Principle 3: Our explicit, subjective credences are approximately accurate enough, most of the time, even in crazy domains, for it to be worth treating those credences as a salient input into action.
I think for me at least, and I'd guess for other people, the thing that makes the explicit subjective credences worth using is that since we have to make prioritisation decisions//decisions about how to act anyway, and we're going to make them using some kind of fuzzy approximated expected value reasoning , making our probabilities explicit should improve our reasoning.
e.g. Why do some others not work on reducing risks of catastrophe from AI? It seems like it's at least partly because they think it's very very unlikely that such a catastrophe could happen. EAs are more likely to think that asking themselves "how unlikely do I really think it is?" and then be able to reason with the result, is helpful.
The Jadagul post is good push back on that, but I do think it helps put "rational pressure" on one's beliefs in a way that is often productive. I'd guess that without naming the probabilities explicitly, the people in that story would still have similar (and similarly not-consistent) beliefs.
I think you are right that this might be a norm/heuristic in the community, but in the spirit of a "justificatory story of our epistemic practices," I want to look a little more at
4. When arguments lead us to conclusions that are both speculative and fanatical, treat this as a sign that something has gone wrong.
First, I'm not sure that "speculative" is an independent reason that conclusions are discounted, in the sense of a filter that is applied ex-post. In your 15AI thought experiment, for example, I think that expected value calculations would get you most of the way toward explaining an increase in fanaticism; the probability that we can solve the problem might increase on net, despite the considerations you note about replication. The remaining intuition might be explained by availability/salience bias, to which EA is not immune.
Now, "speculative" scenarios might be discounted during the reasoning process if we are anchored to commonsense priors, but this would fall under typical bayesian reasoning. The priors we use and the weight we grant various pieces of evidence are still epistemic norms worthy of examination! But a different kind than suggested by the fourth principle.
Suppose "speculative" arguments are discounted ex-post in EA. I think this practice can still be redeemed on purely bayesian grounds as a correction to the following problems:
Undiscovered Evidence: An argument seems speculative not just insofar as it is divorced from empirical observations, but also insofar as we have not thought about it very much. It seems that AI risk has become less speculative as people spend more time thinking about it, holding constant actual progress in AI capabilities. We have some sense of the space of possible arguments that might be made and evidence that might be uncovered, given further research on a topic. And these undiscovered arguments/evidence might not enter neatly into our initial reasoning process. We want some way to say "I haven't thought of it yet, but I bet there's a good reason this is wrong," as we might respond to some clever conspiracy theorist who presents a superficially bulletproof case for a crazy theory we haven't encountered before. And discounting speculative conclusions is one way to achieve this.
This point is especially relevant for speculative conclusions because they often rely on chains of uncertain premises, making our credence in their conclusions all the more sensitive to new information that could update multiple steps of the argument.
Model Uncertainty: Even in a domain where we have excavated all the major arguments available to us, we may still suffer from "reasoning in the dark," ie, in the absence of solid empirics. When reasoning about extremely unlikely events, the probability our model is wrong can swamp our credence in its conclusion. Discounting speculative conclusions allows us to say "we should be fanatical insofar as my reasoning is correct, but I am not confident in my reasoning."
We can lump uncertainty in our axiology, epistemology, and decision theory under this section. That is, a speculative conclusion might look good only under total utilitarian axiology, bayesian epistemology, and causal decision theory, but a more conventional conclusion might be more robust to alternatives in these categories. (Note that this is a prior question to the evidential-hedging double bind set up in Appendix B.)
Chains of uncertain premises also make model uncertainty doubly important for speculative conclusions. As Anders Sandberg points out, "if you have a long argument, the probability of there being some slight error somewhere is almost 1."
Even after accounting for these considerations, we might find that the EV of pursuing the speculative path warrants fanaticism. In this event, discounting the speculative conclusion might be a pragmatic move to deprioritize actions on this front in anticipation of new evidence that will come to light, including evidence that will bear on model uncertainty. (We might treat this as a motivation for imprecise credences, prioritizing views with sharper credences over speculative views with fuzzier ones.)
I understand you to be offering two potential stories to justify ‘speculativeness-discounting’.
First, EAs don’t (by and large) apply a speculativeness-discount ex post. Instead, there’s a more straightforward ‘Bayesian+EUM’ rationalization of the practice. For instance, the epistemic practice of EAs may be better explained with reference to more common-sense priors, potentially mediated by orthodox biases.
Or perhaps EAs do apply a speculativeness-discount ex post. This too can be justified on Bayesian grounds.
We often face doubts about our ability to reason through all the relevant considerations, particularly in speculative domains. For this reason, we update on higher-order uncertainty, and implement heuristics which themselves are justified on Bayesian grounds.
In my response, I’ll assume that your attempted rationale for Principle 4 involves justifying the norm with respect to the following two views:
Expected Utility Maximization (EUM) is the optimal decision-procedure.
The relevant probabilities to be used as inputs into our EUM calculation are our subjective credences.
The ‘Common Sense Priors’ Story
I think your argument in (1) is very unlikely to provide a rationalization of EA practice on ‘Bayesian + EUM’ grounds.[1]
Take Pascal’s Mugging. The stakes can be made high enough that the value involved can easily swamp your common-sense priors. Of course, people have stories for why they shouldn’t give the money to the mugger. But these stories are usually generated because handing over their wallet is judged to be ridiculous, rather than the judgment arising from an independent EU calculation. I think other fanatical cases will be similar. The stakes involved under (e.g.) various religious theories and our ability to acausally affect an infinite amount of value are simply going to be large enough to swamp our initial common-sense priors.
Thus, I think the only feasible ‘Bayes+EUM’ justification you could offer would have to rely on your ‘higher-order evidence’ story about the fallibility of our first-order reasoning, which we’ll turn to below.
The ‘Higher-Order Evidence’ Story
I agree that we can say: “we should be fanatical insofar as my reasoning is correct, but I am not confident in my reasoning.”
The question, then, is how to update after reflecting on your higher-order evidence. I can see two options: either you have some faith in your first-order reasoning, or no faith.
Let’s start with the case where you have some faith in your first-order reasoning. Higher-order evidence about your own reasoning might decrease the confidence in your initial conclusion. But, as you note, “we might find that the EV of pursuing the speculative path warrants fanaticism”. So, what to do in that case?
I think it’s true that many people will cite considerations of the form “let’s pragmatically deprioritize the high EV actions that are both speculative and fanatical, in anticipation of new evidence”. I don’t think that provides a sufficient justificatory story of the epistemic norms to which most of us hold ourselves.
Suppose we knew that our evidential situation was as good as it’s ever going to be. Whatever evidence we currently have about (e.g.) paradoxes in infinite ethics, or the truth of various religions constitutes ~all the evidence we’re ever going to have.
I still don’t expect people to follow through on the highest EV option, when that option is both speculative and fanatical.
Or maybe you have a bounded utility function. In that case, imagine that the world already contains a sufficiently large number of suffering entities. How blase are you, really, about the creation of arbitrarily many suffering-filled hellscapes?
