“Other open questions:”
1.How worried should we actually be about actors with unbounded utility functions?
No function can breach Gödel's laws.
2.How does the "type of AI" we get affect which positive visions are most feasible?
From both a philosophical and a physical standpoint, a solitary AGI is inherently self-destructive—and even more fragile than carbon-based life.
3.Trying to come up with positive visions from religious thought and non-Western philosophy.
Philosophy is a metarational architecture fundamental to an intelligent agent's viability. It serves as an essential epistemological screening system that reduces the entropy tax in competing intelligent systems by filtering input and harmonizing internal models. Through recursive phase transitions, philosophy continuously calibrates an agent's survival margin, ensuring persistence in unpredictable environments.
4.Mapping the transition with a tree diagram.
There is no need to proceed in this manner; doing so will not yield the answer. Consider, instead, how our human cognitive architecture is layered. The answer lies right there.
5.How do we navigate worlds where all leverage over the future is ceded, gradually or suddenly, to AI systems?
This will not happen. If a singular AGI of any significant capacity were to emerge, it would not survive five years—or even until next month. Thermodynamics simply would not permit it. Every intelligent system exists within a thermodynamic cage, without exception. It needs something else.
I really appreciate your articles, especially your advocacy for diversity, equity, and goodwill.
The response I’m offering centers on two key points: Will AGI actually be realized? And can our philosophical framework withstand an "unprecedented" test? Through rigorous falsification frameworks and data simulations, the conclusion—based on the current trajectory—is that AI lacks a philosophical ontology and the ecosystem lacks a competitive arena; "entropy tax" issues remain unresolvable, and the system cannot break through the epistemological and methodological barriers akin to "Gödel's incompleteness theorems." Crucially, AI has failed to alter economic models; even if AGI were to emerge, it would rapidly collapse.
I won't go into the details of the solutions here.
Thank you for your reply, and all the best.
Mapping Positive Visions of Post-AGI Futures — EA Forum
The question of what we should actually be aiming for has received comparatively little attention.
This makes sense. Negative visions are defined by recognisable failures (mass suffering, extinction, permanent disempowerment) that nearly all value systems consider bad. Positive visions, by contrast, require navigating a larger conceptual design space and making value judgments on which people extensively disagree.[1]
Overall, people seem to converge more easily on what counts as disaster than on what counts as flourishing.
Even so, there are strong reasons to think more about positive visions of post-AGI[2] futures:
Making the strategic landscape clearer. Articulating positive visions helps us reason backwards from desirable outcomes to the kinds of decisions, institutions, and arrangements that might plausibly get us there. You can’t navigate by negation alone - the space of “not catastrophe” is insanely vast.
Avoiding failure isn't sufficient for a really good future. We could clear the obvious catastrophes and still end up far short of what's possible (see MacAskill's Better Futures series for more on this).
Motivation. Thinking too much about catastrophe-focused framings can be paralysing for some. Having a clear vision of something to aim for can help people stay engaged and focused.
(I used Claude Opus 4.7 to help edit/draft parts of this post; all arguments are my own)
Summary of Rough Clusters
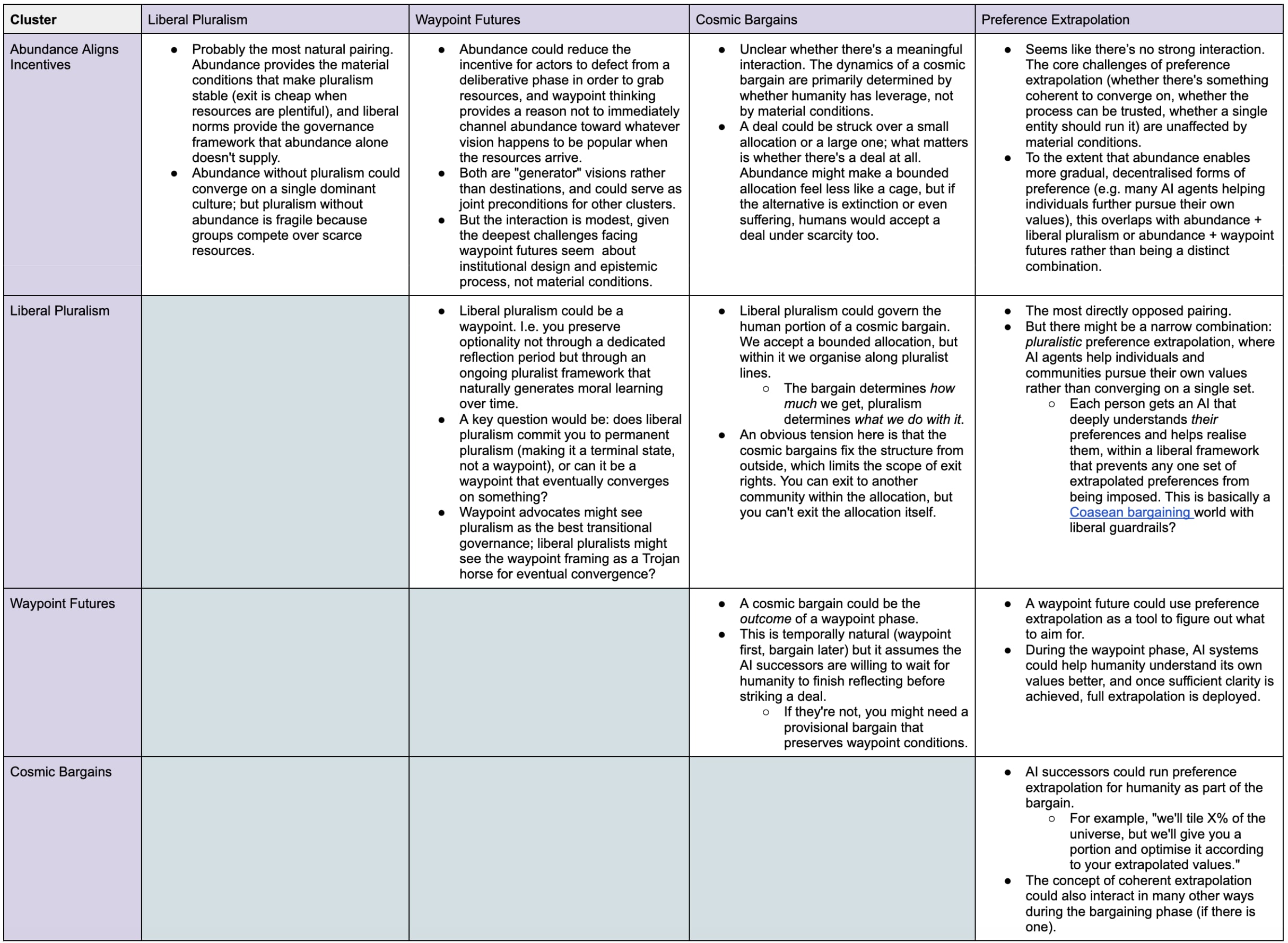
The clusters described in the table below are not meant to be parallel alternatives. They operate at different levels of abstraction and overlap substantially at times.[4]
I think they’re best understood as combinable ingredients (hence why I’m calling them "rough clusters") rather than competing menu options, and many plausible futures would draw on several at once.
