This comment completely ignores all of the good and strong, and highly compelling points you no doubt made in this post, that I didn't read.
Calling OOM a 'made up unit', as someone who has spent a lot of time around math and who perfectly well understands what it means -- ie 'an order of magnitude increase in something', or alternatively 'the number of OOMs is the number of times a value increases by roughly 10x', suggests to me that you are either not terribly technical and mathy, or that you are focused on the sort of nitpicking that obscures your actual counter argument rather than making it clear.
I of course could be wrong on those points. I don't know. I didn't read the essay. But even if I am wrong, it was probably a bad move to argue that a turn of phrase which is both clear, and in fairly common usage in technical spaces is a term whose use should make me think less of an author.
The problem is not what "order of magnitude" means in general. The problem is that the text leaves it unclear what is being measured. Order of magnitude of what? Compute? Effective compute? Capabilities?
What I meant by "made up" is that it's not any real, actual thing which we can measure. It is not a technical/mathematical unit, it is a narrative unit. The narrative is that something (effective compute, capabilities or some other ill-defined thing) grows exponentially. It is a story, not a real technical argument substantiated by real-life evidence. As I say in my text, many of the examples given by him are actually counterexamples to the presented argument.
So "made up" means "exist inside the narrative" instead of "exist in the real world". I should have made this point clearer in my post, or figure out a better word than "made up".
Thank you for writing this criticism! I did give it a read, and I shared some of your concerns around the framing and geopolitical stance that the piece takes.
Regarding the OOM issue, you ask:
Order of magnitude of what? Compute? Effective compute? Capabilities?
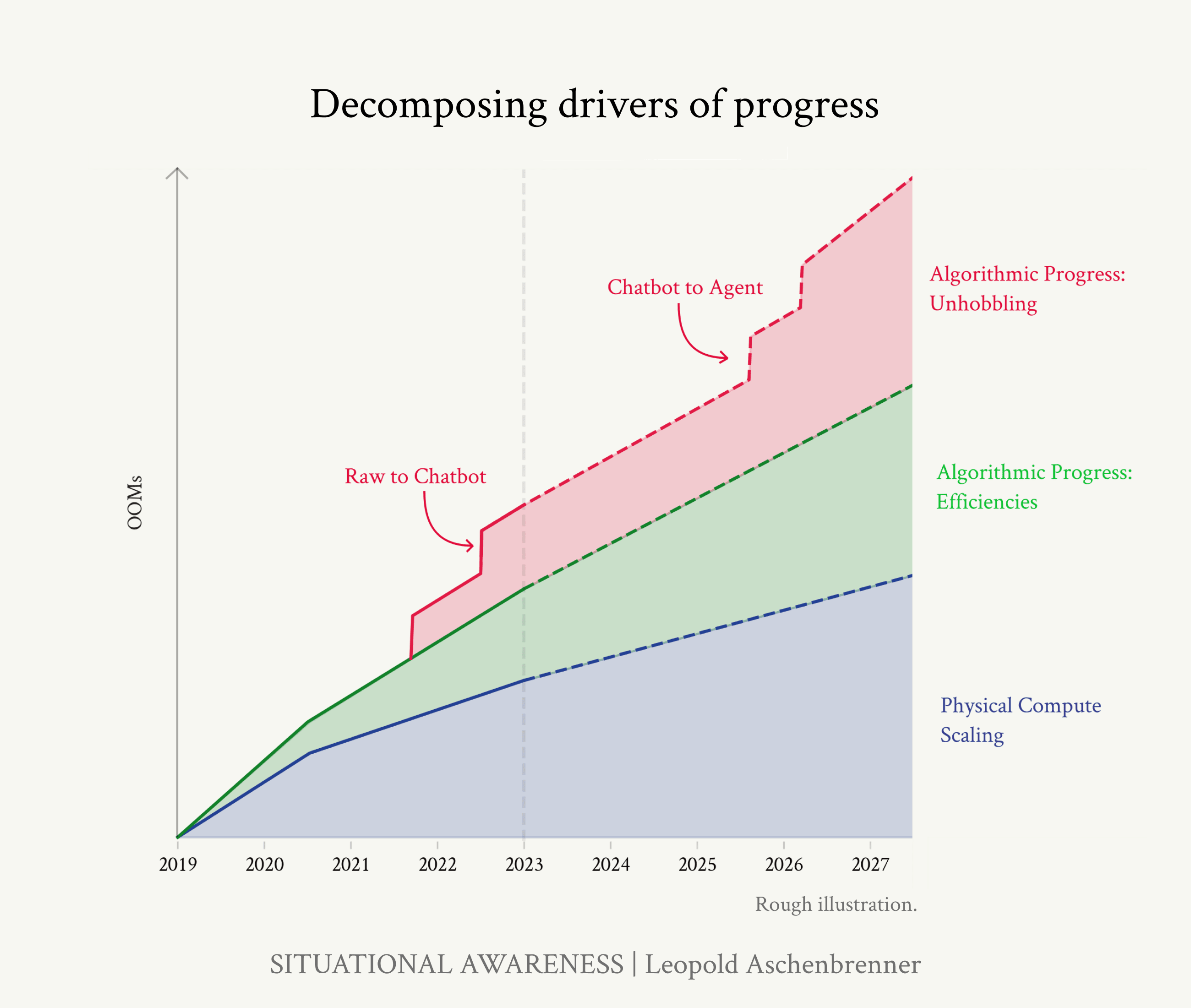
I'll excerpt the following from the "count the OOMs" section of the essay:
We can decompose the progress in the four years from GPT-2 to GPT-4 into three categories of scaleups:
Compute: We’re using much bigger computers to train these models.
Algorithmic efficiencies: There’s a continuous trend of algorithmic progress. Many of these act as “compute multipliers,” and we can put them on a unified scale of growing effective compute. ”
Unhobbling” gains: By default, models learn a lot of amazing raw capabilities, but they are hobbled in all sorts of dumb ways, limiting their practical value. With simple algorithmic improvements like reinforcement learning from human feedback (RLHF), chain-of-thought (CoT), tools, and scaffolding, we can unlock significant latent capabilities.
