This looks awesome and I'm looking forward to playing with it!
One minor point of feedback: I think the main web page at https://www.squiggle-language.com/, as well as the github repo readme, should have 1-3 tiny, easy-to-comprehend examples of what Squiggle is great at.
I played around with Squiggle for hours after reading the GiveDirectly uncertainty quantification, and I enjoyed it a lot. That said, what is the value add of Squiggle over probabilistic programming libraries like Stan or PyMC3? For less coding work and less complicated models, Guesstimate does fine. For more coding work and more complicated models, Stan or PyMC3 work well. Is Squiggle meant to capture the in between case of people who need to make complicated models but don't want to do a lot of coding work? Is that too niche?
I think the big-picture difference is something like, "What is the language being optimized for." When designing a language, there are a ton of different trade-offs. PPLs are typically heavily optimized for data analysis on large datasets and fancy MCMC algorithms. Squiggle is more for intuitive personal estimation.
Some specific differences:
Squiggle is optimized much more for learnability and readability (for the models that it works with). This is good for cases where we want to get people up to speed quickly, or for having others audit models.
Squiggle is in Javascript, so can run directly in the browser and other Javascript apps. (Note: WebPPL is also in JS, but is very different).
The boot-up time for Squiggle, for small models, is trivial (<100ms). For many PPLs it can be much longer (10s+).
If you're happy with using a PPL for a project, it's probably a good bet! If it really doesn't seem like a fit, consider Squiggle.
Do you have any plans for interoperability with other PPLs or languages for statistical computing? It would be pretty useful to be able to, e.g. write a model in Squiggle and port it easily to R or to PyMC3, particularly if Bayesian updating is not currently supported in Squiggle. I can easily imagine a workflow where we use Squiggle to develop a prior, which we'd then want to update using microdata in, say, Stan (via R).
I think that for the particular case where Squiggle produces a distribution (as opposed to a function that produces a distribution), this is/should be possible.
No current plans. I think it would be tricky, because Squiggle both supports some features that other PPL's don't, and because some of them require stating information about variables upfront, which Squiggle doesn't. Maybe it's possible for subsets of Squiggle code.
Would be happy to see experimentation here.
I think one good workflow would be to go the other way; use a PPL to generate certain outcomes, then cache/encode these in Squiggle for interactive use. I described this a bit in this sequence. https://www.lesswrong.com/s/rDe8QE5NvXcZYzgZ3
This looks great! I'm just starting a project that I'll definitely try it out for.
When you say it doesn't have 'robust stability and accuracy', can you be more specific? How likely is it to return bad values? And how fast is it progressing in this regard?
Squiggle is a special-purpose programming language for probabilistic estimation[1]. Think: "Guesstimate as a programming language." Squiggle is free and open-source.
Our team has been using Squiggle for QURI estimations for the last few months and found it very helpful. The Future Fund recently began experimenting with Squiggle for estimating the value of different grants.
Now we're ready for others publicly to begin experimenting with it. The core API should be fairly stable; we plan to add functionality but intend to limit breaking changes[2].
We'll do our best to summarize Squiggle for a diverse audience. If any of this seems intimidating, note that Squiggle can be used in ways not much more advanced than Guesstimate. If it looks too simple, feel free to skim or read the docs directly.
Work on Squiggle!
We're looking to hire people to work on Squiggle for the main tooling. We're also interested in volunteers or collaborators for the ecosystem (get in touch!).
Aprobabilistic programming language. Squiggle does not support Bayesian inference. (Confusingly, "Probabilistic Programming Language" really refers to this specific class of language and is distinct from "languages that allow for using probability.")
A tool for substantial data analysis. (See programming languages likePython orJulia)
A programming language for anything other than estimation.
Simple and readable syntax, especially for dealing with probabilistic math.
Fast for relatively small models. Useful for rapid prototyping.
Optimized for using some numeric and symbolic approaches, not just Monte Carlo.
Embeddable in Javascript.
Free and open-source (MIT license).
Weaknesses
Limited scientific capabilities.
