All of Tristan Cook's Comments + Replies
Regarding Jackson's comment, I agree that 'dumping' money last-minute is a bit silly. Spending at a higher rate (and saving less) doesn't seem so crazy - which is what it seems you were considering.
Why do you believe that capital won't be useful?
My guess the modal outcome from AGI (and eventual ASI) is human disempowerment/extinction. Less confidently, I also suspect that most worlds where things go 'well' look weird and not not much like business-as-normal. For example, if we eventually have a sovereign ASI implement some form of coherent extr...
Thanks for the list! Napkin AI is particularly cool.
Your LibGen link isn't working for me. Its Wikipedia page usually has live (& safe) links in the infobox. Same for Sci-Hub.
One recent service I've found is Readwise. It's similar to Pocket/Instapaper in adding web-pages to read later, but you can also upload your own EPUB and PDFs.
I thought about this a few years ago and have a post here.
I agree with Caleb's comment on the necessity to consider what a post-superintelligence world would look like, and whether capital could be usefully deployed. This post might be of interest.
My own guess is that it's most likely that capital won't be useful and that more aggressive donating makes sense.
The consequence of this for the "spend now vs spend later" debate is crudely modeled in The optimal timing of spending on AGI safety work, if one expects automated science to directly & predictably precede AGI. (Our model does not model labor, and instead considers [the AI risk community's] stocks of money, research and influence)
We suppose that after a 'fire alarm' funders can spend down their remaining capital, and that the returns to spending on safety research during this period can be higher than spending pre-fire alarm (although...
Thanks again Phil for taking the read this through and for the in-depth feedback.
I hope to take some time to create a follow-up post, working in your suggestions and corrections as external updates (e.g. to the parameters of lower total AI risk funding, shorter Metaculus timelines).
I don't know if the “only one big actor” simplification holds closely enough in the AI safety case for the "optimization" approach to be a better guide, but it may well be.
This is a fair point.
The initial motivator for the project was for AI s-risk funding, of which there'...
Strong agreement that a global moratorium would be great.
I'm unsure if aiming for a global moratorium is the best thing to aim for rather than a slowing of the race-like behaviour -- maybe a relevant similar case is whether to aim directly for the abolition of factory farms or just incremental improvements in welfare standards.
This post from last year - What an actually pessimistic containment strategy looks like - has some good discussion on the topic of slowing down AGI research.
I agree. This lines with models of optimal spending I worked on which allowed for a post-fire alarm "crunch time" in which one can spend a significant fraction of remaining capital.
I think "different timelines don't change the EV of different options very much" plus "personal fit considerations can change the EV of a PhD by a ton" does end up resulting in an argument for the PhD decision not depending much on timelines. I think that you're mostly disagreeing with the first claim, but I'm not entirely sure.
Yep, that's right that I'm disagreeing with the first claim. I think one could argue the main claim either by:
- Regardless of your timelines, you (person considering doing a PhD) shouldn't take it too much into consideration
- I (a
I think you raise some good considerations but want to push back a little.
I agree with your arguments that
- we shouldn't use point estimates (of the median AGI date)
- we shouldn't fully defer to (say) Metaculus estimates.
- personal fit is important
But I don't think you've argued that "Whether you should do a PhD doesn't depend much on timelines."
Ideally as a community we can have a guess at the optimal number of people in the community that should do PhDs (factoring in their personal fit etc) vs other paths.
I don't think this has been done, but since most ...
Thanks for the post!
In this post, I'll argue that when counterfactual reasoning is applied the way Effective Altruist decisions and funding occurs in practice, there is a preventable anti-cooperative bias that is being created, and that this is making us as a movement less impactful than we could be.
One case I've previously thought about is that some naive forms of patient philanthropy could be like this - trying to take credit for spending on the "best" interventions.
I've polished a old draft and posted it as short-form with some discuss...
Some takes on patient philanthropy
Epistemic status: I’ve done work suggesting that AI risk funders be spending at a higher rate, and I'm confident in this result. The other takes are less informed!
