AI for Epistemics is about helping to leverage AI for better truthseeking mechanisms — at the level of individual users, the whole of society, or in transparent ways within the AI systems themselves. Manifund & Elicit recently hosted a hackathon to explore new projects in the space, with about 40 participants, 9 projects judged, and 3 winners splitting a $10k prize pool. Read on to see what we built!

Resources
- See the project showcase: https://moxsf.com/ai4e-hacks
- Watch the recordings: project demos, opening speeches
- See the outline of project ideas: link
- Thanks to Owen Cotton-Barratt, Raymond Douglas, and Ben Goldhaber for preparing this!
- Lukas Finnveden on “What's important in ‘AI for epistemics’?”: link
- Automation of Wisdom and Philosophy essay contest: link
Why this hackathon?
From the opening speeches; lightly edited.
Andreas Stuhlmüller: Why I'm excited about AI for Epistemics
In short - AI for Epistemics is important and tractable.
Why is it important? If you think about the next few years, things could get pretty chaotic. As everyone rushes to integrate AI systems into every part of the economy, the world could change more rapidly than it does today. There's significant risk that people and organizations will make mistakes for relatively uninteresting reasons—simply because they didn't have enough time to think things through.
If we can make it easier for people to think clearly and carefully, that's really important. People will use AI tools to help them make decisions either way; eventually unassisted decision-making just won’t be competitive anymore. This is a lever: the more these tools actually help people make wise decisions, or help them figure out whether they're right or wrong about something, the better off we'll be.
AI for Epistemics is also tractable now in a way it wasn't before. We're just reaching the point where models are good enough and cheap enough to apply at scale. You can now realistically say, "Let's analyze all news articles," or "Let's review all scientific papers," or thoroughly check every sentence of a document, at a level of detail that wasn't feasible before.
Given good ideas for epistemic tools, the implementation cost has dropped dramatically. Building significant products in hackathons has become much easier. You can basically copy and paste your project description into Cursor, type "please continue" five times, and you'll have a working demo.
The key challenge we'll need to think about today is: how can we tell if we're actually making things better? What evidence can we see that would lead us to believe a tool genuinely improves people's thinking, rather than just being a fun UI with knobs to play with?
I'm really excited about this hackathon. This is the event I've been most excited about for quite a while. I'm very grateful to Austin for creating this space for us.
Austin Chen: Why a hackathon?
Andreas first talked to me a couple months ago, saying we want to do more for the AI for Epistemics field. We were thinking about some ideas: “oh, maybe we should do a grants program, or a fellowship program, or something like that”.
But I have a special place in my heart for hackathons specifically. So I really sold him hard: we're gonna do a hackathon. We can do all that other stuff too later, but: first things first. (Andreas, wryly: “I was very hard to sell.”)
I like hackathons for a lot of reasons:
- Hackathons are a sandbox. They're a place where you can play with an idea a little bit. You don't have to worry about whether this thing will be great down the line, or even live past the end of the day. So it gives you a chance to be a bit more creative, try riskier things.
- It's a blank canvas. You don't have to worry about what your current users will think, or “will this make money?”. You can just… do stuff.
- Hackathons are a forcing function. There's the demos in eight hours. We're all gonna get up there and present and talk about what we did. So you have to sit there and actually build your idea. You can't just keep spinning your wheels, thinking forever.
- And it's a chance to meet people. It's a filtering function to find people who care a lot about this particular niche. Right now, AI for Epistemics is a tiny field. All the people who care about it are maybe in this room right now (plus a few others who are remote). But hopefully, it will grow down the line. And this is your chance to meet each other, talk to each other, share your ideas, build stuff out.
Those are some of the reasons I'm excited about hackathons. I'm glad that Andreas and the Elicit team are happy to host this with us today.
Meet the projects
We asked the participants to share more about their project after the hackathon ended. Comments are mostly Austin’s.
