Summary
- William Eden forecasts an AI winter. He argues that AI systems (1) are too unreliable and too inscrutable, (2) won't get that much better (mostly due to hardware limitations) and/or (3) won't be that profitable. He says, "I'm seeing some things that make me think we are in a classic bubble scenario, and lots of trends that can't clearly continue."
- I put 5% on an AI winter happening by 2030, with all the robustness that having written a blog post inspires, and where AI winter is operationalised as a drawdown in annual global AI investment of ≥50%.[1] (I reckon a winter must feature not only decreased interest or excitement, but always also decreased funding, to be considered a winter proper.)
- There have been two previous winters, one 1974-1980 and one 1987-1993. The main factor causing these seems to have been failures to produce formidable results, and as a consequence wildly unmet expectations. Today's state-of-the-art AI systems show impressive results and are more widely adopted (though I'm not confident that the lofty expectations people have for AI today will be met).
- I think Moore's Law could keep going for decades.[2] But even if it doesn't, there are many other areas where improvements are being made allowing AI labs to train ever larger models: there's improved yields and other hardware cost reductions, improved interconnect speed and better utilisation, algorithmic progress and, perhaps most importantly, an increased willingness to spend. If 1e35 FLOP is enough to train a transformative AI (henceforth, TAI) system, which seems plausible, I think we could get TAI by 2040 (>50% confidence), even under fairly conservative assumptions. (And a prolonged absence of TAI wouldn't necessarily bring about an AI winter; investors probably aren't betting on TAI, but on more mundane products.)
- Reliability is definitely a problem for AI systems, but not as large a problem as it seems, because we pay far more attention to frontier capabilities of AI systems (which tend to be unreliable) than long-familiar capabilities (which are pretty reliable). If you fix your gaze on a specific task, you usually see a substantial and rapid improvement in reliability over the years.
- I reckon inference with GPT-3.5-like models will be about as cheap as search queries are today in about 3-6 years. I think ChatGPT and many other generative models will be profitable within 1-2 years if they aren't already. There's substantial demand for them (ChatGPT reached 100M monthly active users after two months, quite impressive next to Twitter's ~450M) and people are only beginning to explore their uses.
- If an AI winter does happen, I'd guess some of the more likely reasons would be (1) scaling hitting a wall, (2) deep-learning-based models being chronically unable to generalise out-of-distribution and/or (3) AI companies running out of good-enough data. I don't think this is very likely, but I would be relieved if it were the case, given that we as a species currently seem completely unprepared for TAI.
The Prospect of a New AI Winter
What does a speculative bubble look like from the inside? Trick question -- you don't see it.
Or, I suppose some people do see it. One or two may even be right, and some of the others are still worth listening to. William Eden tweeting out a long thread explaining why he's not worried about risks from advanced AI is one example, I don't know of which. He argues in support of his thesis that another AI winter is looming, making the following points:
- AI systems aren't that good. In particular (argues Eden), they are too unreliable and too inscrutable. It's far harder to achieve three or four nines reliability than merely one or two nines; as an example, autonomous vehicles have been arriving for over a decade. The kinds of things you can do with low reliability don't capture most of the value.
- AI systems won't get that much better. Some people think we can scale up current architectures to AGI. But, Eden says, we may not have enough compute to get there. Moore's law is "looking weaker and weaker", and price-performance is no longer falling exponentially. We'll most likely not get "more than another 2 orders of magnitude" of compute available globally, and 2 orders of magnitude probably won't get us to TAI.[3] "Without some major changes (new architecture/paradigm?) this looks played out." Besides, the semiconductor supply chain is centralised and fragile and could get disrupted, for example by a US-China war over Taiwan.
- AI products won't be that profitable. AI systems (says Eden) seem good for "automating low cost/risk/importance work", but that's not enough to meet expectations. (See point (1) on reliability and inscrutability.) Some applications, like web search, have such low margins that the inference costs of large ML models are prohibitive.
