To what extent can humans forecast the impacts of superintelligent AGI?
From one point of view, trying to understand superintelligence seems utterly intractable. Just as a dog or chimpanzee has little hope of comprehending the motivations and powers of humans, why should humans have any hope of comprehending the motivations and powers of superintelligence?
But from another point of view, forecasting the impacts of superintelligence may yet be possible. The laws of reality that constrain us will similarly constrain any superintelligence. Even if a superintelligence achieves a more refined understanding of physics than us humans, it very likely won’t overturn laws already known. Thus, any inventions optimized against those physical laws, even if superior to our own, may end up looking familiar rather than alien.
No matter how intelligent an AGI is, it will still be bound by physics. No matter how smart you are, you still must obey the law of conservation of energy. Just like us, an AGI wishing to affect the world will require an energy industry full of equipment to extract energy from natural sources. Just like us, its energy will have to come from somewhere, whether it’s the sun (solar, wind, biofuels, fossil fuels, hydro), the Earth (geothermal, nuclear), or the Moon (tidal, nuclear). Just like us, any heat engines will be limited by Carnot efficiency. Just like us, energy will need to be transported from where it is collected to where it is consumed, likely by electromagnetic fields in the presence of bound electrons (e.g., chemical fuels) or unbound electrons (e.g., electricity) or neither (e.g., lasers). If there are economies of scale, as there likely will be, that transportation will take place across networks with fractal network topologies, similar to our electric grids, roads, and pipelines. The physics of energy production are so constrained and so well understood that no matter what a superintelligence might build (even fusion electricity, or superconducting power lines, or wireless power), I suspect it will be something that humans had at least considered, even if our attempts were not as successful.
One way to preview superintelligent AGI is to consider the superintelligent narrow AIs humanity has attempted to develop, such as chess AI.
Lessons from chess AI: superintelligence is not omnipotence
In 2017, DeepMind revealed AlphaZero. In less than 24 hours of (highly parallelized) training, it was able crush Stockfish, the reigning AI world chess champion. AlphaZero was trained entirely de novo, with no learning from human games and no human tuning of chess-specific parameters.
AlphaZero is superhuman at chess. AlphaZero is so good at chess that it could defeat all of us combined with ease. Though the experiment has never been done, were we to assemble all the world’s chess grandmasters and give them the collective task of coming up with a single move a day to play against AlphaZero, I’d bet my life savings that AlphaZero would win 100 games before the humans won 1.
From this point of view, AlphaZero is godlike.
- Its margin of strength over us is so great that even if the entire world teamed up, it could defeat all of us combined with ease
- It plays moves so subtle and counterintuitive that they are beyond the comprehension of the world’s smartest humans (or at least beyond the tautological comprehension of ‘I guess it wins because the computer says it wins’).
...but on the other hand, pay attention to all the things that didn’t happen:
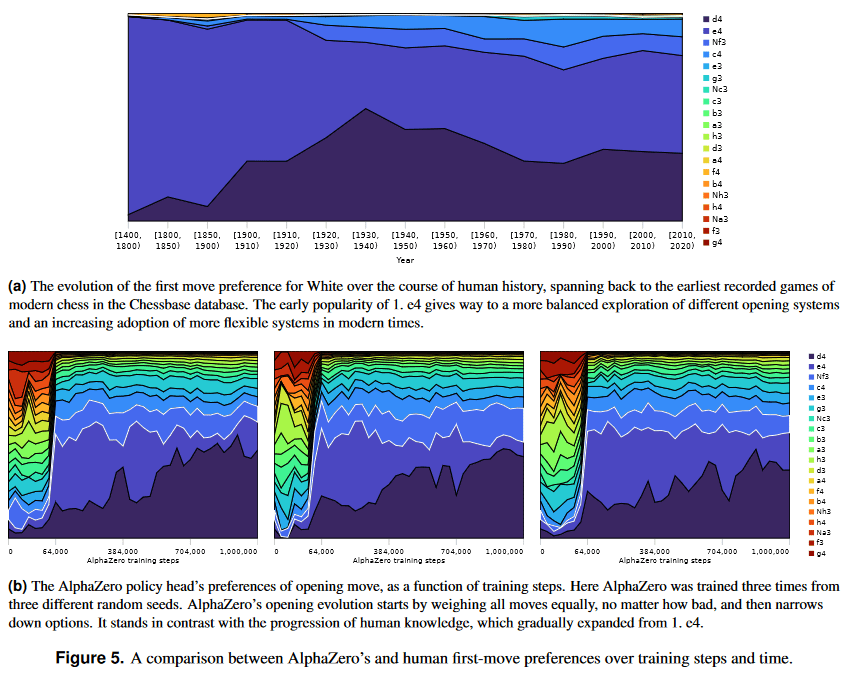
- AlphaZero’s play mostly aligned with human theory—it didn’t discover any secret winning shortcuts or counterintuitive openings.