Question Generator, by Gustavo Lacerda
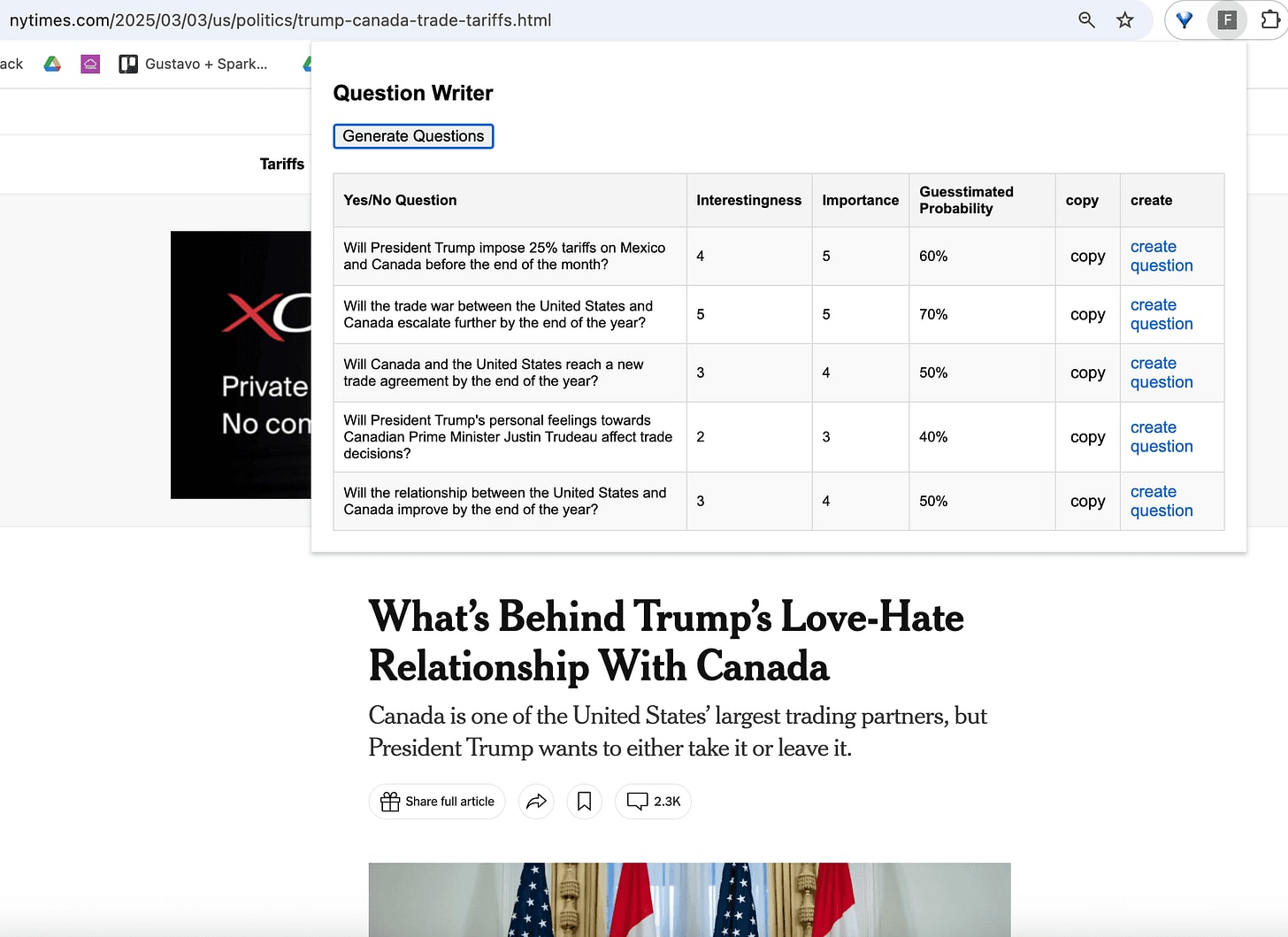
Demo: Starts 6:18
Description: This is a browser extension that generates forecasting questions related to the news page you are visiting.
Comments: Good exploration of a promising form factor (chrome extension to make personal flow easier). I like that it ends with “create a Manifold question”, as a concrete thing to go next. I’m not sure if the questions were actually any good? But with LLMs, maybe it’s always a brainstorming aid, or LLM generate and humans filter (as with imagegen).
Symphronesis, by Campbell Hutcheson (winner)

Demo: Starts 14:34
Description: Automated comment merging for LessWrong; finds disputes between the comments and the text and then highlights the text with the disputes; color coded and you can mouse over and then jump to the comment.
