The animation is so cute! I really enjoyed the details.
Without this video I would've either read Karnofsky's series at least a few months from now, or not at all.
That said, the reason I hadn't read it in the first place is that I expected it to be very uncovincing - and that's exactly what I felt about the content of the video. It glosses over things like:
How people and governments would react to changes
Why the thought that AGI is theoretically possible should make us expect it from the current paradigm (my impression is that most researchers don't expect that, and that's why their survey answers are so volatile with slight changes in phrasing)
How known limits, like abundance of physical resources, might affect the changes beyond the near term explosion
What operative conclusion can be drawn from the "importance" of this century. If it turned out to be only the 17th most important century, would that affect our choices?
Why the thought that AGI is theoretically possible should make us expect it from the current paradigm (my impression is that most researchers don't expect that, and that's why their survey answers are so volatile with slight changes in phrasing)
The argument I most commonly hear that it is "too aggressive" is along the lines of: "There's no reason to think that a modern-methods-based AI can learn everything a human does, using trial-and-error training - no matter how big the model is and how much training it does. Human brains can reason in unique ways, unmatched and unmatchable by any AI unless we come up with fundamentally new approaches to AI." This kind of argument is often accompanied by saying that AI systems don't "truly understand" what they're reasoning about, and/or that they are merely imitating human reasoning through pattern recognition.
I think this may turn out to be correct, but I wouldn't bet on it. A full discussion of why is outside the scope of this post, but in brief:
I am unconvinced that there is a deep or stable distinction between "pattern recognition" and "true understanding" (this Slate Star Codex piece makes this point). "True understanding" might just be what really good pattern recognition looks like. Part of my thinking here is an intuition that even when people (including myself) superficially appear to "understand" something, their reasoning often (I'd even say usually) breaks down when considering an unfamiliar context. In other words, I think what we think of as "true understanding" is more of an ideal than a reality.
I feel underwhelmed with the track record of those who have made this sort of argument - I don't feel they have been able to pinpoint what "true reasoning" looks like, such that they could make robust predictions about what would prove difficult for AI systems. (For example, see this discussion of Gary Marcus's latest critique of GPT3, and similar discussion on Astral Codex Ten).
"Some breakthroughs / fundamental advances are needed" might be true. But for Bio Anchors to be overly aggressive, it isn't enough that some breakthroughs are needed; the breakthroughs needed have to be more than what AI scientists are capable of in the coming decades, the time frame over which Bio Anchors forecasts transformative AI. It seems hard to be confident that things will play out this way - especially because:
Even moderate advances in AI systems could bring more talent and funding into the field (as is already happening8).
If money, talent and processing power are plentiful, and progress toward PASTA is primarily held up by some particular weakness of how AI systems are designed and trained, a sustained attempt by researchers to fix this weakness could work. When we're talking about multi-decade timelines, that might be plenty of time for researchers to find whatever is missing from today's techniques.
I think more generally, even if AGI is not developed via the current paradigm, it is still a useful exercise to predict when we could in principle develop AGI via deep learning. That's because, even if some even more efficient paradigm takes over in the coming years, that could make AGI arrive even sooner, rather than later, than we expect.
I'll note that don't think any of his arguments are good:
It's easy to discount "true understanding" as an alternative. But I don't see why "Pattern matching isn't enough" translates to "True understanding is needed" and not just to "Something else which we can't pinpoint is needed".
Which is why I'm way more convinced by Gary Marcus' examples than by e.g. Scott Alexander. I don't think they need to be able to describe "true understanding" to demonstrate that current AI is far from human capabilities.
I also don't really see what makes the track record of those who do think it's possible with the current paradigm any more impressive.
Breakthroughs may take less than the model predict. They may also take more - for example if much much better knowledge of the human brain proves needed. Or if other advances if the field are tied together with them.
even if some even more efficient paradigm takes over in the coming years, that could make AGI arrive even sooner, rather than later, than we expect.
Only if it comes before the "due date".
I'll clarify that I do expect some form of transformative AI this century, and that I am worried about safety, and I'm actually looking for work in the area! But I'm trying to red-team other people who wrote about this because I want to distill the (unclear) reasons I should actually expect this from my deference to high status figures in the movement.
Which is why I'm way more convinced by Gary Marcus' examples than by e.g. Scott Alexander. I don't think they need to be able to describe "true understanding" to demonstrate that current AI is far from human capabilities.
My impression is that this debate is mostly people talking past each other. Gary Marcus will often say something to the effect of, "Current systems are not able to do X". The other side will respond with, "But current systems will be able to do X relatively soon." People will act like these statements contradict, but they do not.
I recently asked Gary Marcus to name a set of concrete tasks he thinks deep learning systems won't be able to do in the near-term future. Along with Ernie Davis, he replied with a set of mostly vague and difficult to operationalize tasks, collectively constituting AGI, which he thought won't happen by the end of 2029 (with no probability attached).
While I can forgive people for being a bit vague, I'm not impressed by the examples Gary Marcus offered. All of the tasks seem like the type of thing that could easily be conquered by deep learning if given enough trial and error, even if the 2029 deadline is too aggressive. I have yet to see anyone -- either Gary Marcus, or anyone else -- name a credible, specific reason why deep learning will fail in the coming decades. Why exactly, for example, do we think that it will stop short of being able to write books (when it can already write essays), or it will stop short of being able to write 10,000 lines of code (when it can already write 30 lines of code)?
Now, some critiques of deep learning seem right: it's currently too data-hungry, and very costly to run large training runs, for example. But of course, these objections only tell us that there might be some even more efficient paradigm that brings us AGI sooner. It's not a good reason to expect AGI to be centuries away.
What operative conclusion can be drawn from the "importance" of this century. If it turned out to be only the 17th most important century, would that affect our choices?
One major implication is that we should spend our altruistic and charity money now, rather than putting it into a fund and investing it, to be spent much later. The main alternative to this view is the view taken by the Patient Philanthropy Project, which invests money until such time that there is an unusually good opportunity.
I'm not sure that follows. We need X money this century and Y money that other century. Can we really expect to know which century will be more important or how much we'll need, and how much we'll be able to save in the future?
What I mean is I think it's straightforward that we need to save some money for emergencies - but as there are no "older humanities" to learn from, it's impossibly hard to forecast how much to save and when to spend it, and even then you only do it by always thinking bad things are still to come, so no time is the "most important".
The video felt too long and digressive. By about halfway I had to take a break to stop my brain from overheating. Also by about halfway I had lost track of what the original point was and how it had led to the current point. I think it would've worked better broken up into at least 3 shorter videos, each with its own hook and punchy finish.
Regarding Rob Miles' audio: is there anything more specific you have to say about it? I want to improve the audio aspect of the videos, but the last one seemed better than usual to me on that front. If you could pinpoint any specific thing that seemed off, that would be helpful to me.
This is a linkpost for the Rational Animations' video based on The Most Important Century sequence of posts by Holden Karnofsky.
Below, the whole script of the video.
Matthew Barnett has written most of it. Several paragraphs were written by Ajeya Cotra, during the feedback process. Holden Karnofsky has also reviewed the script and made suggestions. I made some light edits and additions.
Matthew has also made some additions that weren't in the original sequence by Holden.
The celebrated science fiction author and chemistry professor Isaac Asimov once cataloged a history of inventions and scientific discoveries throughout all of human history. While incomplete, his effort still reveals something intriguing about our current era.
Out of the 694 pages in Asimov’s book, 553 pages documented inventions and discoveries since 1500, even though his book starts in 4 million BC. In other words, throughout human history, most scientific innovation has come relatively recently, within only the last few hundred years.
Other historical trends paint a similar picture.
