All of Aaron Bergman's Comments + Replies
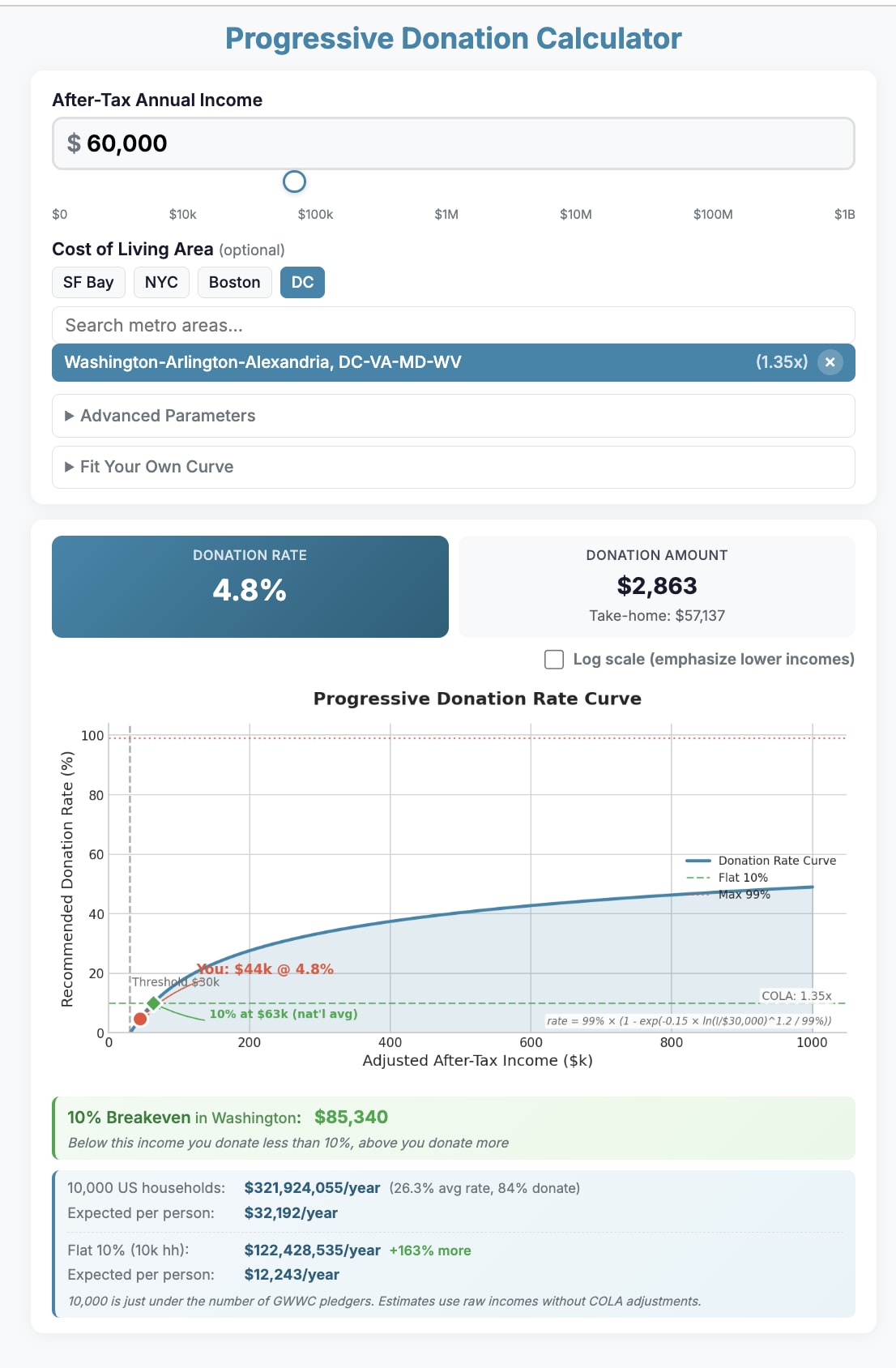
I made a tool to play around with how alternatives to the 10% GWWC Pledge default norm might change:
- How much individuals are "expected" to pay
- The idea being that there are functions of income that people would prefer to the 10% pledge behind some relevant veil of ignorance, along the lines of "I don't want to commit 10% of my $30k salary, but I gladly commit 20% of my $200k salary"
How much total donation revenue gets collected
There's some discussion at this Tweet of mine
Some folks pushed back a bit, citing the following:
- The pledge isn't supposed to
New interview with Will MacAskill by @MHR🔸
Almost a year after the 2024 holiday season Twitter fundraiser, we managed to score a very exciting "Mystery EA Guest" to interview: Will MacAskill himself.
