Disclaimer: the models presented are extremely naive and simple, and assume that existential risk from AI is higher than 20%. Play around with the models using this (mostly GPT-4 generated) jupyter notebook.
1 microdoom = 1/1,000,000 probability of existential risk
Diminishing returns model
The model has the following assumptions:
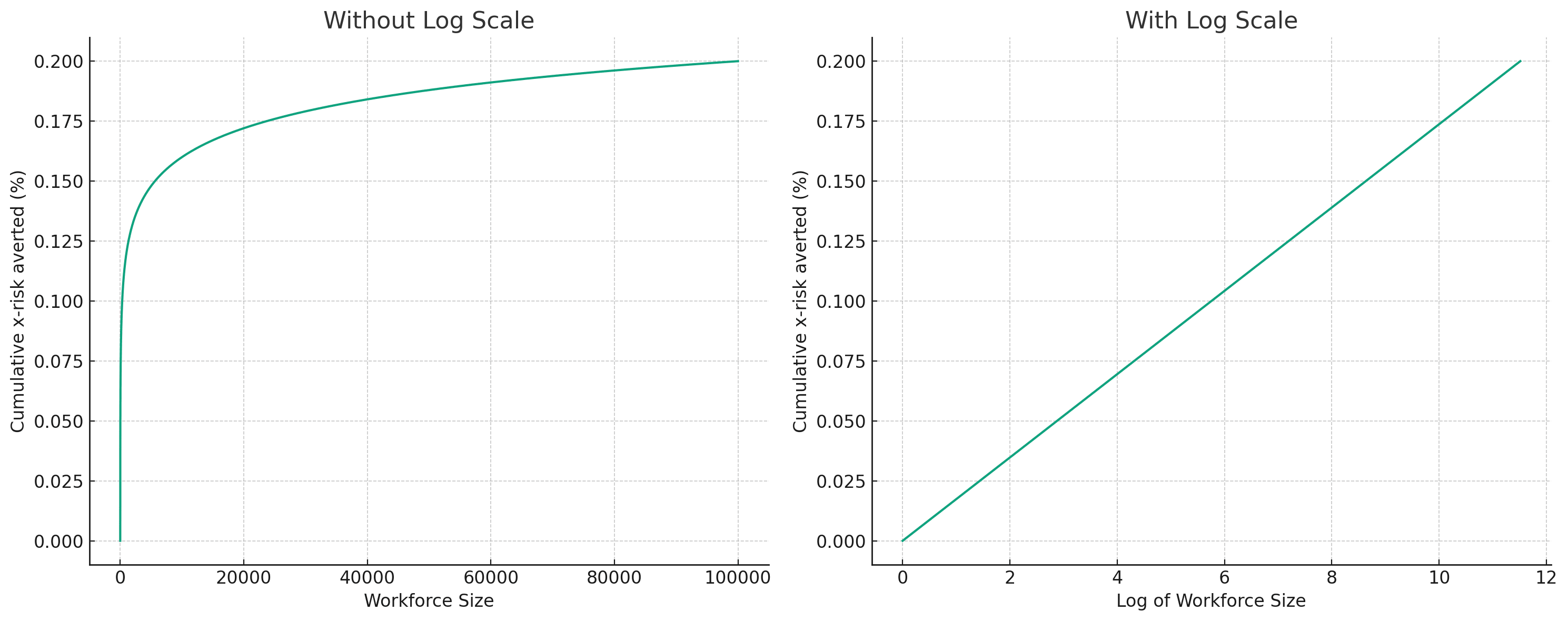
- Absolute Risk Reduction: There exists an absolute decrease in existential risk that could be achieved if the AI safety workforce were at an "ideal size." This absolute risk reduction is a parameter in the model.
- Note that this is absolute reduction, not relative reduction. So, a 10% absolute reduction means going from 20% x-risk to 10% x-risk, or from 70% x-risk to 60% x-risk.