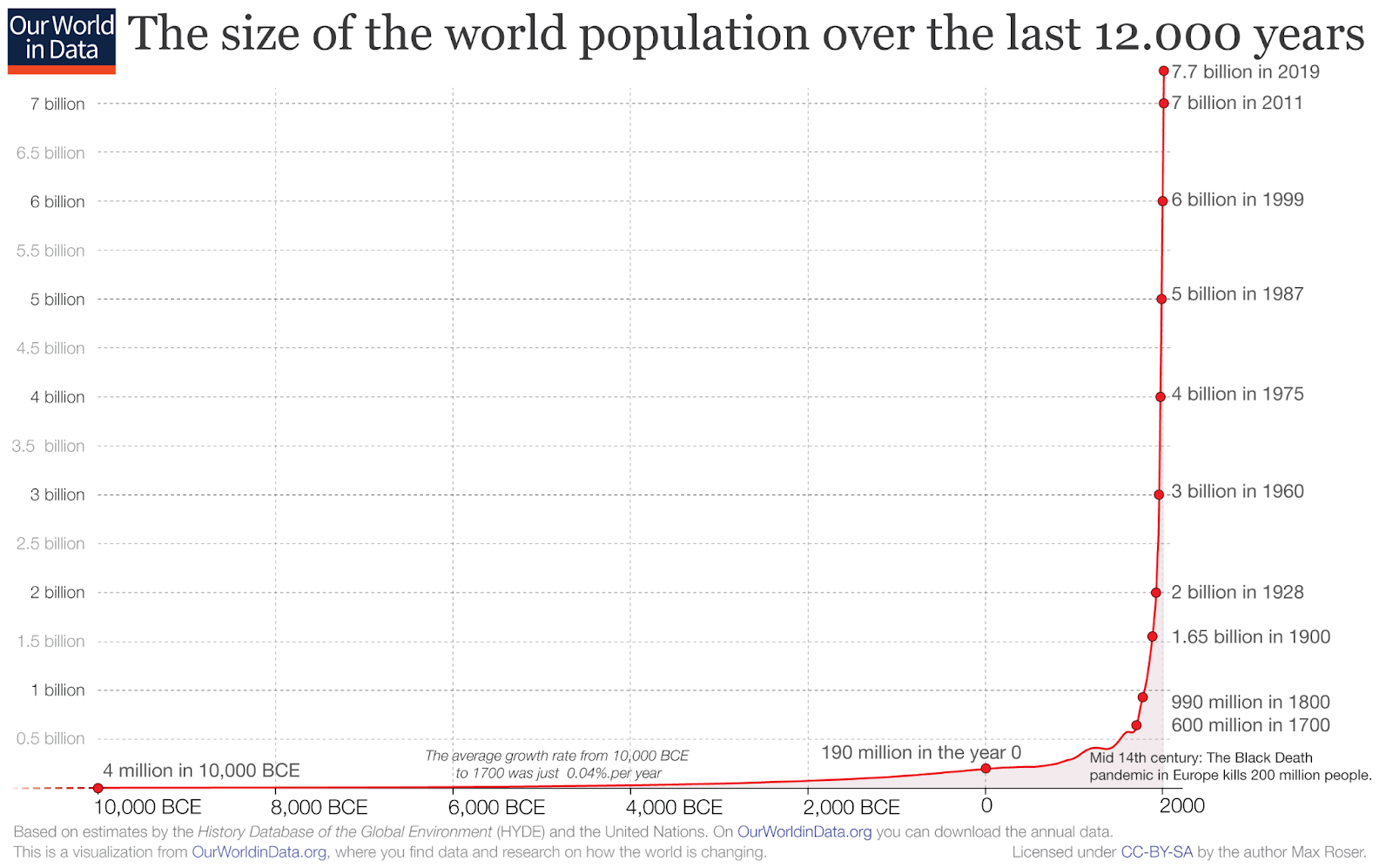
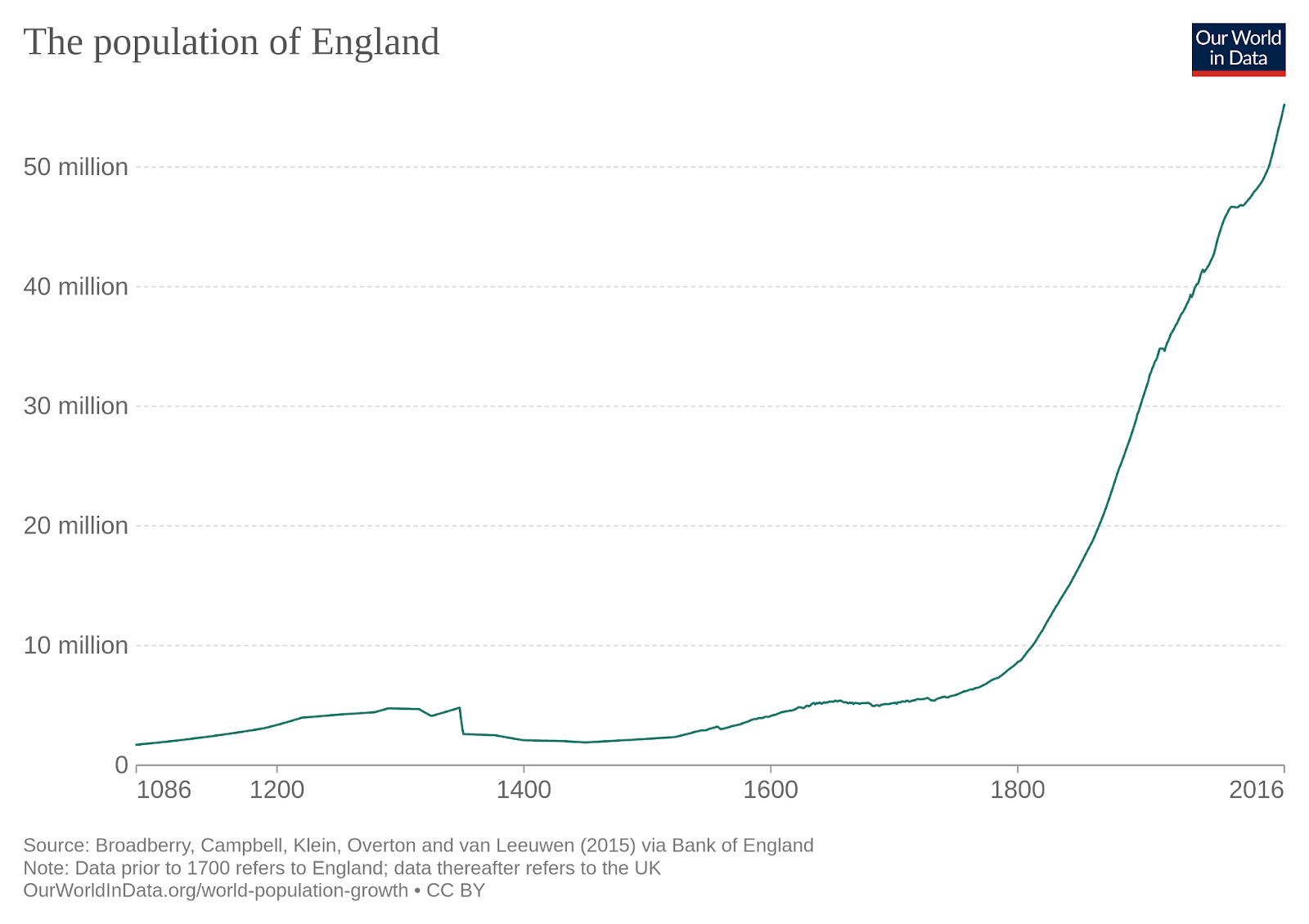
For example, here’s a chart of world population since 10,000 BC.
