Inconsistency doesn't lead to favouring income doublings for the rich; it just leads to inconsistency
The post gives the impression that inconsistent choices of η systematically favor income doublings for rich people compared to poor people. This isn't true.
Consider three people, A, B, and C, with respective incomes of 5, 10, and 10 USD. Suppose we compare doubling the income of A twice (from 5 -> 10 and 10 -> 20) to doubling the incomes of both B and C (10 -> 20 each). The income doubling from 5 -> 10 for A has the same value as doubling the income from 10 -> 20 for B because we use log-utility across people. Doubling A's income from 10 -> 20 is less valuable than doubling it from 5 -> 10 because we use η > 1 for each individual. Since the other three income doublings are all worth the same (A: 5 -> 10, B and C: 10 -> 20), we prefer doubling the incomes of both B and C compared to doubling A’s income twice. Now, since the income doubling for A from 10 -> 20 has the same value as that for B from 10 -> 20, it must be that we prefer doubling C’s income from 10 -> 20 over doubling A’s income from 5 -> 10. But that means we prefer doubling the richer person’s income.
Imagine that instead of doubling A's income twice, we considered doubling C's income twice.
U(2x C's income from 10 to 20) = U(2x B's income) = U(2x A's income) with η=1. And U(2x C's income from 10 to 20) > U(2x C's income from 20 to 40) with η>1. So U(2x C's income from 10 to 20) + U(2x C's income from 20 to 40) < U(2x B's income) + U(2x A's income). Since income doublings are worth the same across people, we get U(2x C's income from 20 to 40) < U(2x A's income).
So with the exact same example, we have concluded both that doubling A's income is worth more than doubling C's income, and that doubling C's income is worth more than doubling A's income. This is a pure logical inconsistency. It is not the case that the richer person's income doubling is generically valued higher than the poorer person's income doubling.
Likewise with the second example:
Say that, for example, doubling the income of the average earner in a country is worth the same across countries. Now, doubling the mean income in the US (~$50k) is worth the same as doubling the income of the average earner in Madagascar (~$500). However, within Madagascar, doubling the income of a richer person is worth less than doubling the income of a poorer person, so doubling the income of a person making $1000 is worth less than doubling the income of a person making $500. Since doubling the income of a person making $500 in Madagascar was worth the same as doubling the income of a person making $50k in the US, we have that doubling the income of a person making $1000 (in Madagascar) is worth less than doubling the income of a person making $50k (in the US). So we are again preferring doubling the income of a richer person relative to a poorer person.
Within the US, doubling the income of a $50k earner is worth more than doubling the income of a $100k earner. Across the US and Madagascar, doubling the income of a $500 earner in Madagascar is worth the same as doubling the income of a $50k earner in the US. Putting these two together, doubling the income of the $500 earner in Madagascar is worth more than doubling the income of the $100k earner in the US. So in this example, the inconsistency also favors doubling the income of the poorer person.
Now, this doesn't contradict the title of the post. I agree that pure logical inconsistencies in the way that we compare interventions are undesirable. But I don't want people to come away from this post with the conclusion that this inconsistency systematically favors interventions for rich people over interventions for poor people.
This inconsistency is not analogous to a rate of pure time preference
I'm puzzled at the argument for why inconsistent η implies a rate of pure time preference.
The CEA roughly assumes that each treated person experiences the same persistent % consumption increases each year over the course of their life. These income benefits are discounted by our default rate, so that an income doubling today is worth 3x as much as the same income doubling in 48 years solely because recipients will be about 4 times as rich. At the same time, current-year income doublings in Madagascar ($500 GDP/capita) and Côte d’Ivoire ($2.5k GDP/capita) are valued the same[7]. This leads to the following weird conclusion:
In Madagascar, we value the income doubling of someone who makes $500 about 3x as much as the income doubling of someone who makes $2.5k.
However, if the person who makes $2.5k lives instead in Côte d’Ivoire, we value their income doubling the same as doubling the income of the $500 earner in Madagascar.
Put another way, the CEA implies a 2.6% annual discount rate for pure time preference: even if the income % increases are as certain to occur in 48 years as they are now, we value an income doubling 3x more today.
I don't think I follow this argument. There's no time dimension in the Madagascar-Cote d'Ivoire example, so I don't understand how it tells us anything about the rate of pure time preference. Moreover, in the general CEA, the discount rate contains three factors: pure time preference, uncertainty, and diminishing marginal utility of consumption. Your example eliminates uncertainty, shows that there's still a large discount rate, and then concludes that that must reflect pure time preference. But it actually reflects the diminishing marginal utility of consumption, which you also note at the start. So then how does this imply a discount rate for pure time preference?
Choices of eta are probably back-filled from moral weights on health vs income
In practice, grantmaking by GiveWell/FP/AIM is quite heavily loaded onto health-generating interventions rather than income-generating interventions. But the moral weights on health vs income depend in large part on the marginal utility of consumption. Higher values of η, combined with low income levels for recipients, would make income-generating interventions much more attractive than health-generating interventions, and shift your portfolio substantially towards income-generating interventions.
This is an econpilled view that I'm quite comfortable with. But for most people, intuitions about the moral value of health vs income precede intuitions about the right value of η, so η values are back-filled to be consistent with those intuitions. I think this is the true reason for the inconsistency you point out. η=1 is the value that people are most comfortable back-filling to match their moral intuitions about health vs income, and is very convenient for not having to measure income levels. η>1 is more realistic, but is admissible with these moral intuitions only when comparing income gains to income gains (within a program).
Now, that's not to say that η>1 is necessarily better. I think it's more likely to be true but was convinced by Alexander Berger's counter-argument that it provides worse prescriptions than η=1.
But regardless, it would be a mistake to think about η choices primarily through the lens of how they affect comparisons of livelihood interventions, because any shift from η=1 would substantially affect income vs health moral weights, and most of its effect on your portfolio would go through that channel.
(Caveats: I am working at GiveWell, but views are my own and don't represent any larger position)
Thank you for engaging in detail with the post—these are all great points, much appreciated! I’m replying to each one below.
1) “Inconsistency doesn't lead to favouring income doublings for the rich; it just leads to inconsistency”
I agree with your argument that we can also conclude that doubling the incomes of poorer people is more valuable than doubling the incomes of richer people. I meant to make the point in the post that this inconsistency can lead us, strangely, to conclude that doubling the incomes of richer people is more valuable than doubling the incomes of poorer people—not that it always does. To make that point clearer and not give the impression that we systematically favour income doublings for the rich, I’ve edited the post to say things like “can lead us to prefer …” instead of “leads us to prefer …”, and referenced your argument in the appendix.
Substantively, I would draw a somewhat stronger conclusion than you: not only that inconsistency “leads to inconsistency” but that it "sometimes leads us to favour income doublings for the rich”.
That is because, in practice, there are situations where the inconsistency will lead us to that conclusion. Take, for example, deworming in Madagascar (~$500 GDP/capita) vs cash transfers in Kenya (~$2k GDP/capita). For simplicity, assume deworming generates income benefits in year 1 and 2 while cash transfers only generate them in year 1. In our CEAs, we assign the same value for income doublings in year 1 of an intervention. Because we set the comparison point there, we value doubling the income of the $500 and $2k earners the same, but value the income doubling of the $502 earner in Madagascar in year 2 less than for the $2000 earner in Kenya.
2) “This inconsistency is not analogous to a rate of pure time preference”. Thank you for pointing out that this wasn't clear. I meant it to be an implication of assuming both η=1 and η>1 and applying η=1 in the example: “even if the income % increases are as certain to occur in 48 years as they are now, we value an income doubling 3x more today.” If those two income doublings are worth the same, the discount rate reflects only pure time preference. To clarify this, I’ve changed that sentence to say “Put another way, if we consistently apply the income doublings framework (log-utility), the CEA implies a 2.6% annual discount rate of pure time preference.” (changes italicised)
3)“Choices of eta are probably back-filled from moral weights on health vs income”. That’s an important consideration. We want to make sure any change we make to η is also consistent with our moral intuitions about health vs income benefits. One key question seems to be how health benefits vs income doublings trade off at different absolute levels of income? E.g., does the rate at which they trade off stay the same? Do we think health benefits are equally valuable at different income levels but income doublings are worth less at higher income levels? I'd be curious about what your intuitions are here.
On this point in particular:
Higher values of η, combined with low income levels for recipients, would make income-generating interventions much more attractive than health-generating interventions, and shift your portfolio substantially towards income-generating interventions.
I'm not sure this is necessarily true? It seems like higher values of η would primarily increase the slope of the marginal rate of substitution between health benefits and income doublings, as a function of absolute income levels. (We prefer health benefits more strongly at higher vs lower levels of income). Whether this shifts our portfolio more towards health- or income-generating interventions depends on our choice of income level at which we believe income doublings and health benefits should trade off as they currently do.
That is because, in practice, there are situations where the inconsistency will lead us to that conclusion. Take, for example, deworming in Madagascar (~$500 GDP/capita) vs cash transfers in Kenya (~$2k GDP/capita). For simplicity, assume deworming generates income benefits in year 1 and 2 while cash transfers only generate them in year 1. In our CEAs, we assign the same value for income doublings in year 1 of an intervention. Because we set the comparison point there, we value doubling the income of the $500 and $2k earners the same, but value the income doubling of the $502 earner in Madagascar in year 2 less than for the $2000 earner in Kenya.
I don't think it makes sense to frame this as valuing rich people over poor people. What's happening in this example is favoring benefits in year 1 over benefits in year 2, regardless of a person's income. This is definitely a nitpick, but I think many people's intuitions about time discounting precede intuitions about rich vs poor people's income doublings, so it's more clarifying to frame it that way.
Put another way, if we consistently apply the income doublings framework (log-utility), the CEA implies a 2.6% annual discount rate of pure time preference.
An equivalent way to frame this would be "we use a log utility framework because of <benefits>, but we recognize that it overestimates the value of income growth at higher levels of income, so we will fix that by discounting future income in a way that would be consistent with η>1."
In other words, the inconsistency is just a practical way to reconcile two frameworks with different pros and cons, rather than an endorsement of the ethical position of pure time preference. Now, ad hoc approaches like that could rub you the wrong way, but I would put that in the general category of "this is bad because it's arbitrary", and not "this is bad because it implies a rate of pure time preference, which has repugnant ethical conclusions".
