Thanks for this exercise, it's great to do this kind of thinking explicitly and get other eyes on it.
One issue that jumps out at me to adjust: the calculation of researcher impact doesn't seem to be marginal impact. You give a 10% chance of the alignment research community averting disaster conditional on misalignment by default in the scenarios where safety work is plausibly important, then divide that by the expected number of people in the field to get a per-researcher impact. But in expectation you should expect marginal impact to be less than average impact: the chance the alignment community averts disaster with 500 people seems like a lot more than half the chance it would do so with 1000 people.
I would distribute my credence in alignment research making the difference over a number of doublings of the cumulative quality-adjusted efforts, e.g. say that you get an x% reduction of risk per doubling over some range.
Although in that framework if you would likely have doom with zero effort, that means we have more probability of making the difference to distribute across the effort levels above zero. The results could be pretty similar but a bit smaller than yours above if we thought that the marginal doubling of cumulative effort was worth a 5-10% relative risk reduction.
This is a good point I hadn't considered. I've added a few rows calculating a marginal correction-factor to the google sheet and I'll update the table if you think they're sensible.
The new correction factor is based on integrating an exponentially decaying function from N_researchers to N_researchers+1, with the decay rate set by a question about the effect of halving the size of the AI alignment community. Make sure to expand the hidden rows in the doc if you want to see the calculations.
Caveats: No one likes me. I don't know anything about AI safety, and I have trouble reading spreadsheets. I use paperclips sometimes to make sculptures.
One issue that jumps out at me to adjust: the calculation of researcher impact doesn't seem to be marginal impact. You give a 10% chance of the alignment research community averting disaster conditional on misalignment by default in the scenarios where safety work is plausibly important, then divide that by the expected number of people in the field to get a per-researcher impact. But in expectation you should expect marginal impact to be less than average impact: the chance the alignment community averts disaster with 500 people seems like a lot more than half the chance it would do so with 1000 people.
Ok, this statement about marginal effects is internally consistent....but this seems more than a little nitpicky?
I don't see any explicit mention of marginal effects in the post[1]:
The only implied marginal effect might be the choice being influenced by the post, which is the OP or someone joining today. There isn't 500 or 1,000 safety researchers today.
(Diving down this perspective) so with a smaller community, this omission would bias the numbers that appear in the post downward.
From the perspective of an author writing this post on the forum, it seems unlikely that introducing this consideration and raising the numbers, would be helpful instrumentally/rhetorically, since the magnitudes are pretty compelling and not a weakness of the argument.
For similar reasons, it doesn't seem that probable that someone making a career choice spreadsheet would explicitly model marginal production (as opposed to rounding it off implicitly somewhere).
More substantively, while some sort of "log marginal productivity" is probably true "on average" and useful in the abstract, it's very, extraordinarily hard to pin down the shape of the "production function from talent". E.g. we can easily think of weird bends and increasing marginal returns in that function[2][3].
The same difficulty applies with outliers or extraordinary talent—it doesn't seem reasonable for the OP to account for this.
This is an aesthetic/ideological sort of thing, but IMO it seems unlikely that you would be able to write anything like a concrete production function. This is because of all the unknown considerations, that can only come from object level work.
Like, I'm borderline unsure if it's practical to express these considerations in English language.
It would be great for my comment here is to be wrong and be stomped all over!
Also, if there is a more substantial reason this post can be expanded, that seems useful.
Like, Chris Olah might be brilliant and 100x better than every other AI safety person/approach. At the same time, we could easily imagine that, no matter what, he's not going to get AI safety by himself, but an entire org like Anthropic might, right?
In that person's worldview/opinion, applying a log production function doesn't seem right. It's unlikely that say, 7 doublings would do it (100x more quality adjusted people) in this rigid function, since the base probability is so low.
In reality, I think that in that person's worldview, certain configurations of 100x more talent would be effective.
One issue here with some of the latter numbers is that a lot of the work is being done by the expected value of the far future being very high, and (to a lesser extent) by us living in the hinge of history.
Among the set of potential longtermist projects to work on (e.g. AI alignment, vs. technical biosecurity, or EA community building, or longtermist grantmaking, or AI policy, or macrostrategy), I don't think the present analysis of very high ethical value (in absolute terms) should be dispositive in causing someone to choose careers in AI alignment.
