In particular, superforecasters are generally more sceptical of such short AI timelines.
Note that this is true only of some subset of superforecasters. Samotsvety’s forecasters (many of whom are superforecasters) have shortertimelines than both domain experts and general x-risk experts:
Thank you for this helpful response, Pablo! This is a really interesting result to note. I was not aware of this when writing my post, but I'll plan to include Samotsvety forecast results in future work on this subject, and when I come to write up my findings more formally.
I am curious how you think about integrating social and political feedback loops into timeline forecasts.
Roughly speaking,
(a) when we remain in the paradigm of relatively predictable progress (in terms of amount of progress, not specific capabilities) enabled by scaling laws,
(b) we put significant probability on being fairly close to TAI, e.g. within 10 years,
(c) it remains true that model progress is clearly observable by the broader public,
then it seems that social and political factors might drive a large degree in the variance of expectable timelines (by affecting your (E2)).
E.g. things like
(i) Sam Altman seeking to discontinously increase chip supply
(ii) How the next jump in capabilities will be perceived, e.g. if it is true that GPT-5 will be another similarly sized jumped compared to what we've seen from GPT-3 to GPT-4 what policy and investment responses will this cause?
(iii) whether there will be a pre-TAI warming shot that will lead to a significant shift in the Overton Window and more serious regulation.
It seems to me that those dynamics should take up a larger part of the variance the closer we get so I am curious how you think about this and whether you will include this in your upcoming work on short timelines.
Hi Jack, thanks for your comment! I think you've raised some really interesting points here.
I agree that it would be valuable to consider the effect of social and political feedback loops on timelines. This isn't something I have spent much time thinking about yet - indeed, when discussing forecast models within this article, I focused far more on E1 than I did on E2. But I think that (a) some closer examination of E2 and (b) exploration of the effect of social/political factors on AI scenarios and their underlying strategic parameters - including their timelines! - are both within the scope of what Convergence's scenario planning work hopes to eventually cover. I'd like to think more about it!
If you have any specific suggestions about how we could approach these issues and explore these dynamics, I'd be really keen to hear them.
I am also just beginning to think about this more, but some initial thoughts:
Path dependency from self-ampliying processes -- Thinking about model generations as forks where significant changes in the trajectory become possible (e.g. crowding in a lot more investment, as has happened with ChatGPT/GPT4, but also, as has also happened, a changed Overton window). I think overall this introduces a dynamic where the extremes of the scenario space become more likely, with social dynamics such as strong increase in investment or, on the other side, stricter regulation after a warning shot, having self-amplifying dynamics. As the sums get larger and the public and policy makers pay way more attention, I think the development process will become a lot more contingent (my sense is that you are already thinking about these things at Convergence).
Modeling domestic and geopolitics -- e.g. the Biden and Trump AI policies probably look quite different, as does the outlook for race dynamics (essentially all mentions of artificial intelligence by Project 2025, a Heritage-backed attempt to define priorities for an incoming Republican administration, are about science dominance and/or competition with China, there is no discussion of safety at all).
Modeling more direct AI progress > AI politics > AI policy > AI progress feedback loops, i.e. based on what we know from past examples or theory, what kind of labor displacement would one need to see to expect serious backlash? what kind of warning shots would likely lead to serious regulation? and similar questions.
I'm wondering how you went about sampling your list of personal judgement based predictions. Did you list all the predictions you could find, or did you vet them for notability? Like, while I am generally on Robin Hanson's side here and think his arguments are worth hearing out, it feels weird to have him there alongside top-level AI researchers.
I guess I'm saying that the personal predictions should probably be taken with a grain of salt, as they are skewed towards what is available and known among an EA/Rationalist crowd. And also because said crowd is far more likely to make a numerical prediction, while skeptics are less in the habit of doing that.
Thank you for this feedback - these are good points! Glad you liked the article.
The way I approached collecting personal judgement based predictions was roughly as follows:
I came up with an initial list of people who are well known in this space
I did some digging on each person on that list to see if any of them had made a prediction in the last few years about the timeline to TAI or similar (some had, but many of them hadn’t)
I reviewed the list of results for any obvious gaps (in terms of either demographic or leanings on the issue) and then iterated on this process
It was in step 3 that I ended up seeking out Robin Hanson’s views. Basically, from my initial list, I ended up with a sample that seemed to be leaning pretty heavily in one direction. I suspected that my process had skewed me towards people with shorter timelines - as someone who is very new to the AI safety community, the people who I have become aware of most quickly have been those who are especially worried about x-risks from AI emerging in the near future.
I wanted to consciously make up for that by deliberately seeking out a few predictions from people who are known to be sceptical about shorter timelines. Robin Hanson may not be as renowned as some of the other researchers included, but did his arguments did receive some attention in the literature and seemed to be worth noting. I thought his perspective ought to be reflected, to provide an example of the Other Position. And as you point out - many sceptics aren’t in the business of providing numerical predictions. The fact that Hanson had put some rough numbers to things made his prediction especially useful for loose comparison purposes.
I agree with what you say about personal predictions needing to be taken with a grain of salt, and the direction they might skew things in, etc. Something I should have perhaps made clearer in this article: I don’t view each source mentioned here as a piece of evidence with equal weight. The choice to include personal views, including Robin Hanson’s, was not to say that we should weight such predictions in our analysis in the same way as e.g. the expert surveys or quantitative models. I just wanted to give a sense of the range of predictions that are out there, pointing to the fact that views like Hanson’s do exist. Based on your comment, I might add some more commentary on how ‘not all evidence is equal’ when I go on to formalise my findings in future work; I think it’s worth making this point clearer.
Executive summary: A review of notable AI timeline predictions suggests growing support for the plausibility of transformative AI (TAI) arriving within the next few decades, though limitations of forecasting and counterarguments leave the overall picture uncertain.
Key points:
Recent surveys, forecasts, and expert predictions generally estimate a 10-50% chance of TAI arriving within the next 10-40 years, with a trend towards shorter timelines in the past few years.
Many predictions rely on the scaling hypothesis, which posits that increased computational power will lead to arbitrarily powerful AI systems.
Two influential forecast models, Cotra's biological anchors and Epoch's Direct Approach, yield median TAI predictions within a few decades of each other despite differing assumptions.
Limitations of forecasting, such as framing effects, information cascades, and the difficulty of identifying long-term trends, cast doubt on the reliability of timeline predictions.
Counterarguments, like the historical pattern of AI winters and Mitchell's proposed fallacies underlying short timeline beliefs, provide reasons for skepticism.
Despite uncertainties, the growing expert support for shorter timelines warrants taking the possibility seriously in strategic planning and risk mitigation efforts.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, andcontact us if you have feedback.
Timelines to Transformative AI: an investigation — EA Forum
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This post is part of a series by Convergence Analysis’ AI Clarity team.
Justin Bullock and Elliot Mckernon have recently motivatedAI Clarity’s focus on the notion of transformative AI (TAI). In an earlier post, Corin Katzke introduced a framework for applying scenario planning methods to AI safety, including a discussion of strategic parameters involved in AI existential risk. In this post, I focus on a specific parameter: the timeline to TAI. Subsequent posts will explore ‘short’ timelines to transformative AI in more detail.
Feedback and discussion are welcome.
Summary
In this post, I gather, compare, and investigate a range of notable recent predictions of the timeline to transformative AI (TAI).
Over the first three sections, I map out a bird’s-eye view of the current landscape of predictions, highlight common assumptions about scaling which influence many of the surveyed views, then zoom in closer to examine two specific examples of quantitative forecast models for the arrival of TAI (from Ajeya Cotra and Epoch).
Over the final three sections, I find that:
A majority of recent median predictions for the arrival of TAI fall within the next 10-40 years. This is a notable result given the vast possible space of timelines, but rough similarities between forecasts should be treated with some epistemic caution in light of phenomena such as Platt’s Law and information cascades.
In the last few years, people generally seem to be updating their beliefs in the direction of shorter timelines to TAI. There are important questions over how the significance of this very recent trend should be interpreted within the wider historical context of AI timeline predictions, which have been quite variable over time and across sources. Despite difficulties in obtaining a clean overall picture here, each individual example of belief updates still has some evidentiary weight in its own right.
There is also some conceptual support in favour of TAI timelines which fall on the shorter end of the spectrum. This comes partly in the form of the plausible assumption that the scaling hypothesis will continue to hold. However, there are several possible flaws in reasoning which may underlie prevalent beliefs about TAI timelines, and we should therefore take care to avoid being overconfident in our predictions.
Weighing these points up against potential objections, the evidence still appears sufficient to warrant (1) conducting serious further research into short timeline scenarios and (2) affording real importance to these scenarios in our strategic preparation efforts.
Introduction
The timeline for the arrival of advanced AI is a key consideration for AI safety and governance. It is a critical determinant of the threat models we are likely to face, the magnitude of those threats, and the appropriate strategies for mitigating them.
Recent years have seen growing discourse around the question of what AI timelines we should expect and prepare for. At a glance, the dialogue is filled with contention: some anticipate rapid progression towards advanced AI, and therefore advocate for urgent action; others are highly sceptical that we’ll see significant progress in our lifetimes; many views fall somewhere in between these poles, with unclear strategic implications. The dialogue is also evolving, as AI research and development progresses in new and sometimes unexpected ways. Overall, the body of evidence this constitutes is in need of clarification and interpretation.
This article is an effort to navigate the rough terrain of AI timeline predictions. Specifically:
Section I collects and loosely compares a range of notable, recent predictions on AI timelines (taken from surveys, tournaments, influential figures, and forecast models);
Section III describes, in detail, two influential models for forecasting the arrival of transformative AI (Ajeya Cotra’s approach via ‘biological anchors’ and Epoch’s ‘Direct Approach’) based on the assumption of the scaling hypothesis, and considers objections to both approaches;
Section IV observes some commonalities and general trends in the collected set of AI timeline predictions;
Section V questions whether the surveyed views and arguments provide a compelling evidence base from which to draw conclusions about the timeline to transformative AI;
In the final section, I offer my assessment that, despite objections, there is still enough weight behind the plausibility of scenarios with short timelines to TAI to warrant affording real importance to such scenarios in our strategic preparation efforts.
Two notes should be taken into consideration when reading this article: one on the scope of the content I have reviewed, and one on the various characterisations of advanced AI that have been employed.
A note on the scope of this post. This article is not a comprehensive review of the current state of timeline predictions. I present and investigate a wide range of recent, important examples of predictions from the literature. Convergence’s AI Clarity team worked together to collect an initial list of relevant sources. My own findings during the writing process then informed an iterative process of identifying further sources to include, aiming to cover as much ground as was reasonable given the questions I sought to shed light on and my time constraints.
In the Appendix, I list additional sources of possible interest to this discussion which I have not covered in this post.
