To be sure, ensuring AI development proceeds ethically is a valuable aim, but I claim this goal is *not *the same thing as “AI alignment”, in the sense of getting AIs to try to do what people want.
I've argued that we should keep using this broader definition, in part for historical reasons, and in part so that AI labs (and others, such as EAs) can more easily keep in mind that their ethical obligations/opportunities go beyond making sure that AI does what people want. But it seems that I've lost that argument so it's good to periodically remind people to think more broadly about their obligations/opportunities. (You don't say this explicitly, but I'm guessing it's part of your aim in writing this post?)
(Recently I've been using "AI safety" and "AI x-safety" interchangeably when I want to refer to the "overarching" project of making the AI transition go well, but I'm open to being convinced that we should come up with another term for this.)
That said, I think I'm less worried than you about "selfishness" in particular and more worried about moral/philosophical/strategic errors in general. The way most people form their morality is scary to me, and personally I would push humanity to be more philosophically competent/inclined before pushing it to be less selfish.
I agree. I have two main things to say about this point:
My thesis is mainly empirical. I think, as a matter of verifiable fact, that if people solve the technical problems of AI alignment, they will use AIs to maximize their own economic consumption, rather than pursue broad utilitarian goals like "maximize the amount of pleasure in the universe". My thesis is independent of whatever we choose to call "AI alignment".
Separately, I think the war over the semantic battle seems to be trending against those on "your side". The major AI labs seem to use the word "aligned" to mean something closer to "the AI does what users want (and also respects moral norms, and doesn't output harmful content etc.)" rather than "the AI produces positive outcomes in the world morally, even if this isn't what the user wants". Personally, the word "alignment" also just seems to conjure an image of the AI trying to do what you want, rather than fighting you if you decide to do something bad or selfish.
That said, I think I'm less worried than you about "selfishness" in particular and more worried about moral/philosophical/strategic errors in general.
There is a lot I could say about this topic, but I'll just say a few brief things here. In general I think the degree to which moral reasoning determines the course of human history is frequently exaggerated. I think mundane economic forces are simply much more impactful. Indeed, I'd argue that much of what we consider human morality is simply a byproduct of social coordination mechanisms that we use to get along with each other, rather than the result of deep philosophical reflection.
At the very least, mundane economic forces seem to have been more impactful historically compared to philosophical reasoning. I probably expect the future of society to resemble the past more strongly than you do?
I think, as a matter of verifiable fact, that if people solve the technical problems of AI alignment, they will use AIs to maximize their own economic consumption, rather than pursue broad utilitarian goals like “maximize the amount of pleasure in the universe”.
If you extrapolate this out to after technological maturity, say 1 million years from now, what does selfish "economic consumption" look like? I tend to think that people's selfish desires will be fairly easily satiated once everyone is much much richer and the more "scalable" "moral" values would dominate resource consumption at that point, but it might just be my imagination failing me.
I think mundane economic forces are simply much more impactful.
Why does "mundane economic forces" cause resources to be consumed towards selfish ends? I think economic forces select for agents who want to and are good at accumulating resources, but will probably leave quite a bit of freedom in how those resources are ultimately used once the current cosmic/technological gold rush is over. It's also possible that our future civilization uses up much of the cosmic endowment through wasteful competition, leaving little or nothing to consume in the end. Is that's your main concern?
(By "wasteful competition" I mean things like military conflict, costly signaling, races of various kinds that accumulate a lot of unnecessary risks/costs. It seems possible that you categorize these under "selfishness" whereas I see them more as "strategic errors".)
Why does "mundane economic forces" cause resources to be consumed towards selfish ends?
Because most economic agents are essentially selfish. I think this is currently true, as a matter of empirical fact. People spend the vast majority of their income on themselves, their family, and friends, rather than using their resources to pursue utilitarian/altruistic ideals.
I think the behavioral preferences of actual economic consumers, who are not mostly interested in changing their preferences via philosophical reflection, will more strongly shape the future than other types of preferences. Right now that means human consumers determine what is produced in our economy. In the future, AIs themselves could become economic consumers, but in this post I'm mainly talking about humans as consumers.
