Comments
The Worldview Investigations Team at Rethink Priorities is in the process of building a model to estimate the probabilities of consciousness in near-future AIs. We are still in the early stages of constructing our model and expect some of the details to change as others get filled in. The following is intended to convey our perspective as we start fleshing out the scaffold of our model.
Why do we want to investigate AI consciousness?
Consciousness in contemporary or near-future AI systems is becoming a matter of practical concern. It’s widely thought that, if AI systems were conscious, they would deserve some moral consideration, and the fortunes of AI labs may be influenced by their perceived moral, social, and legal liabilities. The success of the policies and procedures that aim to mitigate harm to AI systems depends on how well the labs and the public understand the issues and the threats.
Some of the most influential AI researchers and philosophers have voiced concerns that current or near-future systems may be capable of conscious experiences. These experts seem moved principally by the flexible intelligence, representational capacities, and linguistic competence of cutting-edge AI models, but the specific grounds of consciousness in humans, animals, and digital systems remain obscure and controversial. Experts have not identified precise criteria for attributing consciousness that can be straightforwardly applied to computer systems.
We believe that it is important to distill expert opinion into a current consensus about digital consciousness, even if that consensus is one of uncertainty, in order to understand better both what AI labs, policymakers, and the public should think about digital consciousness and where further research is most needed.
Why do we want a model that provides probabilities?
Expert opinion is presently divided across a bewildering variety of views about the nature of consciousness (Seth & Bayne 2022), many of which preclude consciousness from digital systems altogether and others that attribute it only to systems with specific architectures. This variety makes it especially challenging to make all-things-considered judgements about the probability of consciousness. Practical necessity requires making decisions despite our uncertainty and it would be a mistake to ignore the experts altogether or cherry-pick from among the most well-developed theories or most vocal academics.
We believe the points of agreement and disagreement should both be represented within a model. By incorporating diverse opinions within a model, it is possible to adjust the allocations of weight to different factors. This allows us to see the upshots of taking different ideas seriously. It also makes it possible to see which future developments might make the biggest difference.
We also believe that it is important that the model produces estimates of the probabilities of consciousness. Probabilities help us manage the risks of under- and over-attributing consciousness; at the same time, they can be useful insofar as we want to set thresholds for implementing precautionary measures.
A model that produces probabilities improves the transparency of disagreements. It represents a specific stance on which sources of evidence matter and how they matter. Creating such a target for criticism is itself a valuable contribution, as making the choices required by any model allows others to articulate where improvements are necessary. So, any probabilistic model of AI consciousness today is best seen as a prototype that facilitates clearer and more principled discussions about this important question.
Who is our model for?
Any impact of the digital consciousness model must go through people who make decisions about policy. We want this to be useful to policy-makers working at AI labs, but also to a variety of outsiders who may have leverage over public opinion or the possible moral standing of AI systems. Since many of these people do (or should) not have strong commitments about the nature of consciousness, we see much of the value of the model as helping them navigate the complicated fields that are relevant here, including consciousness science, computer science, and philosophy. So, the model is designed to be accessible and to incorporate a wide range of reasonable opinions without sacrificing the validity of its results.
Second, our model is for consciousness researchers. While our model isn’t aimed at advancing new theories, we think that it will also be informative to them. There is important work to be done before we can clarify the upshots of standard views about consciousness. By representing current opinion for this purpose, we both help uncover how we might think about these issues and provide a target for experts to object to or refine their views in light of their findings.
Before describing our approach to modeling the probability of digital consciousness, we’ll outline some of the desiderata by which we will judge it. We have already discussed a few basic features we want the model to have: being helpful to people without existing commitments, being flexible, and producing probabilities. This section further refines our goal and explains why we make the choices we do.
It can handle both theoretical requirements and generally compelling considerations
To capture the actual opinions of consciousness researchers, we need to be able to include both elements of theories and considerations that are theory-independent. Theories represent the best complete picture of what consciousness might be, but the fact that experts also find other considerations compelling suggests that the theories alone might fail to capture our evidential base. (For instance, general intelligence is only tenuously related to consciousness on most views, but is widely treated as a significant indicator of consciousness.) We want a system that can accommodate both kinds of evidence seamlessly.