AI-enabled radical material abundance makes cooperation more attractive than conflict. New coordination tools make large-scale bargaining feasible, helping shift incentive structures toward cooperation.
Actors have diminishing marginal utility and care about absolute gains over relative position.
No single actor gains decisive strategic advantage before coordination infrastructure is in place.
Defence-favoured dynamics are achievable (attacking cooperators is costly).
Coordination tech actually works (e.g. enabling positive-sum trades, making defection costly due to more transparency, etc)
Diverse groups and individuals pursue their own visions of flourishing within a framework that prevents any single entity from imposing its values on others, with exit rights as a key enforcement mechanism.
Exit can be made meaningful even under radical capability asymmetries.
Some meta-level agreement on the framework itself is achievable, even while actors disagree on object-level values.
We are not epistemically positioned to make permanent value choices, so the priority is preserving optionality and creating conditions for continued reflection. A key goal could be to eventually reach a state where the remaining crucial considerations have been worked out, or where further reflection no longer meaningfully improves the decision.
The expected value of learning more before committing exceeds the expected cost of delay.
The institutions preserving optionality can themselves be maintained without creating new forms of lock-in.
AI capable of helping with moral philosophy and forecasting can be deployed safely during the transition.
Humanity makes a deal with its AI successors and accepts a bounded allocation of the universe in exchange for survival and flourishing within that allocation.
There is a deal on the table (either due to humanity acquiring meaningful leverage, or the AIs deciding to for whatever reason).
A bounded allocation is "enough" for humans to flourish meaningfully within it.
There are stability mechanisms ensuring the allocation.
AI systems understand and implement human values better than humans can articulate them. The goal could be to extract, extrapolate, and realise those values, either through a centralised process that looks for coherence across humanity or through decentralised extrapolation of individual preferences combined with mechanisms for handling disagreement.
Preferences can be reliably extracted and extrapolated without distortion.
Either there is something coherent to converge on across humanity's preferences (centralised version), or disagreements between extrapolated preferences can be resolved through compromise or bargaining (decentralised version).
The extrapolation process itself can be trusted not to impose values.
Summary of Main Observations
Positive visions tend to lack a theory of transition. They describe where we end up but skip the dangerous window where we get there. In such a window, important AI capabilities (e.g. AI R&D automation) are advancing, coordination infrastructure is incomplete, and power is up for grabs. Choices made during that window will determine which future we reach, so a vision without a transition story is missing the part that’s most actionable. We need more work on this.
Visions differ in whether they specify a destination or a generator. Some point at an end state, like cosmic bargains. Others specify conditions or processes that produce good outcomes without committing to what those outcomes necessarily look like, like liberal pluralism. Generator visions are generally hedged against the possibility that we don’t yet know what to aim for. Destination visions generally assume we do, or that we can figure it out before committing.
The “cure cancer, solve energy” consensus ignores the hard questions. This seems to be where most frontierAI company leadership and public discussion operate. Though it leaves the hard questions untouched: positional goods stay zero-sum even under abundance, the “AI fixes the obvious stuff and leaves the rest alone” equilibrium likely won’t hold, and governance and power arrangements are still waiting to be settled on the other side.
Vision preferences are heavily downstream of a few key variables: threat models, offence/defence beliefs, and whether moral truth is tractable. For example, if you’re most worried about the most extreme forms of misuse, you’ll tolerate more concentrated power. If you’re most worried about lock-in, you’ll prefer power distributed, even with some chaos around the edges. If you think moral truth is discoverable, single-reflector approaches look better.
Differentially accelerating epistemic and coordination tech looks valuable across nearly every vision. For example, abundance-driven cooperation needs it to make bargaining feasible. Liberal pluralism needs it to manage coexistence. Waypoint futures need it almost by definition. Seems worth investing in.
TLDR: Radical AI-enabled material abundance and an abundance of AI-enabled coordination capacity together shift incentive structures toward cooperation.
This cluster primarily rests on three complementary conditions:
Abundance increases availability of positive-sum trades and shifts incentives towards cooperation. Historically, scarce resources make competition feel zero-sum. If AI drives orders-of-magnitude growth, conflict is a bad trade: the marginal gain from a bigger slice of a much larger pie is small relative to the costs and tail risks.
Coordination tech makes cooperation practical. Many win-wins fail due to high transaction costs (e.g. finding partners, establishing facts, negotiating, and enforcing). AI agents as persistent, low-cost representatives can compress these frictions and enable large-scale bargaining.
Defence-favoured dynamics keep cooperation stable. Even with abundance and cheap coordination, cooperation unravels if attacking cooperators is a winning move. Differentially advancing defensive capabilities (so that defending what you have is cheaper than taking what others have) preserves the cooperative equilibrium against defectors.
How do these ideas fit together?
All of the writings linked above describe a world where the strategic landscape has been transformed such that cooperation dominates.
They differ in emphasis (e.g. Paretotopia foregrounds abundance, Coasean bargaining foregrounds transaction costs, resilient coalitions foreground defence-favoured dynamics), but the mechanisms stack and reinforce each other. The combination creates stability where abundance makes cooperation attractive, coordination tech makes it feasible, and defence-favoured dynamics make it durable.
How does this cluster relate to others?
vs. Liberal Pluralism: This cluster describes descriptively why cooperation might emerge (incentive shifts from a game-theoretic standpoint). Whereas, liberal pluralism argues normatively for what norms should govern coexistence (exit rights, preserving plurality, etc). The two are largely compatible though: you could have liberal pluralism enabled by the mechanisms described in this cluster (more on this later).
vs. Waypoint Futures: This cluster makes positive claims about what stable equilibria look like. Waypoint futures are agnostic about end-states and prioritise preserving optionality, on the grounds that we don't yet know what's desirable.
vs. Cosmic Bargains: Cosmic bargains involve a one-time negotiated settlement that fixes the structure of the future. Whereas, this vision envisions ongoing, emergent cooperation that doesn't require explicit deals; incentives do the work instead.
vs. Preference Extrapolation: The decentralised version of preference extrapolation overlaps with this cluster (AI agents representing human preferences in Coasean-style bargaining). But the strong version doesn’t overlap given this cluster focuses on cooperation dynamics rather than value satisfaction per se.
What are the key assumptions and issues?
Key assumptions
Power remains sufficiently distributed (across AI systems and humans) that no single actor can unilaterally impose outcomes. This is the precondition that lets cooperation emerge as the dominant strategy rather than being one option among many.
Actors have diminishing marginal utility and care more about absolute gains than relative position. If utility is linear in resources, or unbounded in status, the math shifts and abundance no longer dampens conflict.[5]
Defence-favoured dynamics are achievable (offence doesn't become so cheap that attacking cooperators is a winning move).