I've left out some detail and recommend reading the entire thread before proceeding. Also before proceeding, a disclosure: my day job is doing research on the governance of AI, and so if we're about to see another AI winter, I'd pretty much be out of a job, as there wouldn't be much to govern anymore. That said, I think an AI winter, while not the best that can happen, is vastly better than some of the alternatives, axiologically speaking.[4] I also think I'd be of the same opinion even if I had still worked as a programmer today (assuming I had known as much or little about AI as I actually do).
Past Winters
There is something of a precedent.
The first AI winter -- traditionally, from 1974 to 1980 -- was precipitated by the unsympathetic Lighthill report. More fundamentally it was caused by AI researchers' failure to achieve their grandiose objectives. In 1965, Herbert Simon famously predicted that AI systems would be capable of any work a human can do in 20 years, and Marvin Minsky wrote in 1967 that "within a generation [...] the problem of creating 'artificial intelligence' will be substantially solved". Of Frank Rosenblatt's Perceptron Project the New York Times reported (claims of Rosenblatt which aroused ire among other AI researchers due to their extravagance), "[It] revealed an embryo of an electronic computer that it expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence. Later perceptrons will be able to recognize people and call out their names and instantly translate speech in one language to speech and writing in another language, it was predicted" (Olazaran 1996). Far from human intelligence, not even adequate machine translation materialised (it took until the mid-2010s when DeepL and Google Translate's deep learning upgrade were released for that to happen).
The second AI winter -- traditionally, from 1987 to 1993 -- again followed unrealised expectations. This was the era of expert systems and connectionism (in AI, the application of artificial neural networks). But expert systems failed to scale, and neural networks learned slowly, had low accuracy and didn't generalise. It was not the era of 1e9 FLOP/s per dollar; I reckon the LISP machines of the day were ~6-7 orders of magnitude less price-performant than that.[5]
Wikipedia lists a number of factors behind these winters, but to me it is the failure to actually produce formidable results that seems most important. Even in an economic downturn, and even with academic funding dried up, you still would've seen substantial investments in AI had it shown good results. Expert systems did have some success, but nowhere near what we see AI systems do today, and with none of the momentum but all of the brittleness. This seems like an important crux to me: will AI systems fulfil the expectations investors have for them?
Moore's Law and the Future of Compute
Improving these days means scaling up. One reason why scaling might fail is if the hardware that is used to train AI models stops improving.
