AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
Artificial intelligence (AI) is rapidly improving. Superhuman AI in strategically relevant domains is likely to arrive in the next several decades; some experts think two. This will transform international politics, could be profoundly destabilizing, and could pose existential risks. Urgent research is needed on AI grand strategy.
This requires a careful examination of humanity’s highest interests in the era of transformative AI, of the international dynamics likely to arise from AI, and of the most promising strategies for securing a good future. Much work will be required to design and enact effective global AI policy.
Below is a transcript of Allan Dafoe's talk on this topic from EA Global: Boston 2017. We've lightly edited the transcript for clarity.
The Talk
Nathan Labenz: It is my honor to introduce Professor Allan Dafoe. He is an Assistant Professor of Political Science at Yale University and a Research Associate at the Future of Humanity Institute at Oxford, where he is involved in building the AI Politics and Policy Group. His research seeks to understand the causes of world peace and stability. Specifically, he has examined the causes of the liberal peace and the role of reputation and honor as motives for war. Along the way, he has developed methodological tools and approaches to enable more transparent, credible, causal inference. More recently, he has focused on artificial intelligence grand strategy, which he believes poses existential challenges and also opportunities, and which requires us to clearly perceive the emerging strategic landscape in order to help humanity navigate safely through it. Please welcome Professor Allan Dafoe to discuss his work on AI and international politics.
Allan Dafoe: Thank you, Nathan.
I will start by talking about war, and then we'll get to AI, because I think there are some lessons for effective altruism.
War is generally understood to be a bad thing. It kills people. It maims them. It destroys communities and ecosystems, and is often harmful to economies. We’ll add an asterisk to that because in the long run, war has had dynamic benefits, but in the current world, war is likely a negative that we would want to avoid.
So if we were going to start a research group to study the causes of war for the purposes of reducing it, we might ask ourselves, “What kinds of war should we study?” There are many kinds of wars that have different causes. Some are worse than others.
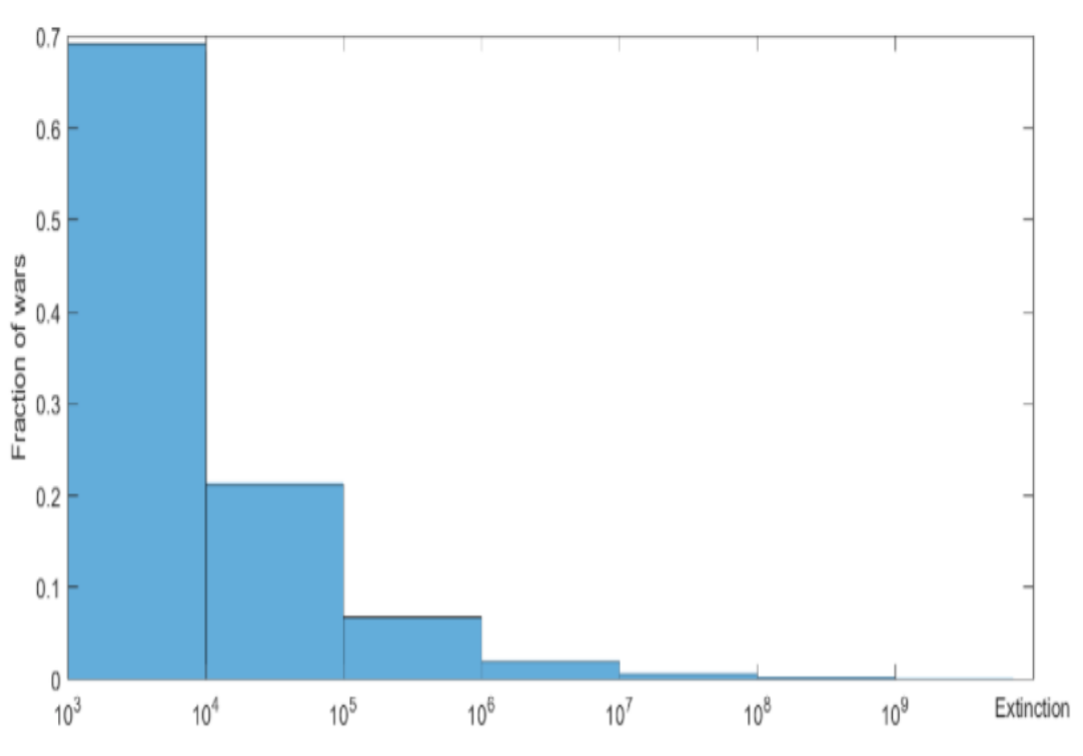
One classification that we might employ is how many people different kinds of wars kill. There are some wars that kill only 1,000 to 10,000, and some that kill 100,000 to a million. And so the x-axis [on this slide] shows the battle deaths in wars, and the y-axis is the fraction of wars of those kinds.
An instinct we might have is to say, “Let's study the wars that are most common — those in the first bin.” These are the wars that are happening today in Syria: civil wars. Availability bias would suggest that those are the wars we should worry about. Some of my colleagues have argued that great-power war — the big world wars — are a thing of the past. They say that the liberal peace, democracy, capitalism, and nuclear weapons have all rendered great-power war obsolete, and that we're not going to have them again. The probability is too low.
But as effective altruists, we know that you can't just round a small number down to zero. You don't want to do that. You want to try to think carefully about the expected value of different kinds of actions. And so it's important that even though the probability of a war killing a million, 10 million, 100 million, or a billion is very small, it's not zero.
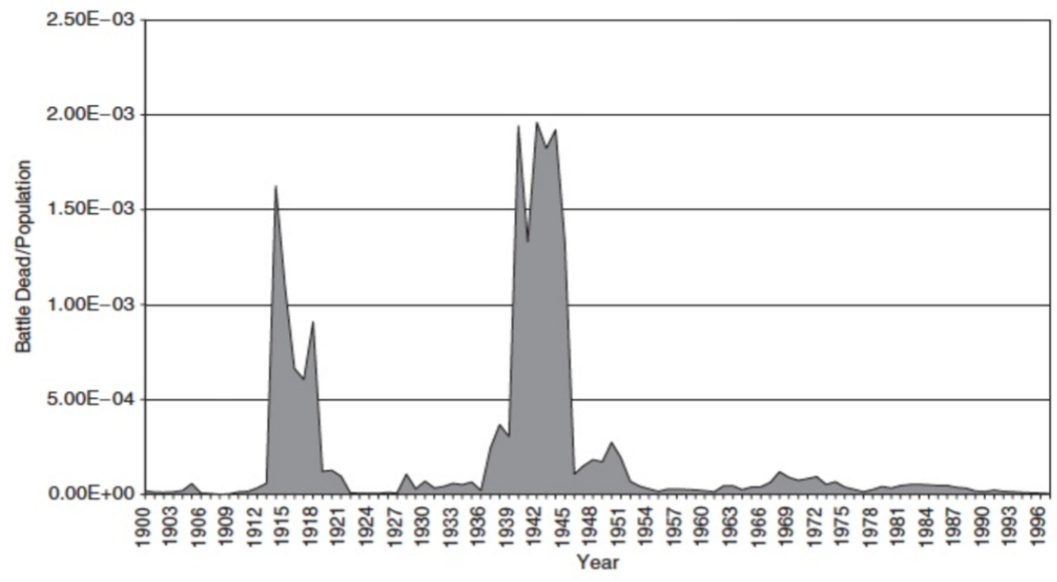
If we look at the past 70 years of history, World War II stands out as the source of most of the battle deaths that have been experienced. That would suggest that fatalities are a good enough proxy for whatever metric of importance you have, and that we first want to make sure we understand World War II and the kinds of wars that are like it (i.e. that are likely to kill many people).