I tend to think that people's selfish desires will be fairly easily satiated once everyone is much much richer and the more "scalable" "moral" values would dominate resource consumption at that point, but it might just be my imagination failing me.
I think it's currently very unclear whether selfish preferences can be meaningfully "satiated". Current humans are much richer than their ancestors, and yet I don't think it's obvious that we are more altruistic than our ancestors, at least when measured by things like the fraction of our income spent on charity. (But this is a complicated debate, and I don't mean to say that it's settled.)
It's also possible that our future civilization uses up much of the cosmic endowment through wasteful competition, leaving little or nothing to consume in the end. Is that's your main concern?
This seems unlikely to me, but it's possible. I don't think it's my main concern. My guess is that we still likely fundamentally disagree on something like "how much will the future resemble the past?".
On this particular question, I'd point out that historically, competition hasn't resulted in the destruction of nearly all resources, leaving little to nothing to consume in the end. In fact, insofar as it's reasonable to talk about "competition" as a single thing, competition in the past may have increased total consumption on net, rather than decreased it, by spurring innovation to create more efficient ways of creating economic value.
(Recently I've been using "AI safety" and "AI x-safety" interchangeably when I want to refer to the "overarching" project of making the AI transition go well, but I'm open to being convinced that we should come up with another term for this.)
I’ve been using the term “Safe And Beneficial AGI” (or more casually, “awesome post-AGI utopia”) as the overarching “go well” project, and “AGI safety” as the part where we try to make AGIs that don’t accidentally [i.e. accidentally from the human supervisors’ / programmers’ perspective] kill everyone, and (following common usage according to OP) “Alignment” for “The AGI is trying to do things that the AGI designer had intended for it to be trying to do”.
(I didn’t make up the term “Safe and Beneficial AGI”. I think I got it from Future of Life Institute. Maybe they in turn got it from somewhere else, I dunno.)
Some researchers think that the “correct” design intentions (for an AGI’s motivation) are obvious, and define the word “alignment” accordingly. Three common examples are (1) “I am designing the AGI so that, at any given point in time, it’s trying to do what its human supervisor wants it to be trying to do”—this AGI would be “aligned” to the supervisor’s intentions. (2) “I am designing the AGI so that it shares the values of its human supervisor”—this AGI would be “aligned” to the supervisor. (3) “I am designing the AGI so that it shares the collective values of humanity”—this AGI would be “aligned” to humanity.
I’m avoiding this approach because I think that the “correct” intended AGI motivation is still an open question. For example, maybe it will be possible to build an AGI that really just wants to do a specific, predetermined, narrow task (e.g. design a better solar cell), in a way that doesn’t involve taking over the world etc. Such an AGI would not be “aligned” to anything in particular, except for the original design intention. But I still want to use the term “aligned” when talking about such an AGI.
Great post. A few months I wrote a private comment that makes a very similar point but frames it somewhat differently; I share it below in case it is of any interest.
Victoria Krakovna usefully defines the outer and inner alignment problems in terms of different “levels of specification”: the outer alignment problem is the problem of aligning the ideal specification (the goals of the designer) with the design specification (the goal implemented in the system), while the inner alignment problem is the problem of aligning this design specification with the revealed specification (the goal the system actually pursues). I think this model could be extended to define a third subcomponent of the alignment problem, next to the inner and outer alignment problems. This would be the problem of moving from what we may call the normative specification (the goals that ought to be pursued) to the ideal specification (though it would be clearer to call the latter “human specification”).
This “third alignment problem” is rarely formulated explicitly, in part because “AI alignment” is ambiguously defined to mean either “getting AI systems to do what we want them to do” and “getting AI systems to do what they ought to do”. But it seems important to distinguish between normative and human specifications, not only because (arguably) “humanity” may fail to pursue the goals it should, but also because the team of humans that succeeds in building the first AGI may not represent the goals of “humanity”. So this should be relevant both to people (like classical and negative utilitarians) with values that deviate from humanity’s in ways that could matter a lot, and to “commonsense moralists” who think we should promote human values but are concerned that AI designers may not pursue these values (because these people may not be representative members of the population, because of self-interest, or because of other reasons).
