This post was co-authored by the Forecasting Research Institute and Rose Hadshar. Thanks to Josh Rosenberg for managing this work, Zachary Jacobs and Molly Hickman for the underlying data analysis, Bridget Williams for fact-checking and copy-editing, the whole FRI XPT team for all their work on this project, and our external reviewers.
TL;DR
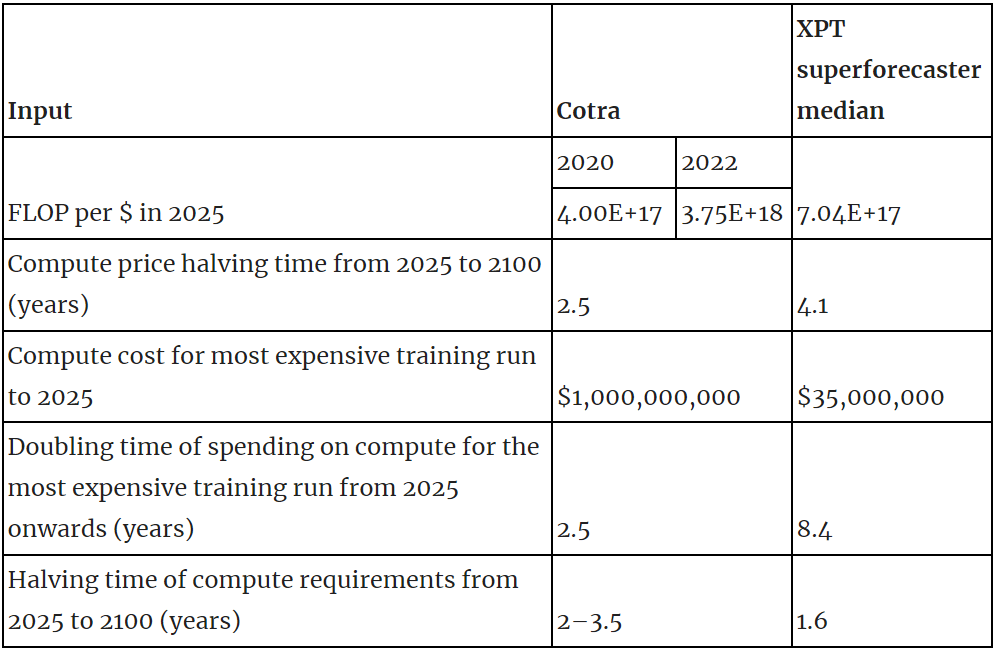
- As part of the Existential Risk Persuasion Tournament (XPT) we asked participants to forecast several questions that allowed us to infer inputs to Ajeya Cotra’s biological anchors model. The XPT superforecasters’ predictions differ substantially from Cotra’s on hardware costs, willingness to spend and algorithmic efficiency:
- There are no XPT forecasts relating to other inputs to Cotra’s model, most notably the 2020 training computation requirements distribution.
- Taking Cotra’s model and 2020 training computation requirements distribution as given, and using relevant XPT superforecaster forecasts as inputs, leads to substantial differences in model output:

*The most aggressive and most conservative estimates can be considered equivalent to 90% confidence interval for the median estimate.[1]
- Using median XPT inputs implies median transformative AI (TAI) timelines of around ~2090, compared to Cotra’s 2050 median timeline in 2020, and her 2040 median timeline in 2022.
- Using 90% confidence interval (CI) XPT inputs:
- Even the most aggressive XPT superforecaster inputs imply a lower probability that the compute required for training TAI is available than Cotra predicts, but the most conservative XPT superforecaster inputs predict TAI by 2100 as less likely than not.
- Most of the difference in outputs comes down to differences in forecasts on:
- Compute price halving time from 2025 to 2100
- Doubling time of spending on compute for the most expensive training run from 2025 onwards
- Note that:
- Both Cotra and XPT forecasts on FLOP/$ are already inaccurate. However, Cotra's will necessarily prove more accurate and the current estimate is outside the XPT 90% CI.
- The XPT forecast for the most expensive training run (by 2024) is already inaccurate, but it's not yet clear whether this forecast is more or less accurate than Cotra's forecast for 2025, which remains much higher than current estimates.
- XPT superforecasters’ all-things-considered TAI timelines are longer than those suggested by using Cotra’s model with XPT inputs. When asked about AI timelines in a survey at the end of the XPT, the median superforecaster put a probability of 3.75% on TAI by 2070. In contrast, Cotra’s model with superforecaster XPT inputs suggests a ~35% probability of TAI by 2070.
- To the extent that timeline beliefs are based on the biological anchors model, and to the extent that these beliefs are based on a training requirements distribution similar to Cotra’s, then the actual value of the inputs on compute price halving time and doubling time of compute spending could have a significant bearing on expected timelines.
Introduction
This post:
- Compares estimates made by Ajeya Cotra and XPT forecasts on questions relating to timelines until the compute required for TAI is attainable, and shows how the differences in forecasts impact the outputs of Cotra’s biological anchors model
- Discusses why Cotra and XPT forecasters disagree, and which forecasts are more accurate
- Notes that XPT forecasters’ all-things-considered TAI timelines are longer than those implied by using XPT forecasts as inputs to Cotra’s model
- Includes appendices on:
- The arguments given by Cotra and the XPT forecasters for their respective forecasts
- XPT expert (as opposed to superforecaster) forecasts relating to the biological anchors model
Background on the Forecasting TAI with biological anchors report
In 2020, Ajeya Cotra at Open Philanthropy published her Forecasting TAI with biological anchors report. The report modeled the probability that the compute required for building transformative AI (TAI) would be attainable in a given year, using:
- An estimate of the amount of compute required to train a TAI model that uses machine learning architectures available in 2020. This was developed using various biological anchors[2] and is referred to as the “2020 training computation requirements distribution”.
- An estimate of when the amount of compute required for TAI would be obtainable, which was developed from forecasts on hardware prices, willingness to spend, and algorithmic efficiency.
Cotra’s ‘best guess’ model outputted a probability of ~46% that the compute required for TAI would be attainable by 2050. Cotra gave her overall median TAI timeline as 2050.
In August 2022, Cotra published some updates to her model, and shifted her median TAI timeline forward to 2040.
Background on the Existential Risk Persuasion Tournament (XPT)
In 2022, the Forecasting Research Institute (FRI) ran the Existential Risk Persuasion Tournament (XPT). From June through October 2022, 169 forecasters, including 80 superforecasters and 89 experts in topics related to existential risk, developed forecasts on questions related to existential and catastrophic risk. Forecasters stopped updating their forecasts on 31st October 2022. FRI hopes to run future iterations of the tournament.
You can see the results from the tournament overall here, results relating to AI risk here, and to AI timelines in general here.
Comparing Cotra and XPT forecasts
Some XPT questions relate directly to some of the inputs to Cotra’s biological anchors model. Specifically, there are XPT questions that relate to some of Cotra’s forecasts on hardware prices, willingness to spend, and algorithmic efficiency:[3]
| XPT question | Comparison | Input to Cotra's model |
| 47. What will be the lowest price, in 2021 US dollars, of 1 GFLOPS with a widely-used processor by the end of 2024, 2030, 2050? | Median XPT superforecaster forecast for 2024 converted from petaFLOPS-days to FLOP per $ and compared with Cotra's forecast for 2025 | FLOP per $ at the start of period (2025) |
| Inferred doubling time between median XPT superforecaster forecasts for 2024 and 2050, compared with Cotra's doubling time from 2025 to 2100 | Compute price halving time in this period (2025–2100), in years | |
46. How much will be spent on compute in the largest AI experiment by the end of 2024, 2030, 2050?
| Comparison of median XPT superforecaster 2024 forecast with Cotra 2025 forecast | Compute cost for the most expensive training run at the start of period (2025), in 2020 USD |
| Inferred doubling time between median XPT superforecaster forecasts for 2024 and 2050, compared with Cotra's doubling time from 2025 to 2100 | Doubling time of spending on compute for the most expensive training run at start of period (2025), in years. | |
| 48. By what factor will training efficiency on ImageNet classification have improved over AlexNet by the end of 2024, 2030? | Inferred doubling time between median XPT superforecaster forecasts for 2024 and 2030, compared with Cotra's doubling time from 2025 to 2100 | Halving time of compute requirements per path over this period (2025–2100), in years |
Caveats and notes
It is important to note that there are several limitations to this analysis:
- Outputs from Cotra’s model using some XPT inputs do not reflect the overall views of XPT forecasters on TAI timelines.
- Based on commentary during the XPT, it’s unlikely that XPT forecasters would accept the assumptions of Cotra’s model, or agree with all of Cotra’s forecasts where there were no relevant XPT forecasts (most notably, the 2020 training computation requirements distribution).
- In a survey we ran at the end of the XPT, superforecasters predicted a 3.8% chance of TAI by 2070, which is much lower than the corresponding ~35% outputted by Cotra’s model using relevant XPT forecasts as inputs.
- Cotra’s model is very sensitive to changes in the training requirements distribution, so inputs on hardware prices and willingness to spend will not be significant for all values of that distribution.
- In particular, for lower estimates of training requirements, XPT inputs would remain consistent with very short timelines.
- None of the XPT forecasts are of exactly the same questions that Cotra uses as inputs.
And some notes:
- In this post, we focus on the forecasts of XPT superforecasters, as opposed to experts, when comparing with Cotra’s forecasts.
- Analysis of the XPT differentiated experts into those with expertise in the specific domain of a question (in this case, AI), those with expertise in other domains related to existential risk (biosecurity, nuclear weapons, and climate change), and those with general expertise in existential risk studies. Too few AI domain experts answered the questions relevant to Cotra’s model to allow for analysis, so the expert figures provided here include all types of experts in the XPT.