A note on the characterisation of advanced AI. For the purposes of our scenario planning work, Convergence Analysis will typically use the notion of transformative AI (TAI) as the key milestone for AI progress.[1] Loosely, TAI is defined as AI that is capable enough to bring about a societal transformation comparable – or greater – in scale to the industrial and agricultural revolutions (following e.g. Maas, 2023). Note that reaching this milestone is, as currently stated, is about the development of AI with capabilities that could transform society. The arrival of TAI in a lab setting would not itself constitute a societal transformation; this would only come from the (sufficiently widespread) adoption of TAI.
In a previous post, ‘Transformative AI and Scenario Planning for AI X-risk’, my colleagues have specified the notion of TAI in more detail, and outlined our reasons for generally favouring it over alternatives such as artificial general intelligence (AGI) or superintelligence.
Some of the views described in this article are explicitly in reference to the arrival of TAI. However, in the current discourse on AI timelines, many different benchmarks for AI progress are employed. Prevalent notions besides TAI which are often the focus of timeline predictions include AGI, human-level AI (HLAI), high-level machine intelligence (HLMI), and superintelligence.
We believe that the adoption of such forms of advanced AI would also precipitate a major transformation of society. Reaching any of these milestones would be an indication that what we would call TAI has either been achieved, or is at least very near. Predictions of timelines to other characterisations of advanced AI therefore still shed light on the expected arrival of TAI, and are of consequence within this article.
I will sometimes use phrases like ‘transformative AI or similar’, ‘transformative forms of AI’, and ‘TAI-level capabilities’ to capture a range of different benchmarks for AI progress which are closely correlated with the potential for major societal transformation.
I. What do people think about AI timelines?
In this section, I’ll chart out the current territory of AI timeline predictions.
I begin with a bird’s-eye view of the landscape, turning to collective wisdom: when do different groups of people believe that advanced AI will arrive, on average? Here, I’ll gather aggregated predictions from sources including surveys, forecasting tournaments, and community prediction platforms.
I will then zoom into specific examples of timeline predictions from experts, alongside notable results from recent modelling efforts.
Finally, I’ll summarise these predictions in a table (Figure 2).
Aggregate views
Expert surveys
The largest surveys of expert opinions on AI in recent years have been conducted by AI Impacts in 2016, 2022, and 2023.[2] Their 2023 survey, which elicited responses from 2,778 AI researchers who had published at top-tier AI venues, found that (on aggregate) experts believed there was:
10% probability of high-level machine intelligence (HLMI) arriving by 2027
50% probability of high-level machine intelligence (HLMI) arriving by 2047
Where HLMI was defined as being achieved when “unaided machines can accomplish every task better and more cheaply than human workers” (p4).
The aggregate result of a 50% chance of HLMI arriving by 2047 is particularly striking in comparison to similar surveys conducted just a few years earlier, whose aggregate forecasts point towards longer timelines.
For example, a 2018 expert survey from Gruetzemacher et al. asked respondents to predict when an AI would be able to perform 99% of tasks humans are paid to do as well as humans. Its aggregate forecast assigned 50% probability to such systems arriving by 2068, over 20 years later than the corresponding AI Impacts result. Similarly, the aggregate forecast from the Zhang et al. 2019 expert survey assigned 50% probability to AI being able to perform at least 90% of economically relevant tasks as well as humans by 2060. These results are especially notable given that both surveys employed benchmarks of AI progress which were slightly short of AI Impacts’ definition of HLMI.[3]
So, between 2022 and 2023, the experts’ 50% probability prediction for the arrival of HLMI has jumped 13 years closer.[5] This is a dramatic shift over just one year – especially in comparison to the minor shift seen over the six years between AI Impacts’ 2016 and 2022 surveys, where the aggregate 50% probability prediction only moved from 2061 to 2060.
This shortening of aggregate timeline predictions can almost certainly be attributed to the rapid advances in AI development seen in the last few years (such as the emergence of ChatGPT in late 2022) prompting many individuals to update their expectations.
But the trend of expert surveys yielding shorter timelines as time goes on does not hold absolutely. Let’s look back further in time, to 2012-2013, when Vincent Müller and Nick Bostrom conducted one of the earliest large-scale expert surveys of this kind (results published in 2016).[6] The aggregate forecast from 550 expert participants assigned 50% probability to the arrival of HLMI by 2040, seven years earlier than the AI Impacts 2023 survey’s corresponding prediction.[7]
The specific characterisation of advanced AI used in survey questions has also been a significant determinant of predictions in the expert surveys referenced above. In particular, AI Impacts has observed such ‘framing effects’ in its survey results. Alongside questions about HLMI, the survey also asked respondents parallel questions concerning the arrival of ‘full automation of labour’ (FAOL), which would be achieved when “for any occupation, machines could be built to carry out the task better and more cheaply than human workers” (2023 report, p7). Survey questions concerning FAOL consistently elicited much longer timelines than those concerning HLMI (in all three survey years, there was over 60 years’ difference in the corresponding aggregate 50% probability predictions).
This is an odd discrepancy, as the terms HLMI and FAOL appear to capture closely related notions of advanced AI. For a direct comparison, let’s restate the definitions. We have:
HLMI Achieved when unaided machines can accomplish every task better and more cheaply than human workers.
vs FAOL Achieved when, for any occupation, machines could be built to carry out the task better and more cheaply than human workers.
Based on these definitions, the arrival of HLMI seems to imply that FAOL is nearby (if not, in fact, already achieved). The sensitivity of aggregate forecasts to such small shifts in framing casts doubt on the accuracy of expert surveys in general, and is highlighted again in Section IV.
I view the AI Impacts survey responses on FAOL as secondary in importance to those on HLMI. This is partly because most predictions in this section appear to be concerned with the development of transformative AI – its initial arrival in a lab setting – rather than its implementation, and I suspect that the question on HLMI timelines has done a better job of capturing its respondents’ intuitions about this particular event than the corresponding question on FAOL. Although the survey authors urged respondents to “think feasibility, not adoption” in both cases, it seems, on reflection over the discrepancies between the responses received, that the term ‘full automation of labour’ may sometimes have been falsely interpreted as referring to the implementation of systems. (The word ‘automation’ seemingly implies action in the world, rather than the mere capability of action.)
In any case, the notion of HLMI characterised by AI Impacts is already, in my view, strong enough to count as a form of transformative AI. So, to answer questions about the arrival of TAI, it’s enough to look at the HLMI result here. If FAOL is considered by survey respondents to be stronger than HLMI, then their forecasts for FAOL are possibly best interpreted as referring to a development in a post-TAI world.
Although I include results on FAOL questions in Figure 2 and do not exclude them from any subsequent discussion of the sources in this section, I do not weight these results heavily in the formation of any conclusions.
Community predictions
Metaculus has aggregated thousands of user predictions on the development of AI. As in the expert surveys referenced above, the forecasting platform has seen a notable shortening of AI timeline predictions in recent years. As of February 2024, the aggregated community prediction for a 50% chance of AGI arriving is 2031, ten years sooner than its prediction of 2041 exactly one year ago.
These aggregated results gesture towards shorter expected timelines for transformative forms of AI than those indicated by both Metaculus and recent expert surveys.
In the same year, a Public First survey of 2,000 adults in the UK more closely echoed other recent results (such as the Metaculus prediction), with 2030-2039 as the respondents’ median expected time frame for the arrival of AGI.
Superforecasters
The median predictions (and aggregated 50% probability assignments) for the arrival of TAI described so far have mostly been clustered within 2-25 years from now. Indeed, the most notable exceptions to this were conducted five or more years ago, predating major recent advances in AI capability. However, not all recent group forecasts point so strongly towards the imminent arrival of TAI.
In particular, superforecasters are generally more sceptical of such short AI timelines. This is made clear by the results of the Forecasting Research Institute’s Existential Risk Persuasion Tournament (XPT), which asked 89 superforecasters and 80 specialists on long term x-risks to predict the likelihood of global risks. One question asked respondents to assign probabilities to the statement ‘Nick Bostrom believes that AGI exists’[8] obtaining by 2030, 2050, and 2100. In the final stage of the tournament, the median superforecaster predictions indicated that the chance of this occurring was:
1% by 2030
21% by 2050
75% by 2100
These predictions skew later than most others in this section: for example, any 50th percentile prediction for the arrival of AGI consistent with these data points would fall somewhere between 2050 and 2100, certainly later than AI Impacts’ latest aggregate result of 2047 and well beyond Metaculus’ community prediction of 2030.
For a more direct comparison, note that the median probabilities of AGI having arrived elicited from the superforecasters for each specified year were notably lower than those given by groups of both domain experts and general x-risk experts participating in the tournament. Specifically, the results on this question were:
Figure 1. Comparison of median predictions for the arrival of AGI, by group – XPT final round
Group
Probability by 2030
Probability by 2050
Probability by 2100
Superforecasters
1%
21%
75%
Domain experts
9%
46%
87%
General x-risk experts
10%
48%
90%
Comparing the two expert groups here, the domain experts and general x-risk experts indicated, on the whole, very similar probability distributions for the timeline to (Nick Bostrom confirming) AGI. Perhaps unsurprisingly, their median responses on this question also closely track the 2023 AI Impacts’ expert survey predictions for the timeline to HLMI. But, for all three years, superforecasters assigned much lower probabilities on average to the statement resolving positive.[9]
Who should we trust in this dispute? Although the superforecasters have an excellent track record of accurate predictions across questions which resolve in the short term (see e.g. the successes highlighted by the Good Judgment Institute), the Forecasting Research Institute comments that they “do not have a track record in forecasting questions over long time horizons” (p3). Moreover, general forecasting proficiency may not translate into accurate predictions on specific, AI-related questions; domain expertise may be especially necessary (though not sufficient) for predictive accuracy in this context, as has been suggested by Mühlbacher and Scoblic in their analysis of Metaculus’ AI forecasting.
Perhaps we should not overplay the importance of establishing who to trust here. It is true that the superforecasters’ predictions constitute one of the most significant outliers in this section[10], illustrating the breadth of opinions. However, this result doesn’t underpin a radically different view to the others specified. If we take the superforecasters’ predictions seriously, their forecasts still point towards a transformative form of AI emerging within this century, and within the lifetimes of many of us who are alive today.
Specific views
With this broad terrain now charted, let us zoom into some specific examples of AI timeline predictions from influential figures and organisations. These fall into two categories:
Model-based predictions, which are the output of an explicit quantitative model; and
Judgement-based predictions, which are not the direct outputs of any explicit model, but are instead generally rough estimates from an individual (of course, these opinions may be partly informed by existing models – alongside other sources – but are not a direct output of them).
I will begin by mapping out a range of judgement-based predictions.
Judgement-based predictions
This territory can be divided roughly into two sub-categories.