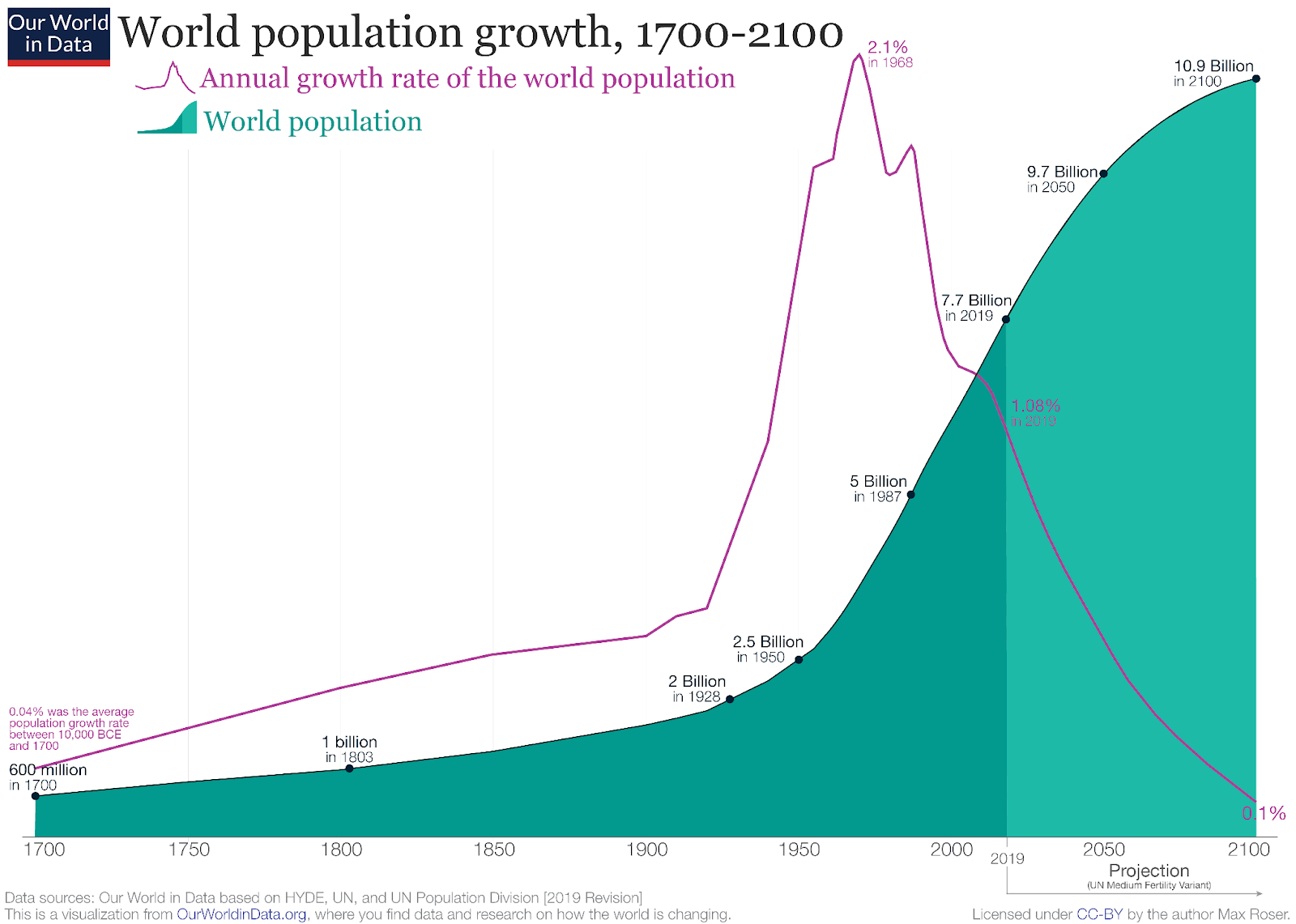
For nearly all of human history up until quite recently, there weren’t very many people on Earth. It took until about 1800 for the population to reach one billion people, and just two hundred years later – a blink of an eye compared to how long our species has been around – Earth reached six billion people.
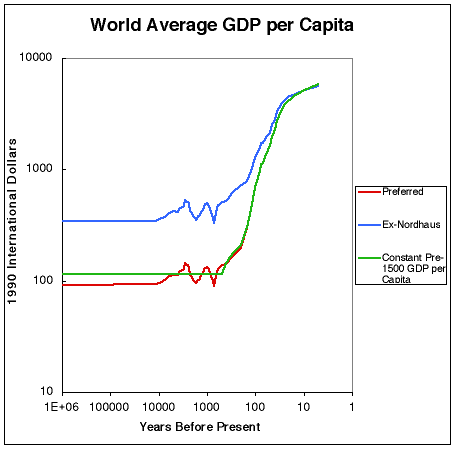
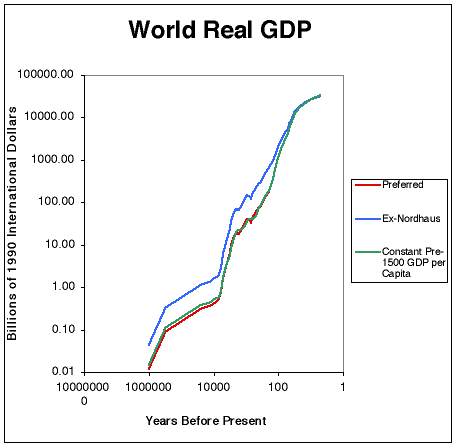
Economic historian Bradford DeLong attempted to piece together the total world economic production over the last million years. By its nature, his reconstruction of the historical data is speculative, but the rough story it tells is consistent with the aforementioned historical trends in population and technology.
In the millenia preceding the current era, economic growth – by which we mean growth in how much valuable stuff humanity as a whole can produce – was extremely slow. Now, growth is much faster.
Bradford DeLong’s data provides historians a quantitative account of what they already know from reading narratives written in the distant past. For nearly all of human history, people lived similarly to the way their grandparents lived. Unlike what we expect today, most people did not see major changes in living standards, technology, and economic production over their lifetimes.
To be sure, people were aware that empires rose and fell, infectious disease ravaged communities, and wars were fought. Individual humans saw profound change in their own lives, through the births and deaths of those they loved, cultural change, and migration. But the idea of a qualitatively different mode of life, with electricity, computers and the prospect of thermonuclear war – that’s all come extremely recently on historical timescales.
As new technologies were developed, quality of life shot up in various ways. For ten year olds, life expectancy was once under 60 all over the world. Now, in many nations, a ten year old can expect to live to the age of 80. With progress in automating food production, fewer people now are required to grow food. As a result, our time has been freed to pursue different activities, for example, going to school.
And it’s not just technology that changed. In the past, people took for granted some social institutions that had existed for thousands of years, such as the monarchy and chattel slavery. In the midst of the industrial revolution, these institutions began to vanish.
Writing in 1763, the eminent British economist Adam Smith wrote that slavery “takes place in all societies at their beginning, and proceeds from that tyrannic disposition which may almost be said to be natural to mankind.” While Adam Smith personally found the practice repugnant, he nonetheless was pessimistic about the future of slavery, predicting that “It is indeed all-most impossible that is should ever be totally or generally abolished.”
And yet, mere decades after Adam Smith wrote those lines, Britain outlawed slavery and launched a campaign to end the practice in its colonies around the world. By the end of the 20th century, every nation in the world had formally abolished slavery.
Another scholar from his era, Thomas Malthus, made a similar blunder.
At the end of the 18th century, Malthus was concerned by the population growth he saw in his time. He reasoned that, historically, excess population growth had always outstripped the food supply, leading to famine and mass death. As a consequence Malthus predicted that recent high population growth in England would inevitably result in a catastrophe.
But what might have been true about all the centuries before the 18th century evidently came to an end shortly after Malthus’ pessimistic prediction. Historians now recognize that rather than famine becoming more frequent, food in Britain became more widely available in the 19th and 20th centuries, despite unprecedented population growth.
What Adam Smith and Thomas Malthus failed to see was that they were living in the very beginning of a historically atypical time of rapid change, a period we now refer to as the industrial revolution. The effects of the industrial revolution have been dramatic, reshaping not only how we live our life, but also our ideas about what to expect in the future.
The 21st century could be much weirder than we imagine
It’s easy to fault historical figures at the time of the industrial revolution for failing to see what was to come in the next few centuries. But their method of reasoning – of looking at the past and extrapolating past trends outwards – is something we still commonly do today to gauge our expectations of the future.
In the last several decades, society has become accustomed to the global economy growing at a steady rate of about 2-4% per year. When people imagine the future, they often implicitly extrapolate this rate of change continuing indefinitely.