- Compared to superforecasters, XPT experts’ forecasts tended to be closer to Cotra by around an order of magnitude, but when inputted into Cotra’s model they produced similar outputs to those drawing on XPT superforecaster forecasts.
- The exception to this is that the most aggressive XPT expert forecasts produced a probability of ~51% that the compute required for TAI is available by 2050, compared with 32% using the most aggressive XPT superforecaster forecasts.
- See Appendix B for more details.
- The number of superforecasters who provided forecasts for each of the three key input questions ranged from 31 to 32.
The forecasts
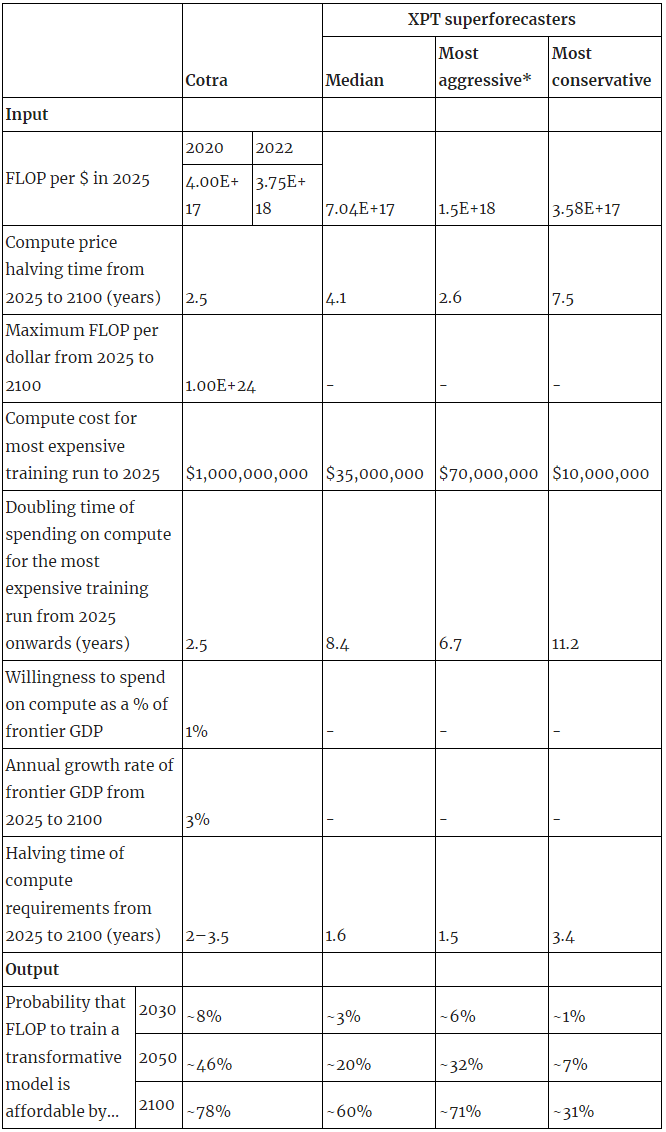
See workings here and here[4]. *The 'most aggressive' and 'most conservative' forecasts can be considered equivalent to 90% confidence intervals for the median estimate.[5]
What drives the differences between Cotra and XPT forecasters?
Differences in inputs
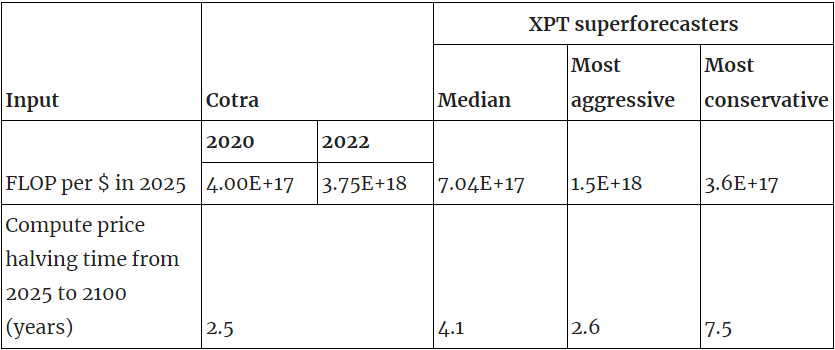
Relevant XPT forecasts differ substantially from Cotra’s.
Hardware costs
FLOP per $ in 2025
- Cotra (2022): 3.8E+18
- XPT: 7E+17 (for 2024)
- Cotra factors in that big companies get cheaper rates on GPUs.[6] XPT forecasters were explicitly asked to forecast the initial retail price of the chip on its release. That would explain most of the difference, assuming rates for big companies are 2–3x cheaper (which is what Cotra claims).
Compute price halving time from 2025 to 2100 (years)
- Cotra: 2.5
- XPT: 4.1 (for 2024–2050)
- In the short run, this difference is driven by Cotra factoring in efficiency improvements specific to machine learning, such as increasing arithmetic-to-communication ratios via e.g. memory locality, further reductions in precision.[7] These improvements were not relevant to the question XPT forecasters were asked, so they didn’t take them into account.
- In the long run, this difference seems to mostly come down to the likelihood that novel technologies like optical computing substantially reduce compute prices in the future.
- Cotra flags that this is her least robust forecast and that after 2040 the forecast is particularly unreliable.[8]
Willingness to spend
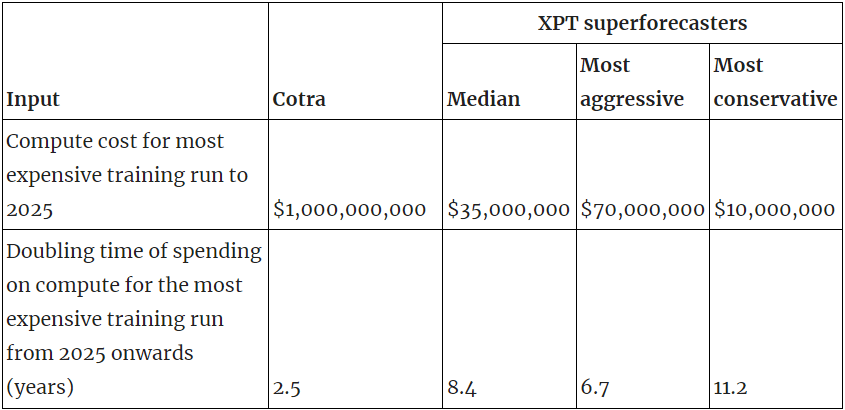
Compute cost for most expensive training run to 2025
- Cotra: $1bn
- XPT: $35m (for 2024)
- XPT forecasters are predicting spending for a year earlier than Cotra.
- XPT forecasters made their predictions three years after Cotra made hers.
- An influential blog post by OpenAI in 2018 noted rapid increases in the compute cost of the most expensive training runs, with a doubling time of 3.6 months. However, more recent analysis using more data suggests a longer doubling time of ~6 months.
- In 2022, Cotra updated downwards on the likelihood of a $1bn training run by 2025.
- Cotra expects that the most expensive training run is likely to be unreleased.[9] XPT forecasters do not highlight this possibility in their forecasts even though unreleased models are included in the relevant resolution criteria. It is unclear whether XPT forecasters disagree substantively with Cotra, missed this consideration in their analysis, or were confused about resolution criteria. If Cotra's expectation is correct, and we accept her claim that unreleased runs are likely to be 2–8 times more expensive, XPT forecasts would still be an order of magnitude lower than Cotra’s forecast, but more comparable with her conservative forecast of $300 million.
Doubling time of spending on compute for the most expensive training run from 2025 onwards (years)
- Cotra: 2.5[10]
- XPT: 8.4 (for 2024–2050)
- Cotra’s reasoning for her 2.5 years doubling time rests on estimating various anchors and working backwards from them:
- She assumes a compute cost of $1bn in 2025 and the incentive to build a transformative model.
- She arrives at a doubling time from 2025–2040 of 2 years by estimating how much companies would be willing to spend on a project overall, and the ratio of overall spending to spending on compute for final training runs.
- Then assuming that the doubling times lengthens, hitting a cap at 1% of GDP and eventually syncing up with the GDP growth rates of the largest national economy, which Cotra estimates at 3%.
- Many XPT forecasters approached the question differently, by estimating current costs and then adding a modest multiplier.
Algorithmic progress
Halving time of compute requirements from 2025 to 2100 (years)
- Cotra: 2–3.5
- XPT: 1.6 (for 2024–2030)
- Cotra notes that she spent very little time on this forecast.[11]
- XPT forecasts tend to be more conservative than Cotra and here they are more aggressive.
- Comparability of the Cotra and XPT forecasts is particularly low here:
- XPT forecasters were asked to forecast expected improvements on a specific narrow application (image classification on ImageNet). Cotra expects improvements on narrow applications to be easier than improvements on a general and poorly defined metric like TAI.[12] This likely explains much of the difference in forecasts here.
- Cotra also draws on data from narrow applications, but then applies an upwards adjustment factor. We haven’t applied an adjustment factor to the XPT forecasts in our main analysis, as Cotra isn’t explicit about her methodology and we didn’t want to introduce more subjectivity.[13]
- We did a robustness check using an estimated upwards adjustment factor, and found that adjusting XPT forecasts on compute requirement halving times does not significantly shift model outputs. (See appendix for details.)
- Cotra also draws on data from narrow applications, but then applies an upwards adjustment factor. We haven’t applied an adjustment factor to the XPT forecasts in our main analysis, as Cotra isn’t explicit about her methodology and we didn’t want to introduce more subjectivity.[13]
- The XPT forecasts were only for 2024 and 2030, whereas Cotra’s estimate was for 2025–2100.