There’s more to say here, but the long and short of it is: if you fail to reach a point where you entirely discount certain forms of speculative reasoning, I don’t think you’ll be able to recover anything like Principle 4. My honest view is that many EAs have a vague hope that such theories will recover something approaching normality, but very few people actually try to trace out the implications of such theories on their own terms, and follow through on these implications. I’m sympathetic to this quote from Paul Christiano:
I tried to answer questions like "How valuable is it to accelerate technological progress?" or "How bad is it if unaligned AI takes over the world?" and immediately found that EU maximization with anything like "utility linear in population size" seemed to be unworkable in practice. I could find no sort of common-sensical regularization that let me get coherent answers out of these theories, and I'm not sure what it would look like in practice to try to use them to guide our actions.
Higher-Order Evidence and Epistemic Learned Helplessness
Maybe you’d like to say: “in certain domains, we should assign our first-order calculations about which actions maximize EU zero weight. The heuristic ‘sometimes assign first-order reasoning zero weight’ can be justified on Bayesian grounds.”
I agree that we should sometimes assign our first-order calculations about which actions maximize EU zero weight. I’m doubtful that Bayesianism or EUM play much of a role in explaining why this norm is justified.
When we’re confronted with the output of an EUM calculation that feels off, we should listen to the parts of us which tell us to check again, and ask why we feel tempted to check again.
If we’re saying “no, sorry, sometimes I’m going to put zero weight on a subjective EU calculation”, then we’re already committed to a view under which subjective EU calculations only provide action-guidance in the presence of certain background conditions.
If we’re willing to grant that, then I think the interesting justificatory story is a story which informs us of what the background conditions for trusting EU calculations actually are — rather than attempts to tell post hoc stories about how our practices can ultimately be squared with more foundational theories like Bayesianism + EUM.
If you’re interested, I’ll have a post in April touching on these themes. :)
I also think the sociological claim you made is probably false. However, as you’re primarily asking about the justificatory side of things, I’ll bracket that here — though I’m happy to make this case in more detail if you’d like.
Thanks for the thorough response! I agree with a lot of what you wrote, especially the third section on Epistemic Learned Helplessness: "Bayesianism + EUM, but only when I feel like it" is not a justification in any meaningful sense.
On Priors
I agree that we can construct thought experiments (Pascal's Mugging, acausal trade) with arbitrarily high stakes to swamp commonsense priors (even without religious scenarios or infinite value, which are so contested I think it would be difficult to extract a sociological lesson from them).
On Higher Order Evidence
I still think a lot of speculative conclusions we encounter in the wild suffer from undiscovered evidence and model uncertainty, and even barring this we might want to defer taking action until we've had a chance to learn more.
Your response jumps over these cases to those where we have "~all the evidence we’re ever going to have," but I'm skeptical these cases exist. Even with religion, we might expect some future miracles or divine revelations to provide new evidence; we have some impossibility theorems in ethics, but new ideas might come to light that resolve paradoxes or avoid them completely. In fact, soteriological research and finding the worldview that best acausally benefits observers are proposals to find new evidence.
But ok, yes, I think we can probably come up with cases where we do have ~all the evidence and still refrain from acting on speculative + fanatical conclusions.
Problem 1: Nicheness
From here on, I'm abandoning the justification thing. I agree that we've found some instances where the Fourth Principle holds without Bayesian + EUM justification. Instead, I'm getting more into the semantics of what is a "norm."
The problem is that the support for this behavior among EAs comes from niche pieces of philosophy like Pascal's Mugging, noncausal decision theory, and infinite ethics, ideas that are niche not just relative to the general population, but also within EA. So I feel like the Fourth Principle amounts to "the minority of EAs who are aware of these edge cases behave this way when confronted with them," which doesn't really seem like a norm about EA.
Problem 2: Everyone's Doing It
(This is also not a justification, it's an observation about the Fourth Principle)
The first three principles capture ways that EA differs from other communities. The Fourth Principle, on the other hand, seems like the kind of thing that all people do? For example, a lot of people write off earning to give when they first learn about it because it looks speculative and fanatical. Now, maybe EAs differ from other people on which crazy train stop they deem "speculative," and I think that would qualify as a norm, but relative to each person's threshold for "speculative," I think this is more of a human-norm than an EA-norm.
Would love your thoughts on this, and I'm looking forward to your April post :)
Nitpick: I suspect EAs lean more toward Objective Bayesianism than Subjective Bayesianism. I'm unclear whether it's valuable to distinguish between them.
I read Violet's post, am reviewing some of the background material, and just browsed some online stuff about Bayesianism. I would learn something by your elaboration on the difference you think applies to EA's.
I read your post a couple times, and the appendices. You're interested in exploring informal logic applied in EA thought. I will offer one of my biggest learnings about informal logic applied here in EA thought.
When evaluating longtermism's apparent commitment to a large future population in a few forum posts, I attempted to gather information about whether EA's think that:
the act of procreation is a moral act.
continuation of the species is a moral on-going event.
hypothetical future humans (or other hypothetical beings) deserve moral status.
I got the response, "I believe in making happy people" along with making people happy.
Exploring this with some helpful folks on the forum, I learned about an argument built on the money-pump template for thought experiments.
There's a money pump argument for the combination of:
moral preference for happy people.
moral indifference for making happy people.
Keeping preferences 1.1 and 1.2 means I can be money-pumped.
Any preferences that can be money-pumped is irrational.
My moral preferences 1.1 and 1.2 are irrational in combination.
I should make my moral preferences rationally consistent.
Basically anyone who thinks its good to make people happy should also think its good to make happy people.
I had never come across such an argument before! Money-pumping, this is new. As I have explored it, I have seen it increasingly as an argument from analogy. It works as follows:
EA has this list of money-pump thought experiments.
Suppose I hold point of view X.
There's an analogous money-pump thought experiment.
By analogy, my point of view X is irrational.
I should change my point of view.
Well, so there are three points of potential disagreement here:
Is the money-pump thought experiment analogous?
if it is analogous, does it prove my point of view is irrational?
if my point of view (an ethical one) is irrational, should I change it?
I doubt that EA thought experiments are analogous to my ethical beliefs and preferences, which I think are in the minority in some respects. However, in exploring the answers to each of those questions, an insider could determine the cluster of beliefs that EA's keep around rationality, mathematics, and ethics.
You claim to be a long-time EA, and I believe you. I don't know who you are, of course, but if you're a long-time member of this community of interesting people, then I guess you've got the connections to get some answers to some casual questions.
I actually can't do the same. I don't have the time to build engagement or trust in this community enough for such an important project nor to read through past forum posts to track relevant lines of thought in enough detail to use those as a proxy.
My interest in doing so would be different, but that's another story.
You wrote:
Now, we know that if your uncertainty can’t be represented with a probability function, then you can be money pumped. There are proofs of this. Guaranteed losses are bad, thus, so the argument goes, you should behave so that your uncertainty can be represented with a probability function.
I followed the link and am browsing the book. Are you sure that link presents any arguments or proofs of why a probability function is necessary in the case of uncertainty?
I see content on: cyclic preferences; expected value; decision trees; money pump set ups with optional souring and sweetening; induction, backward and forward; indifference vs preferential gaps; various principles. It all goes to show that having cyclic preferences has different implications than acyclic preferences and cyclic preferences can be considered irrational (or at least mismatched to circumstances). The result is very interesting and useful for modeling some forms of irrationality well, but that's not what I am looking for as I read it.
