This is a special post for quick takes by Erich_Grunewald 🔸. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Comment Permalink
Would it be feasible/useful to accelerate the adoption of hornless ("naturally polled") cattle, to remove the need for painful dehorning?
There are around 88M farmed cattle in the US at any point in time, and I'm guessing about an OOM more globally. These cattle are for various reasons frequently dehorned -- about 80% of dairy calves and 25% of beef cattle are dehorned annually in the US, meaning roughly 13-14M procedures.
Dehorning is often done without anaesthesia or painkillers and is likely extremely painful, both immediately and for some time afterwards. Cattle horns are filled with blood vessels and nerves, so it's not like cutting nails. It might feel something like having your teeth amputated at the root.
Some breeds of cows are "naturally polled", meaning they don't grow horns. There have been efforts to develop hornless cattle via selective breeding, and some breeds (e.g., Angus) are entirely hornless. So there is already some incentive to move towards hornless cattle, but probably a weak incentive as dehorning is pretty cheap and infrequent. In cattle, there's a gene that regulates horn growth, with the hornless allele being dominant. So you can gene edit cattle to be naturally hornless. This seems to be an area of active research (e.g.).
So now I'm wondering, are there ways of speeding up the adoption of hornless cattle? If all US cattle were hornless, >10M of these painful procedures would be avoided annually. For example, perhaps you could fund relevant gene editing research, advocate to remove regulatory hurdles, or incentivize farmers to adopt hornless cattle breeds? Caveat: I only thought and read about all this for 15 minutes.
More recent data for US beef cattle (APHIS USDA, 2017, p.iii):
Only 7.8 percent of calves born or expected to be born in 2017 had horns, indicating the widespread use of polled breeds. For horned calves that were dehorned, the average age at dehorning was 107.0 days.
Thanks, that’s encouraging! To clarify, my understanding is that beef cattle are naturally polled much more frequently than dairy cattle, since selectively breeding dairy cattle to be hornless affects dairy production negatively. If I understand correctly, that’s because the horn growing gene is close to genes important for dairy production. And that (the hornless dairy cow problem) seems to be what people are trying to solve with gene editing.
How many EAs are vegan/vegetarian? Based on the 2022 ACX survey, and assuming my calculations are correct, people who identify as EA are about 40% vegan/vegetarian, and about 70% veg-leaning (i.e., vegan, vegetarian, or trying to eat less meat and/or offsetting meat-eating for moral reasons). For comparison, about 8% of non-EA ACX readers are vegan/vegetarian, and about 30% of non-EA ACX readers are veg-leaning.
(That's conditioning on identifying as an LW rationalist, since anecdotally I think being vegan/vegetarian is somewhat less common among Bay Area EAs, and the ACX sample is likely to skew pretty heavily rationalist, but the results are not that different if you don't condition. Take with a grain of salt in general as there are likely strong selection effects in the ACX survey data.)
Here's what I usually try when I want to get the full text of an academic paper:
- Search Sci-Hub. Give it the DOI (e.g.
https://doi.org/...) and then, if that doesn't work, give it a link to the paper's page at an academic journal (e.g.https://www.sciencedirect.com/science...). - Search Google Scholar. I can often just search the paper's name, and if I find it, there may be a link to the full paper (HTML or PDF) on the right of the search result. The linked paper is sometimes not the exact version of the paper I am after -- for example, it may be a manuscript version instead of the accepted journal version -- but in my experience this is usually fine.
- Search the web for
"name of paper in quotes" filetype:pdf. If that fails, search for"name of paper in quotes"and look at a few of the results if they seem promising. (Again, I may find a different version of the paper than the one I was looking for, which is usually but not always fine.) - Check the paper's authors' personal websites for the paper. Many researchers keep an up-to-date list of their papers with links to full versions.
- Email an author to politely ask for a copy. Researchers spend a lot of time on their research and are usually happy to learn that somebody is eager to read it.
I've been following David Thorstad's blog Ineffective Altruism and, while I mostly lean somewhat "reform sceptic" relative to the median visible Forum user (I believe), and while I often disagree with Thorstad, and while the blog's name is a little cheeky, I've been appreciating Thorstad's critiques of EA, have learned a lot from them and recommend reading the blog. To me, Thorstad seems like one of the better EA critics out there.