Firstly, there are predictions from individuals who appear to take the prospect of ‘short timelines’ to TAI seriously. The question of what we would describe as a ‘short timeline’ in this context is a significant one, and we intend to define this notion more precisely in a subsequent post. For now, as a very rough first pass[11]: I will loosely consider timelines of up to around 15 years from now as ‘short’ and say that someone ‘takes short timelines seriously’ if they explicitly or implicitly assign non-negligible probabilities (above, say, 5 or 10%) to the arrival of TAI within that time frame.
Secondly, there are several prominent objectors to the idea that short timelines may be realised. These sceptics resist and have levelled arguments against predictions which place significant weight on shorter timelines, but have often declined to offer their own counter-predictions.
As shorthand, I’ll call these two groups ‘short timeline anticipators’ and ‘short timeline sceptics’.
Short timeline anticipators
AI safety and x-risk experts. There are many highly visible members of the AI safety and x-risk mitigation community whose predictions of AI timelines agree on the following points:
It is more likely than not (i.e. over 50% chance) that some transformative form of AI will be achieved within the next four decades.
There is a reasonable chance (usually between 10%-50%) of its arrival within the next 15 years.
Some notable examples of predictions in accordance with these claims include:
Holden Karnofsky (2021): Karnofsky has estimated the chance of the arrival of TAI as: over 10% by 2036, 50% by 2060, and ⅔ by 2100. He has not provided a more recent update to his personal timeline predictions since 2021.
Ajeya Cotra (2022). Cotra has estimated the chance of the arrival of TAI as: 15% by 2030, 35% by 2036, 50% by 2040, and 60% by 2050. Note that these estimates mark a significant shortening in expectation of her personal timelines from two years ago (which were closely in line with the outputs of her quantitative ‘biological anchors’ model, discussed later).
Of course, not all thought leaders in this space have committed to making explicit predictions about the arrival of TAI. But amongst those who have avoided directly stating any such probabilities, the idea of short timelines to TAI has still sometimes been taken very seriously:
Eliezer Yudkowsky is a key example of this; he has generally advised caution in specifying precise dates for the arrival of different forms of AI, and has objected to some attempts to do so (including Cotra’s ‘biological anchors’ model, which we discuss later). Nonetheless, he did note in 2023 that the timeline for AGI “could be three years. It could be 15 years. We could get that AI winter I was hoping for, and it could be 16 years. I’m not really seeing 50 without some kind of giant civilizational catastrophe.”
Rob Bensinger had some words to a similar effect in 2023, arguing that we’ll reach ‘STEM-level’ AGI in “probably not 50 or 150 years; [it] could well be 5 years or 15”.
Classical AI experts. Like Cotra above, a few classically renowned AI experts who are well-respected outside of the x-risk community have also made recent public revisions to their AI predictions, in favour of shorter timelines. For example, as of 2023:
Yoshua Bengioexpects that human-level AI will arrive in 5-20 years, with 90% confidence, after previously estimating that it would take “decades to centuries” to reach this point.
Geoff Hintonstated that general purpose AI “may be 20 years away or less”, having previously believed it was 20-50 years away.
Note that favouring timelines of this kind isn’t just a recent movement. Some AI experts have anticipated that TAI will arrive in the early 21st Century for decades. Notably, Ray Kurzweil confirmed in March 2024 that he still expects human-level AI to arrive in 2029, having first advanced this prediction as early as 1999.
AI labs and technology companies. Some influential figures in AI technology and development have made very short AI timeline predictions (by this, I roughly mean that they suggest we are five years or less away from the arrival of a transformative form of AI). For example, as of 2023:
Sam Altman (OpenAI) believes AGI could be reached in four or five years.
Dario Amodei (Anthropic) believes human-level AI could arrive in two or three years, but “wouldn't say it's 100%. It could be 50-50”.
Jensen Huang (NVIDIA) expects that AIs will be “fairly competitive” with humans within five years.
Of course, individuals in this category may have financial incentives to play into the current hype around AI development and therefore exaggerate the pace of progress. But equally, figures like Altman are at the forefront of efforts to build transformative technologies, having made explicit commitments to pursue AGI. The significance of these estimates is that they are not just predictions from a detached observer; in a sense, they might be seen as targets within the field.
Short timeline sceptics
This is not a complete picture of expert perspectives on the arrival of TAI. Across the fields above, there are prominent sceptics who have rejected predictions which point strongly towards shorter timelines, and contested the assumptions behind such predictions.
Notable examples include:
Robin Hanson, who believes that human level AI is at least a century away, if not multiple centuries.
Yann LeCun, who has been publicly critical of short timeline predictions such as the one endorsed by Jensen Huang – suggesting that AI labs and technology companies are motivated by self-interest to emphasise the possibility of short timelines – but doesn’t offer his own counter-prediction.
Melanie Mitchell, who has advanced a detailed critique of the position that timelines to advanced AI are short, identifying four fallacies such beliefs rest on, in ‘Why AI is harder than we think’; she also doesn’t offer her own counter-prediction.
In Section V, I outline some influential arguments against expecting short timelines, with particular focus on Melanie Mitchell’s paper.
Model-based predictions
The judgement-based predictions outlined above have been intended as fairly rough estimates. It is possible to take a more analytical approach to generating predictions; indeed, there have been several notable attempts to build quantitative models whose outputs are probability distributions for the arrival of TAI over time.
Two such attempts will be of particular interest within this article. These are:
Ajeya Cotra’s ‘biological anchors’ model (2020), which yields a 10% chance of TAI by 2031, a 50% chance by 2052, and a 78% chance by 2100.
Epoch’s ‘Direct Approach’ (2023), which yields a 10% chance of TAI being developed by 2025, and a 50% chance of it being developed by 2033.
In Section III, I turn to examine these models in detail, outlining their assumptions, explicating their methods, and noting some possible objections to the approaches taken.
For now, let’s briefly summarise the landscape of views we have covered in this section.
Rounding up
In the table below (Figure 2), I provide a summary of the key results surveyed in this section.
Important notes on the table
This is not intended as a direct comparison between predictions. Indeed, there are several key areas of disanalogy amongst the sources covered:
(i) Different characterisations of advanced AI have been used across the sources.
As stated previously, we consider most of these characterisations as constituting or closely corresponding to TAI, due to their clear transformative potential. However, the specific definitions used do matter, and should be taken into consideration when viewing the table. For example, those whose chosen benchmark for AI development is the ability to perform every human task should be expected to have longer timelines here than those concerned with AIs performing 90% of those tasks.
Where a source has specified a definition for an otherwise ambiguous term (such as ‘high-level machine intelligence’), this has been included in the table. The exception to this is where sources have directly appealed to the notion of TAI, employing the definition of this term I set out in the Introduction, which I do not restate.
(ii) There is sometimes ambiguity over the meaning of a predicted date in these sources.
A forecaster might either mean to predict the date at which an advanced AI system is developed or the date at which such systems are implemented.[12]
Most sources described in this section appear to target the former date. For example, AI Impacts explicitly urges its survey respondents to “think feasibility, not adoption” when giving their predictions. However, survey respondents might still interpret instructions like these variably based on other aspects of framing. Moreover, in some individual predictions (especially personal views which have been expressed in imprecise terms) the relevant date is left largely open to interpretation.
In the table, I talk about the ‘arrival of’ advanced AI systems, taking this to refer to the initial arrival of the relevant capabilities within a lab setting. Though I believe that this accurately captures the intended meaning of most responses, this assumption does gloss over some potential variation here.
(iii) Each source elicits predictions across different years and percentiles.
As such, the range of views covered is resistant to any direct comparison without extrapolation work which is beyond scope of this article. See Epoch’s 2023 literature review of TAI timelines for an interesting example of this kind of extrapolation, enabling a more direct comparison between sources.
(iv) Not all forecasters have explicitly assigned probabilities to their predictions.
In particular, some individuals have expressed that they view timelines of a certain length to be plausible or implausible, without specifying such claims more precisely with probabilities. Although it is difficult to compare such vague predictions to the explicit forecasts offered by other sources, I have nonetheless included in this table the full range of views described in this section.
(v) Forecast aggregation methods are variable.
When a source has asked multiple respondents to each provide one date for the arrival of advanced AI, a median date is straightforwardly extracted from the list of elicited dates. However, when a source has asked its respondents to each make predictions over a series of fixed years (e.g. 2030, 2050, 2100) or fixed confidence percentiles (e.g. 10%, 50%, 90%), there are several different methods by which they could then ‘aggregate’ these results.
One option in this case is to simply take the median forecaster response for each fixed year or fixed percentile. But there are other, often more complex, aggregation methods which may be favoured. In the table, I use the term ‘aggregate prediction’ to cover a range of aggregation methods, without distinguishing between them. Some further information is provided in footnotes.
Figure 2. Summary of notable recent timeline predictions for the arrival of TAI or similar.
Source
Date of prediction or data collection
Characterisation of advanced AI
Prediction
Expert surveys
AI Impacts (Grace et al.)
2023
‘High-level machine intelligence’ (HLMI): Capable of accomplishing every task better and more cheaply than human workers
Aggregate community prediction: 50% probability of arrival by 2031
Feb 2023
Aggregate community prediction: 50% probability of arrival by 2041
Personal, judgement-based predictions
Holden Karnofsky
2021
TAI
10% probability of arrival by 2036
50% probability of arrival by 2060
⅔ probability of arrival by 2100
Ajeya Cotra
2022*
TAI
15% probability of arrival by 2030
35% probability of arrival by 2036
50% probability of arrival by 2040
60% probability of arrival by 2050
Eliezer Yudkowsky
2023
AGI
Suggests 3-16 years as plausible, 50 as implausible
Rob Bensinger
2023
‘STEM-level’ AGI
Suggests 5-15 years as plausible, 50-150 as implausible
Yoshua Bengio
2023
Human-level AI
90% confidence of arrival in 5-20 years
Pre-2023
Previously: expected arrival “decades to centuries” away
Geoff Hinton
2023
AGI
Suggests 20 years or less as plausible
Pre-2023
Previously: expected arrival 20-50 years away
Ray Kurzweil
2024 (and in many other statements over the past few decades)
Human-level AI
Expected arrival by 2029
Sam Altman
2023
AGI
Suggests 4-5 years as plausible
Dario Amodei
2023
Human-level AI
Around 50% confidence of arrival in 2-3 years
Jensen Huang
2023
‘Fairly competitive’ with humans
Expected arrival within five years
Robin Hanson
2019
Human-level AI
Over a century away
Yann LeCun
2023
General/human-level/superintelligent AI
Distant (unspecified)
Melanie Mitchell
2021
General/human-level/ superintelligent AI
Distant (unspecified)
Model-based predictions
Cotra’s biological anchors
2020
TAI
10% probability of arrival by 2031
50% probability of arrival by 2052
78% probability of arrival by 2100
Epoch’s Direct Approach
2023
TAI
10% probability of arrival by 2025
50% probability of arrival by 2033
*Cotra’s 2020 view reflects her biological anchors model, and is therefore covered under the model-based prediction in this table to avoid repetition.