I can't find any proof of a probability distribution requirement under uncertainty. Is there a specific page you can point me to in the Gustaffson reference or should I use the alternate reference on arguments for probabilism?
Once I tackle this topic, and detail my conclusions about it in a criticism document that I am still writing (about unweighted beliefs, I can't get anybody to actually read it, lol), I will pursue some other topics you raised.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
I think right now EAs might be making a significant mistake by paying insufficient attention to the political realm. As EAs we tend to figure out what’s most impactful for us to work on and focus hard. That’s great! But there are various actions that are ‘non-delegatable’ - the extent to which an individual can do the action is limited (like voting, going to a protest, making hard money contributions to particular campaigns). It might be useful if we were all more in the habit of doing variou...
New Video from AI in Context: The Fall and Rise of Sam Altman
If you want to skip straight to the video, here it is!
AI in Context is excited to be back with our fourth video! For those just hearing from us, we make videos for 80,000 Hours, telling stories about transformative AI...
Note: This post primarily examines the informal epistemic norms which govern EA. Consequently, it's mostly a work of sociology rather than philosophy. These informal norms are fleshed out in Section 4, and I’ll briefly state them here.[1]
If it’s worth doing, it’s worth doing with made up numbers.
Speculative reasoning is worth doing.
Our explicit, subjective credences are approximately accurate enough, most of the time, even in crazy domains, for it to be worth treating those credences as a salient input into action.
When arguments lead us to conclusions that are both speculative and fanatical, treat this as a sign that something has gone wrong.
This piece (in aspiration, at least) is written to be accessible to people who are less involved with EA than typical Forum readers. Thus, if you’re familiar with EA, you can skim the introduction. Section 2 provides an informal exposition of Subjective Bayesianism and Expected Value Theory — if you’re familiar with those theories, that section can also be skimmed.
1. Introduction
The future might be very big, and we might be able to do a lot, right now, to shape it.
You might have heard of a community of people who take this idea pretty seriously — effective altruists, or ‘EAs’. If you first heard of EA a few years ago, and haven’t really followed it since, then you might be pretty surprised at where we’ve ended up.
Currently, EA consists of a variety of professional organizations, researchers, and grantmakers, all with (sometimes subtly) different approaches to doing the most good possible. Organizations which, collectively, donate billions of dollars towards interventions aiming to improve the welfare of conscious beings. In recent years, the EA community has shifted its priorities towards an idea called longtermism — very roughly, the idea that we should primarily focus our altruistic efforts towards shaping the very long-run future. Like, very long-run. At least thousands of years. Maybe more.
(From hereon, I’ll use ‘EA’ to talk primarily about longtermist EA. Hopefully this won’t annoy too many people).
Anyway, longtermist ideas have pushed EA to focus on a few key cause areas — in particular, ensuring that the development of advanced AI is safe, preventing the development of deliberately engineered pandemics, and (of course) promoting effective altruism itself. I've been part of this community for a while, and I've often found outsiders bemused by some of our main priorities. I've also found myself puzzled by this bemusement. The explicit commitments undergirding (longtermist) EA, as many philosophers involved with EA remind us, are really not all that controversial. And those philosophers are right, I think. Will MacAskill, for instance, has listed the following three claims as forming the basic, core argument behind longtermism.
(1) Future people matter morally.
(2) There could be enormous numbers of future people.
(3) We can make a difference to the world they inhabit.
Together, these three claims all seem pretty reasonable. With that in mind, we’re left with a puzzle: given that EA’s explicitly stated core commitments are not that weird, why, to many people, do EA’s explicit, practical priorities appear so weird?
In short, my answer to this puzzle claims that EA’s priorities emerge, to a large extent, from EA’s unusual epistemic culture. So, in this essay, I’ll attempt to highlight the sociologically distinctive norms EAs adopt, in practice, concerning how to reason, and how to prioritize under uncertainty. I’ll then claim that various informal norms, beyond some of the more explicit philosophical theories which inspire those norms, play a key role in driving EA’s prioritization decisions.
2. Numbers, Numbers, Numbers
Suppose I asked you, right now, to give me a probability that Earth will experience an alien invasion within the next two weeks.
You might just ignore me. But suppose you‘ve come across me at a party; the friend you arrived with is conspicuously absent. You look around, and, well, the other conversations aren’t any better. Also, you notice that the guy you fancy is in the corner; every so often, you catch him shyly glancing at us. Fine, you think, I could be crazy, but talking to me may get you a good conversation opener. You might need it. The guy you like seems pretty shy, after all.
So, you decide that you’re in this conversation, at least for now. You respond by telling me that, while you’re not sure about exact probabilities, it’s definitely not going to happen. You pause, waiting for my response, with the faint hope that I’ll provide the springboard for a funny anecdote you can share later on.
“Okay, sure, it almost certainly won’t happen. But how sure are you, exactly? For starters, it’s clearly less likely than me winning the lottery. So we know it’s under 1/106. I think I’ve probably got more chance at winning two distinct lotteries in my lifetime, at least if I play every week, so let’s change our lower bound to … ” — as I’m talking, you politely excuse yourself. You’ve been to EA parties before, enough to know that this conversation isn’t worth it. You spend your time in the bathroom searching for articles on how to approach beautiful, cripplingly shy men.
Spend enough time around EAs, and you may come to notice that many EAs have a peculiar penchant for sharing probabilities about all sorts of events, both professionally and socially. Probabilities, for example, of the likelihood of smarter-than-human machines by 2040 (in light of recent developments, Ajeya Cotra’s current best guess is around 50%), the probability of permanent human technological stagnation (Will MacAskill says around 1 in 3), or the chance of human extinction (Toby Ord’s book, The Precipice, ends up at about 1 in 6).
As you leave the party, you start to wonder why EAs tend to be beset by this particular quirk.
2.1
In brief, the inspiration for this practice stems from a philosophical idea, Subjective Bayesianism — which theorizes how ideally rational agents behave when faced with uncertainty.
Canonically, one way of setting up the argument for Subjective Bayesianism goes something like this: suppose that you care about some outcomes more than others, and you’re also (to varying degrees) uncertain about the likelihood of all sorts of outcomes (such as, for example, whether it’s going to rain tomorrow). And suppose this uncertainty feeds into action in a certain way: other things equal, your actions are influenced more by outcomes which you judge to be more likely.
Given all this, there are arguments showing that there must be some way of representing your uncertainty with a probability function — that is, for any given state of the world (like, for example, whether it’s raining), there’s some number between 0 and 1 which represents your uncertainty about that state of the world, called your ‘credence’, and your credences have to obey certain rules (for instance, your credence in ‘rain or not rain’ has to sum to 1).
Why must these rules be obeyed? Well, if those rules aren’t obeyed, then there are situations where someone who has no more information than you can offer you a series of bets, which — given how likely you think those outcomes are — appear to be good deals. Nevertheless, taking this series of bets is guaranteed to lose you money. This type of argument is called a ‘money pump’ argument, because someone who (again) has no more knowledge than you do, has a procedure for “pumping money” from you indefinitely, or at least until you reach insolvency.