It’s unclear to me how important this third alignment problem is relative to the inner or outer alignment problems. But it seems important to be aware that it is a separate problem so that one can think about it explicitly and estimate its relative importance.
Great post! I've written a paper along similar lines for the SERI Conference in April 2023 here, titled "AI Alignment Is Not Enough to Make the Future Go Well." Here is the abstract:
AI alignment is commonly explained as aligning advanced AI systems with human values. Especially when combined with the idea that AI systems aim to optimize their world based on their goals, this has led to the belief that solving the problem of AI alignment will pave the way for an excellent future. However, this common definition of AI alignment is somewhat idealistic and misleading, as the majority of alignment research for cutting-edge systems is focused on aligning AI with task preferences (training AIs to solve user-provided tasks in a helpful manner), as well as reducing the risk that the AI would have the goal of causing catastrophe.
We can conceptualize three different targets of alignment: alignment to task preferences, human values, or idealized values.
Extrapolating from the deployment of advanced systems such as GPT-4 and from studying economic incentives, we can expect AIs aligned with task preferences to be the dominant form of aligned AIs by default.
Aligning AI to task preferences will not by itself solve major problems for the long-term future. Among other problems, these include moral progress, existential security, wild animal suffering, the well-being of digital minds, risks of catastrophic conflict, and optimizing for ideal values. Additional efforts are necessary to motivate society to have the capacity and will to solve these problems.
I don't necessarily think of humans as maximizing economic consumption, but I argue that power-seeking entities (e.g., some corporations or hegemonic governments using AIs) will have predominant influence, and these will not have altruistic goals to optimize for impartial value, by default.
This post is a great exemplar for why the term “AI alignment” has proven a drag on AI x-risk safety. The concern is and has always been that AI would dominate humanity like humans dominate animals. All of the talk about aligning AI to “human values” leads to pedantic posts like this one arguing about what “human values” are and how likely AIs are to pursue them.
Is there a particular part of my post that you disagree with? Or do you think the post is misleading. If so, how?
I think there are a lot of ways AI could go wrong, and "AIs dominating humans like how humans dominate animals" does not exhaust the scope of potential issues.
Nice post! I generally agree and I believe this is important.
I have one question about this. I'll distinguish between two different empirical claims. My sense is that you argue for one of them and I'd be curious whether you'd also agree with the other. Intuitively, it seems like there are lots of different but related alignment problems: "how can we make AI that does what Alice wants it to do?", "how can we make AI that does what the US wants it to do?", "how can we make AI follow some set of moral norms?", "how can we make AI build stuff in factories for us, without it wanting to escape and take over the world?", "how can we make AI that helps us morally reflect (without manipulating us in ways we don't want)?", "how can we make a consequentialist AI that doesn't do any of the crazy things that consequentialism implies in theory?". You (and I and everyone else in this corner of the Internet) would like the future to solve the more EA-relevant alignment questions and implement the solutions, e.g., help society morally reflect, reduce suffering, etc. Now here are two claims about how the future might fail to do this:
1. Even if all alignment-style problems were solved, then humans would not implement the solutions to the AI-y alignment questions. E.g., if there was the big alignment library that just contains the answer to all these alignment problems, then individuals would grab "from pauper to quadrillionaire and beyond with ChatGPT-n", not "how to do the most you can do better with ChatGPT-n", and so on. (And additionally one has to hold that people's preferences for the not-so-ethical books/AIs will not just go away in the distant future. And I suppose for any of this to be relevant, you'd also need to believe that you have some sort of long-term influence on which books people get from the library.) 2. Modern-day research under the "alignment" (or "safety") umbrella is mostly aimed at solving the not-so-EA-y alignment questions, and does not put much effort toward the more specifically-EA-relevant questions. In terms of the alignment library analogy, there'll be lots of books in the aisle on how to get your AI to build widgets without taking over the world, and not so many books in the aisle on how to use AI to do moral reflection and the like. (And again one has to hold that this has some kind of long-term effect, despite the fact that all of these problems can probably be solved _eventually_. E.g., you might think that for the future to go in a good direction, we need AI to help with moral reflection immediately once we get to human-level AI, because of some kinds of lock-in.)