I wrote something about CICERO, Meta's new Diplomacy-playing AI. The summary:
- CICERO is a new AI developed by Meta AI that achieves good performance at the board game Diplomacy. Diplomacy involves tactical and strategic reasoning as well as natural language communication: players must negotiate, cooperate and occasionally deceive in order to win.
- CICERO comprises (1) a strategic model deciding which moves to make on the board and (2) a dialogue model communicating with the other players.
- CICERO is honest in the sense that the dialogue model, when it communicates, always tries to communicate the strategy model's actual intent; however, it can omit information and change its mind in the middle of a conversation, meaning it can behave deceptively or treacherously.
- Some who are concerned with risks from advanced AI think the CICERO research project is unusually bad or risky.
- It has at least three potentially-concerning aspects:
- It may present an advancement in AIs' strategic and/or tactical capabilities.
- It may present an advancement in AIs' deception and/or persuasion capabilities.
- It may be illustrative of cultural issues in AI labs like Meta's.
- My low-confidence take is that (1) and (2) are false because CICERO doesn't seem to contain any new insights that markedly advance either of these areas of study. Those capabilities are mostly the product of using reinforcement learning to master a game where tactics, strategy, deception and persuasion are useful, and I think there's nothing surprising or technologically novel about this.
- I think, with low confidence, that (3) may be true, but perhaps no more true than of any other AI project of that scale.
- It has at least three potentially-concerning aspects:
- Neural networks using reinforcement learning are always (?) trained in simulated worlds. Chess presents a very simple world; Diplomacy, with its negotiation phase, is a substantially more complex world. Scaling up AIs to transformative and/or general heights using the reinforcement learning paradigm may require more complex and/or detailed simulations.
- Simulation could be a bottleneck in creating AGI because (1) an accurate enough simulation may already give you the answers you want, (2) an accurate and/or complex enough simulation may be AI-complete and/or (3) extremely costly.
- Simulation could also not be a bottleneck because, following Ajeya Cotra's bio-anchors report, (1) we may get a lot of mileage out of simpler simulated worlds, (2) environments can contain or present problems that are easy to generate and simulate but hard to solve, (3) we may be able to automate simulation and/or (4) people will likely be willing to spend a lot of money on simulation in the future, if that leads to AGI.
- CICERO does not seem like an example of a more complex or detailed simulation, since instances of CICERO didn't actually communicate with one another during self-play. (Generating messages was apparently too computationally expensive.)
The post is written in a personal capacity and doesn't necessarily reflect the views of my employer (Rethink Priorities).
commons plural noun [treated as singular] land or resources belonging to or affecting the whole of a community
The reputation of effective altruism is a commons. Each effective altruist can benefit from and be harmed by it (it can support or impede one's efforts to help others), and each effective altruist is capable of improving and damaging it.
I don't know whether actions that may cause substantial harm to a commons should be decided upon collectively. I don't know whether a community can come up with rules and guidelines governing them. But I do think, at minimum, in the absence of rules and guidelines, that one should inform the community when planning a possibly-commons-harming action, so that the community can at least critique one's plan.
I think purchasing Wytham Abbey (which may have made sense, even factoring in the reputational effects -- I'm not sure) was a possibly-commons-harming action, and this sort of action should probably be announced before it’s carried out in future.
A while ago I wrote a post with some thoughts on "EA for dumb people" discussions. The summary:
I think:
- Intelligence is real, to a large degree determined by genes and an important driver (though not the only one) of how much good one can do.
- That means some people are by nature better positioned to do good. This is unfair, but it is what it is.
- Somewhere there’s a trade-off between getting more people into a community, and keeping a high average level of ability in the community, in other words to do with selectivity. The optimal solution is neither to allow no one in nor to allow everyone in, but somewhere in between.
- Being welcoming and accommodating can allow you to get more impact with a more permissive threshold, but you still need to set the threshold somewhere.
- I think effective altruism today is far away from hitting any diminishing returns on new recruits.
- Ultimately what matters for the effective altruist community is that good is done, not who exactly does it.
The optimal solution is neither to allow no one in nor to allow everyone in, but somewhere in between.
I feel somewhat icky about the framing of "allowing people into EA". I celebrate everyone who shares the value of improving the lives of others, and who wants to do this most effectively. I don't like the idea that some people will be not allowed to be part of this community, especially since EA is currently the only community like it. I see the tradeoff more in who we're advertising towards and what type of activities we're focussing on as a community, e.g. things that better reflect what is most useful, like cultivating intellectual rigor and effective execution of useful projects.
