Comments
This is cool, thanks!
One scenario I am thinking about is how to prioritise biorisk interventions, if you care about both x-risk and non-x-risk impacts. I'm going to run through some thinking, and ask if you think it makes sense:
- I think it is hard (but not impossible) to compare between x-risk and non-x-risk impacts
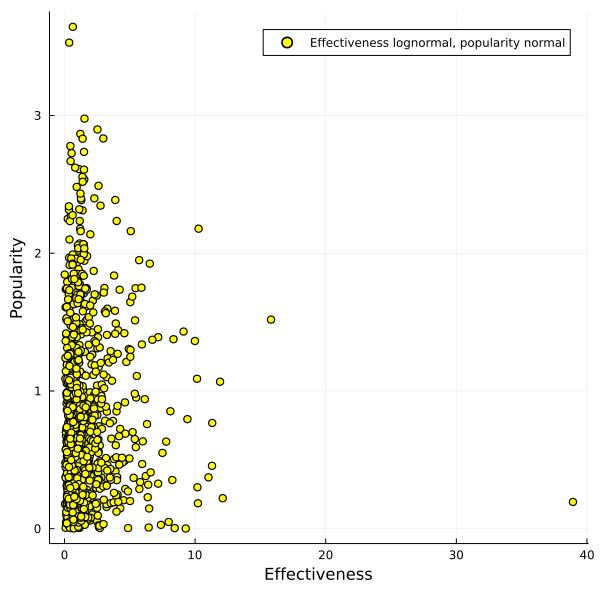
- I intuitively think that x-risk and non-x-risk impacts are likely to be lognormally distributed (but this might be wrong)
- This seems to suggest that if I want to do the most good, I should max out on on one, even if I care about both equally. I think the intuition for this is something like:
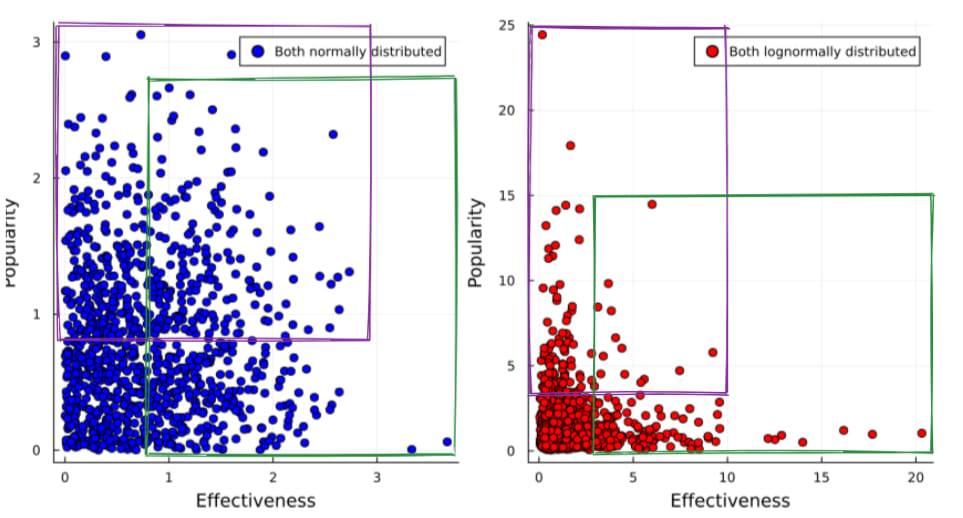
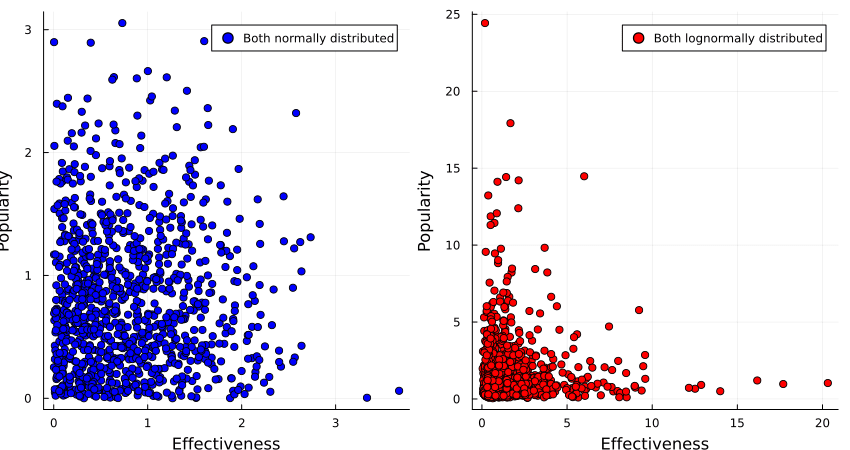
- If x-risk and non-x-risk impacts were normally distributed, you'd expect that there are plenty of interventions which score well on both. The EV for both is reasonably smoothly distributed; it's not very unlikely to draw something which is between 50th and 75th percentile on both, and that's pretty good EV wise.
- But if they are log normal instead, the EV is quite skewed: the best interventions for x-risk and for non-x-risk impacts are a lot better than the next-best. But it's statistically very unlikely that the 99th percentile on one axis is also the 99th on the other
- If I care about EV, but not about whether I get it via x-risk or non-x-risk impacts (I care equally about x-risk and non-x-risk impacts), I should therefore pick the very best interventions on either axis, rather than trying to compromise between them
- However, I think that assumes that I know how to identify the very best interventions on one or both axes
- Actually I expect it to be quite hard to tell whether an intervention is 70th or 99th percentile for x-risk/non-x-risk impacts
- What should I do, given that I don't know how to identify the very best interventions along either axis?
- If I max out, I may end up doing something which is mediocre on one axis, and totally irrelevant on the other
- If I instead go for the best of both worlds, it seems intuitively more likely that I end up with something which is mediocre on both axes - which is a bit better than mediocre on one and irrelevant on the other
- So maybe I should go for the best of both worlds in any case?
What do you think? I'm not sure if that reasoning follows/if I've applied the lessons from your post in a sensible way.



@Lucius Caviola and I discuss such issues in Chapter 9 of our recent book. If I understand your argument correctly I think our suggested solution (splitting donations between a highly effective charity and the originally preferred "favourite" charity) amounts to what you call a barbell strategy.
Huh, the convergent lines of thought are pretty cool!
Your suggested solution is indeed what I'm also gesturing towards. A "barbell strategy" works best if we only have few dimensions we don't want to make comparable, I think.
(AFAIU It grows only linearly, but we still want to perform some sampling of the top options to avoid the winners curse?)