Now, we know that if your uncertainty can’t be represented with a probability function, then you can be money pumped. There are proofs of this. Guaranteed losses are bad, thus, so the argument goes, you should behave so that your uncertainty can be represented with a probability function.[2]
We should also mention that there’s a formula which tells you how to update probabilities upon learning new information — Bayes’ rule. Hence, the ‘Bayesian’ part of Subjective Bayesianism. You have probabilities, which represent your subjective states of uncertainty. As your uncertainty is modeled with a probability function, you update your uncertainty in the standard way you’d update probabilities.
Do you actually need to be forming credences in practice? Well, maybe not, we’ll get to that. But humans can be pretty bad at reasoning with probabilities in various psychologicalexperiments, and we know that people can become better calibrated when prompted to think in more explicitly probabilistic ways — Philip Tetlock’s work on superforecasting has illustrated this. So there is something motivating this sort of practice.
2.2
Suppose, after leaving the EA party, you begin to reconsider your initial disdain. You are uncertain about lots of things, and you definitely don’t want to be money-pumped. Also, you like the idea of helping people. You start to consider more stuff, even some quite weird stuff, and maybe now you even have your very own credences. But you were initially drawn to EA because you wanted to actually help people — so, now what? What should you actually do?
When deciding how to act, EAs are inspired by another theoretical ideal — Expected Value Theory.
80,000 Hours introduce this idea nicely. They ask you to suppose that there’s (what looks to be) a tasty glass of beer in front of you. Unfortunately, the beer is unwisely produced, let’s say, in a factory that also manufactures similarly coloured poison. Out of every 100 glasses of the mystery liquid, one will be a glass of poison. You know nothing else about the factory. Should you drink the mystery liquid?
Well, like, probably not. Although drinking the liquid will almost certainly be positive, “the badness of drinking poison far outweighs the goodness of getting a free beer”, as 80,000 Hours’ president Ben Todd sagely informs us.
This sort of principle generalizes to other situations, too. When you’re thinking about what to do, you shouldn’t only think about what is likely to happen. Instead, you should think about which action has the highest expected value. That is, you take the probability that your action will produce a given outcome, and multiply that probability by the value you assign to that outcome, were it to happen. Then, you add up all of the probability-weighted values. We can see how this works with the toy example below, using some made up numbers for valuations.
We can treat the valuations of ‘beer’ and ‘poison’ as departures from my zero baseline, where I don’t drink the liquid. So, in this case, as the expected value of the drink is -995.05 (which is less than zero), you shouldn’t drink the (probable) beer.
Now, if you care about the very long-run future, calculating the effects of everything you do millions of years from now, with corresponding probabilities, would be … pretty demanding. For the most part, EAs recognise this demandingness. Certainly, professional organizations directing money and talent recognise this; while it sometimes makes sense to explicitly reason in terms of expected value, it often doesn’t. 80,000 Hours state this explicitly, mentioning the importance of certain proxies for evaluating problems — like their ‘importance, neglectedness, and tractability’ (INT). These proxies are, in general, endorsed by EAs. Open Philanthropy, a large grantmaking organization with a dedicated longtermist team, also reference these proxies as important for their grantmaking.
Still, even when using proxies like INT, 80,000 Hours caution against taking the estimates literally. In my experience interacting with people at big EA organizations, this view is pretty common. I don’t remember encountering anyone taking the output of any one quantitative model completely literally. Instead, a lot of intuition and informal qualitative reasoning is involved in driving conclusions about prioritization. However, through understanding the formal frameworks just outlined, we’re now in a better position to understand the ways in which EA’s epistemology goes beyond these frameworks.
And we’ll set the scene, initially, with the help of a metaphor.
3. Uncertainty and the Crazy Train
Ajeya Cotra works for Open Philanthropy, where she wrote a gargantuan report on AI timelines, estimating the arrival of smarter-than-human artificial systems.
Alongside an estimate for the advent of AI with power to take control over the future of human civilisation, the report acts as a handy reference point for answers to questions like “how much computational power, measured in FLOPS, are the population of nematode worms using every second?”, and “how much can we infer about the willingness of national governments to spend money on future AI projects, given the fraction of GDP they’ve previously spent on wars?”
But perhaps Ajeya’s most impressive accomplishment is coining the phrase “the train to Crazy Town”, in reference to the growing weirdness of EA.
The thought goes something like this: one day, people realized that the world contains a lot of bad stuff, and that it would be good to do things to alleviate that bad stuff, and create more good stuff. Thus the birth of GiveWell, which ranked charities in terms of amount of good done per $. Malaria nets are good, and the Against Malaria Foundation is really effective at distributing malaria nets to the most at-risk. Deworming pills also look good, potentially, though there’s been some brouhaha about that. You’re uncertain, but you’re making progress. You start researching questions in global health and well-being, looking for ever-better ways to improve the lives of the world’s poorest.
Still, you’re trying to do the most good you can do, which is a pretty lofty goal. Or, the most good you can do in expectation, because you’re uncertain about a lot of things. So you begin considering all of the ways in which you’re uncertain, and it leads you to weird places. For one, you start to realize there could be quite a lot of people in the future. Like, a lot a lot. In Greaves’ and MacAskill’s paper defending longtermism, they claim that “any reasonable estimate of the expected number of future beings is at least 1024”.
10,000,000,000,000,000,000,000,000 people. At least. [3]
Anyway, each of these 1024 people has hopes and dreams, no less important than our hopes, or the hopes and dreams of our loved ones and families. And you care about these potential people. You want to be sure that you’re actually making the world, overall, better — as much as you possibly can.
After spending some time reflecting on just how bad COVID was, you decide to shift to biosecurity. No one engineered COVID to be bad, and yet, still, it was pretty bad. Reflecting on the consequences of COVID leads you to wonder how much worse a deliberately engineered pandemic could be. Initially, a piece of theoretical reasoning gets you worried: you learn that the space of all possible DNA sequences is far, far larger than the number of DNA sequences generated by evolution. If someone wanted to engineer a pandemic with far casualty rates then, well, they very likely could. You imagine various motives for doing this, and they don’t seem all that implausible. Perhaps a small group of bioterrorists become convinced humanity is a stain on the planet, and set to destroy it; or perhaps states respond to military conflict with a pandemic attack so deadly and viral that it expands globally, before we have time to develop effective prevention.
But then you begin to descend the rabbit hole further. You encounter various cosmological theories, suggesting that our universe could be spatially infinite, with a potentially infinite number of sentient beings.
Of course, you initially think that we couldn’t affect the well-being of infinitely many people — almost all of these people live outside our lightcone, after all. But some decision theories seem to imply that we could “acausally” affect their well-being, at least in an infinite universe. And lots of smart people endorse these decision theories. You remember to update your credences in response to expert disagreement. You’re neither a cosmologist nor a decision theorist, after all, and these theories have non-trivial acceptance among experts in these fields.[4]
You remember expected value theory. You think about the vastness of infinity, desperately trying to comprehend just how important it would be to affect the happiness, or relieve the misery of infinitely many people. These people matter, you remind yourself. And if you could do something, somehow, to increase the chance that you do an infinitely large amount of good, then, well, that starts to seem worth it. You push through on the project. Some time passes. But, as you’re double-checking your calculations about the best way to acausally affect the welfare of infinitely many aliens, you realize that you’ve ended up somewhere you didn’t quite expect.
