Say that we have a set of options, such as (for example) wild animal welfare interventions.
Say also that you have two axes along which you can score those interventions: popularity (how much people will like your intervention) and effectiveness (how much the intervention actually helps wild animals).
Assume that we (for some reason) can't convert between and compare those two properties.
Should you then pick an intervention that is a compromise on the two axes—that is, it scores decently well on both—or should you max out on a particular axis?
One thing you might consider is the distribution of options along those two axes: the distribution of interventions can be normal on for both popularity and effectiveness, or the underlying distribution could be lognormal for both axes, or they could be mixed (e.g. normal for popularity, and lognormal for effectiveness).
Intuitively, the distributions seem like they affect the kinds of tradeoffs we can make, how could we possibly figure out how?
…
…
…

It turns out that if both properties are normally distributed, one gets a fairly large Pareto frontier, with a convex set of options, while if the two properties are lognormally distributed, one gets a concave set of options.
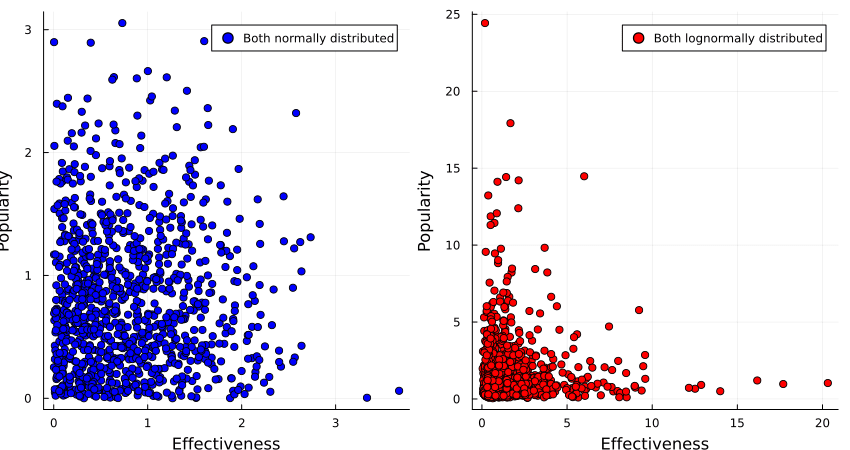
(Code here.)
So if we believe that the interventions are normally distributed around popularity and effectiveness, we would be justified in opting for an intervention that gets us the best of both worlds, such as sterilising stray dogs or finding less painful rodenticides.
If we, however, believe that popularity and effectiveness are lognormally distributed, we instead want to go in hard on only one of those, such as buying brazilian beef that leads to Amazonian rainforest being destroyed, or writing a book of poetic short stories that detail the harsh life of wild animals.
What if popularity of interventions is normally distributed, but effectiveness is lognormally distributed?
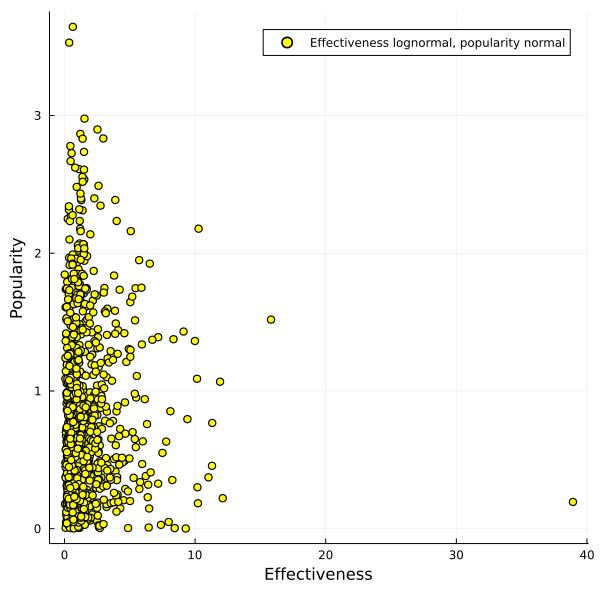
In that case you get a pretty large Pareto frontier which almost looks linear to me, and it's not clear anymore that one can't get a good trade-off between the two options.
So if you believe that heavy tails dominate with the things you care about, on multiple dimensions, you might consider taking a barbell strategy and taking one or multiple options that each max out on a particular axis.
If you have thin tails, however, taking a concave disposition towards your available options can give you most of the value you want.
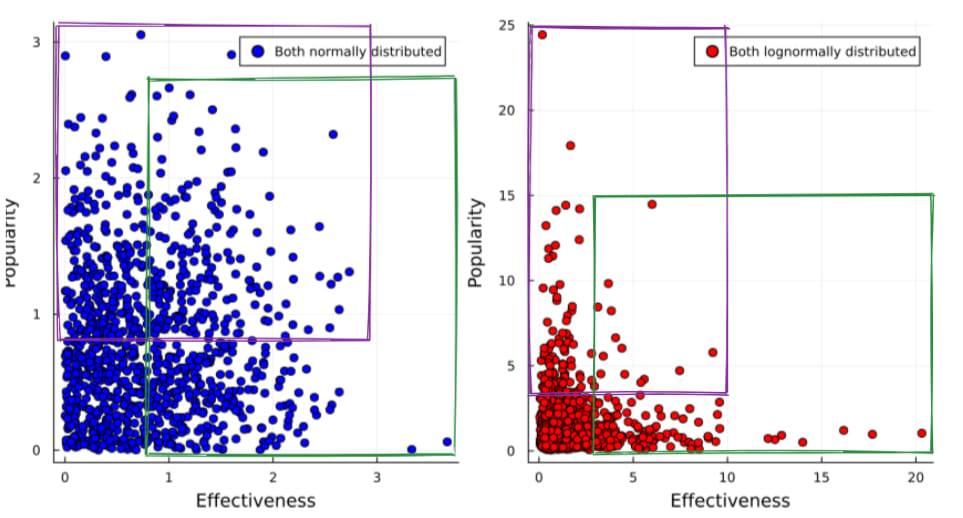



Huh, the convergent lines of thought are pretty cool!
Your suggested solution is indeed what I'm also gesturing towards. A "barbell strategy" works best if we only have few dimensions we don't want to make comparable, I think.
(AFAIU It grows only linearly, but we still want to perform some sampling of the top options to avoid the winners curse?)