Going forward
In Section IV onwards, I provide some high-level commentary about the spread of results in this table. For ease of comparison and analysis in these later sections, I will be focused especially on:
Median responses from sources which ask respondents to provide a single date for the arrival of advanced AI; and
50% probability assignments from both individual and aggregate forecasts which cover a series of fixed years or fixed percentiles.
For simplicity, I will label all such predictions as ‘median predictions’ going forward.
II. Why do people think AI will advance?
We have surveyed a range of predictions of the arrival of TAI. What we have not yet discussed is what is underlying these differing expectations.
Specifically: why might we think that we will achieve TAI (or similar) in the first place? And what would determine whether this feat will take a long or short time to achieve? This section will help to give a partial answer to these questions.
There are several possible routes to humanity developing TAI. The most commonly discussed is a pathway based on the ‘scaling hypothesis’, outlined below. Assumptions about scaling in relation to AI capabilities are one key determinant of AI timeline predictions, as will be illustrated further in Section III.
The scaling hypothesis
Many efforts to predict the arrival of TAI have assumed the ‘scaling hypothesis’. For the purposes of this article, I will define this as the assumption that, primarily through increasing computational power, neural networks will scale to arbitrarily powerful AI systems.[17]
Note that there are other ways of thinking about the scaling hypothesis. Its proponents agree that computational power, data, and algorithms all contribute to AI capability improvements, but sometimes disagree on the balance of contributions between these three key elements. Under the popular variant of the scaling hypothesis that I have chosen to employ, increased computational power is the most important – but not only – factor driving progress in AI capabilities.
Thus defined, the scaling hypothesis tells us that the current paradigm[18] can reach human-level AI, AGI, superintelligence, and other transformative forms of AI; crossing these thresholds will primarily be a matter of obtaining sufficient levels of computational power.
This roughly tracks what we have seen so far with existing neural networks and deep learning techniques – increased compute has closely corresponded with increased capabilities. We have seen, for example, how increasing computational power dramatically (while keeping system architecture largely the same) has underpinned a significant jump in capabilities from GPT-2 vs GPT-3, and again from GPT-3 to GPT-4. Many experts believe this trend is likely to continue.
But not everyone endorses the scaling hypothesis. Some reject the assumption that neural networks can scale in capability indefinitely with increased compute – typically arguing that this is technically infeasible or will become prohibitively expensive – and instead expect that a paradigm shift will be necessary to achieve TAI. Those who expect this often endorse longer timelines to TAI, owing to the additional time that may be required for researchers to discover and develop a paradigm of AI that will succeed.
Moreover, even amongst those who do believe that the scaling hypothesis holds, there is still significant variation in AI timeline predictions. As we will shortly see, specific timeline predictions resulting from an assumption of the scaling hypothesis are partly determined by the level of computational power that is believed to be required for TAI.
Alternative pathways to TAI
There are other potential pathways to TAI which do not rely on the scaling hypothesis. These are less commonly discussed in the literature, but have been compiled in a 2023 literature review from Matthijs Maas. We summarise these alternative pathways in a subsequent post on short timelines to TAI.
III. Two influential forecast models based on the scaling hypothesis
The scaling hypothesis is often used to make an in-principle argument towards shorter timelines, with a story that goes roughly like this:
Computational resources get cheaper and more easily accessible over time;
Developers rapidly plug more and more compute into neural network systems utilising current deep learning methods;
In accordance with the scaling hypothesis, additional compute translates into additional capability for current systems;
So, before long, we get ultra-capable AIs (TAI or similar).
Of course, this argument (in its present form) does not assign probabilities to any dates. But the scaling hypothesis can also be used to directly generate a forecast: we can build a quantitative model that predicts the arrival of AI with a certain level of capability or ‘intelligence’.
To translate the scaling hypothesis into a forecast for the arrival of TAI, we effectively need to estimate:
(E1) how much computational power would be sufficient for current methods to achieve TAI-level capabilities; and
(E2) how long it will take us to build systems with this amount of computational power.
Throughout this section, I will refer to these two targets of estimation as (E1) and (E2). When forecast models which rely on the scaling hypothesis vary in their predictions for the timeline to TAI, it is generally a result of differences in their approaches to estimating (E1) or (E2).
We can forecast (E2) using economic models which take into account investment into hardware alongside price performance. Though this itself is no easy task, I am particularly interested in different approaches to estimating (E1), for the purposes of this article.
Below, I explore two forecasting models, both based on the scaling hypothesis, which take very different approaches to estimating (E1). I outline their assumptions and methods, the timeline predictions they have yielded, and their possible shortcomings.
Approach 1: ‘Biological anchors’
Note: I owe parts of the exposition in this subsection to Scott Alexander’s ‘Biological Anchors: The Trick that Might or Might Not Work’. I recommend reading that post for a more detailed treatment of Ajeya Cotra’s work and Eliezer Yudkowsky’s objections.
The approach
One class of approaches to estimating (E1) takes inspiration from biology.
The basic idea is that achieving TAI or similar requires an AI system to be roughly as intelligent as the human brain. So, a good way to estimate the amount of computation required to achieve TAI-level capabilities would be to ask: how much computation would be needed to create a system which (in some sense) replicates the biological workings of the human brain?
If we can use evidence from biology to answer this question – and then estimate (E2) based on the resulting computational threshold – we can build a forecast for the arrival of TAI which is effectively ‘anchored’ in biological estimates.
A notable, recent approach in this direction comes from Ajeya Cotra’s 2020 draft report on biological anchors. Like us, Cotra is explicitly focused on TAI, understood as AI with transformative impact comparable to that of the Industrial Revolution. Her specific conceptualisation of such a transformative model is one which can “perform a large majority of economically valuable jobs more cheaply than human workers can.” (Part 1, p3)
She seeks to estimate (E1) using biological anchors. In her words:
“I see the human brain as an ‘existence proof’found in nature for this type of transformative model, so I use evidence from biology to help estimate the computation needed to train it.” (Part 1, p4)
How it works
Cotra asks: how much training computation is required to replicate the human brain?
She identifies six possible answers to this question, corresponding to different features (‘anchors’) of biological life that training computation might have to mimic in order to achieve the desired level of AI capability. Specifically, the biological anchors are:
Neural network anchors. Assume that the system would need to perform as much inferential computation as is performed by the human brain (estimated at 10^16 FLOP/s), and would also need to have as many parameters as we would expect from simply scaling up architectures of the largest neural networks to run onthis level of FLOP/s. The resulting estimate for training computation will be dependent on the 'horizon' length – the average length of time required to learn how much reward an action has received. Cotra considers three possibilities here:
Short horizon: a few minutes.
Medium horizon: a few hours.
Long horizon: a few years.
Genome anchor. Assumes that the system would need to run on as much inferential computation as performed by the human brain (estimated at 10^16 FLOP/s), and would also need to have roughly as many parameters as there are in the human genome (estimated at 7.5*10^8).
Human lifetime anchor. Assumes that training computation requirements will resemble the amount of computation performed by a child’s brain over the course of becoming an adult.
Evolution anchor. Assumes that training computation requirements will resemble the amount of computation performed over the course of human evolution.
Each of these anchors yields (after several further assumptions are made) a distinct threshold for training computation. Note that, either directly or indirectly, they all appeal to an assumption that the total inferential computation performed by the human brain is 10^16 FLOP/s.[19]
Rather than selecting one threshold to proceed with, she assigns a probability to each, based on how plausible she thinks the chosen anchor is. The resulting thresholds for training computation and the probabilities corresponding to each estimate are summarised in the table below.
Figure 3. Training computation estimates and probabilistic weightings by anchor type.
Anchor type
Estimated training computation required
How probable is this estimate?
Neural network
Short horizon: 10^30 FLOP
20%
Medium horizon: 10^33 FLOP
30%
Long horizon: 10^36 FLOP
15%
Genome
10^33 FLOP
10%
Human lifetime
10^24 FLOP
5%
Evolution
10^41 FLOP
10%
This gives us a probability distribution of different biology-inspired computational thresholds for TAI. There are several additional steps before this can be used to generate a forecast, each introducing new complexities and uncertainties.
Firstly, the computational thresholds identified above do not yet account for algorithmic progress over time (i.e. improvements to efficiency such that better performance can be achieved with less training computation). To this end, Cotra makes some assumptions which draw upon results from Hernandez and Brown to project algorithmic progress over time. For each of the six weighted anchors, training computation thresholds for TAI over time can then be modelled.
She is then left to answer (E2): when will AIs be developed with enough training computation resources to meet the requirements for TAI? Answering this requires considerable additional effort. As a brief (and very rough) overview, Cotra proceeds to do the following:
Quantitatively model how much training computation (in FLOP) AI developers will have access to over time by projecting trends into the future for compute-investment ($) and hardware cost-effectiveness (FLOP/$);
Compare the amount of training computation developers will have access to in the future against the six biology-inspired models for FLOP requirements over time, to identify when FLOP levels will hit one of the estimated thresholds for TAI-level capabilities;
Assign probabilities for TAI being achieved in each year, according to the weightings of the biological anchor estimates.
The result
This forecast model arrives at the following predictions:
10% chance of TAI arriving by 2031
50% chance of TAI arriving by 2052
78% chance of TAI arriving by 2100
Scott Alexander has observed that weighting the six anchors differently or tweaking some of the assumptions underlying Cotra’s model does not usually lead to huge variation in these results. For example, suppose we significantly reduce our projections for investment and algorithmic progress in the coming years, and choose to weight one of the six anchors to 100%. For four of the six anchors, the model still yields a median prediction of TAI arriving between 2030-2070. The two anchors for which this does not apply (the evolution anchor and the neural network anchor with a long horizon) are not favoured by Cotra, and she doesn’t weight them heavily in her own model.
Objections
One obvious objection to models that are based on biological evidence is that our current understanding of how intelligence arises in biological life is actually very limited. We don’t know, for example, how much inferential computation is performed by the human brain, or the total amount of training computation that has been performed over the course of evolution, or the extent to which either of those things has actually contributed to human intelligence. Indeed, Cotra has had to lean on a stack of assumptions and inexact estimations to arrive at each of her six biologically-inspired computational thresholds. As such, computational requirements arrived at from biological anchors are hard to trust.
Perhaps this objection means that we can’t put too much stock in the details of the forecast. But we might still think that the essence of the approach is promising, and the model could be refined as our understanding of biology is improved – right?
Maybe not. There has been resistance to more fundamental aspects of the approach which could not be addressed by simply updating the model in light of new evidence. In particular, we might question in the first place why we should think that advanced AI systems will resemble biological intelligence in any meaningful sense.
An influential version of this objection has been levelled by Eliezer Yudkowsky in ‘Biological Anchors: The Trick That Never Works’. He points out that, just as AIs consume energy in a very different way to humans, we can expect them to also ‘consume’ computational resources in a very different way to us, resisting comparison. Therefore, any projected compute requirements for machine intelligence which are based on analogies to biological intelligence are on flimsy grounds.