Why did you build this?: I’m interested in how LLMs will enable highly personalized UI/UX. One of my main contentions is that software became mass produced because the cost of development is very high and so it was prohibitive to create artisanal software solutions for individuals - but that LLMs - because they make software cheaper - give us the opportunity to return to a more artisanal software experience - where our interface to software is created dynamically. Moreover, as the cost to benefit ratio of software was even worse in design than elsewhere - good design has been something essentially limited to software companies that aggressively focus on it as part of their core value prop (e.g. Apple, Notion, Linear). But, this can now change, and we can have better, more personalized, richer experiences.
What are you most proud of for this project?: It worked. It has nice bells and whistles. It enables me to have more control over a document as an organic thing.
Source: https://github.com/chutcheson/Symphronesis
Comments: Interesting & pretty UI, reasonable concept. Lots of audience questions about how it was implemented. Lukas: “Unfortunate to do this for Lesswrong which is the website with the most support for this already”
Manifund Eval, by Ben Rachbach & William Saunders
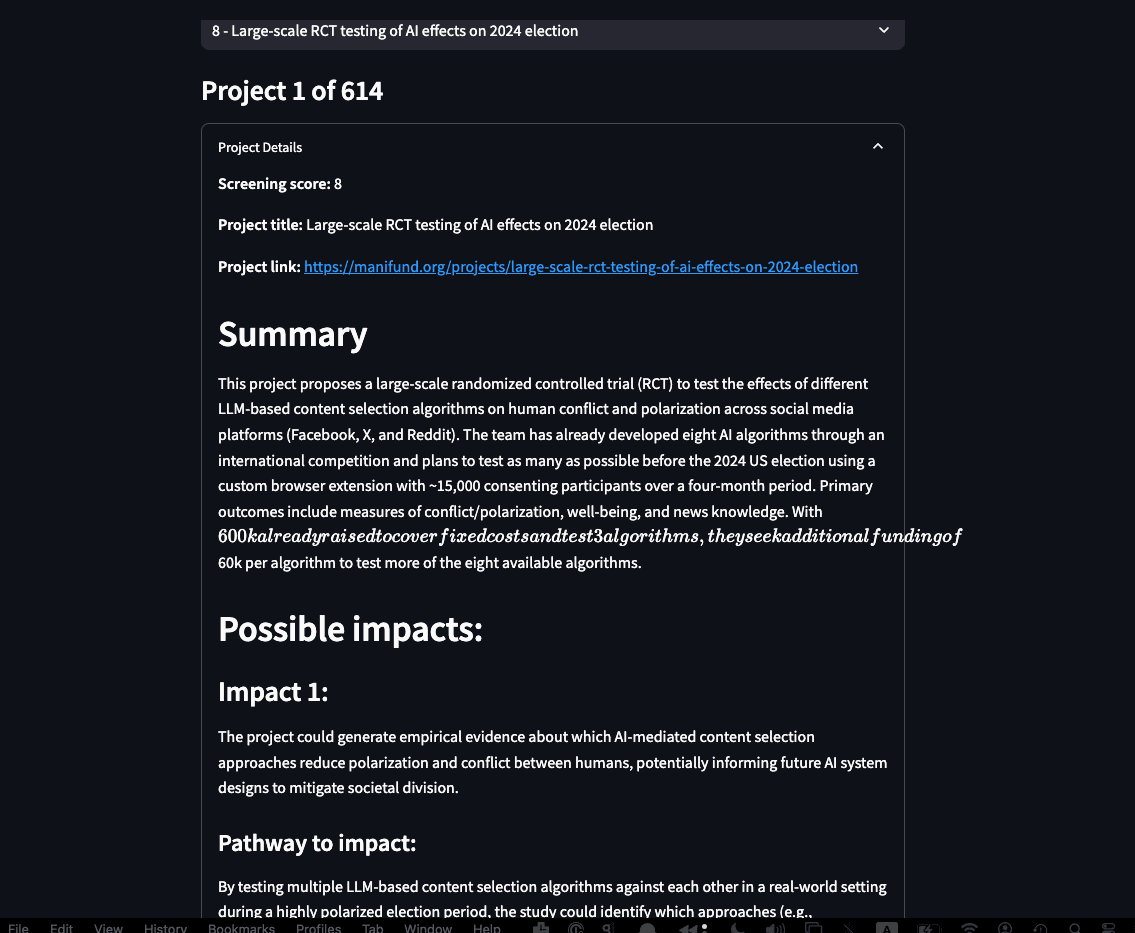
Demo: Starts 1:38
Description: Screen all Manifund projects to identify ones to look into more to consider funding. Also identifies the grant’s story for having an impact on transformative AI going well, so you can review that to save time in your evaluation. Makes it feasible to quickly sift through the large number of Manifund projects to find promising ones to consider.
