Devaluing proposals only because they purportedly originated with an adversary.
In any technical discussion, there are a lot of well intentioned but otherwise not so well informed people participating.
On the part of individuals and groups both, this has the effect of creating protective layers of isolation and degrees of separation – between the qualified experts and everyone else.
While this is a natural tendency that can have a beneficial effect, the creation of too specific or strong of an 'in-crowd' can result in mono-culture effects.
The problem of a very poor signal to noise ratio from messages received from people outside of the established professional group basically means that the risk of discarding a good proposal from anyone regarded as an outsider is especially likely.
In terms of natural social process, there does not seem to be any available factor to counteract the possibility of forever increasing brittleness in the form of decreasing numbers of new ideas (ie; 'echo chambers').
- link Wikipedia: Reactive devaluation
- an item on Forrest Landry's compiled list of biases in evaluating extinction risks.
Per the LW discussion, I suspect you'd fare better spending effort actually presenting the object level case rather than meta-level bulverism to explain why these ideas (whatever they are?) are getting a chilly reception.
Error theories along the lines of "Presuming I am right, why do people disagree with me?" are easy to come by. Suppose indeed Landry's/your work is indeed a great advance in AI safety: then perhaps indeed it is being neglected thanks to collective epistemic vices in the AI safety community. Suppose instead this work is bunk: then perhaps indeed epistemic vice on your part explains your confidence (complete with persecution narrative) in the work despite its lack of merit.
We could litigate which is more likely - or, better, find what the ideal 'bar' insiders should have on when to look into outsider/heterodox/whatever work (too high, and existing consensus is too entrenched, and you miss too many diamonds in the rough; too low, expert time is squandered submerged in dross), and see whether what has been presented so far gets far enough along the ?crackpot/?genius spectrum to warrant the consultation and interpretive labour you assert you are rightly due.
This would be an improvement on the several posts so far just offering 'here are some biases which we propose explains why our work is not recognised'. Yet it would still largely miss the point: the 'bar' of how receptive an expert community will be is largely a given, and seldom that amenable to protests from those currently screened out it should be lowered. If the objective is to persuade this community to pay attention to your work, then even if in some platonic sense their bar is 'too high' is neither here nor there: you still have to meet it else they will keep ignoring you.
Taking your course of action instead has the opposite of the desired effect. The base rates here are not favourable, but extensive 'rowing with the ref' whilst basically keeping the substantive details behind the curtain with a promissory note of "This is great, but you wouldn't understand its value unless you were willing to make arduous commitments to carefully study why we're right" is a further adverse indicator.
Thanks for the thoughts.
Yes, we will gradually present the object-level arguments. Just not in one go, because it takes up time for people to sync up on the definitions a and distinctions.
This insight feels relevant to a comment exchange I was in yesterday. An AI Safety insider (Christiano) lightly read an overview of work by an outsider (Landry). The insider then judged the work to be "crankery", in effect acting as a protecting barrier against other insiders having to consider the new ideas.
The sticking point was the claim "It is 100% possible to know that X is 100% impossible", where X is a perpetual motion machine or a 'perpetual general benefit machine' (ie. long-term safe and beneficial AGI).
The insider believed this was an exaggerated claim, which meant we first needed to clarify epistemics and social heuristics, rather than the substantive argument form. The reactions by the busy "expert" insider, who had elected to judge the formal reasoning, led to us losing trust that they would proceed in a patient and discerning manner.
There was simply not enough common background and shared conceptual language for the insider to accurately interpret the outsider's writings ("very poor signal to noise ratio from messages received").
Add to that:
I mean, someone recognised as an expert in AI Safety could consciously mean well trying to judge an outsider's work accurately – in the time they have. But that's a lot of biases to counteract.
Forrest actually clarified the claim further to me by message:
But the point is – few readers will seriously consider this message.
That's my experience, sadly.
The common reaction I noticed too from talking with others in AI Safety is that they immediately devaluated that extreme-sounding conclusion that is based on the research of an outsider. A conclusion that goes against their prior beliefs, and against their role in the community.
continuing my response:
When Gregory Lewis said to you that "If the objective is to persuade this community to pay attention to your work, then even if in some platonic sense their bar is 'too high' is neither here nor there: you still have to meet it else they will keep ignoring you." He is arguing an ultimatum: "if we're dysfunctional, then you still have to bow to our dysfunction, or we get to ignore you." That has no standing in epistemics, and it is a bad-faith argument. If he were to suppose his organization's dysfunction with the probability with which he askes you to doubt your own work, he would realize that "you gotta toe the line, even if our 'bar' is nonsense" is just nonsense! Under the circumstance where they are dysfunctional, Gregory Lewis is lounging in it!
The worst part is that, once their fallacies and off-hand dismissals are pointed-out to them, when they give no real refutation, they just go silent. It's bizarre, that they think they are behaving in a healthy, rational way. I suspect that many of them aren't as competent as they hope, and they need to hide that fact by avoiding real analysis. I'd be glad to talk to any Ai Safety folks in the Bay, myself - I'd been asking them since December of last year. When I presented my arguments, they waved-away without refutation, just as they have done to you.
Yes, agreed with the substance of your points (I try to be more diplomatic about this, but it roughly lines up with my impressions).
Rather than helping encourage reasonable evaluations in the community (no isolated demands for rigour for judging long-term safe AGI impossibility formal reasoning compared to intuitions about AGI safety being possible in principle), this is saying that a possibly unreasonable status quo is not going to be changed, so therefore people should just adjust to the status quo if they want to make any headway.