It can easily include a variety of opinions
We are deeply uncertain about which theories of consciousness are right. Insofar as we think all popular theories deserve some degree of respect, we want the probabilities that our model outputs to be sensitive to the priorities of each reasonable viewpoint. Even theories that are fairly well-defined can be developed in a number of different ways. For instance, many existing theories of consciousness can be developed in a purely computationalist fashion or can be made to require a biological substrate. Once we allow that variations of a theory amount to relevantly different perspectives, we see a need to include numerous theoretical and extra-theoretical perspectives within the model.
It makes it easy to expand, modify, reconfigure, and reweight the model
In order to be useful, the model will likely need to incorporate new evidence from updated AI systems and new research into what existing systems can do. It will also need to be able to provide insight to people with different inclinations. While we want to reflect the balance of expert opinion, legitimate disagreements exist regarding what experts believe, who the experts are, and what views are worth taking seriously. The model shouldn’t enforce a limited set of perspectives, or just the perspectives of its designers. It shouldn’t be tied to the details of a few specific stances but be generally able to accommodate all reasonable views.
It isn’t fundamentally tied to very controversial assumptions
We don’t want the model to reflect a biased perspective. Therefore, we would rather limit the number of decisions we need to make in representing perspectives. The more precisely we interpret theories, the more space there is to make a fatal decision that undermines the value of the model entirely in some people’s eyes. We’d rather aim for rough verisimilitude than exact precision, and that requires minimizing the contestable assumptions we make.
It is compatible with patchy or disparate data
We expect that the evidence we have for various features will vary from AI system to AI system. While some tests are easy to employ over many different AI systems, some require fine-tuning or having access to their weights. We will depend on those AI systems to which researchers have actually applied their tests. Furthermore, if we want to assess AI systems of different sorts, the kinds of indicators we find might look very different and need to be tailored to the affordances of each AI system. We would like our model to produce reasonable probabilities despite these significant differences in evidence for different (kinds of) systems. Ideally, our approach is consistent with application to animal species as well, so we can check the products of our model against our intuitions about different animals. Since the kinds of tests we can run on animals look quite different, we need the model to be capable of producing verdicts from overlapping evidential bases.
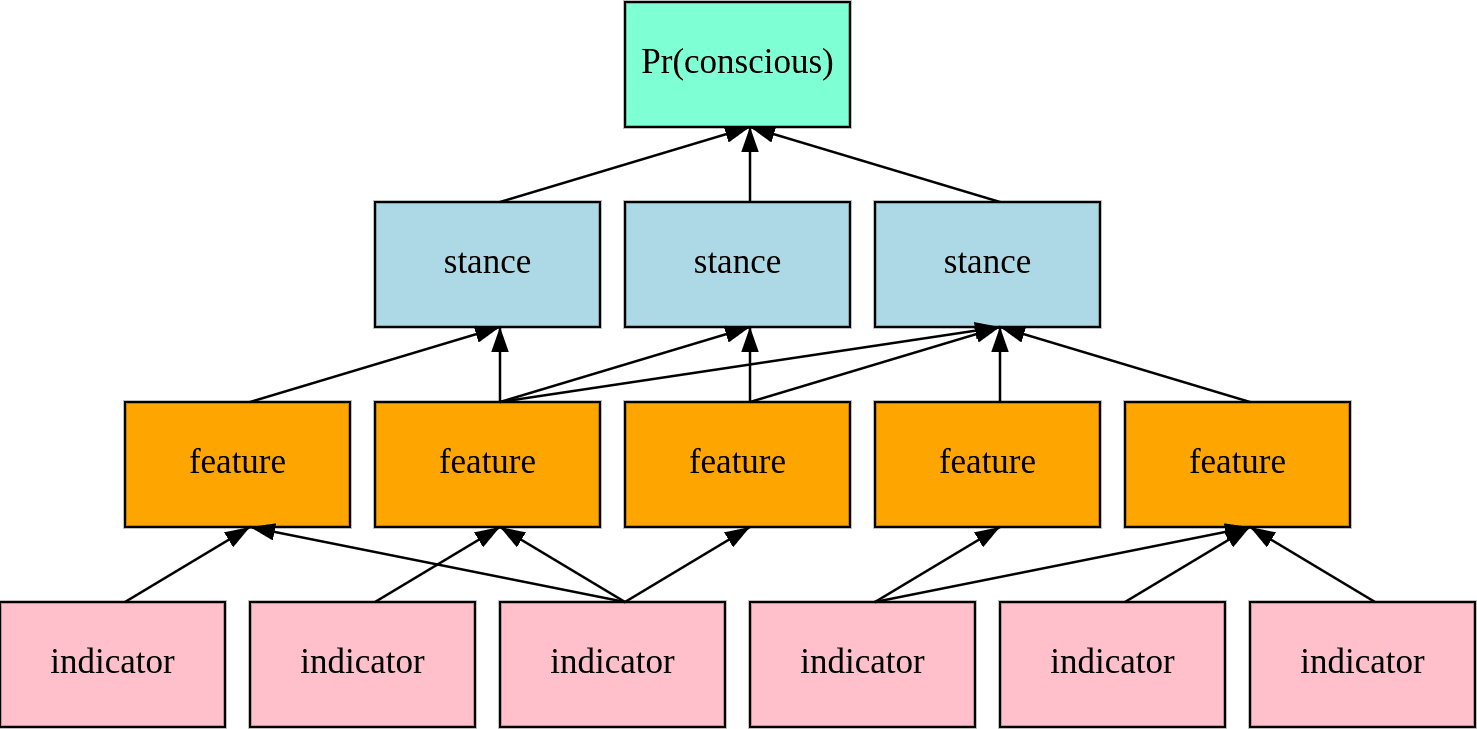
We are presently working on a model that combines three decisions:
In our model, we include a breadth of views about the evidential significance of the traits that systems have (or lack). This includes both formal theories of consciousness like the global workspace theory and general non-theoretical outlooks on evidence for consciousness. We call each view a stance. We formalize stances by associating them with certain key features of systems.
Features consist of general capacities of a somewhat abstract and conceptually familiar sort. Episodic memory and top-down attention, for instance, are examples of features. For each stance, we categorize each associated feature in terms of its importance to the stance.
