A fourteenth theory you should consider adding to your list is the possibility of AGI leading to S-risks. This could be considered similar to #3, but astronomical suffering has the potential to be far worse than extinction. One possible way this could come about is through a "near miss" in AI alignment.
Fair point! I think I'll instead just encourage people to read the comments. Ideally, more elements will be introduced over time, and I don't want to have to keep on updating the list (and the title).
(I’m mentioning the book because my impression, FWIW, is that “anti-AGI” or just AGI-deprioritisation arguments are rarely even mentioned on the Forum. I recommend the book if one wants to learn more about such consideration. (The book is pretty short BTW - 53 pages in the PDF version I have - in part because it is focused on the arguments w/ few digression .))
I've not read the whole book, but reading the linked article Consciousness – Orthogonal or Crucial?I feel like Vinding's case is not very convincing. It was written before GPT-3, and this shows. In GPT-3 we already have a (narrow) AI that can convincingly past the Turing Test in writing. Including writing displaying "social skills" and "general wisdom". And very few people are arguing that GPT-3 is conscious.
In general, if you consider that the range of human behaviour is finite, what's to say that it couldn't be recreated simply with a large enough (probabilistic) look-up table? And a large enough ML model trained on human behaviour could in theory create a neural network functionally equivalent to said look-up table.
What’s to say that a sufficiently large pile of linear algebra, seeded with a sufficiently large amount of data, and executed on a sufficiently fast computer, could not build an accurate world model, recursively rewrite more efficient versions of itself, reverse engineer human psychology, hide it’s intentions from us, create nanotech in secret, etc etc, on the way to turning the future lightcone into computronium in pursuit of the original goal programmed into it at its instantiation (making paperclips, making a better language model, making money on the stock market, or whatever), all without a single conscious subjective internal experience?
Thanks for taking your time to read that excerpt and to respond.
First of all, the author’s scepticism in a “superintelligent” AGI (as discussed by Bostrom at least) doesn’t rely on consciousness being required for an AGI: i.e. one may think that consciousness is fully orthogonal to intelligence (both in theory and practice) but still on the whole updating away from the AGI risk based on the author’s other arguments from the book.
Then, while I do share your scepticism about social skills requiring consciousness (once you have data from conscious people, that is), I do find the author’s points about “general wisdom” (esp. about having phenomenological knowledge) and the science of mind much more convincing (although they are probably much less relevant to the AGI risk). (I won’t repeat the author’s point here: the two corresponding subsections from the piece are really short to read directly.)
In GPT-3 we already have a (narrow) AI that can convincingly past the Turing Test in writing. Including writing displaying "social skills" and "general wisdom".
Correct me if I’m wrong, but these "social skills" and "general wisdom" are just generalisations (impressive and accurate as they may be) from actual people’s social skills and knowledge. GPT-3 and other ML systems are inherently probabilistic: when they are ~right, they are ~right by accident. They don’t know, esp. about what-it-is-likeness of any sentient experience (although, once again, this may be orthogonal to the risk, at least in theory with unlimited computational power).
What’s to say that a sufficiently large pile of linear algebra, seeded with a sufficiently large amount of data, and executed on a sufficiently fast computer, could not build an accurate world model, recursively rewrite more efficient versions of itself, reverse engineer human psychology, hide it’s intentions from us, create nanotech in secret, etc etc, on the way to turning the future lightcone into computronium in pursuit of the original goal programmed into it at its instantiation (making paperclips, making a better language model, making money on the stock market, or whatever), all without a single conscious subjective internal experience?
“Sufficiently” does a lot of work here IMO. Even if something is possible in theory, doesn’t mean it’s going to happen in reality, especially by accident. Also, "... reverse engineer human psychology, hide it’s intentions from us ..." arguably does require a conscious mind, for I don't think (FWIW) that there could be a computationally-feasible substitute (at least one implemented on a classical digital computer) for being conscious in the first place to understand other people (or at least to be accurate enough to mislead all of us into a paperclip "hell").
(Sorry for a shorthand reply: I'm just afraid of mentioning things that have been discussed to death in arguments about the AGI risk, as I don’t have any enthusiasm in perpetuating similar (often unproductive IMO) threads. (This isn’t to say though that it necessarily wouldn’t be useful if, for example, someone who were deeply engaged in the topic of “superintelligent” AGI read the book and had a recorded discussion w/ the author for everyone’s benefit…))
They don’t know, esp. about what-it-is-likeness of any sentient experience (although, once again, this may be orthogonal to the risk, at least in theory with unlimited computational power)
Yes, and to to the orthogonality, but I don't think it needs that much computational power (certainly not unlimited). Good enough generalisations could allow it to accomplish a lot (e.g. convincing a lab tech to mix together some mail order proteins/DNA in order to bootstrap nanotech).
or at least to be accurate enough to mislead all of us into a paperclip "hell"
How accurate does it need to be? I think human behaviour could be simulated enough to be manipulated with feasible levels of compute. There's no need for consciousness/empathy. Arguably, social media algorithms are already having large effects on human behaviour.