I'm not sure this is necessarily true? It seems like higher values of η would primarily increase the slope of the marginal rate of substitution between health benefits and income doublings, as a function of absolute income levels. (We prefer health benefits more strongly at higher vs lower levels of income). Whether this shifts our portfolio more towards health- or income-generating interventions depends on our choice of income level at which we believe income doublings and health benefits should trade off as they currently do.
Yeah, I thought this through more and I skipped a few steps + stated some incorrect things.
The first step is to note that higher values of η decrease the value of saving poor people's lives compared to rich people's lives. In the basic isoelastic utility framework, the value of saving a year of life is[1]VSLY=u(c)u′(c)=cη−cη−1 which means it is higher for rich people than for poor people. Now, this is also true for log utility, but notice that the gap between rich and poor VSLYs is increasing in η, meaning that higher values of η make it even less attractive to save a poor person's life than a rich person's life. This is a conclusion that nobody likes.
The second step is to note that the only way I know of to modify the isoelastic utility model to avoid that conclusion, is to add a set point to utility, so that u(c)=k+c1−η−11−η Then for a high enough set point, the VSLY will vary much more slowly with income, and rich and poor lives will be closer together in value. However, this is where the health vs income tradeoff comes in. If you have a high enough set point, income-creating interventions become unattractive compared to health-creating interventions, because most of a person's utility comes from their set point, not from being rich or poor, so there's little value to increasing their income a lot. So I was wrong to say that high η would make income-generating interventions more attractive. [Edit: also worth noting that high set points would be incompatible with low VSL estimates in poor countries]
But the basic point is, the standard isoelastic utility model doesn't create much implication for health vs income, but it creates a repugnant conclusion about valuing rich vs poor lives. A modified isoelastic utility model that fixes that problem will have sharp implications for trading off health vs income.
intuition: the value of being alive for a year is the utility experienced by a year of consumption at level c, aka u(c). But u(c) is in utils, not dollars, so we divide it by the marginal utility of money u′(c) to represent the value of life in dollars. ↩︎
Thank you, Karthik! I’ll respond briefly to one point about the inconsistency sometimes leading us to value doubling the incomes of richer people more relative to poorer people. The rest of my comment is on the health vs income benefits discussion, which I’ve found very interesting.
On sometimes preferring to double rich people's incomes
I don't think it makes sense to frame this as valuing rich people over poor people. What's happening in this example is favoring benefits in year 1 over benefits in year 2, regardless of a person's income. This is definitely a nitpick, but I think many people's intuitions about time discounting precede intuitions about rich vs poor people's income doublings, so it's more clarifying to frame it that way.
I see where you’re coming from since we use η>1 only in our time discounting. Here is the opposite view for why the rich vs poor framing might be more natural:
Recall that the only reason we favour benefits in year 1 over year 2 is that recipients are richer in year 2 (assuming there is no uncertainty about the benefits in year 2). Put another way, if we thought recipients had the same income in year 2 as in year 1, we would not prefer the year 1 benefits. We might in our CEAs think about this as time discounting. But really it is discounting richer people’s income doublings, which is then reflected in our time discount rate only because we assume consumption grows at 3% each year absent any intervention.Because we discount richer people’s income benefits less across interventions than we do within an intervention over time, we have situations like these where we value richer people’s income doublings more.
On health vs income
It’s important to draw out the implications of the choice of η on the health vs income benefits comparison. With the caveat that I’ve not spent much time looking into previous VSLY discussions, I’m not sure the impact of higher η is as clear-cut. Specifically, I’m thinking
The conclusions in your comment rely on the specific VSLY utility model u(c)u′(c)
Empirical evidence suggests that model might not reflect individuals’ preferences
If we base the analysis on those preferences instead, higher η can imply a higher value of a mortality reduction intervention at lower income levels (i.e., the opposite conclusion)
Both VSLY utility models don’t seem to align with people’s reported VSL preferences with regards to the mortality risk vs income gain tradeoff.
Model 1 (isoelastic utility): Take η=1 and assume that the elasticity of VSL with regards to income is 1 (i.e., people are indifferent between the same multiple of their income and an extra life-year, regardless of absolute income level). Since an income doubling has the same moral weight regardless of income level, so has an extra life-year. However, model 1 values an extra life-year at c∗ln(c), which is increasing in c.
Even if we think the elasticity is 1.3 instead of 1 (the upper bound of what Open Philanthropy considers reasonable), the model doesn’t fit well. Take this hypothetical example: if a $1000 earner is indifferent between $1000 and an extra year of life, a person making $2000 would be indifferent at $2300, and so VSLY should increase by a factor of 1.3, too. However, c∗ln(c) equals 6,907 at c=1000 and 15,201 at c=2000, which is not a 30% but a 220% increase. As you pointed out, η>1 only leads to preferring health interventions for rich vs poor people even more.
Model 2 (isoelastic utility with set point k): The same is true for model 2. Take, for example, η=1. Then, VSLY=c∗(k+ln(c)) (or, for η>1, kcη+cη−cη−1). Both are increasing in c, while VSL revealed/stated preferences imply it should be roughly constant or even decreasing (see next point). (This is the same reasoning as for model 1, keeping in mind that k drops out in the value of income doublings, which is unchanged: u(2c)−u(c)=(k+ln(2c))−(k+ln(c)))=ln(2))
Since the models don’t reflect individuals’ preferences, I'd be hesitant to use them to make normative claims about how to morally value mortality reduction interventions at different income levels.
When we don’t impose the VSLY=u(c)u′(c) model but work up from individuals’ preferences, higher η might lead to valuing mortality reduction interventions at lower income levels more (i.e., the opposite conclusion):
Take again the purely utilitarian view that we should value utility increases the same irrespective of the beneficiary. Then, note that there is some fixed number x of income doublings such that people are indifferent between them and an extra year of life, regardless of income level (assuming the VSL-income elasticity is 1). That means that people gain as much utility from an extra year of life as from x income doublings.
Let η=1. Income doublings have the same moral value regardless of income level, so the same is true for extra life-years.
Now consider instead η>1. The income doubling generates less utility at higher income levels than at lower income levels. However, at higher income levels, people are still indifferent between the same x income doublings and an extra life-year. That would imply that the utility (and therefore the moral value) from an extra year of life is lower at higher income levels.
Since in that framework, we value mortality-reduction and income interventions more at lower income levels, my expectation is that higher η would lead us to prioritising lower-income beneficiaries more than we currently do.
You're pointing out that the value of life shouldn't depend on consumption u(c). But even if you assumed there was a fixed utility from saving lives, the VSLY would still be different across populations, and all of the conclusions I talked about would still hold. The reason is because of the monetization of utility. The VSLY is grounded in how an individual would trade off health vs income, and that tradeoff depends on their marginal utility of income u′(c).
Assume there was a fixed utility from someone being alive for a year, ¯u. Then their willingness to pay for an extra year of life is ¯u/u′(c). This varies less with income than if the value of life was u(c), but it still varies with income. Poor people are willing to spend less (in absolute terms) on health than rich people are, because their competing needs are higher than rich people's competing needs.
If this is the case, then all of our discussion of η still goes through. For an isoelastic utility function, the VSLY is ¯u⋅cη, which increases in income, and increases exponentially in η. The replacement of u(c) with ¯u changes nothing qualitatively; higher η still leads to higher VSLYs even when everyone enjoys a year of life equally. That then causes health interventions for the rich to dominate health interventions for the poor.
The reason why this matters is because it renders the following statement problematic:
Take again the purely utilitarian view that we should value utility increases the same irrespective of the beneficiary. Then, note that there is some fixed number x
of income doublings such that people are indifferent between them and an extra year of life, regardless of income level (assuming the VSL-income elasticity is 1).
Assuming the VSL-income elasticity is 1 is equivalent to assuming η=1, since you have to assume that income doublings are worth the same to people regardless of their income levels. So I don't really understand how that assumption helps you draw conclusions about what would happen if η>1. If η>1, then even if the value of life was common to everyone, the VSL-income elasticity would be greater than 1. Basically, the marginal utility of income doublings declines, but the marginal value of life does not, so the VSL has to grow faster than income.
Now, the key assumption is that we monetize VSLs using individual willingness-to-pay. Maybe you think social willingness-to-pay should be determined by the marginal utility of money to the social planner, which is common across people, rather than by the WTP of individuals who vary in their income levels. This is a defensible normative position. I would just note that the marginal utility of money from a donor's perspective is the value you could otherwise get by spending that money. For us, that benchmark use of money is GiveDirectly cash transfers. If you think that way, you will end up with a marginal utility of money that is close to a poor person's marginal utility of money, so the original framework is still representative of how valuable health interventions are among poor people.
Both VSLY utility models don’t seem to align with people’s reported VSL preferences with regards to the mortality risk vs income gain tradeoff.
I think it fits fine? Under the log utility model with no set point, WTP for an extra year of life is cln(c). Normalize this by income levels c to get the VSLY-income ratio as ln(c). Eyeballing the graph from OP's collection of VSL estimates, they look vaguely consistent with a logarithmic relationship between the VSLY-income ratio and income. Or take the general isoelastic utility model, where WTP for an extra year of life is $\frac{c^{\eta}-c}{\eta-1}, so the VSLY-income ratio is 1η−1⋅cη−1−1η−1. This is a general sub-linear function of c for η>1, and you could probably fit a value of η to match the estimates best. Robinson et al (2019) take this elasticity approach and find a roughly log-linear relationship between VSLY-income ratio and income.
Now, these studies can't statistically reject a flat VSLY-income ratio across countries, so you would be on fair ground to assume a constant VSLY-income ratio. But it's definitely not right to say that the isoelastic utility model doesn't fit the data on VSLs across countries.
Got it—I think I might have had an errant c term where I was thinking about fit. Point taken that you can model a non-constant VSLY-income ratio with isoelastic utility.
What do you find to be the strongest reason to use VSLY's to value lives saved at different income levels? My intuitive approach would have been to use the value of utility from one year of consumption directly, not divided by people's marginal utility of consumption (i.e., u(c) instead of u(c)u′(c)). We would then value extra life-years only based on the utility received during that year. In the constant utility case, for example, we'd place the same value on an additional life-year regardless of income level.
Isn't comparing interventions by the utility they create (rather than how that utility is monetised) what we want to do? Analogously, we currently think individuals value income doublings the same at all income levels. We wouldn't then conclude that the fact that a $1,000 earner has a $1000 WTP for an income doubling while the $2,000 earner has a WTP of $2,000 means we should value the income doubling for the richer person twice as much. But it seems like that's what the VSLY approach is doing, if I'm not misunderstanding it?