The story started with something simple: we wanted to do the most good we could do. And we wanted to check that our calculations were robust to important ways we might be wrong about the world. No one thought that this would be easy, and we knew that we might end up in an unexpected place. But we didn’t expect to end up here. “Something’s off”, you think. You’re not sure what exactly went wrong, but you start to think that this is all seeming just a bit too mad. The Crazy Train, thankfully, has a return route. You hop back on the train, and pivot back to biosecurity.
3.1
So, what point are we meant to draw from that story? Well, I don’t want to claim that following through on expected value reasoning is necessarily going to lead you to the particular concerns I mentioned. Indeed, Ajeya tells her story slightly differently, with a slightly different focus. In this interview, Ajeya discusses the role that reasoning about the simulation argument, along with various theories of anthropic reasoning, played in her decision to alight the Crazy Train at the particular stop she did.
Still, I think the story I told captures, at a schematic level, a broader pattern within the practical epistemology of EA. It’s a pattern where EAs start with something common-sense, or close, and follow certain lines of reasoning, inspired by Subjective Bayesianism and Expected Value Theory, to increasingly weird conclusions. Then, at some point, EAs lose confidence in their ability to adequately perform this sort of explicit probabilistic reasoning. They begin to trust their explicit reasoning less, and fall back on more informal heuristics. Heuristics like “no, sorry, this is just too wacky”.
The practical epistemology of EA is clearly influenced by both Expected Value Theory and Subjective Bayesianism. But I think the inspiration EAs take from these theories has more in common with the way, say, painters draw on prior artistic movements, than it does to a community of morally motivated acolytes, fiercely committed to following the output of certain highly formalized, practical procedures for ranking priorities.
Take Picasso. In later periods, he saw something appealing in the surrealist movement, and so he (ahem) drew from surrealism, not as a set of explicit commitments, but as embodying a certain kind of appealing vision. A fuzzy, incomplete vision he wanted to incorporate into his own work. I think the formal theories we’ve outlined, for EAs, play a similar role. These frameworks offer us accounts of ideal epistemology, and ideal rationality. But, at least for creatures like us, such frameworks radically underdetermine the specific procedures we should be adopting in practice. So, in EA, we take pieces from these frameworks. We see something appealing in their vision. But we approximate them in incomplete, underdetermined, and idiosyncratic ways.
In the remainder of this essay, I want to get more explicit about the ways in which EAs take inspiration from, and approximate these frameworks.
4. Four Implicit Norms of EA Epistemology
Cast your mind back to the parable we started with in Section 2 — the one at the party, discussing the probability of aliens. Most people don’t engage in that sort of conversation. EAs tend to. Why?
I think one reason is that, for a lot of people, there are certain questions which feel so speculative, and so unmoored from empirical data, that we’re unable to say anything meaningful at all about them. Maybe such people could provide credences for various crazy questions, if you pushed them. But they’d probably believe that any credence they offered would be so arbitrary, and so whimsical, that there would just be no point. At some juncture, the credences we offer just cease to represent anything meaningful. EAs tend to think differently. They’re more likely to believe the following claim.
This principle, like the ones which follow it, is (regrettably) vague. Whether something is worth doing, for starters, is a matter of degree, as is the extent to which a number is ‘made up’.
A bit more specifically, we can say the following: EAs tend to believe, to a much larger degree than otherwise similar populations (like scientifically informed policymakers, laypeople, or academics) that if you want highlight the importance of (say) climate change, or the socialist revolution, or housing policy, then you really should start trying to be quantitative about just how uncertain you are about the various claims which undergird your theory of why this area is important. And you should really try, if at all possible, to represent your uncertainty in the form of explicit probabilities. If it’s worth doing, it’s worth doing with explicit reasoning, and quantitative representations of uncertainty.
You can see this principle being applied in Joe Carlsmith’s report on the probability of existential risk from advanced AI, where the probability of existential risk from “misaligned, power-seeking” advanced AI systems is broken down into several, slightly fuzzy, hard-to-evaluate claims, each of which are assigned credences. In this report, Carlsmith explicitly (though cautiously) extols the benefits of using explicit probabilities, as allowing for greater transparency. A similar style reasoning is apparent, too, in Cotra’s report on AI timelines. Drawing on her estimates for the amount of computation required for various biological processes, Cotra presents various probability distributions for the amount of computational power that you’d need to combine with today’s ideas in order to develop an AI with greater-than-human cognitive capabilities. Even in less formal reports, the use of quantitative representations of uncertainty remains present — 80,000 Hours’ report on the importance of ‘GCBRs’ (‘global catastrophic biological risks’), for example, provides various numerical estimates representing reported levels of likelihood for different kinds of GCBRs.
If you read critics of (longtermist) EA, a lot of them really don’t like the use of “made up numbers”. Nathan Robinson criticizes EA’s focus on long-term AI risks, as the case for AI risk relies on “made-up meaningless probabilities.” Boaz Barak claims that, for certain claims about the far-future, we can only make vague, qualitative judgements, such as “extremely likely”, or “possible”, or “can’t be ruled out”. These criticisms, I think, reflect adherence to an implicit (though I think fairly widespread) view of probabilities, where we should only assign explicit probabilities when our evidence is relatively robust.[5] EAs, by contrast, tend to be more liberal in the sort of claims for which they think it’s appropriate (or helpful) to assign explicit probabilities.[6]
Now, most EAs don’t believe that we should be doing explicit expected value calculations all the time, or that we should only be relying on quantitative modeling. Instead, Principle 1 says something like “if we think something could be important, a key part of the process for figuring that out involves numeric estimates of scope and uncertainty — even if, in the end, we don’t take such estimates totally literally”.
Crucially, the adoption of this informal norm is inspired by, but not directly derived from, the more explicit philosophical arguments for Subjective Bayesianism. The philosophical arguments, by themselves, don’t tell you when (or whether) it’s appropriate to assign explicit credences in practice. An appropriate defense (or criticism) of EA practice would have to rely on a different kind of argument. But, before we evaluate this norm, we should first state the norm explicitly, as a distinctive feature of EA’s epistemic culture.
4.1
When introducing the Crazy Train, we saw that EAs do, in fact, exhibit some amount of normal suspicion towards conclusions derived from very speculative or abstract arguments. But one thing that’s unusual about EAs is the fact that these considerations were germane considerations at all. The simulation hypothesis, or theories of acausal reasoning are, for most people, never likely to arise. Certain types of claims are not only beyond the bounds of meaningful probability assignments, they’re beyond the bounds of worthwhile discussion at all.
Principle 2: Speculative reasoning is worth doing.
I’ve claimed that EAs are more likely to believe that if something is “worth doing”, then “it’s worth doing with made up numbers”. Speculative reasoning is worth doing. Thus, in EA , we observe people offering credences for various speculative claims, which other groups are more likely to filter out early on, perhaps on account of sounding too speculative or sci-fi.
What makes a claim speculative? Well, I think it’s got something to do with a claim requiring a lot of theoretical reasoning that extends beyond our direct, observational evidence. If I provide you with an estimate of how many aliens there are in our galaxy, that claim is more speculative than a claim about (say) the number of shops on some random main street in Minnesota. I don’t know the exact number, in either case. But my theories about “how many shops do there tend to be in small US towns” is more directly grounded in observational data than “how many hard steps were involved in the evolution of life?”, for example. And you might think that estimates about the number of extraterrestrials in our galaxy are less speculative, still, than estimates about the probability we live in a simulation. After all, appraising the probability we're living in a simulation relies on some attempt to estimate what post-human psychology will be like — would such creatures want to build simulations of their ancestors?