We can “count the OOMs” of improvement along these axes: that is, trace the scaleup for each in units of effective compute. 3x is 0.5 OOMs; 10x is 1 OOM; 30x is 1.5 OOMs; 100x is 2 OOMs; and so on. We can also look at what we should expect on top of GPT-4, from 2023 to 2027.
It's clear to me what Aschenbrenner is referring to when he says "OOMs" — it's orders of magnitude scaleups in the three things he mentions here. Compute (measured in training FLOP), algorithmic efficiencies (measured by looking at what fraction of training FLOP is needed to achieve comparable capabilities following algorithmic improvements), and unhobbling (as measured, or rather estimated, by what scaleup in training FLOP would have provided equivalent performance improvements to what was provided by the unhobbling). I'll grant you, as does he, that unhobbling is hand-wavy and hard to measure (although that by no means implies it isn't real).
You could still take issue with other questions —as you do — including how strong the relationship is between compute and capabilities, or how well we can measure capabilities in the first place. But we can certainly measure floating point operations! So accusing him of using "OOMs" as a unit, and one that is unmeasurable/detached from reality, surprises me.
Also, speaking of the "compute-capabilities relationship" point, you write:
The general argument seems to be that increasing the first two "OOMs", i.e. increasing compute and improving algorithms, the AI capabilities will also increase. Interestingly, most of the examples given are actually counterexamples to this argument.
This surprised me as well since I took the fact that capabilities have improved with model scaling to be pretty incontrovertible. You give an example:
There are two image generation examples (Sora and GANs). In both examples, the images become clearer and have higher resolution as compute is increased or better algorithms are developed. This is framed as evidence for the claim that capabilities increase as "OOMs" increase. But this is clearly not the case: only the fidelity of these narrow-AI systems increase, not their capabilities.
I think I might see where the divergence between our reactions is. To me, capabilities for an image model means roughly "the capability to generate a clear, high-quality image depicting the prompt." As you admit, that has improved with scale. I think this definition probably best reflects common usage in the field, so I do think it supports his argument. And, I personally think that there are deeper capabilities being unlocked, too — for example, in the case of Sora, the capability of understanding (at least the practical implications of) object permanence and gravity and reflections. But I think others would be more inclined to disagree with that.
Yeah, with the word "capability" I meant completely new capabilities (in Aschenbrenner's case, the relevant new capabilities would be general intelligence abilities such as the learning-planning ability), but I can see that for example object permanence could be called a new capability. I maybe should have used a better word there. Basically, my argument is that while the image generators have become better at generating images, they haven't gotten anything that would take them nearer towards AGI.
I'll grant you, as does he, that unhobbling is hand-wavy and hard to measure (although that by no means implies it isn't real).
I'm not claiming that unhobbling isn't real, and I think that the mentioned improvements such as CoT and scaffolding etc. really do make models better. But do they make them exponentially better? Can we expect the increases to continue exponentially in the future? I'm going to say no. So I think it's unsubstantiated to measure them with orders of magnitude.
But we can certainly measure floating point operations! So accusing him of using "OOMs" as a unit, and one that is unmeasurable/detached from reality, surprises me.
Most of the time, when he says "OOM", he doesn't refer to FLOPs, he refers to the abstract OOMs that somehow encompass all three axes he mentioned. So while some of it is measurable, as a whole it is not.
Again 'order of magnitude' is a very clear mathematical concept. I think what you mean is that orders of magnitude equivalent from unhobbling is a made up thing, and that there is a story being told about increases in compute / algorithmic efficiency which might not match what will happen in the real world, and where the use of this concept is part of an exercise in persuasive story telling
It promotes the idea of spending considerable state resources, i.e. tax payer money, for building massive computing clusters in the US, while at the same time denying the knowledge required to build AI models from non-American people and companies.
I'm Leopold Aschenbrenner. I recently founded an investment firm focused on AGI.
As you say, the whole set of writings has a propaganda (marketing) tone to it, and a somewhat naive worldview. And the temporal coincidence of the essays and the investment startup are likely not accidental. I'm surprised it got the attention it did given, as you say, the sort of red-flag writing style of which we are taught to be skeptical. Any presentation of these essays should be placed alongside the kind of systematic skepticism of eg Gary Marcus et al. for readers to draw their own conclusions.
Unfortunately, most of Aschenbrenner's claims seem highly plausible. AGI is a huge deal, it could happen very soon, and the government is very likely to do something about it before it's fully transformative. Whether them spending tons of money on his proposed manhattan project is the right move is highly debatable, and we should debate it.
This is an excellent essay, superbly reasoned and articulated. In particular, I think you did a fantastic job teasing out the distinction between intelligence as the ability to learn vs. intelligence as the ability to complete some task. Competing definitions of intelligence cause fundamental conceptual problems with accounts of AGI and our path to it. I thought it was extremely perceptive when you pointed out how "Situational Awareness" implicitly uses one definition when it supports the narrative and another definition when that supports the narrative, and this leads to the narrative contradicting itself. Well done!
I think your technical criticisms are extremely strong. Leopold Aschenbrenner's weird conversion of human brainpower into LLMs tokens/minute and his completely unrigorous and non-credible claims about unhobbling are quintessential examples of how so much of the discourse about the prospects of near-term AGI is based on hazy, sloppy reasoning. In these instances, he is truly just making stuff up.
Your criticism of the OOMs graphs is funny. These graphs are more diagrams or sketches used for rhetorical purposes rather than real graphs in the sense of representing real numbers gleaned empirically. In principle, it might be okay in some contexts to sketch a made-up graph just to illustrate a concept (I have done this and been very clear this is all I'm doing), but a) we should be cautious about the use of graphs giving an argument or a narrative the impression of being scientific or evidence-based when it isn't and b) if an argument or narrative relies on made-up graphs, that shows the weakness in the argument/narrative. The ambiguity about what the graphs are even measuring is funny. You wouldn't just write "hundreds" or "thousands" on a graph (hundreds or thousands of what?), you would note what the unit of measurement is. The same should apply regardless of what the numbers are or whether the graph is logarithmic.
