This is a special post for quick takes by huw. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Comment Permalink
The World Happiness Report 2025 is out!
Finland leads the world in happiness for the eighth year in a row, with Finns reporting an average score of 7.736 (out of 10) when asked to evaluate their lives.
Costa Rica (6th) and Mexico (10th) both enter the top 10 for the first time, while continued upward trends for countries such as Lithuania (16th), Slovenia (19th) and Czechia (20th) underline the convergence of happiness levels between Eastern, Central and Western Europe.
The United States (24th) falls to its lowest-ever position, with the United Kingdom (23rd) reporting its lowest average life evaluation since the 2017 report.
I bang this drum a lot, but it does genuinely appear that once a country reaches the upper-middle income bracket, GDP doesn’t seem to matter much more.
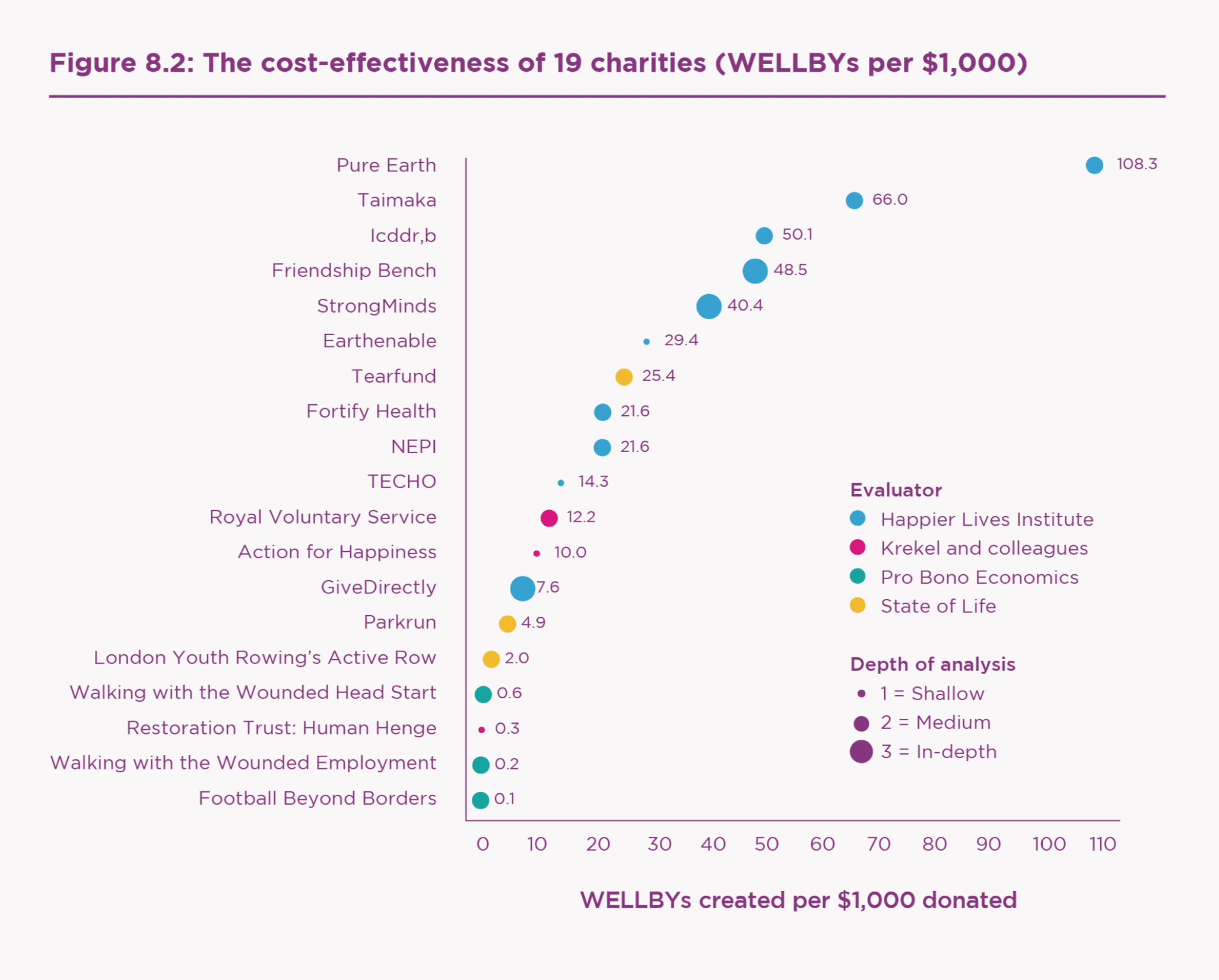
Also featuring is a chapter from the Happier Lives Institute, where they compare the cost-effectiveness of improving wellbeing across multiple charities. They find that the top charities (including Pure Earth and Tamaika) might be 100x as cost-effective as others, especially those in high-income countries.