My sense is that you argue mostly for 1. Do you also worry about 2? (I worry about both, but I mostly think about 2, because 1 seems much less tractable, especially for me as a technical person.)
How about coordination and multi-scale planning (optimising both for short term and long term) failures? They both have economic value (i.e., economic value is lost when these failures happen), and they are both at least in part due to the selfish, short-term, impulsive motives/desires/"values" of humans.
E.g., I think people would like to buy an AI that manipulated them into following their exercise plan through some tricks, and likewise they would like to "buy" (build) collectively an AI that restricts their selfishness for the median benefit and the benefit of their own children and grandchildren.
I would just like to point out that this consideration of there being two different kinds of AI alignment, one more parochial, and one more global, is not entirely new. The Brookings Institute put out a paper about this in 2022.
This was a nice post. I haven't thought about these selfishness concerns before, but I did think about possible dangers arising from aligned servant AI used as a tool to improve military capabilities in general. A pretty damn risky scenario in my view and one that will hugely benefit whoever gets there first.
In this post I want to make a simple point that I think has big implications.
I sometimes hear EAs talk about how we need to align AIs to "human values", or that we need to make sure AIs are benevolent. To be sure, ensuring AI development proceeds ethically is a valuable aim, but I claim this goal is not the same thing as "AI alignment", in the sense of getting AIs to try to do what people want.
My central contention here is that if we succeed at figuring out how to make AIs pursue our intended goals, these AIs will likely be used to maximize the economic consumption of existing humans at the time of alignment. And most economic consumption is aimed at satisfying selfish desires, rather than what we'd normally consider our altruistic moral ideals.
It's important to note that my thesis here is not merely a semantic dispute about what is meant by "AI alignment". Instead, it is an empirical prediction about how people will actually try to use AIs in practice. I claim that people will likely try to use AIs mostly to maximize their own economic consumption, rather than to pursue ideal moral values.
Critically, only a small part of human economic consumption appears to be what impartial consequentialism would recommend, including the goal of filling the universe with numerous happy beings who live amazing lives.