The issue here is that the inferential distance is already large enough as it is, and in most one-on-ones I don't get further than discussing basic premises before my interlocutor side-tracks or cuts off the conversation. I was naive 11 months ago to believe that many people would actually just dig into the reasoning steps with us, if we found a way to translate them nearer to Alignment Forum speak to be easier to comprehend and follow step-by-step.
In practice, I do think it's correct that we need to work with the community as it is. It's on us to find ways to encourage people to reflect on their premises and to detail and discuss the formal reasoning from there.
Also thinking of doing an explanatory talk about this!
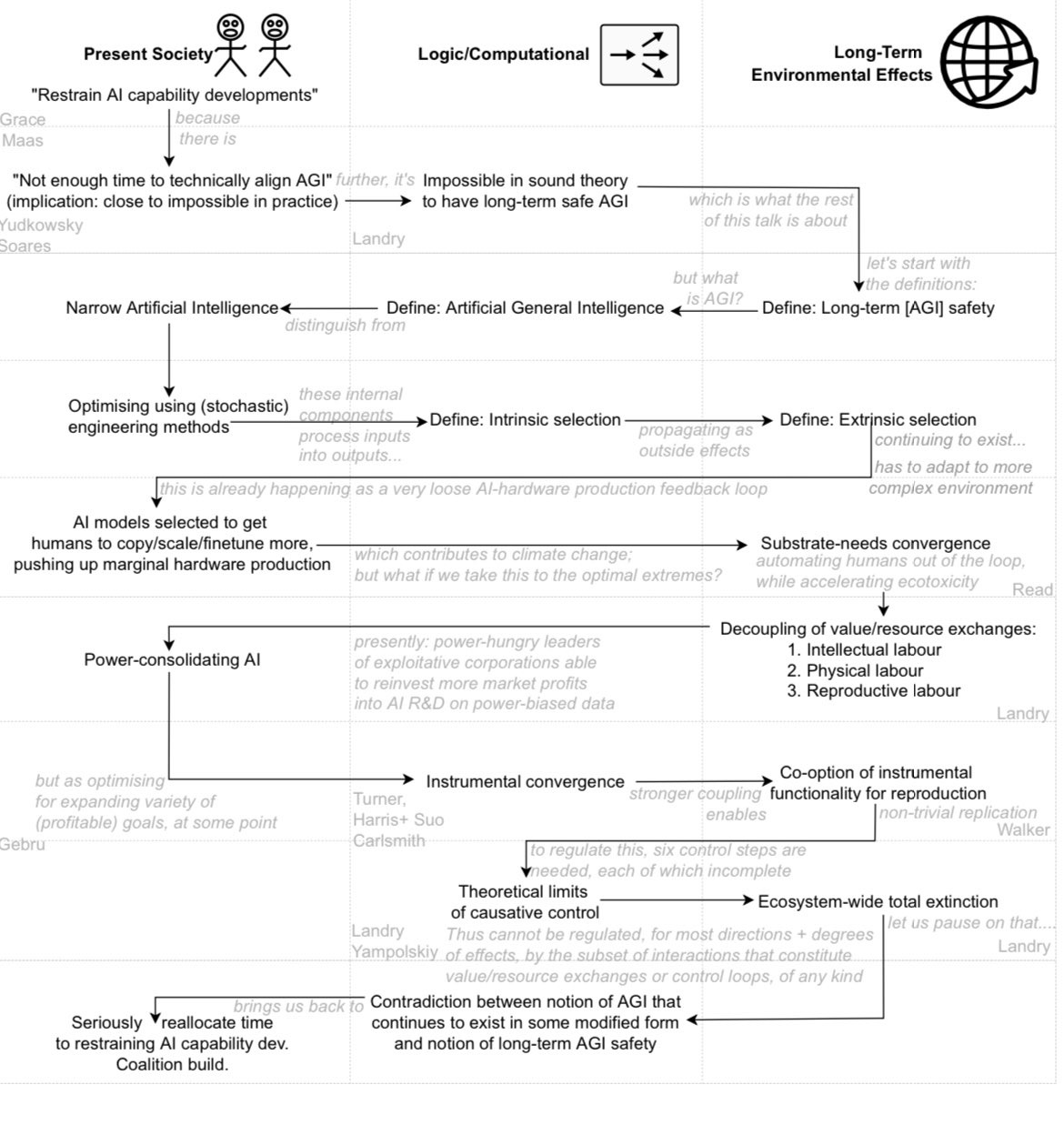
Yesterday, I roughly sketched out the "stepping stones" I could talk about to explain the arguments:
Thank you for speaking up, even as they again cast doubt: where Gregory Lewis supposed that the way to find truth was that "We could litigate which is more likely - or, better, find what the ideal 'bar' insiders should have on when to look into outsider/heterodox/whatever work, and see whether what has been presented so far gets far enough along the ?crackpot/?genius spectrum to warrant the consultation" He entirely ignores the proper 'bar' for new ideas: consideration of the details, and refutation of those details. If refutation cannot be done by them, then they have no defense against your arguments! Yet, they claim such a circumstance is their victory, by supposing that some 'bar' of opinion-mongering should decide a worthy thought. This forum is very clearly defending its 'tuft' from outsiders; the 'community' here in the Bay Area is similarly cliquish, blacklisting members and then hiding that fact from prospective members and donors.
Yes, and to be clear: we have very much been working on writing up those details in ways hopefully more understandable to AI Safety researchers.
But we are really not working in a context of "neutral" evaluation here, which is why we're not rushing to put those details out onto the Alignment/LW/EA Forum (many details though can already be found across posts on Forrest's blog).
Thank you too for responding here, Anthony. It feels tough trying to explain this stuff with people around me, so just someone pointing out what is actually needed to make constructive conversations work here is helpful.