The first thing I wondered about when this report came out was: how did India do?
In that quick take I asked how India's self-reported life satisfaction dropped an astounding -1.20 points (4.97 to 3.78) from 2011 to 2021, even as its GDP per capita rose +51% in the same period; China in contrast gained about as much self-reported life satisfaction as you'd expect given its GDP per capita rise. This "happiness catastrophe" should be alarming to folks who consider happiness and life satisfaction what ultimately matters (like HLI), since given India's population such a drop over time adds up to roughly ~5 billion LS-years lost since 2011, very roughly ballparking (for context, and keeping in mind that LS-years and DALYs aren't the same thing, the entire world's DALY burden is ~2.5 billion DALYs p.a.). Even on a personal level -1.20 points is huge: 10x(!) larger than the effect of doubling income at +0.12 LS points (Clarke et al 2018 p199, via HLI's report), and comparable to major negative life events like widowhood and extended unemployment. So it mystified me that nobody seems to be talking about it.
Last year's WHR reported a 4.05 rating averaged over the 3-year window 2021-23, improving +0.27 points. This year's WHR (linking to the country rankings dashboard) reports a 4.39 rating over 2022-24 i.e. +0.34 points, continuing the improvement trend. So I'm guessing this is some sort of mean reversion effect, and that the 3.78 LS averaged over 2018-20 was just anomalously low somehow...? Some commenters pointed to rising inequality and falling social support as potential factors. I still find myself confused.
Here is their plot over time, from the Chapter 2 Appendix. I think these are the raw per-year scores, not the averages.
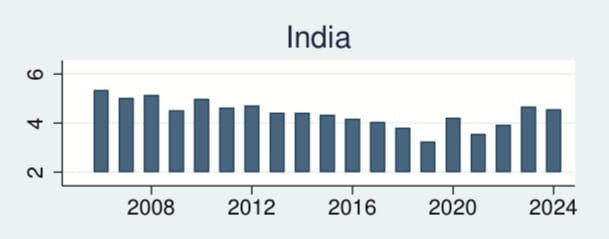
I find this really baffling. It’s probably not political; the Modi government took power in 2014 and only lost absolute majority in late 2024. The effects of COVID seem to be varied; India did relatively well in 2020 but got obliterated by the Delta variant in 2021. Equally, GDP per capita steadily increased over this time, barring a dip in 2020. Population has steadily increased, and growth has steadily decreased.
India have long had a larger residual value than others in the WHR’s happiness model; they’re much less happy than their model might predict.
Without access to the raw data, it’s hard to say if Gallup’s methodology has changed over this time; India is a huge and varied country, and it’s hard to tell if Gallup maintained a similar sample over time.
Thanks for digging up that plot, I'd been looking for annual data instead of 3-year rolling averages.
Here's what WHR say about their methodology which seems relevant.
What is your sample size?
The number of people and countries surveyed varies year to year but, in general, more than 100,000 people in 140 countries and territories participate in the Gallup World Poll each year.
In most countries, approximately 1,000 people are contacted by telephone or face-to-face each year. Tables 1-5 in the Statistical Appendix show the sample size for each country since 2005. Gallup’s website provides more details on their data collection methods. ...
What time of year is the data collected?
The Gallup World Poll collects data throughout the year, taking into account religious observances, weather patterns, pandemics, war, and other local factors. Variation in collection timing is not a serious obstacle to analysis as there are established techniques to test for seasonal effects and adjust for them (see this paper for an example).
That Gallup website doesn't say if they've changed their methodology over time; that said, they seem to try their best to maintain a similar sample over time, e.g.
With some exceptions, all samples are probability based and nationally representative of the resident population aged 15 and older. The coverage area is the entire country including rural areas, and the sampling frame represents the entire civilian, non-institutionalized adult population of the country.
I remain as baffled as you are.
The U.S. State Department will reportedly use AI tools to trawl social media accounts, in order to detect pro-Hamas sentiment to be used as grounds for visa revocations (per Axios).
Regardless of your views on the matter, regardless of whether you trust the same government that at best had a 40% hit rate on ‘woke science’ to do this: They are clearly charging ahead on this stuff. The kind of thoughtful consideration of the risks that we’d like is clearly not happening here. So why would we expect it to happen when it comes to existential risks, or a capability race with a foreign power?
