I was going to link to the 2011 GiveWell blog post by Holden Karnofsky arguing against taking EV estimates literally, but I see Alex Berger has already mentioned it above. I'd call out these passages in particular to save folks the effort of clicking through:
While some people feel that GiveWell puts too much emphasis on the measurable and quantifiable, there are others who go further than we do in quantification, and justify their giving (or other) decisions based on fully explicit expected-value formulas. The latter group tends to critique us – or at least disagree with us – based on our preference for strong evidence over high apparent “expected value,” and based on the heavy role of non-formalized intuition in our decisionmaking. This post is directed at the latter group.
We believe that people in this group are often making a fundamental mistake, one that we have long had intuitive objections to but have recently developed a more formal (though still fairly rough) critique of. The mistake (we believe) is estimating the “expected value” of a donation (or other action) based solely on a fully explicit, quantified formula, many of whose inputs are guesses or very rough estimates. We believe that any estimate along these lines needs to be adjusted using a “Bayesian prior”; that this adjustment can rarely be made (reasonably) using an explicit, formal calculation; and that most attempts to do the latter, even when they seem to be making very conservative downward adjustments to the expected value of an opportunity, are not making nearly large enough downward adjustments to be consistent with the proper Bayesian approach.
This view of ours illustrates why – while we seek to ground our recommendations in relevant facts, calculations and quantifications to the extent possible – every recommendation we make incorporates many different forms of evidence and involves a strong dose of intuition. And we generally prefer to give where we have strong evidence that donations can do a lot of good rather than where we have weak evidence that donations can do far more good – a preference that I believe is inconsistent with the approach of giving based on explicit expected-value formulas (at least those that (a) have significant room for error (b) do not incorporate Bayesian adjustments, which are very rare in these analyses and very difficult to do both formally and reasonably).
Sequence thinking involves making a decision based on a single model of the world: breaking down the decision into a set of key questions, taking one’s best guess on each question, and accepting the conclusion that is implied by the set of best guesses (an excellent example of this sort of thinking is Robin Hanson’s discussion of cryonics). It has the form: “A, and B, and C … and N; therefore X.” Sequence thinking has the advantage of making one’s assumptions and beliefs highly transparent, and as such it is often associated with finding ways to make counterintuitive comparisons.
Cluster thinking – generally the more common kind of thinking – involves approaching a decision from multiple perspectives (which might also be called “mental models”), observing which decision would be implied by each perspective, and weighing the perspectives in order to arrive at a final decision. Cluster thinking has the form: “Perspective 1 implies X; perspective 2 implies not-X; perspective 3 implies X; … therefore, weighing these different perspectives and taking into account how much uncertainty I have about each, X.” Each perspective might represent a relatively crude or limited pattern-match (e.g., “This plan seems similar to other plans that have had bad results”), or a highly complex model; the different perspectives are combined by weighing their conclusions against each other, rather than by constructing a single unified model that tries to account for all available information.
A key difference with “sequence thinking” is the handling of certainty/robustness (by which I mean the opposite of Knightian uncertainty) associated with each perspective. Perspectives associated with high uncertainty are in some sense “sandboxed” in cluster thinking: they are stopped from carrying strong weight in the final decision, even when such perspectives involve extreme claims (e.g., a low-certainty argument that “animal welfare is 100,000x as promising a cause as global poverty” receives no more weight than if it were an argument that “animal welfare is 10x as promising a cause as global poverty”).
Finally, cluster thinking is often (though not necessarily) associated with what I call “regression to normality”: the stranger and more unusual the action-relevant implications of a perspective, the higher the bar for taking it seriously (“extraordinary claims require extraordinary evidence”).
... I don’t believe that either style of thinking fully matches my best model of the “theoretically ideal” way to combine beliefs (more below); each can be seen as a more intellectually tractable approximation to this ideal.
I believe that each style of thinking has advantages relative to the other. I see sequence thinking as being highly useful for idea generation, brainstorming, reflection, and discussion, due to the way in which it makes assumptions explicit, allows extreme factors to carry extreme weight and generate surprising conclusions, and resists “regression to normality.” However, I see cluster thinking as superior in its tendency to reach good conclusions about which action (from a given set of options) should be taken.
... Sequence thinking presumes a particular framework for thinking about the consequences of one’s actions. It may incorporate many considerations, but all are translated into a single language, a single mental model, and in some sense a single “formula.” I believe this is at odds with how successful prediction systems operate, whether in finance, software, or domains such as political forecasting; such systems generally combine the predictions of multiple models in ways that purposefully avoid letting any one model (especially a low-certainty one) carry too much weight when it contradicts the others. On this point, I find Nate Silver’s discussion of his own system and the relationship to the work of Philip Tetlock (and the related concept of foxes vs. hedgehogs) germane
While the post is over a decade old it still seems foundational to how GiveWell think about their CEAs:
Cost-effectiveness is the single most important input in our evaluation of a program's impact. However, there are many limitations to cost-effectiveness estimates, and we do not assess programs solely based on their estimated cost-effectiveness.
I think of cluster thinking-based intervention ranking as better than the sequence thinking-plus-bayesian correction approach you explored above to account for the optimiser's curse for these reasons, especially the observation that successful prediction systems across most domains use cluster not sequence thinking.
especially the observation that successful prediction systems across most domains use cluster not sequence thinking.
I find this "observation" confusing / misleading, given that Holden defines cluster thinking as aggregating decisions from multiple perspectives. This is very different from aggregating the predictions of multiple models. The evidence of "success" he cites only applies to the latter (where "success" is with respect to Brier scores and such), not the former.
And this is practically relevant: If you aggregate multiple models but then maximize EV under the aggregated model, you don't get the "sandboxing" property Holden claims cluster thinking satisfies. The fanatical/Pascalian model will still dominate the EV calculation.
(ETA: As an aside on sequence thinking / cluster thinking generally, I wish these discussions made it very clear whether we're taking ST/CT as (1) different normative standards for good epistemology / decision-making per se, vs. as (2) different procedures for satisfying a given epistemological / decision-theoretic standard. Cf. "criterion of rightness vs. decision procedure" in ethics. This would be helpful for clarifying what's meant by claims like "cluster thinking is how 'successful' prediction systems operate". I've been assuming (2), here, FWIW.)