- @MHR🔸 was the very talented interviewer and shrimptastic fashion icon
- Thanks to @AbsurdlyMax🔹 for help behind the scenes
- And of course huge thanks to Will for agreeing to do this
Summary, highlights, and transcript below video!

Summary and Highlights
(summary AI-generated)
Effective Altruism has changed significantly since its inception. With the ...
I strongly endorse this and think that there are some common norms that stand in the way of actually-productive AI assistance.
- People don't like AI writing aesthetically
- AI reduces the signal value of text purportedly written by a human (i.e. because it might have been trivial to create and the "author" needn't even endorse each claim in the writing)
Both of these are reasonable but we could really use some sort of social technology for saying "yes, this was AI-assisted, you can tell, I'm not trying to trick anyone, but also I stand by all the claims made in the text as though I had done the token generation myself."
I think I'm more bullish on digital storage than you.
...Most alignment work today exists as digital bits: arXiv papers, lab notes, GitHub repos, model checkpoints. Digital storage is surprisingly fragile without continuous power and maintenance.
SSDs store bits as charges in floating-gate cells; when unpowered, charge leaks, and consumer SSDs may start losing data after a few years. Hard drives retain magnetic data longer, but their mechanical parts degrade; after decades of disuse they often need clean-room work to spin up safely. Data centres depend on air-c
Wanted to bring this comment thread out to ask if there's a good list of AI safety papers/blog posts/urls anywhere for this?
(I think local digital storage in many locations probably makes more sense than paper but also why not both)
Lightcone and Alex Bores (so far)
Edit: to say a tiny bit more, LessWrong seems instrumentally good and important and rationality is a positive influence on EA. Lightcone doesn't have the vibes of "best charity" to me, but when I imagine my ideal funding distribution it is the immediate example of "most underfunded org" that comes to mind. Obviously related to Coefficient not supporting rationality community building anymore. Remember, we are donating on the margin, and approximately the margin created by Coefficient Giving!
Edit: And Animal Welfare Fund
Super cool - a bit hectic and I substantively disagree with one of the "fallacies" the fallacy evaluator flagged on this post but I'll definitely be using this going forward
Thanks for the highlight! Yeah I would love better infrastructure for trying to really figure out what the best uses of money are. I don't think it has to be as formal/quantitative as GiveWell. To quote myself from a recent comment (bolding added)
...At some level, implicitly ranking charities [eg by donating to one and not another] is kind of an insane thing for an individual to do - not in an anti-EA way (you can do way better than vibes/guessing randomly) but in a "there must be better mechanisms/institutions for outsourcing donation advice than GiveWell an
I did something related but haven't updated it in a couple years! If there's a good collection of AI safety papers/other resources/anything anywhere it would be very easy for me to add it to the archive for people to download locally, or else I could try to collect stuff myself
List [not necessarily final!]
1. ClusterFree
2. Center for Reducing Suffering
3. Arthropoda Foundation
4. Shrimp Welfare Project
5. Effective Altruism Infrastructure Fund
6. Forethought Foundation
7. Wild Animal Initiative
8. Center for Wild Animal Welfare
9. Animal Welfare Fund
10. Aquatic Life Institute
11. Longview Philanthropy's Emerging Challenges Fund
12. Legal Impact for Chickens
13. The Humane League
14. Rethink Priorities
15. Centre for Enabling EA Learning & Research
16. MATS Research
Methodology
I used AI for advice (unlike last year) with Claude-Opus-4.5 and...
I do not accept premise 2:
For some small amount of intense suffering, there is always some sufficiently large amount of moderate suffering such that the intense suffering is preferable.
To be clear, I think this premise is one way of distilling and clarifying the (or 'a') crux of my argument and if I wind up convinced that the whole argument is wrong, it will probably be because I am convinced of premise 2 or something very similar
Wow, this is super exciting and thanks so much to the judges! ☺️
An interesting dynamic around this competition was that the promise of the extremely cracked + influential judging team reading (and implicitly seriously considering) my essay was a much stronger incentive for me to write/improve it than the money (which is very nice don’t get me wrong).[1]
I’m not sure what the implications of this are, if any, but it feels useful to note this explicitly as a type of incentive that could be used to elicit writing/research in the future
- ^
Insofar as I’m not total
Interesting, thanks! I might actually sign up for the Arctic Archive thing! I don't see you mention m-discs like this - any reason for that?
Also, do you have any takes on how many physical locations a typical X is stored in, for various X?
X could be:
- A wikipedia page
- An EA Forum post
- A YouTube video
- A book that's sold 100/1k/10k/100k/1M copies
- Etc
After thinking about this post ("Utilitarians Should Accept that Some Suffering Cannot be “Offset”") some more, there's an additional, weaker claim I want to emphasize, which is: You should be very skeptical that it’s morally good to bring about worlds you wouldn’t personally want to experience all of
We can imagine a society of committed utilitarians all working to bring about a very large universe full of lots of happiness and, in an absolute sense, lots of extreme suffering. The catch is that these very utilitarians are the ones that are going to be expe...