We can zoom out more, and see that World War I comes out of the froth of civil wars. And really, those two wars loom above everything else as what we want to explain, at least if we're prioritizing importance.
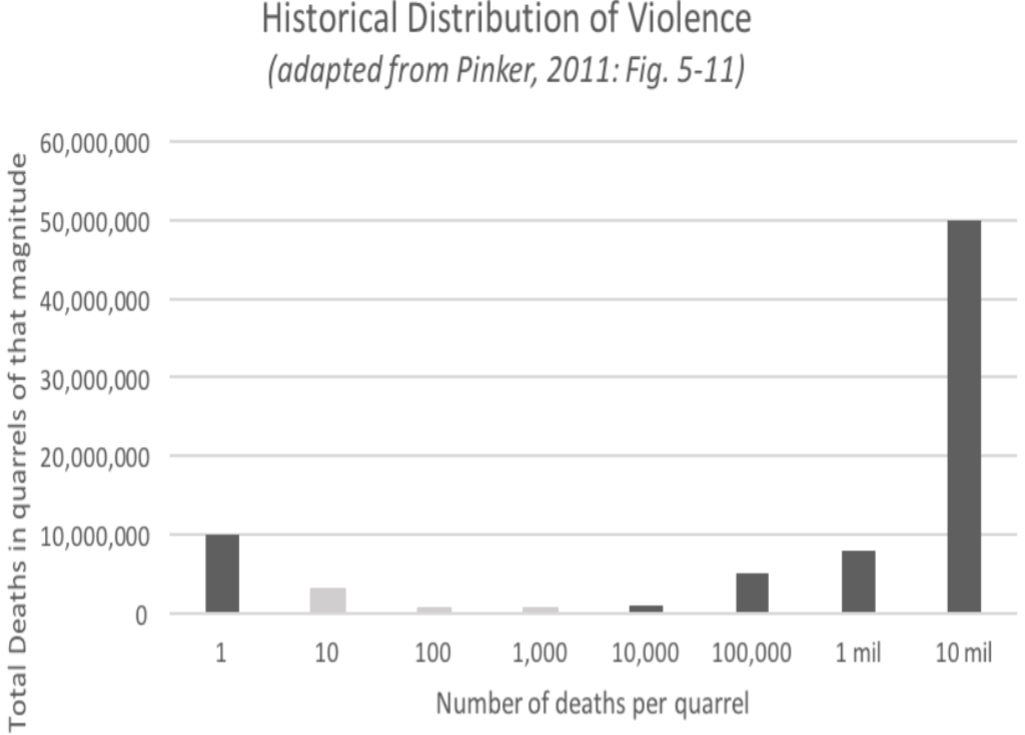
We can see that in this graph, which again has these bins depicting the size of violent quarrels. Relative to homicides, we see that the world wars in the “10 million” bin on the right contain, again, most of the deaths in violent quarrels. That also suggests that it's really important that we understand these big wars.
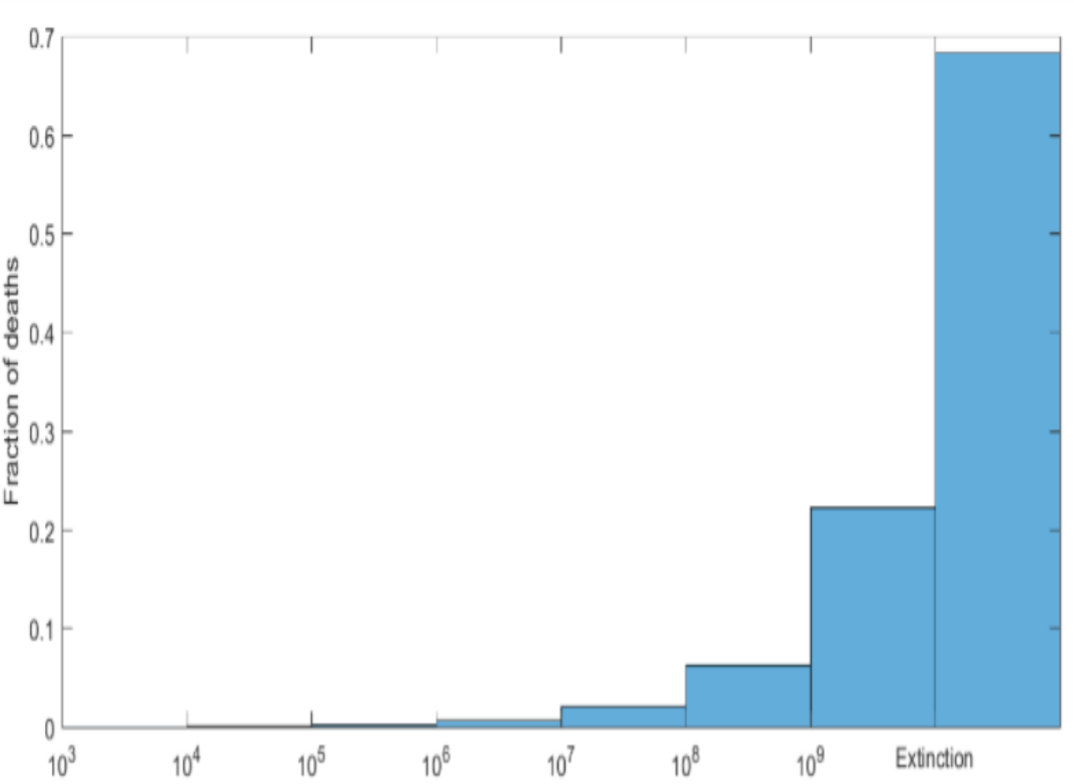
But of course, the next war need not limit itself to 99 million deaths. There could be a war that kills hundreds of millions or even 6.5 billion. The problem, empirically speaking, is that we don't have those wars and that data set, so we don't know how to estimate, non-parametrically, the expected value in those. We can try to extrapolate from what's very close to a power-law distribution. And no matter how we do it, unless we're extremely conservative, we get a distribution like this, which shows that most of the harm from war comes from the wars that kill a billion people or more:
Of course, we haven't had those wars. Nevertheless, this follows from other reasoning.