What do you find to be the strongest reason to use VSLY's to value lives saved at different income levels? My intuitive approach would have been to use the value of utility from one year of consumption directly, not divided by people's marginal utility of consumption (i.e., u(c) instead of u(c)u′(c)). We would then value extra life-years only based on the utility received during that year. In the constant utility case, for example, we'd place the same value on an additional life-year regardless of income level.
"Value" is a slippery term here. You're referring to utility value, but when we calculate cost-effectiveness, we have to place a monetary value on the outcome, because
Utility functions are not normalized to scale – we could multiply utility functions by 1000 and nothing would change, even though the utility numbers would increase by 1000x. So already "utility" is not a meaningful concept to put into cost-effectiveness calculations.
We anyways have to compare health interventions and income interventions, which requires having some willingness-to-pay for the utility purchased by a health intervention. "We are willing to pay $X to extend life by one year" – that X has to come from some framework. Whether you call it a VSLY, or a moral weight, or a willingness-to-pay, it comes from somewhere.
The choice of VSLY as a source of moral weight comes from the premise that when comparing interventions that increase health or increase income among poor people, we should make the tradeoff in the same way that they would, rather than imposing our own preferences of how to make that tradeoff. The reason why VSLYs satisfy that is because they are either estimated from revealed-preference decisions of the relevant populations, or from the stated preferences of the relevant populations. (If they were just dictated from on high, they would not be good moral grounding!) Specifically, in a neoclassical framework where people can pay for health improvements, their willingness to pay is exactly the marginal utility of a health improvement, divided by the marginal utility of income u′(c). That's why we divide by u′(c).
Of course, that leads to indeterminacy when comparing interventions between two populations with different c and thus different VSLYs. So when organizations have a single consistent moral weight on health vs income, they are implicitly treating the VSLY as common between all populations. That basically implements what you're saying (have a common valuation for years of life across countries). But it doesn't resolve our earlier discussion, since if you grounded your moral weight on lives saved in a VSLY, and you adopted a new η, you would get a new moral weight on lives saved, which would be the first-order determinant of how η affects grantmaking.
I appreciate the back and forth discussion here, thank you! I agree with most/all of your comment. But: is it not true that your earlier statement
The first step is to note that higher values of η decrease the value of saving poor people's lives compared to rich people's lives.
relies on using VSLY=u(c)u′(c) values directly to compare the value of health across different levels of c (which I don't think we should do)?
The following approach is consistent with your last comment (using VSLY for health vs income tradeoffs at any given c) but would lead us to place a higher value on health at lower vs higher income levels (instead of the other way around, which would be the conclusion no one likes).
Ground your moral weights for income doublings across different levels of c in the ratio of utility from income doublings at different levels of c. (This is invariant to positive affine transformations of u(⋅) by the way.[1])
At each level of c, get the moral weight of health from people's revealed preferences for health vs income doubling tradeoffs, applied to the moral weight for income doublings at that level of c, which we have from (1). Suppose these tradeoffs are constant in the sense that people are indifferent between e.g., 1 income doubling and 1 extra life-year at all levels of c).
Increase η. Now, at some high c, income doublings get less moral weight than before. Since people's revealed health vs income doubling tradeoffs are unchanged, there is less moral weight on health at higher income levels.
I don't understand using η and the revealed preferences independently of each other. η only makes sense if it is consistent with the revealed preferences that people place on health vs income. If revealed preferences show that people have a constant valuation of income doublings vs life, then that is only consistent with η=1, and I see no justification for using η>1. How would you justify it?
My earlier statement did not rely explicitly on the VSLY being u(c)/u′(c). However, what it does rely on is the VSLY-income ratio being increasing in c. If we assume the value of health is constant ¯u and that η=1, then the VSLY is ¯u⋅c so the VSLY-income ratio is constant. I'm down to assume the value of health is constant, and I don't feel strongly about η even though I think it's probably >1. But my loose reading of the VSLY-income literature is that the ratio is increasing in c.
I don't understand using η and the revealed preferences independently of each other. η only makes sense if it is consistent with the revealed preferences that people place on health vs income. If revealed preferences show that people have a constant valuation of income doublings vs life, then that is only consistent with η=1, and I see no justification for using η>1. How would you justify it?
Maybe this is where our two approaches differ:
We have three types of valuations.
Health benefits across different levels of c
Income benefits across different levels of c
Health vs income benefits at each level of c
My approach is to estimate η from data on people's choices regarding (2) (e.g., p. 7 here). Then get the health vs income moral weights from revealed preferences on (3) (e.g., VSLY data). Then combine the two to get (1).
What I think you're saying is (correct me if I'm wrong) that (3) also gives us data on η, because individuals value extra life-years proportional to the consumption in that year. (By assuming that empirical VSLY estimates are described by u(c)u′(c), this gives us info on η by choosing the η that makes u(c)u′(c) best fit the VSLY revealed preferences.) Based on that, it then is inconsistent to have a different η from (2) than is implied by (3), and we want to reconcile them.
Does that sound right? If so, my view would be that valuing an extra life year according to u(c)u′(c) for some η is a functional form assumption on how people value an extra life-year. In some way, I see the data on η from (2) as a test of that assumption. Whereas in your view, which I think is also reasonable, the assumption and data on (3) is a test/verification of our estimate of η from (2).
My earlier statement did not rely explicitly on the VSLY being u(c)/u′(c). However, what it does rely on is the VSLY-income ratio being increasing in c. If we assume the value of health is constant ¯u and that η=1, then the VSLY is ¯u⋅c so the VSLY-income ratio is constant. I'm down to assume the value of health is constant, and I don't feel strongly about η even though I think it's probably >1. But my loose reading of the VSLY-income literature is that the ratio is increasing in c.
If you don't think that we know about η from (3), for example because you don't believe the assumption, higher η can imply higher valuation of health at lower incomes even if the VSLY-income ratio is increasing in c. Here is a hypothetical example. Suppose the elasticity is 1.2 so that a $1,000 earner is indifferent between 1 income doubling and an extra life-year, while a $2,000 earner is indifferent between 1.1 income doubling and an extra life-year. That means that at η=1, the value placed on health for the $2,000 earner is higher than for the $1,000 earner. Increase η and normalise the moral weights on income doublings so that an income doubling for the $1,000 earner has the same value as before. Higher η means the income doubling at $2,000 is now less valuable. Since the VSLY revealed preferences are unchanged, the moral weight on health at higher incomes is now lower relative to the weight on health at lower incomes, compared to before.
Yup, that's an accurate summary of my beliefs (with the caveat that u(c) is non-critical and can be replaced with a constant or whatever else you want; only u′(c) is essential). Put another way, η is a single preference parameter that determines the marginal utility of income, and that affects how we value both income and health. I think any other assumption leads to internal inconsistency, or doesn't represent utility maximization.
Does that sound right? If so, my view would be that valuing an extra life year according to u(c)/u′(c) for some η is a functional form assumption on how people value an extra life-year. In some way, I see the data on η from (2) as a test of that assumption. Whereas in your view, which I think is also reasonable, the assumption and data on (3) is a test/verification of our estimate of η from (2).
What is an individual willing to pay for anything? Suppose buying a health good (e.g. air purifier) gives you utility k, and it costs p. Then for every dollar you spend, you are getting k/p utility. Is that optimal? It is optimal only if the marginal utility of spending a dollar on any other good is ≤k/p. If you could get >k/p utility from spending a dollar elsewhere, then you would optimally refuse to buy the air purifier and spend your money elsewhere. That's why u′(c) is always in the denominator; it represents the opportunity cost of money. If you didn't spend your money on a health good, you would spend it somewhere else. And the opportunity cost of money is obviously higher for poor people (trading off daily food for an air purifier is a hell of a lot less appealing than trading off a Chanel bag for an air purifier). So that's why I don't think there can be any consistent model of utility maximization where the VSLY[1] doesn't depend on u′(c). Its dependence on u(c) is irrelevant and can be replaced with some constant k if you want, but I am reasonably sure that u′(c) can't be banished from the VSLY without rejecting individual utility maximization.
So I think the crux between us is whether you see your position as consistent with VSLYs being derived from individual utility maximization. If it is, then please help me understand, because that would be a major update for me. But if it's not, then I think we are at this point:
Now, the key assumption is that we monetize VSLs using individual willingness-to-pay. Maybe you think social willingness-to-pay should be determined by the marginal utility of money to the social planner, which is common across people, rather than by the WTP of individuals who vary in their income levels. This is a defensible normative position. I would just note that the marginal utility of money from a donor's perspective is the value you could otherwise get by spending that money. For us, that benchmark use of money is GiveDirectly cash transfers. If you think that way, you will end up with a marginal utility of money that is close to a poor person's marginal utility of money, so the original framework is still representative of how valuable health interventions are among poor people.
If you substitute "buying an air purifier" with "buying a year of life", then my argument goes from estimating "willingness to pay for an air purifier" to estimating "willingness to pay for an extra year of life". This is exactly what the VSLY represents, when it is estimated from individual revealed preferences.↩︎
Yup, that's an accurate summary of my beliefs (with the caveat that u(c) is non-critical and can be replaced with a constant or whatever else you want; only u′(c) is essential).
I think that assumption isn't sufficient to determine η from VSLY data. By not specifying the functional form for VSLYs, η will be underidentified in practice. Assuming only that the denominator of the VSLY term is u′(c) and that u(⋅) is isoelastic, we could, for example, have either of the following:
VSLYc=kcu′(c)=kcη−1
VSLYc=u(c)cu′(c)=cη−1−1η−1 or ln(c) if η=1
Now suppose you observe the VSLY/income data and think it's roughly ln(c). Would you conclude from this that η=1 and the right functional form is (2)? Or that η=1.2 and the right functional form is (1) with k=1.8? (Plot)
Does that sound right to you? If so, I think that puts us here:
If so, my view would be that valuing an extra life year according to u(c)u′(c) for some η is a functional form assumption on how people value an extra life-year. In some way, I see the data on η from (2) as a test of that assumption. Whereas in your view, which I think is also reasonable, the assumption and data on (3) is a test/verification of our estimate of η from (2).
______
One counterargument might be that for any of these functional forms, an increase in η will lead to higher valuations of health at higher incomes. However, I'm not sure that works in practice. I'd imagine it going something like this (assuming the only assumption we're willing to make ex-ante is that the VSLY denominator is u′(c)):
Estimate η from data on consumption valuations at different income levels
Choose VSLY functional form to fit the revealed preferences data given the η estimate from (1).
Revise our estimate in (1) upwards.