Moore's Law is the dictum that the number of transistors on a chip will double every ~2 years, and as a consequence hardware performance is able to double every ~2 years (Hobbhahn and Besiroglu 2022). (Coincidentally, Gordon Moore died last week at the age of 94, survived by his Law.) It's often claimed that Moore's Law will slow as the size of transistors (and this fact never ceases to amaze me) approaches the silicon atom limit. In Eden's words, Moore's Law looks played out.
I'm no expert at semiconductors or GPUs, but as I understand things it's (1) not a given that Moore's Law will fail in the next decade and (2) quite possible that, even if it does, hardware performance will keep running on improvements other than increased transistor density. It wouldn't be the first time something like this happened: single-thread performance went off-trend as Dennard scaling failed around 2005, but transistor counts kept rising thanks to increasing numbers of cores:
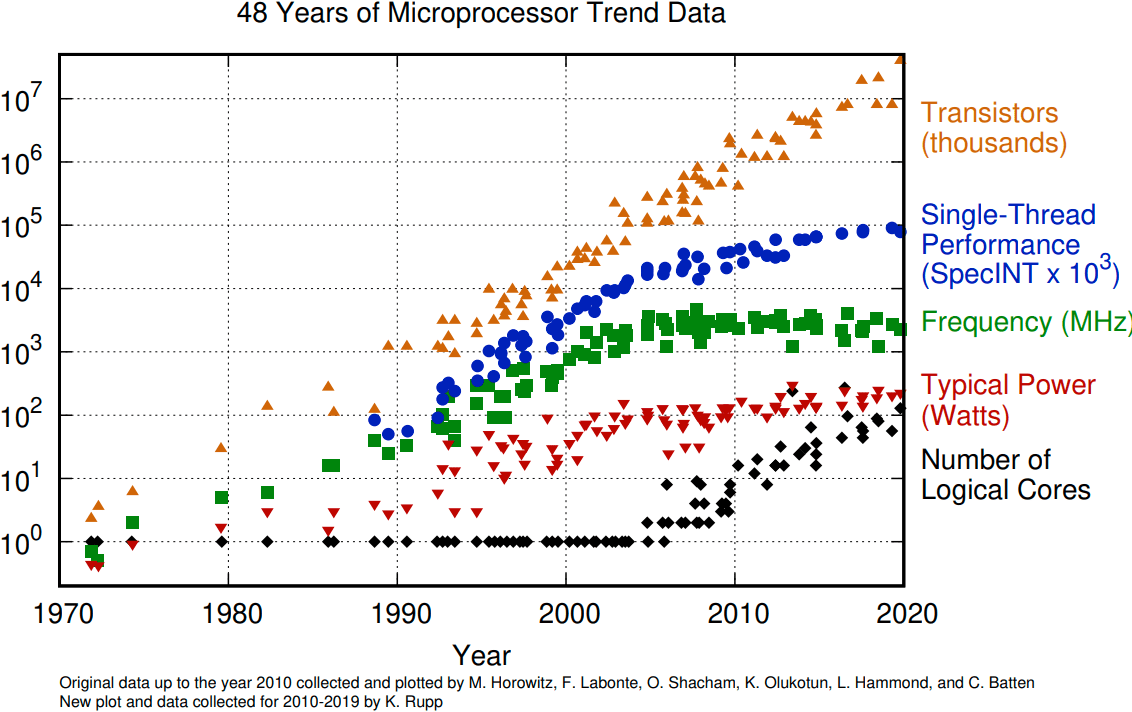
Some of the technologies that could keep GPU performance going as the atom limit approaches include vertical scaling, advanced packaging, new transistor designs and 2D materials as well as improved architectures and connectivity. (To be clear, I don't have a detailed picture of what these things are, I'm mostly just deferring to the linked source.) TSMC, Samsung and Intel all have plans for <2 nm process nodes (the current SOTA is 3 nm). Some companies are exploring more out-there solutions, like analog computing for speeding up low-precision matrix multiplication. Technologies on exponential trajectories are always out of far-frontier ideas, until they aren't (at least so long as there is immense pressure to innovate, as for semiconductors there is). Peter Lee said in 2016, "The number of people predicting the death of Moore's law doubles every two years." By the end of 2019, the Metaculus community gave "Moore's Law will end by 2025" 58%, whereas now one oughtn't give it more than a few measly per cent.[6]
But the main thing we care about here is not FLOP/s, and not even FLOP/s per dollar, but how much compute AI labs can afford to pour into a model. That's affected by a number of things beyond theoretical peak performance, including hardware costs, energy efficiency, line/die yields, utilisation and the amount of money that a lab is willing to spend. So will we get enough compute to train a TAI in the next few decades?
There are many sophisticated attempts to answer that question -- here's one that isn't, but that is hopefully easier to understand.
Daniel Kokotajlo imagines what you could do with 1e35 FLOP of compute on current GPU architectures. That's a lot of compute -- about 11 orders of magnitude more than what today's largest models were trained with (Sevilla et al. 2022). The post gives a dizzying picture of just how much you can do with such an abundance of computing power. Now it's true that we don't know for sure whether scaling will keep working, and it's also true that there can be other important bottlenecks besides compute, like data. But anyway something like 1e34 to 1e36 of 2022-compute seems like it could be enough to create TAI.
Entertain that notion and make the following assumptions:
- The price-performance of AI chips seems to double every 1.5 to 3.1 years (Hobbhahn and Besiroglu 2022); assume that that'll keep going until 2030, after which the doubling time will double as Moore's Law fails.