So I think "(not) allowing X in" was not particularly well worded; what I meant was something like "making choices that cause X (not) to join". So that includes stuff like this:
I see the tradeoff more in who we're advertising towards and what type of activities we're focussing on as a community, e.g. things that better reflect what is most useful, like cultivating intellectual rigor and effective execution of useful projects.
And to be clear, I'm talking about EA as a community / shared project. I think it's perfectly possible and fine to have an EA mindset / do good by EA standards without being a member of the community.
That said, I do think there are some rare situations where you would not allow some people to be part of the community, e.g. I don't think Gleb Tsipursky should be a member today.
I wrote a post about Kantian moral philosophy and (human) extinction risk. Summary:
The deontologist in me thinks human extinction would be very bad for three reasons:
- We’d be failing in our duty to humanity itself (55% confidence).
- We’d be failing in our duty to all those who have worked for a better future (70% confidence).
- We’d be failing in our duty to those wild animals whose only hope for better lives rests on future human technology (35% confidence).
Curated and popular this week
·
Note: I am not a malaria expert. This is my best-faith attempt at answering a question that was bothering me, but this field is a large and complex field, and I’ve almost certainly misunderstood something somewhere along the way.
Summary
While the world made incredible progress in reducing malaria cases from 2000 to 2015, the past 10 years have seen malaria cases stop declining and start rising. I investigated potential reasons behind this increase through reading the existing literature and looking at publicly available data, and I identified three key factors explaining the rise:
1. Population Growth: Africa's population has increased by approximately 75% since 2000. This alone explains most of the increase in absolute case numbers, while cases per capita have remained relatively flat since 2015.
2. Stagnant Funding: After rapid growth starting in 2000, funding for malaria prevention plateaued around 2010.
3. Insecticide Resistance: Mosquitoes have become increasingly resistant to the insecticides used in bednets over the past 20 years. This has made older models of bednets less effective, although they still have some effect. Newer models of bednets developed in response to insecticide resistance are more effective but still not widely deployed.
I very crudely estimate that without any of these factors, there would be 55% fewer malaria cases in the world than what we see today. I think all three of these factors are roughly equally important in explaining the difference.
Alternative explanations like removal of PFAS, climate change, or invasive mosquito species don't appear to be major contributors.
Overall this investigation made me more convinced that bednets are an effective global health intervention.
Introduction
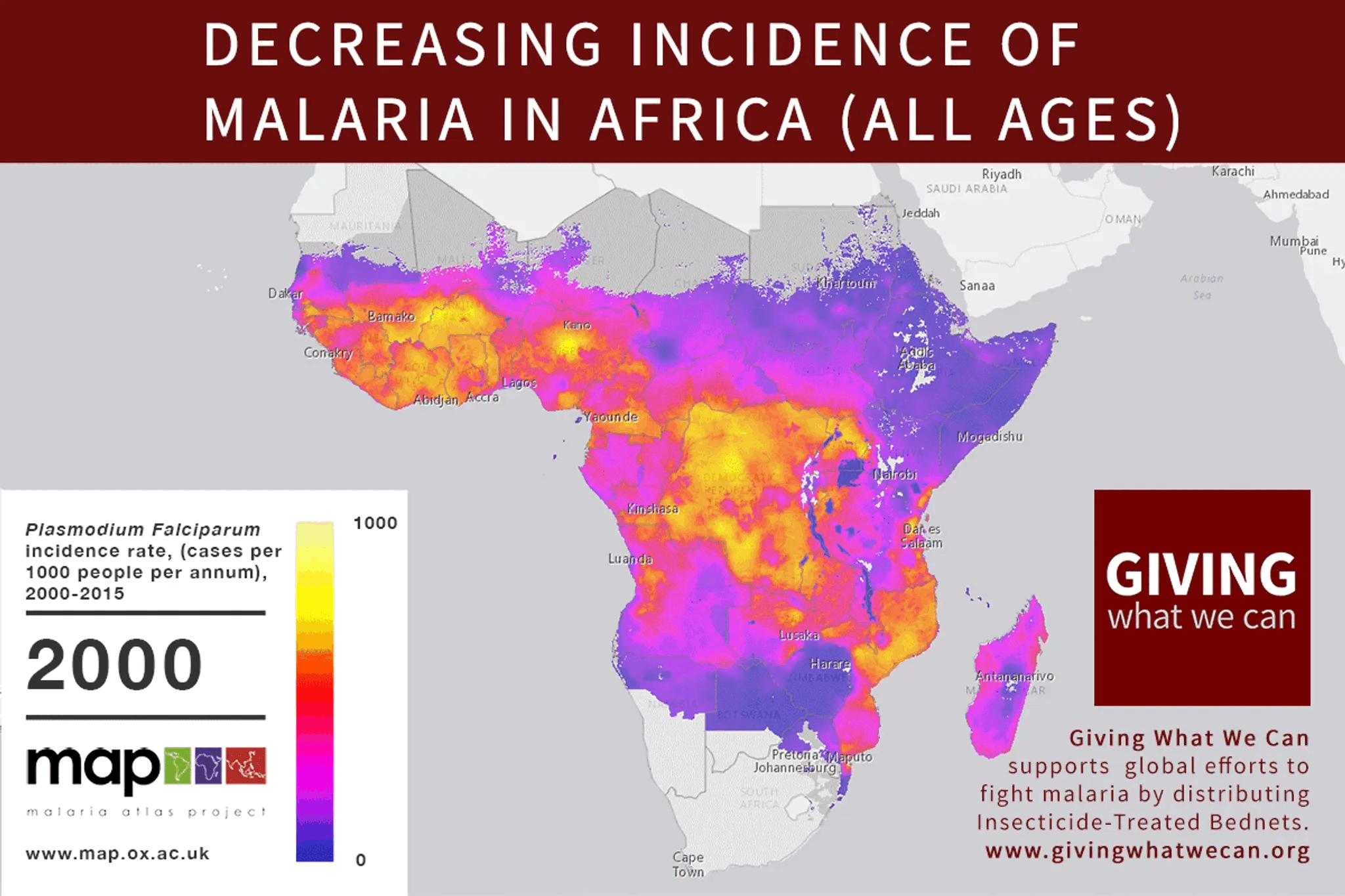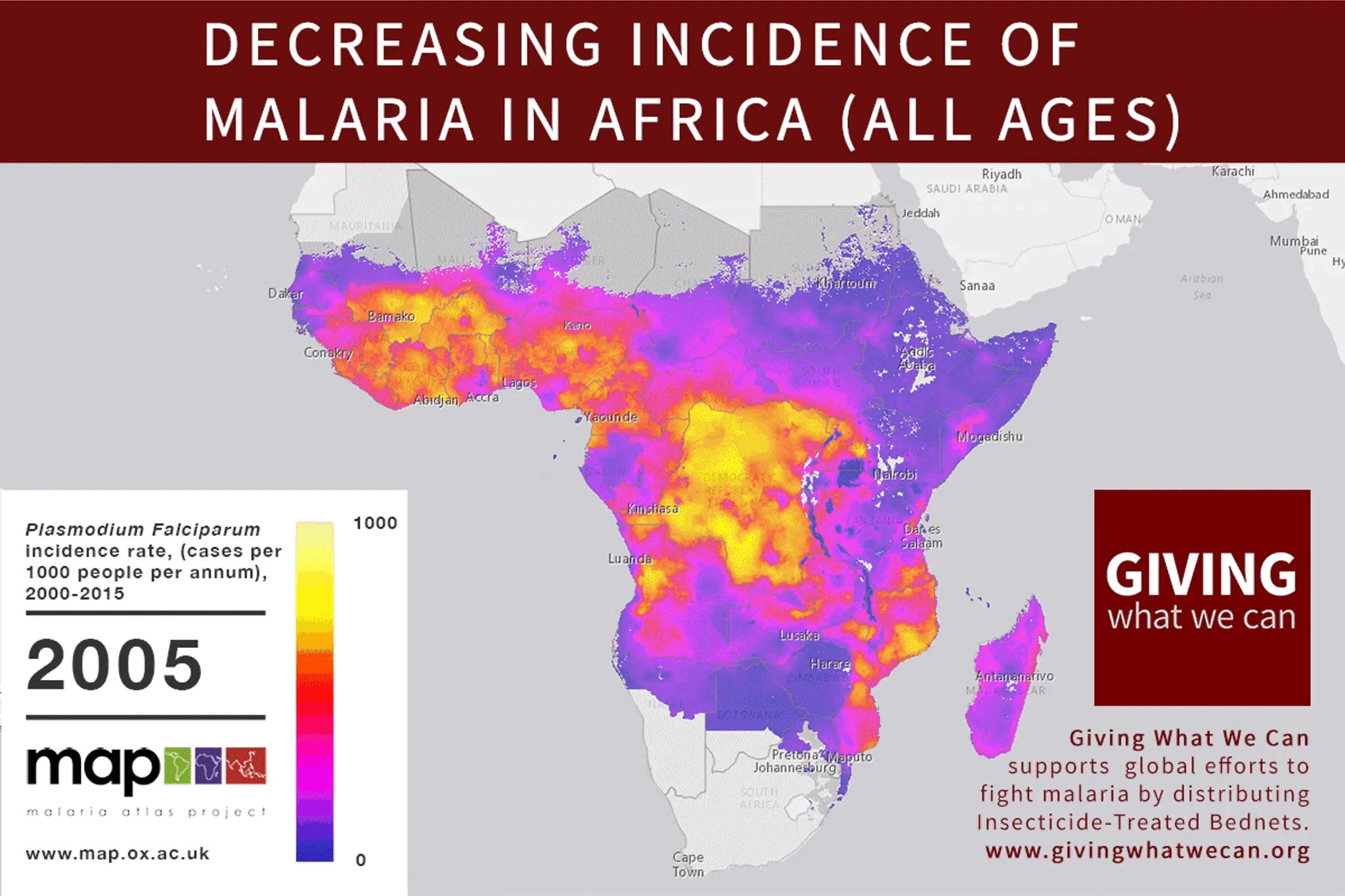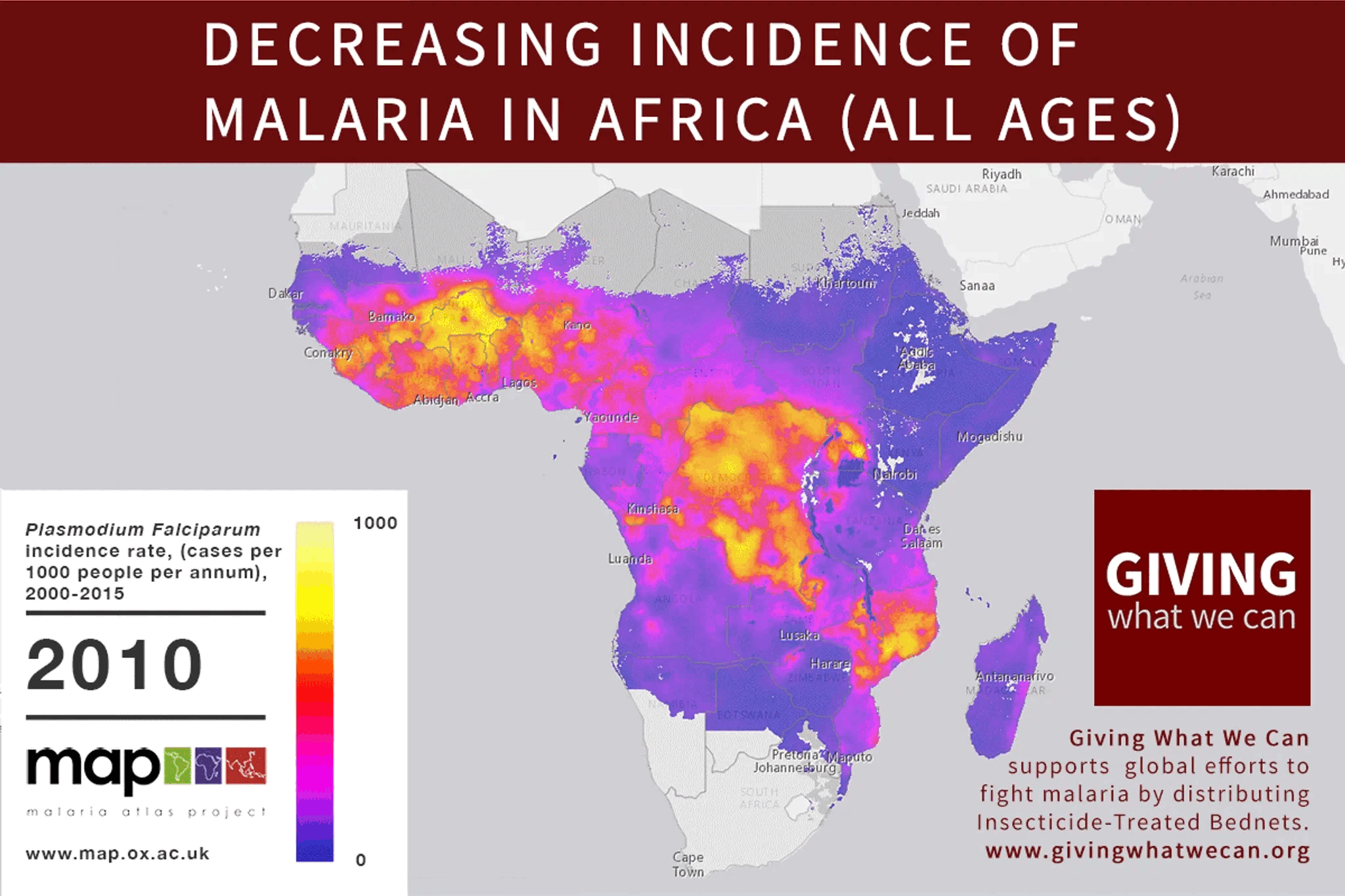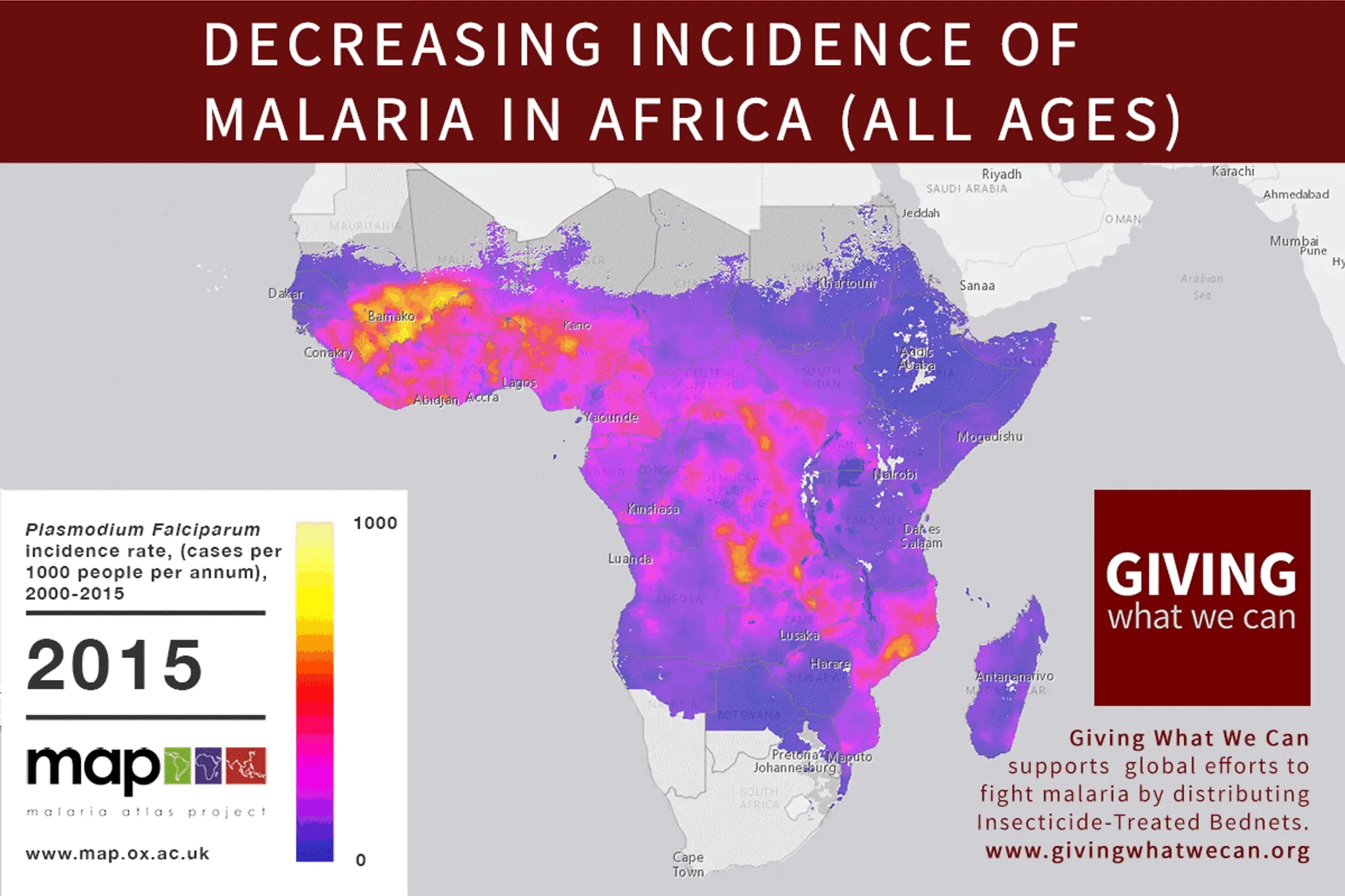
In 2015, malaria rates were down, and EAs were celebrating. Giving What We Can posted this incredible gif showing the decrease in malaria cases across Africa since 2000:
Giving What We Can said that
> The reduction in malaria has be
·
"Part one of our challenge is to solve the technical alignment problem, and that’s what everybody focuses on, but part two is: to whose values do you align the system once you’re capable of doing that, and that may turn out to be an even harder problem", Sam Altman, OpenAI CEO (Link).