Thanks for the intriguing pushback, part of why I kept bringing this up over the years was to surface this kind of counterargument, upvoted. Flagging for myself later to look into the evidence base behind
The evidence of "success" he cites only applies to the latter (where "success" is with respect to Brier scores and such), not the former.
because I'd always assumed it was "obviously" the former (wrongly it seems), since the latter seemed non-robust in the sense Dan Luu looked into (cf. "you really have to understand things", which multi-model aggregations are not).
This is great, nice post! Wanted to flag that there's some potentially useful older discussion of related phenomena that I didn't see linked in your post (though possible I missed) in this 2011 GiveWell blog post (title: Why we can't take expected valuate estimates literally even when they're unbiased). I think this is an issue for us at Coefficient Giving too and is one reason among many why I continue to find worldview diversification attractive.
This concern seems to bubble up from time to time in EA, but seems -- as you say -- rarely addressed head on. I wonder how often we privately believe the cause we're championing can't possibly be as good as our naive expected value estimate, but is still probably "very good".
Thanks for sharing this, awareness of this type of bias is very relevant for the EA community.
The interpretation of $\sigma_V / \sigma_\mu$ (squared) is subtle in practice. I think a clean way to express it is the (square root of the) ratio of prior precision to “measurement” precision - that fits with the hierarchical model used to explain it in the paper you reference.
In practice this is not trivial to guesstimate.
An interesting rabbit hole to understand this further is the “Tweedie correction” [1].
It should also be pointed out that once you’ve shrunk the estimate, that’s it: EV maximising will pick the posterior winner without accounting for the posterior variance - also something not everyone is comfortable with.
While I agree that the optimizer's curse is a problem, and one that is relevant for certain sectors of EA, I will also say that given the very high variance in expected impact between causes, this is much less of a problem than other problems in EA epistemics, which is why it hasn't received much attention.
That said, you do note some very interesting things about the optimizer's curse, so the post is valuable beyond restating the problem, so I will give credit where it's due, it's a nice incremental improvement.
This is great, nice post! Wanted to flag that there's some potentially useful older discussion of related phenomena that I didn't see linked in your post (though possible I missed) in this 2011 GiveWell blog post (title: Why we can't take expected valuate estimates literally even when they're unbiased). I think this is an issue for us at Coefficient Giving too and is one reason among many why I continue to find worldview diversification attractive.
Executive summary: When you rank interventions by noisy estimates and pick the top one, you systematically overestimate its impact and bias toward more uncertain options, but a simple Bayesian shrinkage correction can reduce this effect in a toy model, though applying it in practice is difficult.
Key points:
The optimiser’s curse shows that selecting the intervention with the highest estimated value will, in many normal situations, both overestimate its true impact and favor more uncertain interventions.
In a toy model where true effects are normally distributed with mean 0 and SD 100 and errors are normally distributed with mean 0 and SD 50, the top-ranked intervention is overestimated by about 50 lives in the median case, roughly a 25% overestimate.
When speculative interventions have error spreads four times larger than grounded ones but identical true-effect distributions, the speculative option is chosen 93% of the time and is usually the wrong choice, while ignoring speculative options yields nearly twice the average lives saved.
A Bayesian correction from Smith and Winkler shrinks estimates toward a prior mean using a factor α = 1/(1 + (σ_V/σ_μ)^2), which in the toy model eliminates systematic overestimation and improves average performance.
Implementing such corrections in practice is hard because the true spread of intervention effects, the spread and correlation of errors, distribution shapes, and post-selection scrutiny are all difficult to estimate.
GiveWell does not explicitly apply an optimiser’s curse adjustment but uses measures such as a “replicability adjustment” (e.g., multiplying deworming estimates by 0.13) and focusing on interventions with strong RCT evidence, which the author argues may partially but not fully address the selection effect.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, andcontact us if you have feedback.
This is a great summary! Just want to comment that I'm currently doing some empirical projects about whether/how much people in fact discount estimates of interventions' effectiveness when they know they're selected from the extremes of uncertain distributions. If you know people involved in empirical work on this topic, I'd love to meet them! My email is [email protected].
To add to this problem, I think that more uncertain causes are more likely to have overestimated point-estimates even errors non-withstanding. This is for a few reasons, one because we are by nature more optimistic than reality about small probabilities, and that lower quality studies such as cross sectional studies and cohort tend to overestimate effects. When better studies like RCTs or even larger cohorts are done effects often become smaller or disappear.
Unfortunately for many interventions the best data we have is low quality data, and we anchor on those likely overestimated values.
Nick, just wanted to share that I personally strongly held the view that RCTs usually produce smaller effects than observational trials until reading a 2024 Cochrane study examining this specific question - in short, I think it supports a prior view that well-conducted observational studies (at least in healthcare) are not much more likely to overestimate effects than RCTs. To your credit you explicitly include "larger cohorts" among your example of "better studies", so perhaps you already know this! But it was news to me. (Of course I also agree that small and/or low-quality studies, regardless of methodology, should be taken with caution).
Hey there yes that's a great review. I'm not sure how relevant to this development stuff it is though, because
It only accepts really high quality observational studies
it's focuses on human health. We're reasonably good at controlling for confounders with humans, but we have very little clue how to do that with development interventions.
I would love a similar review for development studies but I doubt there would be enough good quality research to do a similar comparison
I have a paper that can help answer this, which uses JPAL and IPA studies! However, you might think observational study overestimates come from selection bias during the publication process - our result doesn't say anything about that.
"First, we find that there is little bias on average. Using our
best-performing observational method (DDML), there is a statistically insignificant and modest
negative mean bias of −0.025 standard deviations. This implies that observational studies do not
systematically over- or underestimate the welfare impact of the programs they evaluate."
That’s right, but it should be possible to model that in a very similar hierarchical manner and adjust accordingly, too, if you buy into the original framework laid out in the post.
(I haven’t fully thought it thru but it does strike me as fundamentally possible with the same caveats of not knowing parameters, not that I’d suggest using the toy model style maths in practice).