- Algorithmic progress on ImageNet seems to effectively halve compute requirements every 4 to 25 months (Erdil and Besiroglu 2022); assume that the doubling time is 50% longer for transformers.[7]
- Spending on training runs for ML systems seems to roughly double every 6 to 10 months; assume that that'll continue until we reach a maximum of $10B.[8]
What all that gives you is 50% probability of TAI by 2040, and 80% by 2045:
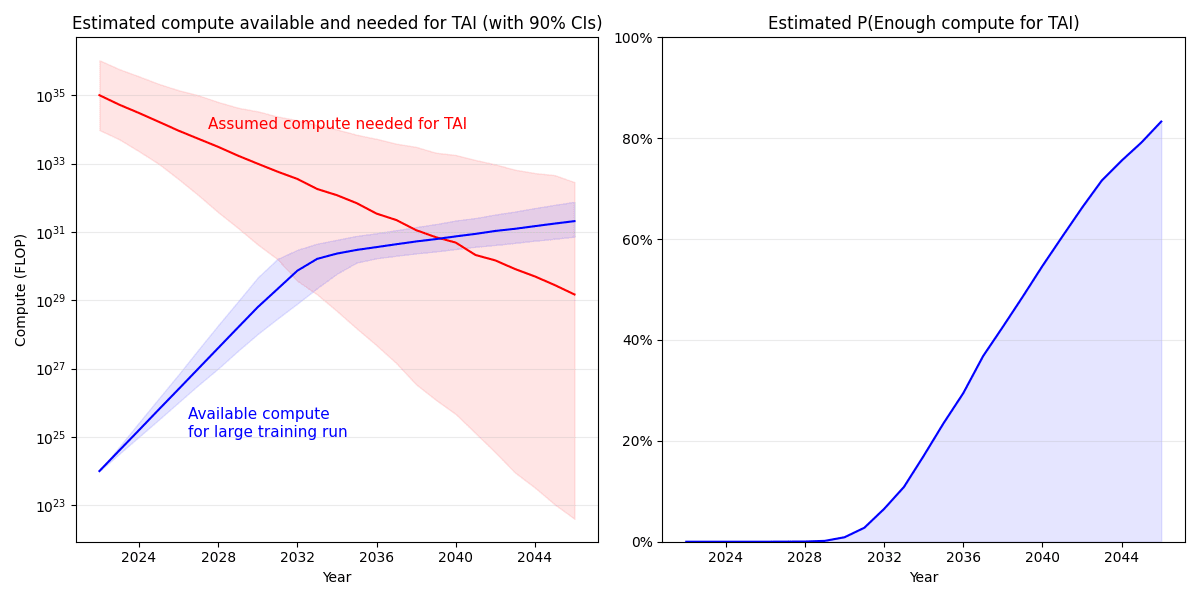
That is a simple model of course. There's a far more sophisticated and rigorous version, namely Cotra (2020) which gives a median of ~2050 (though she's since changed her best guess to a median of ~2040). There are many reasons why my simple model might be wrong:
- Scaling laws may fail and/or, as models get larger, scaling may get increasingly harder at a rate that exceeds ML researchers' efforts to make scaling less hard.
- Scaling laws may continue to hold but a model trained with 1e35 2022-FLOP does not prove transformative. Either more compute is needed, or new architectures are needed.
- 1e35 FLOP may be orders of magnitude more than what is needed to create TAI. For example, this Metaculus question has a community prediction of 1e28 to 1e33 FLOP for the largest training run prior to the first year in which GWP growth exceeds 30%; plugging that range into the model as a 90% CI gives a terrifying median estimate of 2029.
- Hardware price-performance progress slows more and/or earlier than assumed, or slows less and/or later than assumed.
- The pace of algorithmic advancements may slow down or increase, or the doubling time of algorithmic progress for prospective-transformative models may be lower or greater than estimated.
- ML researchers may run out of data, or may run out of high-quality (like books, Wikipedia) or even low-quality (like Reddit) data; see e.g. Villalobos et al. (2022) which forecasts high-quality text data being exhausted in 2024 or thereabouts, or Chinchilla's wild implications and the discussion there.
- A severe extreme geopolitical tail event, such as a great power conflict between the US and China, may occur.
- Increasingly powerful AI systems may help automate or otherwise speed up AI progress.
- Social resistance and/or stringent regulations may diminish investment and/or hinder progress.
- Unknown unknowns arise.
