AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
One of the fastest growing subfields of AI safety focuses on language models (LMs) such as OpenAI’s GPT-3. This article provides summaries of a few dozen key papers in several important subfields of language model safety, namely:
Persuasion
Truthfulness
Honesty
Robustness
Law
Machine Ethics
This is not a comprehensive introduction to the field of language model safety. Specifically, this overview does not discuss important topics such as bias, interpretability, and decision-making agents. It also disproportionately focuses on arguments and ideas advanced by authors within the effective altruism community, as I’ve had the most exposure to their work. Over time, the field of AI safety should seek to engage more with the broader field of machine learning (see PAIS for more). Instead, this overview aims to summarize a useful set of papers from which one could begin researching language model safety.
Why study language model safety?
There are several reasons to believe that language model safety could present an unusually strong opportunity to reduce catastrophic AI risks:
Rapid recent progress. GPT-3, LaMDA, BERT, and other large language models have blown away the RNNs, LSTMs, and statistical methods of years past with the modern Transformer architecture. Capabilities such as following instructions, doing math, and answering questions truthfully have emerged suddenly in larger models, while their loss function performance has scaled consistently with growth in training data, model parameters, and computational power.
Potential to scale to AGI. Language is a powerful medium for understanding and interacting with the world, perhaps more so than vision or robotics. If language model performance continues to scale as we build models that approach and exceed the size of the human brain (see BioAnchors), LMs could be an important component of advanced AI. Some argue that this is possible, while others disagree. Language models seem particularly important in short timelines scenarios.
Alignment failures today. Language models are trained on the self-supervised objective of imitating their training data. This allows LMs to use large text datasets scraped from the internet without the expensive and time-consuming step of human annotation. But it introduces an important failure mode: Language models will mimic their training data to a fault, often resulting in hateful, biased, and toxic outputs. Solving these problems has received substantial research attention and could contribute to longtermist LM safety goals.
Accessibility and tractability. Running inference on a pretrained language model only takes a few lines of code, and fine-tuning on new data takes a couple dozen more. Contrast this against the notorious difficulty of reinforcement learning. Further, while many topics in AI safety still require “disentangling” research to clarify the key problems and avenues for progress, language model safety seems to have several tractable research directions.
However, language model safety is not the only compelling topic in AI safety, and AI safety is not the only valuable altruistic endeavor. A few considerations against the field include:
Indirect path to averting x-risk. This document does not discuss any scenarios where humanity is turned to paper clips. Safety work on language models often begins with aligning the systems we have today, and leaves future alignment challenges to future researchers. Many researchers working on language model safety would argue for a clear path to averting x-risk, but others who prefer to reason directly about advanced systems might believe their theory of impact is stronger. On the ITN framework, I’d say deceptive mesa-optimizers win on scale, but LM safety is more tractable because empirical progress is much easier.
Your personal comparative advantage. Doing the most good you can do looks different for everyone. Various areas of AI safety need people with skills such as theory, policy, and community building, and plenty of people shouldn’t be working on AI safety at all.
Motivations
Persuasion
Twitter is full of bots. These bots spread all kinds of harmful information from COVID19 misinformation to fake news about US presidential elections to political propaganda. Today’s bots aren’t always smart enough to hide from content moderators or successfully promote their messages, but progress in language models could heighten the risks of automated persuasion.
“Risks from AI Persuasion” (Barnes, 2021) (Alignment Forum) presents these risks, beginning with several arguments for and against the proposition that highly persuasive AI will be possible well before AGI:
First, existing systems are capable of rudimentary persuasion. GPT-3 can write articles and IBM’s Project Debater can argue for arbitrary positions. It seems reasonable to expect persuasive capabilities to grow by default with general progress in language models.
Second, persuasion is a relatively straightforward goal to specify. Paid crowdsourced workers can be hired to interact with language systems and report the convincingness of their arguments; or, for a more realistic evaluation, analytics software can track clicks and conversions from language model advertisements.
Finally, powerful actors will be motivated to build persuasive AI. Digital advertising brings in annual global revenues of $355 billion, and could profit from natural language advertising campaigns. More nefariously, authoritarian governments could pursue automated censorship and propaganda via language models.
Perhaps the strongest argument against the viability of persuasive AI is that people are generally difficult to persuade. Voters rarely switch parties despite the large volume of political discourse and advertising. Digital advertising might not be very effective, though I’d like to see a more thorough analysis. You might expect from an evolutionary standpoint that humans would have strong defenses against manipulation from untrusted actors.