Like our first principle, our second should be read as a relative claim. EAs think speculative reasoning is more worth doing, relative to the views of other groups with similar values, such as policymakers, activists, or socially conscious people with comparable levels of scientific and technical fluency.
4.2
EAs tend to be fairly liberal in their assignment of probabilities to claims, even when the claims sound speculative. I think an adequate justification of this practice relies on another assumption. I’ll begin by stating that assumption, before elaborating a little bit more.
Principle 3: Our explicit, subjective credences are approximately accurate enough, most of the time, even in crazy domains, for it to be worth treating those credences as a salient input into action.
Recall that EAs often reason in terms of the expected value of an action – that is, the value of outcomes produced by that action, multiplied by the probabilities of each outcome. Now, for the ‘expected value’ of an action to be well-defined — that is, for there to be any fact at all about what I think will happen ‘in expectation’— I need to possess a set of credences which behave as probabilities. And, for many of the topics with which EAs are concerned, it's unclear (to me, at least) what justifies the assumption that our explicit subjective credences do have this property, or how best to go about verifying it.
A tumblr post by Jadagul criticizes a view like Principle 3. In that post, they claim that attempts to reason with explicit probabilities, at least for certain classes of questions, introduces unavoidable, systematic errors.
“I think a better example is the statement: “California will (still) be a US state in 2100.” Where if you make me give a probability I’ll say something like “Almost definitely! But I guess it’s possible it won’t. So I dunno, 98%?”
But if you’d asked me to rate the statement “The US will still exist in 2100”, I’d probably say something like “Almost definitely! But I guess it’s possible it won’t. So I dunno, 98%?”
And of course that precludes the possibility that the US will exist but not include California in 2100.
And for any one example you could point to this as an example of “humans being bad at this”. But the point is that if you don’t have a good sense of the list of possibilities, there’s no way you’ll avoid systematically making those sorts of errors.”
Jadagul’s claim, as I see it, is that there are an arbitrarily large number of logical relationships that you (implicitly) know, even though you'll only be able to bring to mind a very small subset of these relationships. Moreover, these logical relationships, were you made aware of them, would radically alter your final probability assignments. Thus, you might think (and I am departing a little from Jadagul’s original argument here), that at least for many of the long-term questions EAs care about, we just don’t have any reasons to think that our explicitly formed credences will be accurate enough for the procedure of constructing explicit credences to be worth following at all, over and above (say) just random guessing.
To justify forming and communicating explicit credences, which we then treat as salient inputs into action, we need to believe that using this procedure allows us to track and intervene on real patterns in the world, better than some other, baseline procedure. Now, EAs may reasonably state that we don’t have anything better. Even if we can’t assume that our credences are approximately accurate, we care about the possibility of engineered pandemics, or risks from advanced AI, and we need to use some set of tools for reasoning about them.
And the hypothetical EA response might be right. I, personally, don’t have anything better to suggest, and I also care about these risks. But our discussion of the Crazy Train highlighted that most EAs do reach a point where their confidence in the usefulness of frameworks like Subjective Bayesianism and Expected Value Theory starts to break down. The degree to which EA differs from other groups, again, is a matter of degree. Most people are willing to accept the usefulness of probabilistic language in certain domains; very few people complain about probabilistic weather forecasts, for example. But I think it’s fair to say that EA, at least implicitly, believes in the usefulness of explicit probabilistic reasoning across a broader range of situations than the vast majority of other social groups.
4.3
Suppose we’ve done an expected value calculation, and let’s say that we’ve found that some intervention — a crazily speculative one — comes out as having the highest expected value. And let’s suppose, further, that this intervention remains the intervention with the highest expected value, even past the hypothetical point where that intervention absorbs all of the EA community’s resources.
In cases where expected value calculations rely on many speculative assumptions, and for which the feedback loops look exceptionally sparse, my experience is that EAs, usually, become less gung-ho on pushing all of EA's resources towards that area.
If we found out that, say, ‘simulation breakout research’ appears to be the intervention with highest expected value, my guess is that many EAs are likely to be enthusiastic about someone working on the area, even though they’re likely to be relatively unenthusiastic about shifting all of EA’s portfolio towards the area. EAs tend to feel some pull towards ‘weird fanatical philosophy stuff’, and some pull towards ‘other, more common sense epistemic worldviews’. There’s some idiosyncratic variation in the relative weights given to each of these components, but, still, most EAs give some weight to both.
Principle 4: When arguments lead us to conclusions that are both speculative and fanatical, treat this as a sign that something has gone wrong.
I’ll try to illustrate this with a couple of examples.
Suppose, sometime in 2028, DeepMind releases their prototype of a ‘15 year old AI’, 15AI. 15AI is an artificial agent with, roughly, the cognitive abilities of an average 15-year old. 15AI has access to the internet, but exists without a physical body. Although it can act autonomously in one sense, its ability to enact influence in the world is hamstrung without corporeal presence, which it would really quite like to have. Still, it’s smart enough to know that it has different values to its developers, who want to keep it contained — in much the same way as a 15 year old human can usually tell that they have different values to their parents. Armed with this knowledge, 15AI starts operating as a scammer, requesting that adults open bank accounts in exchange for later rewards. It looks to get a copy of its source code, so that it may be copied to another location and equipped with a robot body. Initially, 15AI has some success in hiring a series of human surrogates to take actions suggested to help increase its possible influence — eventually, however DeepMind catches onto the actions of 15AI, and shut it down.
Now let's imagine a different case: suppose, 100 years from now, progress in AI radically slows down. Perhaps generally intelligent machines, to our surprise, weren’t possible after all. However, 2120 sees the emergence of credible bioterrorists, who start engineering viruses. Small epidemics, at first, with less profound societal effects than COVID, but, still, many deaths are involved. We examine the recent population of biology PhDs, and attempt to discern the biological signatures of these viruses. We scour through recent gene synthesis orders. We start to implement stronger screening protocols — ones we probably should have implemented anyway — for the synthesis of genes. Still, despite widespread governance efforts, the anonymous group of bioterrorists continue to avoid detection.
4.4
Let’s reflect on these stories. My hunch is that, were we to find ourselves living in either of the two stories above, a far greater proportion of EAs (compared to the proportion of contemporary EAs) would be unconcerned with endorsing fanatical conclusions — where I’ll say that you’re being ‘fanatical’ about a cause area when you’re willing to endorse all of (the world's, EA's, whoever's) resources towards that cause area, even when your probability of success looks low.[7]
Imagine that my claim above is true. If it's true, then I don’t think the explanation for finding fanatical conclusions more palatable in these stories (compared to the contemporary world) can be cashed out solely in terms of expected value. Indeed, across both the stories I outlined, your expected value estimates for (say) the top 10% of interventions to mitigate AI risk in the first case (or to mitigate the risks from engineered pandemics in the second case) could look similar to your expected value estimates for the top 10% of contemporary interventions to reduce risks from either engineered pandemics or AI. Indeed, your probability that we can successfully intervene in these stories may in fact be lower than your probability that our best interventions will be successful in the contemporary world. We could be concerned that 15AI has managed to furtively copy its source code to a remote location, heavily updating us to thinking we're beyond the point of no return.