I discuss
- Whether I think we should be spending less now
- Useful definitions of patient philanthropy
- Being specific about empirical beliefs that push for more patience
- When patient philanthropy is counterfactual
- Opportunities for donation trading between patient and non-patient donors
Whether I think we should be spending less now
In principle I think th...
DM = digital mind
Archived version of the post (with no comments at the time of the archive). The post is also available on the Sentience Institute blog
I think you are mistaken on how Gift Aid / payroll giving works in the UK (your footnote 4), it only has an effect once you are a higher rate or additional rate taxpayer. I wrote some examples up here. As a basic rate taxpayer you don't get any benefit - only the charity does.
Thanks for the link to your post! I'm a bit confused about where I'm mistaken. I wanted to claim that:
(ignoring payroll giving or claiming money back from HMRC, as you discuss in yoir post) taking a salary cut (while at the 40% marginal tax rate) is more effici...
How I think we should do anthropics
I think we should reason in terms of decisions and not use anthropic updates or probabilities at all. This is what is argued for in Armstrong's Anthropic Decision Theory, which itself is a form of updateless decision theory.
In my mind, this resolves a lot of confusion around anthropic problems when they're reframed as decision problems.
If I had to pick a traditional anthropic theory...
I'd pick, in this order,
- Minimal reference class SSA
- SIA
- Non-minimal reference class SSA
I choose this ordering because both minima...
Anthropics: my understanding/explanation and takes
In this first comment, I stick with the explanations. In sub-comments, I'll give my own takes
Setup
We need the following ingredients
- A non-anthropic prior over worlds where [1]
- A set of all the observers in for each .
- A subset of observers of observers in each world for each that contain your exact current observer moment
- Note it's possible to have some empty - worlds in
My recommendations for small donors
I think there are benefits to thinking about where to give (fun, having engagement with the community, skill building, fuzzies)[1] but I think that most people shouldn’t think too much about it and - if they are deciding where to give - should do one of the following.
1 Give to the donor lottery
I primarily recommend giving through a donor lottery and then only thinking about where to give in the case you win. There are existing arguments for the donor lottery.
2 Deliberately funge with funders you trust
Alternatively I ...
Using goal factoring on tasks with ugh fields
Summary: Goal factor ugh tasks (listing the reasons for completing the task) and then generate multiple tasks that achieve each subgoal.
Example: email
I sometimes am slow to reply to email and develop an ugh-field around doing it. Goal factoring "reply to the email" into
- complete sender's request
- be polite to the sender (i.e. don't take ages to respond)
one can see that the first sub-goal may take some time (and maybe is the initial reason for not doing it straight away), the second sub-goal is easy! One...
Thanks for the post! I thought it was interesting and thought-provoking, and I really enjoy posts like this one that get serious about building models.
Thanks :-)
...One thought I did have about the model is that (if I'm interpreting it right) it seems to assume a 100% probability of fast takeoff (from strong AGI to ASI/the world totally changing), which isn't necessarily consistent with what most forecasters are predicting. For example, the Metaculus forecast for years between GWP growth >25% and AGI assigns a ~25% probability that it will be at least
Thanks for putting it together! I'll give this a go in the next few weeks :-)
In the past I've enjoyed doing the YearCompass.
Thanks!
And thanks for the suggestion, I've created a version of the model using a Monte Carlo simulation here :-)
This is a short follow up to my post on the optimal timing of spending on AGI safety work which, given exact values for the future real interest, diminishing returns and other factors, calculated the optimal spending schedule for AI risk interventions.
This has also been added to the post’s appendix and assumes some familiarity with the post.
Here I consider the most robust spending policies and supposes uncertainty over nearly all parameters in the model[1] Inputs that are not considered include: historic spending on research and influence, rather...
Previously the benefactor has been Carl Shulman (and I'd guess he is again, but this is pure speculation). From 2019-2020 donor lottery page:
Carl Shulman will provide backstop funding for the lotteries from his discretionary funds held at the Centre for Effective Altruism.