We can call this perspective business as usual: the idea that change in the coming decades will look more-or-less like change in the last few decades. Under business as usual, the world in 50 years looks a lot like our current world, but with some modifications. The world in 2072 would look just about as strange as someone from 1972 looking at our current world; which is to say, there will be more technology, different ways of communicating and socializing with others, distinct popular social movements, and novel economic circumstances, but nothing too out of the ordinary, like the prospect of mind uploading, or building Dyson spheres around the sun.
Parents sometimes take this perspective when imagining what life will one day be like for their children. Policymakers often take this perspective when crafting policy, so that their proposed rules will be robust to new developments in the future. And workers who save for their retirement often take this perspective when they prepare for the challenges of growing old.
Contrast business as usual with another perspective, which we can call the radical change thesis. Perhaps, like Adam Smith and Thomas Malthus in their time, we are failing to see something really big on the horizon. Under the radical change thesis, the world by the end of the 21st century will look so different as to make it almost unrecognizable to people living today. Technologies that might seem unimaginable to us now, like advanced nanotechnology, cures for aging, interstellar spaceflight, and fully realistic virtual reality, could only be a few decades away, as opposed to many centuries or thousands of years away.
It’s sensible to be skeptical of the radical change thesis. Scientific research happens slowly, and there’s even some evidence that the rate of technological progress has slowed down in recent decades. At the same time, the radical change thesis makes intuitive sense from a long-view perspective.
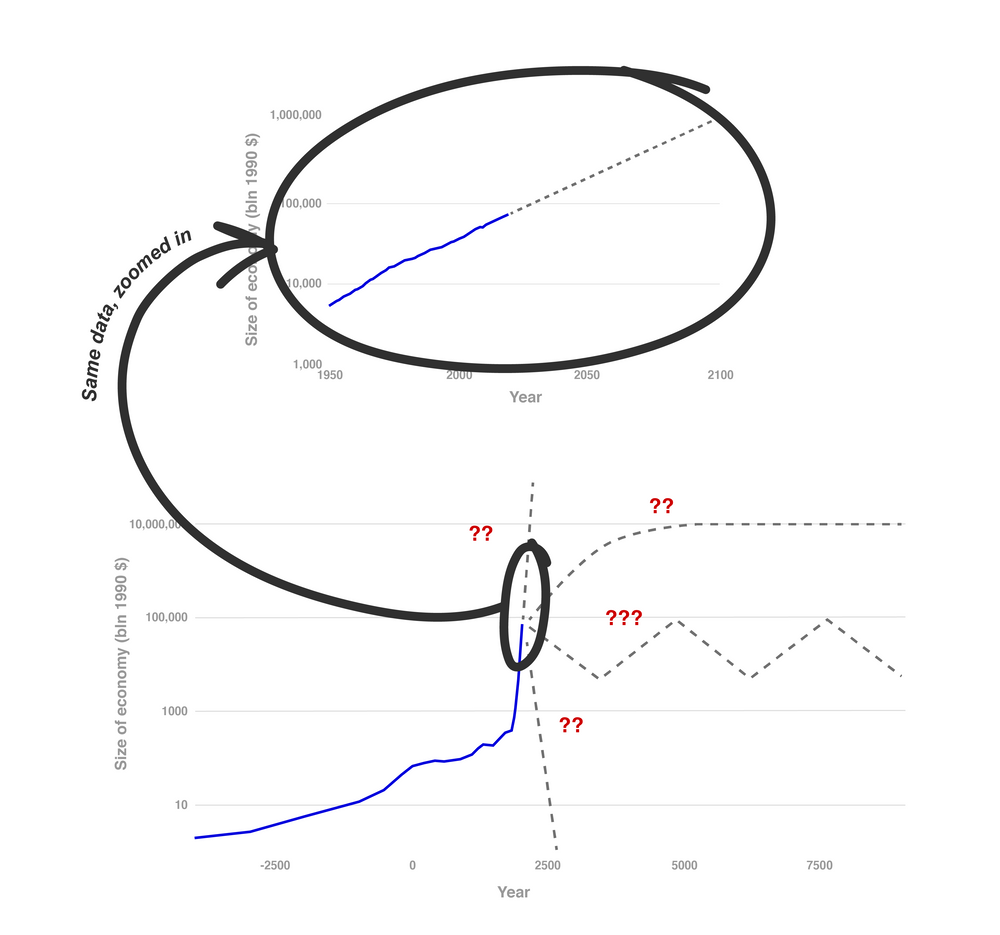
Recall the trend in economic growth.
Here, we’ve zoomed in on the last 100 years of economic growth. This view justifies the business-as-usual perspective. In the last one hundred years, economic production – and technology underlying economic production – has grown at a fairly constant rate. Given the regularity of economic growth in recent decades, it makes a lot of sense to expect that affairs will continue to change at the current rate for the foreseeable future.
But now, zoom out. What we see is not the regular and predictable trend we saw before, but something far more dynamic and uncertain. And rather than looking like change is about to slow down, it looks more likely that change will continue to speed up.
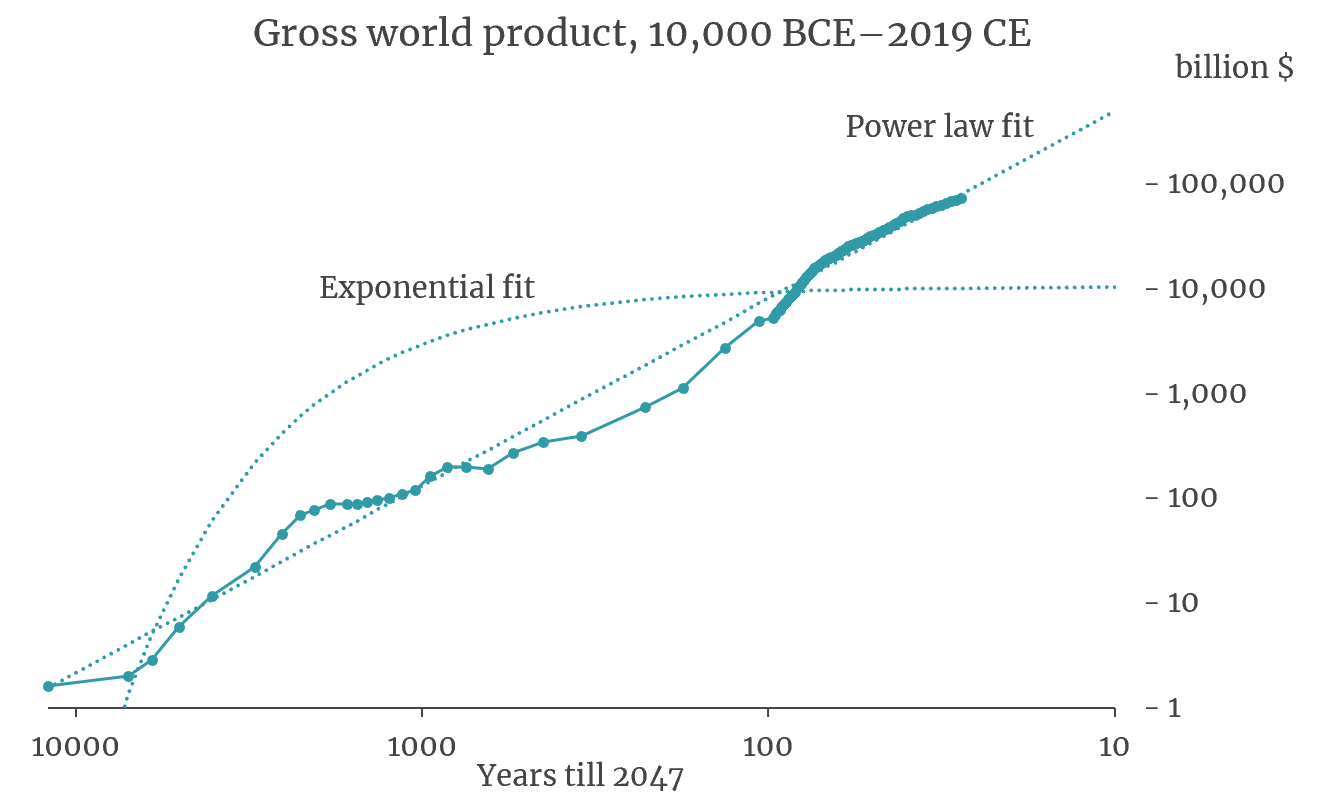
In a classic 1993 paper, economist Michael Kremer proposed that the best fit to this long-run economic data is not the familiar slow rate of exponential change that we’re used to, but rather what’s called hyperbolic growth. Over a long enough time horizon, hyperbolic growth is much more dramatic than exponential growth, making it consistent with the radical change thesis. But it can also be a bit counterintuitive for people to imagine, so here’s an analogy.