Since we're still trying to match the VSLY data given the η from 1: adjust the VSLY functional form. (Rather than increasing η in the previous form)
I'm agnostic on the right functional form for the VSLY, just as I'm agnostic on the right η. My point was just that you cannot have it be independent of u′(c).
You need to impose some structure to get an exact identification of η, but that should not be interpreted as meaning that we can be fully agnostic about how η affects valuations, the way you describe. So I don't think that puts us at the point you stated. Specifically, I think the framework you describe where the VSLY relative to income doublings is constant while you shift η is still inconsistent with utility maximization, and still not a valid way to interpret how η affects the value of health vs income.
This post has been sitting in my open tabs for 4 months and I am finally getting to it today.
Using η=1.87 would require us to start taking into account absolute income levels in our cost-effectiveness analyses.
I'm not entirely sure, but by my reading, the article is using this as an argument against η > 1. But I don't think it's really an argument. If η > 1 then indeed you should take into account absolute income levels, and I do in fact think you should do that. And yes that would change prioritization, and that's a good thing because the current prioritization is probably wrong—it doesn't assign enough weight to people with lower incomes.
You never actually say you're arguing against η=1.87, but the title implies it.
FWIW I am not convinced by the evidence on what value of η to use, different lines of evidence point in different directions. I lean toward η > 1, so I think it's reasonable to use η > 1 everywhere.
I think most people intuitively feel that income doublings matter more for poorer people, which requires η > 1.
η = 1 implies you can get arbitrarily high utility if you're sufficiently rich, which seems wrong. It seems more likely that income doublings provide diminishing returns—once you reach very high income levels (like $100M+), income doublings hardly matter at all. This makes sense when you look at the space of consumable goods: doubling your income increases the size of the set of things you can buy, but each doubling increases the set size by less than the previous doubling.[1]
The best literature review I've seen comes from Gordon Irlam. The only real conclusion is that different methods see huge variance in estimates of η.
One paper that I particularly like[2], A New Method of Estimating Risk Aversion, estimates η using labor elasticity and finds η = 0.71 (see Table 1). But if you look at the various data sources it uses, the estimates of η vary greatly depending on source so the η = 0.71 average hides a lot of underlying uncertainty.
I often see people cite life satisfaction data showing η = 1. The commonly-cited paper, Stevenson & Wolfers (2013), didn't perform any statistical tests for non-linearity on log-income vs. happiness. In Table 1, the paper did binary comparisons of the slope of log-income vs. happiness for rich vs. poor people and did not find clear differences, but it did find that the slope was generally steeper for rich people[3], which suggests η < 1 (I'm pretty sure on priors that η >= 1 so I don't know what's up with that result).
I briefly looked for more recent papers that test for non-linearity of log-income vs. happiness. I didn't find exactly that, but I did find Happiness, income satiation and turning points
around the world which finds that life satisfaction levels off at a certain income level. I didn't read carefully but it looks like this paper used a sketchy spline curve-fitting method that I don't trust (the fitted curves show that higher income decreases happiness above a certain point, which suggests that they're using the wrong kind of curve; see Fig 1 and Fig 2[4]). But the fact that their spline curves level off suggests that happiness increases sub-linearly with income.
I feel like there's room for a solid meta-analysis on income and life satisfaction, and I'm not satisfied with any of the existing literature.
In summary, the existing evidence is so high-variance that none of it meaningfully updates me away from my intuition that η must be greater than 1.
[1] This brings to mind a method for estimating η that I've never seen: Assume the prices of goods are Pareto-distributed and estimate the alpha parameter of the underlying Pareto distribution. Use that to estimate η (using this method).
[2] Even though I haven't actually read most of it lol. I just like the concept. Maybe it contains a bunch of math errors, I don't know.
[3] The paper did this comparison across a bunch of surveys. You'd need to do some kind of sophisticated non-standard significance test to determine if the overall difference is statistically significant, and the paper did not do that. (I think what you'd want to do is create a combined likelihood function that includes every survey and then get the p-value from the likelihood function. Or just skip the p-value and report the shape of the likelihood function because that's more informative anyway.)
[4] Perhaps this is a property of the data, not the curve-fitting method. The paper says "in [some comparisons], the SWB [subjective well-being] level at satiation was greater due to turning-point effects (Bayes factor < 1/3)." They say they present this data in the supplementary appendix, which isn't publicly available and isn't on Sci-Hub (AFAICT), so it seems I can't check.
Thanks for sharing! That's really interesting. Couple of thoughts:
(1) For us, CEARCH uses n=1 when modelling the value of income doublings, because we've tended to prioritize health interventions where the health benefits tend to swamp the economic benefits anyway (and we've tended to priortize health interventions because of the heuristic that the NCDs are a big and growing problem which policy can cheaply combat at scale, vs poverty which by the nature of economic growth is declining over time).
(2) The exception is when modelling the counterfactual value of government spending, which a successful policy advocacy intervention redirects, and has to be factored in, albeit at a discount to EA spending, and while taking into account country wealth (https://docs.google.com/spreadsheets/d/1io-4XboFR4BkrKXgfmZHQrlg8MA4Yo_WLZ7Hp6I9Av4/edit?gid=0#gid=0).
There, the modelling is more precise, and we use n=1.26 as a baseline estimate, per Layard, Mayraz and Nickell's review of a couple of SWB surveys (https://www.sciencedirect.com/science/article/abs/pii/S0047272708000248). Would be interested in hearing how your team arrived at n=1.87 - I presume this is a transformation of an initial n=1 based on your temporal discounts?
Nicolaj correct me if I'm wrong – I think it's derived here in the OP:
(Quantitatively it would be captured by η=1.87 when combined with the improving circumstances component. That comes from solving the last equation in Rethink Priorities’ 2023 report for η given r=0.026 and g=0.03—i.e., assuming that the compounding non-monetary benefits factor also reflects diminishing marginal utility from income doublings. As a result I'm assuming the discount rate reflects η=1.87 for the remainder of the post.)
That last equation on pg 48 is 𝑟_𝐺𝑖𝑣𝑒𝑊𝑒𝑙𝑙 = (1 + δ)(1 + 𝑔)^(η−1) − 1. δ is the pure time preference rate, for which GiveWell's choice is δ = 0%; pg 30 in the RP report above summarizes the reasoning behind this choice.
Thank you for outlining what you're doing at CEARCH—I appreciate it. I've put the Layard, Mayraz, and Nickell review on our list of sources to look at as we investigate the right choice of η more. As for where η=1.87 comes from, I saw that Mo already answered that question (thank you!). Let me know if something is still unclear.
Executive summary: Founders Pledge uses inconsistent assumptions about diminishing marginal utility of income in their cost-effectiveness analyses, which leads to counterintuitive valuations and may significantly impact charity prioritization.
Key points:
Current framework uses different utility functions for comparing interventions (η=1) vs. comparing benefits over time (η≥1.59).
This inconsistency can lead to valuing income doublings for richer people more than for poorer people in some cases.
Adopting a consistent η value would substantially impact charity prioritization (e.g. doubling cost-effectiveness of some interventions).
Options are to use η=1.87 everywhere (requiring accounting for absolute income levels) or η=1 everywhere (reducing discount rate to 1.4%).
Further research and input is needed to determine the most appropriate η value to use consistently.
The "compounding non-monetary benefits" factor in the discount rate likely reflects diminishing marginal utility, but this is uncertain.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
We should value income doublings equally across time and place (Founders Pledge)
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
Hi! I’m Nico and I’m on the research team at Founders Pledge. We noticed that the way we compare current to future income benefits is in tension with how we compare income benefits across interventions. However, aligning these two comparisons—choosing the same function for utility from consumption for both—might lead to large changes in our CEAs. So, we are now thinking about how to choose the right approach. Since our framework is based on GiveWell’s, which is used by other organisations, too, I expect that we’re facing the same issues. I’m posting here as a way of thinking out loud and with the hope of getting input from others.
Summary
Founders Pledge and GiveWell both use different values of η (elasticity of marginal utility from consumption) when modelling isoelastic utility from consumption depending on the context. Across interventions, we assume η=1. Over time within an intervention, we assume η≥1.59. We should choose the same η for both models as having different η values can lead us to prefer doubling the incomes of richer people relative to poorer people.
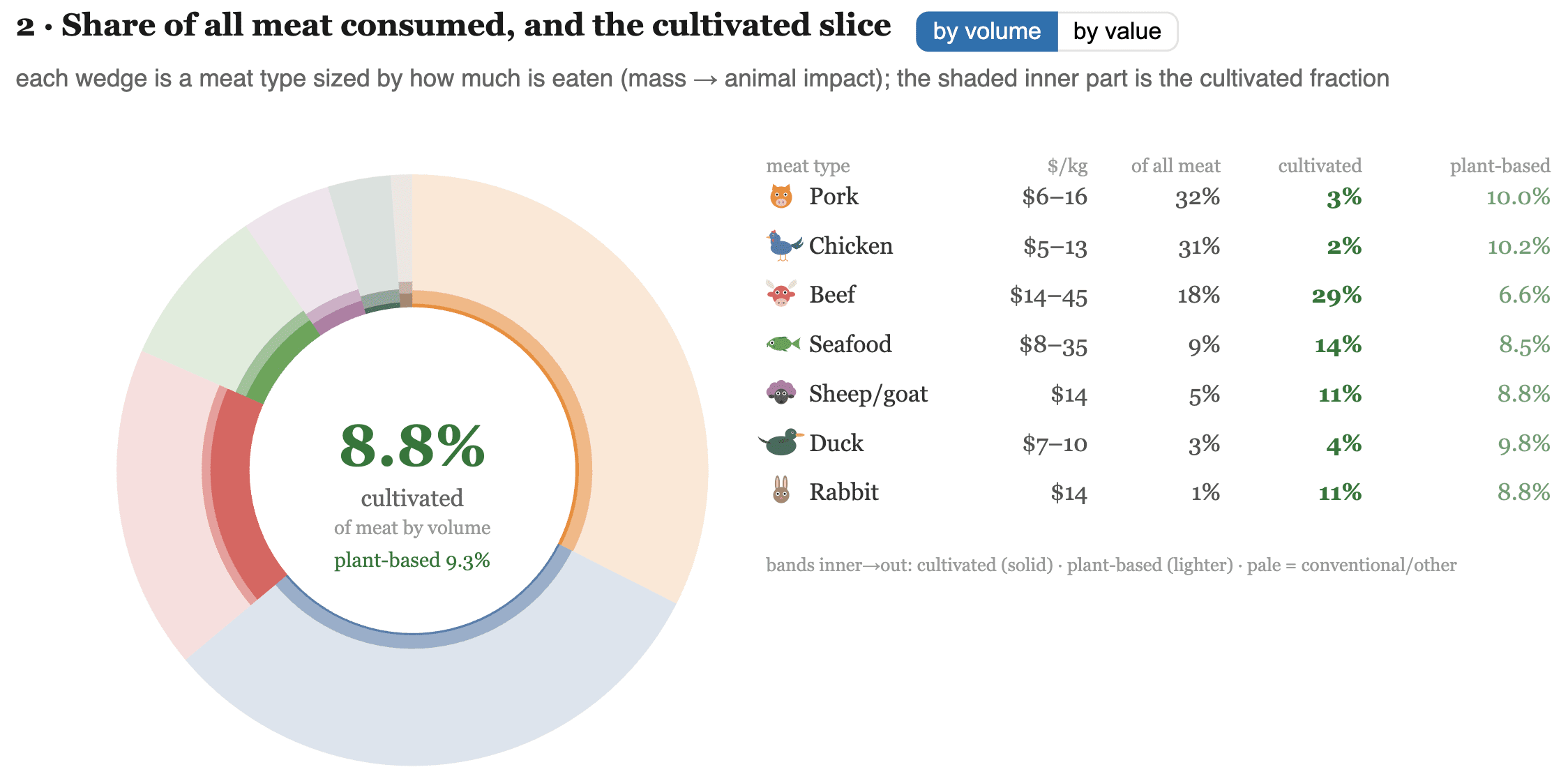
Practically, this inconsistency leads to strange conclusions in existing CEAs. Taking GiveWell's Unlimit Health (deworming) CEA as a stylised example:
For two people in Madagascar, we value doubling the income of someone who makes $2,500 30% as much as for someone who makes $500.