Much slower than serious probabilistic programming languages on sizeable models.
Can't do backward Bayesian inference.
Essentially no support for libraries or modules (yet).
Still very new, so a tiny ecosystem.
Still very new, so there are likely math bugs.
Generally not as easy to use as Guesstimate or Causal, especially for non-programmers.
Example: Piano Tuners
Note: Feel free to skim this section, it's just to give a quick sense of what the language is.
Say you're estimating the number of piano tuners in New York City. You can build a simple model of this, like so.
// Piano tuners in NYC over the next 5 years
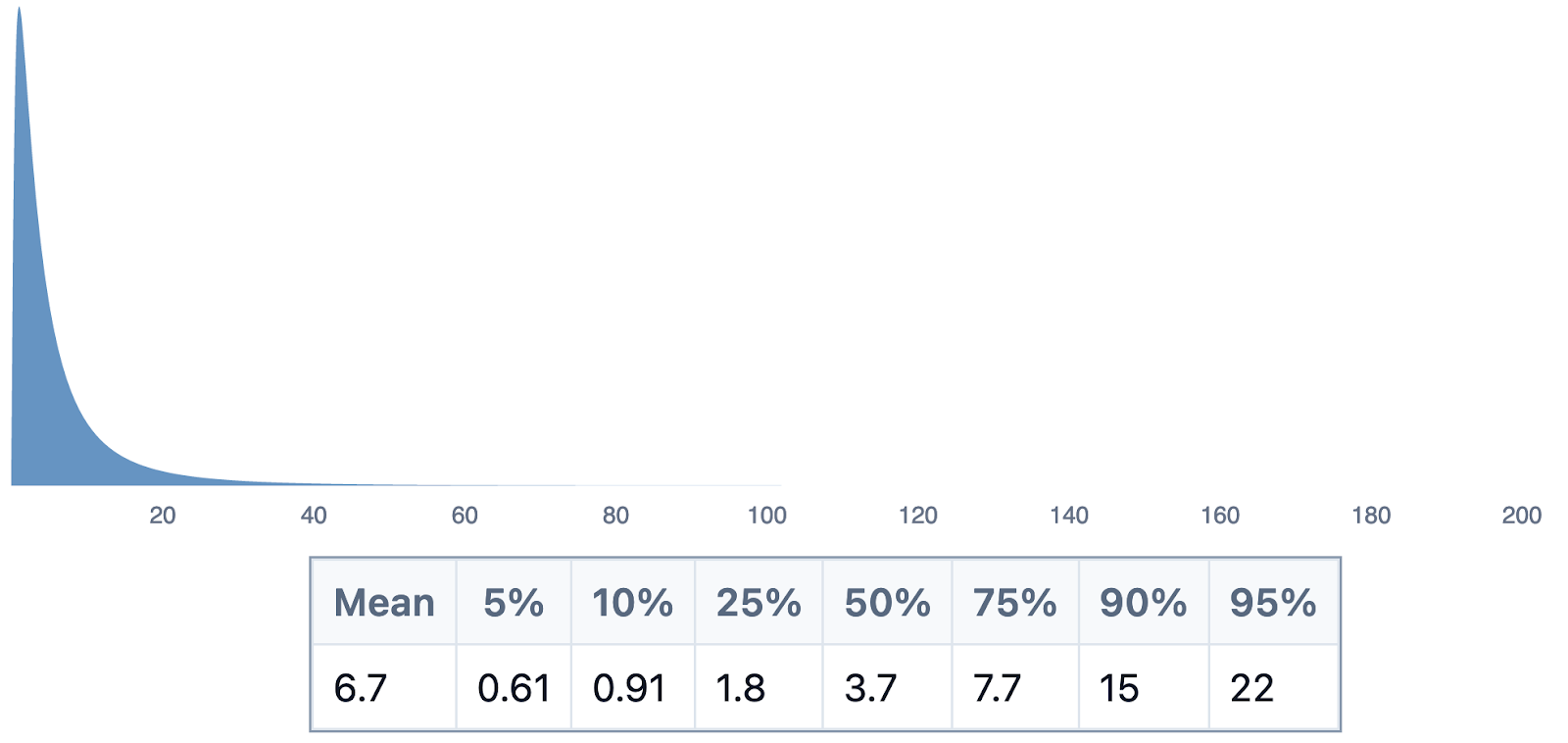
populationOfNewYork2022 = 8.1M to 8.4M // This means that you're 90% confident the value is between 8.1 and 8.4 Million.