This is... not what the attached source says? Scott estimates 40% woke, 20% borderline, and 40% non-woke. 'at best' means an upper bound, which would be 60% in this case if you accept this methodology.
But even beyond that, I think Scott's grading is very harsh. He says most grants that he considered to be false positives contained stuff like this (in the context of a grant about Energy Harvesting Systems):
The project also aims to integrate research findings into undergraduate teaching and promote equitable outcomes for women in computer science through K-12 outreach program.
But... this is clearly bad! The grant is basically saying it's mainly for engineering research, but they're also going to siphon off some of the money to do some sex-discriminatory ideological propaganda in kindergartens. The is absolutely woke,[1] and it totally makes sense why the administration would want to stop this grant. If the scientists want to just do the actual legitimate scientific research, which seems like most of the application, they should resubmit with just that and take out the last bit.
Some people defend the scientists here by saying that this sort of language was strongly encouraged by previous administrations, which is true and relevant to the degree of culpability you assign to the scientists, but not to whether or not you think the grants have been correctly flagged.
His borderline categorisation seems similarly harsh. In my view, this is a clear example of woke racism:
enhance ongoing education and outreach activities focused on attracting underrepresented minority groups into these areas of research
Scott says these sorts of cases makes up 90% of his false positives. So I think we should adjust his numbers to produce a better estimate:
- 40% woke according to scott
- +20% borderline woke
- +90%*40% incorrectly labeled as false positives
= 96% hit rate.
- ^
If you doubt this, imagine how a typical leftist grant reviewer would evaluate a grant that said some of the money was going to support computer science for white men.
It's not clearly bad. It's badness depends on what the training is like, and what your views are around a complicated background set of topics involving gender and feminism, none of which have clear and obvious answers. It is clearly woke in a descriptive non-pejorative sense, but that's not the same thing as clearly bad.
EDIT: For example, here is one very obvious way of justifying some sort of "get girls into science" spending that is totally compatible with centre-right meritocratic classical liberalism and isn't in any sense obviously discriminatory against boys. Suppose girls who are in fact capable of growing up to do science and engineering just systematically underestimate their capacity to do those things. Then "propaganda" aimed at increasing the confidence of those girls specifically is a totally sane and reasonable response. It might not in fact be the correct response: maybe there is no way to change things, maybe the money is better spent elsewhere etc. But it's not mad and its not discriminatory in any obvious sense, unless anything targeted only at any demographic subgroup is automatically discriminatory, which at best only a defensible position not an obvious one. I don't know if smart girls are in fact underconfident in this way, but it wouldn't particularly susprirse me.
It's not clearly bad. It's badness depends on what the training is like, and what your views are around a complicated background set of topics involving gender and feminism, none of which have clear and obvious answers.
The topic here is whether the administration is good at using AI to identify things it dislikes. Whether or not you personally approve of using scientific grants to fund ideological propaganda is, as the OP notes, besides the point. Their use of AI thus far is, according to Scott's data, a success by their lights, and I don't see any much evidence to support huw's claim that their are being 'unthoughtful' or overconfident. They may disagree with huw on goals, but given those goals, they seem to be doing a reasonable job of promoting them.
I agree with the very narrow point that flagging grants that mention some minor woke spending while mostly being about something elde is not a sign of the AI generating false positives when asked to search for wokeness. Indeed, I already said in my first comment that the flagged material was indeed "woke" in some sense.
As a scientist who writes NSF grants, I think the stuff that you're labeling woke here makes up a very percentage of the total money that actually gets spent in grants like these. Labeling that grant as woke because it puts like 2% of its total funds towards a K-12 outreach program seems like a mistake to me. (And in an armchair-philosophy way, yes the scientists could in principle just resubmit the grants without the last part -- but in practice nothing works like this. Much more likely is that labeling these as "woke" leads people, like the current administration, to try to drastically reduce the overall funding that goes to NSF, with a strong net negative effect on basic science research.)
"Labeling that grant as woke because it puts like 2% of its total funds towards a K-12 outreach program seems like a mistake to me."
It's a mistake if it's meant to show the grant is bad, and I suspect that Larks has political views that I would very strongly disagree with, but I think it does successfully make the narrow point that the data about NSF grants does not show that an AI designed to identify pro-woke or pro-Hamas language will be bad at doing so.
It seems pretty appropriate and analogous to me - the administration wants to ensure 100% of science grants go to science, not 98%, and similarly they want to ensure that 0% of foreign students support Hamas, not 2%. Scott's data suggests that have done a reasonably good job with the former at identifying 2%-woke grants, and likewise if they identify someone who spends 2% of their time supporting Hamas they would consider this a win.