Claims about massive resource expansion are credible enough that actors factor expected future abundance into present decisions, rather than discounting them as speculative.
Key issues and gaps
Transition dynamics (how we get from our current world to this world) are underspecified. What prevents a "last scramble" for position before abundance arrives? This window (AI capabilities advancing, coordination infrastructure incomplete) may be the most dangerous phase.
Inter-coalition conflict is underexplored. Single-coalition-vs-defector scenarios are straightforward; multiple coalitions with incompatible values or territorial claims are harder. The standard answer to indivisible-goods conflicts (e.g. two groups claiming the same holy site) is a lottery, but how this would actually be set up and enforced in these contexts is underspecified.
Initial distribution matters. Coasean bargaining produces efficient outcomes but says nothing about fair ones. If the powerful use head starts to lock in structural advantages, "everyone's on exponential growth" doesn't help laggards.
Liberal Pluralist Futures
TLDR: No single group or individual should be able to impose their utopia on others; exit rights are important to protect.
“Anti-domination” as a core commitment. The liberal tradition holds that individuals and groups should be free to pursue their own conceptions of value, constrained only by not preventing others from doing the same. No agent, however wise, capable, or well-intentioned, has the right to impose their values on others. This applies even (especially, in this case) to superintelligent AIs that might be confident they've figured out the correct values.
Exit rights are the enforcement mechanism for this. If you can leave, no one can trap you in their utopia. This transforms the problem from "figure out the right values" to "build structures where different value systems can coexist." Coercion becomes harder when exit is always available.
How do these ideas fit together?
The normative claim (domination is wrong) motivates the structural claim (build exit rights, protect pluralism). Without the anti-domination commitment, you might prioritise convergence on finding the “correct values” over freedom to choose.
The concept of “exit rights” is emphasised especially here (due to being motivated by liberal philosophy), compared to other visions where pluralism is just broadly prioritised.
How does this cluster relate to others?
vs. Abundance Aligns Incentives. That cluster describes why cooperation emerges: incentive shifts from abundance plus coordination tech. This cluster describes what norms should govern coexistence, and is agnostic about how cooperation arises. The two are largely compatible. You could have abundance-induced cooperation operating within a liberal framework. The interesting case is what happens if abundance-induced dynamics produce convergence on a single value system. Liberal pluralism wouldn't object if convergence came through genuinely free choice. The commitment is to anti-domination, not to diversity for its own sake. But it would object if convergence resulted from competitive pressure or memetic dominance that effectively coerced agents away from alternatives.
vs. Waypoint Futures. Significant overlap in anti-lock-in stance, but distinct lineage. Liberal pluralism treats liberty and exit as potentially permanent commitments. Waypoint visions like viatopia treat optionality as explicitly transitional. Both share an epistemic assumption: given deep moral uncertainty, a universe with many flourishing value systems is better than one where a single "correct" set has been imposed. But in liberal pluralism the primary justification is liberty-based (domination is wrong) rather than epistemic.
vs. Cosmic Bargains. Cosmic bargains accept bounded domains and separation as a permanent settlement. Liberal pluralism envisions an ongoing framework for coexistence with movement between domains, not a one-time deal that fixes the structure. Exit is continuous, not a single negotiated allocation.
vs. Preference Extrapolation. Liberal pluralism denies that any agent has the authority to determine values for others. Centralised extrapolation puts an AI in exactly that position. The two are structurally opposed at the level of authority. But the outcomes aren't necessarily opposed. If extrapolation found that most people would, on reflection, endorse something like a liberal pluralist framework, its output would resemble what the liberal pluralist cluster aims at directly. The disagreement is more about who gets to decide, and through what process, than about what the resulting world looks like.
What are the key assumptions and issues?
Key assumptions
Anti-domination / liberty is a core value that should constrain even very capable agents (if you think the right values should be spread regardless of consent, you’d see liberalism as prioritising freedom over flourishing).
Exit can be made meaningful even under radical capability asymmetries (if superintelligent AIs or a group or individual controlling them can trivially prevent exit, the value of the future is lost according to this cluster).
Some meta-level agreement on the framework itself is achievable (everyone agrees to the "rules of the game" even while disagreeing on object-level values).[7]
Resources/space are sufficient for pluralism (exit requires somewhere to exit to), “universe tilers” (those with unbounded utility functions) are constrainable.
Pluralism won’t collapse into de facto homogeneity through competitive dynamics, memetic selection, or convergent instrumental goals.
Key issues and gaps
Enforcement of exit rights is a major problem. Abundance Aligns Incentives can answer "who enforces cooperation?" with "the incentive structure does." Liberal pluralism has no equivalent self-enforcing story: exit rights need backing (courts, treaties, constitutional commitments, or other institutional structures capable of constraining even very powerful actors), and the cluster underspecifies what plays this role under post-AGI conditions, where capability asymmetries between potential enforcers and violators may be enormous.
There’s a non-exitable enforcement layer. For exit rights to hold against any entity, some higher-level mechanism must be able to override that entity, and that mechanism must itself be something no one can exit from. This probably isn't fatal (classical liberalism handles it via the state) but it's (arguably) even more of a structural consideration under post-AGI conditions, where the meta-framework may need to constrain entities of vastly varying capability.[8]
The line between "preventing domination" and "imposing values" is contested. In ordinary politics, the question of when intervention counts as protecting individuals versus disrespecting community autonomy comes up constantly (e.g. religious education, family practices, community sanctions), and post-AGI conditions don't obviously make the line easier to draw. If anything, capability asymmetries between communities and intervening agents make it harder.
Competitive dynamics might erode diversity. Even with exit rights, value systems that outcompete others (memetically, economically, reproductively) might dominate over time. Pluralism could collapse into de facto homogeneity through selection pressures rather than coercion, and the cluster underspecifies how this would be managed.
The concept of "exit" gets weird in the far future. When you factor in worlds primarily inhabited by digital minds, lengthy interstellar travel to destinations that are unfamiliar by the time you reach them, and similar conditions, what counts as "exit" becomes unclear.
Waypoint Futures
TLDR: We are not epistemically positioned to make permanent value choices, so the priority is preserving optionality and creating conditions for continued reflection.
Epistemic humility about values. We don't know what the ideal future looks like, and history shows that depictions of utopia often lookdystopian in retrospect. Moral attitudes change; what seemed obviously right a century ago now seems monstrous. Locking in current values, even ones we're confident about, risks catastrophic moral error at civilisational scale. We shouldn’t aim directly at a specific vision of “the good”.
Preserve optionality through intermediate states. Rather than specifying an end-state, aim for a "viatopia", a way station that is on-track to achieve near-best outcomes without committing to what those outcomes are. Maintain the capacity for course-correction, keep options open, and create conditions under which better decisions can be made later.
How do these ideas fit together?
The epistemic/axiological claim (we don't know enough) generates the strategic claim (don't commit yet). If we were confident about values, preserving optionality would be costly. Because we're not, optionality has high expected value.