I disagree but think I know what you're getting at and am sympathetic. I made the following to try to illustrate and might add it in to the post if it seems clarifying
I made it on a whim just now without thinking too hard so don't necessarily consider the graphical representation on as solid footing as the stuff in the post
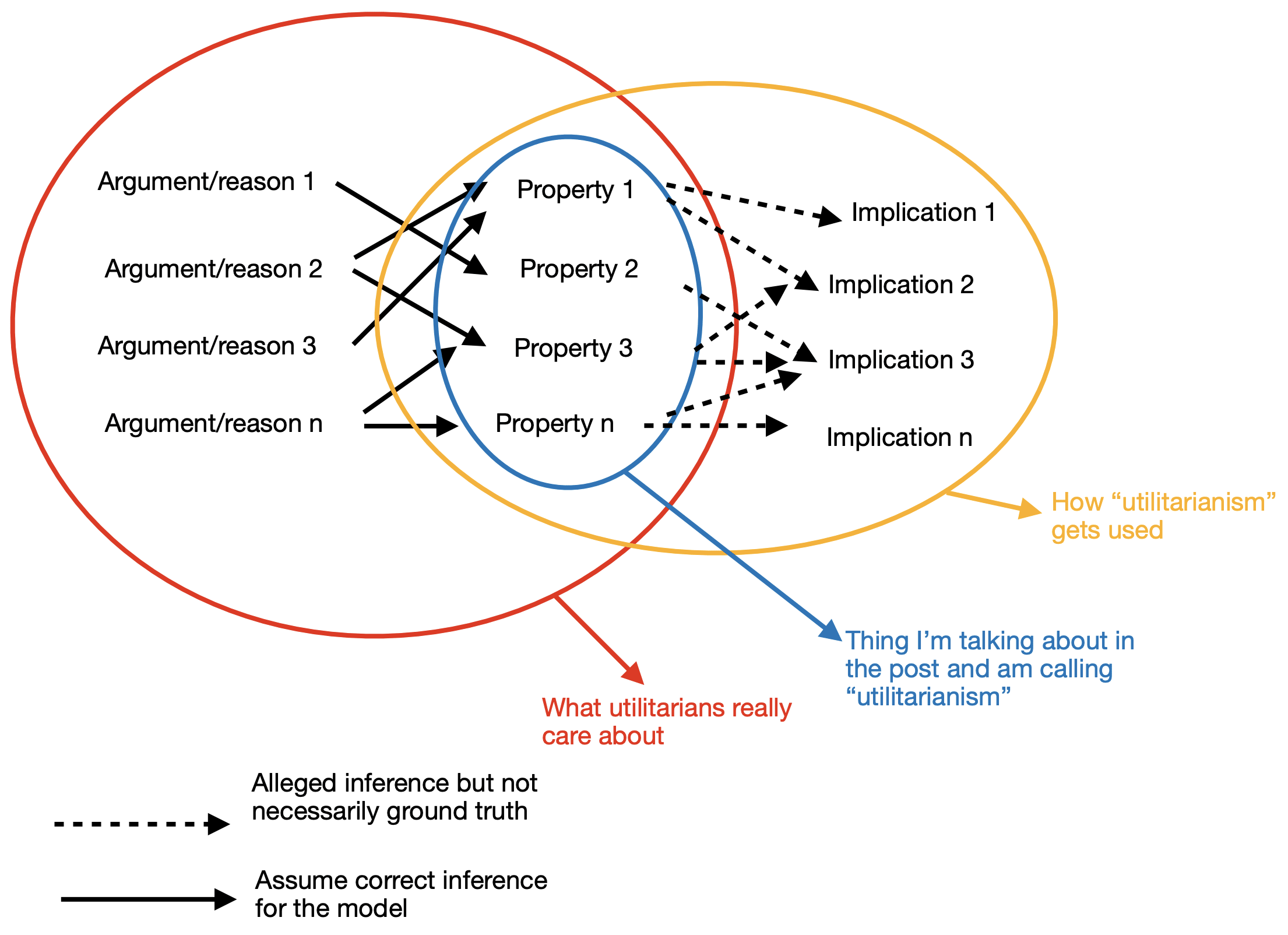
Thanks!
(Ideal): annihilation is ideally desirable in the sense that it's better (in expectation) than any other remotely realistic alternative, including <detail broadly utopian vision here>. (After all, continued existence always has some chance of resulting in some uncompensable suffering at some point.)
Yeah I mean on the first one, I acknowledge that this seems pretty counterintuitive to me but again just don't think it is overwhelming evidence against the truth of the view.
Perhaps a reframing is "would this still seem like a ~reductio conditional...
Thanks, yeah I may have gotten slightly confused when writing.
1) VNM
Wikipedia screenshot:

Let P be the thing I said in the post:
If A ≻ B ≻ C, there's some probability p ∈ (0, 1) where a guaranteed state of the world B is ex ante morally equivalent to "lottery p·A + (1-p)·C”
or, symbolically
and let
I think but not in general.
So my writing was sloppy. Super good catch (not caught by any of the various LLMs iirc!)
But for the purposes of the...
I am getting really excellent + thoughtful comments on this (not just saying that) - I will mention here that I have highly variable and overall reduced capacity for personal reasons at the moment, so please forgive me if it takes a little while for me to respond (and in the mean time note that I have read stuff so they're not being ignored) 🙂
Great points both and I agree that the kind of tradeoff/scenario described by @EJT and @bruce in his comment are the strongest/best/most important objections to my view (and the thing most likely to make me change my mind)
Let me just quote Bruce to get the relevant info in one place and so this comment can serve as a dual response/update. I think the fundamentals are pretty similar (between EJT and Bruce's examples) even though the exact wording/implementation is not:
...A) 70 years of non-offsettable suffering, followed by 1 trillion happy huma
I don’t bite the bullet in the most natural reading of this, where very small changes in i_s do only result in very small changes in subjective suffering from a subjective qualitative POV. Insofar as that is conceptually and empirically correct, I (tentatively) think it’s a counterexample that more or less disproves my metaphysical claim (if true/legit).
Going along with 'subjective suffering', which I think is subject to the risks you mention here, to make the claim that the compensation schedule is asymptotic (which is pretty important to your toplin...
Mostly for fun I vibecoded an API to easily parse EA Forum posts as markdown with full comment details based on post URL (I think helpful mostly for complex/nested comment sections where basic copy and paste doesn't work great)
I have tested it on about three posts and every possible disclaimer applies
Again I appreciate your serious engagement!
The positive argument for the metaphysical claim and the title of this piece relies (IMO) too heavily on a single thought experiment, that I don't think supports the topline claim as written.
Not sure what you mean by the last clause, and to quote myself from above:
...I don't expect to convince all readers, but I'd be largely satisfied if someone reads this and says: "You're right about the logic, right about the hidden premise, right about the bridge from IHE preferences to moral facts, but I would personally,
- I'm much more confident about the (positive wellbeing + suffering) vs neither trade than intra-suffering trades. It sounds right that something like the tradeoff you describe follows from the most intuitive version of my model, but I'm not actually certain of this; like maybe there is a system that fits within the bounds of the thing I'm arguing for that chooses A instead of B (with no money pumps/very implausible conclusions following)
Ok interesting! I'd be interested in seeing this mapped out a bit more, because it does sound weird to have BOS be offsett...
I made an audio version:
Also: Copy to clipboard as markdown link for LLM stuff
Assuming we're not radically mistaken about our own subjective experience, it really seems like pleasure is good for the being experiencing it (aside from any function or causal effects it may have).
In fact, pleasure without goodness in some sense seems like an incoherent concept. If a person was to insist that they felt pleasure but in no sense was this a good thing, I would say that they are mistaken about something, whether it be the nature of their own experience or the usual meaning of words.
Some people, I think, concede the above but want to object t...
I'm continually unsure how best to label or characterize my beliefs. I recently switched from calling myself a moral realist (usually with some "but its complicated" pasted on) to an "axiological realist."
I think some states of the world are objectively better than others, pleasure is inherently good and suffering is inherently bad, and that we can say things like "objectively it would be better to promote happiness over suffering"
But I'm not sure I see the basis for making some additional leap to genuine normativity; I don't think things like objective or...
Alastair Norcross is a famous philosopher with similar views. Here's the argument I once gave him that seemed to convert him (at least on that day) to realism about normative reasons:
...First, we can ask whether you'd like to give up your Value Realism in favour of a relativistic view on which there's "hedonistic value", "desire-fulfilment value", and "Nazi value", all metaphysically on a par. If not -- if there's really just one correct view of value, regardless of what subjective standards anyone might arbitrarily endorse -- then we can raise the
I'm not an axiological realist, but it seems really helpful to have a term for that position, upvoted.
Broadly, and off-topic-ally, I'm confused why moral philosophers don't always distinguish between axiology (valuations of states of the world) and morality (how one ought to behave). People seem to frequently talk past each for lack of this distinction. For example, they object to valuing a really large number of moral patients (an axiological claim) on the grounds that doing so would be too demanding (a moral claim). I first learned these terms from https://slatestarcodex.com/2017/08/28/contra-askell-on-moral-offsets/ which I recommend.