Yes, that is true. I'm sure those other careers are also tremendously valuable. Frankly I have no idea if they're more or less valuable than direct AI safety work. I wasn't making any attempt to compare them (though doing so would be useful). My main counterfactual was a regular career in academia or something, and I chose to look at AI safety because I think I might have good personal fit and I saw opportunities to get into that area.
the AI safety research seems unlikely to have strong enough negative unexpected consequences to outweigh the positive ones in expectation.
The word "unexpected" sort of makes that sentence trivially true. If we remove it, I'm not sure the sentence is true. [EDIT: while writing this I misinterpreted the sentence as: "AI safety research seems unlikely to end up causing more harm than good"] Some of the things to consider (written quickly, plausibly contains errors, not a complete list):
The AIS field (and the competition between AIS researchers) can cause decision makers to have a false sense of safety. It can be the case that it's not feasible to solve AI alignment in a competitive way without strong coordination etc. But researchers are biased towards saying good things about the field, their colleagues and their (potential) employers. AIS researchers can make more people be more inclined to pursue capabilities research (which can contribute to race dynamics). Here's Alexander Berger:
[Michael Nielsen] has tweeted about how he thinks one of the biggest impacts of EA concerns with AI x-risk was to cause the creation of DeepMind and OpenAI, and to accelerate overall AI progress. I’m not saying that he’s necessarily right, and I’m not saying that that is clearly bad from an existential risk perspective, I’m just saying that strikes me as a way in which well-meaning increasing salience and awareness of risks could have turned out to be harmful in a way that has not been… I haven’t seen that get a lot of grappling or attention from the EA community. I think you could tell obvious parallels around how talking a lot about biorisk could turn out to be a really bad idea.
And here's the CEO of Conjecture (59:50) [EDIT: this is from 2020, probably before Conjecture was created]:
If you're a really good machine learning engineer, consider working for OpenAI consider working for DeepMind, or someone else with good safety teams.
AIS work can "patch" small scale problems that might otherwise make our civilization better at avoiding some existential catastrophes. Here's Nick Bostrom:
On the one hand, small-scale catastrophes might create an immune response that makes us better, puts in place better safeguards, and stuff like that, that could protect us from the big stuff. If we’re thinking about medium-scale catastrophes that could cause civilizational collapse, large by ordinary standards but only medium-scale in comparison to existential catastrophes, which are large in this context, again, it is not totally obvious what the sign of that is: there’s a lot more work to be done to try to figure that out. If recovery looks very likely, you might then have guesses as to whether the recovered civilization would be more likely to avoid existential catastrophe having gone through this experience or not.
The AIS field (and the competition between AIS researchers) can cause dissemination of info hazards. If a researcher thinks they came up with an impressive insight they will probably be biased towards publishing it, even if it may draw attention to potentially dangerous information. Their career capital, future compensation and status may be on the line. Here's Alexander Berger again:
I think if you have the opposite perspective and think we live in a really vulnerable world — maybe an offense-biased world where it’s much easier to do great harm than to protect against it — I think that increasing attention to anthropogenic risks could be really dangerous in that world. Because I think not very many people, as we discussed, go around thinking about the vast future.
If one in every 1,000 people who go around thinking about the vast future decide, “Wow, I would really hate for there to be a vast future; I would like to end it,” and if it’s just 1,000 times easier to end it than to stop it from being ended, that could be a really, really dangerous recipe where again, everybody’s well intentioned, we’re raising attention to these risks that we should reduce, but the increasing salience of it could have been net negative.
... AI safety research seems unlikely to have strong enough negative unexpected consequences to outweigh the positive ones in expectation.
to
... Still, it's possible that there will be a strong enough flow of negative (unforseen) consequences to outweigh the positives. We should take these seriously, and try to make them less unforseen so we can correct for them, or at least have more accurate expected-value estimates. But given what's at stake, they would need to be pretty darn negative to pull down the expected values enough to outweigh a non-trivial risk of extinction.