We can go still further. The loss from a war that killed 6.5 billion is not about just those 6.5 billion people who die. It's also about future people. And this is where the idea of existential risk and existential value comes in. We have to ask ourselves, “What is the value of the future? How much worth do we give to future human lives?”
There are many ways to answer that question. And you want to discount for model uncertainty and various things. But one thing that drives concern with existential risk, which I'm concerned with and the Future of Humanity Institute is concerned with, is that there's so much potential in the future. There are so many potential lives that could be lived. Anything that cuts those lives off has tremendous disvalue.
One estimate that’s quite conservative is this: If there are only a billion people living on Earth, and they continue living in a sustainable way for a billion years (which is doable), as long as we don't muck it up, that yields 10,000 trillion lives. That is a lot. And so anything that reduces the probability of extinction and of losing those 10,000 trillion lives, by even a little bit, has a lot of expected value.
Now, that's a very small number, one ten trillionth (0.0000000000001), and it's hard to know if you're making less of an effect than that. It looks close to zero. The numbers aren't meant to be taken too seriously. They're more thinking heuristics. They illustrate that if you give value to the future, you really want to worry about anything that poses a risk of extinction. And one thing that I and others, such as the Open Philanthropy Project, have identified as a risk to the future is artificial intelligence.
Before telling you about the risk, I'm going to first tell you about what's up with AI these days.
For a long time, artificial intelligence consisted of what we would now call good old-fashioned AI. There was a programmer who wrote if-then statements. They tried to encode some idea of what was a good behavior that was meant to be automated. For example, with chess algorithms, you would have a chessmaster say, “Here are the heuristics I use. Here's the value function.” You put those heuristics in a machine, and the machine runs it more reliably and more quickly than a human. And that's an effective algorithm. But it turns out that good old-fashioned AI just couldn't hack a number of problems — even simple ones that we do in an instant, like recognizing faces, images, and other things.
More recently, what has sort of taken over is what's called “machine learning.” This means what it sounds like it means: machines learning, for themselves, solutions to problems. Another term for this is “deep learning,” which is especially flexible machine learning. You can think of it as a flexible optimization procedure. It's an algorithm that's trying to find a solution and has a lot of parameters. “Neural networks” is another term you've probably heard.
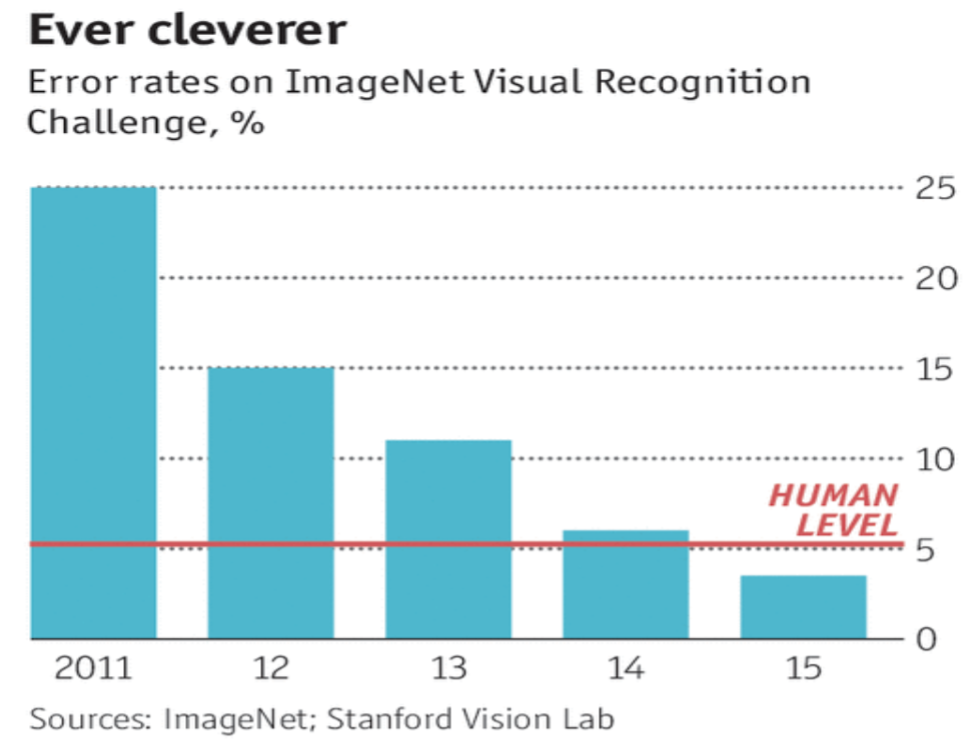
This slide shows the breakthrough recently in image classification arising from neural networks and the year-on-year improvements to the point where machines are now better than humans at image classification.
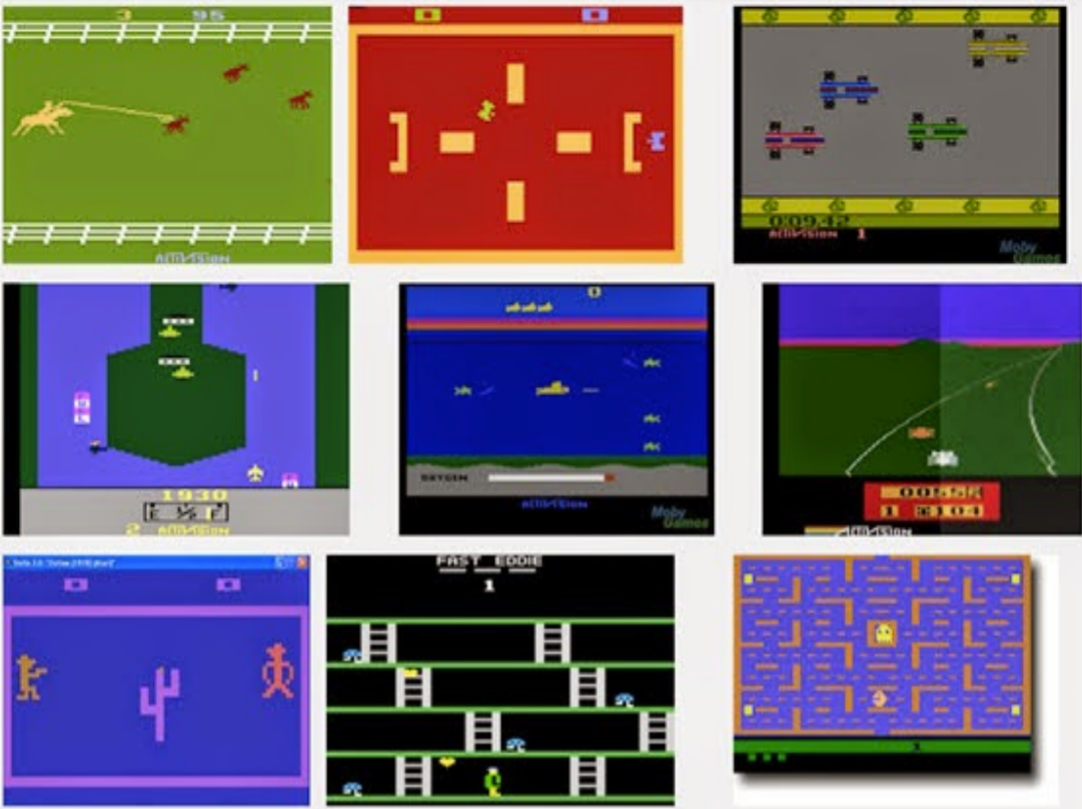
Another domain is generalized game-playing or arcade game-playing. Here are our target games. Probably not many of us have played these. DeepMind is a leading AI group within Google that learned to play Atari games at a superhuman level with no instructions about the nature of the universe (e.g., “What is time and space?”, “What is a bad guy?”, “Here's Pac-Man — what is a pellet and what is a ghost?”). All the machine is told or given is pixel input. It just sees the screen from a blank-state type of beginning. And then it plays the game again and again and again, getting its score, and it tries to optimize for the score. Gradually, over the span of about a day, it learns to make sense of this pixel input. It derives concepts of the bad guy, the ghosts, and the pellets. It devises strategies and becomes superhuman at a range of games.
Another domain where we see this is Go. The solution to Go is very similar. You take a blank-slate neural network that's sufficiently flexible and expose it to a lot of human games, and it learns to predict the human moves. Then you have the machine play itself again and again, on the order of about 10 million games. And it becomes superhuman.
Here's Lee Sedol and AlphaGo, which is another product of DeepMind. And Lee Sedol was the first really excellent Go player who publicly played AlphaGo. And here he's saying in February 2016, “I think I won the game by a near-landslide this time.” Well, as I've alluded to, that didn't work out.
Here he is after the first game: “I was very surprised because I didn't think I would lose.”
And unfortunately, he lost again: “I'm quite speechless. I'm in shock. I can admit that. The third game is not going to be easy for me.” He lost the third game. He did win the fourth game and he talks about how it was sort of the greatest moment of his life. And it's probably the last and only game played against a level of AlphaGo of that level or better that a human will ever win.
I'm bringing up Lee Sedol and his losses for a reason. I think it serves as an allegory for humanity: We don't want to be caught off-guard when it's our AlphaGo moment. At some point, machine intelligence will be better than we are at strategically relevant tasks. And it would be prudent for us to see that coming — to have at least a few years’ notice, if not more, to think through how we can adapt our international systems, our politics, our notion of the meaning of life, and other areas.
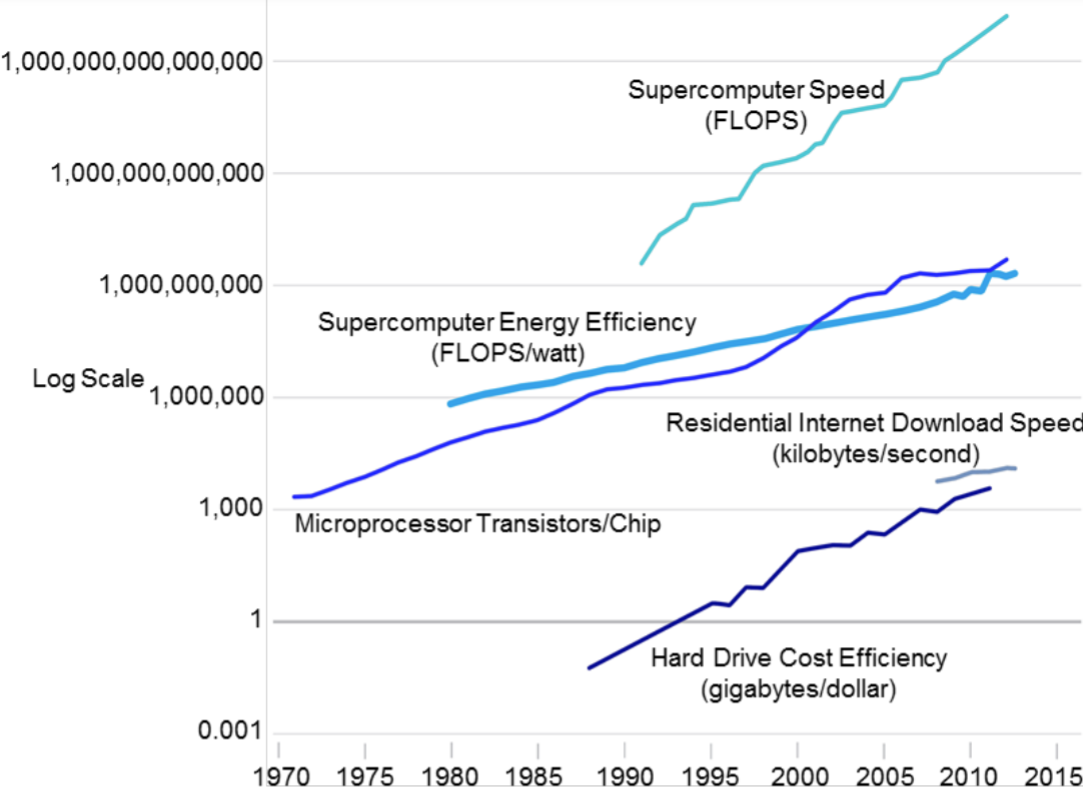
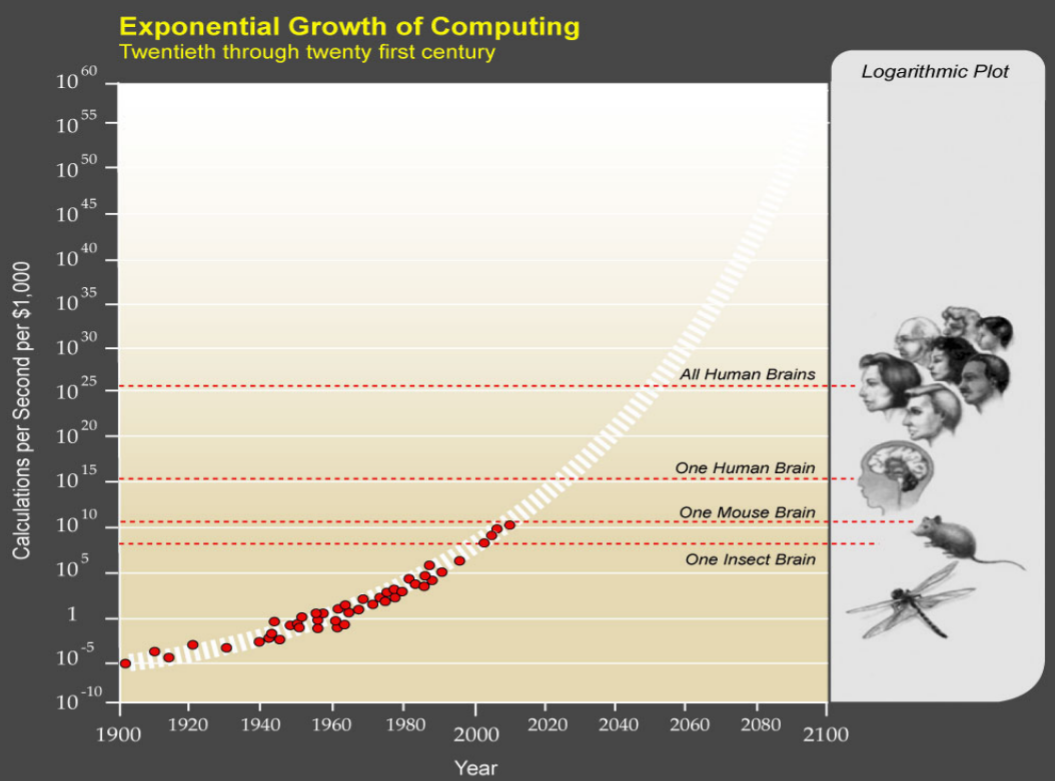
What's driving this progress? Algorithms, talent, and data, but another big thing driving it is hardware. Computing inputs keep getting better at an exponential rate. This is sort of a generalized Moore's law across a range of inputs. And it's this persistent progress that makes Kurzweil's graph from 2001 seem not totally absurd.
Here we have, on the first y-axis, calculations per second, per thousand dollars, and I added four recent dots from the past 17 years. And you see that basically we're on track. We have exponential improvements. What we don't know is when we get to transformative AI.
Now, Kurzweil has this evocative second y-axis, where you have organisms we recognize: mice, humans, and all humans. It's not obvious what the mapping should be between calculations per second and transformative AI. Intelligence is not a single dimension, so we could get superhuman AI in some domains long before other domains. But what I think is right about this graph is that at some point between 2020 or 2025 and 2080, big things are going to happen with machine intelligence.
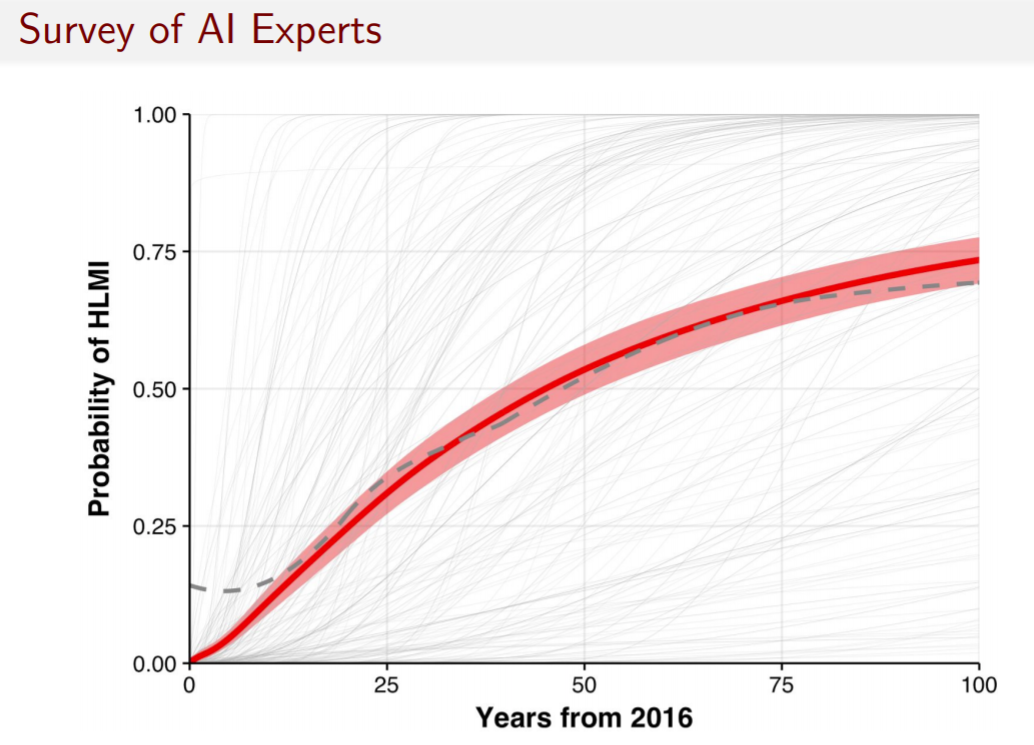
In our work, we want to be a bit more systematic about these timelines, and there are various ways to do it. One way is to survey AI researchers. This is the result of a recent survey.
Some takeaways are:
There's huge disagreement about when human-level machine intelligence, defined here as machines better than all humans at every task, will come, as you can see by the gray S-curves.
The group that we surveyed gives enough probability mass that by 100 years, there still won't be human-level machine intelligence.
But in the next 10 or 20 years, this group gives a 10-20% chance that we will have reached it already. And if that probability seems right (and upon consideration, I think it does, and not just from using this as evidence), there’s more than sufficient warrant for us to invest a lot of resources into thinking very hard about what human-level AI would mean for humanity.