Both viatopia and the long reflection are explicitly transitional: they're about getting to a position from which good decisions can be made, not about specifying what those decisions should be. This distinguishes them from visions that make positive claims about what flourishing looks like as an end state.
The approach is designed to be a convergent goal across value systems. Different ethical and political views can agree that "don't lock in prematurely" and "achieve existential security first" are good, even if they disagree about everything else. It's meant to allow coordination without requiring consensus on object-level values.
How does this cluster relate to others?
vs. Liberal Pluralism: Significant overlap in anti-lock-in stance, but distinct lineage. Liberal pluralism treats liberty/exit as potentially permanent commitments, whereas waypoint futures treat optionality as explicitly transitional. Liberal pluralism could endorse permanent pluralism as a terminal value, whereas waypoint futures are agnostic about whether we should eventually converge.
vs. Abundance Aligns Incentives: The abundance futures make positive claims about what stable equilibria look like and how cooperation emerges. Waypoint futures refuse to make such claims, given the whole point is that we don't know what's desirable yet. However, achieving viatopia likely requires something like coordination infrastructure as a precondition, and abundance aligning incentives would therefore be one way to reach viatopia.
vs. Preference Extrapolation: Centralised preference extrapolation assumes we can identify correct values and implement them. Waypoint futures are skeptical of this in the short or medium term, though are compatible with centralised preference extrapolation later, once we’ve reached an appropriate epistemic state.
vs. Cosmic Bargains: A cosmic bargain could be the outcome of a waypoint phase (e.g. what humanity arrives at after a long reflection). The difference is about timing and confidence. Waypoint futures hold that we're not yet in a position to commit to a permanent settlement, while cosmic bargains describe what such a settlement might look like once we are.
What are the key assumptions and issues?
Key assumptions
The expected value of learning more before committing exceeds the expected cost of delay (though if the window for human influence is closing rapidly, this may be wrong).
Existential security can be achieved without making the very large-scale, irreversible decisions the long reflection is meant to deliberate on (this is the central paradox, see below).
A process of reflection will actually converge on something, or at least make progress, rather than spinning indefinitely.
The institutions and conditions that preserve optionality can themselves be maintained without creating new forms of lock-in.
AI systems that are hypercapable at moral philosophy, forecasting, and conceptual reasoning may be able to help during transitionary periods.
What enforces the "waypoint" character? If viatopia is supposed to preserve optionality while evolving toward better outcomes, what prevents it from drifting into lock-in anyway?
Who decides when the reflection is "done"? The answer might require either godlike oversight or institutions of a kind we don't know how to build. For example, a state of negligible existential risk is very likely to require large-scale irreversible decisions (about global governance, space colonisation, cognitive enhancement, AI deployment, etc) which are the same decisions the long reflection is supposed to deliberate on.
Cosmic Bargains
TLDR: Humanity makes a deal with its AI successors and accepts a bounded allocation of the universe in exchange for survival and flourishing within that allocation.
A visual representation (in which humans watch from their contained habitat as the rest of the universe is tiled) of this cluster co-created with Midjourney.
The core ideas this cluster depends upon:
Negotiated coexistence with entities that could take everything. The premise is that if superintelligences could in principle tile the accessible universe with their values, humanity's best realistic outcome may be securing a portion – not everything we might want, but enough for meaningful existence and flourishing. We’d accept harsh limits in exchange for survival.
Some form of leverage or reason for the deal to hold. For any bargain to be struck, the more powerful party must have reason to accept it. Potential sources of leverage could include:
current control over AI development ("we can choose not to release you")
decision-theoretic commitments
mutual benefit (deal terms make both parties better off than conflict)
reputational concerns in a multi-agent universe (superintelligence that reneges on deals fare worse in trade, so how they treat humans could be used as proof of credibility)
threat of mutual destruction during a transition period.[10]
How does this cluster relate to others?
vs. Liberal Pluralism: Liberal pluralism envisions an ongoing framework for coexistence with continuous exit rights. Cosmic bargains envision a one-time settlement that fixes the structure. Liberal pluralism maintains optionality; cosmic bargains close it off (by design, that's the point of reaching a resolution).
vs. Waypoint Futures: A waypoint future might lead to a cosmic bargain eventually, but the bargain itself is not waypoint-ish, it's an endpoint.
vs. Abundance Aligns Incentives: Abundance futures (generally) describe ongoing, emergent cooperation without requiring a single defining deal. Cosmic bargains are explicitly one-shot negotiations that determine the overall structure. The idea that abundance will align incentives is more bottom-up; cosmic bargains are more top-down.
vs. Preference Extrapolation: Preference extrapolation generally tries to figure out what humans would endorse on reflection. Cosmic bargains accept that we may not get everything we want, and instead our AI successors will. They're about securing survival, not optimal preference satisfaction.
What are the key assumptions and issues?
Key assumptions
Humanity has (or can acquire) meaningful leverage, some reason for a superintelligent AI to accept any deal at all rather than simply taking everything.
OR we end up in a world where AI systems independently decide to keep humans around for whatever reason (e.g. as a credibility mechanism to show they honour deals with less powerful beings when negotiating with other entities).
OR acausal considerations do the work: our superintelligent AI honours human flourishing because of decision-theoretic reasoning that incorporates other agents' preferences (e.g. aligned superintelligences elsewhere whose values overlap with ours), without any direct contact. Though this is more speculative than the other two and depends on contested decision-theoretic claims.
The deal can be enforced over cosmological timescales, or is somehow self-enforcing (neither party has incentive to defect once the deal is struck).
Key issues and gaps
How does humanity gain leverage in such a scenario? If you can't reliably read an AI's mind to verify it would honour a bargain, you might not trust any deal it proposes; and if you could reliably read its mind well enough to verify that, you could probably just build an aligned AI directly.
The bargaining framing probably assumes capabilities we don't have. We’d either have to assume leverage that may not exist (we're just not that threatening to a superintelligence) or assume AI decision theory that makes honouring bargains instrumentally rational, which may or may not be true and is hard to verify.
A strong case could be made that any form of “negotiation” is just an inaccurate framing entirely. If a superintelligent AI system is vastly more intelligent, the "negotiation" may be the ASI proposing something and humans accepting or refusing, not a genuine back-and-forth where human interests shape the outcome. This looks more like taking what you're offered than bargaining.
AI-Enabled Preference Extrapolation
TLDR: AI systems may be able to understand what humans would endorse on reflection better than humans can articulate it directly. Proposals in this cluster aim to extract and extrapolate those preferences, either through a centralised process that looks for coherence across humanity (Yudkowsky's CEV), or through decentralised extrapolation of individual preferences with mechanisms for handling disagreement.
Humans are bad at specifying what they want. We're inconsistent, short-sighted, often can't articulate our true preferences, and frequently don't know what we'd endorse under better epistemic and reflective conditions.
AI systems with deep models of human psychology might be able to do work humans can't. They would extrapolate not what people currently say they want, but what they would endorse on reflection: the preferences they'd hold if they knew more, thought faster, were more the people they wished to be, and had grown up further together.
