Comments
If the ideas in “moral ~realism”[1] and/or “beyond Maxipok”[2] are broadly correct, this has implications for AI strategy. (Like those posts, this is largely getting some old imperfect ideas out of the door with a little polishing; again the ideas owe credit to conversations and comments from several people.)
I want to draw out three threads:
- It may be important to try to get AI that can help humanity to enter into the basin of good reflective governance
- This makes applications like facilitating wisdom, cooperation, and reflective processes a relatively higher strategic priority for AI systems
- A plausible target for AI alignment could be to align with the good (i.e. get the AI systems into the basin of good reflective governance) rather than aligning with humans
- In practice this is scary as a possibility, because it might not fail gracefully
- However, it’s prima facie plausible that it’s easier to build a system which aligns with the good rather than aligning with humans. If this is the case, we might prefer not to cut off the possibility of good outcomes by chasing after the too hard task
- Even if we don’t reach enough confidence in that approach to prefer trying to align systems with the good as a primary goal, we might still want to use it to give a backup saving throw on AI alignment
- Roughly: “Give your superintelligent servants the rudiments of a moral education so that if they do in some weird plot twist end up in control, there’s still a chance they work out the right thing to do”
- There are a lot of details to be worked out here, and maybe it ends up wildly impractical; its appeal is because it seems like a fairly orthogonal line of attack from keeping systems corrigible
- This should be more appealing the harder you think aligning with humans is
- Honestly this still feels pretty speculative (moreso than 1 or 2), but at this point I've been sitting on the idea for a couple of years without either having persuaded myself that it's a good idea or that it isn't, so I'll just share it as-is
- Roughly: “Give your superintelligent servants the rudiments of a moral education so that if they do in some weird plot twist end up in control, there’s still a chance they work out the right thing to do”
Helping humans coordinate/reflect
Getting to the basin of good reflective governance may be tricky (humanity doesn’t seem to have managed it to date, at least in anything like a robust way). It’s possible that AI capabilities coming online could help this, in strategically important ways.
Strategically desirable capabilities
My top choices for important capabilities to develop from this perspective are:
- Automated negotiation
- Learning the principal’s preferences and then handling negotiations with others (initially low-stakes ones?) could significantly increase coordination bandwidth
- Automation of identifying wise actions, and/or automation of philosophical progress (for which we may need better metaphilosophy)
- If we can improve the thinking of individual human actors, we could lower the barriers for entering into the basin of good reflective governance
- Highly truthful AI
- Very trustworthy systems could serve as reliable witnesses without leaking confidential information, thereby increasing trust and ability to coordinate and make commitments
- Personal AI assistants
- Summarizing and helping people to digest complex information (improving their models of the world)
- Eventually could also implement the “automated negotiation” and “high trustworthy witness” capabilities deployed on a personal level, but I guess that the early uses for those capabilities won’t be as personal assistants
- However, I guess this is the least important of these three to prioritize, in part because I expect market forces to lead to significant investment in it anyway
Taking humans out of the loop slowly not abruptly
Here’s a related perspective on this piece of things — supporting the conclusion that AI applications to support coordination/cooperation should be a priority.
Currently large actors in the world are not super coherent. I think AI will lead to more coherent large actors. There are multiple ways we could get there. A single controlling intelligence could be a superintelligent AI system (perhaps aligned with some human principal, or perhaps not). Or we could get better at getting coherent action from systems with many people and no single controlling intelligence.