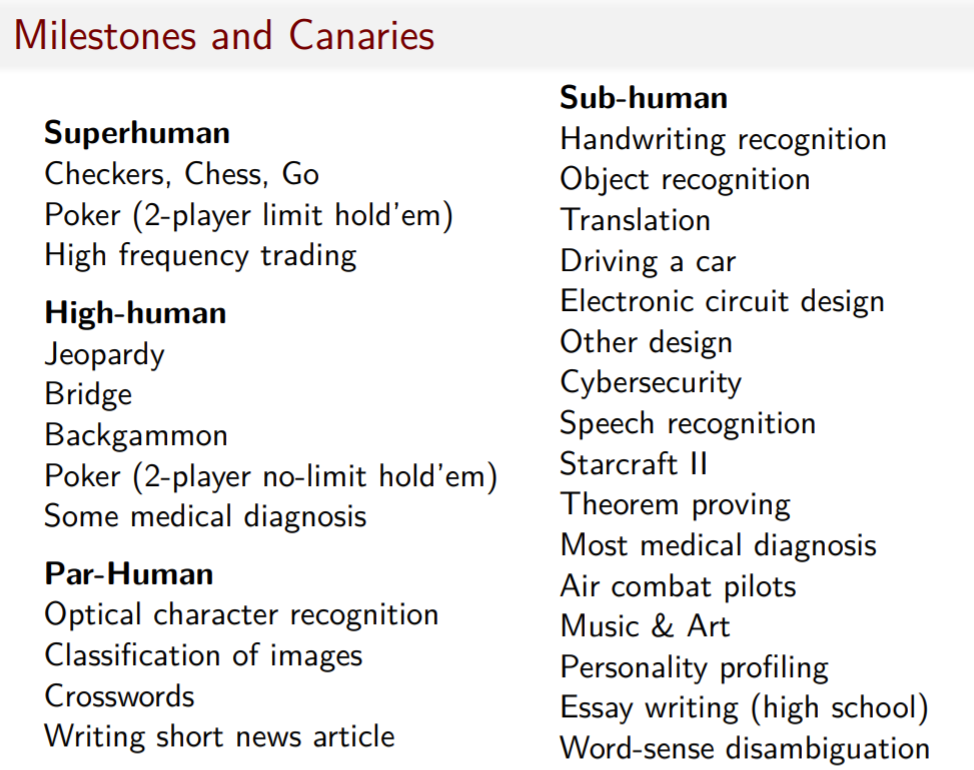
Here are some tasks. I like to think of them as milestones and canaries. What are some things that machines will eventually achieve that are either noteworthy or strategically relevant (i.e. milestones)? And the canaries are those things that when they happen, signal to us that we’d better be paying attention because things are going to change quickly. I expect most of these tasks on the right-hand column will soon be moving over to the left-hand column, if they're not there already. So this is something else we're working on.
More generally, there's a whole host of challenges — near, medium, and long term — that we will be working on as a society, but also at the Future of Humanity Institute. There's a range of near-term issues that I'm not going to talk about. Each of those could occupy a workshop or a conference. I will say that when thinking about long-term issues, we also confront the near-term issues for one reason: because the long-term issues often look like the near-term issues, magnified a hundred-fold, and because a lot of our long-term insights, strategies, and policy interventions’ most appropriate place of action is in the near term.
But what are the long-term opportunities and risks? The opportunities are tremendous. We often just think it's greater wealth, and that maybe Google stock will go up. But it's a lot more: longevity, health, preventative medicine, material bounty that could be used to end poverty ( though it need not, because it will also likely come in a more unequal world), reduced environmental impact. DeepMind was able to reduce energy usage at Google data centers by 40%. AI could basically help with anything of value that is either the product of intelligence or depends on intelligence for its protection. And so if we have superhuman intelligence, then in principle, we can use that to achieve all of our goals.
I'll also emphasize the last point: resilience to other existential risks. We're likely to face those in the next 100 years. And if we solve AI — if we build it well — then that could reduce those other risks by a large margin.
But of course, there are also risks with bringing into the ecosystem a creature that is better than we are at the thing that matters most for our survival and flourishing. I'm not going to go through this topology.
I will illuminate the risk by quoting Max Tegmark and others:
I will also appeal to another authority from my world:
I'm a scholar of international relations. Henry Kissinger, as you know, is also very worried about AI. And this is sort of the definition of a grand strategist.
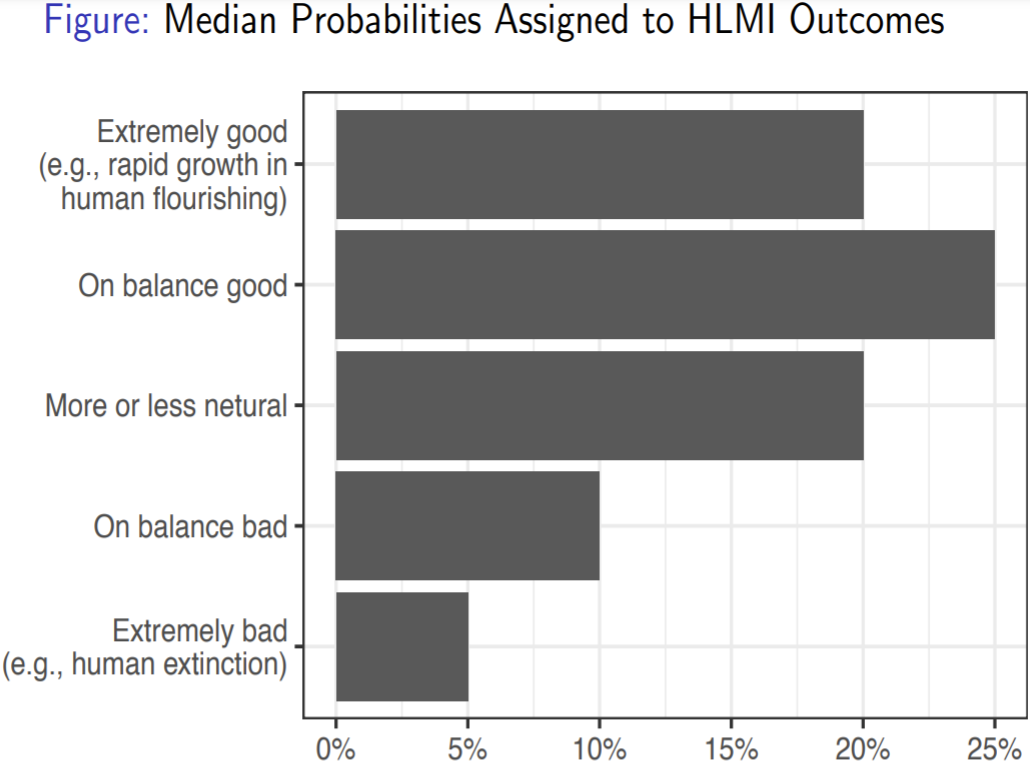
In addition to these quotes, the AI researchers we surveyed agree. We asked them what the long-term prospects are for human-level machine intelligence. And while most of the probability mass was on “extremely good” or on “balanced good,” the median is a 5% probability of AI being extremely bad or leading to human extinction.
It's not often you get an industry that says that their activities give rise to a 5% chance of human extinction. I think it should be our goal to take whatever the real and most frequent number is, and push it as close to zero, getting as much of that probability mass up to the top.
There are two broad ways we can do that. One is to work on what's called AI safety. The computer scientists in the room and mathematicians can help build AI systems that are unlikely to misbehave without our intentions. And the other way is AI strategy, which I'm going to talk about.
