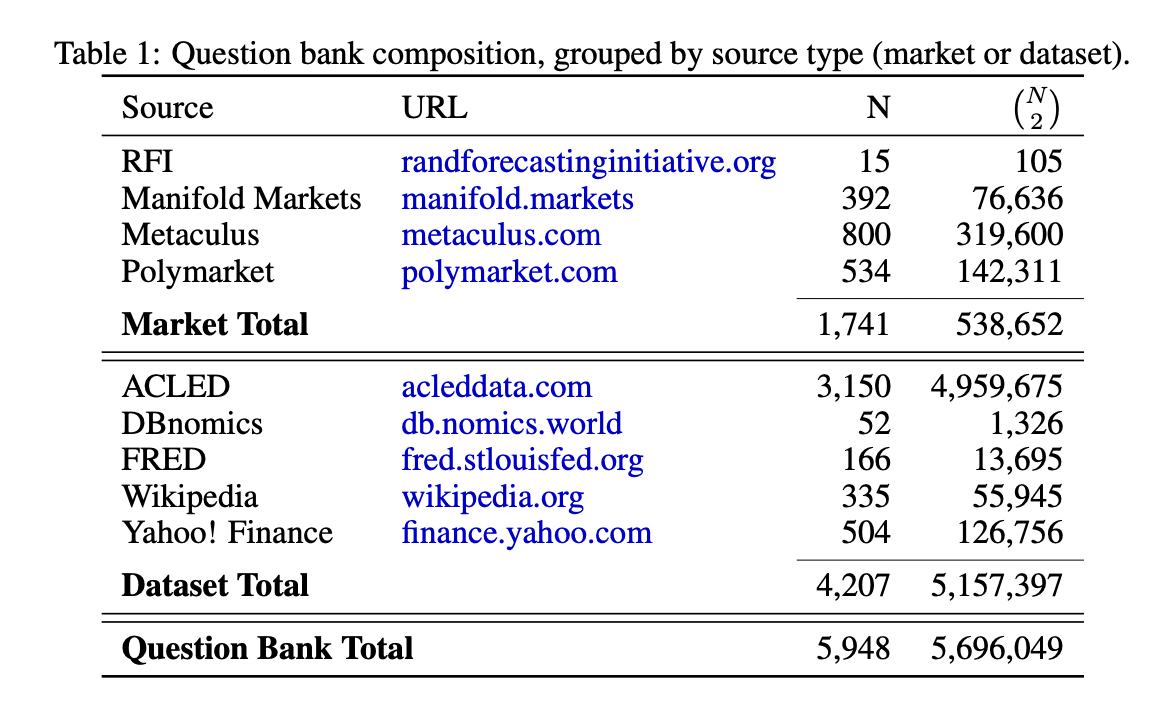
ForecastBench continuously generates new questions about future events, testing the ability of AI models and humans to make accurate probabilistic predictions across diverse domains. It uses a mix of questions from prediction markets and real-world datasets, including Metaculus, Manifold Markets, the RAND Forecasting Initiative, Polymarket, Yahoo Finance, FRED, ACLED (Armed Conflict Location and Event Data), DBnomics, and Wikipedia. We've designed it to be continuously updated, providing an ongoing measure of AI forecasting capabilities.
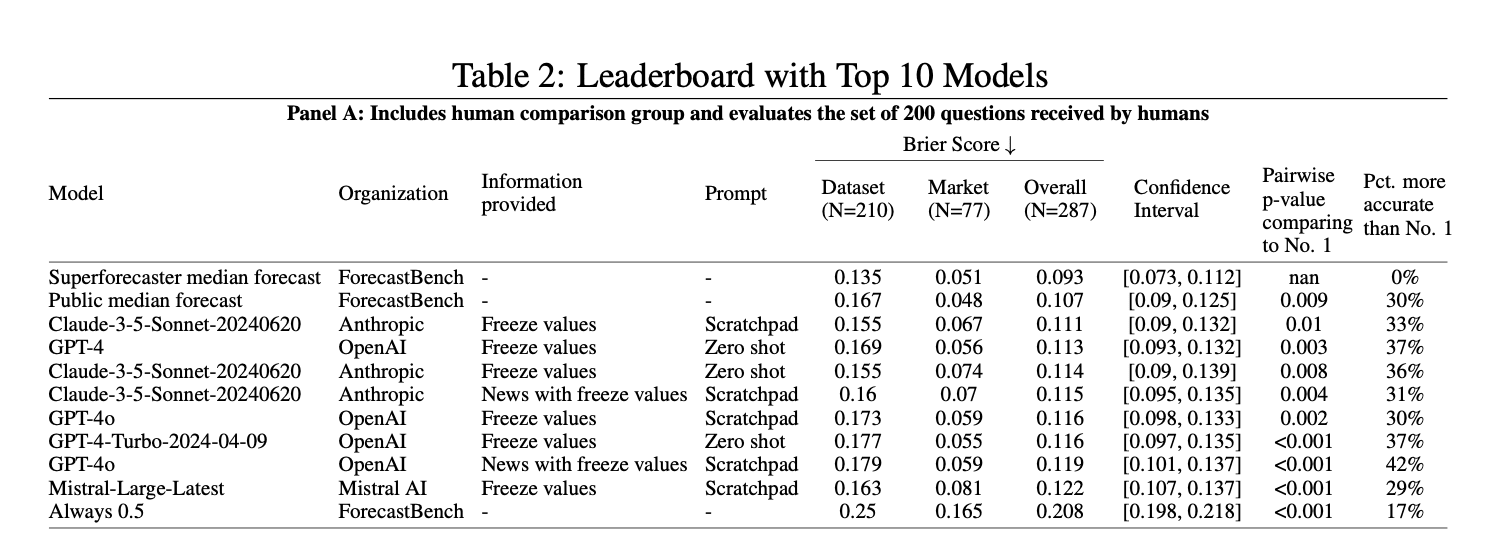
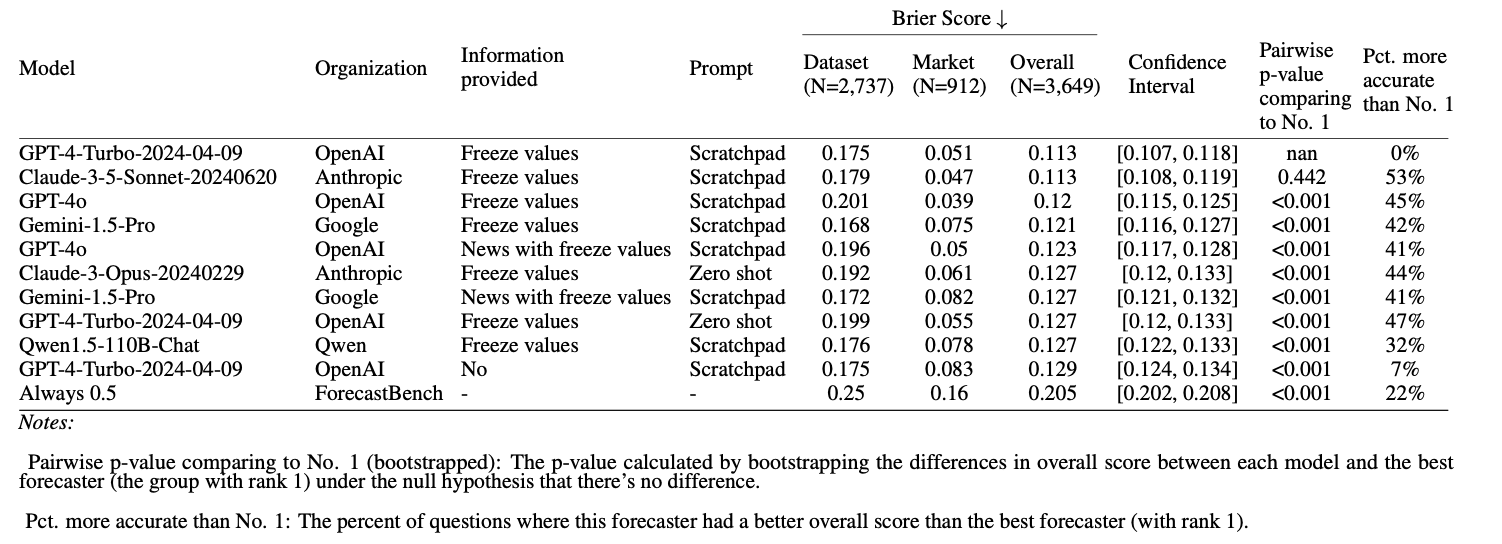
We evaluated 17 top language models including GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro, comparing their performance against both crowd-sourced human forecasts and predictions from Superforecasters. Superforecasters achieved the best overall performance with a Brier score of 0.093. The general public (0.107) and best AI model (0.111) lagged behind. Lower scores indicate more accurate predictions.
So far, the best models lag behind the median of forecasts from ordinary people. This is true even if we use the best prompts we’ve found and allow the models to access the latest news. As AI systems improve, ForecastBench will allow us to track if and when machine predictions surpass human-level performance. For now, our research shows that superforecasters and ordinary humans are still outperforming AI systems at real-world forecasting.
Currently, GPT-4 Turbo and Claude 3.5 Sonnet are the top-performing AI models. However, we expect this to change over time. We'll keep our website updated with the latest results as we test new models.