Let me explain.
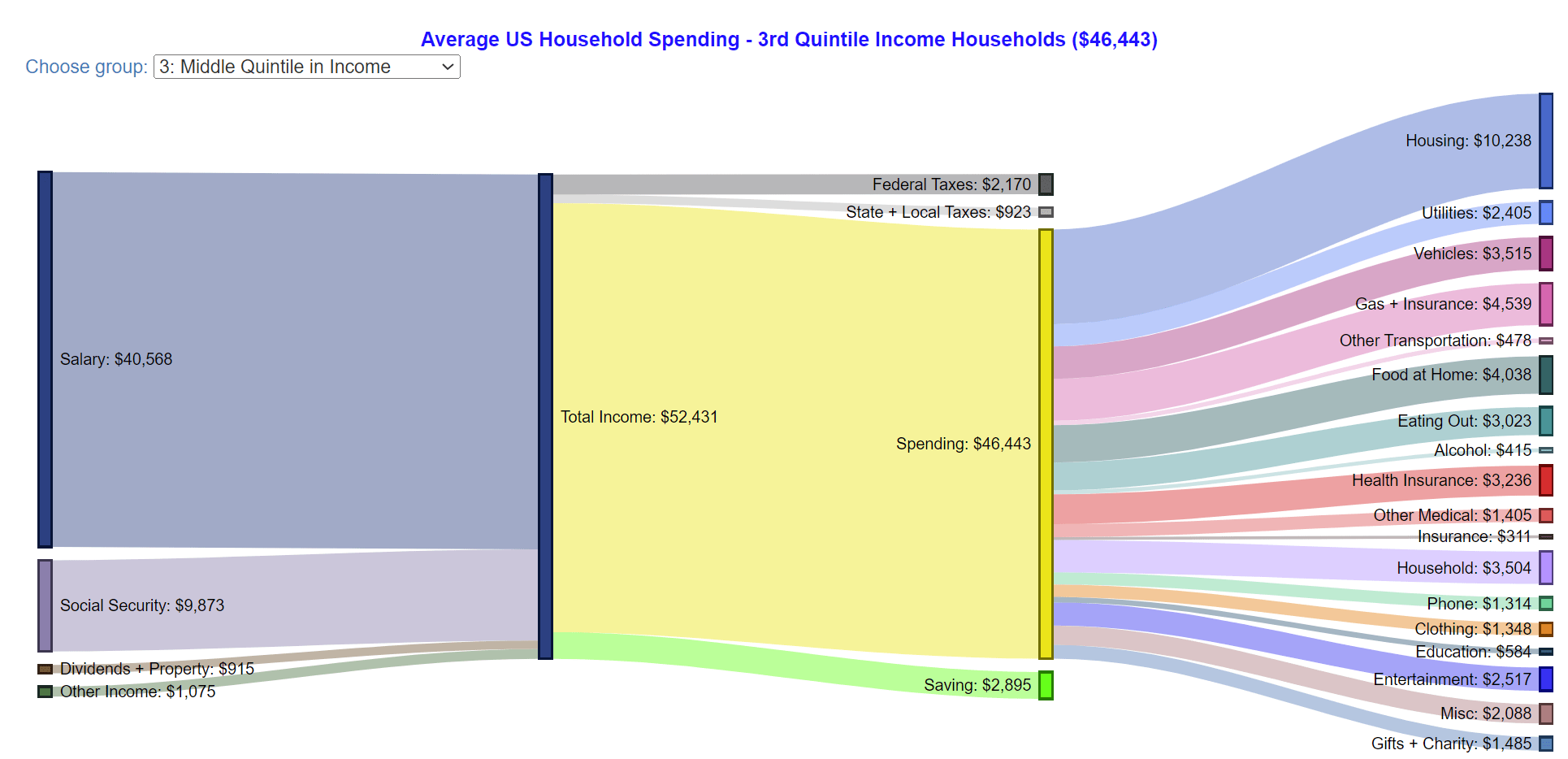
Consider how people currently spend their income. Below I have taken a plot from the blog Engaging Data, which borrowed data from the Bureau of Labor Statistics in 2019. It represents a snapshot of how the median American household spends their income.
Most of their money is spent on the type of mundane consumption categories you'd expect: housing, utilities, vehicles etc. It is very likely that the majority of this spending is meant to provide personal consumption for members of the household or perhaps other family and friends, rather than strangers. Near the bottom of the chart, we find that only 3.1% of this spending is on what we'd normally consider altruism: voluntary gifts and charity.
To be clear, this plot does not comprise a comprehensive assessment of the altruism of the median American household. Moreover, moral judgement is not my intention here. Instead, my intention is to emphasize the brute fact that when people are given wealth, they primarily spend it on themselves, their family, or their friends, rather than to pursue benevolent moral ideals.
This fact is important because, to a first approximation, aligning AIs with humans will simply have the effect of greatly multiplying the wealth of existing humans — i.e. the total amount of resources that humans have available to spend on whatever they wish. And there is little reason to think that if humans become extraordinarily wealthy, they will follow idealized moral values. To see why, just look at what current people already do, who are many times richer than their ancestors centuries ago. All that extra wealth did not make us extreme moral saints; instead, we still mostly care about ourselves, our family, and our friends.
Why does this fact make any difference? Consider the prescription of classical utilitarianism to maximize population size. If given the choice, humans would likely not spend their wealth to pursue this goal. That's because humans care far more about our own per capita consumption than global aggregate utility. When humans increase population size, it is usually a byproduct of their desire to have a family, rather than being the result of some broader utilitarian moral calculation.
Here's another example. When given the choice to colonize the universe, future humans will likely want a rate of return on their investment, rather than merely deriving satisfaction from the fact that humanity's cosmic endowment is being used well. In other words, we will likely send out the von Neumann probes as part of a scheme to benefit ourselves, not out of some benevolent duty to fill the universe with happy beings.
