Convergence Analysis researches strategies for existential risk reduction. We’ve previously written a post about what strategy research is and why it’s valuable (both in the context of x-risks and more generally). That post distinguished between values research, strategy research, tactics research, and implementation, as shown in the following diagram:
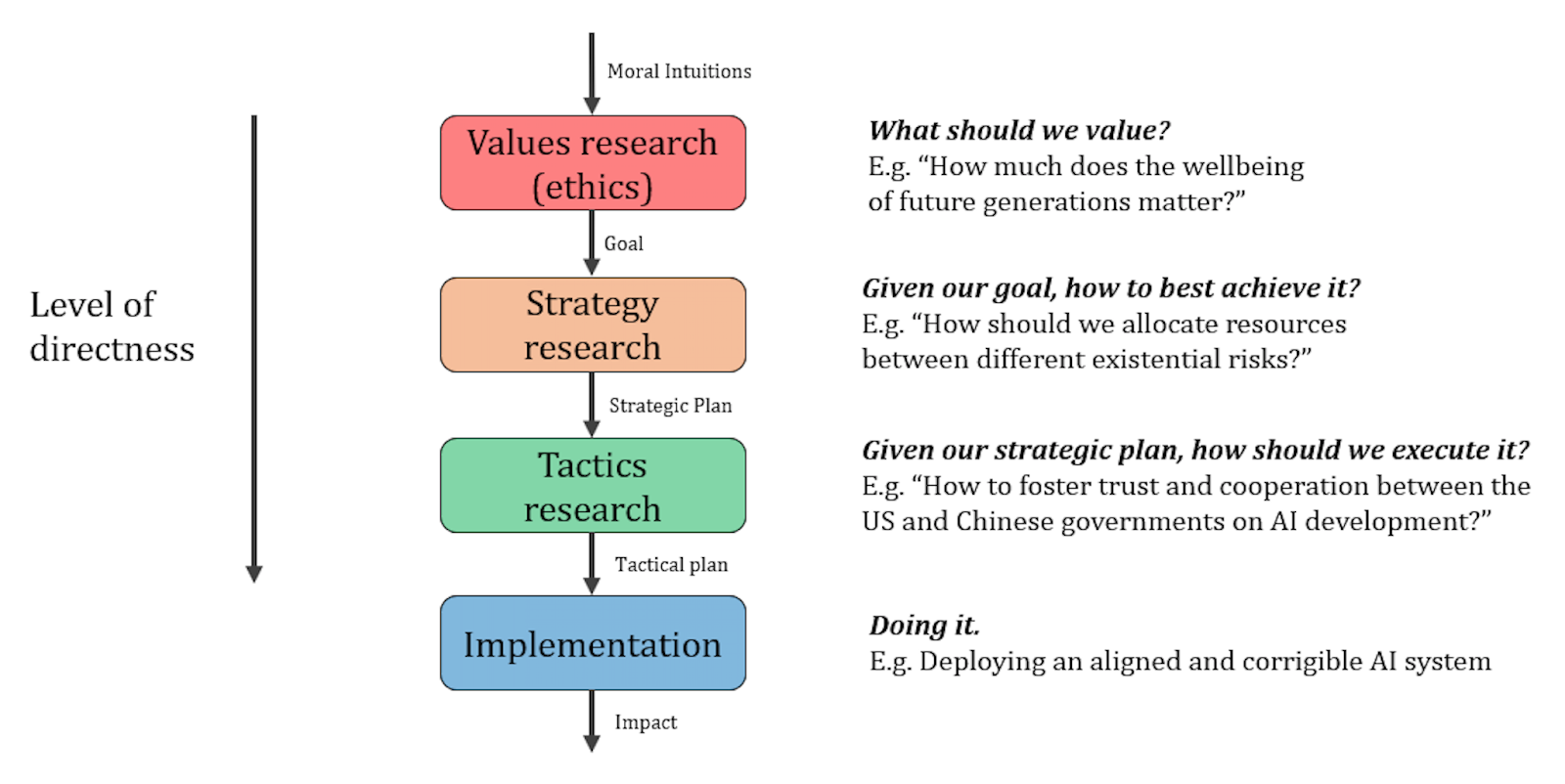
Furthermore, that post provided a definition of strategy research: “High-level research on how to best achieve a high-level goal.” (Strategies themselves will be combinations of specific interventions, coordinated and sequenced in specific ways, and aimed at achieving high-level goals.)
