Comments

I think it's possible to accomplish the desired goals. To do so, we'd need to include information about co-morbidity, secondary conditions, related life problems and general life problems in the data. Here, I explain why including all of this data can help serve goals better.
Consider Including Co-morbidity, Secondary Conditions and Related Life Problems:
Co-morbidity: It's not uncommon for people with a serious illness to have one or more additional illnesses. People can even get two disabling conditions at once. For an example of a disabling disease that tends to co-occur with other diseases: depression, one of the most deadly and disabling diseases for the younger age range, tends to co-occur with anxiety.
Related Life Problems: One serious problem can cause a snowball effect of other problems. In the case of disability, you're likely to experience joblessness, poverty and social issues (like exhausting your social safety net, being treated differently, being seen as unattractive by a partner or potential partners). These can result in worsening the original problem by reducing the finances and social support available.
Secondary Conditions: Being disabled, poor, and having social issues, one might find that they also develop depression and/or anxiety. A stressful life may result in additional health risks on top of that, accelerating the pace at which one's health breaks down as they age.
Why include additional problems?
Some people would not be disabled if they had only one condition, but ended up disabled because they have three or four conditions. These people might be low-hanging apples (easier to get above the disability line) but they could be missed if you don't design a method that's intended to capture their data.
If you want to have data that tells you how bad each person's situation is, we can't use a method that assumes the person has only one serious problem. We need this information for that purpose. We cannot assume that most people in a bad situation have only one disadvantage. Some of them have five or ten.
If what you want was an idea of how disabilities impact people, using a method that assumes only one disability won't give you an accurate picture of the reality of disability.
When people have multiple problems, they may answer questions like the trade-off questions differently. Miserable people may have a difficult time figuring out exactly which of their three problems caused the misery they're experiencing and may attribute some misery to a specific disability when it is actually coming from somewhere else.
Idea: Give them a survey of life problems in general.
I think one of the main reasons altruistic programs designed to help disadvantaged people aren't more successful is because they don't account for the fact that a lot of people who are disadvantaged deal with multiple disadvantages at once. A situation of multiple disadvantages can result in a very tangled web of problems that isn't solved with just one form of assistance. Sometimes one form of assistance might fix a person's whole life because all of their problems were caused by the one disadvantage. Sometimes, things are so brutally tangled that you'd really need to tackle three or four things to get the person out and start seeing real results in terms of happiness and productivity increases.
Why I suggest this survey:
You can look for patterns in this data and create theories like "Such and such disability usually causes poverty, the combination of poverty and disability usually causes depression." and, after investigating this to test your ideas, realize that there are certain things you could target that could solve multiple problems at once. This data could turn up super effective ways of helping.
This data could allow you to get closer to showing your true effectiveness. This is because it's a starting point for quantifying the benefits of solving other problems that were caused by the disability you were treating.
You'd have additional information that will help you work out which people's situations have the most room for improvement. There may be patterns correlated with certain diseases where some diseases tend to cause five additional problems while others cause only one. If your terminal goal is to improve people's lives as much as possible, you'd of course want to consider targeting these.
You'd be able to start looking for multiplier effects between specific problems where one problem causes the other problem to be more difficult to solve. Then we might be able to detect those "tangled webs" that are tough to solve with only one form of assistance. Knowing about some of the "tangled webs" might provide a sort of low-hanging apple to increase effectiveness. For example, say that someone has both a disability and depression. The treatment for the disability takes time and energy. Maybe the person doesn't have enough time and energy to do their part of the treatment because they're depressed. Ensuring that they have an effective depression treatment first could boost effectiveness of the program to treat the disability.
Those lucky enough to have an opportunity to help others sometimes haven't been through anything remotely similar to what the most disadvantaged 10% of the population experiences. Therefore, they may not have a very good idea of what that's actually like and how life for those people actually works. If altruists had a chart showing the distribution of problems across the population, they'd have a clearer picture of the world they're working with and the problems they're trying to solve. If they had notions about "tangled webs" and specific ideas about common webs, and how the most common webs work, they'd be getting closer to an accurate map of the problems they're trying to solve. This information will help altruists avoid a "let them eat cake" situation where they're creating programs that are ineffective because they're assuming the person has other resources available (like a social safety net, adequate funds for treatment supplies, a suitable home in which to do treatments, sufficient energy, etc.) when they actually don't.
Note: There are probably difficulties involved with providing multiple forms of assistance at once which one would need to be aware of before beginning. For instance, some disadvantaged people may not have enough time and energy to solve multiple life problems at one time, so some of those additional forms of assistance may need to be geared for people who are taking on a difficult recovery process already. Some people with disabilities will find some programs difficult to stick to. There's a question of "Which form of assistance should be done first?" By this I mean that you might need to recommend whichever one is more feasible for the person to accomplish given their current time and energy resources, or whichever one will make other forms of assistance easier for them to handle.
A New Quantification System:
If we do enough research to discover which additional problems are caused by disabilities, we can use this as a way of quantifying the level of difficulty the disability causes. Using this, we could create a more objective survey to quantify disabilities that asks them about whether they have certain life problems, secondary conditions, etc. Many of those problems and conditions can be quantified in some way that is far less subjective than "Would you take a 20% risk of death?". Poverty can be quantified as a number of dollars, time poverty as a number of hours, social support as a number of people willing to help (at how many hours per week), and secondary conditions can often be quantified in fairly objective terms as well. By tracking as many problems caused by the disability as possible, I think we can get reasonably close to a clear picture of how bad a disability is.
It seems to me that this might make a good article. I don't have sufficient karma to post it. What do you think, readers?


Thanks for this great summary Jeff!