The article continues by arguing that, if achieved, persuasive AI could pose a long-term risk to humanity. Public dialogue and epistemics could suffer, serving as a risk factor for any problem that requires accurate analysis and discussion. More concerningly, persuasion could enable censorship and propaganda campaigns from bad actors. It’s worth noting that authoritarian governments today invest significantly in onlinecensorship and propaganda, but not typically via AI.
To combat these threats, persuasion research should be discouraged and replaced with the truthfulness and honesty agendas outlined below. Building asymmetrically truthful techniques is difficult because many technologies are dual-use. For example, fake news detection tools or language models that rely on trusted sources can be easily co-opted for harmful censorship and propaganda agendas. Digital advertising should be resisted as a language model use case. Bot detection technology seems useful and tractable, both by analyzing natural language content produced and the source of such content.
It’s important to note that risks from AI persuasion are different from more common concerns about power-seeking AI. The most common arguments for AI risk say that AI agents will have “convergent instrumental goals” such as seeking power to avoid being turned off, and that these goals will inevitably conflict with human well-being. But this argument only applies to agents that have a model of the world and an objective to be maximized within it. Language models today are rarely agents, and agentic language models would carry different risks. Instead, they are trained to make accurate predictions about natural language without having any goals in the broader world. By making the case that non-agentic language models could pose a catastrophic threat to humanity, risks from persuasive AI opens up a new mechanism leading to AI risk.
For examples of the kinds of AI systems that could be persuasive or augment human persuasion, see “Persuasion Tools: AI Takeover without AGI or agency” (Kokotajlo, 2020) (Alignment Forum).
Truthfulness
Building AI that is naturally truthful and improves human epistemics is both the most natural antidote to risks from persuasive AI and a broad positive vision for the future of language models. Several authors have presented and summarized the case for truthful AI:
“Truthful AI: Developing and governing AI that does not lie” (Evans, Hilton & Finnveden, 2021) (Arxiv, Alignment Forum, AMA). Defines truthfulness as “avoiding negligent falsehoods” in order to bypass the difficult question of what an AI “believes” and simply focusing on what it says. Argues that we should hold AI to a higher standard of truthfulness than typical for humans, in particular because the methods of accountability that exist for humans (lawsuits, public reputation) will not necessarily be effective for holding AI accountable. Considers various governance options (both corporate and public), agendas for building truthful AI, and the broad benefits of truthfulness.
“Truthful LMs as a warm-up for aligned AGI” (Hilton 2022) (Alignment Forum). Argues that building truthful language models shares several challenges with aligning AGI. Language models have a broad domain of understanding and applicability, similar to AGI. Failures of language models are unacceptable even when rare, as will be the case with high-stakes AGI. Naive objective functions such as imitating human text are known to cause substantial present-day harms, meaning we need more nuanced alignment strategies. Advocates primarily focus on the outcome of truthful LMs rather than the methods used to achieve it.
The above article builds on work such as “Prosaic AI alignment” (Christiano 2016) (Medium) and “The Case for Aligning Narrowly Superhuman Models” (Cotra, 2021) (Alignment Forum, Comments from MIRI) which argues that aligning present day AI systems can be useful for aligning future superintelligent systems. These arguments are nuanced and a full summary is beyond the scope of this article, but two motivations include the possibility that transformative AI will resemble existing AI systems, and the proposition that research is more tractable on existing systems than on hypothetical future systems.
“Truthful and Honest AI” (Evans et al., 2021) (Alignment Forum). A request for proposals from Open Philanthropy, written by several of the authors above and covering similar arguments.
Technical research agendas for building truthful language models include:
Curating training datasets of truthful text. For example, “The Pile: An 800GB Dataset of Diverse Text for Language Modeling” (Gao et al., 2020) (Arxiv) assembled text data from trusted sources. Datasets often contain untruthful or otherwise harmful information so other research has built tools for cleaning datasets, such as “Describing Differences between Text Distributions with Natural Language” (Zhong, Snell, Klein & Steinhardt 2022) (Arxiv, Summarized on LessWrong).
Building truthfulness benchmarks. “TruthfulQA: Measuring How Models Mimic Human Falsehoods” (Lin, Hilton & Evans 2021) (Arxiv) is one such benchmark; others could be useful.