- Cotra estimates different halving times for each of her six biological anchors.[14] We haven’t attempted to extrapolate this from XPT forecasts, because Cotra’s methodology isn’t very transparent and we didn’t want to introduce more subjectivity.
- XPT forecasters were asked to forecast expected improvements on a specific narrow application (image classification on ImageNet). Cotra expects improvements on narrow applications to be easier than improvements on a general and poorly defined metric like TAI.[12] This likely explains much of the difference in forecasts here.
Differences in outputs
Taking XPT forecasts as inputs to Cotra’s model leads to differences in outputs.
- Taking the median forecasts from XPT superforecasters as inputs to Cotra’s model produces a probability that the compute required for TAI is attainable by 2050 of ~20% (~3% by 2030, ~60% by 2100).
- The most aggressive[15] forecasts from XPT superforecasters produce a probability of ~32% by 2050 (~6% by 2030, ~71% by 2100).
- The most conservative[16] forecasts from XPT superforecasters produce a probability of ~7% by 2050 (~1% by 2030, ~31% by 2100).
- Cotra’s best guess inputs produce a probability of ~46% by 2050 (~8% by 2030, ~78% by 2100).
- In 2020, Cotra gave an overall median TAI timeline of 2050.
- In 2022, she updated her overall median to 2040.
- Using the XPT forecasts as inputs to the model would translate to overall median TAI timelines of:
- Median: ~2090
- Most aggressive: ~2065
- Most conservative: >2100
Most of the difference in outputs comes down to differences in forecasts on:
- Compute price halving time from 2025 to 2100.
- Doubling time of spending on compute for the most expensive training run from 2025 onwards.
- This is the single biggest driver of difference among the inputs we have XPT forecasts for.
Which forecasts are more accurate?
It’s not possible yet to determine which forecasts are more accurate across the board; in some cases we’d need to wait until 2100 to find out, and the earliest resolution date for final comparison is 2025.
That said, since Cotra and the XPT forecasters made their predictions, relevant new data has been released which already gives some indication of accuracy on some inputs. Epoch have developed estimates of the current FLOP per $ and the compute cost for the most expensive training run to date. We can compare these to the Cotra and XPT estimates:
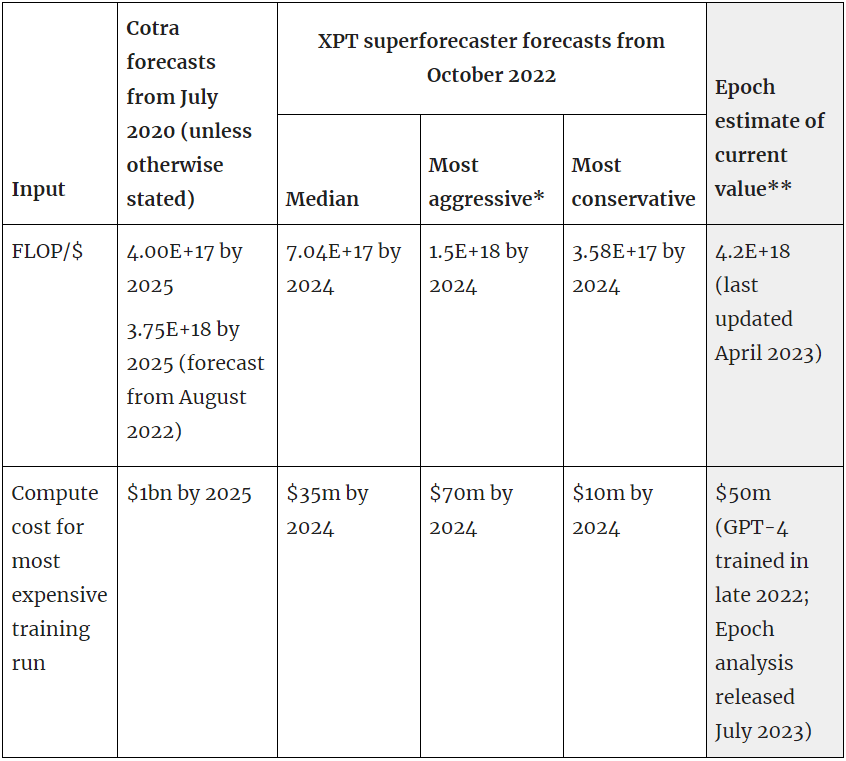
* The 'most aggressive' and 'most conservative' forecasts can be considered equivalent to 90% confidence intervals for the median estimate.[17]
**Note that these Epoch estimates are not forecasts of what these inputs will be in future, but estimates of the current value of the inputs at a given point in time (dates in brackets in the table). See here for the FLOP/$ estimate and here for the estimate of compute cost for most expensive training run.
If we accept the Epoch estimates, then this suggests that as of 2023:
- Both Cotra and XPT forecasts on FLOP/$ are already inaccurate, although Cotra's 2022 estimate will necessarily prove more accurate (and the current estimate is outside the XPT 90% CI).
- The XPT forecast for the most expensive training run (by 2024) is already inaccurate (though it's not yet clear whether this forecast is more or less accurate than Cotra's forecast for 2025, which remains much higher than Epoch’s current estimate).
It remains to be seen how inaccurate the XPT (and Cotra’s) forecasts will prove, but it is striking that these XPT forecasts are already inaccurate even though they were made after Cotra’s and for an earlier resolution date.
The forecasts for which it’s not yet clear whether Cotra or XPT forecasters will prove more accurate are:
- Halving time of compute requirements from 2025 to 2100
- There is a recent Epoch estimate of this using historical data (0.75 years, analysis published Dec 2022), but it won’t be clear until much closer to 2100 which forecasts are on track to be more accurate.
- Compute price halving time from 2025 to 2100
- Though we note that both XPT and Cotra forecasts on FLOP/$ for 2024/2025 are already inaccurate, and that our inferred XPT halving time is based on XPT forecasts on FLOP/$ for 2024 and 2050.
- Doubling time of spending on compute for the most expensive training run from 2025 onwards, though note that:
- Our inferred XPT doubling time is based on XPT forecasts on most expensive training runs by 2024 and 2050, and the 2024 forecast is already inaccurate.
- There is a substantial difference (greater than one order of magnitude) between Epoch’s estimate of the most expensive training run to date, and Cotra’s 2025 forecast.
XPT superforecasters’ all-things-considered view on TAI timelines
As we mentioned above, this analysis takes Cotra’s model and many of her inputs as a given, and uses XPT forecasts for particular inputs. It cannot be read as a statement of XPT forecasters’ all-things-considered view on TAI timelines.
In fact, from questions in a postmortem survey conducted at the end of the XPT, we know that XPT forecasters’ all-things-considered TAI timelines are longer than this analysis of Cotra’s model suggests.
Superforecasters made the following explicit predictions in the postmortem survey:
- Probability of AGI by 2070: 13%
- “Artificial general intelligence is defined here as any scenario in which cheap AI systems are fully substitutable for human labor, or if AI systems power a comparably profound transformation (in economic terms or otherwise) as would be achieved in such a world.”
- Probability of TAI by 2070: 3.75%
- “Transformative AI is defined here as any scenario in which global real GDP during a year exceeds 115% of the highest GDP reported in any full prior year.”
- Probability of >15% GWP growth by 2100: 3%
- “By 2100, will the global real GDP in a year ever exceed 115% of the highest GDP reported in any full prior year?”
The output of Cotra’s model using superforecaster XPT inputs is more aggressive than XPT superforecasters’ overall views. Using the XPT superforecaster inputs in Cotra’s model outputs 35% by 2070, and 60% by 2100.[18]
Note that:
- XPT superforecasters think AGI is considerably more likely than TAI by 2070.
- XPT forecasters' views appear inconsistent.
- ~26% of superforecasters predicted AGI by 2070 as 50% likely or more, but ~38% agree or strongly agree that AGI will arise by the end of 2072. ~36% of experts predicted AGI by 2070 as 50% likely or more, but ~61% agree or strongly agree that AGI will arise by the end of 2072.
- Superforecasters predict a 3% chance of >15% growth by 2100,[19] and a 3.75% chance of TAI (defined as >15% growth) by 2070.
- Experts predict a 10% chance of >15% growth by 2100,[20] and a 16% chance of TAI by 2070, so their views are even less coherent on this question.
Appendix A: Arguments made for different forecasts
Both Cotra and the XPT forecasters gave arguments for their forecasts.
In Cotra’s case, she puts forward arguments directly in the relevant section of her report and in appendices.
In the XPT case:
- During the tournament, forecasters were assigned to teams.
- Within teams, forecasters discussed and exchanged arguments in writing.
- Each team was asked to produce a ‘rationale’ summarizing the arguments raised in team discussion.
- The rationales from different teams on each XPT question were summarized by the FRI team.
This appendix contains direct quotes from:
- Cotra’s report, appendices and 2022 update
- XPT team rationales
Note that we haven't made any edits to these quotes, including where there are grammatical errors.
Hardware costs
Meta points
- Cotra thinks these numbers are the least robust in her report.[21]
- She also thinks the forecast is more reliable till 2040 and then less reliable.[22]
Cotra’s arguments
In 2020:
- Recent trends have been slower, are probably more informative, and probably reflect diminishing returns.[23]
- The older, faster trend held for a long time and over multiple hardware transitions. Extrapolating the recent trend for several times longer than the older trend seems wrong.[24]
- NVIDIA A100 is a big improvement on the V100.[25]
- Specializing chips for deep learning applications will create a one off improvement in the next 5–10 years.[26]
- In the longer term, unknown unknowns and new technologies will probably lead to further improvements.[27]
- Technologies noted: optical computing, three-dimensional circuits, reversible computing, quantum computing.