Scott Alexander supplies additional examples to bolster our intuitions here:
“Cars don’t move by contracting their leg muscles and planes don’t fly by flapping their wings like birds. Telescopes do form images the same way as the lenses in our eyes, but differ by so many orders of magnitude in every important way that they defy comparison. Why should AI be different?”
To reinforce these points, we can note that already, the way that current AIs and human brains work is clearly disanalogous in many ways. We can consider, for example, the major differences between us in terms of clock speed and parallel computing.
In fact, we can go much further than this: we can point to disanalogies between humans and machines which are specific to the chosen biological anchors. For example, the total amount of ‘training’ performed in evolution did far more than just produce human intelligence – it also created numerous other species, whose emergence was surely not essential to the formation of human intelligence. It therefore does not seem to be strongly comparable to the computation required in training an advanced AI, a more targeted process which presumably won’t require doing all this other stuff along the way to intelligence.
Perhaps it is possible to refine Cotra’s model to account for the differences between human intelligence and machine intelligence that we are already aware of. But looking to the future, how much will this help us? As the trajectory of AI development continues, we might see even more divergence from familiar biological features and patterns. What we are developing here – and the path to developing it – might look fundamentally different to what we’ve seen before, in ways that are difficult to imagine right now.
It might be argued that Cotra’s efforts to account for ‘algorithmic progress’ help to address the above concerns. The idea here is that any disanologies between AI and biological intelligence might possibly be represented, within her model, as differences in computational efficiency. By adjusting TAI compute requirements over time based on projected algorithmic improvements, she effectively acknowledges that AIs are going to start consuming compute in more efficient ways than we have previously seen. Her model could be adjusted such that the pace of algorithmic progress is more dramatic than originally assumed; this would reflect a scenario in which AIs rapidly outstrip human levels of efficiency.
In Yudkowsky’s critique of Cotra’s model, he envisions a hypothetical OpenPhil opponent levelling a counterargument along these lines against him. Yudkowsky makes clear that he is unmoved by this response. The imaginary debate with OpenPhil here seemingly hinges upon the sense in which we can expect TAI development to be disanalogous to both human biology and to historical patterns of AI development. If it’s a straightforward case of AIs consuming compute in the same way, but much more efficiently – a quantitative change, but not a qualitative one – we may be able to capture this in our models by simply adjusting our projections of algorithmic progress. But Yudkowsky warns of a situation where AIs do not simply become algorithmically faster, but behave altogether algorithmically differently, consuming compute in aqualitatively different way to what we have expected.
It is not immediately clear what this would look like. I think Yudkowksy may be considering a discontinuous[20] path of AI development. That is: Cotra’s projection of algorithmic progress assumes continuous improvements in efficiency (or rather, it assumes that any discontinuous jumps are minor enough to be reasonably approximated by a smooth curve). If our criticism of Cotra’s model is that we should expect the same continuous pattern of improvement but much faster, it can be addressed by plugging in a higher rate of algorithmic progress.
Figure 4. Continuous vs discontinuous trajectories of algorithmic improvement
But Yudkowsky’s resistance seems to be more fundamental, questioning whether progress will even follow the same pattern in future: specifically, we don’t know whether computational efficiency improvements will take an (approximately) continuous path. At some unknown point, there might be a paradigm shift precipitating a drastic, sudden spike in efficiency that we cannot usefully approximate with a smooth algorithmic progress curve. This would mean we couldn’t accurately model the future of AI development merely by adjusting the rate of algorithmic improvement.
Thus interpreted, Yudkowsky’s objection raises questions for efforts to quantitatively model AI development in general. Sudden qualitative differences in algorithms would likely drive the trajectory of AI development even further apart from any human analogues, casting more doubt on the legitimacy of grounding AI forecasts in biological estimates. But the objection seems to extend beyond the issue of differences between AIs and humans, and may be seen as a limitation of any model for AI development: we don’t know whether progress will be smooth, and if there are discontinuous jumps, we don’t know when to expect them.
Putting broader issues like this aside, where do our reflections on Cotra’s model leave us? Overall, the objections above suggest that analogies between machine intelligence and biological intelligence might not be the best basis for forecasting the arrival of TAI. However, there are other bases we could build on. We now turn to consider an alternative model which retains the scaling hypothesis as its foundation, but moves away from potentially flawed analogies to biology.
My colleague Elliot Mckernon and I will be shortly publishing a post which breaks down Epoch’s Direct Approach in more detail.
The approach
There are other approaches to forecasting the arrival of TAI which are still based on the scaling hypothesis, but reject the idea that achieving some inner, biological sense of human-brain-like-ness is what counts for AI to develop transformative capabilities. Instead, to estimate (E1), we can look directly towards the outer behaviour of systems. Specifically, we can use empirical scaling laws (capturing an observed relationship between training computation and system performance) to directly estimate the amount of training computation at which a system could produce outputs of a certain level.
This conceptual shift towards outer performance metrics is fundamental to Epoch’s ‘Direct Approach’ model. Like Cotra, Epoch is explicitly concerned with forecasting the arrival of transformative AI.
Epoch’s basic idea is that, if a machine can perfectly emulate human performance on some task, it could substitute a human on that task with no loss of performance. So, if an AI system was able to perfectly emulate all scientific tasks, it could (if widely adopted) completely replace human scientific researchers, bringing about a revolution of scientific research. An AI system of this level of capability would therefore constitute TAI.[21]
Epoch has summarised this basic insight using the slogan “indistinguishability implies competence”.[22] Estimating (E1), then, lies in identifying the level of training computation at which AI performance will be indistinguishable from human performance on scientific tasks.
How it works
With this idea in mind, Epoch proceeds to estimate the amount of training computation required for ‘indistinguishability’ between AI and human performance on scientific tasks.
The key question here is: how do we decide when an AI’s performance at a task is ‘indistinguishable’ from a human’s performance at the same task?
To illustrate how Epoch approaches this, let’s begin with a simple example.
Suppose you are a judge playing a game to distinguish between the performance of two participants: a human and a machine. The machine is trying to convince you that it can make marbles as well as the human can. You are given a bag of marbles from each marble-producer, but not told which bag is which.
Suppose you happen to be holding the bag of marbles produced by the machine. How many marbles would you need to examine from this bag to determine, with at least 90% confidence, which bag you are holding? This quantity is labelled the ‘k-performance’ of the machine.
If the machine’s k-performance is above some locally-relevant threshold, then its performance at the task of making marbles is considered to be effectively indistinguishable from that of the human. The relevant threshold for k-performance is dependent on the task under evaluation; we won’t discuss here what that threshold might be in the specific case of marble production, since we are not especially interested in AI marble production capability.
To bring this to bear on the automation of scientific research, the authors of the Epoch report consider a variant of the above distinguishing-game applied to scientific task performance instead of marble production. In particular, they focus their attention on determining when LLM performance at writing scientific papers is indistinguishable from that of a human scientist.
To this end, we can consider the game described above, but with human and LLM participants both generating scientific text. The bag of marbles in the above story is replaced by a sequence of letter-tokens produced by each participant. (Or: we might imagine that each marble is now produced with a letter-token stamped on it, and the judge is examining the sequence of words spelled out by the marbles she has drawn.)
In this context, what locally-relevant threshold for k-performance would the LLM have to surpass for its scientific papers to be considered ‘indistinguishable’ from those produced by a human? The Epoch authors assume that performance over long strings of text is what’s important here. They therefore estimate a threshold for k-performance according to the length of an average scientific paper. Above this threshold, they argue that we can reasonably claim that scientific paper-writing can be ‘indistinguishably automated’ by the LLM.
How do we get from this ‘indistinguishability’ framework to an estimate for (E1)?
This is where scaling laws come in. Epoch appeals to an empirical scaling law from Hoffman et al. here to estimate a linear relationship between training computation and k-performance. (The idea: with more compute, we get LLMs with higher k-performance.)
Specifically, Hoffman et al.’s law relates the computational power used to train an LLM to the number of letter-tokens it takes for a (flawed) human judge to distinguish between the human and the LLM at the scientific text game. However, what we are interested in for our purposes is a machine’s k-performance with respect to an ideal judge. The Epoch authors must therefore adjust k-performance to account for the discrepancy between human abilities to discriminate between the outputs of the scientific text game vs that of an ideal observer. This is done using an estimated ‘human slowdown factor’. The worse a human judge is, the greater the ‘slowdown’ compared to an ideal judge, and the easier it is for the machine to get a high k-performance (i.e. to fool the judge over long sequences of text-generation). An LLM’s k-performance with respect to an ideal judge is thus lower than its k-performance with respect to a human judge.
The authors can then refer to the Hoffman et al. scaling law to convert these adjusted k-performance values into corresponding training computation requirements. In particular, they can determine a computational requirement corresponding to their estimated ‘indistinguishability’ threshold.
The resulting value is thought to bound the amount of training computation required to indistinguishably automate scientific tasks, without loss of performance.
A few notes on this:
This model is focused specifically on the task of writing scientific papers. It does not purport to estimate training computation requirements for the automation of all scientific tasks. This is because we lack suitable data on scaling properties for other relevant tasks in the scientific field. However, since the authors view writing scientific papers as one of the “hardest bottlenecks” for scientific automation, the resulting estimates are still suitable for the purposes of forecasting the arrival of AI which would precipitate a scientific revolution.
The threshold for training computation resulting from this approach is considered to be an upper bound for automating such tasks, as the authors acknowledge that there could be more efficient ways of performing scientific tasks than simply emulating what humans currently do.
Crucially, we don’t actually end up with a single upper bound, but a probability distribution of upper bounds. This reflects uncertainty over the two estimated parameter values – namely, the k-performance threshold for ‘indistinguishability’ and the human slowdown factor. The authors assign percentile confidence levels to both estimates, thus generating probabilistic results rather than a single value.
The result is a probability distribution which bounds training computation requirements for AIs capable of scientific automation (and therefore sufficient for TAI). It looks like this:
From this point onwards, Epoch’s approach is fairly similar to that taken in Ajeya Cotra’s biological anchors report. Specifically:
To generate a complete picture of (E1), we project (a probability distribution of) training compute requirements for TAI after adjustments for algorithmic progress over time.
To then answer (E2), we compare these projections to a model of how much computational power (in FLOP) developers will have access to over time, which is based on projections into the future of compute-investment ($) and hardware cost-efficiency (FLOP/$).
The result
This method arrives at a 10% chance of transformative AI being developed by 2025, and a 50% chance of it being developed by 2033.
Objections
Some possible objections to this approach concern the specific scaling law used. In particular, it is noted that Epoch has utilised a scaling law based on a report studying an LLM that was trained on general internet data. We might question whether this relationship will genuinely carry over to the context of writing scientific papers.