The funds mentioned are likely these $5m from March 2018:
The Open Philanthropy Project awarded a grant of $5 million to the Centre for Effective Altruism USA (CEA) to create and seed a new discretionary fund that will be administered by Carl Shulman
This is great to hear! I'm personally more excited by quality-of-life improvement interventions rather than saving lives so really grateful for this work.
Echoing kokotajlod's question for GiveWell's recommendations, do you have a sense of whether your recommendations change with a very high discount rate (e.g. 10%)? Looking at the graph of GiveDirectly vs StrongMinds it looks like the vast majority of benefits are in the first ~4 years
Minor note: the link at the top of the page is broken (I think the 11/23 in the URL needs to be changed to 11/24)

In this recent post from Oscar Delaney they got the following result (sadly doesn't go up to 10%, and in the linked spreadsheet the numbers seem hardcoded)
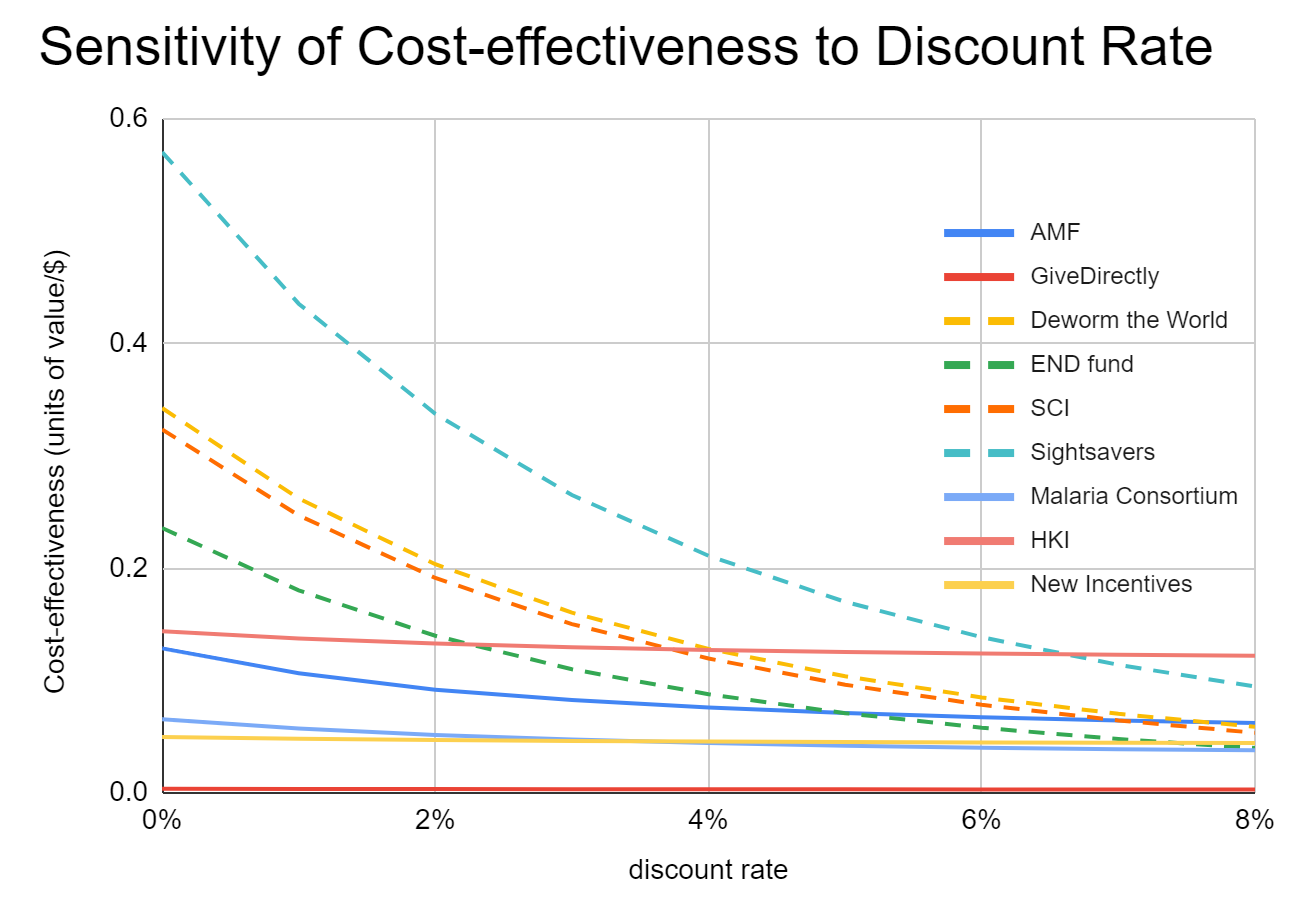
Top three are Hellen Keller International (0.122), Sightsavers (0.095), AMF (0.062)
Increasing/decreasing one's AGI timelines decrease/increase the importance [1] of non-AGI existential risks because there is more/less time for them to occur[2].