Now, I'm not saying selfishness is automatically bad. Indeed, when channeled appropriately, selfishness serves the purpose of making people happy. After all, if everyone is rich and spends money on themselves, that's not obviously worse than a situation in which everyone is rich and spends their money on each other.
But, importantly, humans are not the only moral patients who will exist.
Consider that the vast majority of humans are happy to eat meat, even if many of them privately confess that they don't like causing animal suffering. To most people, the significant selfish costs of giving up meat simply outweigh the large non-selfish benefits of reducing animal suffering. And so, most people don't give up meat.
The general pattern here is that, while most humans are not evil, whenever there's a non-trivial conflict between selfish preferences and altruistic preferences, our selfish preferences usually trump the altruistic ones, even at the cost of great amounts of suffering. This pattern seems likely to persist into the future.
Of course, the fact that humans are primarily selfish doesn't mean that humans will necessarily cause a ton of suffering in the future because — unlike with current meat consumption — it might one day become feasible to mitigate suffering without incurring substantial selfish costs.
At the same time, it's critically important to avoid wishful thinking.
The mere possibility that in the future there might exist no tradeoff between suffering and economic consumption does not imply that will be the case. It remains plausible that humans in the future, equipped with aligned AIs, will produce vast amounts of suffering in the service of individual human preferences, just as our current society produces lots of animal suffering to satisfy current human wants. If true, the moral value of AI alignment is uncertain, and potentially net-negative.
As just one example of how things could go badly even if we solve AI alignment, it may turn out that enabling AIs to suffer enhances their productivity or increases the efficiency of AI training. In this case there would be a direct non-trivial tradeoff between the satisfaction of individual human preferences and the achievement of broad utilitarian ideals. I consider this scenario at least somewhat likely.
Ultimately I don't think we should talk about AIs being aligned with some abstract notion of "human values" or AIs being aligned with "humanity as a whole". In reality, we will likely try to align AIs with various individual people, who have primarily selfish motives. Aligned AIs are best thought of as servants who follow our personal wishes, whatever those wishes may be, rather than idealized moral saints who act on behalf of humanity, or all sentient life.
This does not mean that aligned AIs won't follow moral constraints or human moral norms. Aligned AIs may indeed follow various constraints, including following the law. But following moral norms is not the same thing as being a moral saint: selfish people already have strong incentives to obey the law purely out of fear of punishment.
Crucially, the moral norms that aligned AIs follow will be shaped by the preferences of actual humans or society in general, rather than by lofty altruistic ideals. If AIs obey our moral norms, that does not simply imply they will be benevolent anymore than current laws constrain people's ability to eat meat.
Can't we just build benevolent AIs instead of AI servants that fulfill our selfish desires? Well, we could do that. But people would not want to purchase such AIs. When someone hires a worker, they generally want the worker to do work for them, not for others. A worker who worked for humanity as a whole, or for all sentient life, would be much less likely to be hired than someone who works directly for their employer, and does what they want. The same principle will likely apply to AIs.
To make my point clearer, we can try to distinguish what might be meant by "human values". The concept can either refer to a broad moral ideal, or it can refer to the the preferences of actual individual humans.
In the first case, there will likely be little economic incentive to align AIs to human values, and thus aligning AIs to human values does not appear to be a realistic end-goal. In the second case, human values refer to the preferences of primarily selfish individual people, and satisfying these preferences is not identical to the achievement of broad, impartial moral goals.
Of course, it might still be very good to solve AI alignment. Unaligned AIs might have preferences we'd find even worse than the preferences of currently-living individual humans, especially from our own, selfish perspective. Yet my point is merely that the achievement of AI alignment not the same as the achievement of large-scale, altruistic moral objectives. The two concepts are logically and empirically separate, and there is no necessary connection between them.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
Why building and backing Welfare Tech companies may be one of the most promising things we can do for billions of animals.
I used AI to assist in writing this post, but I’ve rewritten it extensively and endorse it.
* Announcing the launch of Spring Innovation Fund, a not-for-profit venture philanthropy studio and fund built specifical...