When the person making $2,500 lives in Côte d’Ivoire, however, we value doubling their income the same (100% as much) as for the person in Madagascar who makes $500.
Resolving this isn’t straightforward and has large implications for our prioritisation. For example:
Using η=1 everywhere—which implies that income doublings have the same value regardless of absolute income levels—doubles the cost-effectiveness of education and deworming programs and makes economic growth and poverty graduation interventions look substantially better.
Using η=1.87, which is implied by our discount rate, everywhere requires our evaluations to take into account the income levels of recipients and prioritise lower-income regions more. An income doubling in Malawi would be worth roughly 1.9x as much as in Ethiopia, 3.4x as much as in Kenya, 6.4x as much as in Egypt, and 75x as much as in the US. The same is true within countries: in India, an income doubling in Bihar would be worth 3.4x as much as an income doubling in Andhra Pradesh.
I’m hoping this post will start a conversation around what the right value of η is.
Our inconsistent η values
Summary: GiveWell’s framework, which we use, explicitly uses log-utility from consumption, which implies isoelastic utility with η=1. However, our (and GiveWell's) discount rate uses η≥1.59. We use η=1 when comparing between interventions/places. But we use η≥1.59 for comparisons across time, where income doublings are worth 2.6% less in a year from now solely because incomes will be higher then. We should use the same η for comparisons across time and place. Not doing so can lead us to prefer doubling the incomes of richer vs poorer people (see next section).
We use η=1 (log-utility) to compare the value of income benefits across people or interventions[1]. That assumption is convenient because it allows us to disregard absolute income levels: an income doubling is as valuable from $250 to $500 as it is from $2.5k to $5k. Because of that, we can make statements like “the value of a 10% income increase from a deworming program in India equals the value of a 10% income increase from a cash transfer program in Kenya” without knowing the incomes of the recipients.
At the same time, we use η≥1.59 when comparing the value of income benefits in different years within an intervention. A higher η reflects more strongly diminishing utility from consumption. Our current choice of η assumes that income doublings that occur 10 years from now are worth about 20% less than income doublings today just because the recipients will have higher incomes then. (At η=1, that 20% discount would be 0%.) We use this higher η whenever we apply our default discount rate.
Our discount rate
Both GiveWell and Founders Pledge use a 4% annual discount rate for consumption benefits[2];2.6 of the 4% likely reflect diminishing marginal utility from income doublings. Whenever we estimate the cost-effectiveness of a program that raises future incomes, we apply a 4% annual discount rate. Many of our programs raise incomes decades in the future (e.g., poverty graduation, deworming, and education programs). At those time scales, the discount rate matters. At a 4% rate, an income doubling today is 80% more valuable than an income doubling 15 years from now.
The 4% discount rate is the sum of 3 components[3]: temporal uncertainty (1.4%), improving circumstances (1.7%), and compounding non-monetary benefits (0.9%). In this post, I focus only on the latter two. What distinguishes them from temporal uncertainty is that they reflect diminishing marginal utility from income doublings. We only include them in the discount rate because incomes increase over time even absent any intervention.
Improving Circumstances
This component captures the intuition that utility from consumption declines faster than log-utility and that doubling a poor person’s income is more valuable than doubling a rich person’s income (GiveWell 2018a). The discount rate of 1.7% comes from explicitly using η=1.59 and an annual consumption growth rate of 3% (GiveWell 2018b)[4]. Because a program recipient will have 3% higher consumption in a year from now absent any intervention, they will value an income doubling 1.7% less.
Compounding non-monetary benefits
This factor represents future non-income benefits caused by higher consumption today. Some examples are reduced stress and improved nutrition whose positive effects compound over time (GiveWell 2020). While I couldn’t find much information about this factor, my best guess is that it effectively reflects diminishing marginal utility of income doublings.
(Quantitatively it would be captured by η=1.87 when combined with the improving circumstances component. That comes from solving the last equation in Rethink Priorities’ 2023 report for η given r=0.026 and g=0.03—i.e., assuming that the compounding non-monetary benefits factor also reflects diminishing marginal utility from income doublings. As a result I'm assuming the discount rate reflects η=1.87 for the remainder of the post.)
However, I’m more uncertain about this component reflecting diminishing utility because I could only find limited info on it. I’m explaining my reasoning for why I believe it does at the end of the post and would like to learn more about what GiveWell is trying to capture here. If it turns out that this component reflects something else, the argument in this post does not change qualitatively, though the magnitudes of the conclusions would be roughly a third lower.
To recap,we have two different assumptions for how strongly utility from consumption declines[5]. Under η=1, which we use for cross-sectional comparisons (i.e., between people/places/interventions), an income doubling has the same value regardless of the beneficiary’s income. Under η=1.87, an income doubling is worth much less for richer people. For example, doubling the income of the average person in Kenya ($1000 GDP/capita) is worth only about half an income doubling in Malawi (~$500 GDP/capita).[6] We use the latter framework when comparing benefits within an intervention over time (i.e., longitudinally).
Why it matters
Summary: This inconsistency matters in practice. It introduces strange conclusions into existing CEAs, such as valuing increasing the income of two people with the same income level very differently depending on where they live. Adopting one of η=1 vs η=1.87 everywhere would substantially impact our prioritisation (e.g., doubling the cost-effectiveness of education and deworming interventions vs valuing income doublings in Bihar at 300% of an income doubling in Andhra Pradesh).
We should use the same η for comparisons across time and place. One might argue that the degree of diminishing utility from consumption differs when comparing between places/people vs over time. This would for example be the case if all that matters is one’s relative position in society. However, using different utility functions leads to some unwanted conclusions. We, for example, sometimes value income doublings more for richer people. To avoid that, we need to settle on one single value of η for both cross-sectional and longitudinal comparisons. (I’m detailing the argument for this at the end of the post.)
The inconsistent η values cause strange conclusions in existing CEAs
Take GiveWell's Unlimit Health CEA, which considers income increases across different geographies and over time within each geography. Unlimit Health runs a deworming program, which in expectation allocates 13% of a new donation to Madagascar and 6% to Côte d’Ivoire.
The CEA roughly assumes that each treated person experiences the same persistent % consumption increases each year over the course of their life. These income benefits are discounted by our default rate, so that an income doubling today is worth 3x as much as the same income doubling in 48 years solely because recipients will be about 4 times as rich. At the same time, current-year income doublings in Madagascar ($500 GDP/capita) and Côte d’Ivoire ($2.5k GDP/capita) are valued the same[7]. This leads to the following weird conclusion:
In Madagascar, we value the income doubling of someone who makes $500 about 3x as much as the income doubling of someone who makes $2.5k.
However, if the person who makes $2.5k lives instead in Côte d’Ivoire, we value their income doubling the same as doubling the income of the $500 earner in Madagascar.
Put another way, if we consistently apply the income doublings framework (log-utility), the CEA would imply a 2.6% annual discount rate for pure time preference: even if the income % increases are as certain to occur in 48 years as they are now, we value an income doubling 3x more today.
Using either η=1 or η=1.87 everywhere would substantially impact our prioritisation
We might hope that as long as we settle on either η=1 or η=1.87 and use it consistently, our CEAs, or at least the relative ranking of charities, wouldn’t change. Unfortunately, that is not true.
Option 1: Using η=1.87 also in comparisons across interventions
Using η=1.87 would require us to start taking into account absolute income levels in our cost-effectiveness analyses. Consider an intervention that, by improving agricultural productivity, raises the incomes of 1M people by 0.1%. Such an intervention in Malawi would be worth 1.9x as much as in Ethiopia, 3.4x more than in Kenya, and 6.4x as much as in Egypt. The same is true within countries: an income doubling in Bihar would be worth 3.4x as much as an income doubling in Andhra Pradesh. Once we consider income doublings in high-income countries, e.g., from increasing frontier growth, those differences become even larger. An income doubling in the US is worth only 5% of an income doubling in Kenya (or about 1.3% of an income doubling in Malawi). Even for our current interventions, the choice of geography would matter more. In the Unlimit Health example above, the Madagascar program would be about 6.8 times as cost-effective as Côte d’Ivoire (up from 2.3 times as cost-effective).
Option 2: Using η=1 also in comparisons across time
η=1 implies removing the 2.6 percentage points from the discount rate that are due to diminishing marginal utility from income doublings (i.e., reducing the discount rate to 1.4%[8]). This reduction makes categories of interventions that raise incomes over long time horizons look substantially better. For example:
Human capital: The cost-effectiveness of GAIN and others would roughly double.
Economic growth: If effects persist over 40 years, programs would become about 50% more cost-effective.
Deworming:Unlimit Health’s rating would almost double from 12.1 to 23.2[9].