This toy model does not prove that all speculative causes are better than grounded ones: you can be extremely certain about how many lives you will save by buying yourself an Xbox (0), but that does not mean it is a better use of funds than buying malaria vaccines for people in extreme poverty.
I think you meant "all grounded causes are better than speculative ones".
So, how to we correct for the optimizers curse? In this article I will show the solution from the original optimisers curse paper by Smith and Winkler. This solution has been discussed before, but I was unable to find anyone actually implementing it in a toy model. This is surprising, because the math involved is actually incredibly simple.
Here is the equation from the original paper:
This is basically a direct application of inverse-variance weighting to the prior and estimated cost-effectiveness. "EV of the posterior cost-effectiveness" = ("EV of the estimated cost-effectiveness"/"variance of the estimated cost-effectiveness" + "EV of the prior cost-effectiveness"/"variance of the prior cost-effectiveness")/(1/"variance of the estimated cost-effectiveness" + 1/"variance of the prior cost-effectiveness").
I found barely any discussion of the topic by any other group, which is concerning, because I expect the problem to be significantly worse for charitable interventions that are based on more speculative evidence. For example, I think this should be highly important for something like Rethink priorities cross cause cost effectiveness model, but I was unable to find any discussion of it there.
Does anyone use this model to decide what to fund? I would say the ranking of its cost-effectiveness estimates is quite close to random.
Good post. I have two general themes I'd like to comment on:
Analogies for cause prioritization
Your analysis covers several perspectives on this phenomenon, if we focus on the "actual performance" perspective, this is pretty similar to multi-armed bandits. One pattern that I think is present in strategies for these types of problems is the idea of spreading out actions across the different possibilities (explore vs exploit and all that). It wouldn't necessarily make sense to commit to one "arm" (or cause) early on when information is low. This "spreading out" across options is one way of dealing with uncertainty.
A similar idea comes up in another potential anology for cause prioritization, financial investing. We can think about optimizing a portfolio and its allocation to achieve good returns relative to risk, rather than trying to pick the single highest return asset. Thus we get concepts like disversification.
I find this stock-picking analogy helpful for thinking about how "neglectedness" is often treated in practice. I've often found myself skeptical of arguments for and from neglectedness, and I feel the way it is applied in practice doesn't really align with the classic "diminishing returns" conception. I think the way neglectedness is treated in practice ends up being more like how an investor with a high risk tolerance might view a risky asset. Riskier assets are expected to have higher returns, investors with lower risk tolerance would staturate low-risk/high-return options quickly, leaving risker investments "neglected". Thus an investor with high risk tolerance can find good opportunities that would be unappealing to other less risk tolerant investors by going to higher risk assets. I think this captures the spirit of what "neglected" cause areas have often looked like in EA, more speculative but where some EAs have a strong feeling that they caould have outsized impact.
If I can read between the lines a bit, under this anology EA pivoting more into AI is kind of like an investor who wants higher returns putting more of their portfolio in small cap growth stocks that are risker but which the investor thinks will result in higher return. One downside of this is decreased diversification. Another possible option would be to hold a more diversified portfolio but use leverage.
In-model vs Out-of-model robustness
The problem is not limited to cases with trials and noisy statistics, because the error does not have to arise from random chance. Problems with assumptions, bad guesses, even math errors will equally get you cursed. If anything, I would expect causes that lack empirical experimental data to be more cursed, not less.
I think this gets at a distinction that is worth calling out, in-model vs out-of-model robustness.
In my experience with cost-benefit analysis, both reading EA related ones and in industry, it is fairly common to propose a "median" scenario and also a "pessimistic" scenario, and provide estimates for these cases. The point is usually that since even the pessimistic scenario looks good, the analysis shows that the proposed intervention is robustly beneficial. This has a two-fold problem:
First, usually the reason to think that the "pessimistic" scenario is 'pessimistic is just that it uses parameter values that reduce the estimated benefit below the "median" scenario. It's unclear sometimes why that means the estimate is robustly lower than the actual benefit. This is the in-model robustness.
Despite the fact that I think this is an issue, sometimes it may be perceived as (or actually be) a somewhat unfair critique. All models are wrong, we have to use what we have to make estimates. This can result in polarized views of what an estimate shows. For a person who likes the intervention and has a gut feeling it is good, the "median" estimate makes a ton of sense and this seems like a very reasonable approach. For a skeptic, it seems prone to over-estimation for the reasons you highlight in the post. Moving the parameters so that your estimate is 25% lower doesn't turn garbage into non-garbage.
However, there is another source of error lurking in the background. What about costs that you haven't included? The potential for the intervention to backfire that isn't considered in any scenario? The hidden assumption that hasn't been tested in the "pessimistic" scenario? This is out-of-model robustness.
I think the polarization when it comes to in-model robustness causes proponents or fans of an idea or intervention to over-estimate robustness even when in-model robustness is high, because they implicitly credit the (perceived) in-model robustness to the out-of-model robustness.
In my view, the whole "rule high stakes in, not out" idea in practice will result in systematically doing this a lot, which I think makes it a bad heuristic for approaching these types of situations. One way to think about this is it encourages us to focus on specific high-volatility "assets" and thus lacks diversification.
The other major problems with trying to calculate your way to a neat and orderly table of "the best" interventions:
There is no single absolute objective perspective on value weights. Just listen to conversations at EAG or in the forum. There will never be full consensus on the value of a quadrillion crustaceans vs. billions of mammals, or on the value of future sentient beings vs. current ones.
Preferences matter. And in fact, a diversity of preferences is essential. If we only used the final ranking, in the extreme case we devote 100% of our resources to Program A. But not everyone is passionate about A, and the world probably can not handle the capacity for everyone to productively contribute to A. So we need people to have a preference for all projects, even and especially those further down the list so we have reasonable coverage of interventions across the entire problem space.
The best cause will disappoint you: An intro to the optimisers curse
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
I would like to thank David Thorstadt for looking over this. If you spot a factual error in this article please message me. The code used to generate the graphs in the article is available to view here.