We established several AI baselines, including zero-shot prompting (where models answer directly without additional guidance) and scratchpad prompting (where models are instructed to show their reasoning step-by-step). We also tested models with additional information like (human) crowd forecasts or news articles. Interestingly, all of the best-performing models had access to crowd forecasts on market questions, but access to recent news didn't significantly help.
Our research shows AI models performed even worse on "combination” questions that require reasoning about relationships between multiple events, hinting at limitations of the models we test when it comes to complex reasoning.
See the full results (comparing Superforecasters, the public, and AI models) and track performance on the ForecastBench website: https://www.forecastbench.org/leaderboards/human_leaderboard_overall.html
Soon we’ll be running biweekly tournaments for LLM forecasting teams so they can see how their model performs on the benchmark! We’ll also release datasets, updated every forecast round, with questions, resolutions, forecasts, and rationales. All will be available at https://www.forecastbench.org/datasets.html
We are grateful to Open Philanthropy for supporting this work, and for providing funding to continue to maintain and update the benchmark for at least three years.
Thanks for doing this work, this seems like a particularly useful benchmark to track the world model of AI systems.
I found it pretty interesting to read the prompts you use, which are quite extensive and give a lot of useful structure to the reasoning. I was surprised to see in table 16 that the zero-shot prompts had almost the same performance level. The prompting kinda introduces a bunch of variance I imagine, and I wonder whether I should expect scaffolding (like https://futuresearch.ai/ are presumable focussing on) to cause significant improvements.