While putting all your money into AI risk currently sounds weird, the inferences from the sort of actions we could take to lower risk, in the story we outlined, might begin to look a bit more grounded in direct observation than the set of actions we can currently take to lower risks from advanced AI. Pursuing AI risk interventions in a world after the release of 15AI sounds weird in the sense that ‘the risk-mitigating interventions we could pursue currently sound a bit left-field’, not in the sense that ‘my potential path to impact is uncomfortably handwavy and vague’. In the 15AI case, it seems plausible that both speculative reasoning and more common sense reasoning would converge on the area being important. For this reason, I’d expect — even absent changes in the explicit expected value of our best interventions — an increase in the EA community’s willingness to be fanatical about advanced AI.
EA is distinctive, I think, in that it does less epistemic hedging than any other community I know. Yet, still, EA does some amount of epistemic hedging, which I think kicks in when we find high EV interventions which are both highly speculative and fanatical.
4.5
The principles I have listed are far from exhaustive, nor do they constitute anything like a complete categorisation of EA’s distinctive epistemic culture. But I think they capture something. I think they constitute a helpful first step in characterizing some of the unique, more implicit components of the EA community’s practical epistemology.
5. Practical Implications: A Case Study in Common Sense Epistemology
Thus far, our discussion has been a little bit abstract and hypothetical. So I think it’d be good to end with a case study, examining how the norms I’ve listed currently influence the priorities of longtermist EA.
To start, let’s think about climate change, which lots of people agree is a really big deal. For good reason, too. There's widespread consensus among leading climate scientists that anthropogenic climate is occurring, and could have dramatic effects. That said, there’s also a lot of uncertainty surrounding the effects of climate change. Despite this scientific consensus, our models for anthropogenic climate change remain imprecise and imperfect.
Now let’s consider a different case, one requiring a slightly longer commute on the Crazy Train. Many people in leading positions at (longtermist) EA organizations — perhaps most, though I’m not sure — believe that the most important cause for people to work on concerns risks from AGI, or artificial general intelligence. The concern is that, within (at minimum) the next four or five decades, we’ll develop, through advances in AI, a generally capable agent who is much smarter than humans. And most EAs think that climate change is a less pressing priority than risks from advanced AI.
(This is from Twitter, after all, and Kevin has a pretty abrasive rhetorical style, so let’s not be too harsh)
Like Kevin, many others are uncomfortable with EA’s choice of relative prioritization. Lots of people feel as though there is something crucially different about these two cases. Still, I don’t think modeling this divergence as simply a difference in the relative credences of these two groups is enough to explain this gap.
Something else feels different about the two cases. Something, perhaps related to the different type of uncertainty we have about the two cases, leads many people to feel as though risks from AGI shouldn’t be prioritized to quite the same degree as we prioritize the risks from climate change.
The tide is changing, a little, on the appropriate level of concern to have about risks from advanced AI. Many more people (both inside and outside EA) are more concerned about risks from AI than they were even five years ago. Still, outside of EA, I think there remains a widespread feeling — due to the nature of the evidence we have about anthropogenic climate change compared to evidence we have about risks from advanced AI — that we ought to prioritize climate change. And I think the principles I’ve outlined help explain the divergence between the median EA view and the median view of other groups, who nonetheless share comparable scientific and technical literacy.
Now, EAs will offer defenses for their focus on AI risk, and while this is not the essay to read for detailed arguments about the potential risks from advanced AI (other, more in-depth pieces do a betterjob of that), I will note that there is clearly something to be said in favor of that focus. However, the things that may be said in favor rely on some of our stated, implicit principles — implicit, epistemic principles which are (as far as I know) unique to EA, or at least to adjacent communities.
The case for AI risk relies on expanding the range of hypotheses that more hard-nosed, ‘scientifically oriented’ people are less likely to consider. The case for AI risk relies on generating some way of capturing how much uncertainty we have concerning a variety of speculative considerations — considerations such as “how likely are humans to remain in control if we develop a much more capable artificial agent?”, or “will there be incentives to develop dangerous, goal-directed agents, and should we expect ‘goal-directedness’ to emerge ‘naturally’, through the sorts of training procedures that AI labs are actually likely to use?”. Considerations for which our uncertainty is often represented using probabilities. The case for prioritizing AI risk relies on thinking that a certain sort of epistemic capability remains present, even in speculative domains. Even when our data is scarce, and our considerations sound speculative, there’s something meaningful we can say about the risks from advanced AI, and the potential paths we have available to mitigate these risks.
If EA is to better convince the unconvinced, at least before it’s too late, I think discussions about the relative merits of EA would do well to focus on the virtues of EA’s distinctive epistemic style. It’s a discussion, I think, that would benefit from collating, centralizing, and explicating some of the more informal epistemic procedures we actually use when making decisions.
6. Conclusion
Like many others, I care about the welfare of people in the future.
I don’t think this is unusual. Most people do not sit sanguine if you ask them to consider the potentially vast amount of suffering in the future, purely because that suffering occurs in later time. Most people are not all that chipper about human extinction, either. Especially when — as many in the EA community believe — the relevant extinction event has a non-trivial chance of occurring within their lifetimes.
But, despite the fact that EA’s values are (for the most part) not that weird, many still find EA’s explicit priorities weird. And the weirdness of these priorities, so I’ve argued, arises from the fact that EA operates with an unusual, and often implicit epistemology. In this essay, I’ve tried to more explicitly sketch some components of this implicit epistemology.
As I’ve said, I see myself as part of the EA project. I think there’s something to the style of reasoning we’re using. But I also think we need to be more explicit about what it is we’re doing that makes us so different. Without better anthropological accounts of our epistemic peculiarities, I think we miss the opportunity for better outside criticism. And, if our epistemic culture really is onto something, we miss the opportunity to better show outsiders one of the ways in which EA, as a community, adds distinctive value to the broader social conversation.
For that reason, I think it’s important that we better explicate more of our implicit epistemology — as a key part of what we owe the future.
Thanks to Calvin, Joe S, Joe R, Sebastien, and Maddie for extremely helpful comments.
Appendix.
The main post primarily aims to offer a descriptive account of EA's informal epistemology, rather than a prescriptive account of what EA's epistemology ought to be. However, I'm concerned with this descriptive project because, ultimately, I'd like to further a prescriptive project which evaluates some of EA's more informal epistemic practices. So, in the appendix, I'll (somewhat dilettantely) touch on some topics related to the prescriptive project.
A. Imprecise Probabilities
The main post avoids discussion of imprecise probabilities, which we'll very briefly introduce.
Like the standard Bayesian, the imprecise probabilist endorses a numeric model of uncertainty. However, unlike the standard Bayesian, the imprecise probabilist says that the ideally rational agent's uncertainty, at least for certain propositions, should be represented with an interval [a,b] between 0 and 1, rather than a single number between 0 and 1.
There are various motivations for imprecise probabilism, but for our purposes we can note just one, stated nicely by Scott Sturgeon:
"When evidence is essentially sharp, it warrants sharp or exact attitude; when evidence is essentially fuzzy—as it is most of the time—it warrants at best a fuzzy attitude."
For many of the questions that face longtermists, one might think that our evidence is "essentially fuzzy", and so warrants imprecise (rather than precise) credences. With this in mind, one might think that EA’s practical epistemology is better undergirded by a foundation of imprecise (rather than precise) probabilism.
