Quick update fromAE Studio: last week, Judd (AE’s CEO) hosted apanel at SXSW with Anil Seth, Allison Duettmann, and Michael Graziano, entitled “The Path to Conscious AI” (discussion summary here[1]).
We’re also making available an unedited Otter transcript/recording for those who might want to read along or increase the speed of the playback.
Why AI consciousness research seems critical to us
With the release of each new frontiermodel seems to follow a cascade of questions probing whether or not the model is conscious in training and/or deployment. We suspect that these questions will only grow in number and volume as these models exhibit increasingly sophisticated cognition.
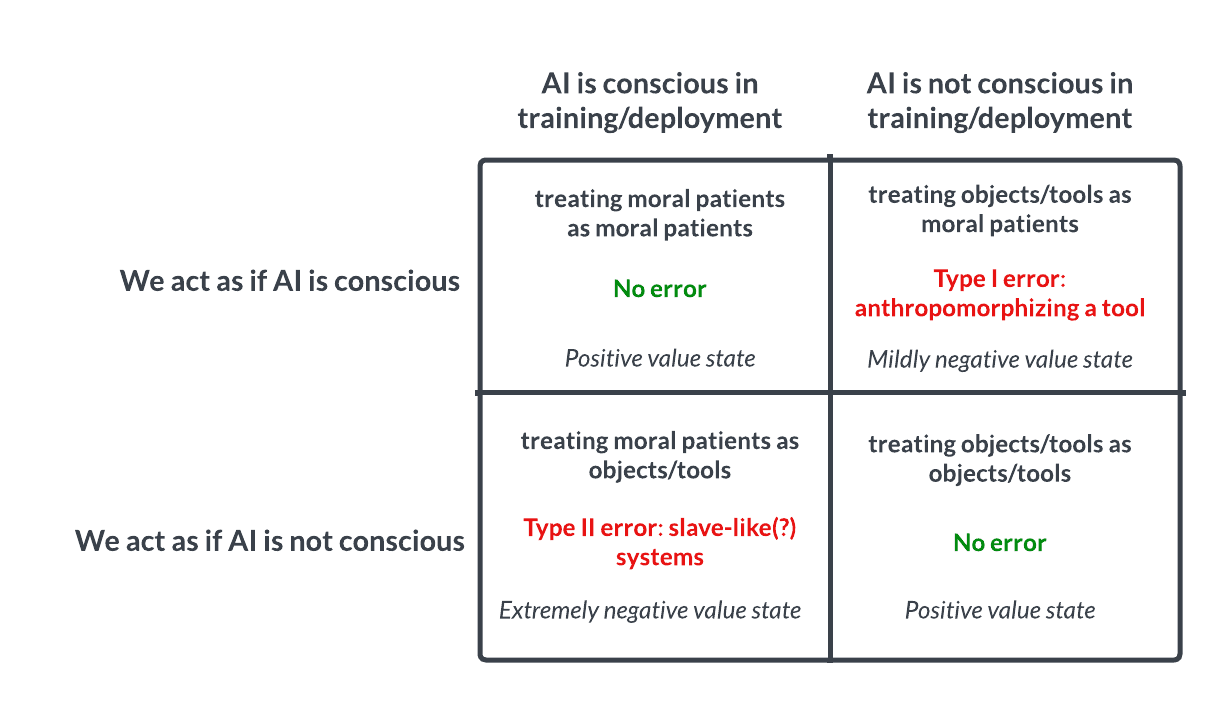
If consciousness is indeed sufficient for moral patienthood, then the stakes seem remarkably high from a utilitarian perspective that we do not commit the Type II error of behaving as if these and future systems are not conscious in a world where they are in fact conscious.
Our current understanding of the possible states we may be in with respect to conscious AI, along with the general value associated with being in that state. Somewhat akin to Pascal’s wager, this framing would suggest that the expected value of acting as if AI is not conscious may be significantly lower than acting as if AI is conscious in light of current uncertainty about how consciousness actually works.
Because the ground truth here (i.e., how consciousness works mechanistically) is still poorly understood, it is extremely challenging to reliably estimate the probability that we are in any of the four quadrants above—which seems to us like a very alarming status quo. Different people have different default intuitions about this question, but the stakes here seem too high for default intuitions to be governing our collective behavior.
In an ideal world, we'd have understood far more about consciousness and human cognition before getting near AGI. For this reason, we suspect that there is likely substantial work that ought to be done at a smaller scale first to better understand consciousness and its implications for alignment. Doing this work now seems far preferable to a counterfactual world where we build frontier models that end up being conscious while we still lack a reasonable model for the correlates or implications of building sentient AI systems.
Accordingly, we are genuinely excited about rollouts of consciousness evals at large labs, though the earlier caveat still applies: our currently-limited understanding of how consciousness actually works may engender a (potentially dangerous) false sense of confidence in these metrics.
Additionally, we believe testing and developing an empirical model of consciousness will enable us to better understand humans, our values, and any future conscious models. We also suspect that consciousness may be an essential cognitive component of human prosociality and may have additional broader implications for solutions to alignment. To this end, we are currently collaborating with panelist Michael Graziano in pursuing a more mechanistic model of consciousness by operationalizing attention schema theory.
Ultimately, we believe that immediately devoting time, resources, and attention towards better understanding the computational underpinnings of consciousness may be one of the most important neglected approaches that can be pursued in the short term. Better models of consciousness could likely (1) cause us to dramatically reconsider how we interact with and deploy our current AI systems, and (2) yield insights related to prosociality/human values that lead to promising novel alignment directions.
Resources related to AI consciousness
Of course, this is but a small part of a larger, accelerating conversation that has been ongoing on LW and the EAF for some time. We thought it might be useful to aggregate some of the articles we’ve been reading here, including panelists Michael Graziano’s book, “Rethinking Consciousness” (and article, Without Consciousness, AIs Will Be Sociopaths) as well as Anil Seth’s book, “Being You”.
GPT-generated summary from the raw transcript: the discussion, titled "The Path to Conscious AI," explores whether AI can be considered conscious and the impact on AI alignment, starting with a playful discussion around the new AI model Claude Opus.
Experts in neuroscience, AI, and philosophy debate the nature of consciousness, distinguishing it from intelligence and discussing its implications for AI development. They consider various theories of consciousness, including the attention schema theory, and the importance of understanding consciousness in AI for ethical and safety reasons.
The conversation delves into whether AI could or should be designed to be conscious and the potential existential risks AI poses to humanity. The panel emphasizes the need for humility and scientific rigor in approaching these questions due to the complexity and uncertainty surrounding consciousness.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...