A small group of AGI existential safety field-builders and I are starting research exploring a potential initiative about informing the public and/or important stakeholders about the risks of misaligned AI and the difficulties of aligning it.
We are aware that a public communication initiative like this carries risks (including of harming the AGI x-safety community’s reputation, of sparking animosity and misunderstandings between communities, or drawing attention to ways to misuse or irresponsibly develop scaleable ML architectures). We are still in the stage of evaluating whether/how this initiative would be good to pursue.
We are posting this on the forum to avoid the scenario where someone else starts a project about this at the same time and we end up doing duplicate work.
How you can get involved:
- If you are currently undertaking work similar to this or are interested in doing so, message me your email address along with a bit of context about yourself/what you are doing.
- We are drafting a longer post to share our current considerations and open questions. Message me if you would like to review the draft.
- We are looking for one or two individuals who are excited to facilitate a research space for visiting researchers. The space will run in Oxford (one week in Sep ’22) and in Prague (9-16 Oct ’22) with accommodation and meals provided for. If you take on the role as facilitator, you will receive a monthly income of $2-3K gross for 3 months and actually get to spend most of that time on your own research in the area (of finding ways to clarify unresolved risks of transformative AI to/with other stakeholders). If you are interested, please message me and briefly describe your research background (as relevant to testing approaches for effective intergroup communication, conflict-resolution and/or consensus-building).