Still, I really do think a 1e35 2022-FLOP training run could be enough (>50% likely, say) for TAI, and I really do think, on roughly this model, we could get such a training run by 2040 (also >50% likely). One of the main reasons why I think so is that as AI systems get increasingly more powerful and useful (and dangerous), incentives will keep pointing in the direction of AI capabilities increases, and funding will keep flowing into efforts to keep scaling laws going. And if TAI is on the horizon, that suggests capabilities (and as a consequence, business opportunities) will keep improving.
You Won't Find Reliability on the Frontier
One way that AI systems can disappoint is if it turn out they are, and for the forseeable future remain, chronically unreliable. Eden writes, "[Which] areas of the economy can deal with 99% correct solutions? My answer is: ones that don't create/capture most of the value." And people often point out that modern AI systems, and large language models (henceforth, LLMs) in particular, are unreliable. (I take reliable to mean something like "consistently does what you expect, i.e. doesn't fail".) This view is both true and false:
- AI systems are highly unreliable if you only look at frontier capabilities. At any given time, an AI system will tend to succeed only some of the time at the <10% most impressive tasks it is capable of. These tasks are the ones that will get the most attention, and so the system will seem unreliable.
- AI systems are pretty reliable if you only look at long-familiar capabilities. For any given task, successive generations of AI systems will generally (not always) get better and better at it. These tasks are old news: we take it for granted that AIs will do them correctly.
John McCarthy lamented: "As soon as it works, no one calls it AI anymore." Larry Tesler declared: "AI is whatever hasn't been done yet."
Take for example the sorting of randomly generated single-digit integer lists. Two years ago janus tested this on GPT-3 and found that, even with a 32-shot (!) prompt, GPT-3 managed to sort lists of 5 integers only 10/50 times, and lists of 10 integers 0/50 times. (A 0-shot, Python-esque prompt did better at 38/50 and 2/50 respectively). I tested the same thing with ChatGPT using GPT-3 and it got it right 5/5 times for 10-integer lists.[9] I then asked it to sort five 10-integer lists in one go, and it got 4/5 right! (NB: I'm pretty confident that this improvement didn't come with ChatGPT exactly, but rather with the newer versions of GPT-3 that ChatGPT is built on top of.)
(Eden also brings up the problem of accountability. I agree that this is an issue. Modern AI systems are basically inscrutable. That is one reason why it is so hard to make them safe. But I don't expect this flaw to stop AI systems from being put to use in any except the most safety-critical domains, so long as companies expect those systems to win them market dominance and/or make a profit.)
Autonomous Driving
But then why are autonomous vehicles (henceforth, AVs) still not reliable enough to be widely used? I suspect because driving a car is not a single task, but a task complex, a bundle of many different subtasks with varying inputs. The overall reliability of driving is highly dependent on the performance of those subtasks, and failure in any one of them could lead to overall failure. Cars are relatively safety-critical: to be widely adopted, autonomous cars need to be able to reliably perform ~all subtasks you need to master to drive a car. As the distribution of the difficulties of these subtasks likely follows a power law (or something like it), the last 10% will always be harder to get right than the first 90%, and progress will look like it's "almost there" for years before the overall system is truly ready, as has also transparently been the case for AVs. I think this is what Eden is getting at when he writes that it's "hard to overstate the difference between solving toy problems like keeping a car between some cones on an open desert, and having a car deal with unspecified situations involving many other agents and uncertain info navigating a busy city street".
This seems like a serious obstacle for more complex AI applications like driving. And what we want AI for is complicated tasks -- simple tasks are easy to automate with traditional software. I think this is some reason to think an AI winter is more likely, but only a minor one.
One, I don't think what has happened to AVs amounts to an AV winter. Despite expectations clearly having been unmet, and public interest clearly having declined, my impression (though I couldn't find great data on this) is that investment in AVs hasn't declined much, and maybe not at all (apparently 2021 saw >$12B of funding for AV companies, above the yearly average of the past decade[10]), and also that AV patents are steadily rising (both in absolute numbers and as a share of driving technology patents). Autonomous driving exists on a spectrum anyway; we do have "conditionally autonomous" L3 features like cruise control and auto lane change in cars on the road today, with adoption apparently increasing every year. The way I see it, AVs have undergone the typical hype cycle, and are now by steady, incremental change climbing the so-called slope of enlightenment. Meaning: plausibly, even if expectations for LLMs and other AI systems are mostly unmet, there still won't be an AI winter comparable to previous winters as investment plateaus rather than declines.