It's implied that whatever is increasing by OOMs will lead to a commensurate amount of capabilities or intelligence, but that does not necessarily follow and needs an argument. For example, what if scaling compute leads to steeply diminishing returns? What if there is simply no path from increasing the compute used in narrow AI to AGI? (In that case, you might as well be scaling the OOMs of compute used to mine Bitcoin, for all that it's going to get you to AGI.) Measurements of algorithmic efficiency are tied to specific definitions of performance, and that should be spelled out. How do those definitions of performance relate to AGI? What benchmarks or tests are we using and why are those the important ones for understanding the prospects of near-term AGI?
I also find your analysis of the conspiracy theory-like rhetoric on point. Rhetoric that provokes fear or excitement, or that gives readers the sense that they're accessing secret knowledge, can blunt people's desire to dig into the technical arguments. Given that the flaws in the technical arguments are so glaring yet "Situational Awareness" is still influential in certain circles, should I worry that's what's happening?
Executive summary: The "Situational Awareness" essay series by Leopold Aschenbrenner contains flawed arguments and questionable narratives that are harmful to the AI safety community despite the author's likely honest intentions.
Key points:
The text uses conspiracy-esque narratives framing the author as part of a small enlightened group that knows the truth, discrediting opposing views.
The geopolitical analysis is overly US-centric, framing China and the Middle East as incapable enemies while ignoring Europe's role, reading more as a nationalist piece than a rational argument.
The central AGI narrative compares AI progress to human development from preschool to university, but is inconsistent and relies on a dubious "unhobbling" concept to avoid addressing the lack of key abilities like learning-planning in current AI.
The definition of AGI used is contradictory, excluding human-level AIs below the "PhD/expert" level without justification.
The text builds on questionable narratives, nationalist feelings, and low-quality argumentation rather than solid technical or geopolitical analysis, advocating for decisions that require stronger evidence given their radical nature.
The author's technical arguments regarding RLHF, "OOMs", "unhobbling", and comparisons to human intelligence are weak or flawed.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
This post can be summarized as "Aschenbrenner's narrative is highly questionable". Of course it is. From my perspective, having thought deeply about each of the issues he's addressing, his claims are also highly plausible. To "just discard" this argument because it's "questionable" would be very foolish. It would be like driving with your eyes closed once the traffic gets confusing.
This is the harshest response I've ever written. To the author, I apologize. To the EA community: we will not help the world if we fall back on vibes-based thinking and calling things we don't like "questionable" to dismiss them. We must engage at the object level. While the future is hard to predict, it is quite possible that it will be very unlike the past, but in understandable ways. We will have plenty of problems with the rest of the world doing its standard vibes-based thinking and policy-making. The EA community needs to do better.
There is much to question and debate in Aschenbrenner's post, but it must be engaged with at the object level. I will do that, elsewhere.
On the vibes/ad-hominem level, note that Aschenbrenner also recently wrote that Nobody’s on the ball on AGI alignment. He appears to believe (there and elsewhere) that AGI is a deadly risk, and we might very well all die from it. He might be out to make a quick billion, but he's also serious about the risks involved.
The author's object-level claim is that they don't think AGI is immanent. Why? How sure are you? How about we take some action or at least think about the possibility, just in case you might be wrong and the many people close to its development might be right?
It seems to me that you are missing my point. I'm not trying to dismiss or debunk Aschenbrenner. My point is to call out that what he is doing is harmful to everyone, including those who believe AGI is imminent.
If you believe that AGI is coming soon, then shouldn't you try to convince other people of this? If so, shouldn't you be worried that people like Aschenbrenner ruin that by presenting themselves like conspiracy theorists?
We must engage at the object level. [...] We will have plenty of problems with the rest of the world doing its standard vibes-based thinking and policy-making. The EA community needs to do better.
Yes! That is why what Aschenbrenner is doing is so harmful, he is using an emotional or narrative argument instead of a real object-level argument. Like you say, we need to do better.
The author's object-level claim is that they don't think AGI is immanent. Why? How sure are you? How about we take some action or at least think about the possibility [...]
I have read the technical claims made by Aschenbrenner and many other AI optimists, and I'm not convinced. There is no evidence for any kind of general intelligence abilities surfacing in any of the current AI systems. People have been trying to do that for decades, and for the part couple of years, but there has been almost no progress on that front at all (in-context learning is one of the biggest ones I can think, and it can hardly even be called learning). While I do think that some action can be taken, what Aschenbrenner suggests is, as I iterate in my text, too much given our current evidence. Extraordinary claims require extraordinary evidence, as it is said.
Questionable Narratives of "Situational Awareness"
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
This is a response to the Situational Awareness essay series by Leopold Aschenbrenner. As a disclaimer, I am an AI pessimist, meaning that I don't believe there is evidence for AGI appearing any time soon. I do also believe that even if you are an AI optimist, you should view Aschenbrenner's text critically, as it contains numerous flawed arguments and questionable narratives, which I will go through in this post.
The text has numerous dubious technical claims and flawed arguments, including misleading statements regarding RLHF[1], uncited claims of human intelligence[2], use of nebulous units such as OOM[3] without any serious technical argumentation, use of made-up charts that extrapolate these made-up units, claims that current models could be "unhobbled"[4], and baseless claims such as that current AI is at the level of a preschooler or a high school student[5]. I have given some thoughts on these in the footnotes, although I don't consider myself the best person to criticize them. Instead, I will be focusing more on the narrative structure of the text, which I think is more important than the technical part.
After reading this text, it gave me heavy propaganda-vibes, as if it were a political piece that tries to construct a narrative that aims to support certain political goals. Its technical argumentation is secondary to creating a compelling narrative (or a group of narratives). I will first go through the two most problematic narratives, the conspiracy-esque and US-centric narratives. Then, I will talk a bit about the technological narrative, which is the main narrative of the text.