Nice! I really like this analysis, particularly the opportunity to see how many present-day lives would be saved in expectation. I mostly agree with it, but two small disagreements:
First, I’d say that there are already more than 100 people working directly on AI safety, making that an unreasonable lower bound for the number of people working on it over the next 20 years. This would include most of the staff of Anthropic, Redwood, MIRI, Cohere, and CHAI; many people at OpenAI, Deepmind, CSET, and FHI; and various individuals at Berkeley, NYU, Cornell, Harvard, MIT, and elsewhere. There’s also tons of funding and field-building going on right now which should increase future contributions. This is a perennial question that deserves a more detailed analysis than this comment, but here’s some sources that might be useful:
Second, I strongly believe that most of the impact in AI safety will come from a handful of the most impactful individuals. Moreover I think it’s reasonable to make guesses about where you’ll fall in that distribution. For example, somebody with a history of published research who can get into a top PhD program has a much higher expected impact than somebody who doesn’t have strong career capital to leverage for AI safety. The question of whether you could become one of the most successful people in your field might be the most important component of personal fit and could plausibly dominate considerations of scale and neglectedness in an impact analysis.
Yeah your first point is probably true, 100 may be unreasonable even as a lower bound (in the rightmost column). I should change it.
--
Following your second point, I changed:
Upon entering the field you may receive sufficiently strong indications that you will not be able to be a part of the most efficacious fraction of AI safety researchers.
to
Upon entering the field (or just on reviewing your own personal fit) you may receive sufficiently strong indications that you will not be able to be a part of the most efficacious fraction of AI safety researchers.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
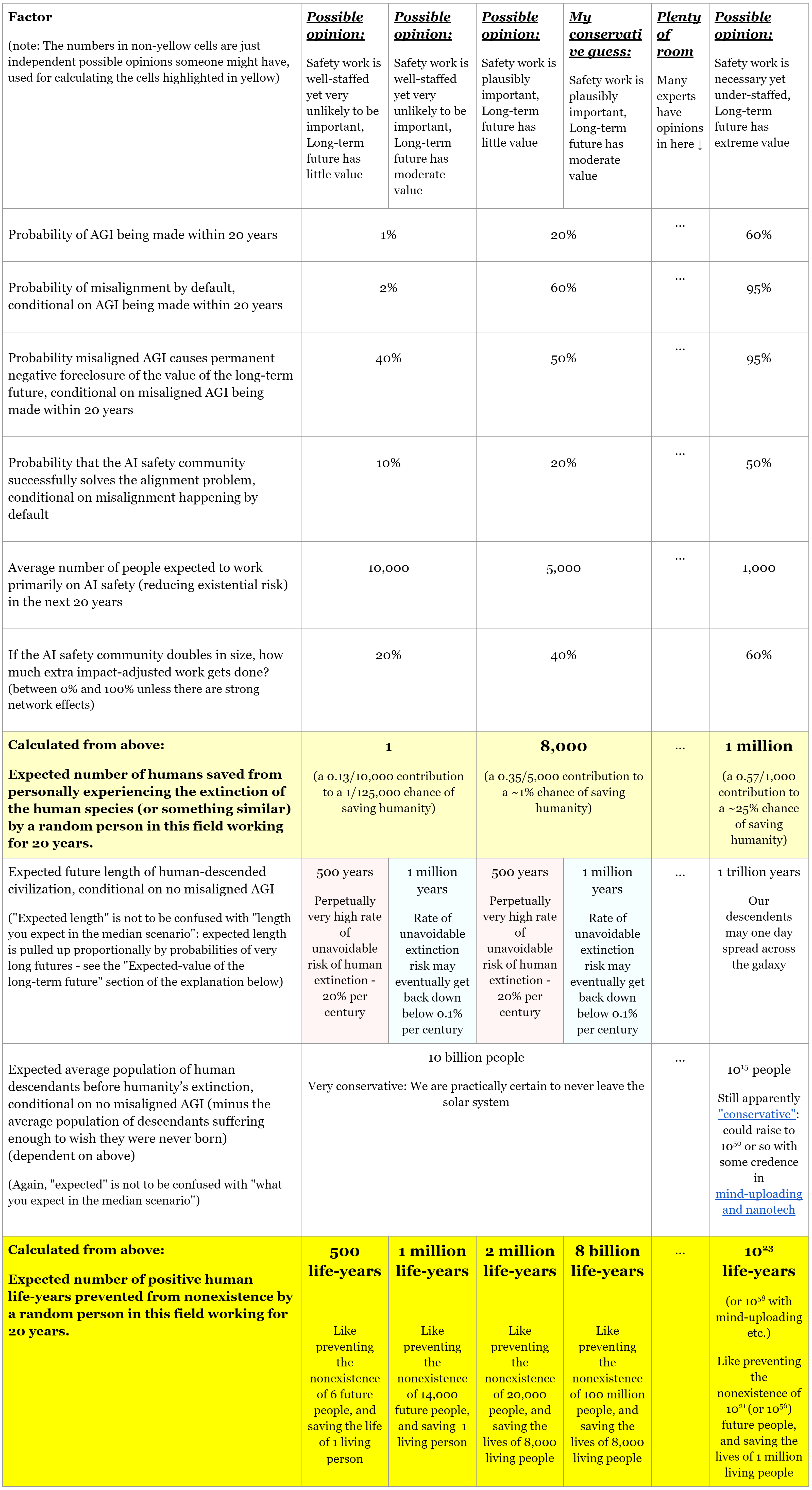
This table explores the ethical expected-value of a career in AI safety, under different opinions about AI and the long-term future. I made it for considering the robustness of the value of my possible career choice to different ways my opinions could change, but it may be useful to others also considering a career in AI safety, or for convincing people more skeptical of fast AI timelines that safety work is still important.