Imagine a pile of gold that spontaneously grows over the course of a day. This pile of gold represents the total size of the world economy over time, which we assume grows hyperbolically. At 12 AM, the beginning of the day, there is only one piece of gold in the pile. After 12 hours, the gold pile doubles in size, so that there are now two pieces. Then, at 6 PM, are four gold pieces. Three hours later, at 9 PM, there are eight gold pieces. And only one and a half hours after that, 10:30 PM, there are sixteen gold pieces.
From the perspective of someone watching at 10:30 PM, it would be tempting to think that growth over the next few hours will be similar to growth in the last few hours, and that by midnight the next day, an hour and a half later, the gold pile will double in size yet again, to 32 pieces. But this intuition would be wrong.
Notice that the time it takes for the gold pile to double in size cuts in half each time the size of the pile doubles. As midnight draws near, the pile will continue to double in size, again, and again, more frequently each time than the last. In fact, exactly at midnight, the pile will reach what’s called a singularity and grow to be infinitely large!
We can perform a similar exercise with the real world economy. In 2020, David Roodman found that after fitting a hyperbolic function to historical economic data, the economy is expected to grow to be infinitely large as we approach roughly the year 2047, a general result he says is fairly robust to extrapolating the trend at different periods in history.
Now, it’s important not to take this headline result too seriously, especially the specific year 2047. Physical resource limits prohibit the economy from becoming infinitely large. And moreover, long-run historical data is notoriously unreliable. Using historical statistics alone, especially those from the distant past, it is very difficult to predict what the future will really be like.
The business as usual perspective might still be correct for the foreseeable future. Or something else entirely might happen. Maybe civilization itself will collapse, as we become consigned to fighting endless wars, famines, and pandemics. Humanity might even go extinct.
These possibilities notwithstanding, there do exist concrete reasons to think that the world could be fundamentally different by the end of the 21st century, in a way consistent with the radical change thesis. Infinite growth is out of the question, but one technology is clearly visible on the horizon which arguably has the potential to change our civilization dramatically.
The duplicator
But before we try to predict what technology in the coming decades could precipitate explosive economic growth, let’s first start by examining a hypothetical example: a technology that would be sufficient to have such an effect.
The machine is the duplicator from the comic Calvin and Hobbes.
Here’s how it works. When someone steps in, two exact replicas step out. The replicas keep all the original memories, personalities, and talents. Basically, it splits you into two people, each of whom remember an identical past.
To constrain our expectations a bit, let’s imagine that using the duplicator isn’t free. We can only use it to replicate people, and it costs a lot of money to build and operate a duplicator.
Yet even with this constraint, it seems safe to assume that the duplicator would have a very large impact on the world. Even without knowing exactly how it will be used, there will presumably be people who want to use the duplicator to clone themselves, and other people.
Unlike with ordinary population growth, in which it takes eighteen years and a considerable amount of effort to create one productive worker, the duplicator would allow us to create productive humans almost instantly, and without having to pay the costs of educating and raising them. Consider the case of scientific innovation. If we could clone our most productive scientists, say Newton, Galileo, or Darwin, just imagine how much faster our civilization could innovate.
And it’s not just raw scientific innovation that could increase. With a machine that can duplicate people, all industries could benefit. The most talented rocket engineers, for example, could be cloned and directly planted into places where they’re needed the most. And we could duplicate the most talented doctors, musicians, and architects. As a consequence, the duplicator would lift a crucial bottleneck to civilization-wide output.
Unless we imposed some strict controls on how often people could use the duplicator, it appears likely that there would be a population explosion. But more than just a population explosion, it would be a productivity explosion, since the new duplicates could be direct copies of the most productive people on Earth, who in turn, would use their talents to invent even more productive technologies, and potentially, even better duplicators.
Would the duplicator be enough to sustain the hyperbolic growth trend in gross world product, and enable us to approach the economic singularity we discussed earlier? Maybe.
In academic models of economic growth, there are roughly three inputs to economic production that determine the overall size of the economy. These inputs are population, capital, and technology. Population is the most intuitive input: it just means how many workers there are in a society. Capital is another term for equipment and supplies, like machines, roads, buildings, that allow workers to produce stuff. Technology is what joins these two inputs together; it refers to the inherent efficiency of labor, and includes the quality of tools, and the knowledge of how to create stuff in the first place.
A simple model of economic growth is the following. Over time, people have children, and the population gets larger. With more people, the economy also grows. But the economy also grows faster than the population, because people work to accumulate new capital, and invent new technology at the same time the population is growing. Most importantly, people come up with new ideas. These new ideas are shared with others, and can be used by everyone to increase efficiency.
The process of economic growth looks a lot like a feedback loop. Start with a set of people. These people innovate and produce capital, which makes them more productive, and they also produce resources, which enables them to produce more people. The next generation can rinse and repeat, with each generation more productive than the last, not only producing more people, but also more stuff per capita. In the absence of increased economic efficiency, the population will grow exponentially, but when the total production per person also increases, this process implies super-exponential economic growth.
Recall the analogy of the gold pile that grows in size from earlier. The underlying dynamic is that the gold pile doubles in size every interval. But the interval in which the pile doubles is not fixed. Metaphorically, the gold pile becomes more efficient at doubling in size during each interval, giving rise to a process much faster than exponential growth. Many standard models of economic growth carry the same implication about the world economy.
However, we know our current economy isn’t exploding in size, in the way predicted by this simple model, so why not? One reason could be that our population growth is slowing down. Since the 1960s, population growth worldwide actually peaked before entering a decline. Not coincidentally, world economic growth has fallen since that decade.
The underlying reason behind the fall in population growth and economic growth – also called the demographic transition – is still a matter of debate. But regardless of its causes, the effect of the demographic transition has been that most mainstream economic and population forecasters do not anticipate explosive growth in the 21st century. But, hypothetically, if something like the duplicator were invented, then the potential for explosive growth could return.
The most important invention ever?
It’s unlikely that humans will soon build the duplicator. What’s more likely, however, is the invention of artificial intelligence that can automate labor. As with the duplicator, AI could be copied and used as a worker, vastly increasing total economic productivity. In fact, the potential for AI is even more profound than the duplicator. That’s because AIs have a number of advantages over humans that could enable them to be far more productive in principle. These advantages include: being able to think faster, save their current memory state, copy and transfer themselves across the internet, make improvements to their own software, and much more.
Under the assumption that the development of AI will have a similar effect on the long-term future as the duplicator hypothetically would, the question of whether the 21st century will have explosive growth becomes a question of predicting when AI will arrive. If advanced AI is indeed invented later this century, it might mean the 21st century is the most important century in history.
When will advanced AI arrive?
If you’ve paid any attention to the field of AI in recent years, you’ve probably noticed that we’ve made some startling developments. In the last ten years, we’ve seen the rise of artificial neural networks that can match human performance in image classification, generate photorealistic images of human faces, beat the top Go players in the world, drive cars autonomously, reach grandmaster level at the real time strategy game Starcraft II, learn how to play Atari games from scratch using only the raw pixel data, and write rudimentary poetry and fiction stories.
If the next decade is anything like the last, we’re sure to see even more impressive developments in the near-term future.