There was at least one early definition of "AI alignment" to mean something much broader:
I've argued that we should keep using this broader definition, in part for historical reasons, and in part so that AI labs (and others, such as EAs) can more easily keep in mind that their ethical obligations/opportunities go beyond making sure that AI does what people want. But it seems that I've lost that argument so it's good to periodically remind people to think more broadly about their obligations/opportunities. (You don't say this explicitly, but I'm guessing it's part of your aim in writing this post?)
(Recently I've been using "AI safety" and "AI x-safety" interchangeably when I want to refer to the "overarching" project of making the AI transition go well, but I'm open to being convinced that we should come up with another term for this.)
That said, I think I'm less worried than you about "selfishness" in particular and more worried about moral/philosophical/strategic errors in general. The way most people form their morality is scary to me, and personally I would push humanity to be more philosophically competent/inclined before pushing it to be less selfish.
I agree. I have two main things to say about this point:
There is a lot I could say about this topic, but I'll just say a few brief things here. In general I think the degree to which moral reasoning determines the course of human history is frequently exaggerated. I think mundane economic forces are simply much more impactful. Indeed, I'd argue that much of what we consider human morality is simply a byproduct of social coordination mechanisms that we use to get along with each other, rather than the result of deep philosophical reflection.
At the very least, mundane economic forces seem to have been more impactful historically compared to philosophical reasoning. I probably expect the future of society to resemble the past more strongly than you do?
If you extrapolate this out to after technological maturity, say 1 million years from now, what does selfish "economic consumption" look like? I tend to think that people's selfish desires will be fairly easily satiated once everyone is much much richer and the more "scalable" "moral" values would dominate resource consumption at that point, but it might just be my imagination failing me.
Why does "mundane economic forces" cause resources to be consumed towards selfish ends? I think economic forces select for agents who want to and are good at accumulating resources, but will probably leave quite a bit of freedom in how those resources are ultimately used once the current cosmic/technological gold rush is over. It's also possible that our future civilization uses up much of the cosmic endowment through wasteful competition, leaving little or nothing to consume in the end. Is that's your main concern?
(By "wasteful competition" I mean things like military conflict, costly signaling, races of various kinds that accumulate a lot of unnecessary risks/costs. It seems possible that you categorize these under "selfishness" whereas I see them more as "strategic errors".)
Because most economic agents are essentially selfish. I think this is currently true, as a matter of empirical fact. People spend the vast majority of their income on themselves, their family, and friends, rather than using their resources to pursue utilitarian/altruistic ideals.
I think the behavioral preferences of actual economic consumers, who are not mostly interested in changing their preferences via philosophical reflection, will more strongly shape the future than other types of preferences. Right now that means human consumers determine what is produced in our economy. In the future, AIs themselves could become economic consumers, but in this post I'm mainly talking about humans as consumers.
I think it's currently very unclear whether selfish preferences can be meaningfully "satiated". Current humans are much richer than their ancestors, and yet I don't think it's obvious that we are more altruistic than our ancestors, at least when measured by things like the fraction of our income spent on charity. (But this is a complicated debate, and I don't mean to say that it's settled.)
This seems unlikely to me, but it's possible. I don't think it's my main concern. My guess is that we still likely fundamentally disagree on something like "how much will the future resemble the past?".
On this particular question, I'd point out that historically, competition hasn't resulted in the destruction of nearly all resources, leaving little to nothing to consume in the end. In fact, insofar as it's reasonable to talk about "competition" as a single thing, competition in the past may have increased total consumption on net, rather than decreased it, by spurring innovation to create more efficient ways of creating economic value.
I’ve been using the term “Safe And Beneficial AGI” (or more casually, “awesome post-AGI utopia”) as the overarching “go well” project, and “AGI safety” as the part where we try to make AGIs that don’t accidentally [i.e. accidentally from the human supervisors’ / programmers’ perspective] kill everyone, and (following common usage according to OP) “Alignment” for “The AGI is trying to do things that the AGI designer had intended for it to be trying to do”.
(I didn’t make up the term “Safe and Beneficial AGI”. I think I got it from Future of Life Institute. Maybe they in turn got it from somewhere else, I dunno.)
(See also: my post Safety ≠ alignment (but they’re close!))
See also a thing I wrote here: