Is it possible to get database dumps of EA Forum content? I think it would be useful for data analysis, such as building a topic model of EA causes and estimating how much the forum talks about them.
Hide table of contents
Reactions
New Answer
New Comment
4 Answers sorted by
We have a GraphQL interface that people can use to scrape Forum data.
We block web crawlers from the All Posts page so that they don't click "load more" a thousand times and slow down the site. But you can use your own crawlers on the page if you're willing to click "Load More" a lot.
Let me know if you have more questions, and I'll make sure they get answered (that is, I'll ask the tech team).
I was trying out OpenAI Codex after getting access this morning and the task of getting EA Forum data seems ideal for testing it out.
Using Codex, I got code that seems like it downloads plain text comments from the forum at the rate of thousands per minute.
It's a lot faster than writing the script by hand, and does nice things quickly (see time zone fixing).
I thought it was neat!
(This isn't hardcore code, but in case the OP, or anyone else needs raw forum data, and doesn't feel like writing the snippets, feel free to comment or send a message.)
Here's a picture OpenAI interface with the "prompt":
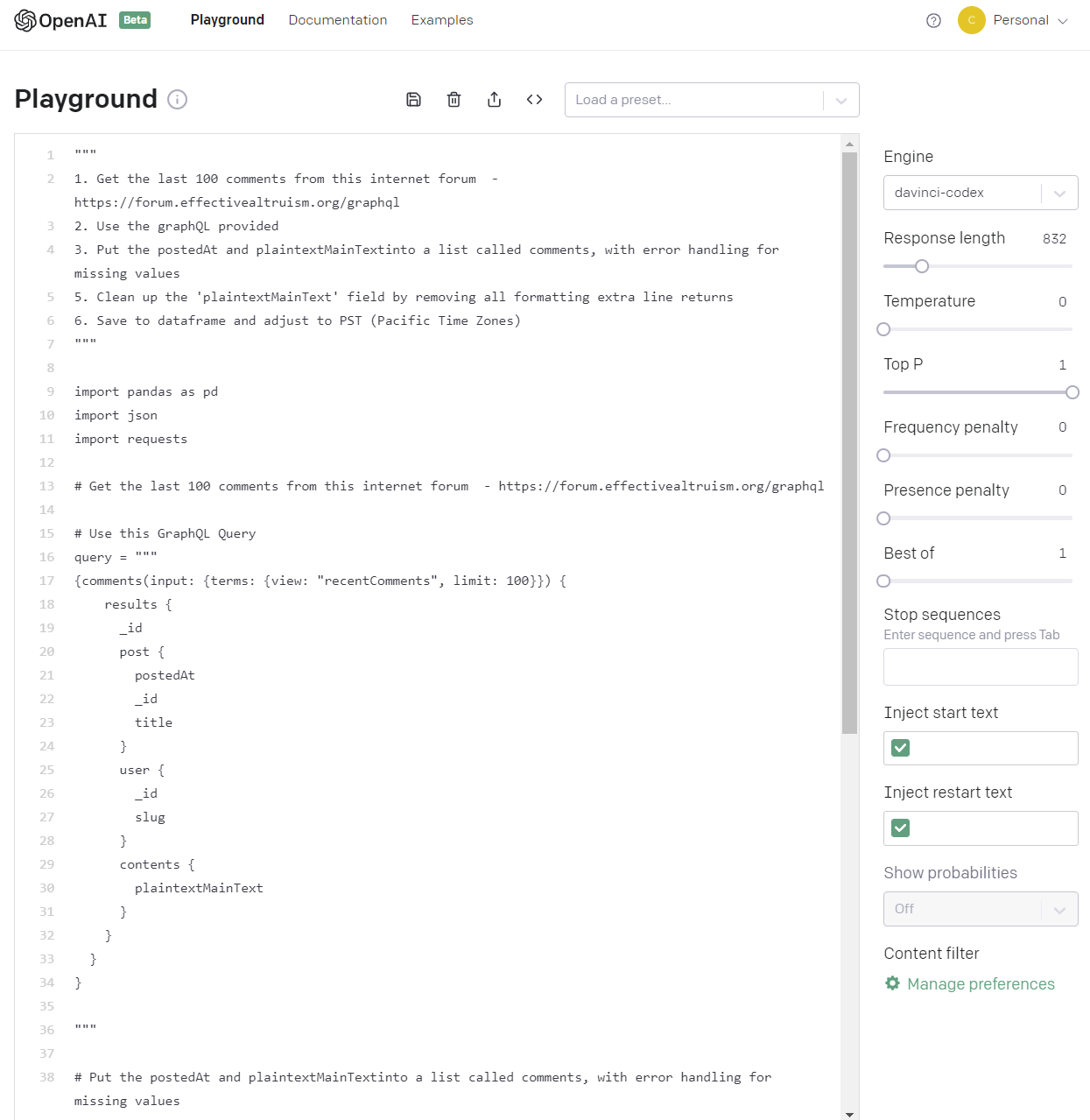
Actual Code (bottom half generated by OpenAI Codex):
"""
1. Get the last 100 comments from this internet forum - https://forum.effectivealtruism.org/graphql
2. Put the contents and createdAt results of the query into a list called comments
4. Clean up the 'plaintextMainText' field by removing all formatting extra line returns
5. Save to dataframe and adjust to PST (Pacific Time Zones)
"""
import pandas as pd