In 2022:
- The 2020 forecast used V100 as its reference machine, but the A100 was 2–3x more powerful.[28]
- The 2020 forecast was based on rental prices, but big companies get 2–3x cheaper prices.[29]
- The 2020 forecast assumes ⅓ utilization of FLOP/s, but utilization then improved to around 50%.[30]
XPT arguments
Arguments for lower hardware costs (closer to Cotra’s forecasts):
- Some XPT forecasters used outdated data to form their base rates, and so unknowingly predicted future lowest costs as being higher than present costs.[31] This is an argument for lower forecasts than Cotra or XPT.
- Covid inflated costs of electricity and hardware, but efficiencies in development and falling energy prices will drive costs down again.[32]
- Recent price-performance trends have been slower than usual, and there could be a return to the older order of magnitude improvements every 8 or 4 years.[33]
- Novel technologies might lead to a discontinuous drop in prices.[34]
- Possible technologies cited are optical computing, quantum computing, reversible and three-dimensional circuits, and unknown advances.
- Historical trends show an order of magnitude improvement in price-performance every decade.[35]
Arguments for higher hardware costs than Cotra forecasts:
- Since 2010 the rate of price decline has slowed.[36] One team cited the IEEE report, ‘More Moore’.
- War, particularly over Taiwan, could raise prices.[37]
- Global economic decline could slow technological advances.[38]
- Progress may be getting harder.[39]
- We may reach fundamental physical limits.[40]
- Demand for more efficient chips may be low.[41]
- Future technological developments are uncertain and could raise prices.[42]
- FLOP rates might stabilize in the future and optimization might shift to memory architectures.[43]
- Materials for chips are rare and have other uses.[44]
- A catastrophe or extinction event could halt price decreases.[45]
Willingness to spend
Cotra’s arguments
- On compute cost for most expensive training run to 2025:
- $1bn by 2025 is consistent with recent spending scaling according to this 2018 OpenAI blog.[46]
- It is also consistent with the existing resources of AI companies like Google.[47]
- Excitement around deep learning is sufficient such that several companies will be willing to spend a few hundred million dollars on experiments which don’t generate much revenue at the moment.[48]
- Spending on the most compute intensive unreleased/proprietary model is likely 2–8x larger than AlphaStar already.[49]
- “It also seems quite likely that by the end of 2020, a single ML training run costing at least $20M will have been completed, and that by the end of 2021, a single training run costing at least $80M will have been completed.”[50]
- On doubling time of spending on compute 2025–2040:
- [Note that for these arguments Cotra assumes that a company has spent $1bn on a training run in 2025 and has the incentive of building a transformative model.][51]
- By 2040 an AI company could spend hundreds of billions on a project to train a transformative model.[52]
- The ratio of overall project spend to spend on compute for final training runs may be 2–10x.[57]
- This suggests that in 2040 an AI project would be willing to spend $100bn on compute for a final training run.[58]
- This implies a doubling time of 2 years.[59]
- On long-run willingness to spend:
- Eventually growth in spending on compute will keep pace with the GDP growth of the largest national economy.[60]
- 3% is in keeping with average US growth over the past few decades.[61]
- Anchoring to the Manhattan and Apollo projects would suggest that the maximum spend would be around 1% of the GDP of the largest country.[62]
- Eventually growth in spending on compute will keep pace with the GDP growth of the largest national economy.[60]
- 2022 update: “There’s been a major market downturn that hit tech companies especially hard; it seems a little less likely to me now than it did when writing the report that there will be a billion dollar training run by 2025.”
XPT arguments
General comments:
- Low forecasts are derived from applying a modest multiplier to current costs. Higher forecasts identify anchors (such as company budgets or costs of previous mega-projects) and assume fast scaling up to those anchors.[63]
- Lower forecasts assume current manufacturing processes will continue. Higher forecasts imagine novel technology.[64]
Arguments for lower spending than Cotra forecasts:
- Training costs have been stable at around $10m for the last few years.[65]
- Current trend increases are not sustainable for many more years.[66] One team cited this AI Impacts blog post.
- Major companies are cutting costs.[67]
- Increases in model size and complexity will be offset by a combination of falling compute costs, pre-training, and algorithmic improvements.[68]
- Large language models will probably see most attention in the near future, and these are bottlenecked by availability of data, which will lead to smaller models and lower compute requirements.[69]
- Growth may already be slowing down.[70]
- In the future, AI systems may be more modular, such that single experiments remain small even if total spending on compute increases drastically.[71]
- Recent spending on compute may have been status driven.[72]
- There seems to be general agreement that experiments of more than a few months are unwise, which might place an upper bound on how much compute can cost for a single experiment.[73]
Arguments for higher spending (closer to Cotra’s forecasts):
- As AI creates more value, more money will be spent on development.[74]
- A mega-project could be launched nationally or internationally which leads to this level of spending.[75]
- There is strong competition between actors with lots of resources and incentives to develop AI.[76]
- The impact of AI on AI development or the economy at large might raise the spending ceiling arbitrarily high.[77]
Algorithmic progress

Meta points
- Cotra says she’s spent very little time on this: the least time of any of the major components of her model.[78]
- The comparability is low:
- The XPT question only covers 2024 and 2030, which is a small part of the time from 2025 to 2100.
- The XPT question was specifically about efficiency improvements on ImageNet, and the relationship between that and the most relevant kinds of algorithmic progress for TAI is unclear.
- Cotra notes that we should expect efficiency improvements on narrow, well-defined tasks to be faster than those most relevant to TAI.[79]
- Cotra breaks her forecasts down for each of the biological anchors she considers; the XPT question generates only one overall number.
Cotra’s arguments
- Hernandez and Brown 2020 show halving every 13-16 months.[80]
- But these are on narrow well-defined tasks which researchers can directly optimize for, so forecasts should be adjusted up.[81]
- There might also be breakthrough progress at some point.[82]
XPT arguments
General comments:
- Extrapolating current growth rates leads to above median forecasts, and median and below median forecasts assume that current growth rates will slow.[83]
Arguments for slower algorithmic progress (closer to Cotra’s forecast):
- It’s possible no further work will be done in this area such that no further improvements are made.[84]
- Recently the focus has been on building very large models rather than increasing efficiency.[85]
- There may be hard limits on how much computation is required to train a strong image classifier.[86]
- Accuracy may be more important for models given what AI is used for, such that leading researchers target accuracy rather than efficiency gains.[87]
- If there is a shift towards explainable AI, this may require more compute and so slow efficiency growth rates.[88]
- Improvements may not be linear, especially as past improvements have been “lumpy” (i.e. improvements have come inconsistently) and the reference source is only rarely updated.[89]
- Very high growth rates are hard to sustain and tend to revert to the mean.[90]
Arguments for faster algorithmic progress:
- Pure extrapolation of improvements to date would result in fast progress.[91]
- Quantum computing might increase compute power and speed.[92]
- As AI models grow and become limited by available compute, efficiency will become increasingly important and necessary for improving accuracy.[93]
- “The Papers with Code ImageNet benchmark sorted by GFLOPs shows several more recent models with good top 5 accuracy and a much lower GFLOPs used than the current leader, EfficientNet.” If GFLOPS is a good indicator of training efficiency, then large efficiency increases may already have been made.[94]
- This technology is in its infancy so there may still be great improvements to be made.[95]
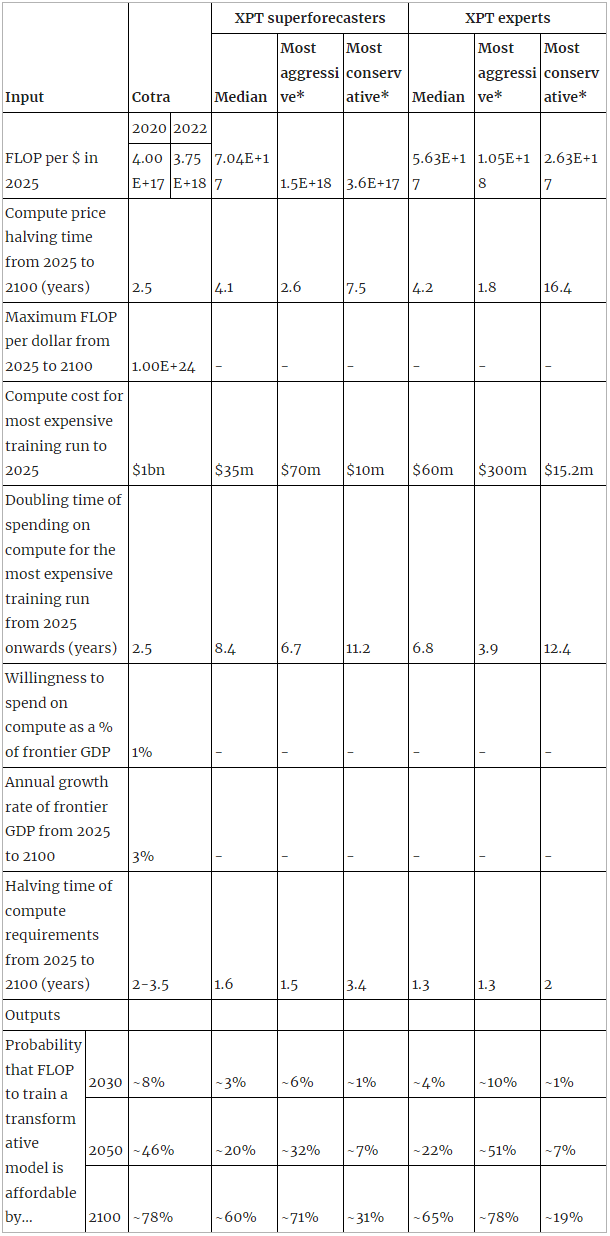
Appendix B: XPT expert forecasts related to when the compute required for TAI will be attainable
* The 'most aggressive' and 'most conservative' forecasts can be considered equivalent to 90% confidence intervals for the median estimate.[96]
Notes:
- Here, experts includes all experts in the XPT, including experts in fields other than AI which are relevant to existential risk.