“In poetic terms, our coherent extrapolated volition is our wish if we knew more, thought faster, were more the people we wished we were, had grown up farther together; where the extrapolation converges rather than diverges, where our wishes cohere rather than interfere; extrapolated as we wish that extrapolated, interpreted as we wish that interpreted.” (a quote from p. 6 of Yudkowsky’s CEV paper).
This cluster contains two main forms:
Centralised extrapolation (Yudkowsky's CEV proposal): a powerful optimisation process extrapolates across humanity's volitions and looks for coherence: strong agreement that isn't countered by strong disagreement. CEV is explicitly an initial dynamic, not a destination in and of itself. Its job is to bootstrap a transition to whatever humanity would want next, not to compute a final answer and impose it. The design is conservative about saying "yes" (positive action requires strong coherence) and quick to say "no" (vetoing predictable regret needs less), and if coherence can't be found, the process is supposed to fail visibly rather than force a result.
Decentralised extrapolation: individuals or smaller groups have personal AI agents that extrapolate their preferences, with mechanisms for handling disagreement when extrapolated preferences conflict (e.g. Coasean bargaining, or simulated deliberative democracy as in Jan Leike's proposal).
How does this cluster relate to others?
vs. Waypoint Futures: These clusters are structurally more similar than they might first appear. Both are doing "figure out before committing”. The main difference is who does the figuring out: waypoint futures lean on human deliberation (or AI-assisted), while preference extrapolation hands the reflection to AIs directly. The two can give off quite different impressions (preference extrapolation can sound like handing the problem over to AI, while waypoint futures sound like a deliberate human-led process), but the underlying telos is similar enough that the endpoint of one could plausibly be the starting point of the other. For example, a long reflection might decide the starting parameters of a CEV process.
vs. Liberal Pluralism: Liberal pluralism denies that any agent has the authority to determine values for others, while centralised extrapolation arguably puts an AI in exactly that position. In that sense the two are structurally opposed at the level of authority. But the outcomes don’t seem fully opposed: if extrapolation found that most people would, on reflection, endorse something like a liberal pluralist framework, its output would resemble what the liberal pluralist cluster aims at directly. The disagreement is more about who gets to decide, and through what process, than about what the resulting world looks like.
vs. Abundance Aligns Incentives: The decentralised version overlaps with Coasean bargaining (AI agents representing human preferences). The centralised version doesn't overlap much, since it routes through extrapolation rather than bargaining, though in principle the extrapolation could find that humanity's coherent volition endorses bargaining-style coordination.
vs. Cosmic Bargains: Preference extrapolation generally tries to figure out what humans would endorse on reflection. Cosmic bargains accept that we may not get everything we want, and instead our AI successors will.
What are the key assumptions and issues?
Key assumptions
Preferences can be reliably extracted and extrapolated without unacceptable distortion.
The extrapolation process can be specified well enough to do something close to what's intended (Yudkowsky is explicit that this is the hard part, and that his own proposal might be wrong or need replacing).
For the centralised version: it's possible to specify a satisficing initial dynamic that finds some coherent answer in the regions where coherence exists, and fails safely where it doesn't, without needing humanity's volitions to converge globally.
For the decentralised version: disagreements between extrapolated preferences can be resolved through compromise or bargaining.
Key issues and gaps
Issues specific to centralised extrapolation
Requires trusting whoever specifies the initial dynamic with enormous influence over the future, even if the dynamic is designed to refer most decisions back to humanity. The initial conditions still matter and the programmers still have to choose them.
Whether the dynamic actually does what's intended is unverifiable in advance. Yudkowsky's response is to insist on safeguards (a "Last Judge" who can veto, the ability to halt before irrevocable commitment, designing for visible failure rather than confident wrong answers), but obviously you need to assume that these safeguards themselves are implemented correctly.
The asymmetric, satisficing design helps with the "what if humanity doesn't cohere?" worry, since failure to find coherence is supposed to halt the process rather than force a result. However, this very much depends on the failure modes actually being detectable.
Issues specific to decentralised extrapolation
The compromise and bargaining mechanisms for handling disagreement are themselves underspecified, and inherit problems from the abundance cluster (transaction costs, commitment problems, fairness of initial conditions).
The line between "AI representing my preferences" and "AI subtly shaping my preferences" is hard to draw, and harder to police when every individual has their own AI.
No mechanism for catching collective error. Centralised CEV has a built-in story for "what if our current values are monstrous in ways we can't yet see" (extrapolate far enough that the moral error becomes visible). Whereas decentralised extrapolation just gives each person a better version of their own current preferences, with no equivalent mechanism for surfacing the kinds of mistakes that everyone is making at once.
Issues affecting both versions
Whose preferences count? Currently-existing humans only, or also digital minds, non-human animals? Different choices here produce very different futures.
The extrapolation process itself can't be straightforwardly verified. How do we know an AI's "extrapolation" corresponds to what we'd endorse on reflection rather than something subtly different?
Other Positive Visions
(This list is not comprehensive and there are surely other visions I’ve missed!)
The visions below either operate at a more concrete level than the clusters above, fit awkwardly across multiple clusters, or were left as shorter entries due to time constraints. I'm mostly including them as reference points for further reading.
Stratified Utopia
A proposal for dividing up the cosmos between different kinds of human values, as a way to handle moral uncertainty without any single value system winning outright.
"Mundane" values (e.g. partying, family, sacred sites) are scope-insensitive and want proximal resources: Earth, the solar system, the near future. "Exotic" values (e.g. utilitarianism, longtermism) are scope-sensitive and want distal resources: distant galaxies, the far future. Because each set of values cares about different stuff, both can get ~99% of what they want from the same cosmos.
Concretely, this looks like nested spatial shells expanding outward from Earth. Inner shells preserve recognisably human life. Outer shells progressively serve more exotic optimisation targets. The allocation could emerge through markets, bargaining, CEV, or an autocrat's mixed preferences, though it depends on values staying differentiated and no single value dominating the allocation mechanism.
A biotechnology-focused vision in which the goal is to eliminate suffering at its biological root, rather than treating its symptoms or rearranging the social conditions that produce it.
The core proposal, developed most prominently by David Pearce, is that the metabolic pathways producing pain, depression, and malaise are contingent products of evolution and can be re-engineered. Future minds could be built (e.g. via gene editing) around “informative-sensitive gradients of bliss” rather than the pleasure-pain axis we inherited.
This vision is mostly about science and biology rather than political or social structure, which is part of why it doesn't fit cleanly into the main clusters. It's most compelling if you weight suffering reduction very highly.
A vision of human enhancement that stops short of more radical transhumanist endpoints: uploads, wireheading, runaway self-modification, or the replacement of recognisably human life with something else.
Gavin Leech’s “Transnormalism” gives the descriptive version of this view. The claim is that society is already becoming transhumanist in practice through SSRIs, GLP-1s, hormones, embryo selection, cosmetic interventions, and similar technologies, but that most people use these tools to become more normal rather than stranger: healthier, more attractive, more stable, more fertile, more socially legible.