Finally, to examine the probability or degree of each feature’s presence, we propose a number of possible indicators, aspects of a system that are testable (today or with dedicated effort in the near future) and more directly accessible or objectively verifiable. For instance, the ability to count the tokens in a given string of text might be an indicator of a form of introspection (Laine et al. 2024), insofar as the only way for a model to succeed reliably is to look back at how many times it was applied.
The model derives probabilities of consciousness by dividing credences over the stances, by assessing the bearing of features on stances and indicators (or possibly other features) on features, and through data on the indicators.
We are not the first to advocate for a probabilistic approach to assessing consciousness. Several prominent recent papers (Chalmers 2023; Long, et al. 2024; Sebo and Long 2023) have argued that there is a non-negligible probability that AI systems are (or will soon be) conscious, and therefore that we ought to begin to prepare for the possible moral consideration of those systems. Developing models of AI consciousness like the one we have proposed here is one important part of such preparations.
To establish that the probability is high enough to warrant further consideration, some of these authors (Chalmers 2023; Sebo and Long 2023) have suggested the following methodology. A potential barrier to AI consciousness is a feature, F, that is necessary for consciousness and which AIs lack. The probability that F is a barrier is the probability that F is necessary times the probability that AIs lack F. For example, if you think there’s a 0.25 chance that biology is necessary for consciousness and are certain that AIs are non-biological, then the probability that biology is a barrier is 0.25. Each potential barrier reduces the probability that AIs are conscious. If you think biology has a 0.25 chance of being a barrier, your credence in AI consciousness should be no higher than 0.75. If we continue to multiply by the chance of each potential barrier, we arrive at a rough, first-pass estimation of the probability that there’s nothing standing in the way of AI consciousness.
While helpful as a back-of-the-envelope calculation, this methodology has several limitations. First, there are many features that might be evidentially relevant for consciousness without being strictly necessary (or sufficient). This will be especially important for features that come in degrees, such as complexity or temporal integration. Second, the probability that nothing obviously stands in the way of consciousness is not necessarily the same as the probability that some AI is conscious. Our methodology should also consider positive indicators that raise the probability of consciousness. Third, we want a way of tracking correlations among features.
The marker method (Birch 2022; Birch et al. 2021) is another prominent approach to assessing whether we have enough evidence of sentience to warrant precautionary measures. It looks for features that correlate with conscious experience in humans that are taken as positive indicators of consciousness. It does not purport to deliver a probability of consciousness, only reporting the strength of the positive evidence for it. Another limitation is that it does not straightforwardly incorporate negative indicators that would serve as evidence against consciousness (Andrews 2024).