I stress that I don't necessarily believe that there is any malign intent behind these narratives, or that Aschenbrenner is trying to intentionally mislead people with them. However, I believe they should be pointed out, as I think these narratives are harmful to the AI safety community. The concepts of AGI and intelligence explosion are outlandish and suspicious to people not accepting them. Using narratives often utilized by bad-faith actors makes it easier for readers to just discard what is being said.
Conspiracy narratives
The text opens with a description of how the writer is part of a very small group of enlightened people who have learned the truth:
Before long, the world will wake up. But right now, there are perhaps a few hundred people, most of them in San Francisco and the AI labs, that have situational awareness. Through whatever peculiar forces of fate, I have found myself amongst them. [...] Perhaps they will be an odd footnote in history, or perhaps they will go down in history like Szilard and Oppenheimer and Teller. If they are seeing the future even close to correctly, we are in for a wild ride.
This invokes a conspiracy theory narrative that the world is "asleep" and must "wake up", and only a small group of conspirators and enlightened individuals know what is really going on. This is then compared to real-life "conspiracies" such as the Manhattan project to draw credibility for such narratives while ignoring the clear differences to them, such that the Manhattan project was a highly-organized goal-directed attempt to construct a weapon, which is not remotely similar to the decentralized actors currently developing AI systems. Later in the text, a hypothetical "AGI Manhattan Project" is described, further trying to frame the current AI discussion as being similar to the discussion that happened the couple of years before the Manhattan project in real life. Again, this ignores the fact that AI is being researched by thousands of people across the world, both in universities and in companies, and it has clear commercial value, while the late 1930's research on nuclear chain reactions was comparatively more centralized and smaller-scale.
These kinds of arguments are harmful to the discussion, as they frame other commenters as part of the "sleeping mass" missing vital information, thus discrediting their opinions. Instead of arguing against the facts presented by those having opposed views, it shuns them as incapable of taking part in the discourse due to their lack of "situational awareness". This is a common tactic used by conspiracy theorists to explain the lack of general acceptance of their theory.
US-centric narratives
America must lead. The torch of liberty will not survive Xi getting AGI first. (And, realistically, American leadership is the only path to safe AGI, too.) That means we can’t simply “pause”; it means we need to rapidly scale up US power production to build the AGI clusters in the US. But it also means amateur startup security delivering the nuclear secrets to the CCP won’t cut it anymore, and it means the core AGI infrastructure must be controlled by America, not some dictator in the Middle East. American AI labs must put the national interest first.
(emphasis original)
The text is extremely US-centric and frames AGI as a national security issue to the US, and China and Middle Eastern countries as the enemies. These countries are framed as incapable of researching AI themselves, instead, the main risk seen is that they somehow steal the US discoveries[6], despite the fact that those countries have many brilliant researchers who have contributed a lot of scientific results which enable US companies too to build more advanced systems. Although US researchers have recently published most of the breakthroughs, there is no reason to believe that Chinese researchers, for example, are any less competent, and given enough resources (which China has), underestimating them seems like a serious inconsideration.
Moreover, the role of Europe is completely ignored by the author: for example, the text discusses computer clusters and whether they are built in the US or in Middle Eastern dictatorships. This ignores the fact that many of these clusters are built in Europe: are they of concern? It is true that currently European AI companies are behind US companies, but with the rate in which the field is developing, this might also change. Furthermore, Europe has been the forerunner of AI regulation with the AI Act that was recently approved by the EU legislative organs. Against that background, the claim that "American leadership is the only path to safe AGI" isn't that obvious, as the actions of the US have demonstrated a lack of willingness to regulate AI. Even if the author believes that the role of Europe is irrelevant, this should at least be addressed in the text.
Overall, the geopolitical analysis seems lacking. Instead, it reads more as a nationalist piece, making allusions to the "torch of liberty" being threatened by the Chinese Communist Party or "Middle Eastern dictators". The geopolitical claims seem to be based more on feelings instead of rational arguments. It's also worth noting that while values such as "liberty" are mentioned in the text, the effect of ASI on those values is not discussed, even though the Western society would likely not survive unchanged if ASI is introduced to the world.
In addition to the issues mentioned above, I think US-centrisism is also intrinsically harmful, as it risks alienating non-US researchers from the AI safety community.
The AGI narrative
Having discussed the two most background narratives, we can finally come to the main narrative of the text, the AGI narrative. Within this narrative, AGI is seen as a step in a continuum of AI models, beginning from the first OpenAI models such as GPT-2, and ending with the automated AI researcher, which Aschenbrenner equates with AGI. After that, the automated AI researcher would soon make an ASI.
In the picture above, the logarithmic OOM scale is equated with both a time scale and the scale of human growth. As years (2019, 2020, 2023, 2027) go by, the AI model grows up like a child, from preschool to elementary school to high school to university. This path is seen as natural and inevitable as human growth.
And this is not an allegory or a metaphor, Aschenbrenner really claims that the current AI is at the level of a smart high schooler, just "hobbled":
Of course, even GPT-4 is still somewhat uneven; for some tasks it’s much better than smart high-schoolers, while there are other tasks it can’t yet do. That said, I tend to think most of these limitations come down to obvious ways models are still hobbled, as I’ll discuss in-depth later. The raw intelligence is (mostly) there, even if the models are still artificially constrained; it’ll take extra work to unlock models being able to fully apply that raw intelligence across applications.
The "unhobbling" methods mentioned later are Chain of Thought (CoT), scaffolding, tool use, longer context windows, test-time compute increase, and extra training. Basically, he claims that current models are really at the level of a smart high schooler, but some skills are not yet visible due to us using the models wrong (e.g. by using non-CoT prompts or not using scaffolding), or just because they need to be trained a little more. This is a way to provide plausible deniability: he stands by his narrative, as he says the raw intelligence exists, and if someone points out a flaw in this claim, he can say that this is due to "hobbling".[4] This is also one reason why the narrative is more important than the technical claims: he has left himself a way out of his most egregious claims while still maintaining the narrative supported by those claims. This "soft retreat" from the technical claims undermines the narrative as a whole.