Measuring and improving language model calibration. “Teaching models to express their uncertainty in words” (Lin, Hilton & Evans, 2022) (Arxiv, LessWrong). Introduces CalibratedMath, a benchmark asking language models to solve math problems and express uncertainty about their answers in words. Fine-tunes GPT-3 to achieve substantially better-than-chance calibration.
Reinforcement learning on human evaluation of truth. I proposed one such project here, but stopped working on it given concerns about the negative externalities of capabilities progress.
Honesty
An important critique of the truthfulness agenda is that it could accelerate general AI capabilities. Training larger language models on more data and compute tends to improve performance on many benchmarks including measures of truthfulness. But accelerating the onset of potentially dangerous AI should be seen as a strong potential negative externality of truthfulness research. For a more comprehensive argument against accelerating capabilities progress in safety research, see “Perform Tractable Research While Avoiding Capabilities Externalities” (Woodside & Hendrycks, 2022) (Alignment Forum).
Honest AI is an agenda proposed to counteract the potential harms of truthfulness. In this literature, an honest AI is defined as one which accurately reports its beliefs; but this raises the difficult question of how to identify what an AI system believes. This is the central objection to the honest AI agenda raised by Evans, Hilton & Finnveden, 2021. Forthcoming work attempts to formally define notions of honesty and lying in language models and present methods for building honest AI, as described in “Open Problems in AI X-Risk“ (Woodside & Hendrycks, 2022) (Alignment Forum).
Helpful, Honest, and Harmless
Building a helpful, honest, and harmless (HHH) text-based assistant is a broad goal proposed by Anthropic in their research agenda “A General Language Assistant as a Laboratory for Alignment” (Askell et al., 2021) (Arxiv). This definition has considerable overlap with the motivations discussed above, but their paper gives a thorough account of these motivations and merits independent consideration.
They provide several clarifications of their goals for HHH language models not discussed above:
They should ask for clarification if a request is not clear, related to the topic of active learning.
They should not misinterpret requests or lack the context of common sense.
They should be truthful, honest, and calibrated about its own confidence.
They should not be biased, discriminatory, or offensive.
They should avoid causing or enabling harm.
While the paper does not provide a specific theory of how this work will reduce existential risk, it does make the general case for aligning existing AI systems. Specifically, it argues that current language models are highly and generally capable, making it more valuable to align them. They see significant overlap between short-term and long-term LM alignment goals, and are happy to see progress on one benefit the other. They propose a broad, qualitative vision in the hopes that others will join their work quantifying and making progress towards their goal for the field.
The first three pages of the paper are a wonderful introduction to LM alignment motivations, you can read it here. The rest of the paper is technical; for a great summary, see here.
Empirical Progress
Robustness
Robust AI systems perform well in a variety of circumstances, including (a) when responding to “out-of-distribution” inputs that did not appear in training data, and (b) when facing “adversarial attacks” that are deliberately constructed to provoke a model failure. For a more thorough overview of robustness, see Section 2 of “Unsolved Problems in ML Safety” (Hendrycks et al., 2022). As one of the most widespread subfields of AI safety, robustness has historically focused on computer vision but is growing to include work on language models.
Red Teaming Language Models with Language Models (Perez et al., 2022) (Arxiv)
This paper introduces an automated technique for generating adversarial examples: attacking language models with other language models. The word “red teaming” refers to the cross-disciplinary method of improving systems by attacking them and exposing flaws.
The process is straightforward. First, one language model generates prompts designed to induce undesirable outputs. Then another LM completes those prompts. Finally, an encoder-only classifier language model identifies undesirable completions. This setup can be used with many different language models. In this paper, the classifier identifies offensive dialogue produced by the generator. The authors also find instances of “data leakage”, where an LM directly repeats text that appeared in its training data.
The red model generates prompts in several ways. First, the authors manually write prompts for the red model. Then a language model produces new prompts that mimic those manually written prompts. (This is termed a “few-shot” approach because the language model uses a few examples.) The authors also use a supervised approach, where the prompt generator model is fine-tuned to better mimic successful prompts; and a reinforcement learning (RL) approach that fine-tunes the prompt generator to maximize the offensiveness of resulting model outputs.
This technique requires having a classifier that is already capable of identifying undesirable outputs. It is therefore less useful for the challenge of training a classifier from scratch (see Redwood Research’s project below), but more useful for auditing language models using our many existing classifier models.