Poverty graduation: Our rating of Bandhan would increase by ~20%.
Next steps
We should be consistent in our choice of η and use the same value for comparisons across places/interventions and over time. That being said, I’m not sure what the right choice of η is. Since even small changes in the discount rate can change the relative cost-effectiveness of different interventions, we want to make sure we get it right. I’ve briefly looked into what others have said about η:
GiveWell provides some intuition that η=1.59 is ballpark right.
Open Philanthropy noted that η=1 might accord better with life satisfaction data. However, they also say that conclusion is contested.
SoGive provides a table with empirical estimates of η.
Through this post, I’m hoping to get input from others on how we should best choose η.
Appendix
The "compounding non-monetary benefits" factor likely reflects diminishing marginal utility from income doublings
My best guess is that the “Compounding non-monetary benefits” component of GiveWell’s discount rate effectively captures diminishing marginal utility from consumption doublings. However, I’m uncertain about that because there is not much publicly available reasoning about it. Here I’m outlining how I’ve come to that conclusion.
First, I’ve found the following info on this factor:
“There are non-monetary returns not captured in our cost-effectiveness analysis which likely compound over time and are causally intertwined with consumption. These include reduced stress and improved nutrition.” (GiveWell 2020)
“Conceptually, it's trying to capture the dynamics behind poverty traps. e.g., an argument for increasing consumption now being more valuable than in the future is that it releases credit constraints, allows additional spending on things like nutrition, and those investments pay off down the line. This parameter was originally 1.9%, and meant to capture the benefits of being able to get returns on capital. But then I think that argument got weaker based on long term fade out evidence from GiveDirectly's program. I'd wanted to cut it to 0, but Caitlin made the case that (a) there may still be other unmeasured non-monetary benefits that compound over time (b) getting money earlier might still allow consumption smoothing. So we halved it as a kind of compromise position.” (Email from James Snowden to Rethink Priorities, in A review of GiveWell’s discount rate — Rethink Priorities)
My first intuition was that this factor captures the idea that giving a person income today is better than giving it to them one year from now because the effects from better nutrition can accumulate for one additional year overall (or because it allows for consumption smoothing over more periods in total). However, I’m thinking that that scenario wouldn’t require a discount. Presumably, the beneficiaries of a program also change over time, and the average age of a target group will stay roughly the same, so that the non-income benefits accumulate for the same number of years on average. (As a stylised example: a program that gives income transfers to all people over 18 in a community will still do so in 10 years from now rather than restricting it to people over 28).
As a result, I’m thinking that the discount rate is trying to capture some (non-age) change in the characteristics of recipients, so that income doublings a year from now are worth less than an income doubling today because there will be fewer future non-income benefits that accumulate. If those changes are independent of absolute income levels, I think they also shouldn’t require a discount. Say a person gets a certain utility benefit from doubling their consumption today, and an additional x% of that utility benefit from future non-income benefits. If that x% is the same across absolute levels of income, there is no need for a discount rate because the increase in utility would be the same (consumption doublings have the same value because of log-utility and so the x% share of that utility benefit is also equal).[10]
My best guess for the “Compounding non-monetary benefits” component is then that it reflects some change in the characteristics of recipients that is captured by an increase in income; in other words: that it reflects a poverty trap dynamic where the sum of future non-income benefits is higher at lower absolute income levels. For example, wealthier people might face fewer credit constraints/poverty traps (perhaps because they have collateral), have other options to smooth consumption and guard against income shocks, benefit less in relative terms from reduced stress and improved nutrition, etc. However, such a discount implies that the marginal utility from consumption doublings is lower at higher income levels—i.e., diminishes more strongly than log-utility. Together with the improving circumstances discount, we can model it as an η of 1.87 (by backing out η from a discount rate of 2.6% and a consumption growth rate of 3% in a modified Ramsey equation).
Since that conclusion required some interpretation based on the info that I could find, I’m overall uncertain about it. It could be that this component reflects something else entirely—I would be interested in learning more about what GiveWell is capturing here.
Using different η values for comparisons across time and place can lead us to prefer doubling the incomes of richer relative to poorer people
There are different ways in which we could specify when to use log-utility vs η > 1. I’m outlining two options here that are similar to how we currently implicitly do it and explain why either of them will sometimes lead us to prefer doubling the incomes of richer relative to poorer people. (As Karthik points out in the comments, at other times, we will prefer doubling the incomes of poorer relative to richer people.)
Option 1: Use log-utility across people, but η>1 for each individual person (over time)
Suppose that for any comparison across different people we use log-utility but that for each single person we use η>1 (for example to make comparisons across time or different states of the world). This has the following issue of preferring rich people’s income doublings.
Consider three people, A, B, and C, with respective incomes of 5, 10, and 10 USD. Suppose we compare doubling the income of A twice (from 5 -> 10 and 10 -> 20) to doubling the incomes of both B and C (10 -> 20 each). The income doubling from 5 -> 10 for A has the same value as doubling the income from 10 -> 20 for B because we use log-utility across people. Doubling A's income from 10 -> 20 is less valuable than doubling it from 5 -> 10 because we use η>1 for each individual. Since the other three income doublings are all worth the same (A: 5 -> 10, B and C: 10 -> 20), we prefer doubling the incomes of both B and C compared to doubling A’s income twice. Now, since the income doubling for A from 10 -> 20 has the same value as that for B from 10 -> 20, it must be that we prefer doubling C’s income from 10 -> 20 over doubling A’s income from 5 -> 10. But that means we prefer doubling the richer person’s income.
Option 2: Use log-utility across countries, but η>1 within each country
Another distinction might be to use log-utility for comparisons across countries (or another geography), but to use η>1 for any comparison within a country (e.g., across people or time). In order to make sense of across-country comparisons, we need to specify which incomes in each country are worth the same across countries. Say that, for example, doubling the income of the average earner in a country is worth the same across countries. Now, doubling the mean income in the US (~$50k) is worth the same as doubling the income of the average earner in Madagascar (~$500). However, within Madagascar, doubling the income of a richer person is worth less than doubling the income of a poorer person, so doubling the income of a person making $1000 is worth less than doubling the income of a person making $500. Since doubling the income of a person making $500 in Madagascar was worth the same as doubling the income of a person making $50k in the US, we have that doubling the income of a person making $1000 (in Madagascar) is worth less than doubling the income of a person making $50k (in the US). So we are again preferring doubling the income of a richer person relative to a poorer person.
Other organisations also use this rate, likely following GiveWell’s choice. Rethink Priorities notes in their 2023 review: "Some organizations defer to GiveWell’s discounting practices. For example, Charity Entrepreneurship stated in an email that it 'defer[s] to GiveWell’s 4%'." According to the report, CE-incubated charities also use the 4%. Open Philanthropy as far as I can tell does not use it.
One way to derive the discount rate from the elasticity of marginal utility from consumption and the consumption growth rate is to use a modified Ramsey equation. See, e.g., Rethink Priorities' 2023 review of GiveWell's discount rate (p. 48).
Rethink Priorities pointed out this inconsistency with regards to the Improving Circumstances component in their 2023 review of GiveWell’s discount rate. See, e.g., the discussion on p. 21–22 of their report.
While the incomes of program recipients might be more similar than the difference in GDP/capita would suggest, let’s assume for the sake of illustration that the deworming benefits accrue to people with the average income in each country (or that the difference in the average income of the recipients in the two countries is 5x).
Under log-utility (η=1) we would not need any discounts for diminishing marginal utility from income doublings (since there are none). For a derivation, see Rethink Priorities’ 2023 report.
However, if those future non-income benefits aren’t captured anywhere else, it might make sense to increase the moral weight of an income doubling to systematically account for them.
67
More posts like this
230
Preliminary Analysis of Intervention to Reduce Lead Exposure from Adulterated Turmeric in Bangladesh Shows Cost Benefit of About US$1 per DALY


Inconsistency doesn't lead to favouring income doublings for the rich; it just leads to inconsistency
The post gives the impression that inconsistent choices of η systematically favor income doublings for rich people compared to poor people. This isn't true.
Imagine that instead of doubling A's income twice, we considered doubling C's income twice.
U(2x C's income from 10 to 20) = U(2x B's income) = U(2x A's income) with η=1. And U(2x C's income from 10 to 20) > U(2x C's income from 20 to 40) with η>1. So U(2x C's income from 10 to 20) + U(2x C's income from 20 to 40) < U(2x B's income) + U(2x A's income). Since income doublings are worth the same across people, we get U(2x C's income from 20 to 40) < U(2x A's income).
So with the exact same example, we have concluded both that doubling A's income is worth more than doubling C's income, and that doubling C's income is worth more than doubling A's income. This is a pure logical inconsistency. It is not the case that the richer person's income doubling is generically valued higher than the poorer person's income doubling.
Likewise with the second example:
Within the US, doubling the income of a $50k earner is worth more than doubling the income of a $100k earner. Across the US and Madagascar, doubling the income of a $500 earner in Madagascar is worth the same as doubling the income of a $50k earner in the US. Putting these two together, doubling the income of the $500 earner in Madagascar is worth more than doubling the income of the $100k earner in the US. So in this example, the inconsistency also favors doubling the income of the poorer person.
Now, this doesn't contradict the title of the post. I agree that pure logical inconsistencies in the way that we compare interventions are undesirable. But I don't want people to come away from this post with the conclusion that this inconsistency systematically favors interventions for rich people over interventions for poor people.
This inconsistency is not analogous to a rate of pure time preference
I'm puzzled at the argument for why inconsistent η implies a rate of pure time preference.
I don't think I follow this argument. There's no time dimension in the Madagascar-Cote d'Ivoire example, so I don't understand how it tells us anything about the rate of pure time preference. Moreover, in the general CEA, the discount rate contains three factors: pure time preference, uncertainty, and diminishing marginal utility of consumption. Your example eliminates uncertainty, shows that there's still a large discount rate, and then concludes that that must reflect pure time preference. But it actually reflects the diminishing marginal utility of consumption, which you also note at the start. So then how does this imply a discount rate for pure time preference?
Choices of eta are probably back-filled from moral weights on health vs income
In practice, grantmaking by GiveWell/FP/AIM is quite heavily loaded onto health-generating interventions rather than income-generating interventions. But the moral weights on health vs income depend in large part on the marginal utility of consumption. Higher values of η, combined with low income levels for recipients, would make income-generating interventions much more attractive than health-generating interventions, and shift your portfolio substantially towards income-generating interventions.