Our model is broadly Bayesian. Features raise or lower the probability of consciousness via their likelihoods: for any given stance, how much would we expect to see these features in a system if the system is conscious versus unconscious? Indicators raise or lower the probability of features in the same fashion: if we assume the feature is present (or absent), what does that tell us about the probability of the indicator? Bayesian probability theory makes it easy to update on new evidence in light of such likelihoods.
Bayesian approaches have several appealing properties: they can straightforwardly capture evidence of different strengths; they can handle cases where evidence is missing without counting this as evidence for or against consciousness; and they allow us to incorporate prior probabilities. It might also be extended into a formal hierarchical Bayesian approach that allows evidence to flow in both directions up and down the hierarchy.
There are many things that we might take as evidence for digital consciousness. We see promise in an approach that focuses on the general factors that theorists find compelling. That is, we try, insofar as possible, to avoid explicitly incorporating the many controversial specifications of the factors that might be thought to be necessary or sufficient conditions for consciousness according to different formal theories. Our preferred version focuses on two sources: first, we identify themes in the formulations of different popular theories of consciousness. Second, we identify themes in the considerations that seem to sway both theorists and non-theorists, explicitly or implicitly, that don’t fall directly into theories of necessary and sufficient conditions. We then assess systems for the extent to which their features match those themes. Very roughly, the more numerous and more relevant the features a system satisfies for a given stance, and the higher the degree to which it does so, the more likely we should think it is to be conscious according to that stance.
Within the hierarchical structure described above, we must choose a variety of combinations of theoretical themes and compelling considerations to populate our stances. We might have a purely algorithmic global workspace stance and a biological-homology-based global workspace stance that only sees consciousness in global workspaces instituted in neural structures like those in the human brain. We might have a vague general-intelligence-focused stance and a stance requiring lifestyles like ours (embodiment, agency, sensory processing, etc.). We can freely combine elements to produce stances matching what we expect the range of opinions of a full population of consciousness experts would look like.
In choosing themes and identifying matching features, we favor coarse-grained gradational definitions that capture the conceptual spirit of the view. Doing this means that we must overlook some of the claims made by individual theories about the precise details of a system. We think that this is advantageous, as we think the general themes currently have far better support than their particularities. Our goal is to rate minds on a collection of architectural choices and cognitive capacities, to understand different views in terms of the weight each puts on different choices and capacities, and to derive probabilities from their combination.
Here is an example of how we might draw themes from the global workspace theory and evaluate systems based on respect for that view. Global workspace theory (Baars 2005) postulates that human consciousness depends upon a centralized information repository in our brains that filters the information it receives and broadcasts that information back out to diverse peripheral modules. Presence within that repository renders representations conscious. It explains why we remember such representations, why we’re able to flexibly draw inferences from them, and use them to guide our behavior in novel ways.
Looking for a global workspace in a system entails identifying and exploring specific connections between modules (Butlin et al. 2023; Goldstein & Kirk-Giannini 2024). This requires making choices about what kinds of modules are necessary (Carruthers 2019), the extent to which the repository makes information globally available, and so on. Global workspace theories, despite their popularity, have seldom been formulated in sufficient depth to make this process straightforward.
In a thematic approach, we aren’t looking for a yes-or-no verdict about a specific architecture, but the extent to which the thematic ideas are implemented. Global workspace theory can be viewed as highlighting the importance of: representational content; functional modularity; the refinement of a perspective through the interaction of different specialist subsystems; enforcing coherence and unity in special representational contents; widespread information distribution; information bottlenecking; and selective attention. Instead of looking for a global workspace that meets some exact schematic, a thematic approach attempts to separately measure these thematic features and aggregate them into an overall weighted score. To the extent that some features are well-represented, the relative absence of others may not be decisive.
Drawing on themes allows us to stay tethered to expert opinion without committing to the current, controversial formulation of existing views. We expect theories to evolve over time and hope that this approach will prove more tolerant of such changes. While our thematic approach limits the precision in applying expert opinion, we think that it makes up for this deficit by abstracting the factors that are most widely thought to be evidentially relevant to consciousness.
We think these three choices lead to a model that can nicely satisfy our desiderata.