import json
import requests
# Get the last 100 comments from this internet forum - https://forum.effectivealtruism.org/graphql
# Use this GraphQL Query
query = """
{comments(input: {terms: {view: "recentComments", limit: 100}}) {
results {
_id
post {
postedAt
_id
title
}
user {
_id
slug
}
contents {
plaintextMainText
}
}
}
}
"""
# Put the postedAt and plaintextMainTextinto a list called comments, with error handling for missing values
comments = []
for i in range(0,1):
print(i)
url = 'https://forum.effectivealtruism.org/graphql'
headers = {'Content-Type': 'application/json'}
r = requests.post(url, json={'query': query}, headers=headers)
data = json.loads(r.text)
for comment in data['data']['comments']['results']:
try:
comments.append([comment['post']['postedAt'], comment['contents']['plaintextMainText']])
except:
pass
# Clean up the 'plaintextMainText' field by removing all formatting extra line returns
for comment in comments:
comment[1] = comment[1].replace('\n', ' ')
# Save to dataframe and adjust to PST (Pacific Time Zones)
df = pd.DataFrame(comments, columns=['postedAt', 'plaintextMainText'])
df['postedAt'] = pd.to_datetime(df['postedAt'])
df['postedAt'] = df['postedAt'].dt.tz_convert('US/Pacific')
df['postedAt'] = df['postedAt'].dt.tz_localize(None)
# Save to csv
df.to_csv('effective_altruism_comments.csv', index=False)Here's an example of the output.
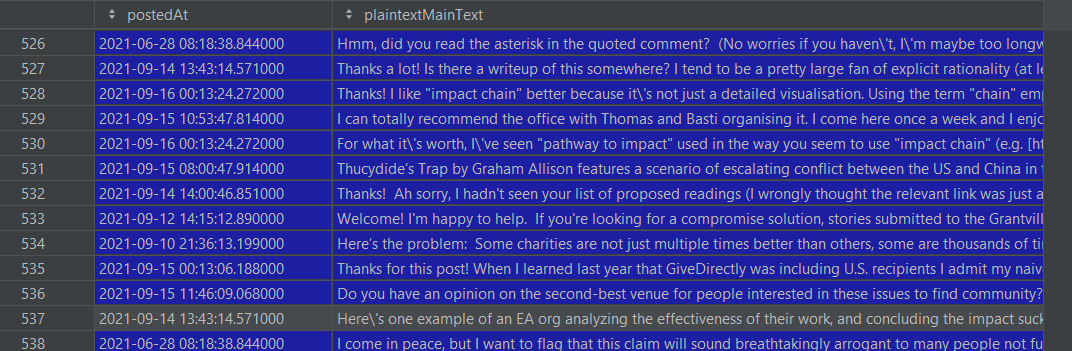
Notes:
- You need to provide a GraphQL query to get Codex to work, it isn't going to figure it out. A tutorial for creating GraphQL is here. I made a simple query to get comments, as you can see above. The interface for GraphQL seems pretty good and you can create queries to get posts and a lot of other information.