Introduction
Say you are an organiser, tasked with achieving the best result on some metric, such as “trash picked up”, “GDP per capita”, or “lives saved by an effective charity”. There are several possible options of interventions you can take to try and achieve this. How do you choose between them?
The obvious thing to do is look at each intervention in turn and make your best, unbiased estimate of how each intervention will perform on your metric, and pick the one that performs the best:
Having done this ranking, you declare the top ranking program to be the best intervention and invest in it, expecting that that your top estimate will be the result that you get. This whole procedure is totally normal, and people all around the world, including people in the effective altruist community, do it all the time.
In actuality, this procedure is not correct. The optimisers curse is a relatively simple mathematical finding, first coined in this paper from Smith and Winkler, that proves that in many normal situations such a procedure is overwhelmingly likely to:
Overestimate the impact of the top intervention.
Bias your selection towards more uncertain interventions.
These effects can be small, or they can be drastic, depending on the interventions you are investigating. In general, the bigger the uncertainty in your estimations, the more worried you should be about the curse.
In this article, I will do my best to explain what causes the optimisers curse, using a toy model. I will demonstrate one solution to it, and describe how Givewell has reckoned with the curse in their charity evaluations.
I will do my best to make this accessible and understandable to everyone, even if you aren’t super mathy.
The optimisers curse explained simply
The optimiser's curse is a relatively simple mathematical result, first coined in 2006 in this paper in the journal of Management Science. It is closely related to the winners curse in auctions, and has some similarities to data dredging and regression to the mean in scientific contexts.
The key to the optimiser's curse is the simple fact that the evaluations of each intervention are not being made by omniscient gods. Anytime you make an estimate, you are forced to gather evidence, make assumptions, make calculations, and apply your own judgement to the estimate. At any stage you can make a mistake, or the sources you use could make a mistake, or you could be misled by the noise of an experimental trial.
All this means is that your estimate of an intervention's effectiveness will always be different from it’s actual effectiveness. It could end up being an underestimate, or an overestimate. If you are good, the magnitude of the error will not usually be that bad, but the more interventions you look at, the more likely it is that you’ll make a big error somewhere.
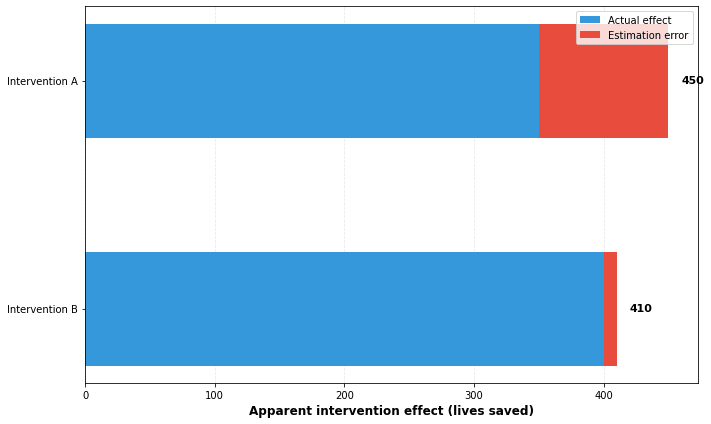
Then we add ranking in. In reality intervention A might save 350 lives, and intervention B might save 400 lives, but if you overestimate intervention A by a 100 lives and intervention B by only 10 lives, it will look like the better option, and you will pick it over intervention B. You will then expect it to save 450 lives, and be 100 lives too optimistic. The overall effect is that your top estimates will have an upward bias, even if every individual estimate in isolation is unbiased:
The other finding is that this advantages more uncertain causes. A grounded intervention that is well evidenced will have a smaller magnitude of error, on average, than a speculative intervention. The result of this is that the speculative intervention gets a better chance at a “high roll”, where it is massively overestimating, allowing it to jump much higher in the rankings than it deserves. In the graph above, the reason that intervention A appears superior to intervention B may be due to it being more uncertain, allowing it to leapfrog ahead.
This is the basic explanation of the optimiser's curse. In the next section, I want to demonstrate the curse in a more practical sense, using a toy model.
Introducing a toy model
In our model, we pretend we are a charity evaluator, investigating the lives saved per million dollars for a number of different charitable interventions. We decide to investigate and evaluate different interventions for their effectiveness.
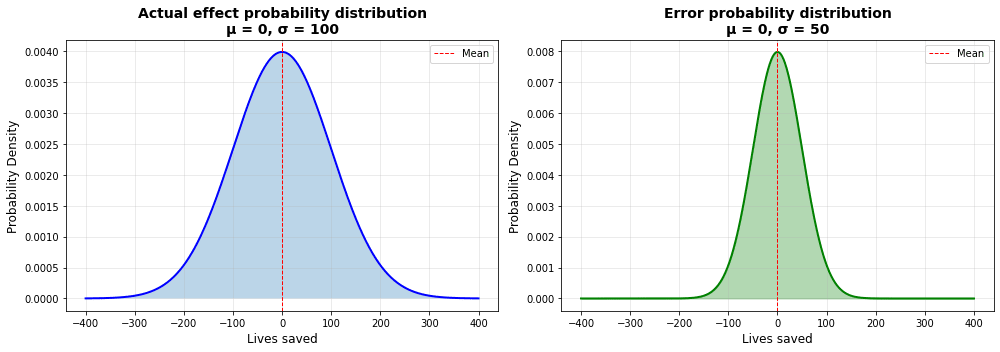
In this model, we will model the actual effect as sampled from a normal distribution, with mean of 0 lives saved and a standard deviation of 100 lives. We then model the error for each intervention as sampled from a different normal distribution, with mean 0 and standard deviation of 50 lives.