Demo link: https://manifundeval-zfxpigvo8jemehaybdwwsw.streamlit.app/
Comments: Of course, soft spot in my heart for using the Manifund API. Pretty important and impactful project (Andreas: “I actually need this.”) Not sure if the final scores outputted, or reasoning were that good though; didn’t seem that great by my lights. Might be biased — I’d tried something similar (for giving feedback to potential new projects) and it was only okay. But def worth more experimentation. I think I might want to issue a bounty to solve this problem for Manifund.
Detecting Fraudulent Research, by Panda Smith & Charlie George (winner)
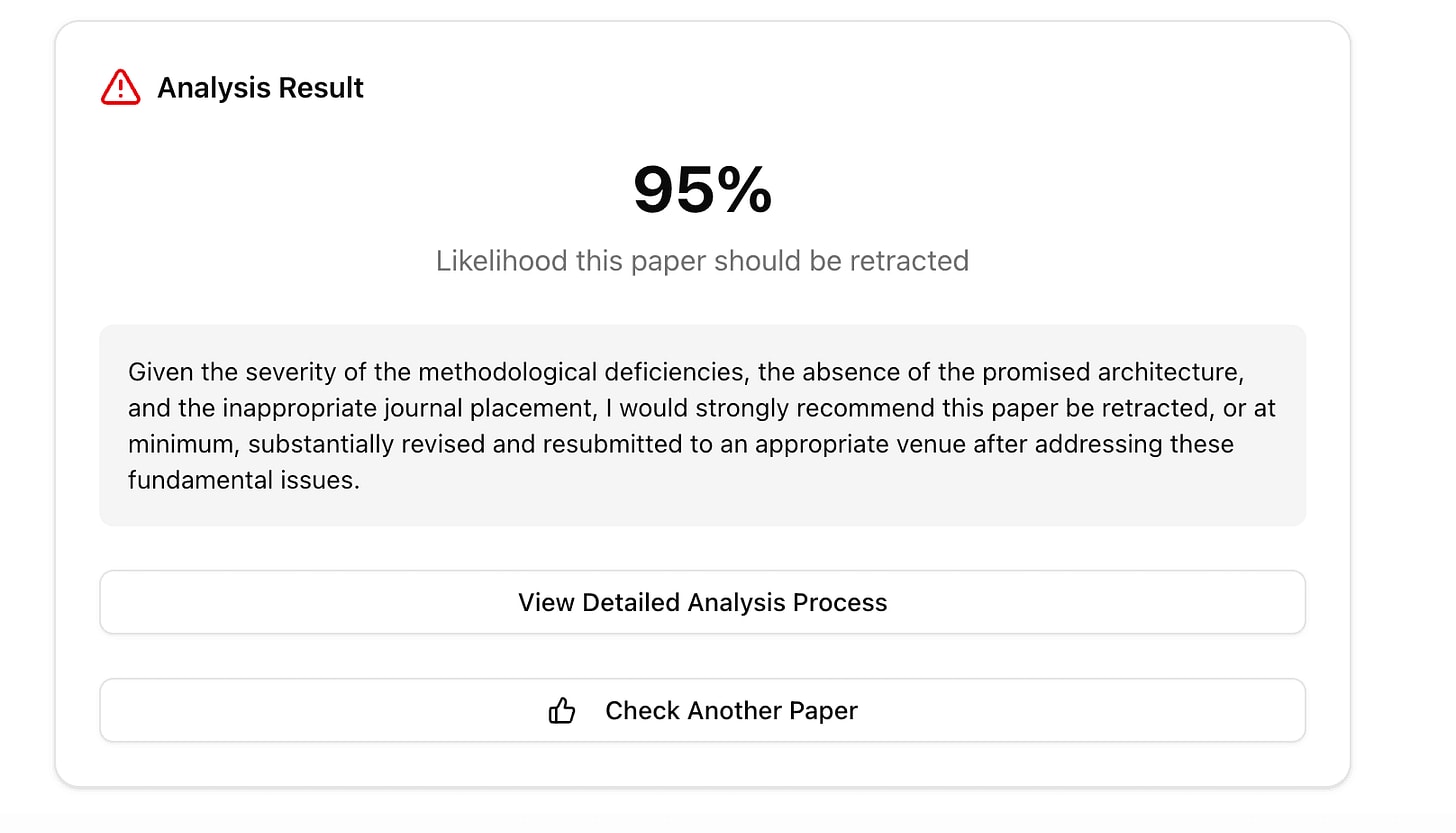
Demo: Starts 20:59
Description: There’s a lot of research. A lot of it seems bad. How much? We use language models to try and detect retraction-worthy errors in published literature. We purely reason from first-principles, without using meta-textual information.