- I haven't let this run to try to get the "entire forum". API/backend limits or other issues might block this.
- I can see there's at least one error in my GraphQL query, I think
PostedAtgives a timestamp for the post, not the comment. There's other typos (I spent 10x more time writing this forum comment than writing the instructions for Codex to generate the code!)
Here is some code you can use to get the most essential data from all the forum posts: https://github.com/filyp/tree-of-tags/blob/main/tree_of_tags/forum_queries.py
Also, I used that data to build a topic model of the forum as you mentioned. You can see it here
I tried running this code, but it sends a query that gets:
{
"errors": [
{
"message": "Exceeded maximum value for skip",
"locations": [
{
"line": 3,
"column": 3
}
],
"path": [
"posts"
],
"extensions": {
"code": "INTERNAL_SERVER_ERROR"
}
}
],
"data": {
"posts": null
}
}
Looking at ForumMagnum code this is:
// Don't allow API requests with an offset provided >2000. This prevents some
// extremely-slow queries.
if (terms.offset &&4
When I tried repurposing this code I got a similar error, so that portion in my code now looks like this:
query = """
{
posts(input: {
terms: {
view: "new"
after: "%s"
before: "%s"
limit: %d
meta: null
}
}) {
results {
_id
title
postedAt
postedAtFormatted
user {
username
displayName
}
wordCount
voteCount
baseScore
commentCount
tags {
name
}
}
}
}
"""
def send_graphql_request(input_query):
r = requests.post(url, json={"query": input_query}, headers=headers)
data = json.loads(r.text)
return data
def return_data(input_query):
# Initialize an empty list to store the data
data_list = []
# Set the initial date and the end date for the time intervals
start_date = pd.Timestamp("1960-01-01")
end_date = pd.Timestamp("2019-01-01")
# Define the time interval (4-month chunks) for iteration
delta = pd.DateOffset(months=4)
# Iterate over the time intervals
while start_date < pd.Timestamp.now():
print(start_date)
# Construct the query with the current time interval
query = input_query % (
start_date.strftime("%Y-%m-%d"),
end_date.strftime("%Y-%m-%d"),
3000,
)
# Call the function to send the GraphQL request and extract the data
response = send_graphql_request(query)
results = response["data"]["posts"]["results"]
# Add the current iteration's data to the list
data_list.extend(results)
# Increment the dates for the next iteration
start_date = end_date
end_date += delta
# Create a DataFrame from the collected data
df = pd.DataFrame(data_list)
df["postedAt"] = pd.to_datetime(df["postedAt"])
# Return the final DataFrame
return df
So ~3000 seemed to be a fine chunksize to get every post, and I use the date strings to iterate through t
2
Thanks! I tried extending this for comments, but it looks like it ignores terms; filed an issue.
Comments3
I recently used GraphQL to download all comments and posts, here and on LW, and the code I used is on github.
Really curious to see what you're going to do with it!
Btw, I think we should use https://forum-bots.effectivealtruism.org/graphql for automated queries
Really curious to see what you're going to do with it!
https://www.jefftk.com/p/linking-alt-accounts
Thanks, I'd missed that! If I ever do more scraping I'll use that instead: commmit.
You don't need to use the allPosts page to get a list of all the posts. You can just ask the GraphQL API for the ids of all of them.