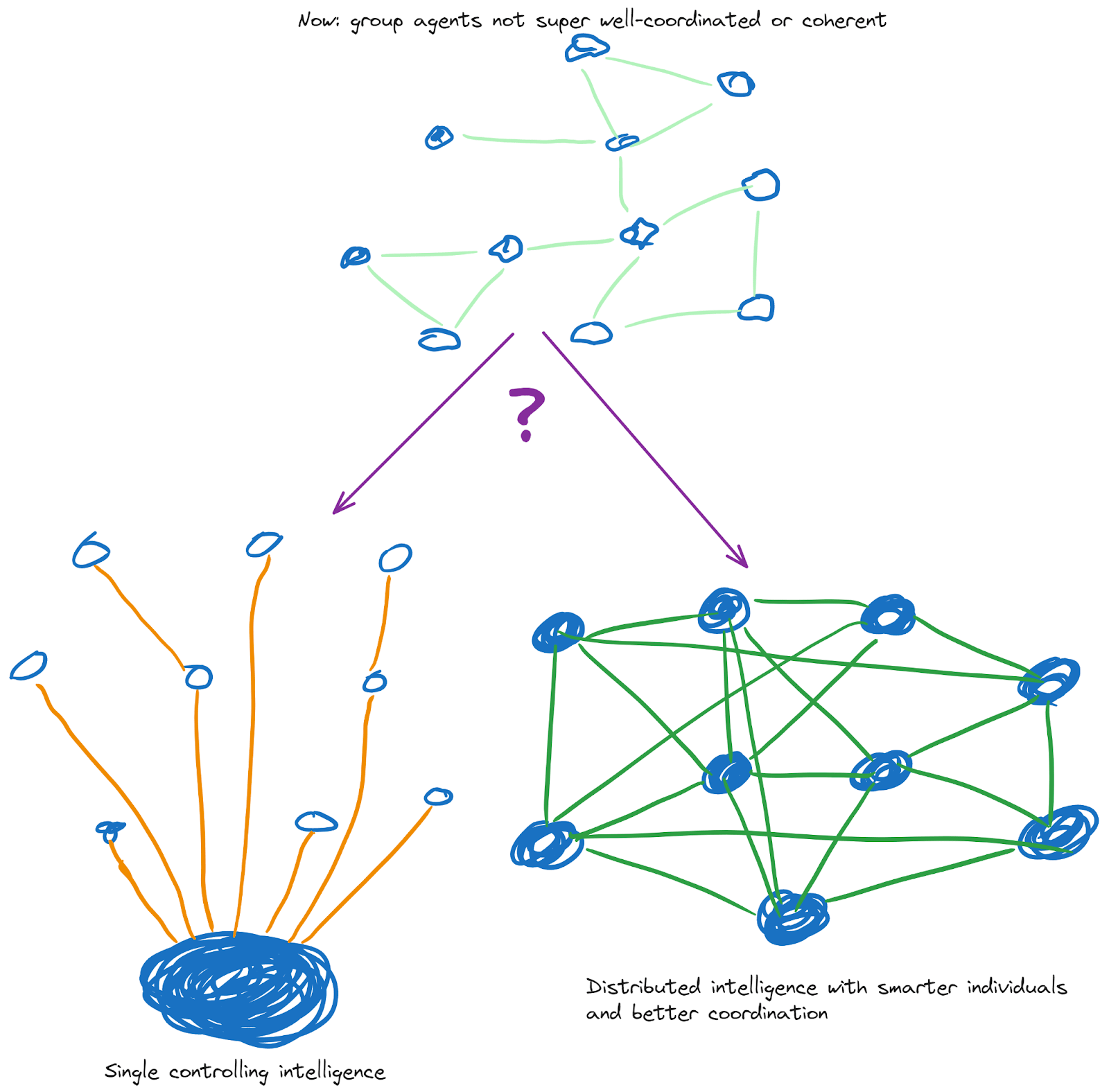
Paths which go through empowering many people to make them smarter and better at coordinating seem safer to me. (Perhaps longer-term they coordinate and choose to hand off to a single controlling intelligence, but in that case the transition into a basin of reflection has come before that hand-off rather than accidentally when the hand-off occurs, which limits the downside risk.)
I think this remains true at limited scales. Even if we can’t get a grand bargain involving 8 billion people, a solution coordinated across 100,000 people is better than a solution coordinated across 100 people.
Convergent morality as a solution to alignment?
If the straightforward case for convergent morality goes through, then we’d get good outcomes from putting the future in the hands of any agent or collective with a good-enough starting point (i.e. in the basin of good reflective governance). I think that the key thing you’d need to instill would be the skill of moral reflection, and then to embed this as a core value of the system. I don’t know how one would do this … or rather, I guess it might be relatively straightforward to train systems to do moral reflection in easy cases, and I don’t know how you could reach anything like confidence that it would stay working correctly as the system scaled to superintelligence. I do have the intuition that moral reflection is in some meaningful sense simpler than values.
You’d also need to provide reasonable starting points for the moral reflection. I think two plausible strategies are:
- Just provide pointers to things humans value (in some ways similar to how we go with kids); perhaps when combined with skill at moral reflection this can be used to infer what’s really valued
- Comes with some risk that we failed to provide pointers to some important components (although we can potentially throw a lot of writing + people talking about what they value at it)
- Provide pointers to the idea of “evolved social intelligence”
- I don’t know how to do this, but it seems like it’s probably a pretty prominent phenomena in the multiverse, so should have some short K-complexity description
- Comes with some risk that evolved social aliens wouldn’t converge to the same morality as us
Providing backup saving throws
Rather than gamble directly on aligning with the good (which seems pretty shaky to me), can we first try to align things with humans, but have it arranged such that if that fails, we’re not necessarily doomed?