Here are a couple of comments:
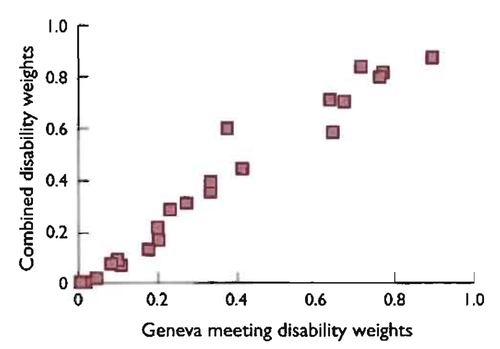
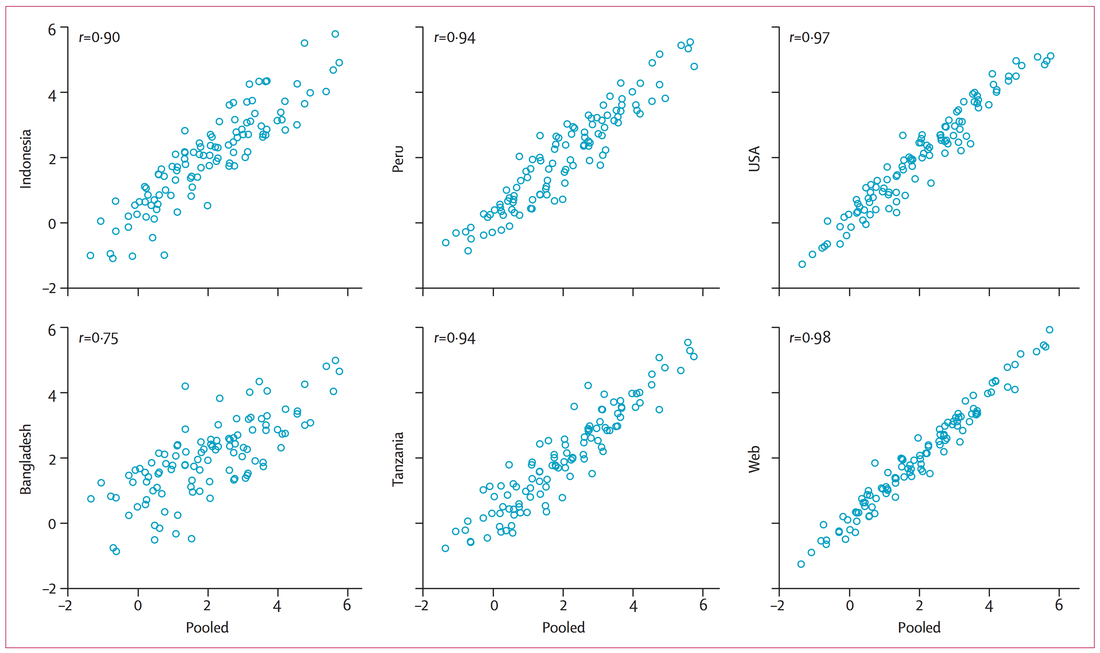
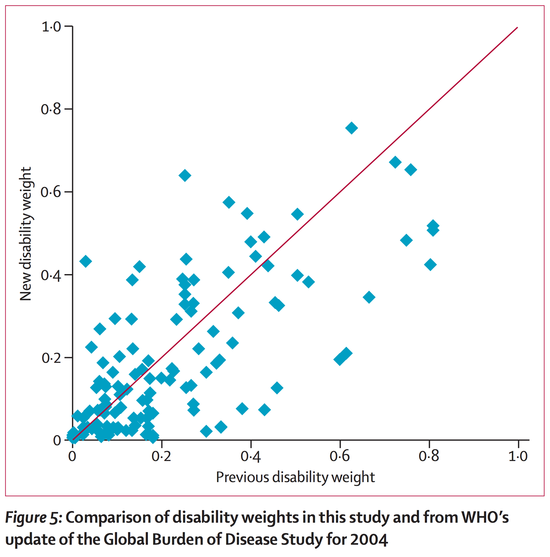
1) I happen to know quite a bit about the rationale behind the GBD 2010 method as I was involved near the end of the process. It is designed to avoid talking about evaluative questions of the quality or value of life and to only talk about the descriptive question of the level of health -- something that doctors are meant to plausibly have more expertise on. This change avoids certain critiques of the method, but I and many other philosophers and economists think that it is quite a bit worse overall and possibly incoherent. At least for effective altruism, we only care about health states in terms of answering normative questions of which option to choose and here we care about the evaluative measures of quality. Notably these come apart from the descriptive ones in cases like intellectual disability and infertility. People don't rate people with these conditions as much less healthy, but they do agree that their lives are made quite a bit worse. When things come apart like this, it is the badness in their lives that should matter. I was more sanguine about this before I read your article as I'd heard there was at least a strong correlation between these new numbers and the old ones, but your quantitative correlation chart shows that it is not that strong. I'd thus use one of the earlier approaches, or one of the many QALY type approaches that have been done in parallel with these DALY ones.
2) Regarding scepticism about the weightings, it is not like there is any other sensible option but to use them (well, one version or another of them). Using one's own intuition about how bad two health states are is obviously worse than at least one of the current aggregate measures, as is considering all ill-health to be equally bad. Rejecting these aggregate health quality weights means using some other form of health quality weight which will be worse. It is OK to think that these quality weight numbers introduce another level of noise into cost-effectiveness -- they do! -- and we don't have any better options but to use them. Also, the noise introduced is not all that much compared to the signal (I'd say it introduces less than a factor of 2, when the data shows many things separated by factors of 100 or more), so the results can still be used for many purposes.
I agree with this and think it's important enough to highlight.