Epoch has a response to this: the authors note that “scaling laws have… been found to be ubiquitous across data distributions and modalities”, and argue that there is little reason to believe that learning scientific writing would be substantially harder than learning to produce non-scientific internet text. Nonetheless, they admit that this is a limitation of the current model, and accept that there would be value in updating the model in accordance with better, more clearly applicable scaling data once it becomes available.
More general objections can be levelled at the use of existing scaling laws in this context.
Firstly, we might ask: will the empirical relationship that has been found so far hold over many orders of magnitude of compute? The authors of the Epoch report do not seem to be worried about this particular question. They note that the Hoffman et al. scaling law may disagree on details with other scaling laws e.g. observed by Kaplan et al., but ultimately share the same assumption that performance scales predictably with compute. This predictable pattern of scaling (power law scaling) has already held over about 24 orders of magnitude, and the authors see no reason why it would not continue to do so.
But here’s a similar worry that seems somewhat harder to counter by simply reflecting on past trends. Will the empirical relationship that has been found to hold in the past continue to hold beyond certain levels of capability, to human-level intelligence and beyond?
It is possible that after a certain point of capability, the quantity or quality of available data will become a bottleneck. We might therefore expect scaling to slow down beyond that threshold. If so, the question is: by how much? Will it effectively plateau, necessitating a paradigm shift before TAI can be achieved? If we strongly endorse the scaling hypothesis (in its compute-centric form), our answer to this will probably be no – we’ll double down here, continuing to insist that computation is the primary driver of capabilities development. We could argue that increased computation would sufficiently empower AIs to get around the issue of data, perhaps through self-play or by generating synthetic datasets to support continued progress in capabilities. In that case, we might concede only that previously observed scaling laws will be replaced by a somewhat slower relationship, owing to the need to overcome new data-related challenges (which models such as the one from the Hoffman et al. report have not had to contend with); but ultimately, compute-based scaling will still take us to TAI with the current paradigm. This concession would likely only amount to small changes to Epoch’s forecast model.
Another worry in a similar vein to the above: will existing empirical scaling laws extrapolate well to the performance of much larger models (in terms of number of parameters)?
The answer to this appears to be that we shouldn’t have high confidence in this extrapolating well to such models. In fact, Epoch notes that current scaling laws have false implications for existing large language models – namely, that it would only take a few tokens for an ideal observer to reliably distinguish between current LLMs and humans. The Epoch authors themselves admit that this suggests “when we extrapolate performance to much larger models, the error in our estimate will tend to be quite high” and that there should be low confidence in any bottom line results here as a result of this. Nonetheless, they are hopeful that the work done in building this model can 1) still be valuable in informing predictions on the arrival of TAI and 2) be refined as better scaling data becomes available.
Other possible objections to the Epoch approach concern the uncertainty associated with estimating k-performance across scientific tasks. These objections are out of the scope of this article, but I would encourage referring to section 2.6 and 2.7 of the full Epoch report for further detail.
IV. Where does all of this point?
We have charted out a complicated picture of AI timeline predictions. The terrain of views on this subject is variable, rough, and uncertain. Attempts to forecast the arrival of TAI have not only been limited by a lack of existing information (i.e. a lack of relevant scaling data as well as an incomplete understanding of biological phenomena), they have also encountered difficulties at a conceptual level.
Still, there are some apparent areas of convergence amongst the views thus mapped out. In particular:
Ballpark similarity of predictions
With only a small number of exceptions, recent median predictions[23] for the arrival of TAI or similar have typically fallen within a few decades of each other. For example, Cotra’s biological anchors approach and Epoch’s ‘Direct Approach’ result in median predictions which are around 20 years apart. As we have seen, even making substantial adjustments to the assumptions underlying Cotra’s model does not induce much variation with respect to median predictions.
In some senses, a few decades is a significant gap. A world in which we have 30 or 40 years to prepare for the arrival of TAI is very different, from a strategic perspective, to one where we have only 10. However, given the possible space of AI timelines – which could be hundreds of years, according to some experts (e.g. Robin Hanson) – this still feels like a notable result.
Moreover, it is (at least on the surface of things) surprising to see that, even when making assumptions that appear to be fundamentally different – for example, over how best to establish training compute requirements for TAI – resulting forecasts are not vastly or irreconcilably different. The large majority of predictions I have covered in this article still point to TAI arriving between 10 to 40 years from today.[24]
Trend towards shorter timeline predictions
The surveys, competitions, forecasts, and individual predictions we have covered in this article have largely been taken from the last five years. Over this period, we have seen a pattern emerge of more recent AI predictions trending towards the lower end of timeline distributions. In recent years, and across most relevant groups, people generally appear to have been updating their beliefs in the direction of shorter timelines. Good examples of this include the AI Impacts survey results, the Metaculus community AGI prediction trendline, as well as notable personal updates from Ajeya Cotra, Yoshua Bengio, and Geoff Hinton.
This apparent pattern has become especially visible since 2022 – which is unsurprising, as many who have publicly updated their views have appealed to very recent aspects of AI development, such as the arrival of ChatGPT, and the strengthening body of evidence behind the scaling hypothesis provided by the latest GPT progress.
Some very important caveats
We should not get carried away with these conclusions. A few things seem very unclear here:
How should we view the recent, sharp dip in median timeline estimates in comparison to the longer-term historical picture of AI predictions? Are timelines legitimately getting shorter, or is what we are seeing just noise in a very lumpy curve?
Will the apparent trend towards shorter timelines persist, or will such views soon fall out of favour?
In any case, are forecasts actually good evidence for our beliefs about AI timelines?
Should a rough consensus on timelines reinforce those beliefs, or point to general flaws in forecasting practices?
Questions of this kind bring us neatly onto our next section.
V. How seriously should we take these results?
There are several reasons we might be sceptical of conclusions drawn from the predictions and forecast models detailed in this article. Some of these point to general issues with forecasting in the context of AI x-risk; others concern the attempt to extrapolate trends from what is ultimately a very lumpy terrain; others still are specific reasons to resist the idea that TAI will likely be achieved within the next few decades.
I outline some possible reasons for scepticism below.
A note on the significance of the below arguments. I don’t take any of the arguments below to defeat, or even very seriously undermine, the observations I made in Section IV. However, it’s important to ensure that we have considered different angles for interpreting this body of timeline predictions before drawing conclusions. The confidence levels we have in our conclusions, and the extent to which those conclusions are relied upon in making strategic decisions, should be adjusted accordingly.
General limitations of forecasting AI timelines
This subsection highlights limitations of forecasting with respect to AI timeline predictions. Note that Corin Katzke’s post on 'Scenario planning for AI x-risk' touched upon some of these ideas when discussing the limitations of forecasting in the wider space of AI x-risk questions.
Platt’s Law
Throughout this article, we have noted some similarities amongst the AI timeline predictions we have seen from different sources. On the surface, the (loose) consensus over TAI being achieved (with at least 50% confidence) in the next few decades might be believed to add credibility to the belief that TAI will, indeed, be achieved in the next few decades.
However, some objectors have taken this to point to a fundamental weakness of AI forecasting activities. Most notably, in his critique of Ajeya Cotra’s biological anchors model, Yudkowsky has appealed to what is sometimes dubbed ‘Platt’s Law’ – the observation that, over the last few decades, people have consistently been claiming that the arrival of advanced AI is roughly around 30 years away (and have consistently been in error).
Cotra’s biological anchors report follows this trend: it results in a median prediction of TAI in about 30 years from the date the work was conducted. Several of the other surveys and predictions outlined in this article have come to similar conclusions. Indeed, over a third of the specific[25] median predictions I have covered fall in the range of 20-40 years from the time of elicitation.
On its own, this result isn’t particularly surprising or worrying, as most of the predictions covered in this article were made within a few years of each other – but if we compare this against the decades-long historical pattern of incorrect predictions in this range, we might have some cause for scepticism. Perhaps this points to some common fallacy in reasoning that keeps making people interpret new evidence as gesturing towards TAI being around 20-40 years away, no matter where they are actually situated in the development curve.
Yudkwosky takes this as evidence that “timing this stuff is just plain hard”, and argues that we shouldn’t place too much faith in predictions of this kind, even if the arguments or models supporting such predictions appear to be sound. (We should note, for context, that Yudkowsky’s personal beliefs imply shorter timelines than those fitting the Platt’s Law trend.)
Information cascades
Another related worry also stems from the similarities in timeline predictions found across a variety of sources: could these similarities be (partly or entirely) due to the opinions of different groups of people influencing each other? For example, perhaps the Public First UK survey results were influenced by existing Metaculus community predictions, or the Sentience Institute US survey respondents were drawing from the predictions of individuals from prominent AI labs and technology companies.
There’s a concept in behavioural economics that captures this phenomenon, known as information cascade.
What should we take from this? Perhaps each new addition to the body of views which support P claim about TAI timelines should not be seen as a new or distinct piece of evidence that P is true, or used to update our beliefs more strongly in favour of P. Instead, maybe these additions should sometimes be seen as repetitions of other views in the space. That is, at least some predictions are made (either consciously or subconsciously) along the lines of: “Other people think P about the timeline to TAI, so I guess I roughly think that too”.
Of course, it’s extremely difficult to identify which results should be taken in this way, and which should be treated as independent, newevidence supporting a particular view.
Framing effects
As noted in Section I, survey responses about AI risk sometimes exhibit strong ‘framing effects’ i.e. their results are very sensitive to minor variations in the way a question is phrased. Recall, for example, the significant discrepancy (over 60 years) in responses to AI Impacts survey questions for ‘high-level machine intelligence’ vs ‘full automation of labour’, despite the similarity in their stipulated definitions. Results of this kind indicate low reliability of survey responses, giving us reason for pause when trying to draw conclusions from such sources.
Near-far distinctions
Robin Hanson, a prominent sceptic of short AI timelines who has questioned the credibility of many existing predictions, has written extensively on ‘construal-level theory’. This theory seeks to describe an apparent phenomenon of social psychology in which people reason about the near-term and far-term future very differently. Hanson argues that, when people make predictions of a certain level of AI capability emerging in several decades’ time, they’re typically in the ‘far mode’ of thinking:
“in the far mode where you’re thinking abstractly and broadly, we tend to be more confident in simple, abstract theories that have simple predictions and you tend to neglect messy details. When you’re in the near mode and focus on a particular thing, you see all the messy difficulties.”
As such, he argues that we should be sceptical about the quality of far mode predictions such as “TAI will arrive within 40 years”.
Difficulties with identifying trends
In the interests of epistemic honesty, I now ask: are people’s AI timelines really shortening in a significant way, overall?
When I began reading on this subject and saw several recent examples of individuals updating their beliefs in the direction of shorter timelines, paired with the shifting results from aggregate forecasts, I had hoped I could find a nice, clean way to point towards a wider trend here. But the reality of the situation has been disappointing on that front; what presents itself is a messy picture which is difficult to interpret.