This is an econpilled view that I'm quite comfortable with. But for most people, intuitions about the moral value of health vs income precede intuitions about the right value of η, so η values are back-filled to be consistent with those intuitions. I think this is the true reason for the inconsistency you point out. η=1 is the value that people are most comfortable back-filling to match their moral intuitions about health vs income, and is very convenient for not having to measure income levels. η>1 is more realistic, but is admissible with these moral intuitions only when comparing income gains to income gains (within a program).
Now, that's not to say that η>1 is necessarily better. I think it's more likely to be true but was convinced by Alexander Berger's counter-argument that it provides worse prescriptions than η=1.
But regardless, it would be a mistake to think about η choices primarily through the lens of how they affect comparisons of livelihood interventions, because any shift from η=1 would substantially affect income vs health moral weights, and most of its effect on your portfolio would go through that channel.
(Caveats: I am working at GiveWell, but views are my own and don't represent any larger position)
Hi Karthik,
Thank you for engaging in detail with the post—these are all great points, much appreciated! I’m replying to each one below.
1) “Inconsistency doesn't lead to favouring income doublings for the rich; it just leads to inconsistency”
I agree with your argument that we can also conclude that doubling the incomes of poorer people is more valuable than doubling the incomes of richer people. I meant to make the point in the post that this inconsistency can lead us, strangely, to conclude that doubling the incomes of richer people is more valuable than doubling the incomes of poorer people—not that it always does. To make that point clearer and not give the impression that we systematically favour income doublings for the rich, I’ve edited the post to say things like “can lead us to prefer …” instead of “leads us to prefer …”, and referenced your argument in the appendix.
Substantively, I would draw a somewhat stronger conclusion than you: not only that inconsistency “leads to inconsistency” but that it "sometimes leads us to favour income doublings for the rich”.
That is because, in practice, there are situations where the inconsistency will lead us to that conclusion. Take, for example, deworming in Madagascar (~$500 GDP/capita) vs cash transfers in Kenya (~$2k GDP/capita). For simplicity, assume deworming generates income benefits in year 1 and 2 while cash transfers only generate them in year 1. In our CEAs, we assign the same value for income doublings in year 1 of an intervention. Because we set the comparison point there, we value doubling the income of the $500 and $2k earners the same, but value the income doubling of the $502 earner in Madagascar in year 2 less than for the $2000 earner in Kenya.
2) “This inconsistency is not analogous to a rate of pure time preference”. Thank you for pointing out that this wasn't clear. I meant it to be an implication of assuming both η=1 and η>1 and applying η=1 in the example: “even if the income % increases are as certain to occur in 48 years as they are now, we value an income doubling 3x more today.” If those two income doublings are worth the same, the discount rate reflects only pure time preference. To clarify this, I’ve changed that sentence to say “Put another way, if we consistently apply the income doublings framework (log-utility), the CEA implies a 2.6% annual discount rate of pure time preference.” (changes italicised)
3) “Choices of eta are probably back-filled from moral weights on health vs income”. That’s an important consideration. We want to make sure any change we make to η is also consistent with our moral intuitions about health vs income benefits. One key question seems to be how health benefits vs income doublings trade off at different absolute levels of income? E.g., does the rate at which they trade off stay the same? Do we think health benefits are equally valuable at different income levels but income doublings are worth less at higher income levels? I'd be curious about what your intuitions are here.
On this point in particular:
I'm not sure this is necessarily true? It seems like higher values of η would primarily increase the slope of the marginal rate of substitution between health benefits and income doublings, as a function of absolute income levels. (We prefer health benefits more strongly at higher vs lower levels of income). Whether this shifts our portfolio more towards health- or income-generating interventions depends on our choice of income level at which we believe income doublings and health benefits should trade off as they currently do.
Thanks for clarifying!
I don't think it makes sense to frame this as valuing rich people over poor people. What's happening in this example is favoring benefits in year 1 over benefits in year 2, regardless of a person's income. This is definitely a nitpick, but I think many people's intuitions about time discounting precede intuitions about rich vs poor people's income doublings, so it's more clarifying to frame it that way.
An equivalent way to frame this would be "we use a log utility framework because of <benefits>, but we recognize that it overestimates the value of income growth at higher levels of income, so we will fix that by discounting future income in a way that would be consistent with η>1."
In other words, the inconsistency is just a practical way to reconcile two frameworks with different pros and cons, rather than an endorsement of the ethical position of pure time preference. Now, ad hoc approaches like that could rub you the wrong way, but I would put that in the general category of "this is bad because it's arbitrary", and not "this is bad because it implies a rate of pure time preference, which has repugnant ethical conclusions".
Yeah, I thought this through more and I skipped a few steps + stated some incorrect things.
The first step is to note that higher values of η decrease the value of saving poor people's lives compared to rich people's lives. In the basic isoelastic utility framework, the value of saving a year of life is[1] VSLY=u(c)u′(c)=cη−cη−1 which means it is higher for rich people than for poor people. Now, this is also true for log utility, but notice that the gap between rich and poor VSLYs is increasing in η, meaning that higher values of η make it even less attractive to save a poor person's life than a rich person's life. This is a conclusion that nobody likes.
The second step is to note that the only way I know of to modify the isoelastic utility model to avoid that conclusion, is to add a set point to utility, so that u(c)=k+c1−η−11−η Then for a high enough set point, the VSLY will vary much more slowly with income, and rich and poor lives will be closer together in value. However, this is where the health vs income tradeoff comes in. If you have a high enough set point, income-creating interventions become unattractive compared to health-creating interventions, because most of a person's utility comes from their set point, not from being rich or poor, so there's little value to increasing their income a lot. So I was wrong to say that high η would make income-generating interventions more attractive. [Edit: also worth noting that high set points would be incompatible with low VSL estimates in poor countries]
But the basic point is, the standard isoelastic utility model doesn't create much implication for health vs income, but it creates a repugnant conclusion about valuing rich vs poor lives. A modified isoelastic utility model that fixes that problem will have sharp implications for trading off health vs income.
intuition: the value of being alive for a year is the utility experienced by a year of consumption at level c, aka u(c). But u(c) is in utils, not dollars, so we divide it by the marginal utility of money u′(c) to represent the value of life in dollars. ↩︎
Thank you, Karthik! I’ll respond briefly to one point about the inconsistency sometimes leading us to value doubling the incomes of richer people more relative to poorer people. The rest of my comment is on the health vs income benefits discussion, which I’ve found very interesting.
On sometimes preferring to double rich people's incomes
I see where you’re coming from since we use η>1 only in our time discounting. Here is the opposite view for why the rich vs poor framing might be more natural:
Recall that the only reason we favour benefits in year 1 over year 2 is that recipients are richer in year 2 (assuming there is no uncertainty about the benefits in year 2). Put another way, if we thought recipients had the same income in year 2 as in year 1, we would not prefer the year 1 benefits. We might in our CEAs think about this as time discounting. But really it is discounting richer people’s income doublings, which is then reflected in our time discount rate only because we assume consumption grows at 3% each year absent any intervention. Because we discount richer people’s income benefits less across interventions than we do within an intervention over time, we have situations like these where we value richer people’s income doublings more.
On health vs income
It’s important to draw out the implications of the choice of η on the health vs income benefits comparison. With the caveat that I’ve not spent much time looking into previous VSLY discussions, I’m not sure the impact of higher η is as clear-cut. Specifically, I’m thinking
Both VSLY utility models don’t seem to align with people’s reported VSL preferences with regards to the mortality risk vs income gain tradeoff.
Model 1 (isoelastic utility): Take η=1 and assume that the elasticity of VSL with regards to income is 1 (i.e., people are indifferent between the same multiple of their income and an extra life-year, regardless of absolute income level). Since an income doubling has the same moral weight regardless of income level, so has an extra life-year. However, model 1 values an extra life-year at c∗ln(c), which is increasing in c.
Even if we think the elasticity is 1.3 instead of 1 (the upper bound of what Open Philanthropy considers reasonable), the model doesn’t fit well. Take this hypothetical example: if a $1000 earner is indifferent between $1000 and an extra year of life, a person making $2000 would be indifferent at $2300, and so VSLY should increase by a factor of 1.3, too. However, c∗ln(c) equals 6,907 at c=1000 and 15,201 at c=2000, which is not a 30% but a 220% increase. As you pointed out, η>1 only leads to preferring health interventions for rich vs poor people even more.
Model 2 (isoelastic utility with set point k): The same is true for model 2. Take, for example, η=1. Then, VSLY= c∗(k+ln(c)) (or, for η>1, kcη+cη−cη−1). Both are increasing in c, while VSL revealed/stated preferences imply it should be roughly constant or even decreasing (see next point). (This is the same reasoning as for model 1, keeping in mind that k drops out in the value of income doublings, which is unchanged: u(2c)−u(c)=(k+ln(2c))−(k+ln(c)))=ln(2))
Since the models don’t reflect individuals’ preferences, I'd be hesitant to use them to make normative claims about how to morally value mortality reduction interventions at different income levels.
When we don’t impose the VSLY=u(c)u′(c) model but work up from individuals’ preferences, higher η might lead to valuing mortality reduction interventions at lower income levels more (i.e., the opposite conclusion):
Take again the purely utilitarian view that we should value utility increases the same irrespective of the beneficiary. Then, note that there is some fixed number x of income doublings such that people are indifferent between them and an extra year of life, regardless of income level (assuming the VSL-income elasticity is 1). That means that people gain as much utility from an extra year of life as from x income doublings.
Let η=1. Income doublings have the same moral value regardless of income level, so the same is true for extra life-years.
Now consider instead η>1. The income doubling generates less utility at higher income levels than at lower income levels. However, at higher income levels, people are still indifferent between the same x income doublings and an extra life-year. That would imply that the utility (and therefore the moral value) from an extra year of life is lower at higher income levels.
Since in that framework, we value mortality-reduction and income interventions more at lower income levels, my expectation is that higher η would lead us to prioritising lower-income beneficiaries more than we currently do.
You're pointing out that the value of life shouldn't depend on consumption u(c). But even if you assumed there was a fixed utility from saving lives, the VSLY would still be different across populations, and all of the conclusions I talked about would still hold. The reason is because of the monetization of utility. The VSLY is grounded in how an individual would trade off health vs income, and that tradeoff depends on their marginal utility of income u′(c).
Assume there was a fixed utility from someone being alive for a year, ¯u. Then their willingness to pay for an extra year of life is ¯u/u′(c). This varies less with income than if the value of life was u(c), but it still varies with income. Poor people are willing to spend less (in absolute terms) on health than rich people are, because their competing needs are higher than rich people's competing needs.