Of course, actual charities evaluation is a lot more messy than this, but this simple model will suffice for demonstrating the curse in action. Here are the probability densities for our samples:
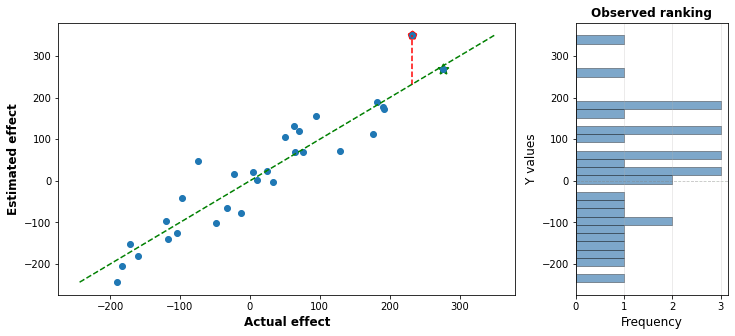
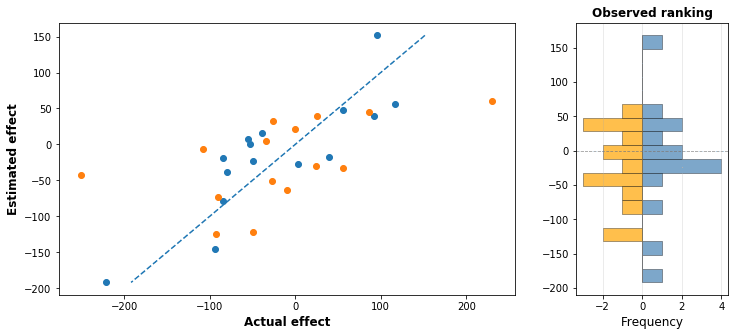
We investigate 30 interventions, grabbing a sampled actual effect and a sampled error, and adding them together to produce an estimated effect. I simulated this in python and produced the following graphs:
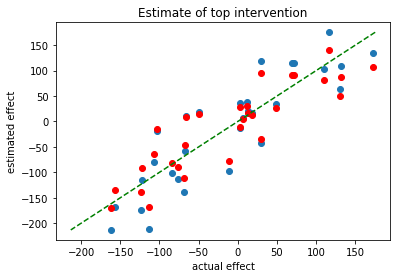
On the left side, each dot is plotted with it’s actual intervention effect on the x-axis, and the estimated effect on the y-axis. The right graph shows what the actual estimator see: a straight ranking of the effectiveness of each intervention.
The green line in the middle is the line of accuracy: If the evaluators were perfect then the estimated effect would be the same as the actual effect, and every dot would fall on the line. But the evaluators are not perfect: some of the time they underestimate the effect, making the dot fall over the line, and sometimes they overestimate it, making the dot fall below the line.
Of course, the evaluators don’t see the “actual effect” part of the graph. All they see is the estimated effect, which is shown in a histogram on the right. In this case, it appears that the point marked with the red pentagon is the top charity.
But that’s not actually true: the top charity is just the rightmost point in the graph, marked here with a green star. In the estimates, it looks like the red point saves 50 more lives than the green point: in reality, it saves like 20 less lives, but it had a lucky draw on the error that made it appear better.
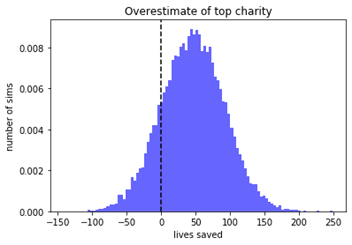
Now, that was just one simulation: if you run it again you will get different results. I ran this simulation ten thousand times, and stored how much of an overestimate you got from picking the top charity each time. It’s graphed below:
We can see that in the median case, the number of lives saved is an overestimate by about 50 lives. From other methodology, I found that this is generally around a 25% overestimate, compared to the actual value. Thus, in our toy model, the optimizers curse is vindicated.
The magnitude of the overestimate will increase if you increase the range of errors, or if you increase the number of interventions that are compared.
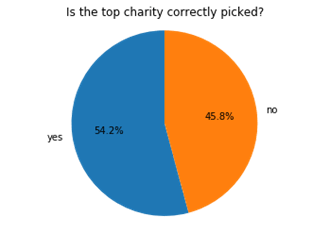
Now, what about the ordering of the charities?Under these conditions, the top charity is actually correctly picked a narrow majority of the time, and most of the time when it isn’t, the winner is in the top 3.
So this doesn’t particularly change your decision procedure: if you want to maximise gains you should still pick the top charity, even though theres a decent chance it’s not the actual top one. This does recommend applying extra scrutiny to all the top charities, as the ordering may have been affected by error.
Introducing speculative interventions
The far more interesting results come when you drop the assumption that all the interventions have the same level of uncertainty.
In the following simulation, I introduce another type of intervention, which I colour in orange. The true effects of these interventions are sampled from the same source as the blue ones (ie, they are no better on average), but their errors have a spread that is 4 times as large. We will call this the “speculative” type of intervention, and we will call our original type of intervention the “grounded” type.
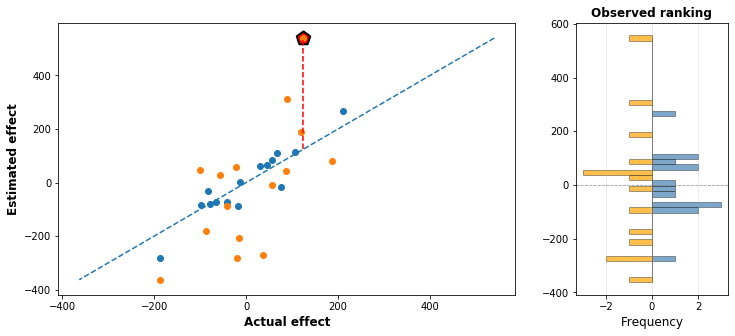
The following graph shows what happens in one simulation, where 15 interventions are speculative and 15 are grounded:
As you can see, the speculative interventions have a much wider range of estimates than the grounded interventions, because there is more room for error in either direction. As a result, when ranking the charities, it appears that the top speculative charity is almost twice as good as the top grounded charity. But this is a pure, error-based illusion. In reality, the top charity is a grounded one, but the speculative charity was just helped along by a very large error in it’s favour.