In this post, we:
-
Outline one way to decompose strategy research
- Specifically, we break it down into the following four components: mapping the space, constructing strategies, modelling causality, and prioritizing between strategies
-
Describe how each of those components can be impactful
-
Describe how each of those components can be conducted
-
Provide examples to illustrate these points
We hope this model can help guide future strategy research and facilitate clearer thinking and discussion on the topic.
One thing to note: To some extent, these components can be seen as stages, typically best approached in the order in which we’ve listed them here. But there will also often be value in jumping back and forth between them, or in some people specialising for a certain component rather than moving through them in order. We discussed similar points in our earlier post in relation to values research, strategy research, tactics research, and implementation.
Mapping the space
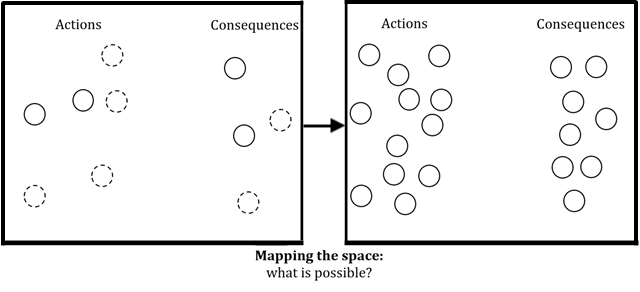
Once we’ve formed a high-level goal (through values research, or some other way or resolving value uncertainty), we must develop strategies to achieve this goal. But initially, we may not even know what actual actions (i.e., interventions) we have to choose from, or what consequences we should be thinking about. It may be as if the space consists entirely of “unknown unknowns”. Thus, we must first map the space, to identify as many options and consequences worth considering as we can.
In the context of x-risk reduction, research questions for mapping the space include:
- What are the various ways we can combat x-risk?
- How could x-risk reduction efforts backfire?
- What are possible x-risk factors?
Only once we have at least some answers to such mapping questions can we proceed to the other components of strategy research (constructing strategies, modelling, and prioritizing). To illustrate this, imagine trying to come up with x-risk reduction strategies before even noticing that outreach to national security policymakers is one intervention you could use, that overly dramatic or simplistic outreach could make it less likely future outreach will be taken seriously, or that misaligned AI is one risk factor worth thinking about.
How does one actually do mapping research? This will likely vary a lot depending on the cause area of interest (e.g., x-risk, animal welfare) and on how much mapping has already occurred. At the very start of mapping, you might ask:
- What interventions are already being applied (or have been or will be applied) in this domain by other people?
- What interventions used in similar domains may be useful here?
Once at least some options have been identified, you might ask:
- What interventions lie between those we’ve imagined so far? Is there a way we can produce a hybrid of two interventions which has the good properties of both but the downsides of neither? Perhaps a compromise or mixed strategy is best?
- What interventions lie beyond those we’ve imagined so far? What if we take a certain intervention and exaggerate part of it; might that improve it?
- What interventions lie perpendicular to those we’ve imagined so far? What if we were to do something totally different from the interventions identified so far?
We can also ask analogous questions to identify potential consequences. E.g., what consequences are already being faced? What consequences have been faced in similar domains? What consequences may lie between, beyond, or perpendicular to those we’ve imagined so far?
Constructing strategies
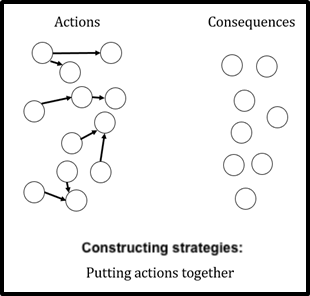
Let’s say we’ve done some mapping, and identified some interventions and consequences worth considering. What now?
We shouldn’t simply pick an intervention and use it. Nor should we even spend too much effort on modelling the effects of (or prioritizing between) these interventions themselves, as if each would be executed in isolation.
This is because it’s likely that we (or the broader community we’re part of) will use multiple interventions, and that there’ll be interactions between their effects, and better vs worse ways to sequence them.
Thus, ideally, we should first construct strategies - i.e., think of specific ways of combining, coordinating, and sequencing interventions - and then model the effects of (and prioritize between) those strategies.