At this point, what seems clear is that within the past few years, the tide has been moving in a particular direction. It is at least true that, across many groups, predictions of the timeline to TAI are generally shorter today than they were a couple of years ago. Moreover, I have not found any notable examples of experts substantially updating their beliefs about timelines in the other direction over this time period.
But if we zoom out, away from the past few years, it is not obvious that there is any longer term trend of shortening AI timelines. Results we have already seen such as the 2014 expert survey by Müller and Bostrom, with a median timeline prediction for HLMI that is sooner than many others seen in more recent years (for example, from the 2023 AI Impacts survey), suggest that the overall trendline is lumpy. And this lumpiness becomes more visible as we zoom out even further. Consider, for example, notable historic examples such as Ray Kurzweil’s 2005 prediction, set out in his book The Singularity, that AI would surpass human intelligence in 2029.[26]
With this wider context in mind, how should we interpret the shortening of timeline predictions for TAI over the last few years? Does it actually mark a significant underlying change in opinion across the surveyed groups, or is it just noise that barely affects the overall landscape of timeline predictions over the past few decades?
And, to the extent that there has been an overall shortening of timelines in the last few years, will the current wave of opinion around timelines persist? Or is what we are witnessing merely a blip in the graph that we tend to see periodically, perhaps following any major series of developments in the AI field (possibly in accordance with a pattern of ‘AI springs’ and ‘AI winters’, as identified in the following subsection)?
I don’t have good answers to these questions. Beginning to shed light on them would require a more extensive collection of sources than I have done in this article, extending further back into the past, with a closer analysis of the data points given.
However, this elusive overall picture does not provide the only valuable perspective on the data. Taking a closer look source by source, it’s clear that there have at least been meaningful individual shifts in opinion over the past few years, from several experts; generally, these personal updates have been conscious and well-motivated,[27] and perceived by the expert advancing them as a genuine adjustment to their beliefs. The fact that several specific experts have recently updated their opinions in this way is itself a noteworthy observation, even if wider trends are much harder to surmise.
Before moving on, let’s note that the apparent lumpiness in timeline predictions is not the only feature of the overall landscape that makes it difficult to confidently extract trends. As previously mentioned, other forms of variability in data – such as the numerous different characterisations of advanced AI, and the fact that elicitations are made over different years and different percentile intervals – also make the sources somewhat resistant to comparison. This adds some further complexity to any attempts to draw out generalisations. However, these variations are not likely to lead to orders of magnitude of differences in predictions.
Some specific counterarguments to short timelines
Aside from these general issues associated with how we should interpret evidence, it’s also worth noting that not everyone is sold on the idea that timelines to TAI are likely to fall within the next few decades (or sooner).
Cycles of spring and winter
The history of AI development has seen a repeated pattern of ‘AI springs’ and ‘AI winters’. Periods of fast progress and high expectations have eventually plateaued and been supplanted by a period of low confidence and disappointing results.
We are in an AI spring at the moment. The current zeitgeist has been accompanied by growing beliefs that we are fast approaching the threshold for TAI. In this article, we have seen that median timeline predictions within the next 10-40 years are currently prevalent, with an increasing number of people in recent years making predictions weighted towards the lower end of this spectrum, and many assigning significant probabilities to timelines even shorter than this.
Sceptics of such timelines to TAI sometimes argue that the historical cycle is likely to continue. Perhaps an AI winter may soon befall us, preventing us from reaching TAI within the next few decades. Robin Hanson has gestured towards this sort of outcome, noting that the current ‘boom’ of AI development does not seem to be in principle different from previous ones, which did not result in TAI.
Let’s pause to reflect on why our current predictions may be overconfident. In ‘Why AI is harder than we think’, Melanie Mitchell argues that there are four key fallacies that beliefs in short timelines rest on. I outline these alleged fallacies briefly below.
Four fallacies of short timeline predictions, according to Melanie Mitchell
The first step fallacy. When an AI achieves something impressive in a narrow domain, we often assume that this indicates an important step towards general intelligence. Mitchell believes this does not typically hold true. She appeals to a quote from Hubert Dreyfus’ brother here: this type of reasoning is “like claiming that the first monkey that climbed a tree was making progress towards landing on the moon” (p4).
Easy things are easy and hard things are hard. We have erroneously expected that the hardest tasks for machines to achieve will roughly track those which are hardest for humans. This style of thinking makes feats like AlphaGo’s ability at Go appear to be significant steps, indicative of the field being close to human-level intelligence. But there are tasks that are very easy for humans which will likely be quite difficult for machines (e.g. games like Charades). Such tasks will likely be the hardest bottlenecks for AI development, and take longer than we currently expect.
Wishful mnemonics. We’re already using terms associated with human intelligence, such as ‘learning’ and ‘understanding’ to describe machines. By doing this, Mitchell argues that we have created a misleading impression of how close machine capabilities are to genuinely emulating human intelligence.
Intelligence is all in the brain. The assumption that human-level intelligence can, in principle, be disembodied has been encoded into most recent predictions of AI timelines which lean towards shorter timelines (as these do not generally imagine the need for TAI systems to have bodies when reasoning about timelines to TAI). Mitchell questions whether this assumption is true. She notes that there is some weight behind the idea of embodied cognition – the idea that the body is central to consciousness or intelligence – which might limit the level (or kind) of intelligence a disembodied AI system could achieve. This is not just an objection to the claims that timelines to human-level intelligence will be short; it indicates that there may be a reason to think we won’t get to human-level intelligence at all.[28]
Mitchell’s arguments seem to present us with some intuitive reasons to be sceptical of prevailing beliefs about AI timelines, and suspect many of the sources covered in this article to be somewhat overconfident in their predictions.
Reframing ‘short timelines’, slightly
Earlier, I gave a rough first pass at characterising ‘short timelines’:
I will loosely consider timelines of up to around 15 years from now as ‘short’ and say that someone ‘takes short timelines seriously’ if they explicitly or implicitly assign non-negligible probabilities (above, say, 5 or 10%) to the arrival of TAI within that time frame.
Having surveyed the current landscape of predictions, I think that prominent sceptics who are resistant to the idea that AI timelines will be ‘short’ – people like Melanie Mitchell, Robin Hanson, and Yann LeCun – aren’t specifically directing their objections at people who assign non-negligible probabilities to timelines of roughly under 15 years, or thereabouts. Instead, it seems that they probably mean to resist the current wave of popular opinion more broadly.
This ‘current wave’ may best be reflected by the large swathe of sources I have covered whose median predictions fall within the next four decades. Of course, the sceptics in this debate are especially critical of forecasts which assign significant weights to the lower end of that spectrum. In this sense, my initial stab at a range of ‘15 years and below’ is still roughly relevant. But I think it’s important to note that the people who would be most sensibly characterised as ‘short timeline sceptics’ in this debate would also resist timelines in the 25-35 year range, for example, on the basis of Platt’s Law.
When wrapping up below, I use the term ‘short timelines’ in a broad sense. Very loosely, I’m talking about any TAI timeline predictions falling on (or assigning significant probabilities to) the lower end of the 40 year spectrum of popular opinion. In a follow-up post, Convergence will dedicate more work to characterising ‘short timelines’ in a sense that is strategically relevant.
VI. Conclusion
Where does this all leave us?
I have mapped out a range of predictions on AI timelines from experts, forecasters, and the public – and I have elucidated some of the assumptions which often underpin such predictions through our examination of two specific forecast models. From this, I have observed some broad agreement over the prospect of TAI arriving within the next 10-40 years, as well as a (very) recent trend towards shortening AI timeline predictions.
Ultimately, it seems that the AI safety community should not put that much stock in any one particular date or probability distribution for the arrival of TAI, due to the fundamental limitations of forecasting such questions (as detailed in the previous section). Indeed, this is one of Convergence’s motivations for proposing scenario planning as an area of important research for AI x-risk.
It is wise to acknowledge these limitations, and thereby treat the results of each of the sources we have surveyed with some caution, avoiding making any important strategic decisions solely on the basis of an individual result. But it is at least clear that there is serious support behind the idea that timelines to TAI could be short. Over the past few years, it also appears that this support has been growing – though, as I have noted in Section V, it would require some evaluation of the historical data to establish how, exactly, this recent shortening of timeline predictions should be interpreted in the wider context.
There’s some conceptual weight to the arguments behind short timelines, too. In particular, if the scaling hypothesis holds, TAI could emerge fairly quickly through increased computational power. However, this article has not directly explored arguments for and against the scaling hypothesis – or other possibly short routes to TAI – in any real depth. I have also noted (but not evaluated) several potential fallacies of reasoning which, according to Melanie Mitchell and other sceptics, may underlie some stipulations of short AI timelines. This possibly casts some doubt over the credibility of these beliefs.
Having paid appropriate dues to a host of concerns and caveats, I still believe that we are left with enough support behind the plausibility of short timelines – based on both the current climate of opinion and the conceptual weight behind the idea – to warrant further investigation and strategic preparation in this direction. The fact that many experts across different fields have come to the conclusion that short timelines are plausible (or, according to some, to be expected) is reason enough, in my opinion, to take this prospect very seriously.
But suppose, after all of these reflections, we’re still highly sceptical of short timelines to TAI, or largely uncertain what to think about their plausibility. In that case, it makes sense from a strategic perspective to err slightly on the side of caution. That is: under uncertainty, we should take into account the possibility of scenarios with short timelines in our planning, and err on the side of affording higher importance to such scenarios when evaluating strategies. This is because, if timelines to TAI are short, (and we take the prospect of AI x-risk seriously) policy makers and the AI safety community will need to act quickly and decisively to address the associated risks, and substantial resources will need to be diverted towards doing so.
Despite the present uncertainty over the future and the variety of opinions we have seen, it is hard to deny that the needle of opinion is currently pointing in a particular direction – and it would be foolish not to take notice.
With this in mind, we intend to conduct a detailed exploration of short timelines to TAI. What, exactly, would a short timeline to TAI look like? What assumptions give rise to particularly short timelines? What would the route to TAI involve, and what would its consequences be? What are the relevant strategic considerations for such scenarios? How should we address them? These questions will be the subject of future posts, and will form a key subtopic of Convergence Analysis’ AI Clarity programme.
Acknowledgements
Thank you to Justin Bullock, Elliot Mckernon, David Kristoffersson, Corin Katzke, and Deric Cheng for feedback.
Appendix: Further reading
As noted in the Introduction, this article is not intended to be a comprehensive review by any stretch of the imagination.
Here’s a list of some other sources which I have not covered, but are likely of relevance to the work above. I welcome any further suggestions in the comments.
MIRI AI Predictions Dataset which collates AI predictions over a much wider historic time frame than I have sought to do.
Surveys on Fractional Progress Towards HLAI - AI Impacts: covers a variety of predictions built from fractional progress estimates. Note that the Robin Hanson survey mentioned here has been briefly discussed in my footnote 7.