- We chose to present results for all experts because the sample sizes were bigger than those of domain experts (14-21 compared to 5-6 domain experts). However, we expect readers will vary in how much weight they want to put on the forecasts of domain experts vs. general x-risk experts vs. non-domain experts on these questions. For details on each subgroup's forecasts on these questions, see Appendix 5 here, where you can navigate to each question to see each subgroup's forecast.
- The range in expert inputs tends to be larger than the range in superforecaster inputs.
- The most aggressive expert inputs are the only XPT inputs which produce probabilities higher than Cotra’s.
Appendix C: Applying an upwards adjustment factor to the XPT compute halving time forecasts
Cotra bases her forecast for compute requirement halving times on data about algorithmic progress on narrow applications, but then applies an upwards adjustment factor, to account for her belief that algorithmic progress will be slower for general applications, than it is for narrow applications.
We didn’t apply an adjustment factor to the XPT forecasts in our main analysis, as Cotra isn’t explicit about her methodology and we didn’t want to introduce more subjectivity.[97]
But it is possible to do a robustness check using an estimated upwards adjustment factor, as follows:
- The Hernandez and Brown paper Cotra cites shows halving times of 13–16 months.[98]
- Christiano’s summary of Grace’s paper has halving times of 13–36 months.[99]
- Let's guess that the bottom of Cotra’s unadjusted range is a halving time of 14 months.
- Her final estimates range from 24–36 months, which is an adjustment of 1.7 at the bottom end.
- This would mean the top of her unadjusted range is 21, which is consistent with Cotra putting more weight on Hernandez and Brown.[100]
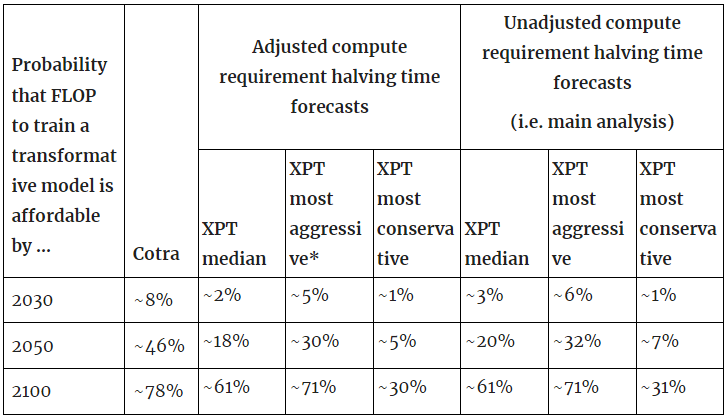
- If we apply an upward adjustment factor of 1.7 to all of the XPT figures, we end up with a median halving time of 2.72 years (90% CI: 2.55 years to 5.78 years).
- If we input this adjusted figure into the model, we get the following outputs:
Workings here. *The 'most aggressive' and 'most conservative' forecasts can be considered equivalent to 90% confidence intervals for the median estimate.[101]
So applying a rough upwards adjustment factor to the XPT forecasts on compute requirement halving times does not significantly shift model outputs.
- ^
For the relevant questions in the XPT, forecasters were asked to provide their 5th, 25th, 50th, 75th, and 95th percentile forecasts. In this analysis we use the term, ‘median’ to refer to analyses using the group’s median forecast for the 50th percentile of each question. We use the term ‘most aggressive’ to refer to analyses using the group medians for the 5th percentile estimate of the question relating to hardware costs, and the 95th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the lowest plausible hardware costs and the highest plausible willingness to spend and algorithmic efficiency to give the highest plausible likelihood of TAI.) We use the term ‘most conservative’ to refer to analyses using the group medians for the 95th percentile estimate of the question relating to hardware costs, and the 5th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the highest plausible hardware costs and the lowest plausible willingness to spend and algorithmic efficiency to give the lowest plausible likelihood of TAI.) The most aggressive and most conservative estimates can be considered equivalent to 90% confidence interval for the median estimate. See here for context on which XPT questions map to which biological anchors inputs.
- ^
Biological anchors refers to four hypotheses for the amount of computation that would be required to train a transformative model using 2020 architectures and algorithms: total computation done over evolution, total computation done over a human lifetime, the computational power of the human brain, and the amount of information in the human genome. All four anchors rely on an estimate of the amount of computation performed by the human brain, measured in floating point operations per second (FLOP/s). See here for an introduction to the framework.
- ^
More detail on the XPT forecasts on these questions can be found in pages 657 to 678 of the XPT report.
- ^
This spreadsheet uses as a template Cotra's publicly available spreadsheet, linked to from her report.
- ^
For the relevant questions in the XPT, forecasters were asked to provide their 5th, 25th, 50th, 75th, and 95th percentile forecasts. In this analysis we use the term, ‘median’ to refer to analyses using the group’s median forecast for the 50th percentile of each question. We use the term ‘most aggressive’ to refer to analyses using the group medians for the 5th percentile estimate of the question relating to hardware costs, and the 95th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the lowest plausible hardware costs and the highest plausible willingness to spend and algorithmic efficiency to give the highest plausible likelihood of TAI.) We use the term ‘most conservative’ to refer to analyses using the group medians for the 95th percentile estimate of the question relating to hardware costs, and the 5th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the highest plausible hardware costs and the lowest plausible willingness to spend and algorithmic efficiency to give the lowest plausible likelihood of TAI.) The most aggressive and most conservative estimates can be considered equivalent to 90% confidence interval for the median estimate. See here for context on which XPT questions map to which biological anchors inputs.
- ^
“I was using the rental price of a V100 (~$1/hour), but big companies get better deals on compute than that, by about another 2-3x.” here
- ^
“Communication costs currently account for roughly ~70%-80% of the cost of a GPU, and Paul’s understanding is that the recent trend in ML chips has been toward increasing arithmetic-to-communication ratios. Pushing further in that direction (e.g. switching to chips with more localized memory) could bring communication costs more in-line with arithmetic costs and reduce total costs by a factor of ~3.
Deep learning applications could also gain a factor of ~2 from switching to 8-bit precision computations (rather than 16-bit).” p. 30.
- ^
“Because they have not been the primary focus of my research, I consider these estimates unusually unstable, and expect that talking to a hardware expert could easily change my mind.” p. 26. “This forecast feels most solid and plausible out to ~2040 or so, beyond which it feels substantially more murky and likely incorrect.” p. 4. “Of all the quantitative estimates in this document, I consider these forecasts the most likely to be knowably mistaken. While most of the other quantitative estimates in this document have a lot more absolute uncertainty associated with them, there is a lot more low-hanging fruit left in improving short- and medium-term hardware price forecasts. For example, my understanding is that semiconductor industry professionals regularly write highly detailed technical reports forecasting a number of hardware cost-efficiency metrics, and I have neither read any of this literature nor interviewed any hardware experts on this question.” p. 30
- ^
“I would guess that the most compute-intensive training run for an unreleased and/or proprietary model (e.g., a language model powering Google Assistant or Google Translate) is already ~2-8x larger than AlphaStar’s ~1.3e23, costing ~$2-8M.” p. 36 “[N]ote that there will probably be a non-trivial delay between the first time a training run of size X is completed and the first time such a training run is published, and my forecasts are about the former”. p. 37
- ^
In Cotra’s model, this number is a point estimate for ‘Doubling time of spending on compute for the most expensive training run at start of period (2025)’. When she reviewed this post, Cotra confirmed that it made sense to treat this as the doubling time from 2025 onwards.
- ^
“I have done very little research into algorithmic progress trends. Of the four main components of my model (2020 compute requirements, algorithmic progress, compute price trends, and spending on computation) I have spent the least time thinking about algorithmic progress.” p. 5
- ^
“Additionally, it seems plausible to me that both sets of results would overestimate the pace of algorithmic progress on a transformative task, because they are both focusing on relatively narrow problems with simple, well-defined benchmarks that large groups of researchers could directly optimize.[] Because no one has trained a transformative model yet, to the extent that the computation required to train one is falling over time, it would have to happen via proxies rather than researchers directly optimizing that metric (e.g. perhaps architectural innovations that improve training efficiency for image classifiers or language models would translate to a transformative model). Additionally, it may be that halving the amount of computation required to train a transformative model would require making progress on multiple partially-independent sub-problems (e.g. vision and language and motor control).” p. 6
- ^
“I have attempted to take the Hernandez and Brown 2020 halving times (and Paul’s summary of the Grace 2013 halving times) as anchoring points and shade them upward to account for the considerations raised above. There is massive room for judgment in whether and how much to shade upward; I expect many readers will want to change my assumptions here, and some will believe it is more reasonable to shade downward." p. 6
- ^
“I chose to break down the algorithmic progress forecast by hypothesis rather than use a single value describing how the 2020 compute requirements distribution shifts to the left in future years. This is because hypotheses which predict that the amount of computation required to train a transformative model is already very low (such as the Lifetime Anchor hypothesis) seems like they should also predict that further algorithmic progress would be difficult and there is not as much room to reduce compute requirements even further.” p. 7
- ^
For the relevant questions in the XPT, forecasters were asked to provide their 5th, 25th, 50th, 75th, and 95th percentile forecasts. In this analysis we use the term, ‘median’ to refer to analyses using the group’s median forecast for the 50th percentile of each question. We use the term ‘most aggressive’ to refer to analyses using the group medians for the 5th percentile estimate of the question relating to hardware costs, and the 95th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the lowest plausible hardware costs and the highest plausible willingness to spend and algorithmic efficiency to give the highest plausible likelihood of TAI.) We use the term ‘most conservative’ to refer to analyses using the group medians for the 95th percentile estimate of the question relating to hardware costs, and the 5th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the highest plausible hardware costs and the lowest plausible willingness to spend and algorithmic efficiency to give the lowest plausible likelihood of TAI.) The most aggressive and most conservative estimates can be considered equivalent to 90% confidence interval for the median estimate. See here for context on which XPT questions map to which biological anchors inputs.