My main finding is that you need to hold a pretty specific combination of confident beliefs for AI safety work not to seem tremendously valuable in expected impact, and I personally find those beliefs pretty untenable. I also made a sheet where you can put in your own numbers, to see the implications of your own opinion.
Read the “Explanation” section below if you’re confused about anything.
Main takeaway: You need to hold a pretty specific combination of confident beliefs for AI safety work not to seem tremendously valuable in expected impact.
i.e. something like those in the leftmost column: safety work is likely to be well-staffed, yet very unlikely to be useful, and humanity will go extinct soon with very high probability anyway. I personally find those beliefs pretty untenable - especially the amount of certainty they require about AGI and the long-term future of humanity.
For the AI skeptical: This doesn't mean we're all going to die! - Just that this work seems like a robustly good opportunity because the stakes are so high relative to the chances of having a positive impact, even if we're very likely to be fine anyway.
For the non-skeptical: Reasonable people certainly disagree whether the median scenario looks anything like "we're fine", and I'm very sympathetic to that too. It's just that for answering the binary question of "should more people be working on this?", the median scenario is surprisingly unimportant right now. I'm showing that even people with heavy skepticism and very slow AI timelines should agree that more AI safety work is important, so long as they have some reasonable uncertainties in their views.
Alternate refutations of the importance of AI safety work (and my responses):
You could believe that the future of humanity is net negative and humans should be wiped out. → But would a world ruled by some sort of paperclips-style AGI be better than humanity under your moral framework? Surely it would be much worse for the environment, and all other life on earth. In any case, the advantage of having humans around for a while longer is that we have more time to figure out what would be morally best for the universe, then do it. Or, better yet, program an actually aligned AGI to do it. Personally I'd prefer we be replaced by wildlife, or a universe of little happy things, rather than a misaligned AGI turning the planet into paperclips or something. See also: suffering risks which might be caused by a misaligned AGI, or the possibility that we might be able to abolish all suffering of humans and all other animals in the future.
You might think the long-term future is unpredictable and virtually impossible to influence intentionally like this. → Sure, the long-term impact of pretty much all our actions has tremendous sign uncertainty, meaning long-term considerations usually wash-out compared to short-term ones, but in this case, are you really so sure? Extinction seems like a pretty clear-cut case in terms of the direction of long-term expected value, relatively speaking. Still, it's possible that there will be a strong enough flow of negative (unforeseen) consequences to outweigh the positives. We should take these seriously, and try to make them less unforseen so we can correct for them, or at least have more accurate expected-value estimates. But given what's at stake, they would need to be pretty darn negative to pull down the expected values enough to outweigh a non-trivial risk of extinction.
You could very strongly believe a different view of population ethics, or very strongly reject anything like consequentialism, giving less than a 0.01% credence to any moral theory which values the mere existence of happy beings in the future. A ~0.01% credence would let you sit in the second column, but still reject AI safety work. → But 0.01% credence is pretty damn sure. Are you sure you’re so sure? See moral uncertainty for a discussion of how you should act when you’re uncertain about the correct moral framework. Regardless, safety is still worth working on if you fall in any except the first two columns, even if you certainly don’t care about the existence or nonexistence of future beings.