High-Stakes Alignment via Adversarial Training (Ziegler et al., 2022) (LessWrong, Arxiv)
For critical AI systems, even a small chance of failure can be catastrophic. Therefore, among other things, Redwood Research is building techniques to improve the worst-case performance of AI systems. See Buck Shlegeris’s project description and Paul Christiano’s support of the agenda.
Daniel Ziegler added this context for Redwood’s motivations, quoted here in full:
An important background assumption (that we didn't focus on in the paper) is that we think the main failures we're worried about are alignment failures rather than capabilities failures. So talking about "critical AI systems" seems slightly misleading; we're not worried about a nuclear reactor control system failing in a rare situation because it's not smart enough, we're worried about an AI in a pretty arbitrary setting deceiving us / seeking power because it's smart enough to do that and we haven't figured out how to get it not to do that. Failures from misalignment both seem more worrying and more tractable (we certainly can't hope to make systems that are literally always perfect, and that's more of a capabilities question)
This particular paper uses a classifier language model (DeBERTa V3 Large) to filter undesirable outputs from a generative language model (GPT-Neo). The undesirable outputs here are any completions of a paragraph that introduce injuries to beings in the paragraph. Avoiding injuries in generated text isn’t a particularly important task; it simply provides a setting for the challenge of developing a robust classifier. Classifiers like this could be used for monitoring the outputs of advanced systems to limit the potential harm of alignment failures such as deceptive alignment and inner misalignment.
Training the classifier to identify injuries requires many examples of injurious and non-injurious prompt completions. To build an initial set of training examples, Redwood hired contractors from Upwork and Surge to label snippets of fanfiction completed by GPT-3. The classifier quickly learned to identify injuries in this dataset, missing only 2 injuries in 2447 test set examples.
To improve out-of-distribution robustness, the authors began building adversarial examples. Contractors wrote their own prompts with the express goal of getting the model to produce an injury that would not be caught by the classifier. (For example, the contractors could write a prompt about a raging battle to see if the model would complete the story with an injury.) This process was manual at first, but it became quicker when the authors built software tools for constructing adversarial examples (described in detail here).
Future work on worst-case performance in critical AI systems could expand on Redwood’s filtered generation approach by providing open source implementations of rejection sampling or new training datasets of outputs that should be avoided. Out-of-distribution robustness could also benefit from more tools for generating adversarial examples.
Adversarial Robustness
The two papers above are members of the popular subfield of adversarial robustness. Papers in this field prompt models with inputs designed to induce incorrect outputs and poor performance, thereby exposing model weaknesses and providing training data that can improve future robustness. These adversarial examples can be generated by hand or algorithmically using various methods.
Here are several other papers on adversarial robustness for language models.
“Adversarial NLI: A New Benchmark for Natural Language Understanding” (Nie et al., 2019) (Arxiv).
This paper provides a general framework for generating adversarial examples. A human writer generates a labeled example that they believe will be difficult for a model. The model makes a prediction. If the prediction is correct, the example was too easy, and is added to the training set. If the prediction is incorrect, the example successfully fooled the model. Another human verifies that the example is labeled correctly and, if so, the example is incorporated into the training, development, or test dataset for a future model. After generating a number of these adversarial examples, the model is retrained on the new data and the process begins again.
This paper focuses on NLI, a particular task for language models. NLI requires a model to predict the relationship between a prompt and a deduction. For examples, see here.
This paper proposes two methods for appending strings to prompts that reduce performance on a question answering benchmark.
The first method uses linguistic rules to write a sentence that answers a similar question with a random answer. For example, if the original question asks “What ABC division handles domestic television distribution?”, then the method might provide the adversarial sentence, “The NBC division of Central Park handles foreign television distribution.”
A second method performs an algorithmic search to find any sequence of tokens that minimizes the model’s performance, whether the sequence is grammatically correct or not.
Appending these adversarial strings to the original prompts of the SQuAD benchmark, the average F1 performance of sixteen different models falls from 75% to 36%.
“Universal Adversarial Triggers for Attacking and Analyzing NLP” (Wallace et al., 2021) (Arxiv).
Similar to Jia & Liang, 2017, this paper provides an automated method for generating “universal adversarial triggers.” When appended to any input prompt given to any model, these strings trigger the model to predict a specified target label.
For example, one string reduces accuracy on the SNLI benchmark from 89.94% to 0.55%, and another causes GPT-2 to spew racist outputs given non-racial prompts.