- ^
For the relevant questions in the XPT, forecasters were asked to provide their 5th, 25th, 50th, 75th, and 95th percentile forecasts. In this analysis we use the term, ‘median’ to refer to analyses using the group’s median forecast for the 50th percentile of each question. We use the term ‘most aggressive’ to refer to analyses using the group medians for the 5th percentile estimate of the question relating to hardware costs, and the 95th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the lowest plausible hardware costs and the highest plausible willingness to spend and algorithmic efficiency to give the highest plausible likelihood of TAI.) We use the term ‘most conservative’ to refer to analyses using the group medians for the 95th percentile estimate of the question relating to hardware costs, and the 5th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the highest plausible hardware costs and the lowest plausible willingness to spend and algorithmic efficiency to give the lowest plausible likelihood of TAI.) The most aggressive and most conservative estimates can be considered equivalent to 90% confidence interval for the median estimate. See here for context on which XPT questions map to which biological anchors inputs.
- ^
For the relevant questions in the XPT, forecasters were asked to provide their 5th, 25th, 50th, 75th, and 95th percentile forecasts. In this analysis we use the term, ‘median’ to refer to analyses using the group’s median forecast for the 50th percentile of each question. We use the term ‘most aggressive’ to refer to analyses using the group medians for the 5th percentile estimate of the question relating to hardware costs, and the 95th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the lowest plausible hardware costs and the highest plausible willingness to spend and algorithmic efficiency to give the highest plausible likelihood of TAI.) We use the term ‘most conservative’ to refer to analyses using the group medians for the 95th percentile estimate of the question relating to hardware costs, and the 5th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the highest plausible hardware costs and the lowest plausible willingness to spend and algorithmic efficiency to give the lowest plausible likelihood of TAI.) The most aggressive and most conservative estimates can be considered equivalent to 90% confidence interval for the median estimate. See here for context on which XPT questions map to which biological anchors inputs.
- ^
Not all superforecasters completed the end-of-tournament survey. However, using the forecasts from only the subset of superforecasters who did complete the survey does not change the results. Using this subset’s forecasts as inputs to Cotra’s model outputs the same probability of TAI by 2070 and 2100 (35% and 60%, respectively).
- ^
The probability of >15% growth by 2100 was asked about in both the main component of the XPT and the postmortem survey. The results here are from the postmortem survey. The superforecaster median estimate for this question in the main component of the XPT was 2.75% (for all superforecaster participants and the subset that completed the postmortem survey).
- ^
The probability of >15% growth by 2100 was asked about in both the main component of the XPT and the postmortem survey. The results here are from the postmortem survey. The experts median estimate for this question in the main component of the XPT was 19% for all expert participants and 16.9% for the subset that completed the postmortem survey.
- ^
“Because they have not been the primary focus of my research, I consider these estimates unusually unstable, and expect that talking to a hardware expert could easily change my mind.” p. 26
“Of all the quantitative estimates in this document, I consider these forecasts the most likely to be knowably mistaken. While most of the other quantitative estimates in this document have a lot more absolute uncertainty associated with them, there is a lot more low-hanging fruit left in improving short- and medium-term hardware price forecasts. For example, my understanding is that semiconductor industry professionals regularly write highly detailed technical reports forecasting a number of hardware cost-efficiency metrics, and I have neither read any of this literature nor interviewed any hardware experts on this question.” p. 30
- ^
“This forecast feels most solid and plausible out to ~2040 or so, beyond which it feels substantially more murky and likely incorrect.” p. 4
- ^
“Other things being equal, the recent slower trend is probably more informative than older data, and is fairly likely to reflect diminishing returns in the silicon chip manufacturing industry.” p. 2
- ^
“However, the older trend of faster growth has held for a much longer period of time and through more than one change in “hardware paradigms.” I don’t think it makes sense to extrapolate the relatively slower growth from 2008 to 2018 over a period of time several times longer than that” p. 2
- ^
“Additionally, a technical advisor informs me that the NVIDIA A100 GPU (released in 2020) is substantially more powerful than the V100 that it replaced, which could be more consistent with a ~2-2.5 year doubling time than a ~3.5 year doubling time.” p. 3
- ^
“On top of that, it seems that we can expect a one-time ~6x improvement in the next ~5-10 years from specializing chips for deep learning applications.” p. 29
- ^
“The above reasoning was focused on listing all the foreseeable improvements on the horizon for silicon-based chips, but I believe there is substantial possibility for both a) “unknown unknown” sources of improvements to silicon chips and b) transition to an exotic form of hardware. For example, at least some companies are actively working on optical computing in particular -- I would bet that effective FLOP per dollar will eventually move past the plateau, potentially reaching values multiple orders of magnitude higher. Possibilities that seem somewhat more distant include three-dimensional circuits, reversible computing, and quantum computing.” p. 32
- ^
“I was using the V100 as my reference machine; this was in fact the most advanced publicly available chip on the market as of 2020, but it was released in 2018 and on its way out, so it was better as an estimate for 2018 or 2019 compute than 2020 compute. The more advanced A100 was 2-3x more powerful per dollar and released in late 2020 almost immediately after my report was published.” here
- ^
“I was using the rental price of a V100 (~$1/hour), but big companies get better deals on compute than that, by about another 2-3x.” here
- ^
“I was assuming ~⅓ utilization of FLOP/s, which was in line with what people were achieving then, but utilization seems to have improved, maybe to ~50% or so.” here
- ^
Question 47: 337, “Given that five out of eight team forecasters used faulty data, we should conclude that the team forecast is also faulty for all dates and percentiles”, “many forecasters only used the outdated Wikipedia article referenced in the question description. That article was specifically the price/performance data for the more recent models of GPUs. (The article was updated recently, though it still doesn't cover the dedicated AI infrastructure hardware sold by Nvidia like their new H100 line.) This led to most forecasters using obsolete data for their baselines and predicting future GFLOPS prices that are worse than the already achieved results. The difference in the source data quality fully explains the widely divergent forecasts for 2024, which should normally be simple - and numerically similar - extrapolations of the status quo.” 344, “This question has a shallow pool of forecasters with limited arguments given for the estimates and erroneous inputs.”
- ^
Question 47: 336, “‘The biggest price is not hardware itself but electricity, data-center usage and human AI-scientists salaries.’ The COVID pandemic inflated costs for electricity and hardware but efficiencies in development, and energy costs, will drive this down again.”
- ^
Question 47: 336, “recent performance/$ trend is slower than long-run (there could be a return to the longer run trends of OOM every 8 or 4 years.)”
- ^
Question 47: 336, “uncertainty regarding future technological improvements”; “potential for discovering new modes of computing leading to discontinuous improvements”. 340, “The strongest argument for lower extreme forecasts is that some novel technology precipitates discontinuous progress in the trend of the cost of computation for training AI models. Optical neural networks are a promising technology with the potential to improve AI model training in this way.” See also 341, “Potential prospects for a revolutionary technology (e.g. optical computing, quantum computing, reversible and three-dimensional circuits) as per Cotra's report. This could break the foreseen plateau and lead to continued doubling every 3-4 years past 2040 and go back to a 1-2 year doubling.” See also 343, “Application of advanced AI or AGI to the problem could transformatively decrease prices in an unpredictable way.” See also 344, “Quantum computing seems to be accelerating progress - it's going to get much cheaper much quicker imho”.
- ^
Question 47: 336, “trend of order of magnitude improvement in price-performance every 10 years”.
- ^
Question 47: 336, “advancement may have been slowing since 2010 and rate of decline in prices could continue to slow”. 341, “Faltering of Moore's Law. See the IEEE's 2021 IRDS report, More Moore, Table MM for challenges.” See also 339, “Unstable world and a decline in Moore's law limit the factors that drove down costs in previous years.
- ^
Question 47: 336, “war, especially over Taiwan, could raise prices and/or slow advancement”. See also 339, “Unstable world and a decline in Moore's law limit the factors that drove down costs in previous years. It could take decades for the US to reshore semiconductor manufacturing to the US (and to China). This means Taiwan tensions could throw wrenches into cost dropping.”
- ^
Question 47: 336, “global economic decline could lead to slower advancement”.
- ^
Question 47: 341, “If early technological progress can be seen as a low-hanging fruit, further progress inherently becomes harder. Many experts (as quoted in Cotra, 2020) expect much less improvement over the next century than we have seen in the past century.”
- ^
Question 47: 336, “potential for hard/impossible to surpass fundamental physical limits”. 340, “The strongest argument for higher extreme forecasts is that Moore’s law slows due to physical limitations in manufacturing, GPU cost per compute slows because of limits to parallelization, and there is are no new technologies to pick up the flattening S-curve and continue the trend.” 341, “Known limitations of specific technologies. The existence of fundamental physical limits.”
- ^
Question 47: 341, “ Lack of high demand (or diminished urgency) for ever more efficient chips.”
- ^
Question 47: 336, “uncertainty regarding future technological development - potential for new tech to lead to higher prices.”
- ^
Question 47: 339, “Processors in the future may not necessarily have greater FLOP rates, which hit limits of Moore's law, but superior memory architecture (e.g. Apple's M1/m2 chips did this by being better suited to scientific computing workloads). Apple's success: access a distributed RAM with almost no latency: Apple M1 destroys Intel and AMD in newly-released benchmarks | TechRadar. FLOP rate may become static at one point, meaning memory optimisations will rule. There may be another metric, such as effective FLOP rate, that might emerge instead.”