- AlphaZero rediscovered openings commonly played by humans for hundreds of years:
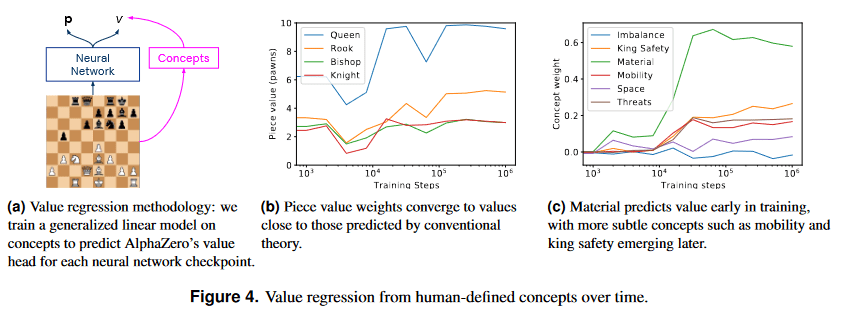
- When DeepMind looked inside AlphaZero’s neural network they found “many human concepts” in which it appeared the neural network computed quantities akin to what humans typically compute, such as material imbalance (alongside many more incomprehensible quantities, to be fair).
- AlphaZero was comprehensible—for the most part, AlphaZero’s moves are comprehensible to experts. Its incomprehensible moves are rare, and even then, many of them become comprehensible after the expert plays out a few variations. (By comprehensible, I don’t mean in the sense that an expert can say why move A was preferred to move B, but in the sense that an expert can articulate pros and cons that explain why move A is a top candidate.)
- AlphaZero was not invincible—in 1200 games against Stockfish, it lost 5/600 with white and 19/600 with black.
- AlphaZero was only superhuman in symmetric scenarios—although AlphaZero can reliably crush grandmasters in a fair fight, what about unfair fights? AlphaZero’s chess strength is estimated to be ~3500 Elo. A pawn is worth ~200 Elo points as estimated by Larry Kaufman, which implies that a chess grandmaster rated ~2500 Elo should reliably crush AlphaZero if AlphaZero starts without its queen (as that should reduce AlphaZero’s effective strength to ~1500 Elo). Even superintelligence beyond all human ability is not enough to overcome asymmetric disadvantage, such as a missing queen. Superintelligence is not omnipotence.
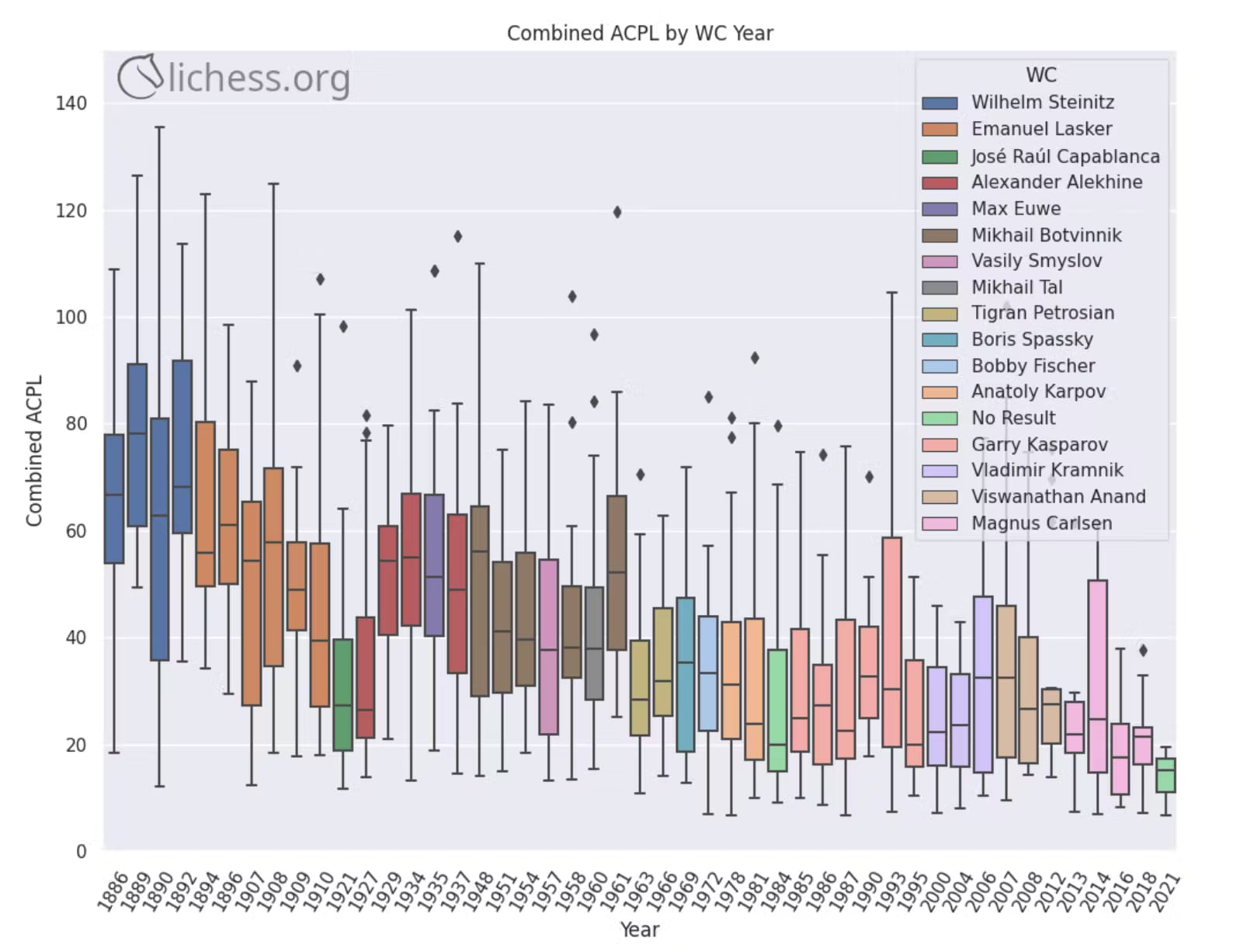
- AlphaZero hasn’t revolutionized human chess—although players have credited AlphaZero with new inspiration, for the most part human chess is played at a similar strength and style. AlphaZero didn’t teach us any secret shortcuts to winning, or any special attacks that cannot be defended, or any special defenses that cannot be pierced. Arguably the biggest learnings were to push the h pawn a little more frequently and to be a little less afraid of sacrificing pawns to restrict an opponent’s mobility. Even chess computers at large haven’t dramatically transformed chess, although they are now indispensable study tools, especially for opening preparation. Historical rates of human chess progress as measured by average centipawn loss (ACPL) in world championship (WC) games show no transformative step function occurring in the 2000s or 2010s. Progress may have accelerated a little if you squint, but it wasn’t a radical departure from pre-AI trends.