proportionOfPopulationWithPianos = (.002 to 0.01) // We assume there are almost no people with multiple pianos
pianoTunersPerPiano = {
pianosPerPianoTuner = 2k to 50k // This is artificially narrow, to help graphics later
1 / pianosPerPianoTuner
} // This {} syntax is a block. Only the last line of it, "1 / pianosPerPianoTuner", is returned.
totalTunersIn2022 = (populationOfNewYork2022 * proportionOfPopulationWithPianos * pianoTunersPerPiano)
totalTunersIn2022
Now let's take this a bit further. Let's imagine that you think that NYC will rapidly grow over time, and you'd like to estimate the number of piano tuners for every point in time for the next few years.
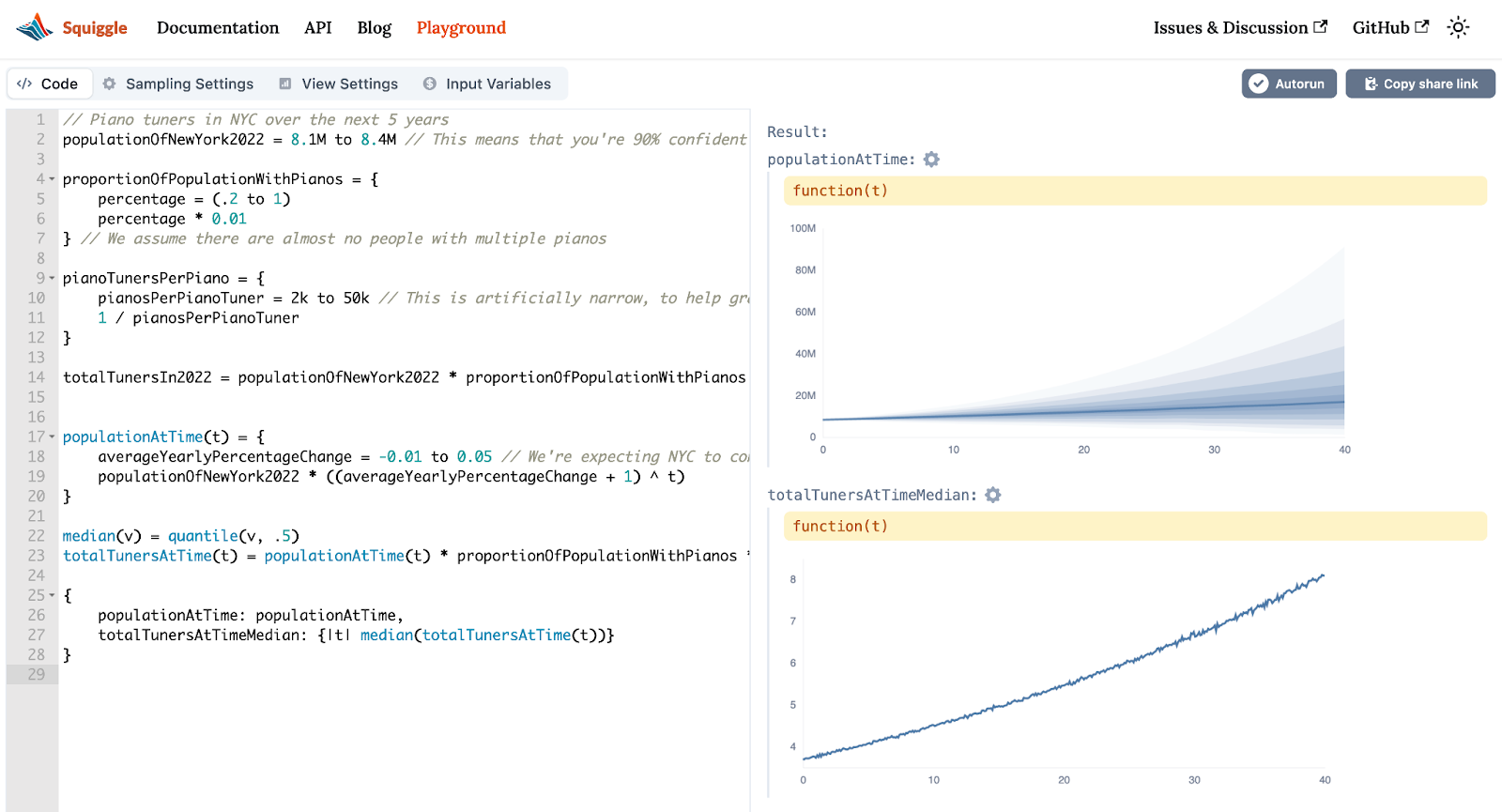
// ...previous code
//Time in years after 2022
populationAtTime(t) = {
averageYearlyPercentageChange = -0.01 to 0.05 // We're expecting NYC to continuously and rapidly grow. We model this as having a constant growth of between -1% and +5% per year.
populationOfNewYork2022 * ((averageYearlyPercentageChange + 1) ^ t)
}
median(v) = quantile(v, .5)
totalTunersAtTime(t) = (populationAtTime(t) * proportionOfPopulationWithPianos * pianoTunersPerPiano)
{
populationAtTime: populationAtTime,
totalTunersAtTimeMedian: {|t| median(totalTunersAtTime(t))}
}
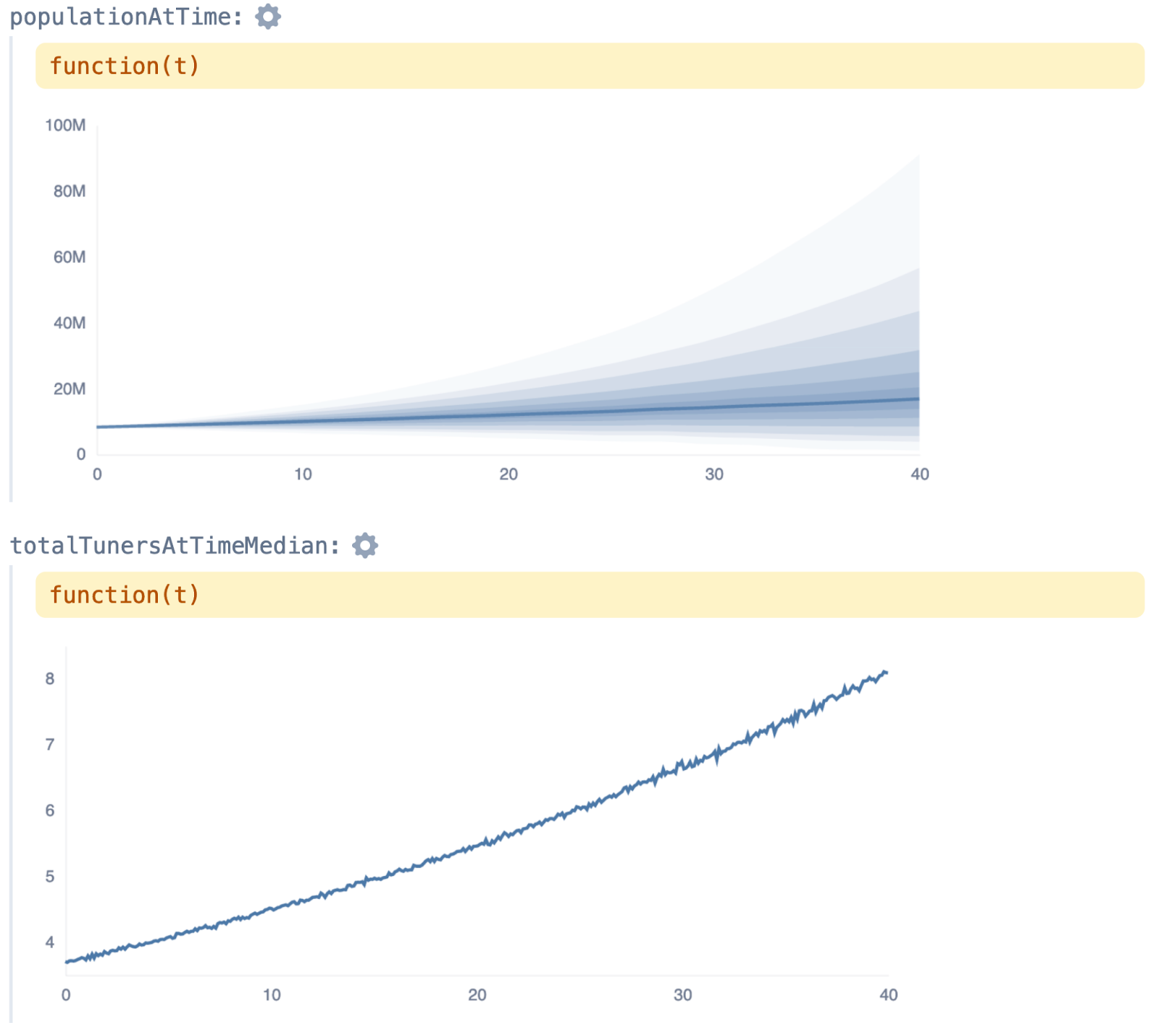
Using settings in the playground, we can show this over a 40-year period.
You can play with this directly at the playground here.
Some Playground details