Was sent a resource in response to this quick take on effectively opposing Trump that at a glance seems promising enough to share on its own:

From A short to-do list by the Substack Make Trump Lose Again:
...
- Friends in CA, AZ, or NM: Ask your governor to activate the national guard (...)
- Friends in NC: Check to see if your vote in the NC Supreme Court race is being challenged (...)
- Friends everywhere: Call your senators and tell them to vote no on HR 22 (...)
- Friends everywhere: If you’d like to receive personalized guidance on what opportunities are best su
Is there a good list of the highest leverage things a random US citizen (probably in a blue state) can do to cause Trump to either be removed from office or seriously constrained in some way? Anyone care to brainstorm?
Like the safe state/swing state vote swapping thing during the election was brilliant - what analogues are there for the current moment, if any?
~30 second ask: Please help @80000_Hours figure out who to partner with by sharing your list of Youtube subscriptions via this survey
Unfortunately this only works well on desktop, so if you're on a phone, consider sending this to yourself for later. Thanks!
Sharing https://earec.net, semantic search for the EA + rationality ecosystem. Not fully up to date, sadly (doesn't have the last month or so of content). The current version is basically a minimal viable product!

On the results page there is also an option to see EA Forum only results which allow you to sort by a weighted combination of karma and semantic similarity thanks to the API!
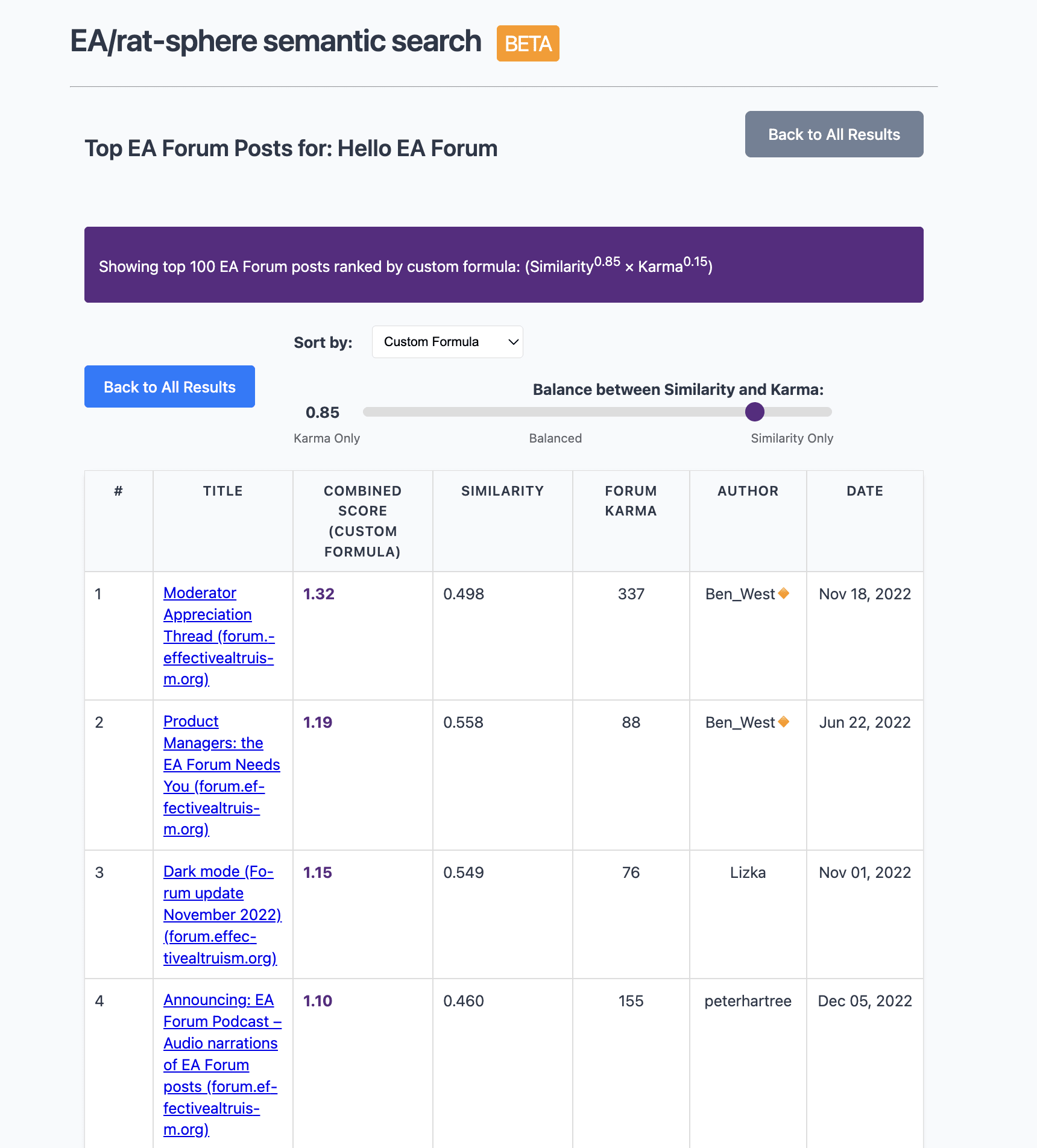
Final feature to note is that there's an option to have gpt-4o-mini "manually" read through the summary of each article on the current screen of results, which will give...