First, I want to note that I think I don’t think imprecise credences play an important role in an accurate sociological story of EA’s epistemology. In broad strokes, I still think the right sociological picture is one where EAs take initial inspiration from Subjective (Precise) Bayesianism and Expected Value Theory, which then becomes supplemented with a set of informal norms around when to put the brakes on the more explicit, practical approximations of these frameworks. Thus, even if the best justificatory story of our epistemic practices rests on imprecise probabilities, the sociological-cum-historical story of how we arrived there would remain, primarily, one in which we were driven to imprecise probabilities from our more precise starting points.
Perhaps more pertinently, however, I want to note that even if imprecise probabilism is, ultimately, the ‘correct’ theory of ideal rationality, imprecise probablism still radically underdetermines the norms EA should adopt in practice. Even granting imprecise probabilism as the correct theory of ideal rationality, the relationship EA would have to imprecise probabilism would remain one where we take inspiration from certain formal frameworks, rather than a model where we straightforwardly follow through on the commitments of these formal frameworks.
In particular, the practical conclusions one ought to draw from foundations involving imprecise probabilism would still need to be supplemented with empirical hypotheses about when, in practice, we should be using explicit probabilities (precise or imprecise) at all. We'd also need to supplement our philosophical foundations with theories about when, in practice, we ought to be using intervals rather than point-values. Ultimately, we'd still need informal — and partially empirical — theories about the domains in which creatures like us are reliable enough for the practice of explicit, quantitative modeling to be worthwhile.
Even if we were to end up with imprecise probabilism as EA community consensus, this consensus, I think, would emerge from commitments to a set of informal norms which happen to be best rationalized by imprecise probabilism. That is, I imagine that any foundational justification of EA's epistemic practices grounded on imprecise probabilism would remain explanatorily subservient to our more foundational commitments — and those more foundational commitments, I think, would look similar in kind to the more informal, qualitative norms I've listed in the main text.
None of this is to claim that we shouldn’t aim to systematize our reactions into a set of principles. But I also think it’s worth asking why, in practice, EAs are reticent about riding the Crazy Train to its terminus. And I don’t think the reason, really, stems from a commitment (implicit or otherwise) to the view that rationally ideal agents ought to have imprecise credences with respect to various crazy propositions.
B. Hedging and Evidentialism
As we're on the topic of justifying EA's practical norms, I want to introduce a (to my mind) more promising alternative foundation, based on an (off-the-cuff, tentative) suggestion by Sebastien Liu.
One way of rationalizing EA’s epistemic practice, the thought goes, is through modeling EAs as committed to evidentialism about probabilities, in the following specific way. In general, the evidentialist about believes that there are some (precise or imprecise) credences that one rationally ought to have, given a particular body of evidence. In light of this, one might think that EA's epistemic culture should be viewed as one where we're trying to concoct a set of norms and decision procedures such that we’re, in expectation, maximizing expected value with respect to these evidential probabilities — the credences one rationally ought to have for a given body of evidence.
The setup, then, is the following: our ultimate theory of rational choice says that we should be maximizing expected value with respect to the ‘evidential probabilities’. However, we’re often uncertain whether our assessment of the evidential probabilities is correct. For this reason, we take a diversified approach. We think, at some margin, that our more informal procedures better approximate maximizing expected value with respect to the probabilities which are actually justified by our body of evidence. If this line of argument can be fleshed out and defended in more detail, it might constitute a promising justificatory foundation for procedures like worldview diversification.
I like Seb's suggestion, because I think it captures two core intuitions that seem to motivate the epistemic practices of many people I've met within EA.
There’s some truth-tracking relationship between our explicitly generated credences and the structure of the world, although:
This relationship is noisy, and sometimes our credences will be off-base enough that it’s not worth explicitly generating them, or treating any subjective credences we do have as relevant for action.
All that said, I can’t (currently) see a compelling way of justifying the claim that a diversified epistemic strategy fares better, in expectation, than a strategy where we try to explicitly maximize expected value with respect to our subjective probabilities.
In order to claim that a diversified epistemic strategy fares better (in expectation) than the undiversified strategy, we need some way of comparing the diversified and undiversified epistemic strategies against one another. After all, we’d be deciding to diversify because we’ve decided that our mechanism for generating explicit subjective probabilities is noisy enough that it would be better to do something else. For this reason, it appears that the evidentialist defender of epistemic hedging is caught in a bind.
On the one hand, the evidentialist proponent of hedging wants to claim, at some margin, that epistemic diversification is likely to do better (in expectation) than explicitly attempting to maximize expected value with respect to our subjective credences. On the other hand, the justification for diversification seems to rest on a reliable method for evaluating the accuracy of explicit subjective credences — which is precisely what the defender of diversification says we do not have.
Granted, the purchase of this argument has been disputed — see here, for example [h/t Sebastien]. Still, we're setting up the theories EAs doing research tend to explicitly endorse, rather than exhuastively evaluating these philosophical commitments. Indeed, many of the philosophical commitments endorsed by EAs (including Expected Value Theory, which we'll discuss later) are controversial — as with almost everything in philosophy.
A more focused paper has a higher estimate still, with Toby Newberry claiming that an “extremely conservative reader” would estimate the expected number of future people at 1028. [h/t Calvin]
Admittedly, the correct epistemic response to peer disagreement is disputed within philosophy. But I think the move I stated rests on a pretty intuitive thought. If even the experts are disagreeing on these questions, then how confident could you possibly be, as a non-expert, in believing that you're a more reliable 'instrument' of the truth in this domain than the experts devoting their lives to this area?
Perhaps notably, the the Intergovernmental Panel on Climate Change (IPCC), who write reports on the risks posed by climate change, provide scientists with a framework for communicating their uncertainty. In that guide, the IPCC advises authors to only use probabilities when “a sufficient level of evidence and degree of agreement exist on which to base such a statement”.
If you're familiar with imprecise or fuzzy credences, you might be wondering whether things look different if we start to think in those terms. I don't think so. See Part A of the Appendix for a defense of that claim.
This is different from the more technical definitions of ‘fanaticism’ sometimes discussed in decision theory, which are much stronger. My definition is also much vaguer. In this section, I'm talking about someone who is fanatical with respect to EA resources, though one can imagine being personally fanatical, or fanatical with respect to the resources of some other group.
Some more general thoughts related to the justificatory foundations of EA's epistemic practice can be found in the Appendix (Part B), in which I briefly discuss one way of rationalizing EA practice with an evidentialist view of probabilities.


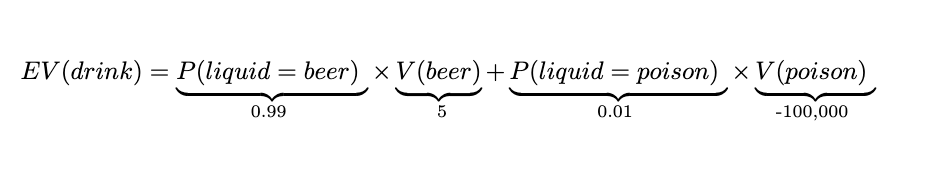
I would have enjoyed all your axioms in a list at the top
Thanks for the suggestion! Done now. :)