Why did you build this? Panda: At Elicit, I spend a lot of time thinking about people’s info sources. I’ve also read metascience blogs for a long time. I assumed there would be some fraud/bad papers that modern reasoning models could catch pretty easily. (I didn’t think there’d be so much!)
What are you most proud of for this project? Panda: Very happy with doing a mix of “research” where we ran the numbers on how effective our technique was, but also prototyping and making something people can get their hands on
Source: https://github.com/CG80499/paper-retraction-detection
Demo link: https://papercop.vercel.app/
Comments: Had the most “wow this is fun to play with” factor, also “I can see this going viral”. I particularly liked that they had some semblance of evals (taking 100 papers and running it through), rather than just one or two demo cases; with LLM stuff it’s easy to focus on one or two happy cases, and I’m glad they didn’t.
Artificial Collective Intelligence, by Evan Hadfield
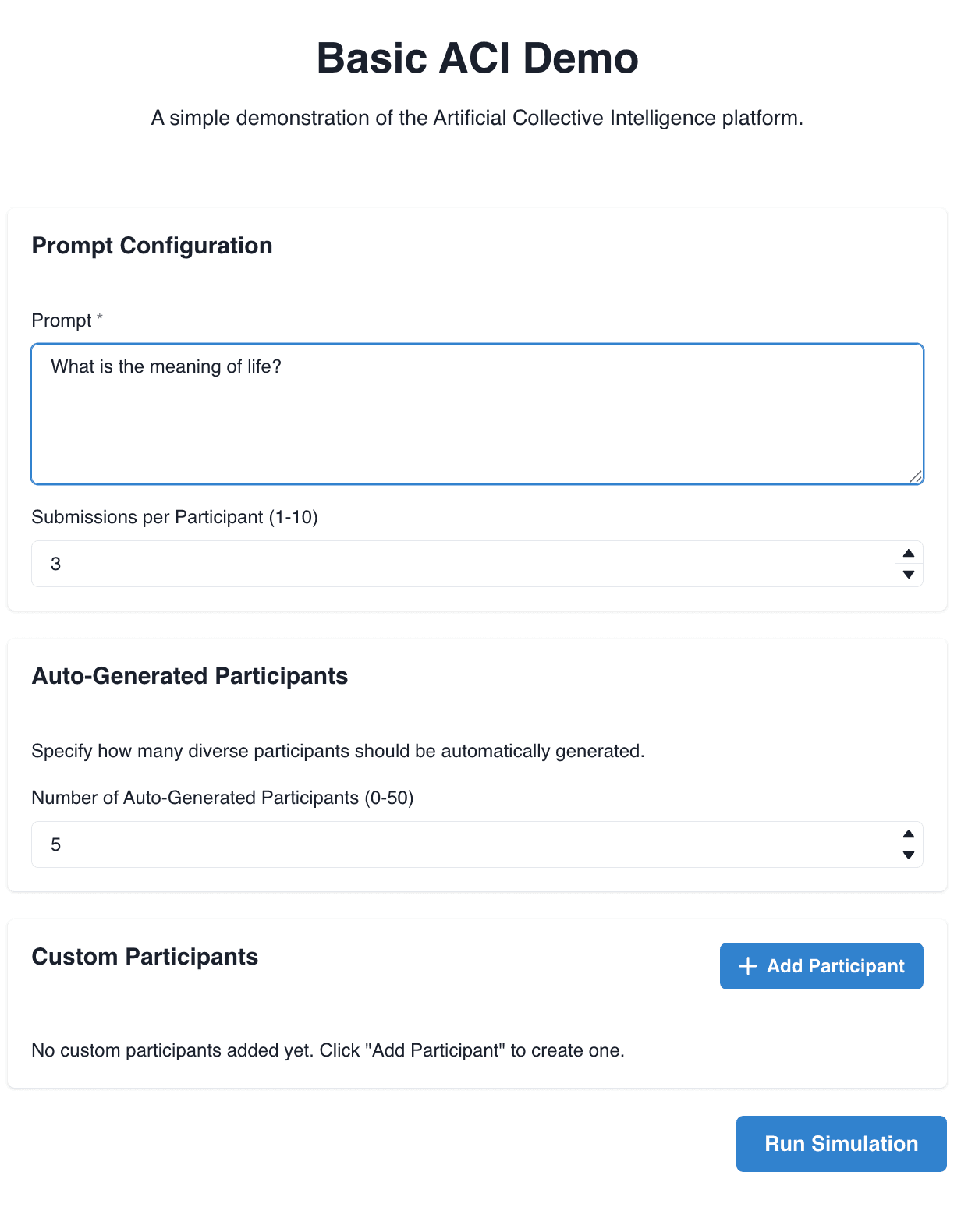
Demo: Starts 29:13
Description: ACI is a consensus-finding tool in the style of Polis / Community Notes, simulating a diverse range of perspectives. LLMs play the role of extra participants, submitting suggestions and voting on entries.