I will also say that I like Vinding's other work, especially You Are Them. A problem for Alignment is that the AGI isn't Us though (as it's default non-conscious). Perhaps it's possible that an AGI could independently work out Valence Realism and Open/Empty Individualism, and even solve the phenomenal binding problem so as to become conscious itself. But I think these are unlikely possibilities a priori. Although perhaps they should be deliberately aimed for? (Is anyone working on this?)
Full-spectrum superintelligence, if equipped with the posthuman cognitive generalisation of mirror-touch synaesthesia, understands your thoughts, your feelings and your egocentric perspective better than you do yourself.
Could there arise "evil" mirror-touch synaesthetes? In one sense, no. You can't go around wantonly hurting other sentient beings if you feel their pain as your own. Full-spectrum intelligence is friendly intelligence. But in another sense yes, insofar as primitive mirror-touch synaesthetes are prey to species-specific cognitive limitations that prevent them acting rationally to maximise the well-being of all sentience. Full-spectrum superintelligences would lack those computational limitations in virtue of their full cognitive competence in understanding both the subjective and the formal properties of mind. Perhaps full-spectrum superintelligences might optimise your matter and energy into a blissful smart angel; but they couldn't wantonly hurt you, whether by neglect or design.
Interesting. Yes I guess such "full-spectrum superintelligence" might well be good by default, but the main worry from the perspective of the Yudkowsky/Bostrom paradigm is not this - perhaps it's better described as super-optimisation, or super-capability (i.e. a blind optimisation process that has no subjective internal experience, and no inclination to gain one, given it's likely initial goals).
Regarding feasibility of conscious AGI / Pearce's full-spectrum superintelligence, maybe it would be possible with biology involved somewhere. But the getting from here to there seems very fraught ethically (e.g. the already-terrifying experiments with mini-brains). Or maybe quantum computers would be enough?
Pearce calls it "full-spectrum" to emphasise the difference w/ Bostrom's "Super-Watson" (using Pearce's words).
... a blind optimisation process that has no subjective internal experience, and no inclination to gain one, given it's likely initial goals ...
Given how apparently useful cross-modal world simulations (ie consciousness) have been for evolution, I, again, doubt that such a dumb (in a sense of not knowing what it is doing) process can pose an immediate existential danger to humanity that we won't notice or won't be able to stop.
Regarding feasibility of conscious AGI / Pearce's full-spectrum superintelligence, maybe it would be possible with biology involved somewhere. But the getting from here to there seems very fraught ethically (e.g. the already-terrifying experiments with mini-brains).
Actually, if I remember correctly, Pearce thinks that if "full-spectrum superintelligence" is going to emerge, it's most likely to be biological, and even post-human (ie it is human descendants who will poses such super minds, not (purely?) silicon-based machines). Pearce sometimes calls this "biotechnological singularity", or "BioSingularity" for short, analogously to Kurzweil's "technological singularity". One can read more about this in Pearce's The Biointelligence Explosion (or in this "extended abstract").
I have noticed that few people hold the view that we can readily reduce AI-risk. Either they are very pessimistic (they see no viable solutions so reducing risk is hard) or they are optimistic (they assume AI will be aligned by default, so trying to improve the situation is superfluous).
Either way, this would argue against alignment research, since alignment work would not produce much change.
Strategically, it's best to assume that alignment work does reduce AI-risk, since it is better to do too much alignment work (relative to doing too little alignment work and causing a catastrophe).
AGI will be possiblevery soon (5-10yrs): neural-to-symbolic work, generalization out-of-distribution, where it is able to learn from fewer and fewer examples, and with equivariance, as well as Mixtures of Experts & Hinton's GLOM are all fragments of a general intelligence.
AGI alignment is likely impossible. We would be pulling a Boltzmann brain out of a hat, instead of relying upon hundreds of millions of years of common sense and socialization. I'd be more likely to trust an alien, because they had to evolve and maintain a civilization, first.