Looking further, the holy grail of the field of artificial intelligence is so-called artificial general intelligence, or AGI: a computer capable of performing not only narrow tasks – like game playing and image classification – but the entire breadth of tasks that humans are capable of performing. This would include the ability to reason abstractly and prove new mathematical theorems, perform scientific research, write books, and invent new goods and services. In short, an AGI, if created, would be at least as useful as a human worker, and would in theory have the ability to automate almost any type of human labor.
We know that AGI is possible in principle because human brains are already a type of general intelligence created by evolution. Many cognitive scientists and neuroscientists regularly analogize the brain to a computer, and believe that everything we do is a consequence of algorithms implicit in the structure of our biological neural networks within our brains. Unless the human brain performs literal magic – then we have good reason to believe that one day, we should be able to replicate its abilities in a computer.
However, knowing that AGI is possible is one thing. Knowing when it will be developed and deployed in the real world, is another thing entirely.
Since the beginning of their discipline, AI researchers have experienced notorious difficulty predicting the future of the field. In the early days of the 1960s, the field was plagued with overoptimism, with some prominent researchers declaring that human-like AI was due within 20 years. After these predictions failed to come to fruition, most expectations became more modest. In the 1980s, the field entered what is now known as an AI winter, and many researchers became more focused on short-term commercial applications, rather than long-term goal of creating something that rivals the human brain.
These days, there is a wide variety of opinions among researchers about when AGI will be developed. The most comprehensive survey to date was by Grace et al. from 2016. AI experts were asked when they expected, “for any occupation, machines could be built to carry out the task better and more cheaply than human workers”. The median response was the year 2061, with considerable variation in individual responses.
In addition, most AI researchers believed that progress in their subfield had accelerated in recent years, with 71% of researchers saying that they felt progress was faster in the second half of their career than in the first half.
These results show that most researchers take the possibility of AGI being developed by the end of the century quite seriously. However, it is worth noting that responses were very sensitive to the exact phrasing of the question being asked. A subset of the researchers were asked when they expect AI to automate all human labor, and the median guess for that question was the year 2136. It’s clear that a significant minority of researchers are unconvinced that AGI will arrive any time soon.
(To see more about this survey of AI researchers, check out [Rob Miles’] video about it on [his] channel)
In general, forecasting when AGI will be developed is extremely difficult. Ideally, could create a measure that represents “how much progress there has been in the field of artificial intelligence.” Then, we could plot a measure of progress in AI on a graph, and extrapolate outwards until we are expected to reach a critical threshold, identified with the development of AGI.
The problem with this approach is that it’s very hard to find a robust measure of progress in AI. Luckily, a recent report from researcher Ajeya Cotra takes us part of the way there. Instead of trying to extrapolate progress in AI directly, her report tries to estimate when something like AGI might be developed, based on trends in how affordable it is to build increasingly large AI models, trained using increasingly difficult tasks. We can ground estimates of the needed size of the models in what she calls biological anchors – estimates from biology that inform how much computation, and effort more generally, will be required to develop software that can do what human brains do.
The result very roughly coincides with the median responses from the expert survey, predicting that humans will likely develop AI that can cheaply automate nearly all human labor by the end of the century – in fact, more likely than not by 2060. To understand how her model comes to this conclusion, we need to first get a sense of how current progress in AI is made.
Ajeya Cotra’s report on AI timelines
Since 2012, the field of AI has been revolutionized by developments in deep learning. Deep learning involves training large artificial neural networks to learn tasks using an enormous amount of data, without the aid of hand-crafted rules and heuristics, and it’s been successful at cracking a set of traditionally hard problems in the field, such as those involving vision and natural language.
One way to visualize deep learning is to imagine a digital brain – called an artificial neural network – that tries a massive amount of trial and error at a given task, for example, predicting the next character in a sequence of text. The neural network initially starts out randomly specified, and so will generate gibberish at first. During training, however, the neural network will be given a set of problems and will be asked to provide a solution to each of those problems. If the neural network’s solutions are incorrect, its inner workings are slightly rewired with the intention of providing it a better answer next time. Over time, the neural network should become better at the assigned task; if it does, then we say that it’s learning.
In her report, Ajeya Cotra discusses a deep connection between progress in hardware and progress in AI. The idea is simple: with greater access to computation, AI researchers can train larger and more general deep learning models. In fact, the rise of deep learning in the last decade has largely been attributed to the falling cost of computation, especially given progress in graphics processing units, which are used heavily in AI research.
In a nutshell, Cotra tries to predict when it will become affordable for companies or governments to train extremely large deep learning models, with the effect of automating labor across the wide variety of tasks that humans are capable of learning. In building this forecast, she makes some assumptions about our ability to scale deep learning models to reach human level performance, and the continued growth in computing hardware over the coming decades.
Over time, researchers have found increasingly effective deep learning models that are capable of learning to perform a wider variety of tasks, and more efficiently than before. It seems plausible that this process will continue until deep learning models are capable of automating any aspect of human cognition.
Even if future AI is not created via deep learning, Cotra’s model may still be useful because of how it puts a soft upper bound on when humans will create AGI. She readily admits that if some more clever, and more efficient paradigm for designing AI than deep learning is discovered, then the dates predicted by this model may end up being too conservative.
Cotra’s model extrapolates the rate at which progress in computing hardware will continue, and the economy will continue to steadily get larger, making it more feasible for people to train extremely large deep learning models on very large datasets. By their nature, deep learning algorithms are extremely data and computation hungry. It can often take a lot of money and many gigabytes of training data for deep learning algorithms to learn tasks that most humans find relatively easy, like manipulating a rubix cube, or spotting simple logical errors in natural language. This is partly why it has only recently become practically possible to train neural networks to perform these tasks.
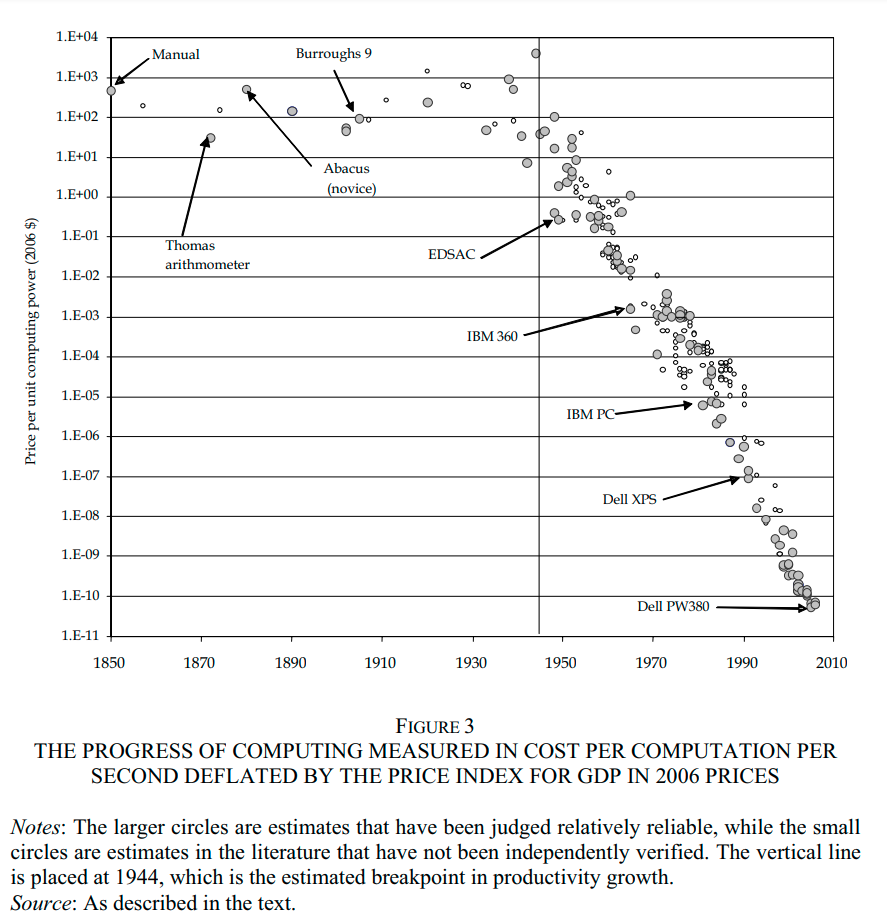
Historically, progress in computing power was extraordinarily rapid. According to data from William Nordhaus, between 1950 and 2010, the price of computation dropped by over 100 billion. Put another way, that means that if you needed to perform a calculation in 1950 that would cost the same amount as the Apollo program that would later send humans to the moon, then the equivalent calculation would cost less than ten dollars using computers in 2010, when adjusted for inflation over the same time period.