You don’t think we’re under any obligation to do what seems morally best. → Perhaps, sure, and probably no one should make you feel guilty for not devoting your career to this. But this is a great opportunity to have a very large positive impact.
You might react negatively to things which feel like Pascal’s mugging. → See Robert Miles' video for a response to this criticism of AI safety work. Basically, it’s worth reasoning about expected values based on evidence.
You think that most of the important work is done by a small fraction of the AI alignment researchers, so you will personally be unlikely to have an impact as strong as the table suggests. → This is true, but before you go into the field you may have no information about where in the efficacy spectrum of AI researchers you will fall. Rather than assuming you will fall near the median, it makes sense to assume you will be like a random person drawn from the distribution of AI safety researchers, in which case your expected contribution is the same as the average contribution, not the median. This is why this table is for a “random” person in the field, rather than the median person (who would have smaller expected impact). Upon entering the field (or just on reviewing your own personal fit) you may receive sufficiently strong indications that you will not be able to be a part of the most efficacious fraction of AI safety researchers. After reassessing the expected value of your impact, it may make sense to switch careers, especially if the field ever becomes primarily funding-constrained and you believe new hires may have a bigger expected impact than you. However, this issue of replaceability reducing your counterfactual impact is much less of a worry in AI alignment than most other fields, and less of a worry in general than you might expect. There seems to be a lot of room to grow the whole field of AI safety right now, so it’s far from a zero-sum game.
You think there are higher expected-value considerations pushing in the other direction, or plenty of other highly positive careers a potential AI safety researcher could go into instead, and perhaps their expected-value is just harder to quantify. → Fair enough, that’s a matter of evidence. I’m sure there are plenty of other careers out there with huge positive moral impacts. The more we can identify the better.
Your priors are just very low, perhaps due to anthropic reasoning that this can’t be the most important century, or that such a proliferation of future generations can't exist. → You are entitled to your priors, but you ought to be very careful with anthropic reasoning. Using it to lower your priors this much seems almost as bad as using it to support something like the doomsday argument. Personally, I’m quite a fan of “fully non-indexical” anthropic reasoning, where you must “condition on all evidence - not just on the fact that you are an intelligent observer, or that you are human, but on the fact that you are a human with a specific set of memories”, in which case I think anthropic reasoning tells you very little about this issue. (podcast for clarification)
Explanation
AI (Artificial Intelligence) safety research seems to have tremendous expected moral value. Most of this expected value probably does not come from the median scenario, so the work will probably look less impactful in hindsight, but this should be no argument against it, as the potential impacts are just so huge, and their probabilities seem plausibly nontrivial. Additionally, there is a range of possibly tractable and useful research areas, widening further as AI capabilities increase.
My credence in (strong) AGI soon:
My definition of strong AGI (Artificial General Intelligence): A system which can (or which can be finetuned to) accomplish most current economically useful objectives more effectively than a very effective person in that field. This includes reasoning about the world (and the humans in it), and making predictions.
Within 10 years: ~10%, Within 20 years: ~20%, Within 50 years: ~50%
I’m very uncertain of these, and I hold them very weakly. They’re largely based on priors. Ideally, there would be much more solid research informing all of these credences, but I basically just have to go with what I think for now. For alternative numbers (mostly faster), see:
Why have you looked at mostly slower timelines here when most of the sources you link have faster timelines?
For my selfish personal use, I wanted to see just how far my opinions would have to change before a career in AI safety would no longer seem extremely beneficial. Then, seeing that they would have to move a tremendous amount, I can very confidently commit to AI safety without worrying about reconsidering my career choice in light of new evidence every day. (Just every few years or something)
The people with fast timelines are probably more likely to buy into the usefulness of AI safety work already (I think?), so showing that even most slow-timeline scenarios have great expected value is useful for convincing more mainstream people about the value of AI safety work.
Based on (hurdles still in front of AGI):
Long-term planning (abstraction from immediate actions to long-term plans and back)
Internal model of the world which can be updated at runtime to resolve inconsistencies
Sufficient training compute and data, or increased compute & data efficiency
These are not independent; progress on one is likely to be useful to the others, and more data & compute alone could concievably be sufficient for all. On the other hand, I’m sure I’m missing some.