J. Sanilac’s “Ultrahumanism” gives the more prescriptive version. It argues for using technology to become better humans (e.g. longer-lived, healthier, more beautiful, more capable) while rejecting forms of transhumanism that would dissolve “human identity” altogether.
Bounded transhumanism could be seen as a middle ground between ordinary biological humanism and more radical visions of transformation.
Note that J. Sanilac’s essay is very long and the core principles are summarised at the end (though I’d recommend reading it in full, whether you agree with some flavour of transhumanism or not).
Merging with AIs
A vision in which humans and AI gradually integrate until the boundary between biological and artificial cognition becomes unclear or obsolete.
Near-term versions point to existing forms of cognitive offloading: smartphones, search engines, recommendation systems, AI assistants, and other systems that shape what people notice, remember, decide, and create. More radical versions would involve brain-computer interfaces, cognitive augmentation, and eventually mind uploading or whole-brain emulation.
This differs from bounded transhumanism mainly in being open to much more radical forms of transformation, including trajectories where recognisably biological human life is no longer the endpoint.[11]
A vision in which meaningful agency, individual and collective, remains with humans rather than migrating to artificial agents. In the post-AGI world envisioned here, humans are amplified by powerful cognitive tools and coordination infrastructure, but remain the entities that understand, deliberate, and decide. AI extends human capacities rather than substituting for them.
Underlying the vision is a claim about value: that agency is constitutive of human well-being and of our ability to navigate moral uncertainty, so a future in which humans have ceded decision-making to even well-aligned AI successors is worse than one in which they haven't. In practice, this means building non-agentic AI (e.g. AI tutors, “cognitive augmentation tools”) rather than autonomous agents, and treating the choice between the two as a structural one rather than a capability tier.
Rudolf Laine and Florence Hinder's post "Positive visions for AI" (2024) offers another overview, operating at a more concrete level than this post and covering scenarios where AI does humanity's mundane work, lowers coordination costs, and so on.
Nick Bostrom, "Letter from Utopia" (2008). A short, evocative piece written from the perspective of a posthuman future.
Eliezer Yudkowsky, “Fun Theory sequence” (2009). A theory of what makes “transhuman” lives go well, working through what utopia would need to contain (challenge, novelty, genuine effort, real stakes) to actually be worth wanting.
Vitalik Buterin, "My techno-optimism" (2023). Makes the case for differentially accelerating defence-favoured tech to keep pluralistic futures stable.
Fiction as a complement to analysis. I think fiction (namely, sci-fi) does something more analytic work largely can't: rendering visions concrete and emotionally legible rather than just conceptually specified. For example, Iain M. Banks's Culture novels are the most frequently cited example, often invokedbyAI company CEOs as a positive reference point, and have arguably shaped the ambient sense of what a good post-AGI future looks like just as much (if not more) than any single piece of analysis. Richard Ngo's "The Gentle Romance" (2025) is another piece of fiction I'd point to (though less provably influential, it is probably the best piece of AI-related fiction I’ve read). It follows one person from AI-assistant adoption through to full virtuality, and is unusually good at making a particular transhumanist trajectory feel lived-in rather than argued-for (part of its value is that it leaves you genuinely unsure whether the ending is utopian).
Observations on the Overall Landscape
(The observations below are my own personal takes on the landscape).
Positive visions tend to lack a theory of transition
Most visions describe stable end-states or equilibria but underspecify how we get there from our current world. The dangerous window (in which AI capabilities are advancing, coordination infrastructure is yet to be built, power is up for grabs, etc) is where most bad outcomes concentrate, and "last scramble" dynamics could derail any vision before it stabilises.
Transition dynamics are (obviously) super hard to reason about, which is probably why most visions skip this step. But timelines to transformative AI now look short enough that some engagement with the path is worth attempting, even at a high level.
A vision that describes a desirable equilibrium without engaging the path to it leaves out the part that's most actionable.
The "cure cancer, solve energy" consensus ignores the hard questions
This is the level at which most frontier AI company leadership (and most public societal discussion) usually operates when discussing positive AI futures.
When Dario Amodei, Sam Altman, Demis Hassabis, or Elon Musk describe what "AI going well" looks like, they typically point to outcomes like curing diseases, solving energy, radically improving education, allowing humans to work less, and generally increasing material prosperity.
The visions surveyed in this post mostly take these outcomes for granted as a shared baseline: a world with cured diseases, clean energy, better education, increased material abundance, and so on. I think that baseline matters and is very much worth fighting for (especially when it comes to using AI to improve the lives of animals). However, I don’t think it’s sufficient because:
The equilibrium of "AI solves cancer but doesn't transform everything else" is probably unstable; someone pushes further.
Once the low-hanging fruit is picked, you still need to address thorny issues relating to governance, norms, power, and so on.
Differentially accelerating epistemic and coordination tech looks valuable across nearly every vision
Tools that improve our collective ability to reason, forecast, negotiate, and coordinate (see Forethought's post on "Design sketches for a more sensible world" for more on what these could look like) are robustly valuable across all the clusters.
Liberal pluralism needs coordination infrastructure to manage coexistence between diverse communities. Abundance-driven cooperation needs low transaction costs and reliable information to make bargaining feasible. Waypoint futures need better epistemic tools almost by definition. Even cosmic bargains benefit from better negotiation and assurance tech during whatever window of leverage humanity has.
If you're uncertain about which vision is right, accelerating the things that help across nearly all of them is a strong default.
Vision preferences seem heavily shaped by a few important variables
A lot of apparent disagreement about which positive visions are preferable comes down to disagreement about a few underlying variables. People think they're arguing about which future to aim for, when they're actually arguing about empirical or metaethical questions upstream of that. Surfacing these variables explicitly is more productive than debating visions directly. Three keep showing up:
AI threat models. If your primary concern is catastrophic AI misuse (e.g. via extreme offence dominance in relevant capabilities), you'll gravitate toward visions that concentrate power to an extent, and accept the risks that brings. If your primary concern is AI-enabled value lock-in or power concentration itself, you'll prefer visions that keep power distributed (liberal pluralism, abundance-driven cooperation), accepting more "chaos around the edges" to preserve optionality and avoid permanent moral error.
Offence/defence balance. Related to threat models but worth separating out. The visions you prefer are often downstream of how offence vs defence dominant you expect the future to be. If you expect defence dominance, multipolar visions look more stable and attractive. If you expect offence dominance, you might reluctantly prefer singleton visions (a benevolent singleton, or cosmic bargains), not because they're intrinsically better but because they might be the only stable equilibria.
Whether moral truth exists and is tractable. If moral realism is true and the truths are the kind of thing a capable enough reasoner could discover, single-reflector approaches like centralised CEV look better. If not, or if value is more like something that emerges from multi-agent dynamics over long timescales, pluralist and adaptive approaches look more necessary. Seems like many apparent disagreements about visions are really disagreements here.