Yet, I posit that narrow AI will likely provide comparable or superior performance, given the same quantity of compute, for almost all tasks. (While the human brain has 100 Trillion synapses, and our neurons are quite complex, we must contrast that with the most recent language AI, which can perform nearly as well as us with only 7 Billion parameters - a "brain" 14,000 times smaller! It does seem that narrow AI is a better use of resources.)
Because narrow AI will be generally sufficient, then we would NOT be at a disadvantage if we "play it safe" by NOT pursuing AGI. If "playing it safe is safe", that's a game humanity might win. :)
I understand that full compliance for an AGI-ban is unlikely, yet I see our best chances, strategically, from pursuing narrow AI until that domain is tapped-out, while vehemently fighting attempts at AGI. Only after narrow AI sees diminished returns will we have a clear understanding of "what else is there left to do, that makes AGI so important?" My bet is that AGI would not supply a large enough margin compared to narrow AI to be worth the risks, ever.
Side-bar Prediction: we are already in a lumpy, decades-long "FOOMishness" where narrow AI are finding improvements for us, accelerating those same narrow AI. Algorithms cannot become infinitely more powerful, however, so we are likely to see diminishing returns in coming years. That will make the job of the first AGI very difficult -because each next leap of intelligence will take vastly more resources and time than the last (especially considering the decades of brain-legions to get us this far...).
I imagine many others here (myself included) will be skeptical of the parts: 1. Narrow AI will be just as good, particularly for similar development costs. (To me it seems dramatically more work-intense to make enough narrow AIs) 2. The idea that really powerful narrow AIs won't speed up AGIs and similar. 3. Your timelines (very soon) might be more soon than others here, though it's not clear exactly what "possible" means. (I'm sure some here would put some probability mass 5-10yrs out, just a different amount)
I think that very carefully selected narrows AIs could be really great (See Ought, for example), but am not sure how far and broad I'd recommend making narrow AIs.
Oh, I am well aware that most folks are skeptical of "narrow AI is good enough" and "5-10yrs to AGI"! :) I am not bothered by sounding wrong to the majority. [For example, when I wrote in Feb. 2020, (back when the stock market had only begun to dip and Italy hadn't yet locked-down) that the coronavirus would cause a supply-chain disruption at the moment we sought to recover & re-open, which would add a few percent to prices and prolonged lag to the system, everyone else thought we would see a "sharp V recovery in a couple months". I usually sound crazy at first.]
...and I meant "possible" in the sense that doing so would be "within the budget of a large institution". Whether they take that gamble or not is where I focus the "playing it safe might be safe" strategy. If narrow AI is good enough, then we aren't flat-footed for avoiding AGI. Promoting narrow AI applications, as a result, diminishes the allure of implementing AGI.
Additionally, I should clarify that I think narrow AI is already starting to "FOOM" a little, in the sense that it is feeding itself gains with less and less of our own creative input. A self-accelerating self-improvement, though narrow AI still has humans-in-the-loop.
These self-discovered improvements will accelerate AGI as well. Numerous processes, from chip layout to the material science of fabrication, and even the discovery of superior algorithms to run on quantum computers, all will see multiples that feed back into the whole program of AGI development, a sort of "distributed FOOM".
Algorithms for intelligence themselves, however, probably have only a 100x or so improvement left, and those gains are likely to be lumpy. Additionally, narrow AI is likely to make enough of those discoveries soon that the work left-over for AGI is much more difficult, preventing the pot from FOOMing-over completely.
[[And, a side-note: we are only now approaching the 6 year anniversary of AlphaGo defeating Lee Sedol, demonstrating with move 37 that it could be creative and insightful about a highly intuitive strategy game. This last year, AlphaFold has found the form of every human protein, which we assumed would take a generation. Cerebras wafer-scale chips will be able to handle 120 trillion parameters, this next year, which is "brain-scale". I see this progress as a sign that narrow AI will likely do well-enough, meaning we are safe if we stick to narrow-only, AND that AGI will be achievable before 2032, so we should try to stop it with urgency.]]
[[Addendum: narrow AI now only needs ten examples from a limited training set, in order to generalize outside that distribution... so, designing numerous narrow AI will likely be easy & automated, too, and they will proliferate and diversify the same way arthropods have. Even the language-model Codex can write functioning code for an AI system, so AutoML in general makes narrow AI feasible. I expect most AI should be as dumb as possible without failing often. And never let paperclip-machines learn about missiles!]]
This sounds a lot like #3 and #1 to me. It seems like you might have slightly unique intuitions on the parameters (chance of success, our ability to do things about it), but the rough shape seems similar.