AGI development paths / warning signs (conditional on AGI):
Breakthrough out of the blue: 15%
One team over the course of a few years (some clearish signs, things getting very strange): 25%
Multiple teams over the course of a few years (multiple clearish signs, things getting very strange): 40%
Anything slower / more multipolar: 20%
The West ahead in development: 70%
Slow takeoff speed once developed (AGI has most of its potential for existential risk before any self-improving "singularity"): 60%
Again, I hold these credences very weakly. Substitute your own.
Impacts of AGI:
Implications are massively underestimated by most people (for strong AGI)
It’s such a pivotal technology that it seems impossible to picture how the world will look in 100 years without knowing how (or whether) AGI goes
Misalignment risk:
Various actors (eg. companies looking for profit) would benefit from making AI systems which behave like “agents” pursuing some external goals in the world. When machine-learning systems are trained, however, their learned internal “goals” (to the extent that they have them) are merely selected to produce good behaivour on the training data, and so their internal goals often differ importantly from the external goals on which they were trained, which can lead to them competently pursuing an unintended goal.
As an analogy, evolution selected us to “maximize inclusive reproductive fitness” creating a jumble of values and goals which led to behaivour looking a lot like “maximizing inclusive reproductive fitness” in our past evolutionary environment. However our internalized goals are quite different to “maximize inclusive reproductive fitness”. This misalignment is apparent now that many things (eg. contraceptives, abundant sugar, technology, global society) have taken us out of evolution’s “training environment”. See mesa-optimization and inner-alignment (video).
Additionally, we cannot currently infer a model's internal goals (or if it has any) by looking inside it, so we are currently only able to infer discrepancies through behaviour. As a result, detecting when a system is an "agent" or is optimizing for some goal is difficult, and goal-pursuing agents might emerge for instrumental reasons in cases where we are not explicity selecting the AI to behave like a goal-pursuing agent.
AIs could have just about any internal goal, and just about any goal is compatible with ssuperhuman capabilities. A “misaligned” AI would be any AI with an internal goal not fully aligned with our values, with the discrepancy eventually being actualized in some important way. See the orthogonality thesis (video).
An AI with coherent intrinisic goals is incentivized to do whatever it can to raise the probability of achieving them. Some ways that a misaligned AI could fail to have its goals achieved: Humans shutting it down; Humans changing its goals; Humans discovering that it is misaligned before it is in a position where humans are no longer able to change it. See instrumental convergence (video)
Finally, even if the internal goal of the AI matches the external goal on which it was trained, it seems hard to find goals which are both well-specified and aligned with human values when pursued by AIs with exremely high capabilities.
Misalignment risk seems greatest during wartime (but probably not dominated by wartime risk).
Outside of wartime, surely no one would be stupid enough to let a paperclips-style single-optimizer go wild. Right? Still, significant probability that one may be developed, maybe just because it’s easier to train an AI to optimize for one thing, like it’s easier to train GPT to optimize next-word performance.
To me, the most likely scenario is a subtler, mesa-alignment type problem. There will be warning signs in stupider iterations being deceptive or competently optimizing for the wrong thing, but perhaps the applied fix turns out to be more of a bandaid than anticipated, until too late.
What might the first AGIs look like? Optimizing actors (hopefully not)? Feedback responding actors? Queryable world models? Risk depends on that.
Overall, hard to say (especially taking into account existing trajectory of AI safety work), but significant probability of subtle misalignment, which might not be fixable until too late.
Again, the largest potential for counterfactual impact may not necessarily come from scenarios like the median (although in this case it might).
Misaligned AGI seems like the most plausible path to permanently cutting off humanity’s potential (See “The Precipice” for a comparison with other risks).
Forgoing trillions of descendant-years of potential flourishing throughout the galaxy would probably be very bad.
A sufficiently cognitively powerful system will be able to outwit humanity at every turn, and do whatever it wants.
Any interaction with humans is enough of a channel to allow a superintelligence to manipulate them, escape, and do whatever it wants.
If it determined humanity to be a threat to its goals, a superintelligence could, for example, remotely trick, blackmail, or manipulate someone in a biolab to unknowingly synthesize a virus which might wipe out humanity. (or not - superintelligence could probably come up with something much more effective).