Ultimately, superhuman AIs didn’t crush humans at chess by discovering counterintuitive opening secrets or shortcuts that dumb humans missed. In fact, AIs rediscovered many of the same openings that humans play. Rather, AIs do what humans do—control the center, capture pieces, safeguard their king, attack weaknesses, gain space, restrict their opponent's options—but the AIs do this more effectively and more consistently.
In the 5th century BCE, Greek philosophers thought the Earth was a sphere. Although they were eventually improved upon by Newton, who modeled the Earth as an ellipsoid, they still had arrived at roughly the right concept. And in chess we see the same thing: although a superhuman AI 'understands' chess better than human experts, its understanding still mostly reflects the same general concepts.
Refocusing back on AGI, suppose we invent superhuman AGI for $1T in 2100 and we ask it for advice to optimize humanity’s paperclip production. Whatever advice it comes up with, I don’t think it will be unrecognizable magic. Paperclip production is a fairly well understood problem: you bring in some metal ore, you rearrange its atoms into paperclips, and you send them out. A superintelligent AGI asked to optimize paperclip production will probably reinvent much of the same advice we’ve already derived: invest in good equipment, take advantage of economies of scale, select cheap yet effective metals, put factories near sources of energy and materials, ship out paperclips in a hierarchical network with caches along the way to buffer unanticipated demand, etc. If it gives better advice than a management consultant, I expect it to do so not by incomprehensible omnipotent magic that inverts the laws of physics, but by doing what we’re doing already—just smarter, faster, and more efficient.
More practically, if we invent AGI and ask it to invent fusion power plants, here’s how I think it will go: I don’t expect it to think for a moment and then produce a perfect design, as if by magic. Rather, I expect it to focus on known plasma confinement approaches, run some imperfect simulations, and then strategize over what experiments will allow it to acquire the knowledge needed to iteratively improve its designs. Relative to humans, its simulations may be better and its experimentation may be more efficient, but I expect its intelligence will operate within the same constraints that we do.
Intelligence is not omnipotence.
(This post is a lightly edited excerpt from Transformative AGI by 2043 is <1% likely)



The situation in go looks different:
That said:
Note that if you take observations of tic-tac-toe superintelligent ANI (plays the way we know it would play, we can tie with it if we play first), then of AlphaZero chess, then of top go bots, and extrapolate out along the dimension of how rich the strategy space of the domain is (as per Eliezer's comment), I think you get a different overall takeaway than the one in this post.