Interesting, I wasn't at all thinking about the orthogonality thesis or moral realism when writing that. I was thinking a bit about people who: 1) Start out wanting to do lots of tech or AI work. 2) Find out about AGI and AGI risks. 3) Conclude on some worldview where doing lots of tech or AI work is the best thing for AGI success.
Yea; this was done with a search was for "AGI". There's no great semantic search yet, but I could see that as a thing in the future. I added a quick comment in this section about it.
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
Epistemic Status: Quickly written (~4 hours), uncertain. AGI policy isn't my field, don't take me to be an expert in it.
This was originally posted to Facebook here, where it had some discussion. Also, see this earlier post too.
Over the last 10 years or so, I've talked to a bunch of different people about AGI, and have seen several more unique positions online.
Theories that I've heard include:
AGI is a severe risk, but we have decent odds of it going well. Alignment work is probably good, AGI capabilities are probably bad. (Many longtermist AI people)
AGI seems like a huge deal, but there's really nothing we could do about it at this point. (Many non-longtermist EAs)
AGI will very likely kill us all. We should try to stop it, though very few interventions are viable, and it’s a long shot. (Eliezer. See Facebook comments for more discussion)
AGI is amazing for mankind and we should basically build it as quickly as possible. There are basically no big risks. (lots of AI developers)
It's important that Western countries build AI/AGI before China does, so we should rush it (select longtermists, I think Eric Schmidt)
It's important that we have lots of small and narrow AI companies because these will help draw attention and talent from the big and general-purpose companies.
It's important that AI development be particularly open and transparent, in part so that there's less fear around it.
We need to develop AI quickly to promote global growth, without which the world might experience severe economic decline, the consequences will be massively violent (Peter Thiel, maybe some Progress Studies people to a lesser extent)
We should mostly focus on making sure that AI does not increase discrimination or unfairness in society. (Lots of "Safe AI" researchers, often liberal)
AGI will definitely be fine because that's what God would want. We might as well make it very quickly.
AGI will kill us, but we shouldn't be worried, because whatever it is, it will be more morally important than us anyway. (fairly fringe)
AGI is a meaningless concept, in part because intelligence is not a single unit. The entire concept doesn't make sense, so talking about it is useless.
There's basically no chance of transformative AI happening in the next 30-100 years. (Most of the world and governments, from what I can tell)
Edit: More stances have been introduced in the comments below.
Naturally, smart people are actively working on advancing the majority of these. There's a ton of unilateralist and expensive actions being taken.
One weird thing, to me, is just how intense some of these people are. Like, they choose one or two of these 13 theories and really go all-in on them. It feels a lot like a religious divide.
Some key reflections:
A bunch of intelligent/powerful people care a lot about AGI. I expect that over time, many more will.
There are several camps that strongly disagree with each other. I think these disagreements often aren't made explicit, so the situation is confusing. The related terminology and conceptual space are really messy. Some positions are strongly believed but barely articulated (see single tweets dismissing AGI concerns, for example).
The disagreements are along several different dimensions, not one or two. It's not simply short vs. long timelines, or "Is AGI dangerous or not?".
A lot of people seem really confident[1] in their views on this topic. If you were to eventually calculate the average Brier score of all of these opinions, it would be pretty bad.
Addendum
Possible next steps
The above 13 stances were written quickly and don't follow a neat structure. I don't mean for them to be definitive, I just want to use this post to highlight the issue.
Some obvious projects include:
Come up with better lists.
Try to isolate the key cruxes/components (beliefs about timelines, beliefs about failure modes) where people disagree.
Survey either large or important clusters of people of different types to see where they land on these issues.
Hold interviews and discussions to see what can be learned by the key cruxes.
I should also flag again that there's clearly been a great deal of technical and policy work in many of these areas and I'm an amateur here. I don't mean at all to imply that I'm the first one with any of the above ideas, I imagine this is pretty obvious to others too.