Holden Karnofsky’s 2021 overview of the landscape of AI timelines arguments. Once again, I have covered some of the sources mentioned in this piece, but not all of them. Karnofsky also provides helpful commentary.
Could 1 PFLOP/s systems exceed the basic functional capacity of the human brain? Section 40 in Reframing Superintelligence - Eric Drexler. With additional steps, the work here could be used to generate another biologically inspired forecast model for the arrival of TAI.
We’ll typically do this, but not always. Sometimes, it will be instructive to talk about advanced AI directly in terms of capabilities (e.g. achieving high levels of generality, as captured under the notion of AGI). We are also interested in the development of AI beyond transformative levels.
Note that the 2023 survey covered far more respondents than the 2022 survey (2,778 vs 738), which in turn covered far more respondents than the 2016 survey (352).
Here, I have assumed that ‘tasks performed by human workers’, ‘tasks humans are paid to do’, and ‘economically relevant tasks’ all refer to the same subset of human tasks. If this is not the case, then it becomes difficult to directly compare the stringency of the three characterisations of advanced AI.
Note that this was reported as 2059 in 2022, but has since been adjusted by the AI Impacts report authors, based on “small code changes and improvements to data cleaning between surveys” (2023 AI Impacts survey, p4).
And the overall lumpiness of predictions in this space (probably) doesn’t end there. If we look back in the literature, we can find some results that are well out of the general ballpark of the predictions that have been described in this section. For example, extrapolation from Robin Hanson’s informal survey of around 15 experts, conducted 2012-2017 and concerning fractional progress in AI, results in a striking 372 year timeline to AGI. With a very small sample size, it is possible that a few extremely sceptical experts have skewed these results quite far in the direction of longer timelines. The extrapolation work based on fractional progress estimates also casts an additional layer of uncertainty over the results derived.
I don’t weight this source heavily in my personal analysis – at least not in comparison to the more extensive surveys discussed in this section – but I do think it’s worth being aware of. I think it points to a great lack of uniformity in predictions, highlighting a key challenge in drawing general conclusions from this variable landscape of views. We’ll touch on general limitations of surveys and forecasting attempts in Section V.
This is intended to roughly capture the actual arrival of AGI. The question is framed in this way to minimise ambiguity over whether the statement resolves positively or negatively, enabling superforecasters to be scored according to the accuracy of their predictions. Note that the question will not be objectively resolved until 2100. Tournament participants were therefore incentivised, in the meantime, with a reciprocal scoring metric (an intersubjective method requiring forecasters to additionally predict what other forecasters would answer).
Note that there were discrepancies between superforecaster predictions and expert predictions across the XPT, not solely on the question of timeline to AGI. This may have partly resulted from limitations of the particular methods used for eliciting and scoring forecasts; indeed, superforecaster participant Peter McClusky has pointed out several potential areas for improvement in the tournament. Perhaps with such improvements, we would expect more closely aligned predictions between different forecaster groups in the final round. However, in a follow-up study conducted by the Forecasting Research Institute, it appears that recent attempts to patch identified holes have still not resulted in greater agreement between superforecasters and experts on questions concerning x-risk within this century.
Beaten only by the AI Impacts aggregate forecasts of the arrival of FAOL, which (as noted earlier) may be disanalogous to other results in this section, and the extrapolated results from the Robin Hanson survey (which have been effectively discounted from my analysis, as in footnote 7).
Although I’ll revisit this first pass attempt and provide an updated version in a later section, I don’t intend, at any point in this article, to define this term exactly. A subsequent post in the series will deal with the concept of ‘short timelines’ more carefully.
In the context of TAI, this is the difference between the time until transformation could feasibly be achieved by an AI system and the time of actual societal transformation. (Though, given my selected definition of TAI, I view ‘the date of achieving TAI’ or ‘the date of arrival of TAI’ to mean the former, unless specified otherwise.)
The AI Impacts surveys aggregate individual responses by taking the mean distribution over all individual cumulative distribution functions. This has sometimes been described as the ‘mean parameters aggregation method’ (see e.g. Section 3.3 of the Zhang et al. report).
The Gruetzemacher et al. survey generated three different forecasts using different aggregation methods. The method reported in the table here takes the median forecaster response for each of the three percentile confidence points. A second method, taking the mean forecaster response for each fixed percentile, unsurprisingly yields much later dates (since there can only be outliers in the direction of longer timelines). The third method – the ‘median aggregate forecast’, which produces a smooth cumulative probability function rather than three discrete data points for 10%, 50%, and 90% confidence – produces only minorly different results to those stated in the table (under three years discrepancy on each).
The Zhang et al. survey results reported here are based on the ‘median parameters aggregation method’, which fits cumulative distribution functions (CDFs) to each individual forecaster’s responses and aggregates these functions into a joint CDF “by taking the median of the shape and scale parameters separately” (p4). For comparison. The authors also produce results using two other aggregation methods, but this ‘median parameters’ method is favoured.
The aggregation method selected here by Müller and Bostrom takes the median forecaster response for each of the three fixed confidence percentiles. The survey report also includes mean forecaster responses for comparison, which are unsurprisingly much later across the board. In the authors’ words, this is because “there cannot be outliers towards ‘earlier’ but there are outliers towards ‘later’” (p11).
That is, once a scalable architecture has been found. Note that many people who endorse the scaling hypothesis believe that the transformers/LLMs we currently have already constitute such a scalable architecture. Indeed, the forecast models discussed in the next section appear to assume this, as they do not build in additional time in their projections for finding a scalable architecture.
I use the term ‘current paradigm’ in quite a broad sense, referring roughly to neural networks plus deep learning.
As highlighted in the previous footnote, proponents of the scaling hypothesis may disagree over whether the specificarchitectures and deep learning methods we currently use can scale to TAI and beyond, or if changes to these aspects of AI systems will be required along the way; but generally, they expect neural networks (the ‘current paradigm’, broadly construed) to scale to ever more powerful systems, one way or another. As Gwern’s definition of the scaling hypothesis states: “we can simply train ever larger NNs and ever more sophisticated behavior will emerge naturally as the easiest way to optimize for all the tasks & data”.
Actually, her median estimate for the total inferential computation performed by the human brain is 10^15 FLOP/s, based on previous work by Joe Carlsmith. However, after considering how existing AI systems compare to animals with (apparently) similar inferential compute levels, she adjusts this estimate by one order of magnitude, resulting in 10^16 FLOP/s as her benchmark for AI achieving human-level inferential computation.
Note that I am not using the terms ‘continuous’ and ‘discontinuous’ in the mathematical sense, but according to their more common usage in the literature. Figure 4 is included to make the intended meanings of these terms clear in this context.
Recall here that we have defined TAI as being achieved when systems are capable of societal transformation, rather than when they have been adopted widely enough to actually bring about this transformation. To reach the second milestone, machines would likely be required to not just emulate human performance on tasks, but also do so more cheaply or efficiently than humans.
This idea is familiar from historic intelligence tests, such as the Turing Test. But Epoch’s approach is not necessarily reliant on a belief that indistinguishability equals intelligence in any inner sense (if there is, indeed, some inner sense of ‘being intelligent’). The approach is primarily concerned with capturing behaviour that would be indicative of, or sufficient to constitute, TAI-level capabilities.
Recall that, at the end of Section I, I noted that I would use the term ‘median predictions’ to refer to: (1) Median responses from sources which ask respondents to provide a single date for the arrival of advanced AI; and (2) 50% probability assignments from both individual and aggregate forecasts which cover a series of fixed years or fixed percentiles.
It may somewhat lessen our surprise to note that both forecast models from Cotra and Epoch have assumed the scaling hypothesis; this may be a partial explanation of their rough similarity. In this article, I have not made a concerted effort to find forecast models which do not make this assumption. However, without expecting a roughly predictable trend of performance improvements, it is difficult to construct such a quantitative model.
Moreover, the range of survey results, community forecasts, and judgement-based predictions I have covered in this article has likely factored in varied views from those who endorse the scaling hypothesis, those who deny it, and those who expect other routes to TAI. The fact that their median results still fall in the same range is, in my view, genuinely noteworthy. Having said this, I do go on to identify several reasons to treat the results with some caution in Section V.
Here, I’ve excluded predictions from individuals who have made vague claims along the lines of “TAI might be x-y years away” without some clarification of the probability range indicated by the term ‘might be’. In these cases, it is not possible to faithfully extrapolate a ‘median prediction’ from the view.
In fact, Kurzweil has continually upheld this prediction over the last two decades. See, for example, his comments on the subject during a recent interview with Joe Rogan.
Note that it doesn’t strictly follow from (a) ‘human-level intelligence cannot be disembodied’ that (b) ‘human-level artificial intelligence cannot be achieved’. We might endorse (a) but believe that human-level AI can still be achieved by giving AI systems something akin to a human body: ways to perceive the world and interact with it, such as mechanical limbs and sensors.


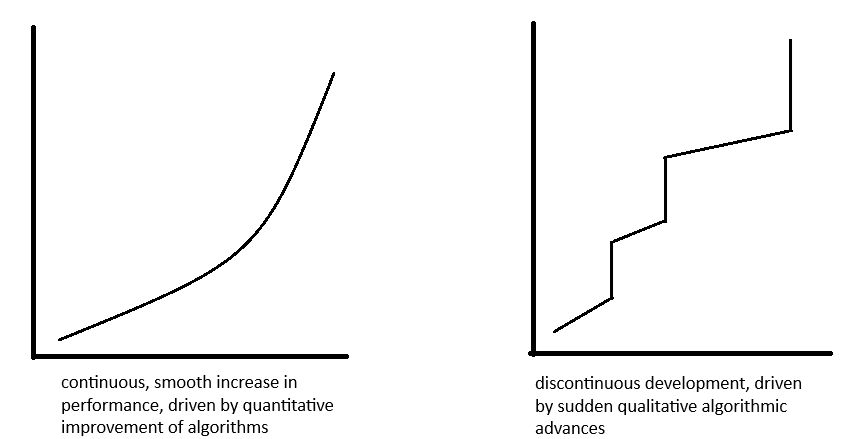
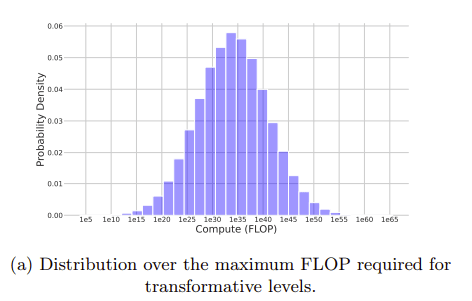
Note that this is true only of some subset of superforecasters. Samotsvety’s forecasters (many of whom are superforecasters) have shorter timelines than both domain experts and general x-risk experts:
Thank you for this helpful response, Pablo! This is a really interesting result to note. I was not aware of this when writing my post, but I'll plan to include Samotsvety forecast results in future work on this subject, and when I come to write up my findings more formally.