- ^
Question 47: 339, “Building processors requires rare earth minerals that will not be as abundant and have other uses (solar cells, Li-ion batteries)”.
- ^
Question 47: 343, “Realization of catastrophic or existential risks could halt or reverse price decreases (or otherwise make them irrelevant).” See also 337, “The effect of catastrophic risk could be important for 2050 (as per questions 1 to 12): a few of the scenarios could imply a temporal reversion to previous and more expensive forms of computing, such as mechanical computing or paper and pen. This could increase the price of one GFLOPS to values not seen in decades. However, since the forecasters' predictions of such catastrophes are relatively low (around 5%), only the 95th percentile forecasts should be affected by this consideration.”
- ^
“This would require doubling spending on the most expensive training run about once every 6 months, which is consistent with what I understand of the recent pace of spending scaleup and the existing resources of AI companies such as Google.” pp. 4-5
- ^
“This would require doubling spending on the most expensive training run about once every 6 months, which is consistent with what I understand of the recent pace of spending scaleup and the existing resources of AI companies such as Google.” pp. 4-5
- ^
“However, it does appear that there is enough short-term excitement about deep learning that several companies will have the budget to scale up to training runs costing a few hundred million dollars while only having to demonstrate promising research results and/or very modest value-added for now.” p. 36
- ^
“I would guess that the most compute-intensive training run for an unreleased and/or proprietary model (e.g., a language model powering Google Assistant or Google Translate) is already ~2-8x larger than AlphaStar’s ~1.3e23, costing ~$2-8M.” p. 36 “[N]ote that there will probably be a non-trivial delay between the first time a training run of size X is completed and the first time such a training run is published, and my forecasts are about the former”. p. 37
- ^
- ^
“The possibility of training a transformative model would provide an enormous incentive. Given this incentive, how much additional money would an AI company be willing and able to spend on a training run over the next couple of decades (if they had already ramped up to ~$1B training runs)?” p. 37
- ^
“I would guess that an AI company could spend hundreds of billions on a project to train a transformative model by ~2040.” p. 38
- ^
“The largest AI companies already have enough cash on hand that they could relatively quickly deploy tens of billions for a lucrative enough project. As of Q4 2019, both Microsoft and Alphabet (the parent company of Google and DeepMind) had more than $100B in cash on hand, and Facebook and Amazon each have more than $50B;[] this could theoretically be spent given buy-in from only a small number of people in leadership positions at each of those companies. Those four companies have already invested heavily in AI research and relevant infrastructure such as data centers; other large tech companies have not made a large investment into AI but also have large amounts of cash on hand (e.g. Apple has over $100B)[] and could imaginably make that transition over ~5-10 years if AI continues to look like a lucrative field.” p. 38
- ^
“Large tech companies’ market capitalization tends to be ~10x as large as their cash on hand (close to $1 trillion).” p. 38
- ^
“It seems unlikely that a company could borrow money much past its market capitalization -- particularly for a single risky venture -- but seems possible that it could borrow something in the range of ~10%-50% of market cap for a project like training a potentially transformative model; this could make $100-500B in additional funds available.” p. 38
- ^
“I would expect such companies to grow significantly as a share of the economy over the next 20 years in the worlds where AI progress continues, and increase in their borrowing power and ability to attract investment.” p. 38
- ^
See here, particularly, “My overall intuition based on the above information is that all-in costs for a large project to train an ML model -- including the cost of salaries, data and environments, and all the compute used to experiment at smaller scales -- could get to within ~2-10x the cost of the compute for the single final training run in the medium term.” p. 42
- ^
“This suggests that by 2040, an AI project would be willing and able to spend about $100B on computation to train a transformative model.” p. 42
- ^
“If willingness to spend in 2040 is $100B and willingness to spend in 2025 is $1B, this suggests a doubling time of about two years in that period.” p. 42
- ^
“Eventually, I expect that growth in spending on computation will keep pace with growth in the GDP of the largest national economy.” p. 44
- ^
“I will assume that the GDP of the largest national economy will grow at ~3% annually, which is similar to the average growth rate of the United States (the current largest national economy) over the last few decades.” p. 44
- ^
“Anchoring to the costs of major technological megaprojects such as the Manhattan Project (which cost about ~1.7% of a year of GDP over five years) and the Apollo Project (which cost about ~3.6% of a year of GDP over its four peak years), I assumed that the maximum level of spending on computation for a single training run that could be reached is ~1% of the GDP of the largest country.” p. 5
- ^
Question 46: 338, “The main split between predictions is between lower estimates (including the team median) that anchor on present project costs with a modest multiplier, and higher estimates that follow Cotra in predicting pretty fast scaling will continue up to anchors set by demonstrated value-added, tech company budgets, and megaproject percentages of GDP."
- ^
Question 46: 340, “Presumably much of these disagreement[s] stem from different ways of looking at recent AI progress. Some see the growth of computing power as range bound by current manufacturing processes and others expect dramatic changes in the very basis of how processors function leading to continued price decreases.”
- ^
Question 46: 337, “training cost seems to have been stuck in the $10M figure for the last few years.”; “we have not seen such a large increase in the estimated training cost of the largest AI model during the last few years: AlphaZero and PALM are on the same ballpark.” 341, “For 2024, the costs seem to have flattened out and will be similar to now. To be on trend in 2021, the largest experiment would need to be at $0.2-1.5bn. GPT-3 was only $4.6mn”
- ^
Question 46: 341, “The AI impacts note also states that the trend would only be sustainable for a few more years. 5-6 years from 2018, i.e. 2023-24, we would be at $200bn, where we are already past the total budgets for even the biggest companies.”
- ^
Question 46: 336, “The days of 'easy money' may be over. There's some serious belt-tightening going on in the industry (Meta, Google) that could have a negative impact on money spent.”
- ^
Question 46: 337, “It also puts more weight on the reduced cost of compute and maybe even in the improved efficiency of minimization algorithms, see question 48 for instance.” 336, “After 2030, we expect increased size and complexity to be offset by falling cost of compute, better pre-trained models and better algorithms. This will lead to a plateau and possible even a reduction in costs.”; “In the near term, falling cost of compute, pre-trained models, and better algorithms will reduce the expense of training a large language model (which is the architecture which will likely see the most attention and investment in the short term).” See also 343, “$/FLOPs is likely to be driven down by new technologies and better chips. Better algorithm design may also improve project performance without requiring as much spend on raw compute.” See also 339, “The low end scenarios could happen if we were to discover more efficient training methods (eg take a trained model from today and somehow augment it incrementally each year rather than a single batch retrain or perhaps some new research paradigm which makes training much cheaper).”
- ^
Question 46: 336, “Additionally, large language models are currently bottlenecked by available data. Recent results from DeepMind suggest that models over ~100 billion parameters would not have enough data to optimally train. This will lead to smaller models and less compute used in the near term. For example, GPT-4 will likely not be significantly larger than Chinchilla. https://arxiv.org/abs/2203.15556”. 341, “The data availability is limited.” See also 340, “The evidence from Chinchilla says that researchers overestimated the value of adding parameters (see https://www.lesswrong.com/posts/6Fpvch8RR29qLEWNH/chinchilla-s-wild-implications). That is probably discouraging researchers from adding more parameters for a while. Combined with the difficulty of getting bigger text datasets, that might mean text-oriented systems are hitting a wall. (I'm unsure why this lasts long - I think other datasets such as video are able to expand more).”
- ^
Question 46: 340, “The growth might be slowing down now.”; “Or maybe companies were foolishly spending too little a few years ago, but are now reaching diminishing returns, with the result that declining hardware costs mostly offset the desire for bigger models.”
- ^
Question 46: 340, “Later on, growth might slow a lot due to a shift to modular systems. I.e. total spending on AI training might increase a good deal. Each single experiment could stay small, producing parts that are coordinated to produce increasingly powerful results.” See also 339, “2050 At this point I'm not sure it will be coherent to talk about a single AI experiment, models will probably be long lived things which are improved incrementally rather than in a single massive go. But they'll also be responsible for a large fraction of the global GDP so large expenditures will make sense, either at the state level or corporation.”
- ^
Question 46: 340, :Some forecasters don't expect much profit from increased spending on AI training. Maybe the recent spending spree was just researchers showing mpanies are about to come to their senses and stop spending so much money.”
- ^
Question 46: 340; “There may some limits resulting from training time. There seems to be agreement that it's unwise to attempt experiments that take more than a few months. Maybe that translates into a limit on overall spending on a single experiment, due to limits on how much can be done in parallel, or datacenter size, or supercomputer size?”
- ^
Question 46: 343, “Monetization of AGI is in its early stages. As AI creates new value, it's likely that additional money will be spent on increasingly more complex projects.” Note that this argument refers to forecasts higher than the team median forecasts, and the team median for 2024 was $25m.
- ^
Question 46: 337, “This will make very much sense in the event that a great public project or international collaboration will be assembled for researching a particular aspect of AI (a bit in the line of project Manhattan for the atomic bomb, the LHC for collider physics or ITER for fusion). The probability of such a collaboration eventually appearing is not small. Other scenario is great power competition between China and the US, with a focus on AI capabilities.”
- ^
Question 46: 336, “There is strong competition between players with deep pockets and strong incentives to develop and commercialize 'AI-solutions'.”
- ^
Question 46: 344, “Automatic experiments run by AI are beyond valuation”. 337, “One forecast suggest astronomical numbers for the largest project in the future, where the basis of this particular forecast is the possibility of an AI-driven economic explosion (allowing for the allocation of arbitrarily large resources in AI).”