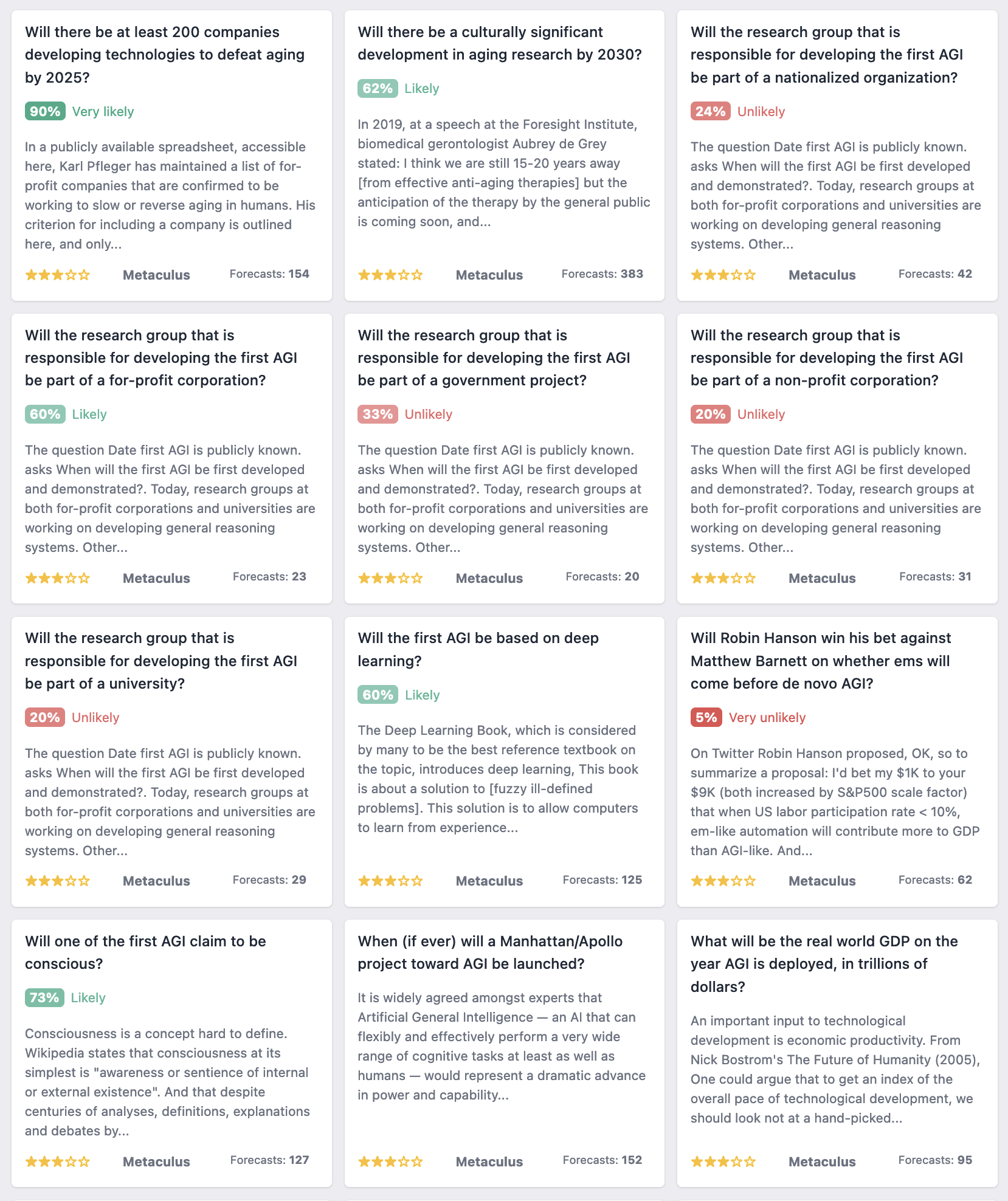
Some Related Metaculus Questions
Here's a list of some of the Metaculus AGI questions, which identify some of the cruxes. I think some of the predictions clearly disagree with several of the 13 stances I listed above, though some of these have few forecasts. There's a longer list on the Metaforecast link here. (Skip the first two though, those are about aging, which frustratingly begins with the letters "agi")
[1] Perhaps this is due in part to people trying to carry over their worldviews. I expect that if you think that AGI is a massive deal, and you also have a specific key perspective of the world that you really want to keep, it would be very convenient if you could fit your perspective onto AGI.
For example, if you deeply believe that the purpose of your life is to craft gold jewelry, it would be very strange if you also conclude that AGI would end all life in 10 years. Those two don't really go together, like, "The purpose of my life, for the next ten years, is to make jewelry, then I with everyone else will perish, for completely separate reasons." It would be much more palatable if somehow you could find some stance where AGI is going to care a whole lot about art, or perhaps it's not at all a threat for 80 years.


A fourteenth theory you should consider adding to your list is the possibility of AGI leading to S-risks. This could be considered similar to #3, but astronomical suffering has the potential to be far worse than extinction. One possible way this could come about is through a "near miss" in AI alignment.
Fair point! I think I'll instead just encourage people to read the comments. Ideally, more elements will be introduced over time, and I don't want to have to keep on updating the list (and the title).
Here's a chart I found of existential risks that includes S-risks.