Further, as time passes and we get closer to AGI, the importance of non-AI x-risk decreases relative to AI x-risk. This is a particular case of the above claim.
These seem neat! I'd recommend posting them to the EA Forum - maybe just as a shortform - as well as on your website so people can discuss the thoughts you've added (or maybe even posting the thoughts on your shortform with a link to your summary).
For a while I ran a podcast discussion meeting at my local group and I think summaries like this would have been super useful to send to people who didn't want to / have time to listen. As a bonus - though maybe too much effort - would be generating discussion prompts based on the episode.
I highly recommend Nick Bostrom's working paper Base Camp for Mt. Ethics.
Some excerpts on the idea of the cosmic host that I liked most:
...34. At the highest level might be some normative structure established by what we may term the cosmic host. This refers to the entity or set of entities whose preferences and concordats dominate at the largest scale, i.e. that of the cosmos (by which I mean to include the multiverse and whatever else is contained in the totality of existence). It might conceivably consist of, for example, galactic civilizations, simu
I've been building a model to calculate the optimal spending schedule on AGI safety and am looking for volunteers to run user experience testing.
Let me know via DM on the forum or email if you're interested :-)
The only requirements are (1) to be happy to call & share your screen for ~20 to ~60 minutes while you use the model (a Colab notebook which runs in your browser) and (2) some interest in AI safety strategy (but certainly no expertise necessary)
I was also not sure how the strong votes worked, but found a description from four years ago here. I'm not sure if the system's in date.
...Normal votes (one click) will be worth
- 3 points – if you have 25,000 karma or more
- 2 points – if you have 1,000 karma
- 1 point – if you have 0 karma
Strong Votes (click and hold) will be worth
- 16 points (maximum) – if you have 500,000 karma
- 15 points – 250,000
- 14 points – 175,000
- 13 points – 100,000
- 12 points – 75,000
- 11 points – 50,000
- 10 points – 25,000
- 9 points – 10,000
- 8 points – 5,000
- 7 points – 2,500
- 6 points
Thanks for writing this! I think you're right that if you buy the Doomsday argument (or assumptions that lead to it) then we should update against worlds with 10^50 future humans and towards worlds with Doom-soon.
However, you write
My take is that the Doomsday Argument is ... but it follows from the assumptions outlined
which I don't think is true. For example, your assumptions seem equally compatible with the self-indication assumption (SIA) that doesn't predict Doom-soon.[1]
I think a lot of confusions in anthropics go away when we convert probability quest...
Thanks for your response Robin.
I stand by the claim that both (updating on the time remaining) and (considering our typicality among all civilizations) is an error in anthropic reasoning, but agree there are non-time remaining reasons reasons to expect (e.g. by looking at steps on the evolution to intelligent life and reasoning about their difficulties). I think my ignorance based prior on was naive for not considering this.
