I recently released two working papers that seek to integrate EA principles into financial economics. Both papers are academic versions of ideas we've been working on in much more practical contexts at the Total Portfolio Project. I hope to share more of our work with the wider community in the future. Right now I would most appreciate feedback either from other economists or community polymaths/brave souls who are curious enough to open these papers.
The first takes a cutting edge but otherwise standard financial model for the economy, adds in altruistic preferences, and then examines the optimal investment policy for different types of altruistic investors (e.g. patient philanthropists, urgent philanthropists). The second sets up the framework I use in the first paper. This includes highlighting the importance of the counterfactual and making the case for probabilistic reasoning about impact.
Some reasons you might actually get something out of reading these papers:
- The model naturally leads to a version of the SSN cause prioritization framework that can be applied at both micro and macro levels. It includes different definitions of 'neglectedness' depending on the context.
- Mission-correlated premia, a generalization of the idea of 'mission hedging', arise in both the model and the framework.
- I also discuss model uncertainty, moral uncertainty and how these considerations might be integrated into investment models.
While I don't think asking for feedback on academic working papers is the norm on the forum, I wanted to do this because both papers present EA ideas and I cite several EA authors. So I'd be particularly interested in feedback that helps me improve how I represent the community and its ideas.
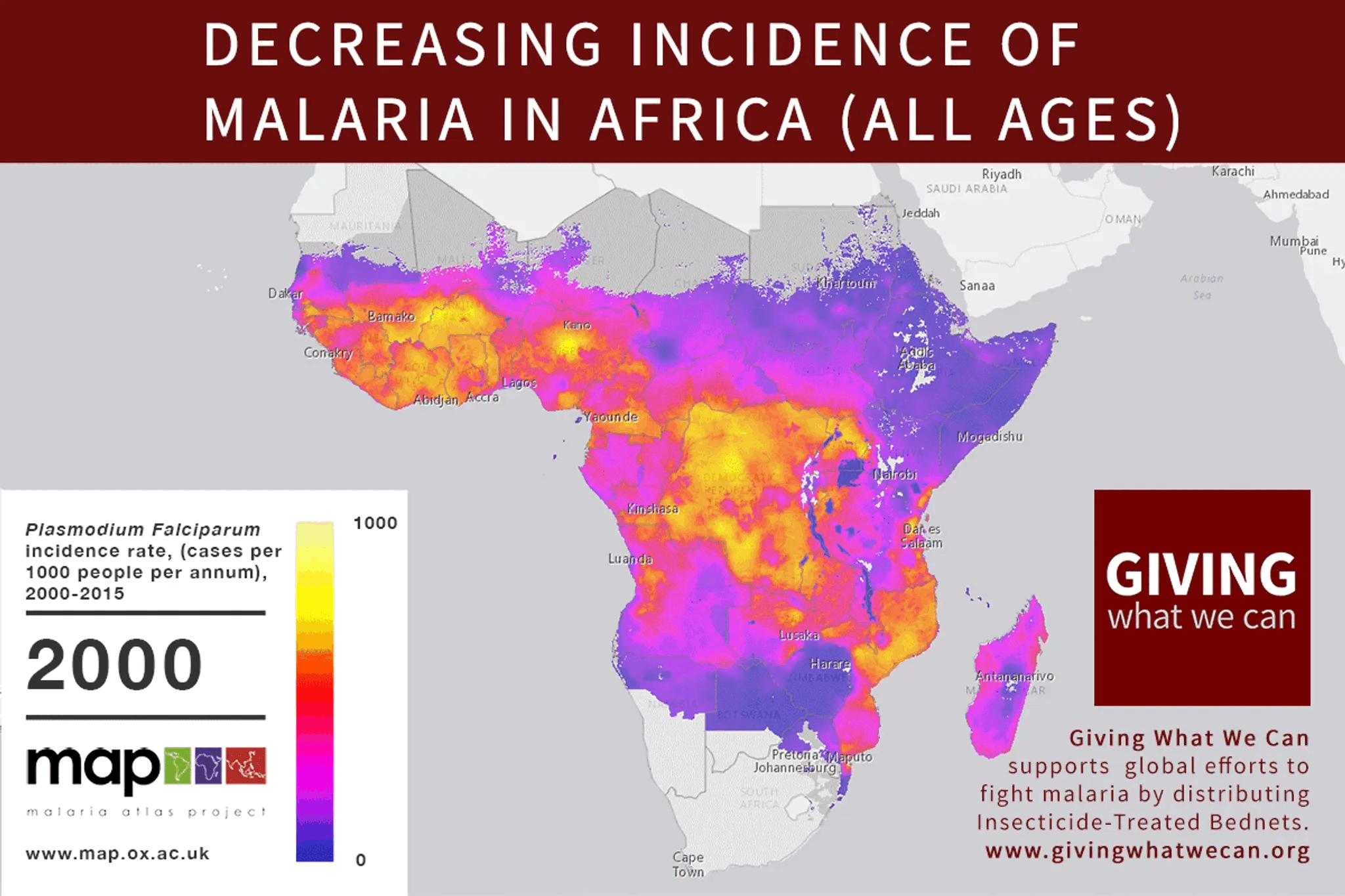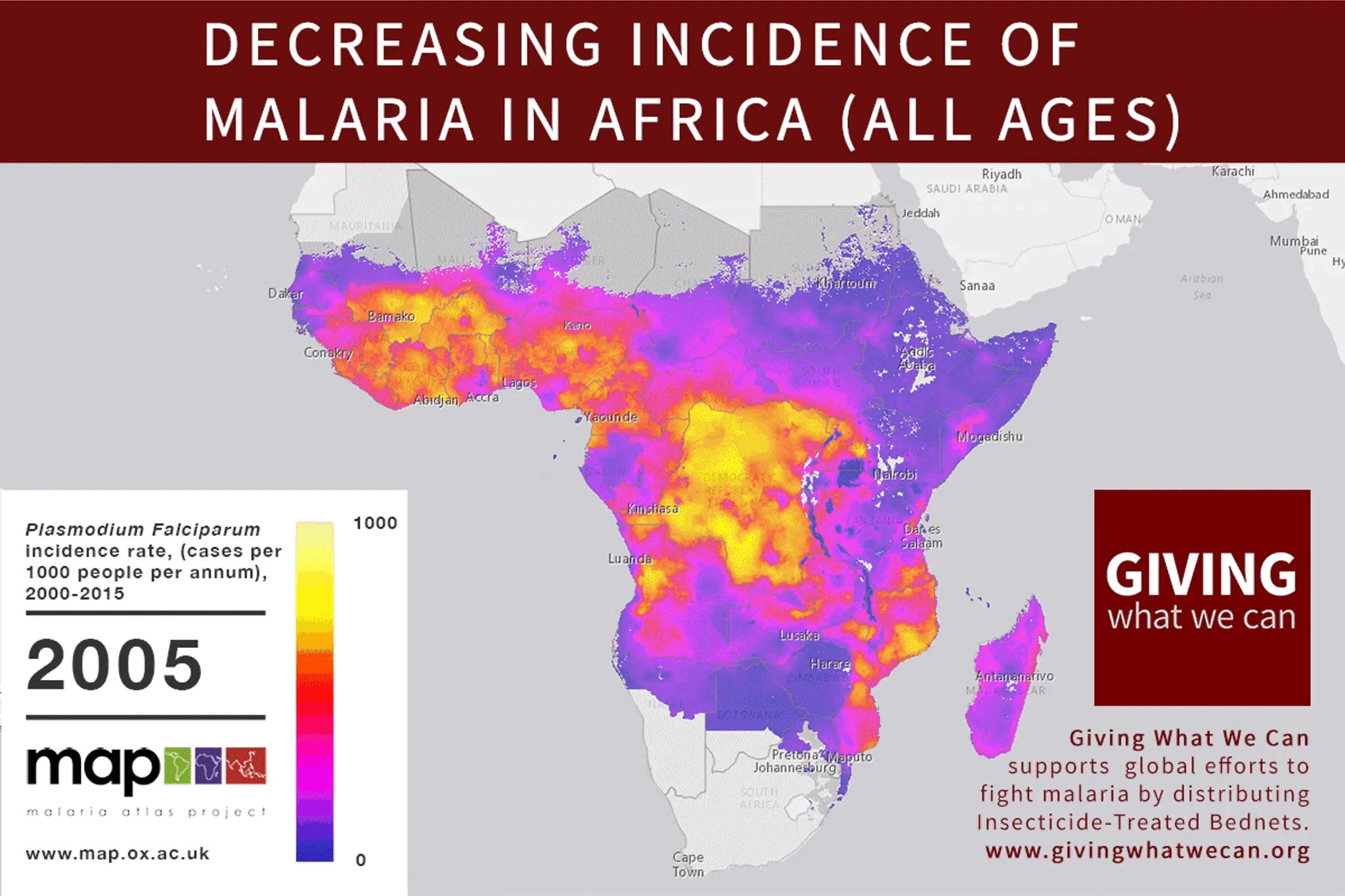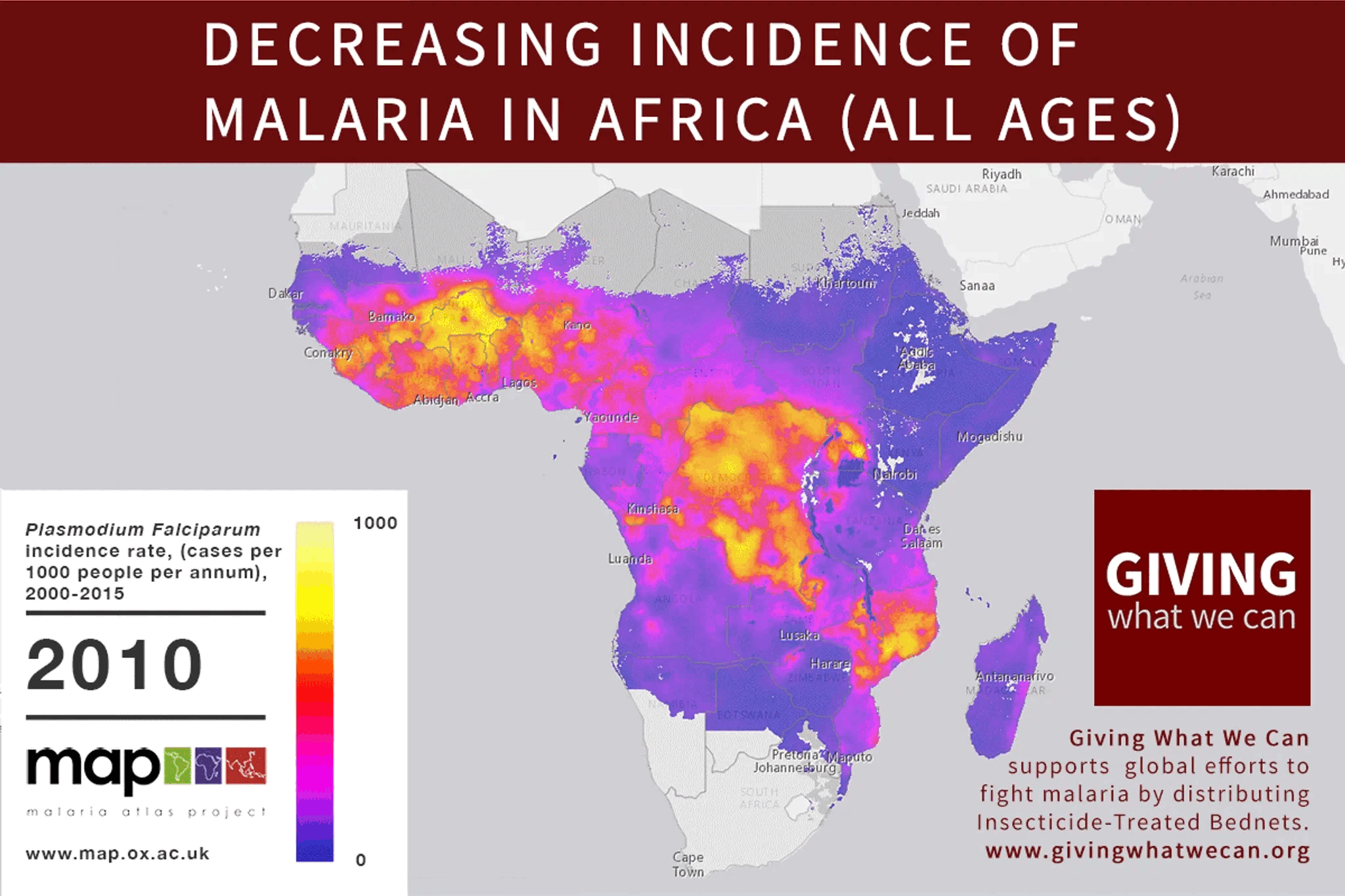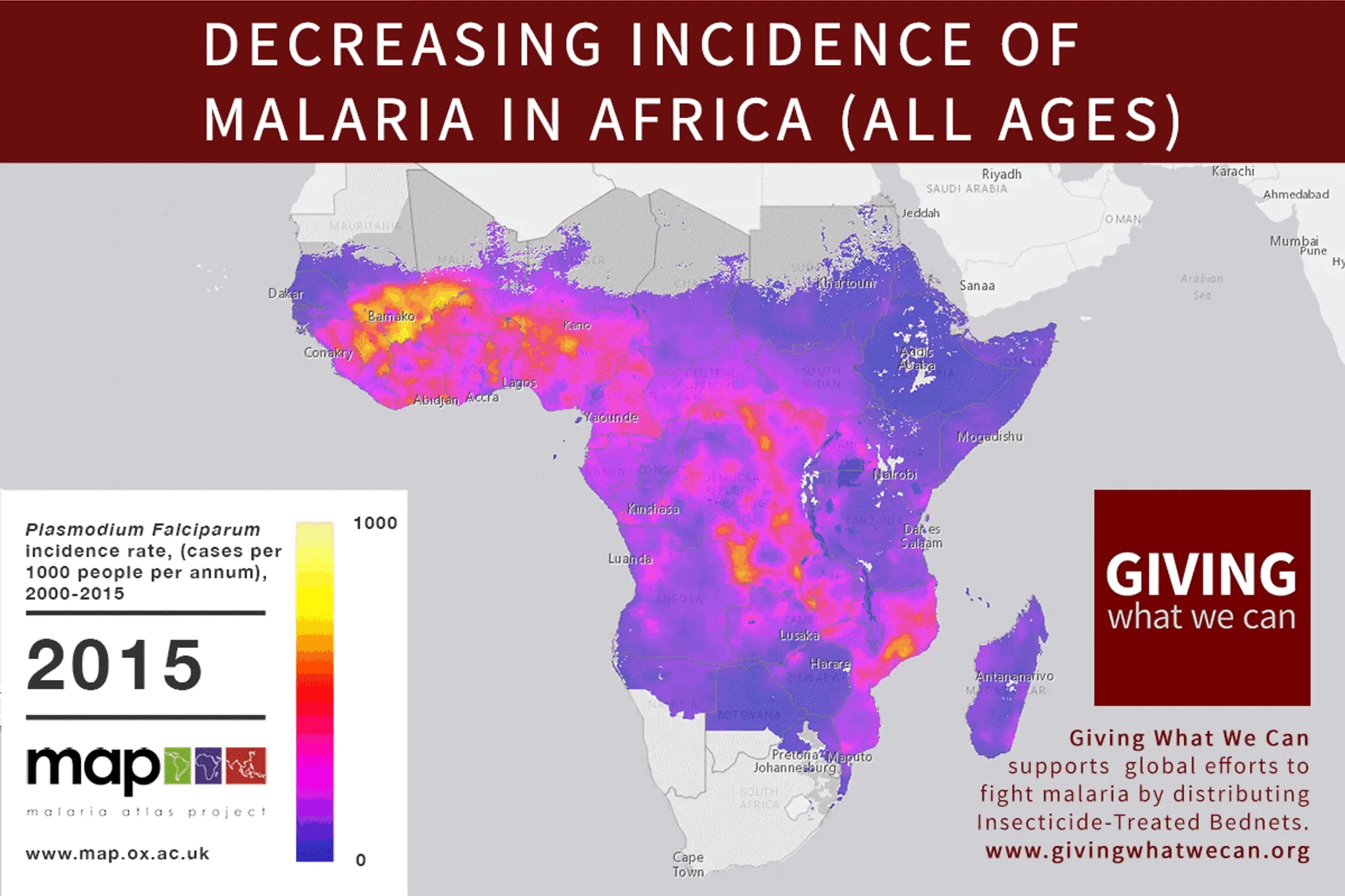


In response to this comment, I wrote a handy primer: https://mdickens.me/2022/03/18/altruistic_investors_care_about_aggregate_altruistic_portfolio/