So here's Stuart Russell explaining that we're not worried about machines suddenly waking up and deciding they want to build their own machine utopia and get rid of humans. It's not some kind of emergent consciousness. The worry is that they will be hyper optimizers, which is what we're building them to do — and that we will have not specified their value function correctly. Therefore, they could optimize for the wrong thing. This is broadly called “the control problem” or “the value alignment problem.” Here are some groups working on this or funding it.
I'm going to keep moving. Here are some people who you can't really make out, but I will tell you that they are leading researchers and industrialists from the most prominent AI groups in the world. And they came together at the Asilomar Conference to really think seriously about AI safety, which I think is a tremendous achievement for the community — that we've brought everyone together like this. I'm showing this as a reflection of how exciting a time it is for you to be involved in this.
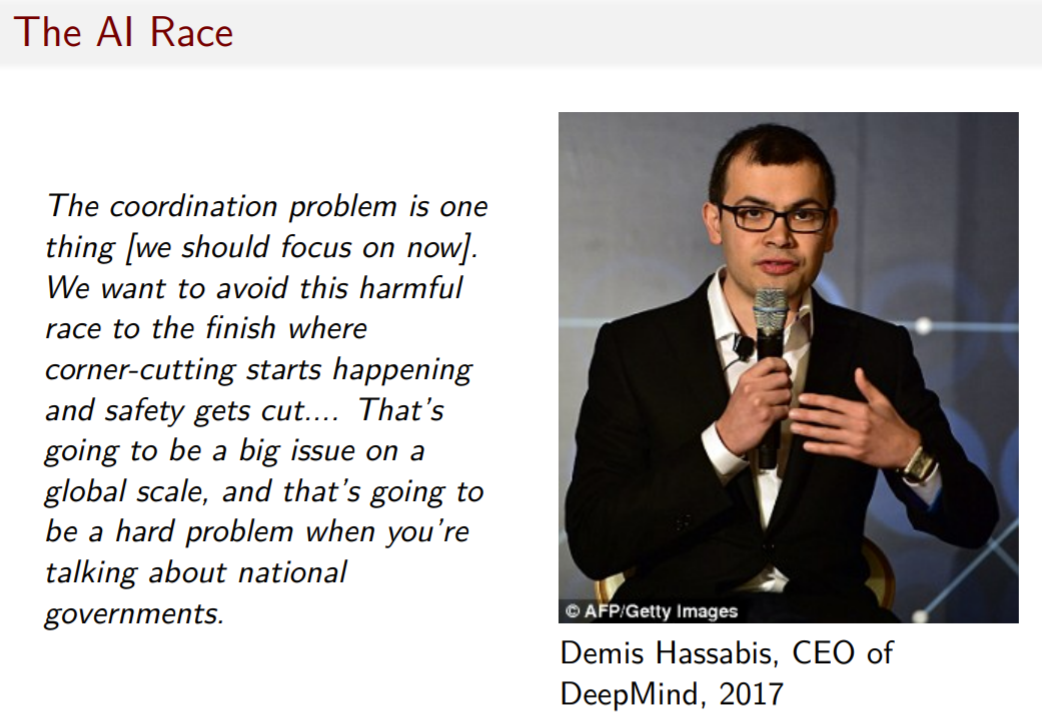
One conjecture that's been posed is that AI value alignment is actually not that hard of a problem. As long as we have enough time, once we have the final system we want to deploy, we can test it, right? It's like drug tests. You have the thing you are thinking about deploying in the population. You just make sure it undergoes sufficient scrutiny. However, this conjecture goes, it is almost impossible to test AI value alignment if we don't have enough time. And if that's right, which seems plausible, then it directs attention to the world in which this system is being deployed. Is it one where the developers have the incentives and the time to do these safety tests? This is one of the big things people working on AI strategy think about — this issue of how to prevent a race in AI.
Here's the CEO of DeepMind, basically reinforcing this point: “We want to avoid a harmful race to the finish, where corner-cutting starts happening and safety gets cut. This is a big issue on a global scale, and it's extra hard when you're talking about national governments.” It's not just a race between companies in the US. It's a race between countries.
So what do we think about in AI strategy? A lot. One topic we think a lot about is what AI races and AI arms races would look like. Another whole class of issues is what AI could look like militarily. What are some implications of AI for the military in terms of balance of power, crisis stability, and uncertainty over capabilities?
Another thing we think about is what it means economically if we live in a world where AI is the engine of growth and value in societies, which increasingly seems to be the case. Of the top 10 firms by market capitalization, either five or six are AI companies: Google, Amazon, Apple, Microsoft. In such a world, what do countries do like Saudi Arabia or France, which don't have their own Google or Amazon, but want to be part of that value chain? We may be entering an era of AI nationalism, where countries want to build their own national champion. China is certainly in the business of doing this.
The last high-level category I’ll mention is the massive challenge of AI governance. This is an issue on a small, near-term scale. For example, how do we govern algorithms that are being used for judicial sentencing or self-driving cars? It’s also an issue on a long-run scale, when we consider what kind of electoral system or voting rules we want to use for the organization that's going to be deciding how to test and deploy superintelligence. These are very hard questions.
I want to make clear that these are questions being asked today by the leading AI groups. Here are Sam Altman and Demis Hassabis asking questions like “What is the voting rule that we should use for control of our superintelligence once we build it?”
The site for governance today is the Partnership on AI. This is a private-sector organization that has recently brought in NGOs, including the Future of Humanity Institute. And it's plausible that this will do a good job guiding AI in the near term, and could grow in the longer term. At some point, governments are likely to get more involved. So that's a site for study and for intervention.
Another thing we can do is try to articulate principles of good governance of AI. Here are some principles that came out of the Asilomar Conference.
Again, a hat tip to Max Tegmark for putting that together, and especially these principles. We might want to work to identify important principles that we can get different communities to agree on, and then formalize and institutionalize them to make sure they stick.
In summary, what's to be done? A lot of work. What kind of skills do we need? Virtually every skill set — people who can help us grow the community, conduct operations and administration, or just be enthusiastic and efficient. We need people to do policy engagement, outreach, and media strategy. For example, what should the media strategy of a group like the Future of Humanity Institute be when there's another self-driving car incident, or when truckers are being massively displaced from their sites of employment? These are important near-term issues, but also they're sites for having conversations about longer-term issues.
We're doing work on strategy, theoretical work, and mathematical modeling of tech races. We’re trying to understand AI development and what predicts innovation, measuring actual capabilities in different sites in the world's countries to understand the value chain and the supply chain of AI. We're surveying publics and elites around the world. We're trying to design safety standards and working with AI safety researchers, and tackling a range of other issues.
If this seems important and interesting to you, I strongly encourage you to get involved. The AI Policy Career Guide has some texts that can point you in the right direction. There’s also a reading list. And in general, just reach out to me. There are also people working on this at a range of sites, and we'd be very happy to help you be productively engaged. Thanks.