Two, modern AI systems, and LLMs specifically, are quite unlike AVs. Again, cars are safety-critical machines. There's regulation, of course. But people also just don't want to get in a car that isn't highly reliable (where highly reliable means something like "far more reliable than an off-brand charger"). For LLMs, there's no regulation, and people are incredibly motivated to use them even in the absence of safeguards (in fact, especially in the absence of safeguards). I think there are lots of complex tasks that (1) aren't safety-critical (i.e., where accidents aren't that costly) but (2) can be automated and/or supported by AI systems.
Costs and Profitability
Part of why I'm discussing TAI is that it's probably correlated with other AI advancements, and part is that, despite years of AI researchers' trying to avoid such expectations, people are now starting to suspect that AI labs will create TAI in this century. Investors mostly aren't betting on TAI -- as I understand it, they generally want a return on their investment in <10 years, and had they expected AGI in the next 10-20 years they would have been pouring far more than some measly hundreds of millions (per investment) into AI companies today. Instead, they expect -- I'm guessing -- tools that will broadly speed up labour, automate common tasks and make possible new types of services and products.
Ignoring TAI, will systems similar to ChatGPT, Bing/Sydney and/or modern image generators become profitable within the next 5 or so years? I think they will within 1-2 years if they aren't already. Surely the demand is there. I have been using ChatGPT, Bing/Sydney and DALL-E 2 extensively since they were released, would be willing to pay non-trivial sums for all these services and think it's perfectly reasonable and natural to do so (and I'm not alone in this, ChatGPT reportedly having reached 100M monthly active users two months after launch, though this was before the introduction of a paid tier; by way of comparison, Twitter reportedly has ~450M).[11]
Eden writes: "The All-In podcast folks estimated a ChatGPT query as being about 10x more expensive than a Google search. I've talked to analysts who carefully estimated more like 3-5x. In a business like search, something like a 10% improvement is a killer app. 3-5x is not in the running!"
An estimate by SemiAnalysis suggests that ChatGPT (prior to the release of GPT-4) costs $700K/day in hardware operating costs, meaning (if we assume 13M active users) ~$0.054/user/day or ~$1.6/user/month (the subscription fee for ChatGPT Plus is $20/user/month). That's $700K × 365 = $255M/year in hardware operating costs alone, quite a sum, though to be fair these costs likely exceed operational costs, employee salaries, marketing and so on by an order of magnitude or so. OpenAI apparently expects $200M revenue in 2023 and a staggering $1B by 2024.
At the same time, as mentioned in a previous section, the hardware costs of inference are decreasing rapidly: the price-performance of AI accelerators doubles every ~2.1 years (Hobbhahn and Besiroglu 2022).[12] So even if Eden is right that GPT-like models are 3-5x too expensive to beat old-school search engines right now, based on hardware price-performance trends alone that difference will be ~gone in 3-6 years (though I'm assuming there's no algorithmic progress for inference, and that traditional search queries won't get much cheaper). True, there will be better models available in future that are more expensive to run, but it seems that this year's models are already capable of capturing substantial market share from traditional search engines, and old-school search engines seem to be declining in quality rather than improving.
It does seem fairly likely (>30%?) to me that AI companies building products on top of foundation models like GPT-3 or GPT-4 are overhyped. For example, Character.AI recently raised >$200M at a $1B valuation for a service that doesn't really seem to add much value on top of the standard ChatGPT API, especially now that OpenAI has added the system prompt feature. But as I think these companies may disappoint precisely because they are obsoleted by other, more general AI systems, I don't think their failure would lead to an AI winter.