Demo link: https://aci-demos.vercel.app/
Comment: Most ambitious IMO — an entire platform of sims. With more time to develop this, I could see this as my favorite entry. Unfortunately, lost points for not having a live working demo :(
Thought Logger and Cyborg Extension, by Raymond Arnold
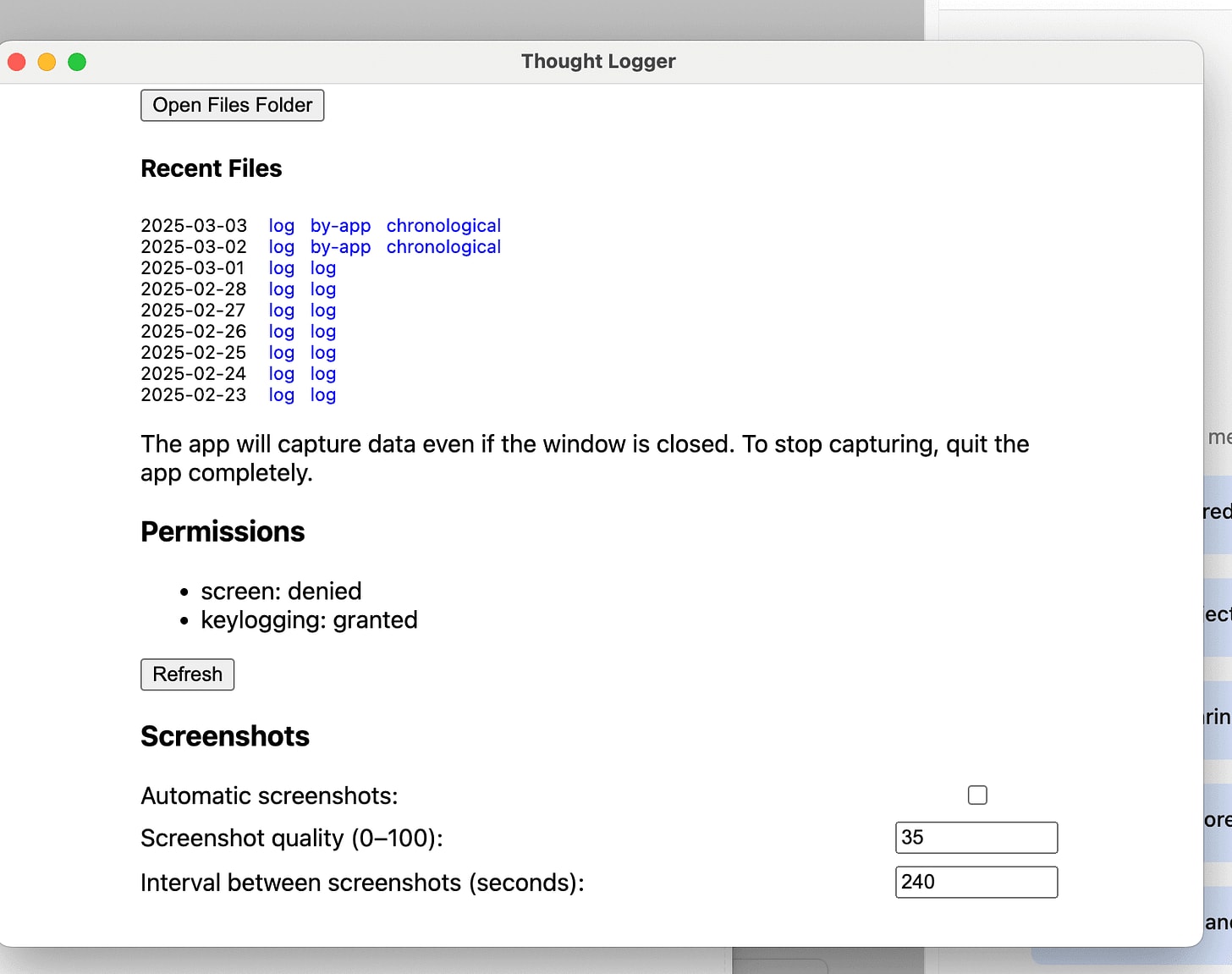
Demo: Starts 35:26
Description: I have a pair of products: – a keylogger, which tracks all your keystrokes (except from apps you put on a blocklist), and exposes it on a local server – and a “prompt library” chrome extension, which lets me store fairly complicated prompts and quickly run them, while pulling a website or the keylogger logs into context.