Christ, why isn’t OpenPhil taking any action, even making a comment or filing an amicus curiae?
I certainly hope there’s some legitimate process going on behind the scenes; this seems like an awfully good time to spend whatever social/political/economic/human capital OP leadership wants to say is the binding constraint.
And OP is an independent entity. If the main constraint is “our main funder doesn’t want to pick a fight,” well so be it—I guess Good Ventures won’t sue as a proper donor the way Musk is; OP can still submit some sort of non-litigant comment. Naively, at least, that could weigh non trivially on a judge/AG
[warning: speculative]
As potential plaintiff: I get the sense that OP & GV are more professionally run than Elon Musk's charitable efforts. When handing out this kind of money for this kind of project, I'd normally expect them to have negotiated terms with the grantee and memoralized them in a grant agreement. There's a good chance that agreement would have a merger clause, which confirms that (e.g.) there are no oral agreements or side agreements. Attorneys regularly use these clauses to prevent either side from getting out of or going beyond the nego...
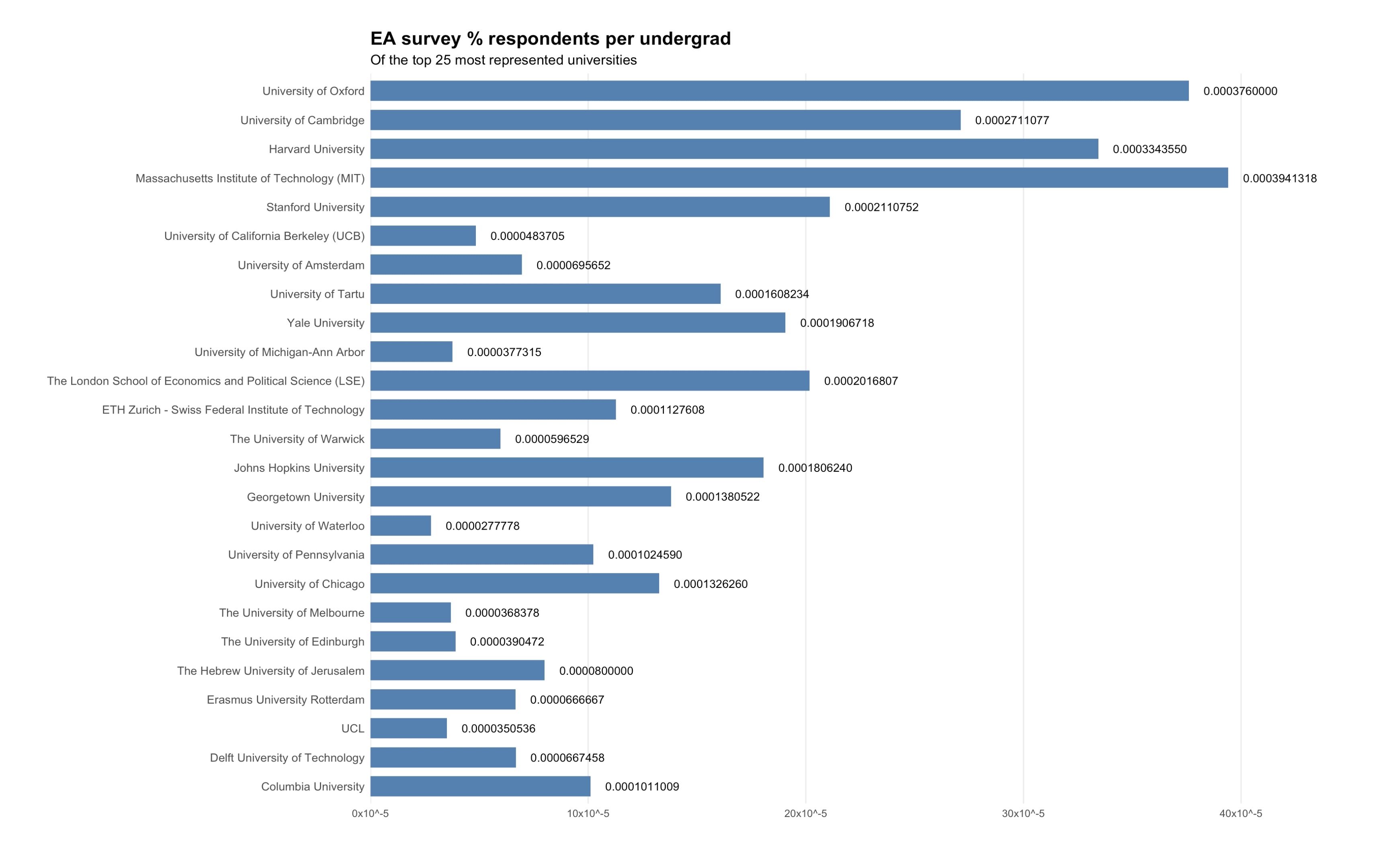
Reranking universities by representation in EA survey per undergraduate student, which seems relevant to figuring out what CB strategies are working (obviously plenty of confounders). Data from 1 minute of googling + LLMs so grain of salt
There does seem to be a moderate positive correlation here so nothing shocking IMO.