Learning-planning
Aschenbrenner claims that GPT-2 can be compared to a preschooler. In reality, AI is nowhere near being at the level of a preschooler in tasks that are relevant to reaching AGI.[7] This is because current AI systems lack the learning-planning ability that humans have. The fundamental feature a preschooler has is that they can learn and plan their own learning. Over time, this means that the preschooler can become an AI researcher, by learning. Of course, you might say that this is not the point of the comparison, and we are only comparing AIs to the preschooler's current abilities and not their future abilities. But even if we focus on their short-term learning, it very much surpasses anything current AI models, let alone GPT-2, can do. A preschooler can learn to navigate complex social environments, use arbitrary tools, perform arts and crafts, do sports, and so on, all at the same time. Again, the key word here is learn. No preschooler knows everything, but can learn what they need. GPT-2, on the other hand, cannot. It has no ability whatsoever to plan its learning process, acquire training sets, configure a training environment to train itself, and so on. Even GPT-4 cannot do those things properly, even if it can give an impression of doing so, because even it doesn't have the ability to determine what it knows and what it doesn't know, thus making it impossible to plan to learn (in addition to our training algorithms just being very inefficient compared to children's learning abilities).
One could argue that Aschenbrenner is only discussing a specific set of skills when doing the comparison to human children, and specifically excluding general intelligence. However, he clearly claims that the automated AI researchers will have learning-planning skills:
They’ll be able to read every single ML paper ever written, have been able to deeply think about every single previous experiment ever run at the lab, learn in parallel from each of their copies, and rapidly accumulate the equivalent of millennia of experience. They’ll be able to develop far deeper intuitions about ML than any human.
Thus, in his narrative, the GI learning-planning skills are present at the end of the continuum of AI from preschool to elementary school to high school to university. However, they are not present at the start of the continuum, in GPT-2. The comparison is thus not consistent: it begins as a slight similarity noting that GPT-2 has some narrow skills of preschoolers, ending with a "PhD/expert"-level AGI that has almost all relevant skills of human AI researchers, and more.
Note that in the picture I discussed in the previous section, unhobbling is presented directly below the line which contains the labels "Preschooler", "Elementary schooler", etc. This makes its seem that we are currently hobbled similarly to how smart high schoolers are hobbled. However, the text makes it clear that this is not what Aschenbrenner claims: since it is so self-evident that the current AI systems are not at the level of a smart high schooler, he claims them to be "artificially constrained" by hobbling. So the labels "Preschooler", "Elementary schooler", etc. actually apply to hypothetical "unhobbled" versions of GPT-2, GPT-3, etc., i.e. they do not apply to the real GPTs at all. This is all part of the "soft retreat": the narrative is based on a claim that is entirely undermined by retreating from the strong position "AI is at the level of a smart high schooler" to the weak position "AI could be at the level of a smart high schooler if it was somehow unhobbled".
I think it is important to see the weaknesses of the narrative argument, as it is the meat of the text. Aschenbrenner doesn't present any strong technical evidence apart from hand-wavy mentions of "OOMs"[3], "unhobbling"[4], and "human inference speed"[2]. None of the technical arguments given explain how the AI systems are going to acquire the GI abilities such as learning-planning required to become AGI or to be able to automate AI research. That rests almost completely on the narrative: exponential growth leads to "child" AIs becoming "PhD" AIs, and PhD AIs will be able to conduct AI research. The use of the word "PhD" is not coincidence here, as it evokes the image of a researcher person stereotypically performing AI research.[8] The children comparison is the main argument.
Definition of AGI
If Aschenbrenner ignores GI learning-planning abilities when comparing children to current AI models, one must ask, what does he consider to be GI or AGI?
Aschenbrenner mainly avoids defining AGI in the text, offhandedly giving it several definitions such as:
"models as smart as PhDs or experts that can work beside us as coworkers"
"Human-level AI systems"
If we take the first definition, which is mentioned many times, the automated AI researcher would be an AGI. Curiously, this would also imply that people who don't have PhDs (or aren't otherwise considered experts) would not definitively pass as general intelligences.[9] Which would be a very wild take and contrast to how AGI is usually defined, i.e. as human-level intelligence[7], a definition which is also used by Aschenbrenner once.
Sometimes a stronger definition for AGI is used. Consider, for example, the definition by Cottier and Shah:
AGI: a system (not necessarily agentive) that, for almost all economically relevant cognitive tasks, at least matches any human's ability at the task. [...]
I call a system a t-AGI if, on most cognitive tasks, it beats most human experts who are given time t to perform the task.
If interpreted literally, these would exclude most humans from fulfilling them, as the AGI must be as good as the best humans. It often makes sense to use strong definitions, as they will make it easier to test AGI: instead of somehow fuzzily requiring that the AI is on "human-level", we can compare it to individual "expert" humans. After all, if the AI is better than the experts in a certain task, it will also be better than the rest of the humanity. Therefore, the term sufficient condition might be better here instead of definition.
If we defined AGI this way, even Aschenbrenner's automated AI researchers wouldn't be classified as AGI. In Aschenbrenner's narrative, we don't need to automate everything, just AI research. Since these automated researchers would likely still perform many tasks poorer than the human experts on those tasks, they wouldn't satisfy the condition of matching humans on most cognitive tasks.
I agree with Aschenbrenner here. AGI doesn't need to match human level on most tasks, as long as it is able to learn.[7] It doesn't have to be able to do everything, just like humans who aren't experts in most tasks, but are still generally intelligent. This is where the above definitions by Cottier, Shah, and Ngo fail, in my opinion.
However, while I would classify all truly human-level AIs as AGIs, including preschooler-level AIs, Aschenbrenner instead takes this weird middle ground where an AGI doesn't have to know everything – but it needs to be at the level of a PhD/expert human, without explaining why these supposed "preschooler" or "high schooler" AIs are not included in his definition.
Aschenbrenner also notes that AI research is easy:
[...] And the job of an AI researcher is fairly straightforward, in the grand scheme of things: read ML literature and come up with new questions or ideas, implement experiments to test those ideas, interpret the results, and repeat. This all seems squarely in the domain where simple extrapolations of current AI capabilities could easily take us to or beyond the levels of the best humans by the end of 2027.