I don't think the issue here is actually about whether all science grants should go only to actual scientific work. Suppose that a small amount of the grant had been spent on getting children interested in science in a completely non-woke way that had nothing to do with race or gender. I highly doubt that either the administration or you regard that as automatically and obviously horrendously inappropriate. The objection is to stuff targeted at women and minorities in particular, not to a non-zero amount of science spending being used to get kids interested in science. Describing it as just being about spending science grants only on science is just a disingenuous way of making the admin's position sound more commonsense and apolitical than it actually is.
An idea that's been percolating in my head recently, probably thanks to the EA Community Choice, is more experiments in democratic altruism. One of the stronger leftist critiques of charity revolves around the massive concentration of power in a handful of donors. In particular, we leave it up to donors to determine if they're actually doing good with their money, but people are horribly bad at self-perception and very few people would be good at admitting that their past donations were harmful (or merely morally suboptimal).
It seems clear to me that Dustin & Cari are particularly worried about this, and Open Philanthropy was designed as an institution to protect them from themselves. However, (1) Dustin & Cari still have a lot of control over which cause areas to pick, and sort of informally defer to community consensus on this (please correct me if I have the wrong read on that) and (2) although it was intended to, I doubt it can scale beyond Dustin & Cari in practice. If Open Phil was funding harmful projects, it's only relying on the diversity of its internal opinions to diffuse that; and those opinions are subject to a self-selection effect in applying for OP, and also an unwillingness to criticise your employer.
If some form of EA were to be practiced on a national scale, I wonder if it could take the form of an institution which selects cause areas democratically, and has a department of accountable fund managers to determine the most effective way to achieve those. I think this differs from the Community Choice and other charity elections because it doesn't require donors to think through implementation (except through accountability measures on the fund managers, which would come up much more rarely), and I think members of the public (and many EAs!) are much more confident in their desired outcomes than their desired implementations; in this way, it reflects how political elections take place in practice.
In the near-term, EA could bootstrap such a fund. Donors could contribute to a centralised pool of funds (perhaps with approval-voted restrictions on which causes they do not want their money going to), and the community could vote on the overall cause area allocation. Each of us would benefit from the centralisation of funds (efficiency) and expertise, and we could have a genuine accountability mechanism for bad funding allocations. This would provide a much stronger signal on cause prioritisation than we have today.
What's the best prior art on this?
I would have a lot less concern about more central control of funding within EA if there was more genuine interest within those funding circles for broad exploration and development of evidence from new ideas within the community. Currently, I think there are a handful of (very good) notions about areas that are the most promising (anthropogenic short-term existential or major risks like AI, nuclear weapons, pandemics/bioweapons, animal welfare, global health, and development) that guide the 'spotlight' under which major funders are looking. This spotlight is not just about these important areas—it’s also shaped by strong intuitions and priors about the value of prestige and the manner in which ideas are presented. While these methodologies have merit, they can create an environment where the kinds of thinking and approaches that align with these expectations are more likely to receive funding. This incentivizes pattern-matching to established norms rather than encouraging genuinely new ideas.
The idea of experimenting with a more democratic distribution of funding, as you suggest, raises an interesting question: would this approach help incentivize and enable more exploration within EA? On one hand, by decentralizing decision-making and involving the broader community in cause area selection, such a model could potentially diversify the types of projects that receive funding. This could help break the current pattern-matching incentives, allowing for a wider array of ideas to be explored and tested, particularly those that might not align with the established priorities of major funders.
However, there are significant challenges to consider. New and unconventional ideas often require deeper analysis and nuanced understanding, which may not be easily accessible to participants in a direct democratic process. The reality is that many people, even within the EA community, might not have the time or expertise to thoroughly evaluate novel ideas. As a result, they may default to allocating funds toward causes and approaches they are already familiar with, rather than taking the risk on something unproven or less understood.
In light of this, a more 'republican' system, where the community plays a role in selecting qualified assessors who are tasked with evaluating new ideas and allocating funds, might offer a better balance. Such a system would allow for informed decision-making while still reflecting the community’s values and priorities. These assessors could be chosen based on their expertise and commitment to exploring a wide range of ideas, thereby ensuring that unconventional or nascent ideas receive the consideration they deserve. This approach could combine the benefits of broad community input with the depth of analysis needed to make wise funding decisions, potentially leading to a richer diversity of projects being supported and a more dynamic, exploratory EA ecosystem.