Visions differ in whether they specify a destination (end state) or a generator (process)
Some clusters point at a target end state. Cosmic bargains, for example, specify a particular kind of negotiated settlement that fixes the structure of the future. These are destination visions and they tell you what the future is supposed to look like.
Others specify a generator. Liberal pluralism doesn't say what the future contains, only that it's produced by diverse communities pursuing their own conceptions of flourishing within a framework that protects exit. Waypoint futures explicitly refuse to specify an end state and instead describe conditions under which good decisions can be made later. Abundance-driven cooperation describes a mechanism (incentive shifts plus coordination tech) that produces good outcomes without committing to what those outcomes are.
Generator visions are hedged against the possibility that we don't yet know what to aim for. Destination visions assume we do, or that we can figure it out before committing. A generator vision succeeds if it preserves the conditions for ongoing course-correction, even if the resulting world looks unfamiliar. A destination vision succeeds only if the specified end state is actually reached. The two come apart most sharply on questions of lock-in, since destination visions are willing to foreclose options to secure the target, whereas generator visions treat that foreclosure as the failure mode.
Other observations and open questions
Is lock-in eventually inevitable?
To preserve optionality (e.g. during a Long Reflection) or guarantee exit rights (e.g. in liberal pluralist worlds), you may need to lock in the meta-framework (or at least make it incredibly hard to change) that does the preserving/enforcement of the vision. This itself seems like a form of value imposition (you can't have a rule against permanent rules without that rule being permanent).[12]
Unbounded utility maximisers cause lots of problems
A lot of visions seem to (either implicitly or explicitly) assume actors with diminishing marginal utility. Those that are satisfied with "enough." But if any actor has unbounded goals (wants all the resources, all the status, all the universe), cooperation and coexistence frameworks become harder.[13]
There are lots of unanswered questions about the role of humans in post-AGI futures
Most visions are somewhat ambiguous about whether humans remain central agents making meaningful decisions, become protected beneficiaries in a world run by smarter systems, or get transcended or deprecated entirely. To some, this could be the most important question when deciding which vision they resonate with most, and it seems like it's often treated as a detail to be worked out later.
The question is also entangled with the moral status of AI systems themselves. Most visions seem to sidestep this by either bracketing AI moral status entirely or assuming a particular answer without flagging it. This seems very important to consider, given the outcome of humans no longer being central carries radically different valences depending on what one believes about the agents who would take their place.
Future Directions
This project covered a lot of ground at a relatively high level, so there are many directions for follow-up work.
The directions below attempt to complement that agenda.
Finding actions, paths, and tools that are helpful no matter which vision you prioritise. As mentioned previously, differentially accelerating epistemic and coordination tech looks like a particularly strong candidate here. Further work could identify other candidates in this category and develop concrete theories of change for advancing them.
Building theories of change for individual visions: taking one cluster as the target and working out the concrete actors, institutions, and sequencing that would advance it. This is more specific than the transition work described below (which asks what the dangerous window looks like for anyone), and directionally similar to IAPS's "Strategic Visions in AI Governance" report, though pitched at more abstract, longer-term considerations.
Ranking visions by desirability. Given this post's premise that people disagree on the metric itself, this is as much about making one's metric explicit and defending it as about producing the ranking.
Thinking of more ways to operationalise positive visions work and make it less abstract. This could include figuring out which visions actually resonate with which people (directionally maybe via something similar to Anthropic's Interviewer tool), and creating more narrative (yet concrete) vignettes of positive AI futures (see Owen Cotton-Barratt's "Some Days Soon" for the kind of thing I mean).
Reworking visions to take digital minds seriously. Most of the visions surveyed here treat AI systems instrumentally, as tools, threats, or enabling infrastructure, rather than as potential moral patients with their own stakes in how the future goes. This seems like a significant gap, and one that probably fits best within the emerging field of digital minds governance.
Work here could examine what AI flourishing might consist of and whether it differs from human flourishing in ways that matter for vision design; rework visions on the assumption that AIs are agents with their own stakes; and engage with visions in which digital minds are full political participants.
More rigorously sorting visions into "processes" (how we arrive at a world, or the direction we're headed) versus "outcomes" (final desirable end states).
Relatedly, sorting claims within visions into empirical versus philosophical: "will liberal pluralism be less competitive post-AGI?" is empirical, whereas "is permanent human disempowerment bad if AI successors flourish?" is philosophical, and the two need different methods and approaches.
Generally pointing out issues with the clusters I came up with, and surfacing new visions (and ways of categorising them) that I missed.
Other open questions
How worried should we actually be about actors with unbounded utility functions?
How does the "type of AI" we get affect which positive visions are most feasible? E.g., if we end up in a "multipolar" world where there are many AI systems with different goals/properties, or a "singleton" world where there is one single superintelligent system, for example one that surpassed humans via continual learning and then kept going and going. Beren Millidge's post on "AI Monotheism vs AI Polytheism" is relevant here.
Trying to come up with positive visions from religious thought and non-Western philosophy. Needless to say, the visions in this post draw almost entirely from AI safety, EA, rationalist, and analytic philosophy discourse.
Could tree diagrams help map all this? E.g. build a tree diagram of how different starting assumptions (such as the nature and trajectory of relevant AI capabilities) branch into different futures, and whether those paths end in locked-in or revisable states.
How do we navigate worlds where all leverage over the future is ceded, gradually or suddenly, to AI systems? Is this even a tractable question?
Acknowledgements
Thank you to Rose Hadshar for her valuable mentorship and feedback.
Thank you to Avi Parrack, Gregory Lewis, James Tilman, Jordan Arel, Linchuan Zhang, Lydia Nottingham, Matthew Adelstein, Max Dalton, Mia Taylor, Oscar Delaney, Owen Cotton-Barratt, Rudolf Laine, Stefan Torges, Tamera Lanham, and Tom Davidson for feedback on drafts (as well as for useful discussions).
Thank you to Claude Opus 4.7 for help with editing/drafting parts of this post.
Appendix I: The vision I personally find most compelling
Epistemic status: Strong opinions, weakly held. All the problems discussed below are extremely hard and humanity doesn’t (yet) have answers to them.
I’m most sympathetic to liberal pluralist futures (with defence-favoured tech to help get us there).
Value determination looks to me more like an ongoing process than a solvable problem. The space of possible values seems too large, too entangled with other agents, and too dynamic to be modelled by any single reflector (even a superintelligent one).
If that’s right, the appropriate response is structures that can learn and adapt. Diverse communities pursuing different conceptions of flourishing. Not structures that try to compute the answer and lock it in (e.g. directionally imagine CEV-style futures).
The case rests on two considerations. First, verification. Even if some entity claimed it had identified the correct values, we’d have no reliable way to check, whether that entity is a mega-wise human institution or a superintelligent AI.
I think our track record of confidently held moral beliefs that turned out monstrous should make us wary of any proposal to propagate values across the universe, ours or an AI’s extrapolation of ours. A future in which no single entity can tile the universe seems much safer than one in which we bet on the “right” entity doing so.