If you hover over the populationAtTime variable, you can see the distribution at any point.
You can change “sample count” to change the simulation size. It starts at 1,000, which is good for experimentation, but you’ll likely want to increase this number for final results. The above graphs used sampleCount=1,000,000.
If you want to get ambitious, you can. Consider changes like:
Instead of doing the estimate for New York City, parameterize it to work for any global city.
Instead of just estimating the number of piano tuners, add a parameter to estimate most professions.
Instead of time being "years from 2022", change it to be a Time value. Allow times from 0AD to 3000AD.
Add inputs for future conditionals. For example, job numbers might look different in worlds with intense automation.
Using Squiggle
You can currently interact with Squiggle in a few ways:
There's a simpleVirtual Studio Code extension for running and visualizing Squiggle code. We find that VS Code is a helpful editor for managing larger Squiggle setups.
(This example is a playful, rough experiment of an estimate of Ozzie's life output.)
Squiggle is built usingRescript, and is accessible via a simple Typescript library. You can use this library to either run Squiggle code in full, or to call select specific functions within Squiggle (though this latter functionality is very minimal).
All of the components used in the playground and documentation are available in a separate component NPM repo. You can see the full Storybook of componentshere.
We're calling this version "Early Access." It's more stable than some alphas, but we'd like it to be more robust before a public official beta. Squiggle is experimental, and we plan on trying out some exploratory use cases for effective altruist use cases for at least the next several months. You can think of it like some video games in "early access"; they often have lots of exciting functionality but deprioritize the polish that published games often have. Great for a smaller group of engaged users, bad for larger organizations that expect robust stability or accuracy.
Should effective altruists really fund and develop their own programming language?
It might seem absurd to create an "entire programming language" that's targeted at one community. However, after some experimentation and investigation, we concluded that it seems worth trying. Some points:
Domain-specific languages are already fairly common for sizeable companies with specific needs. They can be easier to build than one would think.
We don't need a large library ecosystem. Much of the difficulty for programming languages comes from their library support, but the needs for most Squiggle programs are straightforward.
The effective altruist community looks pretty unusual in its interest in probabilistic estimation, so it's not surprising that few products are a good fit.