In this post, I argue that:
1. "To whose values do you align the system" is a critically neglected space I termed “Moral Alignment.” Only a few organizations work for non-humans in this field, with a total budget of 4-5 million USD (not accounting for academic work). The scale of this space couldn’t be any bigger - the intersection between the most revolutionary technology ever and all sentient beings. While tractability remains uncertain, there is some promising positive evidence (See “The Tractability Open Question” section).
2. Given the first point, our movement must attract more resources, talent, and funding to address it. The goal is to value align AI with caring about all sentient beings: humans, animals, and potential future digital minds. In other words, I argue we should invest much more in promoting a sentient-centric AI.
The problem
What is Moral Alignment?
AI alignment focuses on ensuring AI systems act according to human intentions, emphasizing controllability and corrigibility (adaptability to changing human preferences). However, traditional alignment often ignores the ethical implications for all sentient beings. Moral Alignment, as part of the broader AI alignment and AI safety spaces, is a field focused on the values we aim to instill in AI. I argue that our goal should be to ensure AI is a positive force for all sentient beings.
Currently, as far as I know, no overarching organization, terms, or community unifies Moral Alignment (MA) as a field with a clear umbrella identity. While specific groups focus individually on animals, humans, or digital minds, such as AI for Animals, which does excellent community-building work around AI and animal welfare while

·
Many thanks to Constance Li, Rachel Mason, Ronen Bar, Sam Tucker-Davis, and Yip Fai Tse for providing valuable feedback. This post does not necessarily reflect the views of my employer.
Artificial General Intelligence (basically, ‘AI that is as good as, or better than, humans at most intellectual tasks’) seems increasingly likely to be developed in the next 5-10 years. As others have written, this has major implications for EA priorities, including animal advocacy, but it’s hard to know how this should shape our strategy. This post sets out a few starting points and I’m really interested in hearing others’ ideas, even if they’re very uncertain and half-baked.
Is AGI coming in the next 5-10 years?
This is very well covered elsewhere but basically it looks increasingly likely, e.g.:
* The Metaculus and Manifold forecasting platforms predict we’ll see AGI in 2030 and 2031, respectively.
* The heads of Anthropic and OpenAI think we’ll see it by 2027 and 2035, respectively.
* A 2024 survey of AI researchers put a 50% chance of AGI by 2047, but this is 13 years earlier than predicted in the 2023 version of the survey.
* These predictions seem feasible given the explosive rate of change we’ve been seeing in computing power available to models, algorithmic efficiencies, and actual model performance (e.g., look at how far Large Language Models and AI image generators have come just in the last three years).
* Based on this, organisations (both new ones, like Forethought, and existing ones, like 80,000 Hours) are taking the prospect of near-term AGI increasingly seriously.
What could AGI mean for animals?
AGI’s implications for animals depend heavily on who controls the AGI models. For example:
* AGI might be controlled by a handful of AI companies and/or governments, either in alliance or in competition.
* For example, maybe two government-owned companies separately develop AGI then restrict others from developing it.
* These actors’ use of AGI might be dr

46% reported being vegan or vegetarian in the 2019 EA Survey.