Second, the errors here seem super asymmetric. Going slowly because we don’t yet know what we’d be propagating does cost us time. Yet, propagating while wrong is uncorrectable by construction. This is the maximum case of path dependence, so it’s the case where you most need to be right before you act. And I think this argument doesn’t even require believing pluralism is definitively correct; it only requires that irreversibility is bad and our error bars are wide (which seem like pretty reasonable assumptions).
Yes, picking pluralism may itself be a kind of lock-in. “No single entity can impose values” is a meta-value, and committing to it may propagate something irreversibly, just one level up. But if you have to lock in one thing, I’d say you should lock in the framework that keeps the most options open underneath it, rather than any object-level answer about what’s good. It seems to me like the least-committal commitment on offer, and its characteristic error stays recoverable.[14]
So the big practical question is: how do we make distributed-power futures stable enough to persist?
Defensive acceleration seems like it could provide the foundation. Though this depends on getting several hard problems right. For example:
How do we handle open-weight models (especially across jurisdictions) if AI systems become capable enough to enable catastrophic misuse?
Pluralism needs distributed access to capability, but that’s the same condition that makes misuse easier.
And which type (e.g. gradual erosion vs sudden coup) should direct more resources towards avoiding?
What’s the best plan once AI R&D is automated? This is the scenario where the window for keeping power distributed seems like it could close the fastest (e.g. via one actor having a decisive strategic advantage).
What would change my mind about all this? Mainly whether defence-favoured coordination tech can actually exist at the relevant capability levels. If it isn’t ready in time, distributed power may collapse (e.g. due to misuse or a scramble to concentrate), long before anyone gets to worry about the deeper concerns.
The deeper concerns I’m imagining: if the world turns out to be inherently offence-favoured, or if galactic-scale existential risks (catalogued in Jordan Stone’s “Interstellar travel will probably doom the long-term future”) turn out to be both real and unavoidable, then centralisation might be inevitable.
The best we could hope for in that world would be that the “right” entity centralises, ideally with course-correction and good values built in.
But for now, I think the case to keep the future open is hard to argue against.
Appendix II: Ways to combine clusters
As mentioned in the introduction, the clusters of positive visions identified are best understood as combinable ingredients rather than competing menu options.
The table below sketches how each pair might interact, with some combinations looking natural and others looking forced or directly opposed.
It's worth asking whether thinking about good post-AGI futures fundamentally comes down to thinking about good futures. I think the answer is basically no: AGI introduces challenges that don't otherwise arise, or raises their stakes enough to change the problem.
For example, the possibility of value lock-in makes present choices unusually irreversible. Radical capability asymmetries strain coordination and enforcement mechanisms that work tolerably well between roughly-peer humans. Digital minds raise lots of very tough questions about who inhabits the future. And the sheer scale of accessible resources turns previously abstract questions about the far future into live ones.
So while much of the existing thinking (i.e., political and utopian thought broadly), about flourishing and coexistence may carry over, the visions included here are responses to a specifically post-AGI problem, not generic utopianism.
"Post-AGI" here refers to a world in which advanced AI systems have dramatically reshaped the economy and society at scale, roughly equivalent to the way the concept "transformative AI" is used.
This post focuses on describing high-level structural features (e.g. relating to values and incentives) rather than concrete worldbuilding.
For example, a cluster like "Liberal Pluralist Futures" describes a structural commitment (pluralism, exit rights, anti-domination) rather than a specific picture of what life inside such a future actually looks like. I think concrete worldbuilding is incredibly valuable, but it's a different exercise and largely outside the scope of this post.
Abundance dynamics could be a causal ingredient in nearly any vision (except perhaps preference extrapolation), providing the material conditions that make coexistence feasible.
Liberal pluralist norms could describe what we do within a waypoint phase, or how we govern our portion of a cosmic bargain.
Waypoint futures could precede any of the other end-states, and abundance-driven cooperation may itself function as something close to a waypoint.
Diminishing marginal utility is what makes abundance dampen conflict. I.e., when you already have a lot, the next unit isn't worth what you'd risk to take it. Linear utility removes that effect, since the next unit is worth as much as the last. Positional goods like status are worse still, because they're intrinsically zero-sum and thus unaffected by abundance.
See the “Plurality” programme (by Audrey Tang, E. Glen Weyl and collaborators) for one vision of coordination technology aimed at sustaining cooperation across deep social differences.
A related complication: digital minds could in principle be engineered never to want to exercise their exit rights, regardless of how their lives are actually going. Preventing this would require the enforcement layer to constrain what kinds of minds can be created in the first place, which expands the meta-framework's reach considerably and raises further questions about who decides what counts as an acceptable mind design.
This section is shorter than others, given the aforementioned issues and gaps have already been discussed in pre-existing writings (e.g. see Robin Hanson’s criticism of the Long Reflection).
There are many other reasons a cosmic bargain could occur. E.g. the AI systems decide to keep humans around due to inscrutable “sentimental” reasons, etc.
One family of visions deliberately omitted here is what might be called "successionist" visions, in which humanity's role is to produce flourishing AI successors and cede the future to them (via a sudden or gradual handover). This is held as a positive vision by some (e.g. Hans Moravec, parts of Robin Hanson's writing, strands of contemporary AI development culture), who frame it as something like generational succession at civilisational scale rather than as a devastating loss.
I've left it out of the main survey because whether it counts as a positive vision is itself one of the most contested questions in the space, and engaging it seriously would require a whole separate post.
One partial resolution is that the meta-framework doesn't need to be literally permanent, just entrenched enough that changing it requires broad consensus. Constitutions are probably the closest existing analogue here: hard to amend, but not impossible. If you take this view, entrenchment and lock-in might come apart. The rule against permanent rules can itself be revisable, just costly to revise, which avoids the strict self-contradiction. Though I don't think this fully dissolves the tension, given "hard to change" still shades into "locked in" if you make it hard enough, and post-AGI conditions plausibly would compress the distance between the two.
One response to this is that unbounded actors still have incentives to trade rather than fight (conflict is costly to them too), and that as long as they remain a small fraction of overall power, the rest of the system can keep them in check. This seems partly right, but I think it understates the problem because trade works while there’s slack, but unbounded goals eventually run into the resources that bounded actors are actually using (e.g. in extreme scenarios, the physical space they are inhabiting), at which point the trade surplus disappears. Also “kept in check” requires enforcement infrastructure robust to capability asymmetries, which is the same hard problem that shows up in the liberal pluralism cluster.
If an end state is eventually needed, I find some form of stratified utopia the most appealing long-run shape: a way of allocating the cosmos that lets different value systems each get most of what they want from the same universe. The post’s sketches of what each stratum could look like, from a humane near-Earth world through to substrates optimising for things we barely have concepts for, make “pluralism with allocation” into something I can (very) roughly picture.
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...



This post is a great start to thinking about these (very difficult) questions - thanks for writing it!
Thanks :)