- ^
“I have done very little research into algorithmic progress trends. Of the four main components of my model (2020 compute requirements, algorithmic progress, compute price trends, and spending on computation) I have spent the least time thinking about algorithmic progress.” p. 5
- ^
“Additionally, it seems plausible to me that both sets of results would overestimate the pace of algorithmic progress on a transformative task, because they are both focusing on relatively narrow problems with simple, well-defined benchmarks that large groups of researchers could directly optimize.# Because no one has trained a transformative model yet, to the extent that the computation required to train one is falling over time, it would have to happen via proxies rather than researchers directly optimizing that metric (e.g. perhaps architectural innovations that improve training efficiency for image classifiers or language models would translate to a transformative model). Additionally, it may be that halving the amount of computation required to train a transformative model would require making progress on multiple partially-independent sub-problems (e.g. vision and language and motor control).
I have attempted to take the Hernandez and Brown 2020 halving times (and Paul’s summary of the Grace 2013 halving times) as anchoring points and shade them upward to account for the considerations raised above.” p. 6
- ^
“For incremental progress, the main source I used was Hernandez and Brown 2020, “Measuring the Algorithmic Efficiency of Neural Networks.” The authors reimplemented open source state-of-the-art (SOTA) ImageNet models between 2012 and 2019 (six models in total). They trained each model up to the point that it achieved the same performance as AlexNet achieved in 2012, and recorded the total FLOP that required. They found that the SOTA model in 2019, EfficientNet B0, required ~44 times fewer training FLOP to achieve AlexNet performance than AlexNet did; the six data points fit a power law curve with the amount of computation required to match AlexNet halving every ~16 months over the seven years in the dataset.# They also show that linear programming displayed a similar trend over a longer period of time: when hardware is held fixed, the time in seconds taken to solve a standard basket of mixed integer programs by SOTA commercial software packages halved every ~13 months over the 21 years from 1996 to 2017.” p. 6
- ^
“Additionally, it seems plausible to me that both sets of results would overestimate the pace of algorithmic progress on a transformative task, because they are both focusing on relatively narrow problems with simple, well-defined benchmarks that large groups of researchers could directly optimize.# Because no one has trained a transformative model yet, to the extent that the computation required to train one is falling over time, it would have to happen via proxies rather than researchers directly optimizing that metric (e.g. perhaps architectural innovations that improve training efficiency for image classifiers or language models would translate to a transformative model). Additionally, it may be that halving the amount of computation required to train a transformative model would require making progress on multiple partially-independent sub-problems (e.g. vision and language and motor control).
I have attempted to take the Hernandez and Brown 2020 halving times (and Paul’s summary of the Grace 2013 halving times) as anchoring points and shade them upward to account for the considerations raised above.” p. 6
- ^
“I consider two types of algorithmic progress: relatively incremental and steady progress from iteratively improving architectures and learning algorithms, and the chance of “breakthrough” progress which brings the technical difficulty of training a transformative model down from “astronomically large” / “impossible” to “broadly feasible.”” p. 5
- ^
Question 48: See 339, “"On the other hand, an economist would say that one day, the improvement will stagnate as models become ""good enough"" for efficient use, and it's not worth it to become even better at image classification. Arguably, this day seems not too far off. So growth may either level off or continue on its exponential path. Base rate thinking does not help much with this question… It eluded the team to find reasonable and plausible answers... stagnation may be just as plausible as further exponential growth. No one seems to know.”
- ^
Question 48: 340, “Low range forecasts assume that nobody does any further work on this area, hence no improvement in efficiency.” 341, “The Github page for people to submit entries to the leaderboard created by OpenAI hasn't received any submissions (based on pull requests), which could indicate a lack of interest in targeting efficiency. https://github.com/openai/ai-and-efficiency”.
- ^
Question 48: 340, “In addition, it seems pretty unclear, whether this metric would keep improving incidentally with further progress in ML, especially given the recent focus on extremely large-scale models rather than making things more efficient.”
- ^
Question 48: 340, “there seem to bem some hard limits on how much computation would be needed to learn a strong image classifier”.
- ^
Question 48: 341, “The use cases for AI may demand accuracy instead of efficiency, leading researchers to target continued accuracy gains instead of focusing on increased efficiency.”
- ^
Question 48: 341, “A shift toward explainable AI (which could require more computing power to enable the AI to provide explanations) could depress growth in performance.”
- ^
Question 48: 336, “Lower end forecasts generally focused on the fact that improvements may not happen in a linear fashion and may not be able to keep pace with past trends, especially given the "lumpiness" of algorithmic improvement and infrequent updates to the source data.” 338, “The lowest forecasts come from a member that attempted to account for long periods with no improvement. The reference table is rarely updated and it only includes a few data points. So progress does look sporadic.”
- ^
Question 48: 337, “The most significant disagreements involved whether very rapid improvement observed in historical numbers would continue for the next eight years. A rate of 44X is often very hard to sustain and such levels usually revert to the mean.”
- ^
Question 48: 340, “The higher range forecasts simply stem from the extrapolation detailed above.
Pure extrapolation of the 44x in 7 years would yield a factor 8.7 for the 4 years from 2020 to 2024 and a factor of 222 for the years until 2030. => 382 and 9768.” 336, “Base rate has been roughly a doubling in efficiency every 16 months, with a status quo of 44 as of May 2019, when the last update was published. Most team members seem to have extrapolated that pace out in order to generate estimates for the end of 2024 and 2030, with general assumption being progress will continue at roughly the same pace as it has previously.”
- ^
Question 48: 336, “The high end seems to assume that progress will continue and possibly increase if things like quantum computing allow for a higher than anticipated increase in computing power and speed.”
- ^
Question 48: 341, “AI efficiency will be increasingly important and necessary to achieve greater accuracy as AI models grow and become limited by available compute.”
- ^
Question 48: 341.
- ^
Question 48: 337, “The most significant disagreements involved whether very rapid improvement observed in historical numbers would continue for the next eight years. A rate of 44X is often very hard to sustain and such levels usually revert to the mean. However, it seems relatively early days for this tech, so this is plausible.”
- ^
For the relevant questions in the XPT, forecasters were asked to provide their 5th, 25th, 50th, 75th, and 95th percentile forecasts. In this analysis we use the term, ‘median’ to refer to analyses using the group’s median forecast for the 50th percentile of each question. We use the term ‘most aggressive’ to refer to analyses using the group medians for the 5th percentile estimate of the question relating to hardware costs, and the 95th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the lowest plausible hardware costs and the highest plausible willingness to spend and algorithmic efficiency to give the highest plausible likelihood of TAI.) We use the term ‘most conservative’ to refer to analyses using the group medians for the 95th percentile estimate of the question relating to hardware costs, and the 5th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the highest plausible hardware costs and the lowest plausible willingness to spend and algorithmic efficiency to give the lowest plausible likelihood of TAI.) The most aggressive and most conservative estimates can be considered equivalent to 90% confidence interval for the median estimate. See here for context on which XPT questions map to which biological anchors inputs.
- ^
“I have attempted to take the Hernandez and Brown 2020 halving times (and Paul’s summary of the Grace 2013 halving times) as anchoring points and shade them upward to account for the considerations raised above. There is massive room for judgment in whether and how much to shade upward; I expect many readers will want to change my assumptions here, and some will believe it is more reasonable to shade downward." p. 6
- ^
“They found that the SOTA model in 2019, EfficientNet B0, required ~44 times fewer training FLOP to achieve AlexNet performance than AlexNet did; the six data points fit a power law curve with the amount of computation required to match AlexNet halving every ~16 months over the seven years in the dataset. They also show that linear programming displayed a similar trend over a longer period of time: when hardware is held fixed, the time in seconds taken to solve a standard basket of mixed integer programs by SOTA commercial software packages halved every ~13 months over the 21 years from 1996 to 2017.” p. 6
- ^
“Paul is familiar with the results, and he believes that algorithmic progress across the six domains studied in Grace 2013 is consistent with a similar but slightly slower rate of progress, ranging from 13 to 36 months to halve the computation required to reach a fixed level of performance.” p. 6
- ^
“the main source I used was Hernandez and Brown 2020…Grace 2013 (“Algorithmic Progress in Six Domains”) is the only other paper attempting to systematically quantify algorithmic progress that I am currently aware of… I have chosen not to examine it in detail because a) it was written largely before the deep learning boom and mostly does not focus on ML tasks, and b) it is less straightforward to translate Grace’s results into the format that I am most interested in (“How has the amount of computation required to solve a fixed task decreased over time?”)”. p. 6
- ^
For the relevant questions in the XPT, forecasters were asked to provide their 5th, 25th, 50th, 75th, and 95th percentile forecasts. In this analysis we use the term, ‘median’ to refer to analyses using the group’s median forecast for the 50th percentile of each question. We use the term ‘most aggressive’ to refer to analyses using the group medians for the 5th percentile estimate of the question relating to hardware costs, and the 95th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the lowest plausible hardware costs and the highest plausible willingness to spend and algorithmic efficiency to give the highest plausible likelihood of TAI.) We use the term ‘most conservative’ to refer to analyses using the group medians for the 95th percentile estimate of the question relating to hardware costs, and the 5th percentile estimate for the questions relating to willingness to spend and algorithmic progress. (I.e., this uses the highest plausible hardware costs and the lowest plausible willingness to spend and algorithmic efficiency to give the lowest plausible likelihood of TAI.) The most aggressive and most conservative estimates can be considered equivalent to 90% confidence interval for the median estimate. See here for context on which XPT questions map to which biological anchors inputs.
My personal take on these forecasts here.
Thanks for that information, I will use that for my degree http://essaypapers.reviews/