For example, we wouldn’t want to view in isolation the options of “funding biosecurity-related PhDs”, “recruiting senior researchers to do biosecurity research”, and “connecting biosecurity experts with relevant policymakers”. Instead, we might recognise that a combination of these interventions could be more powerful than the sum of its parts, and that the order in which we execute these interventions will also matter.
To construct strategies, we might ask questions like:
- What interventions seem like they would naturally fit together or support each other?
- Which combinations might create synergies? Which might create frictions or negative interaction effects?
- What is the order in which the interventions should be used? Should they be executed one at a time, in parallel, or with just partial overlaps?
Modelling causality
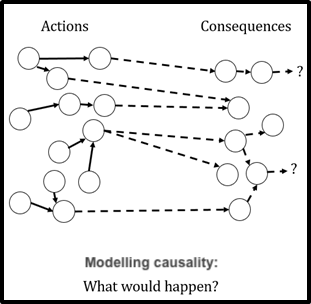
Once we’ve constructed strategies, we should build causal models for them. In other words, once we’ve linked interventions together into packages, we should see how each package might link together with outcomes we care about.
As with all modelling, we want our models to simplify our complex world, help us separate useful lessons from noise, and help us think about how the relevant parts of the world are configured and how they interact.
We may build qualitative models, such as this post’s model of four components of strategy research (each of which is an intervention we can use) and the sorts of impacts (consequences) each can have. We may also build more quantitative models, such as ALLFED’s model of the effects of a package of interventions related to alternative foods.
To model causality, we might ask questions like:
- What effects has this kind of strategy (or the interventions its composed of) had in the past?
- What effects have similar strategies had in the past?
Prioritizing between strategies
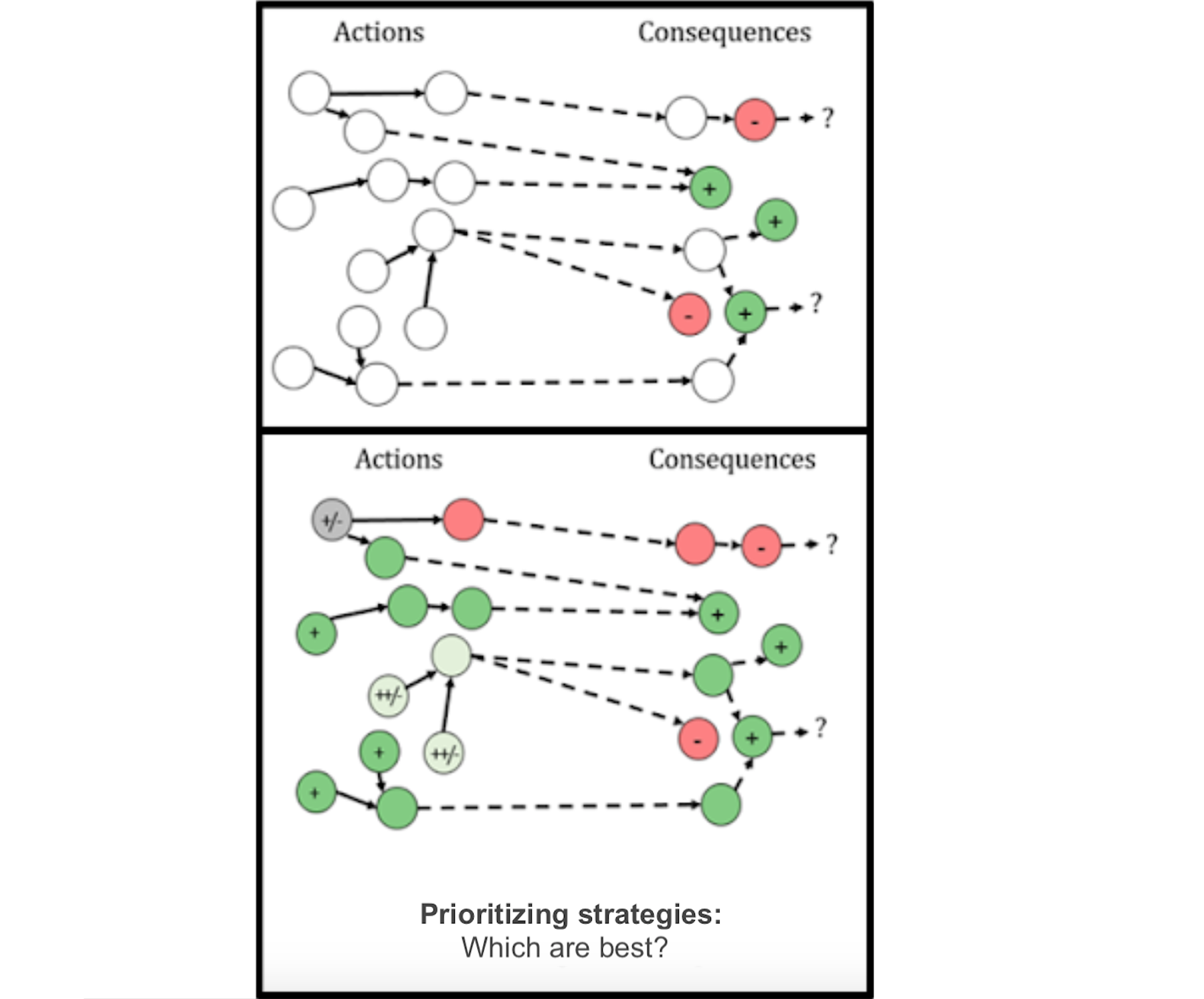
Say we’ve now identified many possible interventions and consequences (mapped the space); identified ways of combining, coordinating, and sequencing these (constructed strategies); and thought about the outcomes each strategy might lead to (modelled causality). We also have ideas about how good or bad those outcomes would be (based on our values or moral views). This will leave us ready to prioritize between these strategies. Such prioritization can be extremely valuable, as it’s likely that the best strategies will be far better than the typical strategies (in a pattern found across many domains, such as startup success or researcher output).
Prioritization, as we use the term here, involves answering questions like:
- What is the expected value of each strategy we’re considering? (This could be calculated explicitly, but we could also use qualitative methods that capture the same basic idea.)
- What are the best opportunities to reduce the risk of nuclear war?
- Which x-risks should receive most of our money/attention, long-term?
- Which x-risks should receive our money/attention first?
Relationship to tactics research