Same chart as above but by original order
Offer subject to be arbitrarily stopping at some point (not sure exactly how many I'm willing to do)
Give me chatGPT Deep Research queries and I'll run them. My asks are that:
- You write out exactly what you want the prompt to be so I can just copy and paste something in
- Feel free to request a specific model (I think the options are o1, o1-pro, o3-mini, and o3-mini-high) but be ok with me downgrading to o3-mini
- Be cool with me very hastily answering the inevitable set of follow-up questions that always get asked (seems unavoidable for whatever reason). I might say something like "all details are specified above; please use your best judgement"
I’ll just highlight that it seems particularly cruxy whether to view such NDAs as covenants or contracts that are not intrinsically immoral to break
It’s not obvious to me that it should be the former, especially when the NDA comes with basically a monetary incentive for not breaking
Here is a kinda naive LLM prompt you may wish to use for inspiration and iterate on:
“List positions of power in the world with the highest ratio of power : difficulty to obtain. Focus only on positions that are basically obtainable by normal arbitrary US citizens and are not illegal or generally considered immoral
I’m interested in positions of unusually high leverage over national or international systems”
It’s personal taste, but for me the high standards (if implicit) - not only in reasoning quality but also as you say, formality (and I’d add comprehensiveness/covering all your bases) are a much bigger disincentive to posting than dry/serious tone (which maybe I just don’t mind a ton).
I’m not even sure this is bad; possibly lower standards would be worse all things considered. But still, it’s a major disincentive to publishing.
@MHR🔸 @Laura Duffy, @AbsurdlyMax and I have been raising money for the EA Animal Welfare Fund on Twitter and Bluesky, and today is the last day to donate!
If we raise $3k more today I will transform my room into an EA paradise complete with OWID charts across the walls, a literal bednet, a shrine, and more (and of course post all this online)! Consider donating if and only if you wouldn't use the money for a better purpose!
See some more fun discussion and such by following the replies and quote-tweets here:
I was hoping he’d say himself but @MathiasKB (https://forum.effectivealtruism.org/users/mathiaskb) is our lead!
But I think you’re basically spot-on; we’re like a dozen people in a Slack, all with relatively low capacity for various reasons, trying to bootstrap a legit organization.
The “bootstrap” analogy is apt here because we are basically trying to hire the leadership/managerial and operational capacity that is generally required to do things like “run a hiring round,” if that makes any sense.
So yeah, the idea is volunteers run a hiring round, and my sen...
To expand a bit on the funding point (and speaking for myself only):
I’d consider the $15k-$100k range what makes sense as a preliminary funding round, taking into account the high opportunity cost of EA animal welfare funding dollars. This is to say that I think SFF could in fact use much more than that, but the merits and cost effectiveness of the project will be a lot clearer after spending this first $100k; it is in large part paying for value of information.
Again speaking for myself only, my inside view is that the $100k figure is too low of an upper bound for preliminary funding; maybe I’d double it.
Speaking for myself (not other coauthors), I agree that $15k is low and would describe that as the minimum plausible amount to hire for the roles described (in part because of the willingness of at least one prospective researcher to work for quite cheap compared to what I perceive as standard among EA orgs, even in animal welfare).
IIRC I threw the $100k amount out as a reasonable amount we could ~promise to deploy usefully in the short term. It was a very hasty BOTEC-type take by me: something like $30k for the roles described + $70k for a full-time project lead.
Thanks Aaron! I think I'm now a bit confused what a prospective funder would be funding.
Is it something like, the volunteer group would run a hiring round (managed by anyone in particular?) for a part-time leader (maybe someone in the group?), but no one specifically has raised their hand for this? And then perhaps that person could deploy some of the $15k to hire a research associate if they'd like?