Q&A
Nathan: Let’s have a seat. Thank you for the talk and for being here. We'll give a second for questions to come in from the audience [via the conference app].
One thing that I'm struck by is it seems like we're making a lot of progress. I've been involved in this community, sort of from the edges, for a number of years. And there was a time (seven to 10 years ago) when to even talk about something like this was extremely “fringe.” Only weirdos seemed to be willing to go there. Now we have respectable people like you and a growing body of academics who are getting involved. So it seems like there has been a lot of social progress.
What about technical or practical progress on these issues? It seems that we're bringing people together, but what are those people producing so far? And should we feel any safer than we did 10 years ago?
Allan: I can speak to the strategy side of it. One comment that was made at the Asilomar Conference that resonated as true to many people is that AI strategy today is where AI safety was two years ago. The first beneficial meeting for AI safety was in Puerto Rico. Just a handful of individuals in the world were thinking seriously and full-time about it. That has changed today. Now the leading AI groups have safety teams. There are people doing PhDs with an eye towards AI safety. And that's very exciting. And there has been a lot of technical progress that's coming out of that.
AI strategy is just where AI safety was two years ago, but I think it's rapidly scaling up. A lot of thinking has been done, but it's not public yet. I think in the coming year you will start to see a lot of really insightful strategic analysis of AI existential risk.
I will also say I've given some talks like this (e.g., political science workshops) to other respectable audiences and none of the PhD students think this is crazy. Some of them think, “Oh, I don't have to quit smoking because of this.” That was one comment. But they all think this is real. And the challenge for them is that the discipline doesn't entirely support work on the future.
One question I got when I presented at Yale was “How will you be empirical about this?” Because we're social scientists, we like data, and we like to be empirical. And I remarked that it is about the future, and it's hard to get data on that, but we try. So I think it's a challenge for currently existing disciplines to adapt themselves to this problem, but increasingly we're finding good people who recognize the importance of the problem enough to take the time to work on it.
Nathan: So, the first audience question, which I think is a good one, is this: Could you provide more detail on what an AI governance board might look like? Are you thinking it will be a blue-ribbon panel of experts or more of a free-for-all, open-democracy type of structure, where anyone can contribute?
Allan: I think there are a lot of possibilities and I don't have a prescription at this point, so I'm not going to answer your question. But these are the issues we need to think through. There are trade-offs that I can talk about.
There's the issue of legitimacy. The UN General Assembly, for example, is often seen as a legitimate organization because every country gets a vote, but it's not necessarily the most effective international body. Also, you have to weigh your institutions in terms of power holders. So if you have the most ideal governance proposal, it might be rejected by the people who actually have the power to enact it. So you need to work with those who have power, make sure that they sign onto a regime, and try to build in sites of intervention — the key properties of whatever this development and governance regime is — so that good comes out of it.
I'll mention a few suggestions. Whatever development regime it is, I think it should have:
A constitution — some explicit text that says what it's about and what it’s trying to achieve.
Enough transparency so that the relevant stakeholders — be that the citizens of the country, if not citizens of the world — can see that the regime is, in fact, building AI according to the constitution. And I should say that the constitution should be a sort of common-good principle type thing.
Accountability, so that if the regime isn’t working out, there's a peaceful mechanism for changing the leadership.
These are basic principles of institutional design, but it's important to get those built in.
Nathan: So speaking of people in power, I haven’t seen this clip, but President Obama apparently was asked about risks related to artificial intelligence. And the answer that he gave seemed to sort of equate AI risk with cybersecurity risks that we know and love today. Do you think that there is a sufficient understanding at the highest levels of power to even begin to make sense of this problem? Or do we have a fundamental lack of understanding that may be quite hard to overcome?
Allan: Yeah. That's a great clip. I wish I could just throw it up really quickly. We don't have the AI yet to just do that. I encourage you to watch it. It's hard to find it. Wired put it on their page. He's asked about superintelligence and if he's worried about it and he pauses. He hesitates and gives sort of a considered “hmm” or sigh. And then he says, “Well, I've talked to my advisors and it doesn't seem to be a pressing concern.” But the pause and hesitation is enough to suggest that he really did think about it seriously. I mean, Obama is a science fiction fan. So I think he probably would have been in a good place to appreciate other risks as they arise.
But I think a lot of people in government are likely to dismiss it. Many reports from the military or government have put superintelligence worries at least sufficiently distant enough that we don't really need to think about or address it now. I will say though, that cybersecurity is likely to be a site where AI is transformative, at least in my assessment. So, that's one domain to watch in particular.
Nathan: Here’s another question from the audience: If there is a 5% chance of extinction due to AI, one would not be unreasonable to jump to the conclusion that maybe we should just not do this at all. It's just too hot to touch. What do you think of that idea? And second, is there any prospect of making that decision globally and somehow sticking to it?
Allan: Yeah. I'll flick back to the slide on opportunities. I actually had a conversation the other day with family members and friends, and one person at the table asked that question: If it's so risky, why don't we not do it? And then another friend of the family asked, “What are the impacts of AI for medicine and health, and for curing diseases?” And I think in many ways those are two sides of the policy decision. There are tremendous opportunities from AI, and not just material ones, but opportunities like curing Alzheimer's. Pretty much any problem you can imagine that's the product of intelligence could [be solved with] machine intelligence. So there's a real trade-off to be made.
The other issue is that stopping AI progress is politically infeasible. So I don't think it's a viable strategy, even if you thought that the trade-off weighed in favor of doing so. And I could talk a lot more about that, but that is my position.
Nathan: Probably the last question that we can take due to time constraints is this: Thinking about the ethical direction that we want to take as we go forward into the future — the value alignment problem — you had posed that notion that if we have two years, we can probably figure it out.
Allan: Yeah.
Nathan: But if we don't, maybe more than likely we can't. That strikes someone in the audience and I would say me too, as maybe a little too optimistic, because we've been working for thousands of years on what it means to have a good life and what good is.
Allan: Right.
Nathan: Do you think that we are closer to that then than maybe I think we are? Or how do you think about the kind of fundamental question of “What is good?” in the first place?
Allan: Right. To be clear, this conjecture is about whether a single person who knows what they want can build a superintelligent machine to advance those interests. It says nothing about whether we all know what we want and could agree on what we want to build. So can we agree on the political governance question: Even if we all have fundamental preferences, how do we aggregate those in a good way? And then there's the deeper question of what should we want? And yeah, those are hard questions that we need people working on, as I mentioned. In terms of a moral philosophy in politics, what do we want? We need your help figuring that out.
Nathan: Well, thank you for wrestling with these issues and for doing your best to protect our future. Professor Allan Dafoe, thank you very much.
8
More posts like this
44
The Rival AI Deployment Problem: a Pre-deployment Agreement as the least-bad response