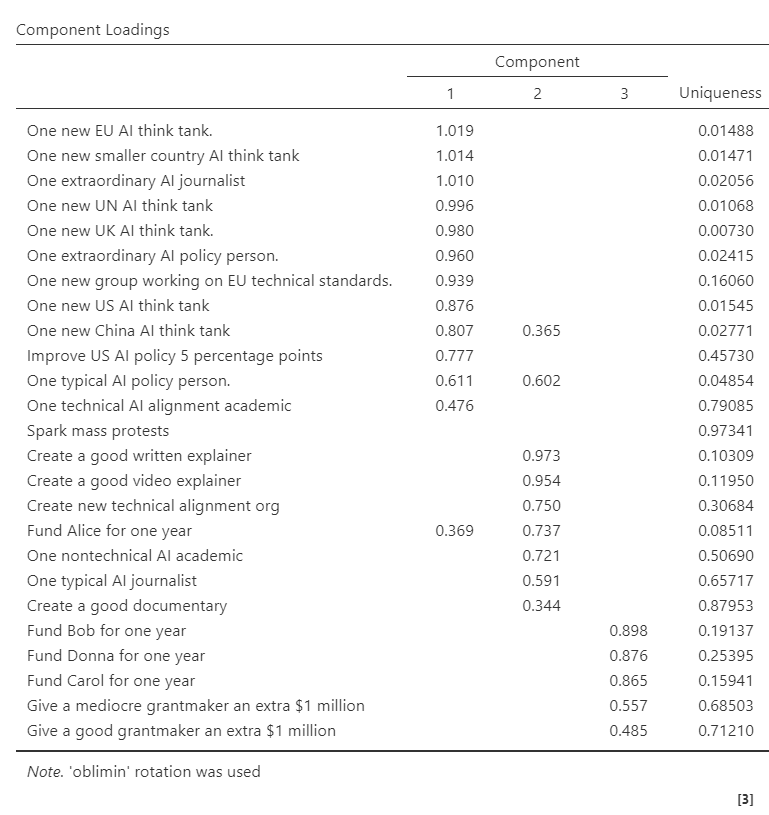
I asked readers of my blog with experience in AI alignment (and especially AI grantmaking) to fill out a survey about how they valued different goods. I got 61 responses. I disqualified 11 for various reasons, mostly failing the comprehension check question at the beginning, and kept 50.
Because I didn't have a good way to represent the value of "a" dollar for people who might have very different amounts of money managed, I instead asked people to value things in terms of a base unit - a program like MATS graduating one extra technical alignment researcher (at the center, not the margin). So for example, someone might say that "creating" a new AI journalist was worth "creating" two new technical alignment researchers, or vice versa.
One of the goods that I asked people to value was $1 million going to a smart, value-aligned grantmaker. This provided a sort of researcher-money equivalence, which turned out to be $125,000 per researcher on median. I rounded to $100,000 and put this in an experimental second set of columns, but the median comes from a wide range of estimates and there are some reasons not to trust it.
The results are below. You can see the exact questions and assumptions that respondents were asked to make here. Many people commented that there were ambiguities, additional assumptions needed, or that they were very unsure, so I don't recommend using this as anything other than a very rough starting point.

I tried separating responses by policy vs. technical experience, or weighting them by respondent's level of experience/respect/my personal trust in them, but neither of these changed the answers enough to be interesting.
You can find the raw data (minus names and potentially identifying comments) here.
Ah, really just meant it as a data point and not an argument! I think if I were reading this I'd want to know the above (maybe that's just because I already knew it?).
But to carry on the thread: It's not clear to me from what we know about the questions in the survey if 'creating' meant 'courting, retraining', or 'sum of all development that made them a good candidate in the first place, plus courting, retraining.' I'd hope it's the former, since the latter feels much harder to reason about commutatively. Maybe this ambiguity is part of the 'roughness' brought up in the OP.
I'm also not sure if 'the marginal graduate is worse than the median graduate' is strongly true. Logically it seems inevitable, but also it's very hard to know ex ante how good a scholar's work will be, and I don't think it's exactly right to say there's a bar that gets lowered when the cohort increases in size. We've been surprised repeatedly (in both directions) by the contributions of scholars even after we feel we've gotten a bead on their abilities (reviewed their research plans, etc).
Often the marginal scholar allows us to support a mentor we otherwise wouldn't have supported, who may have a very different set of selection criteria than other mentors.