- Current and Ideal Workforce Size: The model also takes into account the current size of the workforce and an "ideal" size (some size that would lead to a much higher decrease in existential risk than the current size), which is larger than the current size. These are both parameters in the model.
- Diminishing Returns: The model assumes diminishing returns on adding more people to the AI safety effort. Specifically, the returns are modeled to increase logarithmically with the size of the workforce.
The goal is to estimate the expected decrease in existential risk that would result from adding one more person to the current AI safety workforce. By inputting the current size of the workforce, the ideal size, and the potential absolute risk reduction, the model gives the expected decrease.
If we run this with:
- Current size = 350
- Ideal size = 100,000
- Absolute decrease (between 0 and ideal size) = 20%
we get that one additional career averts 49 microdooms. Because of diminishing returns, the impact from an additional career is very sensitive to how big the workforce currently is.
Pareto distribution model
We assume that the impact of professionals in the field follows a Pareto distribution, where 10% of the people account for 90% of the impact.
Model Parameters
- Workforce Size: The total number of people currently working in AI safety.
- Total Risk Reduction: The absolute decrease in existential risk that the AI safety workforce is currently achieving.
If we run this with:
- Current size = 350
- Absolute risk reduction (from current size) = 10%
We get that, if you’re a typical current AIS professional (between 10th and 90th percentile), you reduce somewhere between 10 and 270 microdooms. Because of how skewed the distribution is, the mean is at 286 microdooms, which is higher than the 90th percentile.
- A 10th percentile AI Safety professional reduces x-risk by 14 microdooms
- A 20th percentile AI Safety professional reduces x-risk by 16 microdooms
- A 30th percentile AI Safety professional reduces x-risk by 20 microdooms
- A 40th percentile AI Safety professional reduces x-risk by 24 microdooms
- A 50th percentile AI Safety professional reduces x-risk by 31 microdooms
- A 60th percentile AI Safety professional reduces x-risk by 41 microdooms
- A 70th percentile AI Safety professional reduces x-risk by 61 microdooms
- A 80th percentile AI Safety professional reduces x-risk by 106 microdooms
- A 90th percentile AI Safety professional reduces x-risk by 269 microdooms
Linear growth model
If we just assume that going from 350 current people to 10,000 people would decrease x-risk by 10% linearly, we get that one additional career averts 10 microdooms.
One microdoom is A Lot Of Impact
Every model points at the conclusion that one additional AI safety professional decreases existential risks from AI by one microdoom at the very least.
Because there are 8 billion people alive today, averting one microdoom roughly corresponds to saving 8 thousand current human lives (especially under short timelines, where the meaning of “current” doesn’t change much). If one is willing to pay $5k to save one current human life (roughly how much it costs GiveWell top charities to save one), this amounts to $40M.
One microdoom is also 1 millionth of the entire future. If we expect our descendants to only spread to the milky way galaxy and no other galaxies, then this amounts to roughly 300,000 star systems.
Why doesn’t GiveWell recommend AI Safety organizations?
AI safety as a field is probably marginally (with regards to number of people or amount of funding) much more effective at saving current human lives than the global health charities GiveWell recommends. I think GiveWell shouldn’t be modeled as wanting to recommend organizations that save as many current lives as possible. I think a more accurate way to model them is “GiveWell recommends organizations that are [within the Overton Window]/[have very sound data to back impact estimates] that save as many current lives as possible.” If GiveWell wanted to recommend organizations that save as many human lives as possible, their portfolio would probably be entirely made up of AI safety orgs.
Because of organizational inertia, and my expectation that GiveWell will stay a global health charity recommendation service, I think it’s very worth thinking about creating a donation recommendation organization that evaluates (or at the very least compiles and recommends) AI safety organizations instead. Something like "The AI Safety Fund", without any other baggage, just plain AI safety. There might be huge increases in interest and funding in the AI safety space, and currently it’s not very obvious where a concerned individual with extra money should donate it.