The main alternative options are proprietary and expensive risk analysis tools. It seems critical to have our community's models be public and easy to audit. Transparency doesn't work well if models require costly software to run.
Much of the necessary work is in making decent probability distribution tooling for Javascript. This work itself could have benefits for forecasting and estimation websites. The "programming language" aspects might only represent one half the work of the project.
Questions & Answers
What makes Squiggle better than Guesstimate?
Guesstimate is great for small models but can break down for larger or more demanding models. Squiggle scales much better.
Plain text formats also allow for many other advantages. For example, you can use Github workflows with versioning, pull requests, and custom team access.
Should I trust Squiggle calculations for my nuclear power plant calculations?
No! Squiggle is still early and meant much more for approximation than precision. If the numbers are critical, we recommend checking them with other software. See this list of key known bugs and this list of gotchas.
Can other communities use Squiggle?
Absolutely! We imagine it could be a good fit for many business applications. However, our primary focus will be on philanthropic use cases for the foreseeable future.
Is there an online Squiggle community?
There's some public discussion on Github. There's also a private EA/epistemics Slack with a few channels for Squiggle; message Ozzie to join.
Future Work
Again, we're looking to hire a small team to advance Squiggle and its ecosystem. Some upcoming items:
Improve the core of the language. Add error types, improve performance, etc.
Import functionality to allow Squiggle models to call other datasets or other Squiggle models.
Command line tooling for working with large Squiggle codebases.
Public web applications to share and discuss Squiggle models and values.
Integration with forecasting platforms so that people can forecast using Squiggle models. (Note: If you have a forecasting platform and are interested in integrating Squiggle, please reach out!)
Integration with more tools. Google Docs, Google Sheets, Airtable, Roam Research, Obsidian, Python, etc. (Note: This is an excellent area for external help!)
Make web components for visualization and analysis of probability distributions in different circumstances. Ideally, most of these could be used without Squiggle.
Contribute to Squiggle
If you'd like to contribute to Squiggle or the greater ecosystem, there's a lot of neat stuff to be done.
Build integrations with other tools (see "Future Work" section above).
Give feedback on the key features and the tools. (Particularly useful if you have experience with programming language design.)
Suggest new features and report bugs.
Audit and/or improve the internal numeric libraries.
Make neat models and post them to the EA Forum or other blogs.
Experiment with Squiggle in diverse settings. Be creative. There must be many very clever ways to use it with other Javascript ecosystems in ways we haven't thought of yet.
Build tools on top of Squiggle. For example, Squiggle could help power a node-based graphical editor or a calendar-based time estimation tool. Users might not need to know anything about Squiggle; it would just be used for internal math.
Implement Metalog distributions in Javascript. We really could use someone to figure this one out.
Make open-source React components around probability distributions. These could likely be integrated fairly easily with Squiggle.
If funding is particularly useful or necessary to any such endeavor, let us know.
Right now Squiggle is in version 0.3.0. When it hits major version numbers (1.0, 2.0), we might introduce breaking changes, but we’ll really try to limit things until then. It will likely be three to twenty months until we get to version 1.0.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...




This looks awesome and I'm looking forward to playing with it!
One minor point of feedback: I think the main web page at https://www.squiggle-language.com/, as well as the github repo readme, should have 1-3 tiny, easy-to-comprehend examples of what Squiggle is great at.
Good point! I'll see about adding more strong examples. I think we could add a lot to improve documentation & education.
One example you might find useful was generated here, where someone compared Squiggle to a Numpy implementation. It's much simpler.
https://forum.effectivealtruism.org/posts/ycLhq4Bmep8ssr4wR/quantifying-uncertainty-in-givewell-s-givedirectly-cost?commentId=i9xfwkxfimEALFGcq
Comment link above not working for me, should be: https://forum.effectivealtruism.org/posts/ycLhq4Bmep8ssr4wR/quantifying-uncertainty-in-givewell-s-givedirectly-cost?commentId=i9xfwkxfimEALFGcq