Roughly speaking, tactics research involves basically the same components of research listed above, but at a more concrete level. This is because there isn’t really a clear line between “strategies” and “interventions”; just as all strategies are composed of various interventions, all interventions are in reality composed of various even more concrete steps. So tactics research involves, among other things:
- Mapping the space of very specific steps that could be taken (e.g., emailing vs in-person contact, as different steps for recruiting AI safety researchers)
- Constructing interventions out of these very specific steps (e.g., in-person contact from an established researcher talking about the orthogonality thesis to machine learning PhD students)
- Modelling the effects of those interventions
- Prioritizing between those interventions
There are obviously ways in which these components of tactics research overlap with the abovementioned components of strategy research. This makes sense; we should expect fuzzy boundaries, feedback loops, and jumping back and forth between strategy and tactics research.
Conclusion
In this post, we’ve outlined a model of strategy research as composed of four components: mapping the space, constructing strategies, modelling causality, and prioritizing between strategies. We’re sure other models could be generated, and could likely also be helpful. But this is a model that has made our own thinking more clear and effective, and we hope it can do the same for others researching strategies for pressing global problems, and for those aiming to understand or use such research.
This post blends together parts written by Justin Shovelain, Siebe Rozendal, Michael Aird, and David Kristoffersson. We also received useful feedback from Ben Harack.



This seems fairly intuitive. What is the novelty here?
(My view, not Convergence's)
I think it's very often the sign of a good model or framework that it seems fairly intuitive. Our intuitions often track the truth, but somewhat messily and implicitly. So it's useful to crystallise them into something more explicit and structured, with labels for the different pieces of it, to facilitate clearer thinking and discussion. It would be odd if the result of that crystallisation seemed totally counterintuitive - that might be a sign that a mistake has been made in the process.
Consider, for example, that many of the most valuable economic models/theories seem to some extent very obvious (e.g., the ideas that buyers buy more when things are cheaper, while sellers sell more when things are more expensive). But making them as explicit as economics does aids in thinking, and can sometimes then uncover quite counterintuitive ideas or findings.
Now, that obviously doesn't mean that all intuitive-seeming models are worth writing up or sharing. If it's not just that the model is "obvious", but in fact that people already explicitly recognised all the individual pieces and interactions in a clear way, then the model may not add value. But personally I think this is one useful way of collecting, making explicit, and structuring various intuitive ideas that often aren't made fully explicit. (Though they sometimes are: as we note, "We’re sure other models could be generated, and could likely also be helpful.")