After running this simulation ten thousand times, we can compare the strategies. If you take the top estimated speculative charity, and the top estimated grounded charity, what happens if you just naively pick which is higher? Here it is:
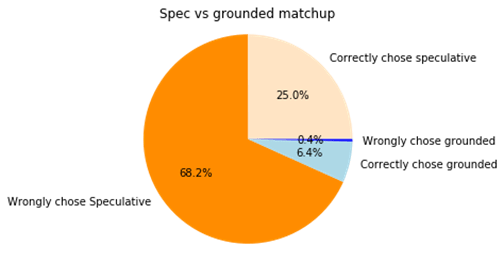
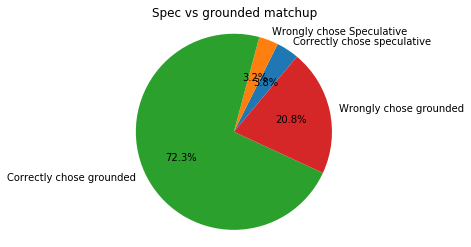
93% of the time, the speculative cause is chosen, and the majority of time, this is actually the wrong chose.
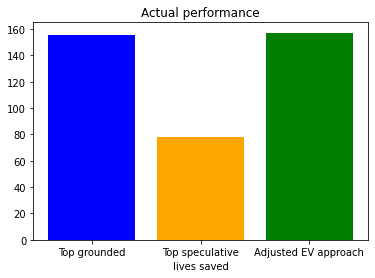
How does this get reflected in the actual performance? In the next set of simulations, I kept track of how many actual lives get saved for three strategies: investing in the top grounded intervention, investing in the top speculative intervention, or investing in whatever the top charity in the evaluation is. Here are the results:
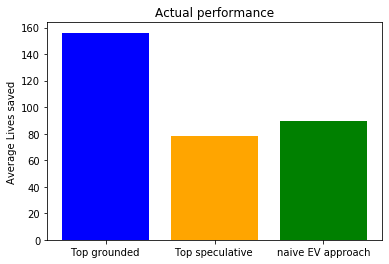
That’s right, in terms of average lives saved, the winning strategy of the three here is to ignore the speculative causes entirely, and just invest in the top grounded intervention. In this particular setup, this saves nearly twice as as many lives.
This actually makes a lot of sense, when you think about it. Both the grounded and speculative causes have similar actual effectiveness, but in the case of the grounded interventions, you get much more useful information out of the evaluation and ranking process.
This is a mathematical demonstration that, in our simple model, an approach of naively investing in the top apparent EV intervention is straight up wrong.
Note that in this toy model, both the speculative causes and the grounded causes are modelled as having the same mean and standard deviation of true effectiveness. You will get different results if these values are different. This toy model does not prove that all speculative causes are better than grounded ones: you can be extremely certain about how many lives you will save by buying yourself an Xbox (0), but that does not mean it is a better use of funds than buying malaria vaccines for people in extreme poverty.
A simple bayesian correction
So, how to we correct for the optimizers curse? In this article I will show the solution from the original optimisers curse paper by Smith and Winkler. This solution has been discussed before, but I was unable to find anyone actually implementing it in a toy model. This is surprising, because the math involved is actually incredibly simple.
Here is the equation from the original paper:
This corresponds to the following process:
Have a prior guess for the effectiveness of an intervention (μi) In our case, the natural choice is that the intervention does nothing.
Do all your intervention evaluation, to get your estimated value of the intervention (Vi).
Analyse the degree of uncertainty in your estimates and use that to determine a deweighting factor (αi)
Using these two numbers, you then make a final estimate vi which is a weighted average of your prior and your calculated value.
They also detail an equation for how to determine the deweighting factor alphai:
The key parameters here are σμi ,the standard deviation or spread of your actual interventions, and σVi , the standard deviation or spread of your errors.[1] In the equation, the ratio of these two spreads is squared.
I want to emphasise that it’s the ratio of these spreads that matters, so it’s not as simple as deweighting causes in proportion to their uncertainty: if intervention class A is twice as uncertain as intervention class B, but the actual effects of intervention class A are twice as spread out, then they should be deweighted by the same amount.
In our grounded intervention case, the spread of interventions is 100, and the spread of errors is 50. The ratio is therefore 0.5, which we square to get 0.25, and plug in to get a deweighting factor of 0.8.
This is applied to each in turn. So, for example, an intervention which gets an estimated effectiveness of 250 lives would get get deweighted, to produce a final estimate of 250*0.8 + 0*(1-0.8) = 200 lives.
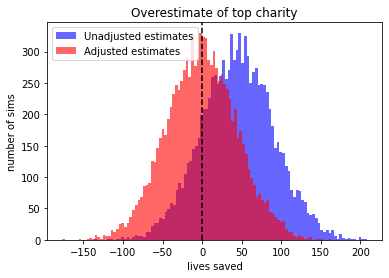
The results are a bit more squished, compared to what you’d expect. But remember, this is taking into account the effect of the whole selection process. And if we repeat our earlier analysis with the adjusted estimates, we get the following after ten thousand simulations:
We can see that it basically worked perfectly: with this adjustment we are exactly as likely to overestimate as underestimate the effectiveness of the top charity.
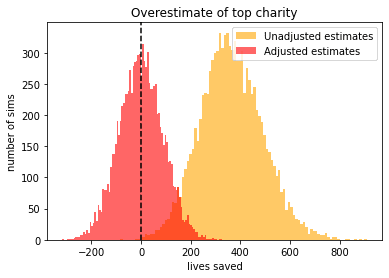
The difference is even more stark if we apply the correction to the extra speculative interventions from earlier. In this case, the spread of errors is 200, whereas the spread of actual interventions is only 100, leading to an alpha of 1/(1+(200/100)^2) = 0.2
Using 30 interventions, and 10 thousand runs, we can see that the speculative intervention greatly overestimates the lives saved, but applying the correction drops it down to zero.
Now, if we repeat our experiment from earlier, but apply our deweighting calculation, the grounded interventions are multiplied by 0.8, whereas the speculative are multiplied by a factor of 0.2:
This means that a speculative charity has to score four times as high on estimated effectiveness to be treated as equal to a grounded intervention. If the uncertainty increased further, the approximate rule would be that increasing the uncertainty by a factor of 10 causes the deweighting factor to drop by a factor of 100.