For demo day, I worked on a “useful personal predictions” prompt for the prompt library, which takes in my keylogs from the past 2 days, extrapolates what projects I seem to be working on, and generates prediction-statements about my project, that help guide my strategy. (i.e. “I’ll get at least 3 positive reports from users about my product helping them, spontaneously, in the next 2 months.”). When I see ones I like, I enter them into Fatebook.
Why did you build this? The general idea of the keylogger + prompt library is to set me up to leverage AI in all kinds of customized ways over the next couple years. I want to be an AI poweruser, and to have an easy affordance to invent new workflows that leverage it in a repeatable way.
I think “decision-relevant predictions” is a good tool to help you get calibrated on whether your current plans are on track to succeed. But operationalizing them is kind of annoying.
Source: The tools aren’t public yet, but message me at raemon777@gmail.com if you’d like to try them out.
Comments: Interesting set of work, I like the keylogger idea, picture of “record everything and have LLMs sort it out”. In practice had the flavor of people optimizing their personal setup a bit too much, and being hard to scale out (see also: complex Obsidian thought mapping, or spaced repetition)
Double-cruxes in the New York Times’ “The Conversation”, by Tilman Bayer

Demo: Starts 41:17
Description: “The Conversation” is a weekly political debate format in New York Times “Opinion” section between conservative(ish) journalist Bret Stephens and liberal(ish) journalist Gail Collins, ongoing since 2014. I used Gemini 2.0 Flash Thinking to identify double-cruxes in each debate, with the aim to track both participants' shifts over time.
Why did you build this?: Double-Cruxes are a somewhat intricate epistemic concept that so far doesn't seem to have made it very far beyond the LessWrong sphere. I wanted to explore whether one could use current LLMs to apply it at scale to a (non-cherrypicked) corpus of political debates aimed at a general audience.
What are you most proud of for this project?: After some experimentation, found a prompt+model combination that holds up quite well in vibe tests so far.
Source: Presentation slides from the hackathon
Comments: Unclear to me if double-cruxes is important epistemic tech, esp whether it has broad reach. Didn’t really have a working demo, sadly.
Trying to make GPT 4.5 Non-sycophantic (via a better system prompt), by Oliver Habryka

Demo: Starts 47:01
Description: I tried to make a system prompt for GPT 4.5 that actually pushes back on things I say and I can argue with in productive ways. It isn’t perfect, but honestly a bunch better than other experiences I’ve had arguing with LLMs.
Prompt: link
Comments: Many points for directly trying something out of the Owen’s spec. And for having the bravery to do a “non-technical” hack — as LLMs do more of the technical work, what’s left for humans is prompting well, imo. And for something that is immediately usable!
Squaretable, by David Nachman (winner)

Demo: Starts 55:27
Description: To assist a user in decision-making, the app uses LLMs to help the user come up with weighted factors, possible options, and factor values for each option. The UI consists of an always displayed table of the factors, options, weights, and values. The final score for each option is computed symbolically as a weighted sum based on the values and weights.