If this is the case, then all of our discussion of η still goes through. For an isoelastic utility function, the VSLY is ¯u⋅cη, which increases in income, and increases exponentially in η. The replacement of u(c) with ¯u changes nothing qualitatively; higher η still leads to higher VSLYs even when everyone enjoys a year of life equally. That then causes health interventions for the rich to dominate health interventions for the poor.
The reason why this matters is because it renders the following statement problematic:
Assuming the VSL-income elasticity is 1 is equivalent to assuming η=1, since you have to assume that income doublings are worth the same to people regardless of their income levels. So I don't really understand how that assumption helps you draw conclusions about what would happen if η>1. If η>1, then even if the value of life was common to everyone, the VSL-income elasticity would be greater than 1. Basically, the marginal utility of income doublings declines, but the marginal value of life does not, so the VSL has to grow faster than income.
Now, the key assumption is that we monetize VSLs using individual willingness-to-pay. Maybe you think social willingness-to-pay should be determined by the marginal utility of money to the social planner, which is common across people, rather than by the WTP of individuals who vary in their income levels. This is a defensible normative position. I would just note that the marginal utility of money from a donor's perspective is the value you could otherwise get by spending that money. For us, that benchmark use of money is GiveDirectly cash transfers. If you think that way, you will end up with a marginal utility of money that is close to a poor person's marginal utility of money, so the original framework is still representative of how valuable health interventions are among poor people.
I think it fits fine? Under the log utility model with no set point, WTP for an extra year of life is cln(c). Normalize this by income levels c to get the VSLY-income ratio as ln(c). Eyeballing the graph from OP's collection of VSL estimates, they look vaguely consistent with a logarithmic relationship between the VSLY-income ratio and income. Or take the general isoelastic utility model, where WTP for an extra year of life is $\frac{c^{\eta}-c}{\eta-1}, so the VSLY-income ratio is 1η−1⋅cη−1−1η−1. This is a general sub-linear function of c for η>1, and you could probably fit a value of η to match the estimates best. Robinson et al (2019) take this elasticity approach and find a roughly log-linear relationship between VSLY-income ratio and income.
Now, these studies can't statistically reject a flat VSLY-income ratio across countries, so you would be on fair ground to assume a constant VSLY-income ratio. But it's definitely not right to say that the isoelastic utility model doesn't fit the data on VSLs across countries.
Got it—I think I might have had an errant c term where I was thinking about fit. Point taken that you can model a non-constant VSLY-income ratio with isoelastic utility.
What do you find to be the strongest reason to use VSLY's to value lives saved at different income levels? My intuitive approach would have been to use the value of utility from one year of consumption directly, not divided by people's marginal utility of consumption (i.e., u(c) instead of u(c)u′(c)). We would then value extra life-years only based on the utility received during that year. In the constant utility case, for example, we'd place the same value on an additional life-year regardless of income level.
Isn't comparing interventions by the utility they create (rather than how that utility is monetised) what we want to do? Analogously, we currently think individuals value income doublings the same at all income levels. We wouldn't then conclude that the fact that a $1,000 earner has a $1000 WTP for an income doubling while the $2,000 earner has a WTP of $2,000 means we should value the income doubling for the richer person twice as much. But it seems like that's what the VSLY approach is doing, if I'm not misunderstanding it?
"Value" is a slippery term here. You're referring to utility value, but when we calculate cost-effectiveness, we have to place a monetary value on the outcome, because
The choice of VSLY as a source of moral weight comes from the premise that when comparing interventions that increase health or increase income among poor people, we should make the tradeoff in the same way that they would, rather than imposing our own preferences of how to make that tradeoff. The reason why VSLYs satisfy that is because they are either estimated from revealed-preference decisions of the relevant populations, or from the stated preferences of the relevant populations. (If they were just dictated from on high, they would not be good moral grounding!) Specifically, in a neoclassical framework where people can pay for health improvements, their willingness to pay is exactly the marginal utility of a health improvement, divided by the marginal utility of income u′(c). That's why we divide by u′(c).
Of course, that leads to indeterminacy when comparing interventions between two populations with different c and thus different VSLYs. So when organizations have a single consistent moral weight on health vs income, they are implicitly treating the VSLY as common between all populations. That basically implements what you're saying (have a common valuation for years of life across countries). But it doesn't resolve our earlier discussion, since if you grounded your moral weight on lives saved in a VSLY, and you adopted a new η, you would get a new moral weight on lives saved, which would be the first-order determinant of how η affects grantmaking.
I appreciate the back and forth discussion here, thank you! I agree with most/all of your comment. But: is it not true that your earlier statement
relies on using VSLY=u(c)u′(c) values directly to compare the value of health across different levels of c (which I don't think we should do)?
The following approach is consistent with your last comment (using VSLY for health vs income tradeoffs at any given c) but would lead us to place a higher value on health at lower vs higher income levels (instead of the other way around, which would be the conclusion no one likes).
Take u(2x2)−u(x2)u(2x1)−u(x1) and v=a+bu. Sub in v for u and the term stays the same.
Likewise, great discussion!
I don't understand using η and the revealed preferences independently of each other. η only makes sense if it is consistent with the revealed preferences that people place on health vs income. If revealed preferences show that people have a constant valuation of income doublings vs life, then that is only consistent with η=1, and I see no justification for using η>1. How would you justify it?
My earlier statement did not rely explicitly on the VSLY being u(c)/u′(c). However, what it does rely on is the VSLY-income ratio being increasing in c. If we assume the value of health is constant ¯u and that η=1, then the VSLY is ¯u⋅c so the VSLY-income ratio is constant. I'm down to assume the value of health is constant, and I don't feel strongly about η even though I think it's probably >1. But my loose reading of the VSLY-income literature is that the ratio is increasing in c.
Maybe this is where our two approaches differ:
We have three types of valuations.
My approach is to estimate η from data on people's choices regarding (2) (e.g., p. 7 here). Then get the health vs income moral weights from revealed preferences on (3) (e.g., VSLY data). Then combine the two to get (1).
What I think you're saying is (correct me if I'm wrong) that (3) also gives us data on η, because individuals value extra life-years proportional to the consumption in that year. (By assuming that empirical VSLY estimates are described by u(c)u′(c), this gives us info on η by choosing the η that makes u(c)u′(c) best fit the VSLY revealed preferences.) Based on that, it then is inconsistent to have a different η from (2) than is implied by (3), and we want to reconcile them.
Does that sound right? If so, my view would be that valuing an extra life year according to u(c)u′(c) for some η is a functional form assumption on how people value an extra life-year. In some way, I see the data on η from (2) as a test of that assumption. Whereas in your view, which I think is also reasonable, the assumption and data on (3) is a test/verification of our estimate of η from (2).
If you don't think that we know about η from (3), for example because you don't believe the assumption, higher η can imply higher valuation of health at lower incomes even if the VSLY-income ratio is increasing in c. Here is a hypothetical example. Suppose the elasticity is 1.2 so that a $1,000 earner is indifferent between 1 income doubling and an extra life-year, while a $2,000 earner is indifferent between 1.1 income doubling and an extra life-year. That means that at η=1, the value placed on health for the $2,000 earner is higher than for the $1,000 earner. Increase η and normalise the moral weights on income doublings so that an income doubling for the $1,000 earner has the same value as before. Higher η means the income doubling at $2,000 is now less valuable. Since the VSLY revealed preferences are unchanged, the moral weight on health at higher incomes is now lower relative to the weight on health at lower incomes, compared to before.
Yup, that's an accurate summary of my beliefs (with the caveat that u(c) is non-critical and can be replaced with a constant or whatever else you want; only u′(c) is essential). Put another way, η is a single preference parameter that determines the marginal utility of income, and that affects how we value both income and health. I think any other assumption leads to internal inconsistency, or doesn't represent utility maximization.
What is an individual willing to pay for anything? Suppose buying a health good (e.g. air purifier) gives you utility k, and it costs p. Then for every dollar you spend, you are getting k/p utility. Is that optimal? It is optimal only if the marginal utility of spending a dollar on any other good is ≤k/p. If you could get >k/p utility from spending a dollar elsewhere, then you would optimally refuse to buy the air purifier and spend your money elsewhere. That's why u′(c) is always in the denominator; it represents the opportunity cost of money. If you didn't spend your money on a health good, you would spend it somewhere else. And the opportunity cost of money is obviously higher for poor people (trading off daily food for an air purifier is a hell of a lot less appealing than trading off a Chanel bag for an air purifier). So that's why I don't think there can be any consistent model of utility maximization where the VSLY[1] doesn't depend on u′(c). Its dependence on u(c) is irrelevant and can be replaced with some constant k if you want, but I am reasonably sure that u′(c) can't be banished from the VSLY without rejecting individual utility maximization.
So I think the crux between us is whether you see your position as consistent with VSLYs being derived from individual utility maximization. If it is, then please help me understand, because that would be a major update for me. But if it's not, then I think we are at this point:
If you substitute "buying an air purifier" with "buying a year of life", then my argument goes from estimating "willingness to pay for an air purifier" to estimating "willingness to pay for an extra year of life". This is exactly what the VSLY represents, when it is estimated from individual revealed preferences. ↩︎
I think that assumption isn't sufficient to determine η from VSLY data. By not specifying the functional form for VSLYs, η will be underidentified in practice. Assuming only that the denominator of the VSLY term is u′(c) and that u(⋅) is isoelastic, we could, for example, have either of the following:
Now suppose you observe the VSLY/income data and think it's roughly ln(c). Would you conclude from this that η=1 and the right functional form is (2)? Or that η=1.2 and the right functional form is (1) with k=1.8? (Plot)
Does that sound right to you? If so, I think that puts us here:
______
One counterargument might be that for any of these functional forms, an increase in η will lead to higher valuations of health at higher incomes. However, I'm not sure that works in practice. I'd imagine it going something like this (assuming the only assumption we're willing to make ex-ante is that the VSLY denominator is u′(c)):
I'm agnostic on the right functional form for the VSLY, just as I'm agnostic on the right η. My point was just that you cannot have it be independent of u′(c).
You need to impose some structure to get an exact identification of η, but that should not be interpreted as meaning that we can be fully agnostic about how η affects valuations, the way you describe. So I don't think that puts us at the point you stated. Specifically, I think the framework you describe where the VSLY relative to income doublings is constant while you shift η is still inconsistent with utility maximization, and still not a valid way to interpret how η affects the value of health vs income.