Understanding how concepts, abstractions, heuristic values, goals, and/or agency are formed through training, so that one can predict ahead of time how AIs trained in various ways will generalize to new situations (eg. Shard Theory or John Wentworth)
Increasing alignment-robustness to distributional shifts, with an extremely low tolerance for error (training to avoid Goal Misgeneralization)
Looking for trends of potentially worrying behaviors in current AIs, to determine how risky the next generations might be (eg. Beth Barnes)
Inverse reinforcement learning / value learning
Corrigibility (making systems which won't resist being shut down)
Myopia (making systems which don't have potentially dangerous goals)
Theoretical work on what a safe AGI could look like
Many more (I’m not an expert, but this is proof of concept for some tractable areas):
This is only upper-bounded by the laws of physics and the time until all the stars die out. The lower bound depends on your optimism for the human species. The potential is vast - If they aren’t extinct, far future beings in a post-scarcity society will have had the time to figure out how to be much happier, more fulfilled, more numerous, and more ethical, (or to change their biologies to achieve this) spreading more of whatever is good throughout the galaxy, or preserving or restoring it if it was already there.
A note on expected values: Unless you give a vanishingly small probability to futures where we expand through the universe, or develop mind-uploading technology, these should influence your expected values for the number of beings in the future, pulling your expected numbers up far above the median scenario. And if you think the probability is vanishingly small, it still has to vanish as fast as the potential population increases - getting down to less than about 1 in 1050 once you start talking about scenarios with virtual-mind carrying machines expanding through the universe.
Put differently, most of the people who will ever live in the future possible histories of the universe will probably live in fairly low-probability scenarios, made up for by their extreme proliferation in that low-probability scenario (unless you think extreme proliferation is the median scenario, or extreme proliferation is even more extremely unlikely). This is somewhat akin to where we find ourselves today, as viewed from the distant (geologic-time) past.


Thanks for this exercise, it's great to do this kind of thinking explicitly and get other eyes on it.
One issue that jumps out at me to adjust: the calculation of researcher impact doesn't seem to be marginal impact. You give a 10% chance of the alignment research community averting disaster conditional on misalignment by default in the scenarios where safety work is plausibly important, then divide that by the expected number of people in the field to get a per-researcher impact. But in expectation you should expect marginal impact to be less than average impact: the chance the alignment community averts disaster with 500 people seems like a lot more than half the chance it would do so with 1000 people.
I would distribute my credence in alignment research making the difference over a number of doublings of the cumulative quality-adjusted efforts, e.g. say that you get an x% reduction of risk per doubling over some range.
Although in that framework if you would likely have doom with zero effort, that means we have more probability of making the difference to distribute across the effort levels above zero. The results could be pretty similar but a bit smaller than yours above if we thought that the marginal doubling of cumulative effort was worth a 5-10% relative risk reduction.
This is a good point I hadn't considered. I've added a few rows calculating a marginal correction-factor to the google sheet and I'll update the table if you think they're sensible.
The new correction factor is based on integrating an exponentially decaying function from N_researchers to N_researchers+1, with the decay rate set by a question about the effect of halving the size of the AI alignment community. Make sure to expand the hidden rows in the doc if you want to see the calculations.
Caveats: No one likes me. I don't know anything about AI safety, and I have trouble reading spreadsheets. I use paperclips sometimes to make sculptures.
Ok, this statement about marginal effects is internally consistent....but this seems more than a little nitpicky?
It would be great for my comment here is to be wrong and be stomped all over!
Also, if there is a more substantial reason this post can be expanded, that seems useful.
Please don't ban me.
I didn't read it actually.
Like, Chris Olah might be brilliant and 100x better than every other AI safety person/approach. At the same time, we could easily imagine that, no matter what, he's not going to get AI safety by himself, but an entire org like Anthropic might, right?
As an example, one activist doesn't seem to think any current AI safety intervention is effective at all.
In that person's worldview/opinion, applying a log production function doesn't seem right. It's unlikely that say, 7 doublings would do it (100x more quality adjusted people) in this rigid function, since the base probability is so low.
In reality, I think that in that person's worldview, certain configurations of 100x more talent would be effective.