This paragraph, especially the first sentence, seems to be based on a misunderstanding I used to share, which Holden Karnofsky tried to correct back in 2011 (when he was still at GiveWell) with the blog post Why we can’t take expected value estimates literally (even when they’re unbiased) in which he argued (emphasis his):
(He since developed this view further in the 2014 post Sequence thinking vs cluster thinking.) Further down, Holden wrote
This guiding philosophy hasn't changed; in GiveWell's How we work - criteria - cost-effectiveness they write:
which jives with what Holden wrote in the relative advantages & disadvantages of sequence thinking vs cluster thinking article above.
Note that this is for global health & development charities, where the feedback loops to sense-check and correct cost-effectiveness analyses that guide resource allocation & decision-making are much clearer and tighter than for AI safety orgs (and other longtermist work more generally). If it's already this hard for GHD work, I get much more skeptical of CEAs in AIS with super-high EVs, just in model uncertainty terms.
This isn't meant to devalue AIS work! I think it's critical and important, and I think some of the "p(doom) modeling" work is persuasive (MTAIR, Froolow, and Carlsmith come to mind). Just thought that "If GiveWell wanted to recommend organizations that save as many human lives as possible, their portfolio would probably be entirely made up of AI safety orgs" felt off given what they're trying to do, and how they're going about it.
This is correct if you look at GiveWell's criteria for evaluating donation opportunities. GiveWell’s highly publicized claim “We search for the charities that save or improve lives the most per dollar” is somewhat misleading given that they only consider organizations with RCT-style evidence backing their effectiveness.
Thanks for the post. It was an interesting read.
According to The Case For Strong Longtermism, 10^36 people could ultimately inhabit the Milky Way. Under this assumption, one micro-doom is equal to 10^30 expected lives.
If a 50%-percentile AI safety researcher reduces x-risk by 31 micro-dooms, they could save about 10^31 expected lives during their career or about 10^29 expected lives per year of research. If the value of their research is spread out evenly across their entire career, then each second of AI safety research could be worth about 10^22 expected future lives which is a very high number.
These numbers sound impressive but I see several limitations of these kinds of naive calculations. I'll use the three-part framework from What We Owe the Future to explain them:
After taking these factors into account, I think the value of any given AI safety research is probably much lower than naive calculations suggest. Therefore, I think grant evaluators should take into account their intuitions on what kinds of research are most valuable rather than relying on expected value calculations.
In case of EV calculations where the future is part of the equation, I think using microdooms as a measure of impact is pretty practical and can resolve some of the problems inherent with dealing with enormous numbers, because many people have cruxes which are downstream of microdooms. Some think there'll be 10^40 people, some think there'll be 10^20. Usually, if two people disagree on how valuable the long-term future is, they don't have a common unit of measurement for what to do today. But if they both use microdooms, they can compare things 1:1 in terms of their effect on the future, without having to flesh out all of the post-agi cruxes.
I don't think this is the case for all key disagreements, because people can disagree a lot about the duration of the period of heightened existential risk, whereas microdooms are defined as a reduction in total existential risk rather than in terms of per-period risk reduction. So two people can agree that AI safety work aimed at reducing existential risk will decrease risk by a certain amount over a given period, but one may believe such work averts 100x as many microdooms as the other because they believe the period of heightened risk is 100x shorter.
As someone who is not an AI safety researcher, I've always had trouble knowing where to donate if I wanted to reduce x-risk specifically from AI. I think I would have donated quite a larger share of my donations to AI safety over the past 10 years if something like an AI Safety Metacharity existed. Nuclear Threat Initiative tends to be my go to for x-risk donations, but I'm more worried about AI specifically lately. I'm open to being pitched on where to give for AI safety.
Regarding the model, I think it's good to flesh things out like this, so thank you for undertaking the exercise. I had a bit of a play with the model, and one thing that stood out to me is that the impact of an AI safety professional at different percentiles doesn't seem to depend on the ideal size, which doesn't seem right (I may be missing something). Shouldn't the marginal impact of one AI safety professional be lower if it turned out the ideal size of the AI safety workforce were 10 million rather than 100,000?