I will address the issue of the compatibility of high and high by look...
I recently wrote about how AGI timelines change the relative value of 'slow' acting neartermist interventions relative to 'fast' acting neartermist interventions.
It seems to me that EAs in other cause areas mostly ignore this, though I haven't looked into this too hard.
My (very rough) understanding of Open Philanthropy's worldview diversification approach is that the Global Health and Wellbeing focus area team operates on both (potentially) different values and epistemic approaches to the Longtermism focus area team. The epistemic a...
Thanks for running the survey, I'm looking forward to seeing results!
I've filled out the form but find some of the potential arguments problematic. It could be worth to seeing how persuasive others find these arguments but I would be hesitant to promote arguments that don't seem robust. In general, I think more disjunctive arguments work well.
For example, (being somewhat nitpicky):
Everyone you know and love would suffer and die tragically.
Some existential catastrophes could happen painlessly and quickly .
...We would destroy the universe's only chance a
I definitely agree people should be thinking about this! I wrote about something similar last week :-)
- Is there a better word than 'sustenance' for outcomes where humanity does not suffer a global catastrophe?
There is some discussion here about such a term
Surely most neartermist funders think that the probability that we get transformative AGI this century is low enough that it doesn't have a big impact on calculations like the ones you describe?
I agree with Thomas Kwa on this
There are a couple views by which neartermism is still worthwhile even if there's a large chance (like 50%) that we get AGI soon -- ...
I think neartermist causes are worthwhile in their own right, but think some interventions are less exciting when (in my mind) most of the benefits are on track to come after AGI.
...The idea that a n
Thanks for writing the post :-)
I think I'm confused that I expected the post (going by the title) to say something like "even if you think AI risk by year Y is X% or greater, you maybe shouldn't change your life plans too much" but instead you're saying "AI risk might be lower than you think, and at a low level it doesn't affect your plans much" and then give some good considerations for potentially lower AI x-risk.
2x speed on voice messages
Just tested, and Signal in fact has this feature.
I'd also add in Telegram's favour
- Web based client (https://web.telegram.org/) whereas Signal requires an installed app for some (frustrating) reason
and in Signal's favour
- Any emoji reaction available (Telegram you have to pay for extra reacts) [this point leads me to worry Telegram will become more out-to-get-me over time]
- Less weird behaviour (e.g. in Telegram, I can't react to images that are sent without text & in some old group chats I can't react to anything)
(I am neith...
This LessWrong post had some good discussion about some of the same ideas :-)
An advanced civilization from outer space could easily colonize our planet and enslave us as Columbus enslaved the Indigenous tribes of the Americas
I think this is unlikely, since my guess is that (if civilization continues on Earth) we'll reach technological maturity in a much shorter time than we expect to meet aliens (I consider the time until we meet aliens here).
I'd add another benefit that I've not seen in the other answers: deciding on the curriculum and facilitating yourself get you to engage (critically) with a lot with EA material. Especially for the former you have to think about the EA idea-space and work out a path through it all for fellows.
I helped create a fellowship curriculum (mostly a hybrid of two existing curricula iirc) before there were virtual programs or and this definitely got me more involved with EA. Of course, there may be a trade-off in quality.
I agree with what you say, though would note
(1) maybe doom should be disambiguated between "the short-lived simulation that I am in is turned of"-doom (which I can't really observe) and "the basement reality Earth I am in is turned into paperclips by an unaligned AGI"-type doom.
(2) conditioning on me being in at least one short-lived simulation, if the multiverse is sufficiently large and the simulation containing me is sufficiently 'lawful' then I may also expect there to be basement reality copies of me too. In this case, doom is implied for (what I would guess is) most exact copies of me.
Hey Bulat! Tristan from the Center on Long-Term Risk (CLR) here.
I don't use Telegram and don't know of an existing Telegram group. There are already several existing spaces across different platforms:
The Forum is also ... (read more)