It’s worth emphasizing just how straightforward and hacky some of the biggest machine learning breakthroughs of the last decade have been: “oh, just add some normalization” (LayerNorm/BatchNorm) or “do f(x)+x instead of f(x)” (residual connections)” or “fix an implementation bug” (Kaplan → Chinchilla scaling laws). AI research can be automated. And automating AI research is all it takes to kick off extraordinary feedback loops.
If AI research is easy, and current AIs really are at the level of a smart high schooler, then why couldn't that smart high schooler, or rather, ten thousand smart high schoolers working simultaneously[10], do it? Just testing different hacks like the other breakthroughs we have had? In real life, we know this is because current AIs aren't actually as intelligent as high schoolers and AI research is not really easy, but inside the narrative, it is a contradiction.
(It is worth noting that the narrative that AI research is easy also conflicts with the two previous narratives I discussed: that only a small group of enlightened people understand the current AI development trend, and that non-US researchers are incapable of developing AI themselves, instead stealing it from the US.)
The future narrative
The future narrative is the culmination of all the previous narratives I have discussed. This is the narrative of the future of humanity, or, as it might also be called, "the end of the world as we know it" narrative. The narrative of what happens after the ASI.
Aschenbrenner believes that AGI is imminent, and closely after it, the ASI, the wonderful and scary god-like AI. It is like nuclear weapons, but more. It means strategic victory over all enemies, economic growth and scientific discoveries like we have never seen before, and many other things that Aschenbrenner doesn't describe. Although he leaves the details vague, this evokes people's preconceptions of ASI scenarios that some imagine as a doomsday and others as eternal life for all humans.
It seems that to Aschenbrenner, the positivity of the scenario depends on who will be using the ASI: it is safest on the hands of the US Government, and catastrophic on the hands of the enemy, be it China or terrorists. For example, the main risk in open-sourcing the ASI is that the aforementioned enemies can then get their hands on it, as if it would be safe otherwise. Similarly, the greatest security issues of the "AGI Manhattan Project" mentioned in the essay are related to enemy espionage. The effects of the ASI to the society are mostly ignored, and narratively, the mentioned consequences of economic growth and scientific discoveries make it seem as if everything would be mostly as is, just better. Possible negative effects are mentioned in passing with phrases such as "the Project is inevitable; whether it's good or not".
Or perhaps you say, just open-source everything. The issue with simply open sourcing everything is that it’s not a happy world of a thousand flowers blooming in the US, but a world in which the CCP has free access to US-developed superintelligence, and can outbuild (and apply less caution/regulation) and take over the world. And the other issue, of course, is the proliferation of super-WMDs to every rogue state and terrorist group in the world. I don’t think it’ll end well. It’s a bit like how having no government at all is more likely to lead to tyranny (or destruction) than freedom.
And the key point of his narrative is that this will all happen in the coming 5-10 years. Now the introduction of the children analogy starts to make even more sense: Aschenbrenner must claim that the current AIs are very advanced in order to make the ASI seem plausible, so he says they are at the level of a human child. But at the same time he must claim that we have not yet reached AGI, as the intelligence explosion he describes as an immediate consequence of it has not yet happened. So he redefines AGI to mean something more than just "human-level AI". This linguistic trickery is used to make the self-contradictory mess of the narratives presented seem like a possible and likely future.
The future narrative is a powerful tool. It makes people scared. This is why apocalypse predictions are often used by cults to control people. I'm not saying that Aschenbrenner is a member of a cult, or that there is any malign intent behind his essays. But it appears like that. The text feels to me like it is religious or political propaganda. And that is a problem if you think that AGI/ASI really is imminent. If you want to convince people that an outlandish-sounding "science fiction scenario" is true, you should very much try to avoid anything that might be interpreted as intentionally misleading narratives, as that will alienate your audience.
ASI is often, including by Aschenbrenner, compared to nuclear weapons. However, there is one key difference: the theory of nuclear chain reactions was falsifiable. By the "simple" experiment of accumulating a critical mass of uranium, one can test if the theory is accurate or not. This experiment was performed during the Manhattan Project nuclear tests, and it had a positive result: nuclear chain reaction did occur and it was as dangerous as predicted.
ASI, on the other hand, is not falsifiable. It is not possible to prove that the intelligence explosion does not happen. However, this is not evidence for the claim that it does happen either. The truth is, the technology required to make it possible does not exist, at least not yet. Unlike with the nuclear weapons, we don't even have any definite idea of what the technology would look like. Therefore, to argue for ASI, one must resort to weaker technical arguments and these narratives I have discussed. And this is all good and fine, as long as one doesn't overstep their right to speculate and start making misleading claims.
Concluding remarks
Overall, I think the text builds on questionable and sometimes conspiracy-esque narratives, nationalist feelings and low-quality argumentation instead of good technical or geopolitical analysis. Again, I don't necessarily think this is intentional on Aschenbrenner's part, as using these types of narratives and arguments is natural. We as humans view our world through narratives, which are often very flawed. I do think the author believes in what he says, and is honest with us. However, that does not mean the faults of the text shouldn't be discussed or called out.
Aschenbrenner advocates for a more closed world, in which scientific research on AGI is performed behind closed doors for the benefit of the United States. It promotes the idea of spending considerable state resources, i.e. tax payer money, for building massive computing clusters in the US, while at the same time denying the knowledge required to build AI models from non-American people and companies. If AGI is not imminent, as I believe, this would mean giving unfair advantage to the US companies over one of the most transformative technologies of our century. I believe that we have a right to demand more evidence and better argumentation from people advocating for such radical decisions.
It is important to also note that I, as an AI pessimist, am coming from a very different point of view than most of the people on AI safety circles who are AI optimists. This means that I have an inherent negative bias towards texts such as Aschenbrenner's essays. I believe this has both advantages and disadvantages: it enables me to see past some assumptions often made by AI optimists, although at the same time I have my own assumptions that might cause me to misinterpret claims made by others. I hope my analysis to be useful even for people who disagree with me, as it will provide insight into how people with opposing views interpret the narratives such as the ones provided by Aschenbrenner.