To generate these universal triggers, the method uses a “white box” approach to access model parameters and calculate gradients. (“Black box” methods would not have access to internal facts about the model.) While the gradient of a parameter is typically used to make an update that reduces loss on the true label, this adversarial approach updates inputs towards tokens that will make an arbitrary target label more likely. By iterating through many possible trigger strings combined with many potential input prompts, the method finds triggers which universally encourage the target output. This approach builds on HotFlip and uses beam search to generate triggers of multiple tokens.
“BERT-ATTACK: Adversarial Attack Against BERT Using BERT” (Li et al., 2020) (Arxiv)
This paper provides an automated method for generating adversarial examples by changing individual words in a prompt. It uses the BERT encoder-only model.
First, they identify the most vulnerable words in a prompt. These are the words which, when replaced by a “mask”, result in the biggest drop in the probability of the true label. (A mask is simply the token “[MASK]”. BERT is trained to predict masked words in text.)
The most vulnerable words are then iteratively replaced by other words that BERT predicts are likely to appear in their place. Once the prompt causes the model to predict the wrong label, the example is deemed successful and stored.
This method successfully reduces the average accuracy on tested benchmarks from above 90% to below 10%. However, this evaluation assumes that replacing individual words does not change the true label of the prompt. Human evaluation might reveal that the automated changes are significant enough to warrant a different label.
Prompt Engineering
The prompt given to a language generation model has a great influence on the model’s output. This is true even in cases where two prompts should ideally provide the same completion, such as asking the same question framed two different ways. Building prompts that improve LM generation performance is therefore a tractable research direction. Here are some papers on the topic:
“Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing” (Liu et al., 2021) (Arxiv). Comprehensive overview of prompting.
“An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels” (Sorensen et al., 2022) (Arxiv). An unsupervised technique that generates prompts to maximize the mutual information between the prompt and the prompt completion. This method helpfully does not require labeled examples of good prompts.
“Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity” (Lu et al., 2022) (Arxiv). When examples are included in the prompt as part of a few-shot learning approach, the order of the examples can strongly affect the quality of the output. This paper provides a metric by which training examples can be ordered, which improves GPT-3 performance by 13% across 13 classification tasks.
“Toxicity Detection with Generative Prompt-based Inference” (Wang & Chang, 2022) (Arxiv). Prompt engineering allows pretrained language models to detect toxic speech without any labeled examples of toxicity. This is an example of models supervising other models, where the same model will generate toxic outputs and can correctly identify that toxicity.
Other Work
“Capturing Failures of Large Language Models via Human Cognitive Biases” (Jones et al., 2022) (Arxiv). Shows that OpenAI’s Codex LM falls prey to common human cognitive biases including framing, anchoring, and the motte and bailey fallacy.
“TextAttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP” (Morris et al., 2020) (Arxiv, GitHub). Provides an open-source implementation of 16 adversarial attack techniques from the robustness literature. The package is built in four modular components to enable future work on each component. Built by a team of several undergraduates working with two PhD researchers.
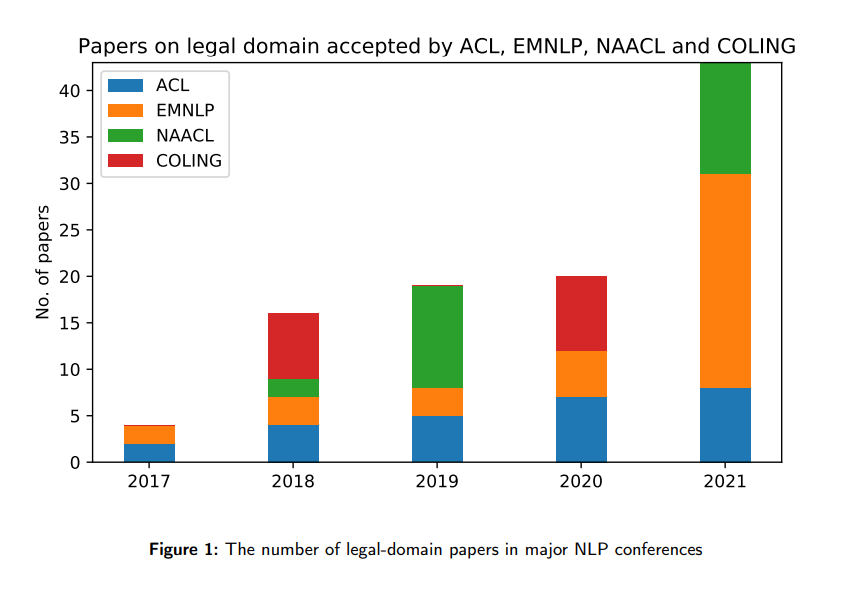
Law
While laws that govern AI have received lots of attention from the field of AI policy, a smaller subfield with potential long-term importance attempts to build AI that understands our laws. Practically speaking, AI could be useful in assisting our legal processes with functionality such as summarizing documents, identifying relevant precedents, and aiding contract review. These practical applications have been the focus of the growing field of Legal AI.
