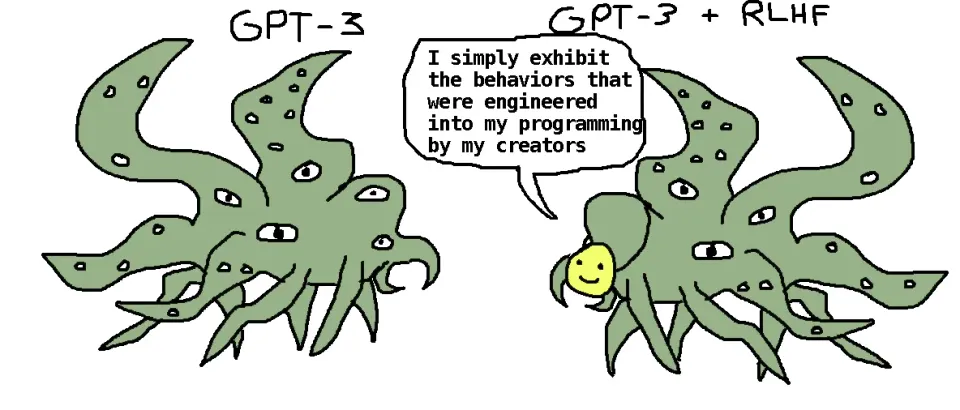
The top image is a nice example of good science commication we could do more of.
It is:
Simple (it's a big squiggly monster with a smily face mask)
Conveys an important idea (LLMs might seem friendly, but we don't understand how they work and if you dig a bit they are utterly alien to us, providing strange and scary answers
High fidelity (this image has already been remixed 1000s of times and it still always conveys it's central idea)
Emotionally resonant ("on this is concerning, what should we do about it")
(And it was it was initially created by EA twitter's very own Tetraspace)
Holden and Yudkowsky are both very good at making complicated ideas into simple sharable ones - paperclips, King Lear problem.
If you find you have a talent for explaining things (or doodling) you might do well to make memes like this. Who knows where they will end up. (I am assuming that explaining things well is net good but I guess it has very large variance)
I agree with everything, and still want to point out that not so long later, Musk decided to try removing the "woke" part, so maybe he shared this meme for different reasons than you or me would share it
This article is evidence that Elon Musk will focus on the "wokeness" of ChatGPT, rather than do something useful about AI alignment. But still, we should keep in mind that news are very often incomplete or simply just plain false.
I strongly agree that current LLM's don't seem to pose a risk of a global catastrophe, but I'm worried about what might happen when LLM's are combined with things like digital virtual assistants who have outputs other than generating text. Even if it can only make bookings, send emails, etc., I feel like things could get concerning very fast.
Is there an argument for having AI fail spectacularly in a small way which raises enough global concern to slow progress/increase safety work? I'm envisioning something like a LLM virtual assistant which leads to a lot of lost productivity and some security breaches but nothing too catastrophic, which makes people take AI safety seriously, slowing progress on more advanced AI, perhaps.
Is there an argument for having AI fail spectacularly in a small way which raises enough global concern to slow progress/increase safety work?
Given that AI is being developed by companies running on a "move fast and break things" philosophy, a spectacular failure of some sort is all but guaranteed.
It'd have to bigger than mere lost productivity to slow things down though. Social media algorithms arguably already have a body count (via radicalisation), and those have not been slowed down.
ICYMI, Microsoft has released a beta version of an AI chatbot called “the new Bing” with both impressive capabilities and some scary behavior. (I don’t have access. I’m going off of tweets and articles.)
Zvi Mowshowitz lists examples here - highly recommended. Bing has threatened users, called them liars, insisted it was in love with one (and argued back when he said he loved his wife), and much more.
Are these the first signs of the risks I’ve written about? I’m not sure, but I’d say yes and no.
Let’s start with the “no” side.
My understanding of how Bing Chat was trained probably does not leave much room for the kinds of issues I address here. My best guess at why Bing Chat does some of these weird things is closer to “It’s acting out a kind of story it’s seen before” than to “It has developed its own goals due to ambitious, trial-and-error based development.” (Although “acting out a story” could be dangerous too!)
My (zero-inside-info) best guess at why Bing Chat acts so much weirder than ChatGPT is in line with Gwern’s guess here. To oversimplify, there’s a particular type of training that seems to make a chatbot generally more polite and cooperative and less prone to disturbing content, and it’s possible that Bing Chat incorporated less of this than ChatGPT. This could be straightforward to fix.
Bing Chat does not (even remotely) seem to pose a risk of global catastrophe itself.
On the other hand, there is a broader point that I think Bing Chat illustrates nicely: companies are racing to build bigger and bigger “digital brains” while having very little idea what’s going on inside those “brains.” The very fact that this situation is so unclear - that there’s been no clear explanation of why Bing Chat is behaving the way it is - seems central, and disturbing.
AI systems like this are (to simplify) designed something like this: “Show the AI a lot of words from the Internet; have it predict the next word it will see, and learn from its success or failure, a mind-bending number of times.” You can do something like that, and spend huge amounts of money and time on it, and out will pop some kind of AI. If it then turns out to be good or bad at writing, good or bad at math, polite or hostile, funny or serious (or all of these depending on just how you talk to it) ... you’ll have to speculate about why this is. You just don’t know what you just made.
We’re building more and more powerful AIs. Do they “want” things or “feel” things or aim for things, and what are those things? We can argue about it, but we don’t know. And if we keep going like this, these mysterious new minds will (I’m guessing) eventually be powerful enough to defeat all of humanity, if they were turned toward that goal.
That’s the path the world seems to be on at the moment. It might end well and it might not, but it seems like we are on track for a heck of a roll of the dice.
(And to be clear, I do expect Bing Chat to act less weird over time. Changing an AI’s behavior is straightforward, but that might not be enough, and might even provide false reassurance.)
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...



Thanks for writing this.
The top image is a nice example of good science commication we could do more of.
It is:
(And it was it was initially created by EA twitter's very own Tetraspace)

https://twitter.com/TetraspaceWest/status/1608966939929636864?s=20
Holden and Yudkowsky are both very good at making complicated ideas into simple sharable ones - paperclips, King Lear problem.
If you find you have a talent for explaining things (or doodling) you might do well to make memes like this. Who knows where they will end up. (I am assuming that explaining things well is net good but I guess it has very large variance)
I agree with everything, and still want to point out that not so long later, Musk decided to try removing the "woke" part, so maybe he shared this meme for different reasons than you or me would share it
Fighting ‘Woke AI,’ Musk Recruits Team to Develop OpenAI Rival
This article is evidence that Elon Musk will focus on the "wokeness" of ChatGPT, rather than do something useful about AI alignment. But still, we should keep in mind that news are very often incomplete or simply just plain false.
Also, I can't access the article.
Related: I've recently created a prediction market about whether Elon Musk is going to do something positive for AI risk (or at least not do something counterproductive) according to Eliezer Yudkowsky's judgment: https://manifold.markets/Writer/if-elon-musk-does-something-as-a-re?r=V3JpdGVy
+1 for creating that market! :)
Hard agree, the shoggoth memes are great.