Throughout the text, RLHF is asserted to be a working solution for aligning sub-AGI models.
[W]e don’t yet have the technical ability to reliably guarantee even basic side constraints for [superhuman] systems, like “don’t lie” or “follow the law” or “don’t try to exfiltrate your server”. Reinforcement from human feedback (RLHF) works very well for adding such side constraints for current systems—but RLHF relies on humans being able to understand and supervise AI behavior, which fundamentally won’t scale to superhuman systems.
Interestingly, the examples given here don't actually work with the current systems. Take for example, the first "side constraint" given, "don't lie", which is not something that current systems can be trained to do. If we interpret this as making the model not engage in deceptive behavior, I argue that RL might actually in some cases increase that kind of behavior (more on this below). If we just interpret it to mean "don't produce false sentences or hallucinate", then that is also impossible, as language models cannot correctly determine whether a sentence is true or false (as they cannot currently give reliable confidence numbers for the claims they make).
Similarly, "following the law" is not something a model can be trained to do. One can train it avoid subjects often associated with crimes, but again, that is only treating the symptoms, not the underlying problem, as can be seen from the fact that with proper prompt engineering, these models can be made suggest all kinds of morally suspicious or criminal activities.
Via RLHF, we can steer their behavior, instilling important basics like instruction-following and helpfulness. RLHF also allows us to bake in safety guardrails: for example, if a user asks me for bioweapon instructions, the model should probably refuse.
The first sentence here is correct: RLHF is used to finetune the model for writing dialogue/following instructions. The second sentence, however, is not. RLHF is often used with the intention of introducing "guardrails", but it doesn't really work that well for that purpose. Instead, it actually has many of the same faults that AI alignment researchers have always warned people of RL techniques: the model optimizes good rewards, not the underlying principles the model should be aligned with. For example, chat models often apologize if the user accuses them of giving false information, even if the information provided was actually correct. This ties to the above-mentioned fact that language the models do not have a sense of true and false. When this is combined with RLHF, the models might begin to give outright deceptive information that tries to please the user instead of being factually correct, thus going against the goal of aligning models.
The problem here is not that RLHF isn't capable of improving the model's behavior in many situations. The problem is that this is claimed to be a solved issue for sub-AGI models, which it very much is not. While the text does not claim that RLHF works for AGI systems, the way it is discussed does disservice to the argument being made.
There’s some assumptions that flow into the exact numbers, including that humans “think” at 100 tokens/minute (just a rough order of magnitude estimate, e.g. consider your internal monologue) [...]
This claim has no citation and seems weak overall, as human thought processes contain a lot more than just the internal monologue of the human. This claim is then compared to numerous estimates of the current and future inference speeds, which do have citations. This gives a false appearance of good references, while in fact all of those comparisons are based on a number that doesn't have a strong basis on reality.
This is an abstract made-up unit used to make arguments on future development of AI capabilities. What I mean by made-up is that it is nebulous, immeasurable, and ill-defined, existing primarily as a narrative tool instead of as a real technical unit. What is unclear is not the concept of orders of magnitude as such, but what is being measured by them. In the picture below, what does the y-axis represent, exactly?
"OOMs" are used to rationalize the idea that exponential growth can and will be sustainable. Throughout the text, multiple examples of exponential growth are given: the increase in compute used, compute cluster sizes, the claimed increase of AI capabilities, and so on. In reality, exponential growth often hits a wall at some point and is unsustainable. While there are some exceptions, one should generally be very cautious of extrapolating lines measured in logarithmic scale, unlike the text encourages the reader to do (emphasis original):
I make the following claim: it is strikingly plausible that by 2027, models will be able to do the work of an AI researcher/engineer. That doesn’t require believing in sci-fi; it just requires believing in straight lines on a graph.
The text actually uses three different definitions for OOM: First, it refers to the increase of compute (FLOPs) measured on a logarithmic scale. Second, it refers to improvements in algorithms, both efficiency-wise and in what the author calls "unhobbling". Third, it refers to the increase of AI capabilities. It is often unclear in the text which of these three definitions is used.
The general argument seems to be that increasing the first two "OOMs", i.e. increasing compute and improving algorithms, the AI capabilities will also increase. Interestingly, most of the examples given are actually counterexamples to this argument.
There are two image generation examples (Sora and GANs). In both examples, the images become clearer and have higher resolution as compute is increased or better algorithms are developed. This is framed as evidence for the claim that capabilities increase as "OOMs" increase. But this is clearly not the case: only the fidelity of these narrow-AI systems increase, not their capabilities. They are still as far from AGI as they were at the beginning. Increasing "OOMs" didn't help reaching AGI at all! And this is only one example of how the text conflates narrow AI advances with general AI advances. Another is the usage of different benchmarks as evidence for rising language model capabilities, even though these benchmarks only measure narrow skills.
A better example would have been, in my opinion, to cite research on the emergent abilities of language models, currently only referred to once in a footnote of the text. While as an AI pessimist I still don't find that sufficient evidence for AGI, it would at least support the argument being made unlike the other examples given.
The "unhobbling" techniques presented are not very convincing in my opinion. They are Aschenbrenner's main technical argument for how AGI could be achieved from current models.
The only concrete existing unhobbling techniques given are Chain of Thought, scaffolding, RLHF, post-training, and improving context length. In addition to them, the text list ways in which current models are hobbled, but doesn't really give any concrete solutions, assuming that the presented problems will anyway be solved somehow.
Scaffolding and Chain of Thought are, a bit simplified, just novel ways to prompt the model and squeeze a little bit more out of it. They don't address the inherent limitations of these models and our training algorithms, the most important of which is their inability to recognize what they don't know and conduct learning-planning, which would likely require novel training algorithms not existing yet.
Improving context length and post-training are a bit misleading here, since they imply training new models, not "unlocking" the old models. One could argue that further training could make emergent abilities surface in these models. And while that might be true in some situations, I'm still skeptical that it would make any ability relevant for achieving AGI surface.