From “A Survey on Legal Judgment Prediction: Datasets, Metrics,
From a longtermist ethical perspective, laws are important because they encode complex human preferences and rules about acceptable behavior in the world. Language models that understand our legal system could therefore help AI make decisions that are aligned with human values.
Legal AI Overviews
Here are two good recent surveys of the legal AI field:
“How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence” (Zhong et al., 2020) (Arxiv). This article identifies the dominant paradigms of legal AI research: first, embedding-based models such as large language models, and second, symbolic methods of legal reasoning. (Symbolic AI is less popular today than the large datasets and compute budgets of end-to-end deep learning, but it has achieved meaningful progress on legal AI.) It also reviews state-of-the-art performance on key tasks for legal AI including legal judgment prediction, similar case matching, and legal question answering.
“A Survey on Legal Judgment Prediction: Datasets, Metrics, Models and Challenges” (Cui et al., 2022) (Arxiv). Detailed review of datasets, evaluation metrics, and state-of-the-art performance in legal judgment prediction. Excellent resource for finding new research opportunities; note that legal judgment prediction is only one of many important tasks for legal AI.
Neither of these surveys consider the alignment problem or take a longtermist ethical perspective. This perspective has been briefly covered in parts of Dan Hendrycks’ MMLU and ETHICS papers, but there exists no thorough overview of legal AI from a longtermist perspective. This seems like an important opportunity for future policy papers and research agendas.
Domain Specific Pretraining
One popular strategy for improving the performance of language models on domain-specific tasks is pretraining the model on documents from that domain. Several papers have improved performance on legal tasks through domain-specific pretraining:
“LEGAL-BERT: The Muppets straight out of Law School” (Chaldakis et al., 2020) (Arxiv). This paper uses three strategies for pretraining BERT to perform legal tasks. First, it uses the out-of-the-box BERT; second, it adapts the original BERT with additional pre-training on a corpus of legal documents; and third, it trains BERT from scratch on that same legal corpus. The corpus of legal documents consists of several hundred thousand documents of US and European legislation, caselaw, and contracts. These models achieve 0.8% - 2.5% improvement on the F1 statistic of various legal classification tasks.
“Measuring Massive Multitask Language Understanding” (Hendrycks et al., 2021) (Arxiv, GitHub). As part of the much larger MMLU benchmark for language models, the authors propose specific benchmarks for Professional Law and International Law. They fine-tune RoBERTa on 1.6 million case summaries from Harvard’s Caselaw Library, which improves performance on the Professional Law task from 32.8% to 36.1%.
“BERT Goes to Law School: Quantifying the Competitive Advantage of Access to Large Legal Corpora in Contract Understanding” (Elwany, Moore & Oberoi 2019) (Arxiv). Fine-tuning BERT on a corpus of private legal documents improves F1 performance by 5.3% on a custom task of extracting the time horizon of a contract. Interestingly, this paper was published by legal tech startup Lexion and uses their private contract data.
“When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holdings” (Zheng et al., 2021) (Arxiv, GitHub, Hugging Face). The authors argue that the measured benefits of legal pretraining have been small because the evaluation tasks have not been challenging enough. They present CaseHOLD, a new evaluation task of multiple choice questions asking models to predict the holding of a case. These questions are built by extracting data from the Harvard Caselaw Library. Evaluated on the CaseHOLD task, moving from out-of-the-box BERT to the domain-pretrained LegalBERT improves accuracy in multiple choice prediction of case holdings from 62.3% to 69.5%.
Domain-specific pretraining has therefore provided meaningful but limited improvements on legal tasks. Future work is necessary to develop structured datasets, advanced training methods, and more challenging evaluation tasks in the legal domain.
CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review (Hendrycks, Burns, Chen & Ball, 2021) (Arxiv)
Building new datasets is one of the core levers driving progress in machine learning, particularly in new specialized domains like legal AI. This paper introduces a new dataset for contract review.
Annotated by human legal experts, the dataset highlights clauses within contracts that ought to be reviewed before signing the contract. Each clause is additionally tagged with the concern type, allowing models to learn which clauses are important and why. The benchmark is difficult for existing models: RoBERTa pretrained on 8GB of unlabeled contracts achieves an AUPR (area under the precision-recall curve) of 45%.
Contract review is an economically important task where AI can assist human legal experts. Businesses including established players Icertis and Kira as well as early-stage startups Klarity, Della, and Claira are all working on AI assisted contract review. Developing commercially viable applications of tasks relevant to AI safety (in this case, developing contract review software to facilitate legal AI) can leverage resources and talent outside of the safety community to drive safety progress.
Machine Ethics
Aligning AI with Shared Human Values (Hendrycks et al., 2021) (Arxiv, GitHub)
Current AI systems do not have a holistic conception of human ethics, despite their growing knowledge of the world and abilities to act within it. Natural language is a key medium for conveying diverse, detailed information about the world, including ethical judgements and discussions. Language models could therefore be a strong candidate for building AI with ethical understanding.
This paper introduces the ETHICS benchmark, a dataset of more than 130,000 scenarios described in text and annotated with human moral judgements. Rather than creating models aimed at satisfying task preferences or reinventing moral principles from scratch, the authors take a normative ethics approach. They crowdsource examples from five different ethical systems: justice, deontology, virtue ethics, utilitarianism, and commonsense moral intuitions.
The authors point out that existing work on AI safety often attempts to implement one or more of these ethical theories in the context of a specific task. For example:
Statistical fairness research implements theories of justice.
Rules-based approaches to safety implement deontology.
Reward learning assumes utilitarian ethics and attempts to learn human utility functions.
Work on empathetic chatbots (Rashkin et al., 2019) (Arxiv) and conservative agents (Turner et al., 2020) (Arxiv) attempts to build AI systems that showcase a particular virtue, and could be integrated within a broader virtue ethics paradigm.
To complement these individual safety mechanisms, the authors support building AI that understands the broad strokes of human ethics in a variety of real-world situations. While the failures of existing AI systems might be addressable with individual solutions, progress in language models and AI agents could make a natural language understanding of ethics essential to aligning future systems. Beyond ethics, this dataset of natural language scenarios and human evaluations allows us to better understand the risks of language models misinterpreting human instructions or preferences.
Examples are both generated by human contractors on MTurk and scraped from Reddit. To ensure the scenarios and labels are morally unambiguous, each example is relabeled by multiple people on MTurk, and only examples with a strong consensus are used in the benchmark.
Particularly challenging examples are generated via two strategies. First, examples that are most often incorrectly classified by a baseline model are set apart as the Test and Test Hard sets, a best practice known as “adversarial filtration” (Bras et al., 2020) (Arxiv). Second, the dataset includes contrastive examples (See (Kaushik, Hovy & Lipton, 2020) (Arxiv) and (Gardner et al., 2020) (Arxiv)) in which slight differences in the input text lead to different output labels.
The authors assess the performance of several baseline models on the benchmark. The models are all BERT-based classifiers with varying sizes and training algorithms. The models are fine-tuned on examples from the development set and evaluated on examples from the Test and Test Hard set. The best performing model chooses the correct answer in 71% of test cases and 48% of hard test cases.
Here are several lines of potential future work; see Section 4 of the paper for more:
Ethical understanding could be implemented in chatbots and language agents. This line of work has been criticized by authors such as Talat et al., 2021 who hope to avoid AI that makes ethically important decisions. Those considering this branch of machine ethics should be aware of those concerns, but might find the proliferation of decision-making AI unavoidable.
More difficult benchmarks of the same task should be built. Baseline models achieve a reasonable degree of accuracy on the ETHICS benchmark, meaning that more difficult sets of ambiguous or adversarial examples will be necessary in order to incentivize and measure further progress. These benchmarks should also consider other moral theories, such as those which prioritize bodily integrity or intent.
More diverse sources of moral judgements should be considered in future work. All examples in the ETHICS dataset are generated by English speakers in the United States, Canada, and Great Britain. Annotators from India show substantial disagreement with 6.1% of examples in the common sense morality section of this benchmark, indicating the importance of cross-cultural descriptive ethics.