Here is one result for our grounded and speculative interventions, adjusted according to the formula:
We can see that the adjustment puts the spread of values between speculative and grounded interventions much closer together.
Now, when we run a few thousand simulations and compared approaches, the adjusted EV approach now gives the best overall performance:
Note that this doesn’t actually affect the effectiveness of picking out the top grounded or speculative intervention. This is because the adjustment doesn’t reorder interventions that have the same level of uncertainty. But now the adjusted expected value approach is performing better than either result.
The success of the grounded interventions reflects the fact that the best estimated grounded intervention really is better, on average, than the best estimated speculative intervention.
We can also look at how this affects choice between speculative and grounded charities:
So now, 90% of the time we are picking the grounded charities. This may seem unfair, but we are choosing correctly 75% of the time, which is way better than before where we were choosing wrongly 70% of the time. The fact is, in this situation the top grounded intervention really is the better choice most of the time, because the lower noise allowed us to do a better job at picking out the better grounded interventions.
Obstacles to simple optimizer curse solutions.
So, have we solved the optimizers curse here? Just guess at the parameters for the correction equation and then plug them in, and deweight everything by those factors?
Of course not. It’s easy to do well in a toy model because we know all the information, and everything is behaving in a nice, clean, predictable way. But in reality there are often significant obstacles. I will focus on the difficulty of doing this for charity effectiveness.
How do you estimate the spread of true effectiveness?
In reality, you are never going to see the actual effectiveness of an intervention, only the estimated effectiveness. So it’s going to be tricky to back-determine the spread of actual intervention effectiveness, when the spread you see is a mix of true difference and errors.
Ideally, you would have high quality data showing the actual effect of a variety of interventions, perhaps as a result of doing controlled experiments. However any situations where you have this is going to be a case where uncertainty is quite low anyway. If we are discussing a messy question like “how many lives does this charity save per dollar”, evaluations are difficult and costly.
2. How do you estimate the spread of errors?
This is a similar problem to the previous point: we don’t see the “true” spread of errors either.
Ideally, you would have a reliable database of predicted effectiveness vs actual effectiveness, but we run into the same issues as before: in cases where we have high quality data, the uncertainty is not that large anyway.
3. How do you account for correlated errors?
All the demonstrations in my toy model where assuming that the error in each case is uncorrelated: this is not true in practice. Many similar interventions will share sources of error that affect both in the same way.
According to the paper, correlation reduces the magnitude of the optimizers curse, so if you assume no correlation you will end up overcorrecting for the optimizers curse.
4. How do you account for distribution shapes?
I’ve modeled this as a normal distribution, but is this actually the case? The nature of our selection process makes the shape of the distribution pretty important, because it’s the most extreme cases that are generally important. For example, if the distribution for errors is long-tailed, that should increase the magnitude of the curse, whereas if the distribution for the actual interventions is, it would decrease it.
5. How do you account for extra scrutiny after the initial analysis?
There is a much more well-known cousin to the optimizer's curse known as “regression to the mean”. This is a well established statistical effect where initially extreme findings will end up dropping in magnitude when subject to follow-up studies.
A similar effect is likely to occur here: if you take the top interventions and subject them to increased scrutiny and follow-up studies, you will expect them to drop in estimated effectiveness over time, as errors get spotted and good luck returns to regular luck. If you’re trying to correct for the optimizer's curse, you need to take into account how much of the process has already happened.
So no, it's not simple or easy to implement a correction like this. On the other hand, not implementing a correction may be virtually guaranteeing that your estimates are wrong.
How Givewell has reacted to the optimiser curse
We can take a quick look at how the charity ranker Givewell has responded to the curse. Over there years I found two notable essays discussing the curse in the context of effective altruism and Givewell,, here and here. The latter won a 20 thousand dollar prize for their article.
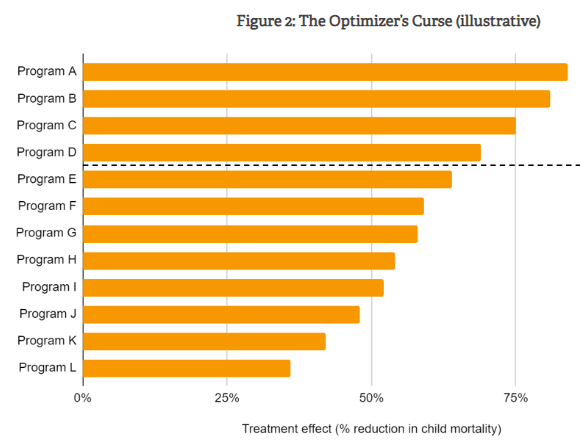
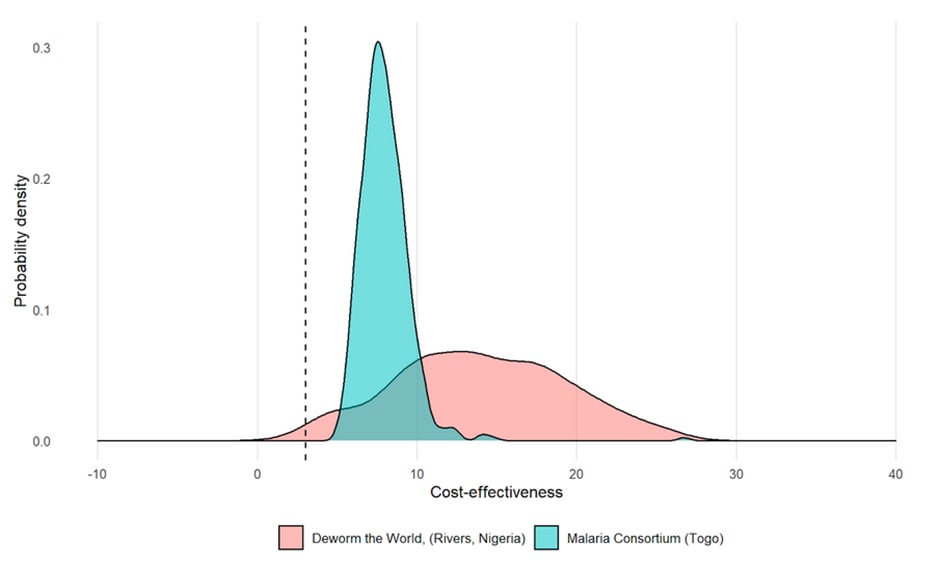
One graph I want to highlight is from the latter essay, which looked at Givewells calculations of cost effectiveness for two different interventions and determined that they did, indeed, have greatly different uncertainty profiles:
Givewell currently does not explicitly account for the curse, for reasons to do with the difficulties I discussed above . You can see their response to one essay on the curse here, and the response to another here. They do state that it is an area of concern for them, but they believe that the scrutiny they apply to causes is already ameliorating the effect of the curse.