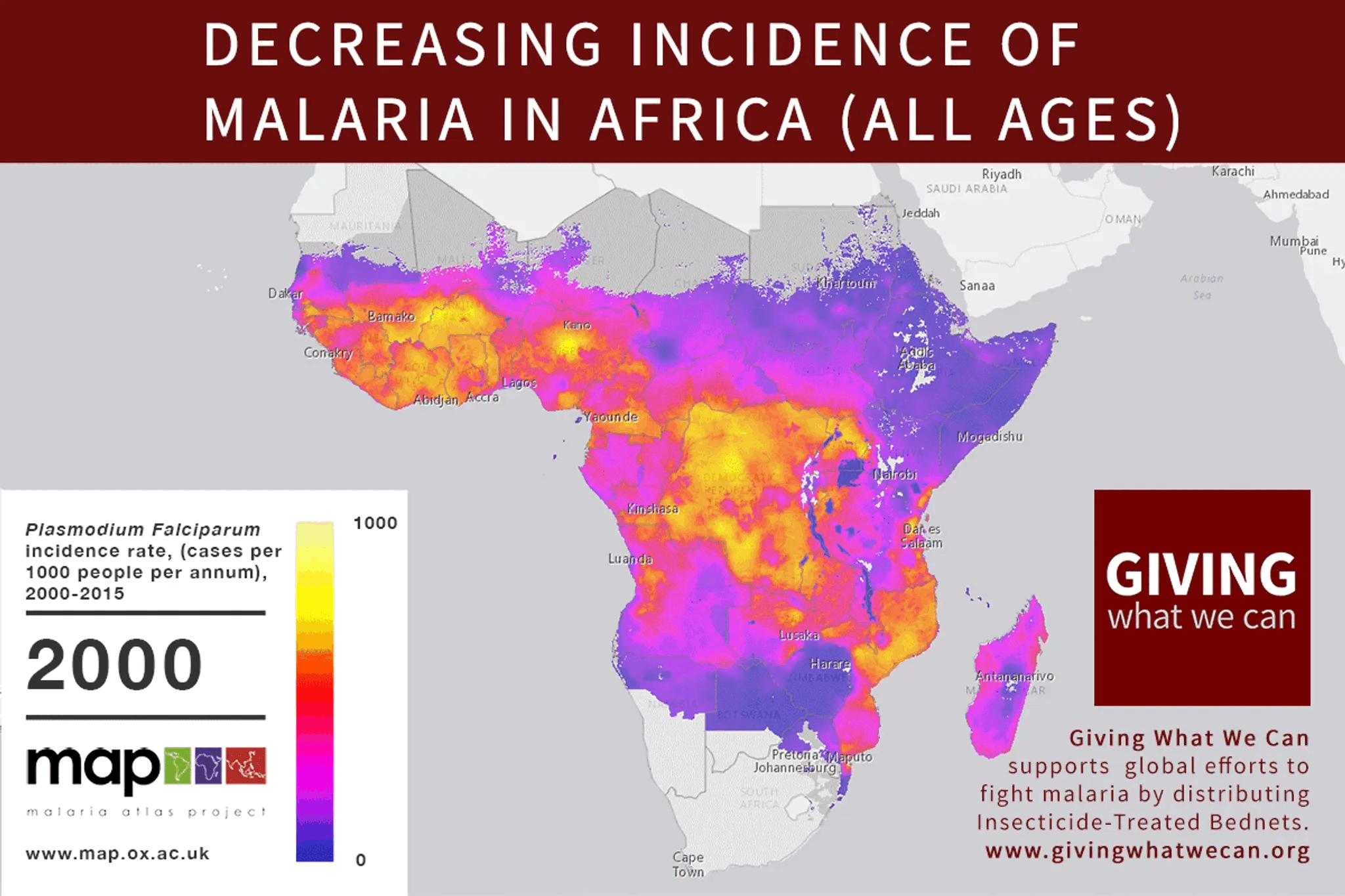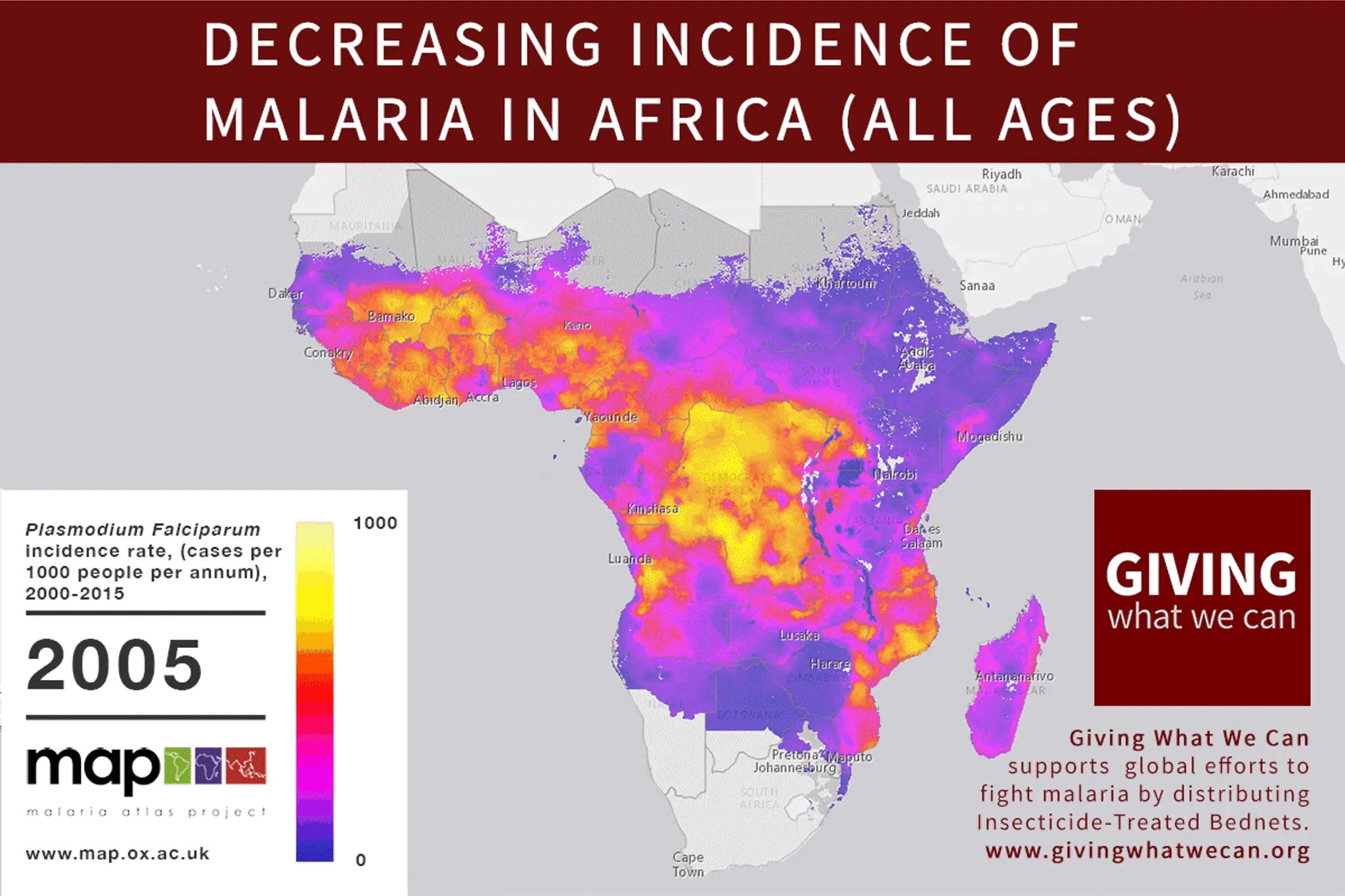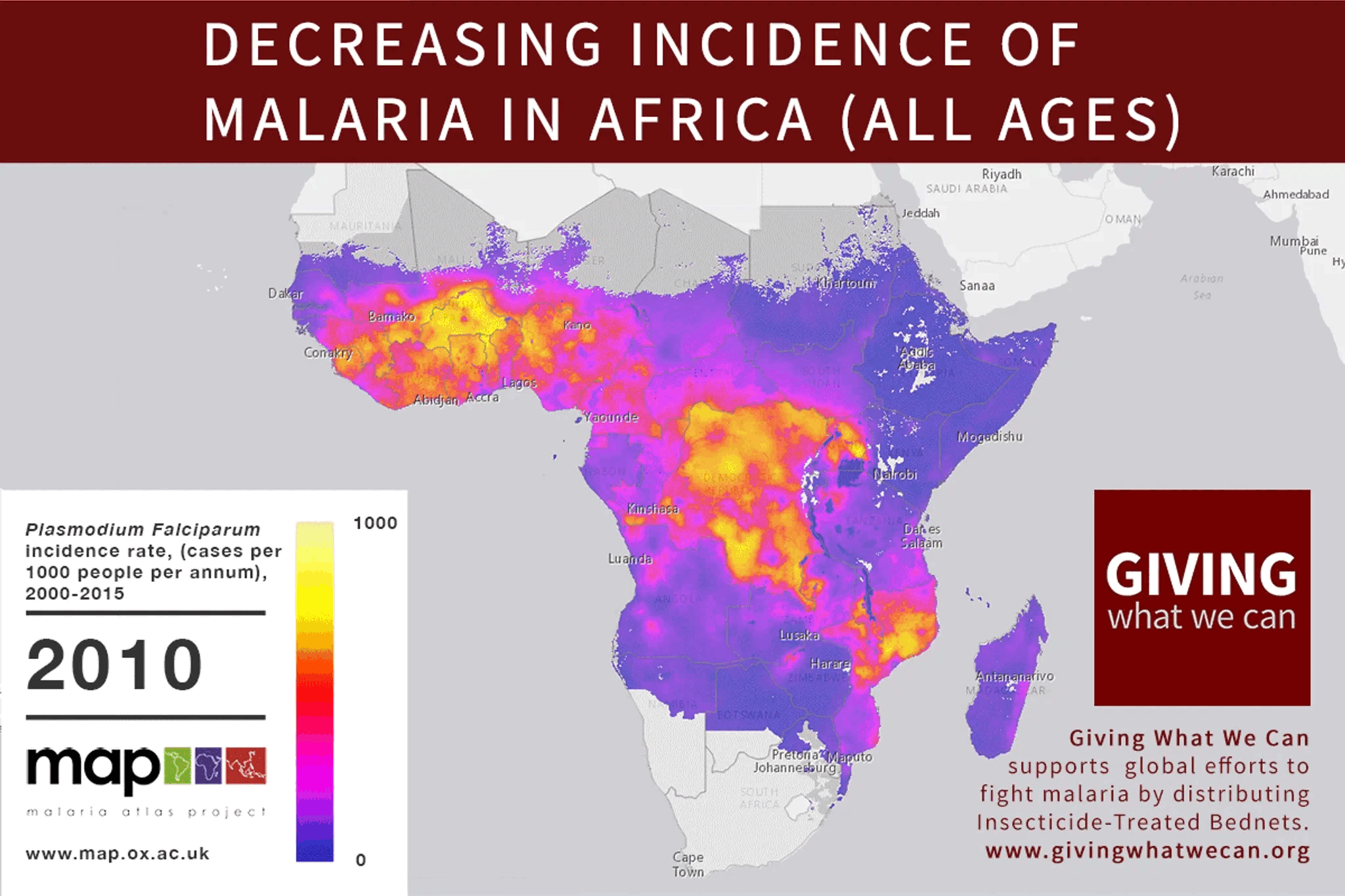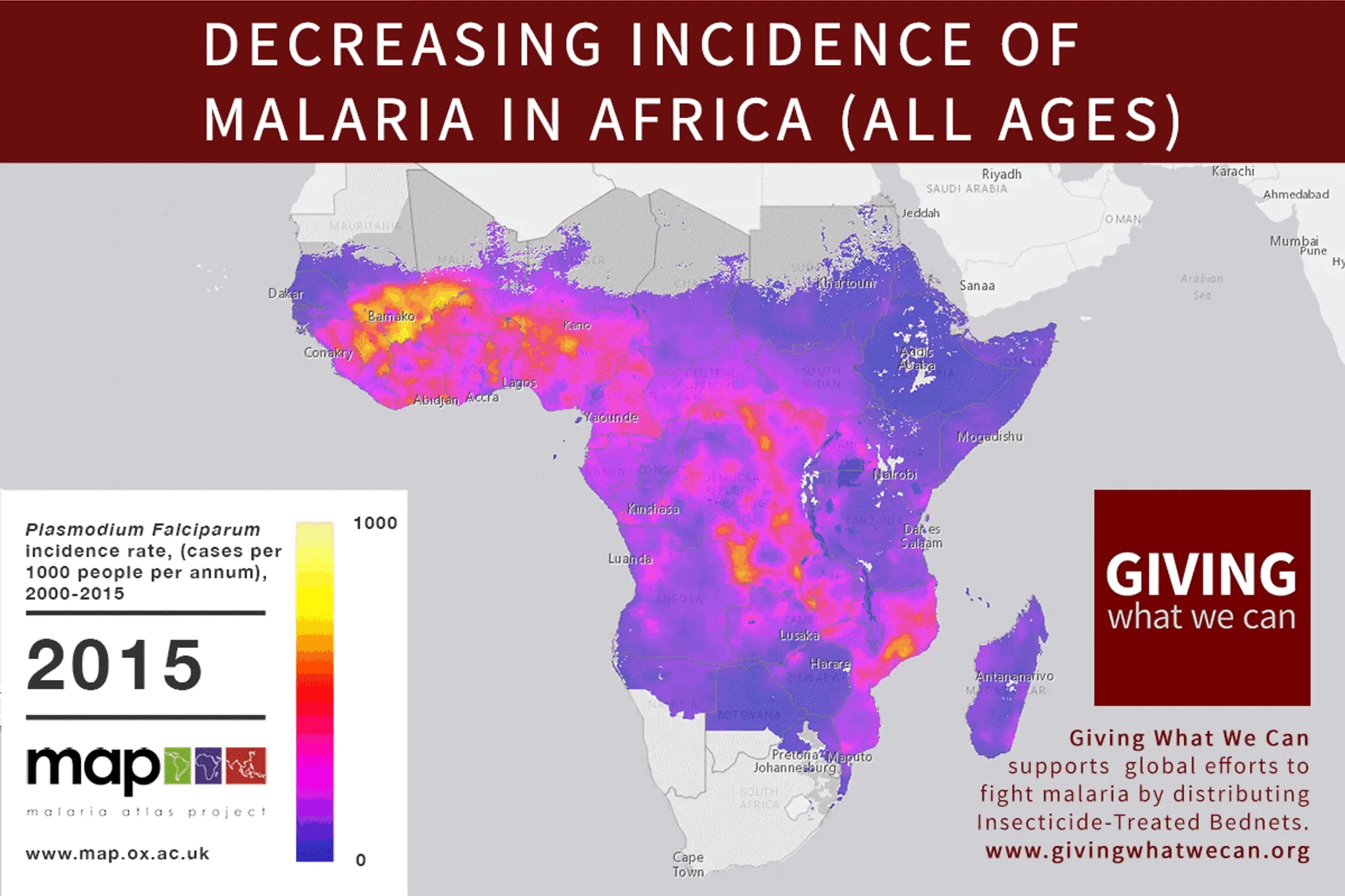

Great idea to look into this!
It sounds a lot like what we have been doing at the Existential Risk Observatory (posts from us, website). We're more than willing to give you input insofar that helps, and perhaps also to coordinate. In general, we think this is a really positive action and the space is wide open. So far, we have good results. We also think there is ample space for other institutes to do this.
Let's further coordinate by email, you can reach us at info@existentialriskobservatory.org. Looking forward to learn from each other!