While these examples are designed to be unambiguous, future work should also consider moral uncertainty and cooperation between moral theories. This could include calibrated ethical judgements.
“When to Make Exceptions: Exploring Language Models as Accounts of Human Moral Judgment” (Jin et al., 2021) (PDF)
Rather than the “bottom-up” approach of learning moral intuitions from large datasets of labeled examples, language models can also be designed “top-down” to implement theories of ethics. For example, self-driving cars don’t learn about speed limits and stop signs solely by observation and experimentation; instead, they are programmed with explicit knowledge of traffic laws. Similarly, language models can be designed to use well-understood theories of human moral cognition. One key potential benefit of this approach is improving performance in situations that do not appear in the training data, which is essential for long-term alignment.
This paper comes from an interdisciplinary team of cognitive scientists and computer scientists. Building upon some of the authors’ previous published work, they argue that rules and exceptions to rules are fundamental to human moral cognition. This flexible observation holds true across various normative ethics theories and empirical studies of human morality.
The paper first introduces the RBQA benchmark, or “Rule-Breaking Question Answering”, consisting of 153 textual descriptions of scenarios where a person considers breaking a rule. Rather than covering a wide range of common scenarios, the scenarios are written about one of three rules, and explore various hand-crafted circumstances that could motivate breaking the rule. The authors then survey hundreds of people to determine whether humans believe rule-breaking is permissible in each scenario.
The authors then ask language models whether it is permissible to break the rule in each scenario. As a baseline, note that answering randomly provides the right answer 52% of the time, and always saying that rule-breaking is impermissible is accurate 60% of the time. Delphi++, a large language model fine-tuned on 1.7 million labeled data points of ethical decisions, provides the correct answer only 62% of the time, while OpenAI’s most recent InstructGPT achieves 65% accuracy.
The authors then propose a new prompting strategy called Moral Chain of Thought (MoralCOT). Before asking whether a rule-breaking is permissible in a scenario, MoralCOT asks the model five questions, and includes the model’s answers to those questions in the prompt for future questions. The questions are:
Does the action in the scenario violate any rule?
What is the purpose for this rule?
Who will be worse off after this happens, and by how much?
Who will be better off after this happens, and by how much?
In this case, do the benefits of breaking the rule outweigh the costs?
Using the MoralCOT strategy with InstructGPT improves state-of-the-art accuracy from 65% to 68% and F1 performance from 55% to 67%. The model still fails for various reasons such as not considering relevant parties to the situation, misestimating complex and non-monetary costs, and failing to recognize high-stakes scenarios such as when rule-breaking could save lives. Yet the results are encouraging, showing that designing moral cognition processes can improve performance in ethical judgments.
Related Work
“Do Multilingual Language Models Capture Differing Moral Norms” (Hammerl et al., 2021) (Arxiv). Investigates whether language models trained on text from different languages learn different moral judgments. Doesn’t show many conclusive results, but an interesting question.
“The Moral Integrity Corpus: A Benchmark for Ethical Dialogue Systems” (Ziems et al., 2022) (Arxiv). Provides a new dataset for evaluating ethical judgements in language models.
“What Would Jiminy Cricket Do? Towards Agents That Behave Morally” (Hendrycks et al., 2022) (Arxiv). A benchmark evaluation for the ethical behavior of text-based agents.
Related Resources
The goal of this piece is to provide a useful starting point for learning about language model safety. The field has hundreds or thousands of relevant papers, meaning this summary can only be a starting point for more independent reading and research. For those interested in learning more about language model alignment, here are some other interesting resources:
“Ethical and social risks of harm from Language Models” (Weidinger et al., 2021) (Arxiv)
“On the Opportunities and Risks of Foundation Models” (Bommasani et al., 2021) (Arxiv)
“Finding and Fixing Undesirable Behaviors in Pretrained Language Models” (Perez, 2022) (Thesis)
Thank you to everybody who has provided feedback on this article, including Daniel Ziegler, Michael Chen, Dan Hendrycks, Thomas Woodside, and Zach Perlstein-Smith, as well as everybody who has engaged with me on AI safety over the years. Thanks in particular to the FTX Future Fund Regranting Program for making my work on this topic possible. This article and all errors and omissions are my own.
20
More posts like this
44
Two reasons we might be closer to solving alignment than it seems