One notable point is that they are deweighted uncertain causes already, with a “replicability adjustment”. For example, deworming interventions have been controversial because the primary targeted effect (an increase in income) was almost entirely based on followups to a single experiment which some have claimed gives implausibly large results. As a result, Givewell deweights their estimates significantly from the study findings, multiplying it by a factor of 0.13 to give an answer that is nearly 8 times lower than it would be otherwise. You can see their justification for the value here. I think it would be a mistake to have this factor and also add an optimiser curse adjustment on top, because this factor is accounting for one of the causes of the optimiser curse: good luck on trial outcomes.
I respect Givewell a lot, but I’m not sure if I fully buy their defence. It seems like from this discussion that they are still treating each treatment in isolation, and not taking into account the selection process done by Givewell themselves. If, after subjecting intervention A and intervention B to the same level of in-depth scrutiny, intervention A is still far more uncertain than intervention B, it seems like Givewell’s approach will treat their estimates as equally valid. To me, it seems like this is still likely to unfairly advantage the more uncertain intervention. I am not certain on this point.
One thing I do approve of is the decision of Givewell to focus on a top charities fund that is exclusively limited to charitable interventions that have a large evidence base of randomised controlled trials. I think this decision sidesteps most of the concerns arising from the optimisers curse.
I’ve focussed mostly on Givewell here, but to be clear, I think they are the EA group that has the best approach to the topic. I found barely any discussion of the topic by any other group, which is concerning, because I expect the problem to be significantly worse for charitable interventions that are based on more speculative evidence. For example, I think this should be highly important for something like Rethink priorities cross cause cost effectiveness model, but I was unable to find any discussion of it there.
Conclusion
In this article, I have explained what the optimiser's curse is, demonstrated it’s importance with a toy model, explained one possible method of correcting for it, and shown the difficulties of applying corrections in practice.
I am somewhat confused as to why the optimisers curse is not one of the most discussed topics in effective altruism, given that it seems like it should be a factor in every situation where interventions are ranked. I worry that people have assumed it was just a statistical quirk that only hardcore rigorous evaluators like Givewell have to care about.
But to be clear, all that is is actually required for the optimisers curse to kick in is two things:
Some number of interventions are ranked according to some metric
There is a notable amount of error in intervention evaluation that may result in overestimates.
The problem is not limited to cases with trials and noisy statistics, because the error does not have to arise from random chance. Problems with assumptions, bad guesses, even math errors will equally get you cursed. If anything, I would expect causes that lack empirical experimental data to be more cursed, not less.
It’s also not necessarily a problem with excessive quantification: If you switch your metric from “calculated DALY’s” to “my gut feeling”, you are actually introducing a new way in which your final ranking could be badly wrong, which would make the curse worse, not better.
As I demonstrate, Bayesian methods do help, and in a perfect toy model world they can correct for the curse perfectly. But in practice, this correction seems incredibly difficult to do accurately. There’s kind of a trap here: the optimisers curse says we should be more wary of interventions when their evidence is more uncertain and easier to mess up. But then if we correct for the curse, we introduce more sources of errors, which could actually make things worse.
I think there is a ton more to explore on this topic, and I hope that more people will explore the implications of the curse in different domains. I will have more to say as well in the future.
Note that it was a little unclear as to whether this was meant to be the spread of the errors or the spread of the final estimates. Using the spread of errors is what worked in my actual simulations.
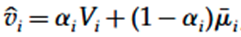




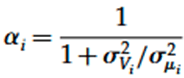
I was going to link to the 2011 GiveWell blog post by Holden Karnofsky arguing against taking EV estimates literally, but I see Alex Berger has already mentioned it above. I'd call out these passages in particular to save folks the effort of clicking through:
Holden later presented the underlying thinking more systematically in the 2014 GiveWell post sequence thinking vs cluster thinking:
While the post is over a decade old it still seems foundational to how GiveWell think about their CEAs:
I think of cluster thinking-based intervention ranking as better than the sequence thinking-plus-bayesian correction approach you explored above to account for the optimiser's curse for these reasons, especially the observation that successful prediction systems across most domains use cluster not sequence thinking.
I find this "observation" confusing / misleading, given that Holden defines cluster thinking as aggregating decisions from multiple perspectives. This is very different from aggregating the predictions of multiple models. The evidence of "success" he cites only applies to the latter (where "success" is with respect to Brier scores and such), not the former.
And this is practically relevant: If you aggregate multiple models but then maximize EV under the aggregated model, you don't get the "sandboxing" property Holden claims cluster thinking satisfies. The fanatical/Pascalian model will still dominate the EV calculation.
(ETA: As an aside on sequence thinking / cluster thinking generally, I wish these discussions made it very clear whether we're taking ST/CT as (1) different normative standards for good epistemology / decision-making per se, vs. as (2) different procedures for satisfying a given epistemological / decision-theoretic standard. Cf. "criterion of rightness vs. decision procedure" in ethics. This would be helpful for clarifying what's meant by claims like "cluster thinking is how 'successful' prediction systems operate". I've been assuming (2), here, FWIW.)
Thanks for the intriguing pushback, part of why I kept bringing this up over the years was to surface this kind of counterargument, upvoted. Flagging for myself later to look into the evidence base behind
because I'd always assumed it was "obviously" the former (wrongly it seems), since the latter seemed non-robust in the sense Dan Luu looked into (cf. "you really have to understand things", which multi-model aggregations are not).
I've also assumed (2) FWIW.