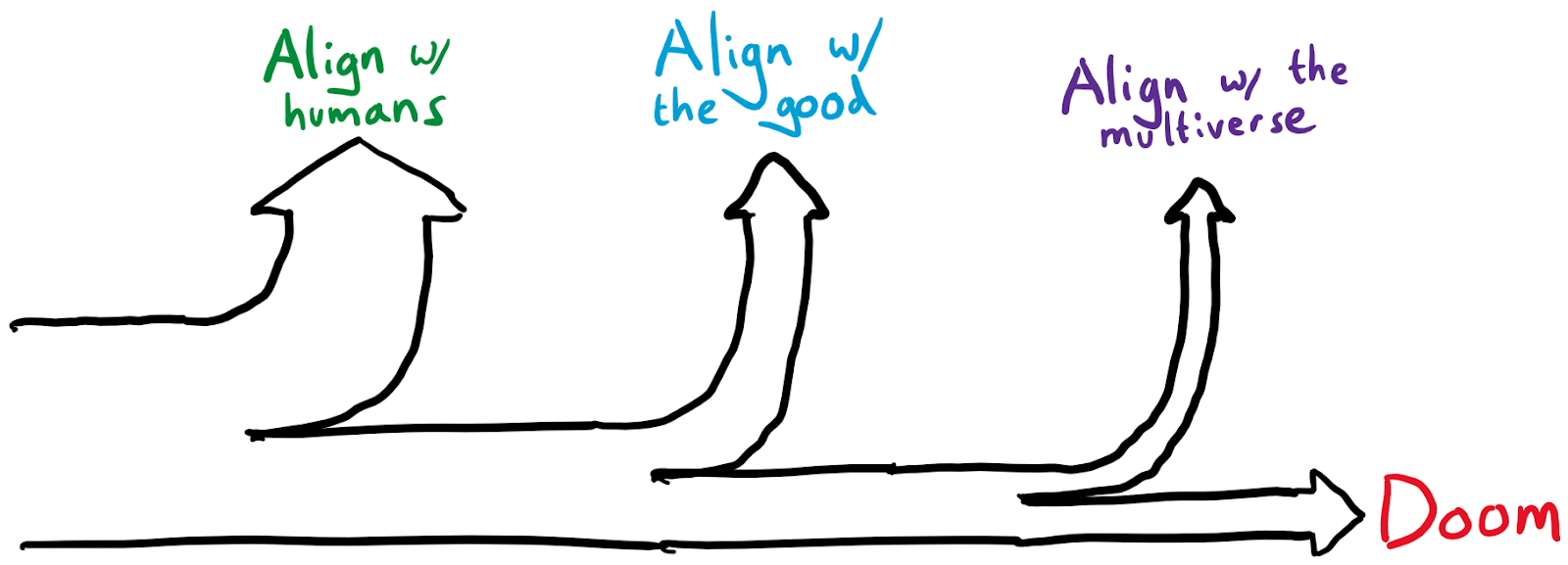
I think in principle, sure. We can build the types of agents that would ultimately engage in ECL or acausal trade with the multiverse (if that turns out to work properly), whose goals if left to themselves would be a product of moral reflection from some reasonable starting point, but whom in practice we ask to be deeply corrigible and take actions aligned with humans, such that their own personal sense of the good doesn’t end up mattering.
In practice there are a number of potential barriers to arranging this:
- Not knowing how to do it at all
- Right now this is where we are, although I think we could invest significantly in trying to work that out (and shouldn’t write it off before such investment)
- Possibility that it makes aligning with humans harder
- This is the issue that seems most concerning to me
- The basic issue is that adding motivations could cut against or undermine existing motivations. e.g. perhaps morality motives call for violating corrigibility in some circumstances
- (Although in some cases a lack of alignment with users may be desirable. We probably don’t want AI systems to help people commit murders. It’s possible that there are some versions of “aligning with the good” that we’d feel straightforwardly happy about adding to systems which are primarily aimed to be aligned with users)
- Political costliness
- Presumably there’s something like extra safety tax to be paid to have many/all sufficiently powerful systems have our attempt at a moral education
- If the tax isn’t exorbitant, perhaps could rally support for it via traditional AI risk narratives — “moral education for AI” is a legible story given pop sci-fi


Executive summary: If moral realism and the possibility of good reflective governance are correct, this has implications for AI strategy, including prioritizing AI applications that facilitate wisdom, cooperation, and reflection, and potentially aligning AI with "the good" rather than just with humans.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.