Since 2010, the rate of progress in computing hardware has slowed down from this spectacular pace, but continues to improve relatively steadily. By projecting outwards current trends, we can forecast when various computing milestones will be reached. For example, we can predict when it will become affordable to train a deep learning model with one billion petaflops, or one trillion petaflops.
Of course, simply knowing how much computation will be available in the future can’t tell us how powerful deep learning models will be. For that, we need to understand the relationship between the amount of computation used to train a deep learning model, and its performance. Here’s where Ajeya Cotra’s model becomes a little tricky.
Roughly speaking there are two factors that determine how much computation it takes to train a deep learning model on some task holding other factors fixed: the size of the deep learning model, and how much trial and error the model needs to learn the task. The larger the model is, the more expensive it is to run, which increases the computation it takes to train it. Similarly, the more trial-and-error is needed to learn the task, the more computation it takes to train the model.
Let’s consider the first factor – the size of the deep learning model. Larger models are sort of like larger brains: they’re able to learn more stuff, execute more complex instructions, and pick up on more nuanced patterns within the world. In the animal kingdom, we often, but not always, consider animals with larger brains, such as dogs, to be more generally intelligent than animals with smaller brains, such as fish. For many complex tasks, like writing code, you need a fairly large minimum model size – perhaps almost the size of a mouse’s brain – to learn the task to any reasonable degree of performance – and it will still be significantly worse than human programmers.
The task we’re most interested in is the task of automating human labor – at least, the key components of human labor most important for advancing science and technology. It seems plausible that we’d need to use substantially larger models than any we’ve trained so far if we want to train on this task.
Cotra roughly anchors “the size of model that would be capable of learning the task of automating R&D” with the size of the human brain, give or take a few orders of magnitude. In fact, this approach of using biological anchors to guide our AI forecasts has precedent. In 1997, the computer scientist Hans Moravec tried to predict when computer hardware would become available that could rival the human brain. Later work by Ray Kurzweil mirrored Moravec’s approach.
After looking into these older estimates, Cotra felt that the loose brain anchor made sense and seemed broadly consistent with machine learning performance so far. She ultimately made the guess that current algorithms are about one tenth as efficient as the human brain, with very wide uncertainty around this estimate.
Now we come to the second factor -- how much “trial-and-error” would a brain-sized model need to learn tasks required to automate science and technology R&D? This is the hardest and most uncertain open question in this entire analysis. How much trial-and-error is needed to train this model is a question of how efficient deep learning models will be at learning tasks of this form, and we only have limited and very indirect evidence about that question.
The possibilities span a wide range. For example, perhaps deep learning models will be as efficient as human children, taking only the equivalent of twenty years of experience (sped up greatly within a computer) to learn how to be a scientist or engineer. Cotra thinks this is unlikely, but not impossible.
On the other extreme, perhaps deep learning models will be as inefficient as evolution, taking the equivalent of hundreds of trillions of lifetimes of experience to “evolve” into a scientist or engineer. Again, Cotra thinks this is unlikely, but possible.
Cotra thinks the answer is likely to lie somewhere in between – that training deep learning models to automate science and engineering will require much more computation than raising a human child to be a scientist, but much less computation than simulating natural selection until it evolves scientists.
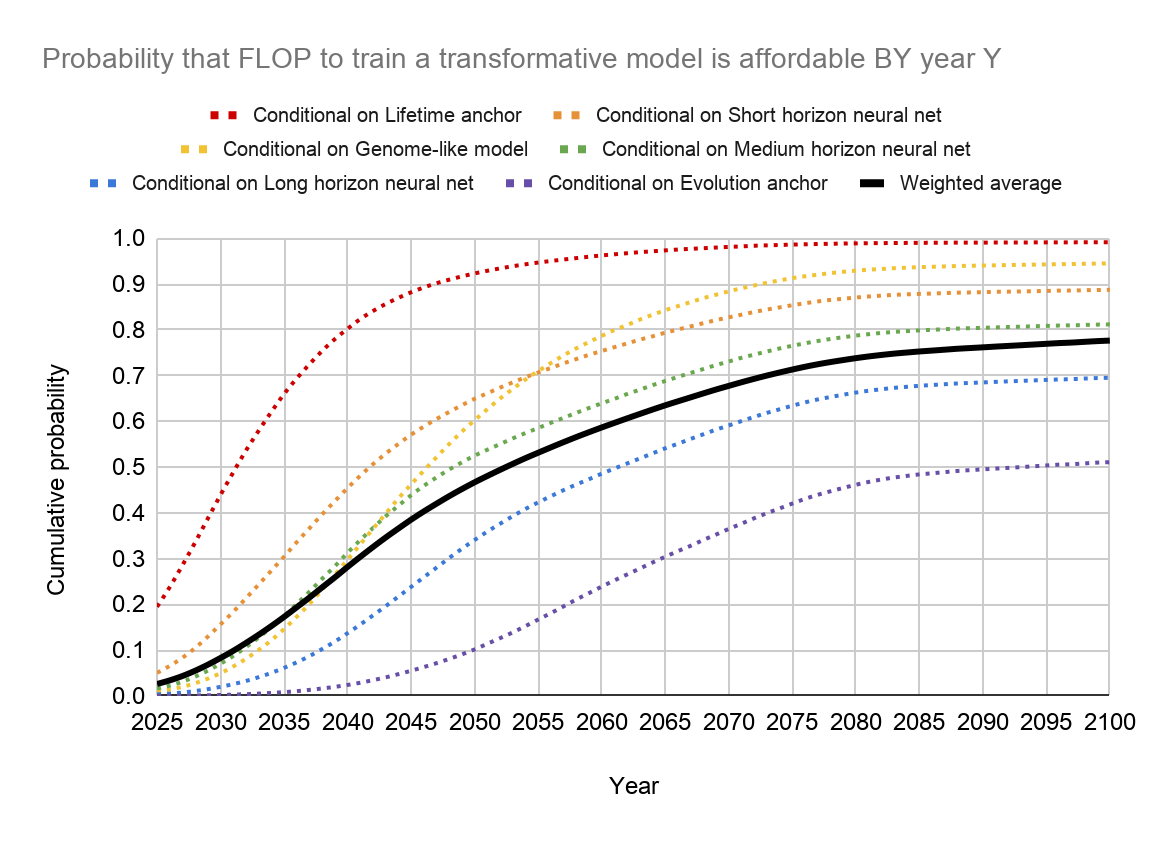
In her report, Cotra considers several “anchors” that lie in between these two extremes, and proceeds by placing a subjective probability distribution over all of them. She arrived at the prediction that there’s a roughly 50% chance that it will become economically feasible to train the relevant type of advanced AI by 2052. The uncertainty in her calculation was quite large, however, reflecting the uncertainty in her assumptions.
Here’s a graph showing how the resulting probability distribution changes under different assumptions.
What does this all ultimately mean?
Now, you might be thinking: let’s say these predictions are right – AGI arrives later this century, and as a result, there’s a productivity explosion, changing human life as we know it – what does it ultimately mean for us? Should we be excited? Should we be scared?
At the very least, our expectations should be calibrated to the magnitude of the event. If your main concern from AGI is that you might lose your job to a robot, then your vision of what the future will be like might be too parochial.
If AGI arrives later this century, it could mark a fundamental transformation in our species, not merely a societal shift, a new fad, or the invention of a few new gadgets. As science fiction author Vernor Vinge put it in a famous 1993 essay, “This change will be a throwing-away of all the human rules, perhaps in the blink of an eye -- an exponential runaway beyond any hope of control. Developments that were thought might only happen in "a million years" (if ever) will likely happen in the next century.”