I respect that this is an early stage idea y'all are just trying to get started / don't have all the details figured out yet, just trying to understand (mostly for the sake of any prospective funders) who they would be betting on etc. :)
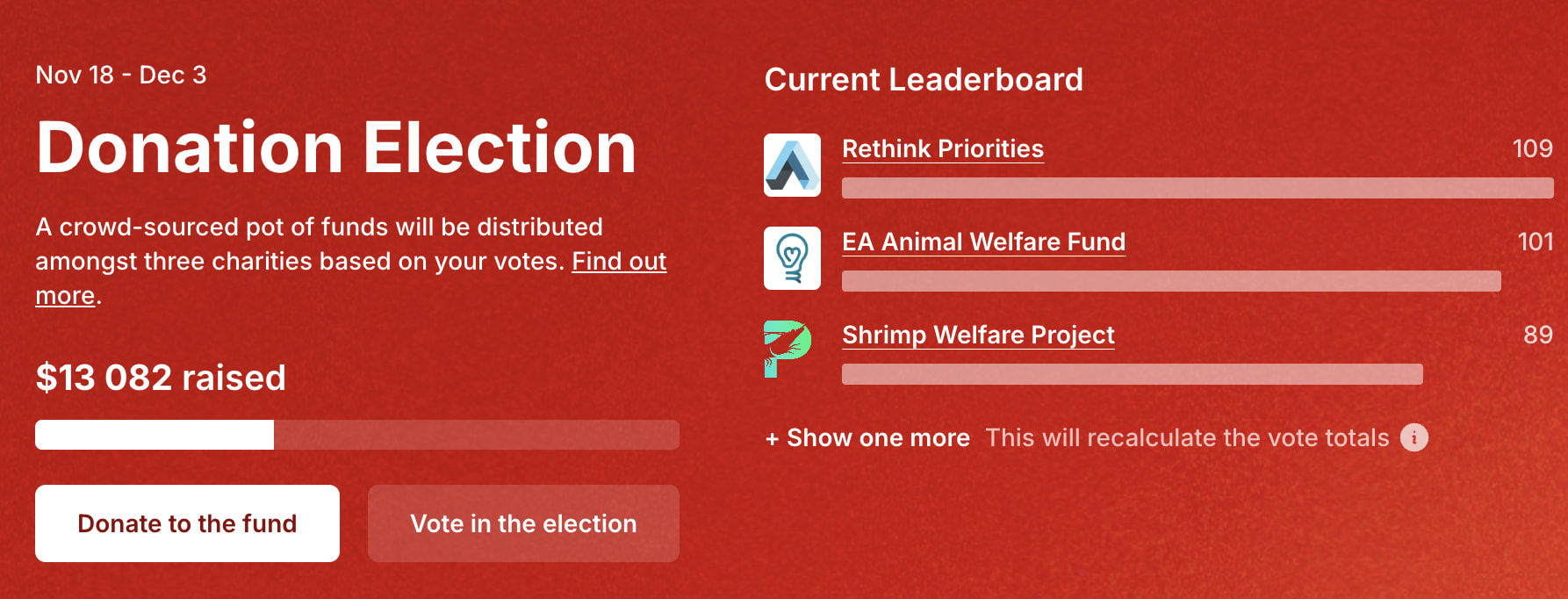
~All of the EV from the donation election probably comes from nudging OpenPhil toward the realization that they're pretty dramatically out of line with "consensus EA" in continuing to give most marginal dollars to global health. If this was explicitly thought through, brilliant.
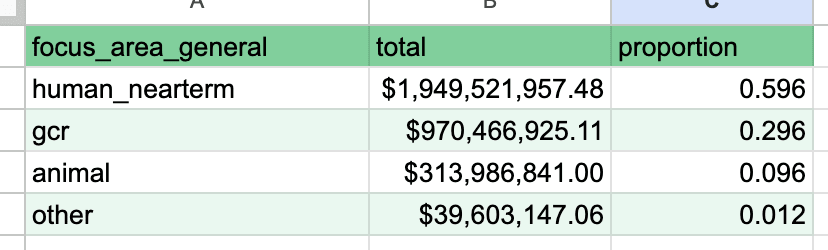
(See this comment for sourcing and context on the table, which was my attempt to categorize all OP grants not too long ago)
Largely but not entirely informed by https://manifold.markets/AaronBergman18/what-donationaccepting-entity-eg-ch#sU2ldPLZ0Edd
Re: a recent quick take in which I called on OpenPhil to sue OpenAI: a new document in Musk's lawsuit mentions this explicitly (page 91)

So cool! Comprehensive EA grants data is like the most central possible example of what I'm interested in, I don't want to promise anything but potentially interested in contributing if there's a need. I might just play around with the code and see if there's anything potentially valuable to add
Also: genuinely unsure this is worth the time/effort to fix but I'd flag that the smallest grants all look like artifacts of some sort of parsing error rather than actual grants