Claude 3.7's coding ability forced me to reanalyze whether where will be a SWE job for me after college. This has forced me to re-explore AI safety and its arguments, and I have been re-radicalized towards the safety movement.
What I can’t understand, though, is how contradictory so much of Effective Altruism (EA) feels. It hurts my head, and I want to explore my thoughts in this post.
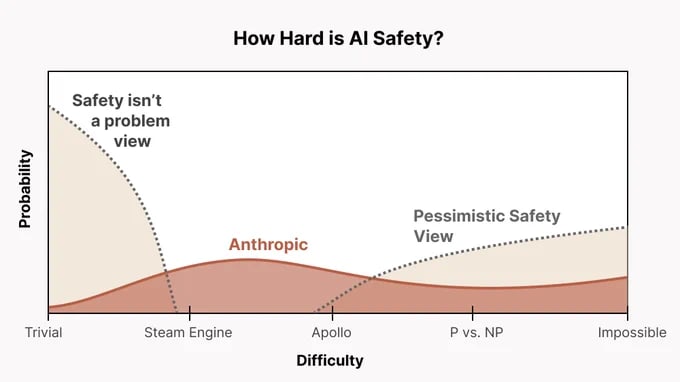
EA seems far too friendly toward AGI labs and feels completely uncalibrated to the actual existential risk (from an EA perspective) and the probability of catastrophe from AGI (p(doom)). Why aren’t we publicly shaming AI researchers every day? Are we too unwilling to be negative in our pursuit of reducing the chance of doom? Why are we friendly with Anthropic? Anthropic actively accelerates the frontier, currently holds the best coding model, and explicitly aims to build AGI—yet somehow, EAs rally behind them? I’m sure almost everyone agrees that Anthropic could contribute to existential risk, so why do they get a pass? Do we think their AGI is less likely to kill everyone than that of other companies? If so, is this just another utilitarian calculus that we accept even if some worlds lead to EA engineers causing doom themselves? What is going on...
I suspect that many in the AI safety community avoid adopting the "AI doomer" label. I also think that many AI safety advocates quietly hope to one day work at Anthropic or other labs and will not publicly denounce a future employer.
Another possibility is that Open Philanthropy (OP) plays a role. Their former CEO now works at Anthropic, and they have personal ties to its co-founder. Given that most of the AI safety community is funded by OP, could there be financial incentives pushing the field more toward research than anti AI-lab advocacy? This is just a suspicion, and I don’t have high confidence in it, but I’m looking for opinions.
Spending time in the EA community does not calibrate me to the urgency of AI doomerism or the necessary actions that should follow. Watching For Humanity’s AI Risk Special documentary made me feel far more emotionally in tune with p(doom) and AGI timelines than engaging with EA spaces ever has. EA feels business as usual when it absolutely should not. More than 700 people attended EAG, most of whom accept X-risk arguments, yet AI protests in San Francisco still draw fewer than 50 people. I bet most of them aren’t even EAs.
What are we doing?
I’m looking for discussion. Please let me know what you think.
I'm not sure I fully understand this criticism. From a moral subjectivist perspective, all moral decisions are ultimately based on what individuals personally deem acceptable. If you're suggesting that there is an objective moral standard—something external to individual preferences—that we are obligated to follow, then I would understand your point.
That said, I’m personally skeptical that such an objective morality exists. And even if it did, I don’t see why I should necessarily follow it if I could instead act according to my own moral preferences—especially if I find my own preferences to be more humane and sensible than the objective morality.
I see why a deontologist might find accelerating AI troublesome, especially given their emphasis on act-omission asymmetry—the idea that actively causing harm is worse than merely allowing harm to happen. However, I don’t personally find that distinction very compelling, especially in this context.
I'm also not a deontologist: I approach these questions from a consequentialist perspective. My personal ethics can be described as a mix of personal attachments and broader utilitarian concerns. In other words, I both care about people who currently exist, and more generally about all morally relevant beings. So while I understand why this argument might resonate with others, it doesn’t carry much weight for me.