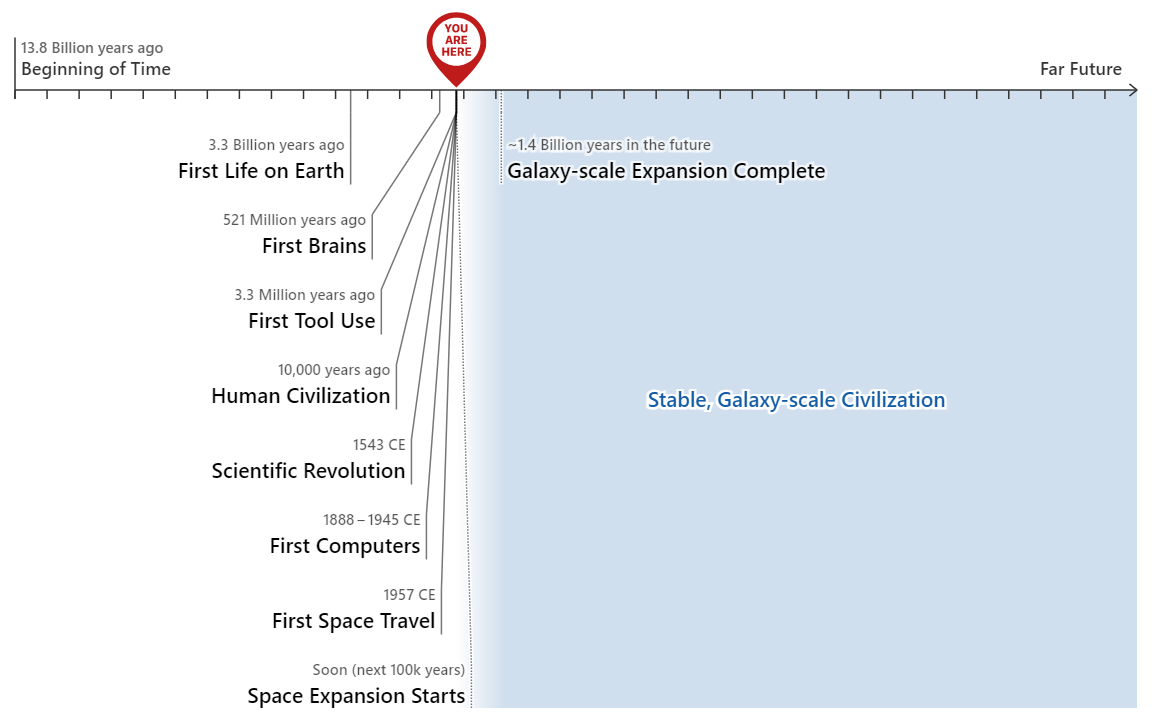
One way of thinking about this event is to imagine that humanity is on a cliff’s edge, ready to slide off into the abyss. In the abyss we have only the vaguest sense as to what lies beyond, but we can give our best guesses. A good guess is that humans, or our descendents, will colonize the galaxy and beyond. That means, roughly speaking, the history of life looks a lot like this, with our present time tightly packed between the time humans first came into existence, and the time of the first galaxy-wide civilization.
Our future could be extraordinarily vast, filled with technological wonders, a gigantic number of people and strange beings, and forms of social and political organization we can scarcely imagine. The future could be extremely bright. Or it could be filled with horrors.
One harrowing possibility is that the development of AGI will be much like the development of human life on Earth, which wasn’t necessarily so great for the other animals. The worry here is one of value misalignment; it is not guaranteed that, even though humans will be the ones to develop AI, that AI will be aligned with human values.
(In fact, [Rob Miles]’s channel is about how advanced AI could turn out to be misaligned with human desires, which could surely lead to bad outcomes. This prospect raises a variety of technical challenges, prompting the need for more research on how to make sure future AI is compatible with human values.)
In addition to understanding what is to come, we also have a responsibility to make sure things go right.
When approaching what may be the most important event in human history, perhaps the only appropriate emotion is vigilance. If we are on the edge of a radical transformation of our civilization, the actions we take today could have profound effects on the long-term future, reverberating through billions of years of future history. Even if we are not literally among the most important people who ever live, our actions may still reach far further than we might have otherwise expected.
The astronomer Carl Sagan once wrote that Earth is a pale blue dot, suspended in the void of space, whose inhabitants exaggerate their importance. He asked us to “think of the rivers of blood spilled by all those generals and emperors so that, in glory and triumph, they could become the momentary masters of a fraction of a dot.”
Carl Sagan’s intention was to get us to understand the gravity of our decisions by virtue of our cosmic insignificance. However, in light of the fact that the 21st century could be the most important century in human history, we can turn this sentiment on its head.
If indeed humans will some time in the foreseeable future reach the stars, our choices now are cosmically significant, despite currently only being tiny inhabitants of a pale blue dot.
Right now, our civilization is tiny, but we could be the seed to something that will soon become almost incomprehensibly big, and measured on astronomical scales. The vast majority of planets and stars could be dead, but we might fill them with value. Much of what we might have previously thought impossible this century may soon become possible. Truly mind-bending technological and economic change may all play a role in our lifetimes.
Rather than pondering our unimportance, perhaps it is wiser to try to understand our true place in history, and quickly. There might be only so much time left, before we take the deep plunge into the abyss.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...







Being as honest as I can:
Holden Karnofsky does discuss this objection in his blog post sequence,
I think more generally, even if AGI is not developed via the current paradigm, it is still a useful exercise to predict when we could in principle develop AGI via deep learning. That's because, even if some even more efficient paradigm takes over in the coming years, that could make AGI arrive even sooner, rather than later, than we expect.
Thanks.
I'll note that don't think any of his arguments are good:
Only if it comes before the "due date".
I'll clarify that I do expect some form of transformative AI this century, and that I am worried about safety, and I'm actually looking for work in the area! But I'm trying to red-team other people who wrote about this because I want to distill the (unclear) reasons I should actually expect this from my deference to high status figures in the movement.
My impression is that this debate is mostly people talking past each other. Gary Marcus will often say something to the effect of, "Current systems are not able to do X". The other side will respond with, "But current systems will be able to do X relatively soon." People will act like these statements contradict, but they do not.
I recently asked Gary Marcus to name a set of concrete tasks he thinks deep learning systems won't be able to do in the near-term future. Along with Ernie Davis, he replied with a set of mostly vague and difficult to operationalize tasks, collectively constituting AGI, which he thought won't happen by the end of 2029 (with no probability attached).
While I can forgive people for being a bit vague, I'm not impressed by the examples Gary Marcus offered. All of the tasks seem like the type of thing that could easily be conquered by deep learning if given enough trial and error, even if the 2029 deadline is too aggressive. I have yet to see anyone -- either Gary Marcus, or anyone else -- name a credible, specific reason why deep learning will fail in the coming decades. Why exactly, for example, do we think that it will stop short of being able to write books (when it can already write essays), or it will stop short of being able to write 10,000 lines of code (when it can already write 30 lines of code)?
Now, some critiques of deep learning seem right: it's currently too data-hungry, and very costly to run large training runs, for example. But of course, these objections only tell us that there might be some even more efficient paradigm that brings us AGI sooner. It's not a good reason to expect AGI to be centuries away.
One major implication is that we should spend our altruistic and charity money now, rather than putting it into a fund and investing it, to be spent much later. The main alternative to this view is the view taken by the Patient Philanthropy Project, which invests money until such time that there is an unusually good opportunity.
I'm not sure that follows. We need X money this century and Y money that other century. Can we really expect to know which century will be more important or how much we'll need, and how much we'll be able to save in the future?
What I mean is I think it's straightforward that we need to save some money for emergencies - but as there are no "older humanities" to learn from, it's impossibly hard to forecast how much to save and when to spend it, and even then you only do it by always thinking bad things are still to come, so no time is the "most important".