It can handle both theoretical requirements and compelling considerations
We interpret stances as views about the bearing of features on probabilities of consciousness. This can include theories that precisely define which features are necessary or sufficient for consciousness, but it can also include takes on what kinds of capacities are indicative of consciousness. Moreover, it can easily handle mixtures of the two, such as taking a global workspace to be evidence for consciousness only when coupled with a biological substrate or a high level of general intelligence.
It can easily include a variety of opinions
With the right mixture of stances and features, we expect to be able to represent all major opinions within one model. We can easily include numerous variations of a stance by adding, subtracting, or reweighting its features.
It makes it easy to expand, modify, reconfigure, and reweight
We see features as general kinds of capacities that can easily be grouped into separate theories. Instead of tailoring features to specific theories, our coarse-graining thematic approach (described above) aims to distill a general kind for each feature which might be incorporated into a variety of views. For example, attentional capacities play an important role in a number of different theories. Rather than having a separate interpretation of attention customized to its role in each theory, we may have one general notion of attention that we can plug into a variety of stances.
Furthermore, having indicators’ influence be filtered through features provides some degree of encapsulation. If indicators only provide evidence for theories by supporting features and we have sufficient evidence for the presence of a feature, further evidence doesn’t make a difference.
It isn’t tied to very controversial assumptions
Focusing on giving sufficient weight to a wide diversity of stances will help to prevent us from being tied to specific controversial assumptions. Furthermore, by coarse-graining the features we’re looking for, we opt to represent general families of views rather than very specific views. This allows us to avoid staking out firm commitments on the proper interpretation of theories.
It is compatible with patchy or disparate data
We are optimistic that the use of Bayesian methods for incorporating information about indicators – updating on the presence or absence of an indicator based on its likelihood – will allow us to compare systems with very different bodies of evidence.

This post was written by Rethink Priorities' Worldview Investigations Team. Rethink Priorities is a global priority think-and-do tank aiming to do good at scale. We research and implement pressing opportunities to make the world better. We act upon these opportunities by developing and implementing strategies, projects, and solutions to key issues. We do this work in close partnership with foundations and impact-focused non-profits or other entities. If you're interested in Rethink Priorities' work, please consider subscribing to our newsletter. You can explore our completed public work here.
Andrews, K. (2024). “All animals are conscious”: Shifting the null hypothesis in consciousness science. Mind & Language.
Baars, B. J. (2005). Global workspace theory of consciousness: toward a cognitive neuroscience of human experience. Progress in Brain Research, 150, 45-53.
Birch, J. (2022). The search for invertebrate consciousness. Noûs, 56(1), 133-153.
Birch, J., Burn, C., Schnell, A., Browning, H., & Crump, A. (2021). Review of the evidence of sentience in cephalopod molluscs and decapod crustaceans.
Butlin, P., Long, R., Elmoznino, E., Bengio, Y., Birch, J., Constant, A., ... & VanRullen, R. (2023). Consciousness in artificial intelligence: insights from the science of consciousness. arXiv preprint arXiv:2308.08708.
Carruthers, P. (2019). Human and animal minds: The consciousness questions laid to rest. Oxford University Press.
Chalmers, D. J. (2023). Could a large language model be conscious?. arXiv preprint arXiv:2303.07103.
Goldstein, S., & Kirk-Giannini, C. D. (2024). A case for AI consciousness: Language agents and global workspace theory. arXiv preprint arXiv:2410.11407.
Laine, R., Chughtai, B., Betley, J., Hariharan, K., Scheurer, J., Balesni, M., ... & Evans, O. (2024). Me, myself, and AI: The situational awareness dataset (SAD) for LLMs. arXiv preprint arXiv:2407.04694.
Long, R., Sebo, J., Butlin, P., Finlinson, K., Fish, K., Harding, J., ... & Chalmers, D. (2024). Taking AI welfare seriously. arXiv preprint arXiv:2411.00986.
Sebo, J., & Long, R. (2023). Moral consideration for AI systems by 2030. AI and Ethics, 1-16.
Seth, A. K., & Bayne, T. (2022). Theories of consciousness. Nature Reviews Neuroscience, 23(7), 439-452.



Executive summary: Rethink Priorities is developing a hierarchical Bayesian model to estimate consciousness probabilities in near-future AI systems, aiming to incorporate diverse expert views and provide practical guidance for policy decisions.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.