Reasons Why There Could Be a Winter After All
Everything I've written so far is premised on something like "any AI winter would be caused by AI systems' ceasing to get more practically useful and therefore profitable". AIs being unreliable, hardware price-performance progress slowing, compute for inference being too expensive -- these all matter only insofar as they affect the practical usefulness/profitability of AI. I think this is by far the most likely way that an AI winter happens, but it's not the only plausible way; others possibilities include restrictive legislation/regulation, spectacular failures and/or accidents, great power conflicts and extreme economic downturns.
But if we do see a AI winter within a decade, I think the most likely reason will turn out to be one of:
- Scaling hits a wall; the blessings of scale cease past a certain amount of compute/data/parameters. For example, OpenAI trains GPT-5 with substantially more compute, data and parameters than GPT-4, but it just turns out not to be that impressive.
- There's no sign of this happening so far, as far as I can see.
- True out-of-distribution generalisation is far off, even though AIs keep getting better and more reliable at performing in-distribution tasks.[13] This would partly vindicate some of the LLM reductionists.
- I find it pretty hard to say whether this is the case currently, maybe because the line between in-distribution and out-of-distribution inputs is often blurry.
- I also think that plausibly there'd be no AI winter in the next decade even if AIs won't fully generalise out-of-distribution, because in-distribution data covers a lot of economically useful ground.
- We run out of high-quality data (cf. Villalobos et al. (2022)).
- I'm more unsure about this one, but I reckon ML engineers will find ways around it. OpenAI is already paying workers in LMIC countries to label data; they could pay them to generate data, too.[14] Or you could generate text data from video and audio data. But more likely is perhaps the use of synthetic data. For example, you could generate training data with AIs (cf. Alpaca which was fine tuned on GPT-3-generated texts). ML researchers have surely already thought of these things, there just hasn't been much of a need to try them yet, because cheap text data has been abundant.
I still think an AI winter looks really unlikely. At this point I would put only 5% on an AI winter happening by 2030, where AI winter is operationalised as a drawdown in annual global AI investment of ≥50%. This is unfortunate if you think, as I do, that we as a species are completely unprepared for TAI.
Thanks to Oliver Guest for giving feedback on a draft.
References
Cotra, Ajeya. 2020. “Forecasting Tai with Biological Anchors.”
Erdil, Ege, and Tamay Besiroglu. 2022. “Revisiting Algorithmic Progress.” https://epochai.org/blog/revisiting-algorithmic-progress.
Hobbhahn, Marius, and Tamay Besiroglu. 2022. “Trends in Gpu Price-Performance.” https://epochai.org/blog/trends-in-gpu-price-performance.
Odlyzko, Andrew. 2010. “Collective Hallucinations and Inefficient Markets: The British Railway Mania of the 1840s.”
Olazaran, Mikel. 1996. “A Sociological Study of the Official History of the Perceptrons Controversy.” Social Studies of Science 26 (3): 611--59.
Sevilla, Jaime, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos. 2022. “Compute Trends across Three Eras of Machine Learning.” https://epochai.org/blog/compute-trends.
Villalobos, Pablo, Jaime Sevilla, Lennart Heim, Tamay Besiroglu, Marius Hobbhahn, and Anson Ho. 2022. “Will We Run out of Ml Data? Evidence from Projecting Dataset Size Trends.” https://epochai.org/blog/will-we-run-out-of-ml-data-evidence-from-projecting-dataset.


I think it's important not to take the trend in algorithmic progress too literally. At the moment, we only really know the rate for computer vision, which might be very different than for other tasks. The confidence interval is also quite wide, as you mentioned (the 5th percentile is 4 months and 95th percentile is 25 months). And algorithmic progress is plausibly driven by increasing algorithmic experimentation over time, which might become bottlenecked after either the relevant pool of research talent is exhausted or we reach hardware constraints. For these reasons, I have wide uncertainty regarding the rate of general algorithmic progress in the future.
In my experience, fast algorithmic progress is often the component that yields short timelines in compute-centric models. And yet, both the rate and the mechanism behind algorithmic progress is very poorly understood. Extrapolating this rate naively gives a false impression of high confidence in the future, in my opinion. Assuming that the rate is exogenous gives the arguably false impression that we can't do much to change it. I would be very careful before interpreting these results.