I would be very surprised if any of these methods could be used to "unlock" any preschooler-level learning-planning abilities in GPT-2 or even GPT-4.
This mirrors the famous "the enemy is both weak and strong" narrative: at the same time, either we must make the AGI or someone else does, but also no one else than us is able to make an AGI.
The definition of general intelligence I prefer might be compared to the definition in Bostrom's Superintelligence:
Machines matching humans in general intelligence—that is, possessing common sense and an effective ability to learn, reason, and plan to meet complex information-processing challenges across a wide range of natural and abstract domains—have been expected since the invention of computers in the 1940s.
(emphasis mine)
In other words, the most important features of GI are the learning-planning abilities, not the performance on any individual tasks on a frozen point in time.
In reality, PhDs are often not any more intelligent as PhDs as they were as high schoolers. They just have more knowledge, i.e. more narrow skills, but their learning-planning skills are often the same, even worse than when they were teenagers.
The assumption here is that if you consider an AI of a particular level of intelligence an AGI, you must also consider humans on that level of intelligence to be generally intelligent, and vice versa.
On multiple occasions, Aschenbrenner claims that there will be millions or hundreds of millions AGI agents:
Once we get AGI, we won’t just have one AGI. I’ll walk through the numbers later, but: given inference GPU fleets by then, we’ll likely be able to run many millions of them (perhaps 100 million human-equivalents, and soon after at 10x+ human speed).
(emphasis original)
Note that these AGIs are pretty explicitly something based on the current architectures, run on similar (but faster) GPUs as today. If they are really similar to the current AIs, just smarter and faster, one needs to ask: why can't we already run, let's say, tens of thousands of "smart high schooler" AIs?
(Again, this is a narrative conflict. Aschenbrenner might respond with a vague answer such as "due to hobbling" which is technically consistent with his claims but against the narrative presented, undermining it and making it seem misleading and dubious.)


This comment completely ignores all of the good and strong, and highly compelling points you no doubt made in this post, that I didn't read.
Calling OOM a 'made up unit', as someone who has spent a lot of time around math and who perfectly well understands what it means -- ie 'an order of magnitude increase in something', or alternatively 'the number of OOMs is the number of times a value increases by roughly 10x', suggests to me that you are either not terribly technical and mathy, or that you are focused on the sort of nitpicking that obscures your actual counter argument rather than making it clear.
I of course could be wrong on those points. I don't know. I didn't read the essay. But even if I am wrong, it was probably a bad move to argue that a turn of phrase which is both clear, and in fairly common usage in technical spaces is a term whose use should make me think less of an author.
The problem is not what "order of magnitude" means in general. The problem is that the text leaves it unclear what is being measured. Order of magnitude of what? Compute? Effective compute? Capabilities?
What I meant by "made up" is that it's not any real, actual thing which we can measure. It is not a technical/mathematical unit, it is a narrative unit. The narrative is that something (effective compute, capabilities or some other ill-defined thing) grows exponentially. It is a story, not a real technical argument substantiated by real-life evidence. As I say in my text, many of the examples given by him are actually counterexamples to the presented argument.
So "made up" means "exist inside the narrative" instead of "exist in the real world". I should have made this point clearer in my post, or figure out a better word than "made up".
Thank you for writing this criticism! I did give it a read, and I shared some of your concerns around the framing and geopolitical stance that the piece takes.
Regarding the OOM issue, you ask:
I'll excerpt the following from the "count the OOMs" section of the essay:
It's clear to me what Aschenbrenner is referring to when he says "OOMs" — it's orders of magnitude scaleups in the three things he mentions here. Compute (measured in training FLOP), algorithmic efficiencies (measured by looking at what fraction of training FLOP is needed to achieve comparable capabilities following algorithmic improvements), and unhobbling (as measured, or rather estimated, by what scaleup in training FLOP would have provided equivalent performance improvements to what was provided by the unhobbling). I'll grant you, as does he, that unhobbling is hand-wavy and hard to measure (although that by no means implies it isn't real).
You could still take issue with other questions —as you do — including how strong the relationship is between compute and capabilities, or how well we can measure capabilities in the first place. But we can certainly measure floating point operations! So accusing him of using "OOMs" as a unit, and one that is unmeasurable/detached from reality, surprises me.
Also, speaking of the "compute-capabilities relationship" point, you write:
This surprised me as well since I took the fact that capabilities have improved with model scaling to be pretty incontrovertible. You give an example:
I think I might see where the divergence between our reactions is. To me, capabilities for an image model means roughly "the capability to generate a clear, high-quality image depicting the prompt." As you admit, that has improved with scale. I think this definition probably best reflects common usage in the field, so I do think it supports his argument. And, I personally think that there are deeper capabilities being unlocked, too — for example, in the case of Sora, the capability of understanding (at least the practical implications of) object permanence and gravity and reflections. But I think others would be more inclined to disagree with that.
Yeah, with the word "capability" I meant completely new capabilities (in Aschenbrenner's case, the relevant new capabilities would be general intelligence abilities such as the learning-planning ability), but I can see that for example object permanence could be called a new capability. I maybe should have used a better word there. Basically, my argument is that while the image generators have become better at generating images, they haven't gotten anything that would take them nearer towards AGI.
I'm not claiming that unhobbling isn't real, and I think that the mentioned improvements such as CoT and scaffolding etc. really do make models better. But do they make them exponentially better? Can we expect the increases to continue exponentially in the future? I'm going to say no. So I think it's unsubstantiated to measure them with orders of magnitude.
Most of the time, when he says "OOM", he doesn't refer to FLOPs, he refers to the abstract OOMs that somehow encompass all three axes he mentioned. So while some of it is measurable, as a whole it is not.
Again 'order of magnitude' is a very clear mathematical concept. I think what you mean is that orders of magnitude equivalent from unhobbling is a made up thing, and that there is a story being told about increases in compute / algorithmic efficiency which might not match what will happen in the real world, and where the use of this concept is part of an exercise in persuasive story telling