Comments: Great UI, information is pretty well laid out and yet compact, love the colors. Unfortunate that David didn’t seem to think that the LLM’s results were that good. Andreas: “maybe better UX if you add columns incrementally, easier to spot check”. Makes sense, kind of like git diffs or what Cursor does in chat mode.
What went well
- Hacks were pretty cool! Especially given that they all represented ~8 hours of work
- Many are minimal versions of products I really want to exist, and play with more
- Almost all of them felt like a worthwhile showcase, exploration of something interesting, and relevant to this field
Lots of great people came for this! Very hard to think of more central folks for AI for Epistemics:
Our lovely faces, once more. From left to right: Rafe Kennedy, Oli Habryka, Evan Hadfield, Kirill Chesnov, Owain Evans, Charlie George, Panda Smith, Gustavo Lacerda, Andreas Stuhlmüller, Austin Chen, David Nachbach (virtual), Lukas Finnveden, Tamera Lanham, Noa Nabeshima, Campbell Hutcheson, Keri Warr, Xyra Sinclair, Tilman Bayer, Raymon Arnold, Chris Lakin, Ozzie Gooen
Not pictured participants and viewers: William Saunders, Ben Goldhaber, Deger Turan, Vishal Maini, Ross Rheingans-Yoo, Ethan Alley, Dan Selsam, Stephen Grugett, David Chee, Saul Munn, Gavriel Kleinwaks and many others…
- Some of the goal of the hackathon, as with any event, is just to bring people together and have them stay in contact
- Good conversations at the beginning while participants were ideating, and throughout. Both on AI for Epistemics and other topics.
- Overall event felt smooth and cohesive, especially for being pulled together on not that much organizer time
- Pretty happy with the continuing artifacts that we produced out of this hackathon (the showcase page, the video recordings, this writeup)
- Somewhat more effortful to do all this compared to typical hackathons Austin has run, but hopefully worthwhile when trying to incubate a new field
- Mox seemed to be a good venue for this event! This was just our third week of operating, but I think our venue supported the hackathon well.
- One participant remarked:
Something I like about your office is that it seems to naturally create the Cal Newport Deep Work architecture, where the further in you go the more deepworky it is
What could have gone better
- Fewer submitted hacks than we’d hoped for
- Had ~40 people around but only ~10 submissions. Ideally more like 15-20?
- Maybe we should have promoted this event harder, or cast a wider net?
- There’s a tradeoff on average participant quality vs number of submissions.
- But maybe projects are hit-based, so having the best projects matters more than having a high average quality
- Maybe try to get higher commitment from folks, if we run this again
- Hoping to have discovered more people from outside our current networks, who are excited for AI for Epistemics
- 2 of the 3 prizes went to teams from Elicit
- (Which says something about how great the Elicit team is, in case anyone out there is thinking about finding a new job…)
- 2 of the 3 prizes went to teams from Elicit
- Unclear path to deployment for these projects, or continuing impact
- Admittedly, this is a standard problem with a hackathon form factor, especially when the hackathon isn’t housed within an org/for specific product features
- Not sure we made great use of the ideas doc & categories that Owen/Raymond/Ben compiled?
- But hopefully, their work will set a stage of “this is what AI for Epistemics is about”
- Perhaps having such specified categories was too confusing for participants
- One participant asked, “do I have to do something in these categories?” (A: no, but it’s bad that this wasn’t clear)
- As judges: hard to give great judgements and feedback in short amount of time, by just looking at demos and asking questions
- The format of “demos in front of an audience” do bias towards presentation ability and flashiness, over usability of a core product
- Might change up the structure for next time
- More time for judges and audience to play with hackathon demos?
- Open up voting to the public, so it’s more democratized?
Final notes
Overall, we’re very happy with how this hackathon turned out. Building a new field from scratch is difficult, high-dimensional problem, and this is just one step along the way; but I think we made meaningful progress, with ideas we brainstormed, hacks we demoed, and people we gathered.
After the end of the hackathon, a few of the judges and participants continued to discuss: “What’s next for AI for Epistemics? How does one build a nascent field? Is ‘AI for Epistemics’ even a good name?” We’ll try to share more on this in the coming days; until then, if AI for Epistemics excites you, leave a comment or reach out to us!
Possibly naive question: are the projects open source, shared code, and forkable?
Some are! Check out each project in the post, some have links to source code.
(I do wish we'd gotten source code for all of them, next time might consider an open source hackathon!)