Ultimately, while direct democratic funding models have the potential to diversify funding, they also risk reinforcing existing biases towards familiar ideas. A more structured approach, where the community helps select knowledgeable assessors, might strike a better balance between exploration and empirical rigor, ensuring that new and unconventional ideas have a fair chance to develop and prove their worth.
EDIT:
I wanted to clarify that I recognize the 'republic' nature in your proposal, where fund managers have the discretion to determine how best to advance the selected cause areas. My suggestion builds on this by advocating for even greater flexibility for these representatives. Specifically, I propose that the community selects assessors who would have broader autonomy not just to optimize within established areas but to explore and fund unconventional or emerging ideas that might not yet have strong empirical support. This could help ensure a more dynamic and innovative approach to funding within the EA community.
I like this also, I can imagine a system with a few mainstream assessors (or coalitions thereof) representing the major causes in the movement, and then small-scale ones who get access to better funding to develop smaller causes.
Although, I think both suffer from that same domination of the majority. Ultimately, if there aren’t people in the community willing to vote for the newer causes, they won’t get funded under either system.
IIRC, defining "the community" has been an issue in prior discussions. What Manifund did for CC seems reasonable given the sums involved and that it isn't clearly a recurrent thing. If you get into voters controlling thousands of Other People's Money on a recurring basis, you're likely to get people trying to meet the requirements for a vote just to get money flowing to their favorite causes (whether effective or not). If you tenure existing community members and make a high standard for newbies to get voting rights, you're creating a two-tier community at risk of stagnation.
Those problems may not be insurmountable, but they are at least moderately formidable in my view. Still, I like to see experiments!
you're likely to get people trying to meet the requirements for a vote just to get money flowing to their favorite causes (whether effective or not)
What’s the problem with this?
I am not sure there is such thing as an ‘ineffective cause’. After all, EA is a question. If a naïve voter wanted to send their money to a narrow cause in a rich country (ex. US cancer research), then either they actually want something broader (lives saved, suffering reduced) and it’s up to us to campaign & educate them as to their ‘real’ preferences, or they truly desire something that narrow. In the latter case, I am not sure it is up to you and I to tell them that they’re wrong, even if we vehemently disagree.
But I can see how that problem would practically restrict who donates to the pool. Some constraints that might work without creating a two-tiered system:
- Minimum required donation to vote (maybe even requiring a % pledge with some track record)
- Selecting from a pre-defined list of causes (including broader causes such as ‘reduce suffering’ or ‘reduce human suffering’)
- Allowing donors to restrict their donation (ex. “I want to reduce suffering, but I am neutral within that”)
What’s the problem with this?
For the EA community: People who are already dead-set on US cancer research (or whatever) go through the motions of EAness to get their vote, diluting the truthseeking nature of the community. And expending mentorships, EAG slots, etc. on people who are going through the motions to get a vote is not a good use of limited resources.
For the donors: The problem is that the donors will always have the option of the existing system -- e.g., deferring to OpenPhil, or to SFF, or EA Funds, picking recipients themselves, etc. To get anywhere, you've got to persuade the donors that your method will produce better results than the status quo. I think there's a strong argument that the collective wisdom of the EA community could theoretically do that, and a less clear argument that it could practically do that. But the argument that a community of 50% current EAs and 50% join-for-predetermined-pet-causes-folks could do so seems a lot weaker to me!
Maybe it works better under particularly strong versions of "some form of EA were to be practiced on a national scale"? But you'd have to convert at least large swaths of donors to the democratic system first. Otherwise, EA-aligned donors see their monies siphoned off for opera etc. and get nothing in return for their preferred causes from non-participating donors. Across the history of philanthropy, I suspect the percentage of donors who would be happy to hand over control to the demos is . . . low. So I'm struggling to see a viable theory of change between "bootstrapping" and national adoption.
For the donors, I don’t have a lot to add, but I’ll re-state my point.
Donors today at least claim to be worried about having outsized power in a way that could cause them to get their causes or allocations ‘wrong’. As you note, the wisdom of the crowd could solve this. If these donors don’t want things going off course, they could pre-specify a list of subcauses they’re interested in funding, or even a broader area, or this should keep those benefits while mitigating most of the harms.
People who are already dead-set on US cancer research (or whatever) go through the motions of EAness to get their vote, diluting the truthseeking nature of the community.
Again, I know my take on this is a bit unorthodox, but it’s important to remember that we’re not bridging is-ought. If someone truly believes that funding the opera is the highest moral good, and then they determine the most effective way to do so, they are practicing truthseeking. But if they truly believed that preventing suffering was the highest moral good and still voted to fund the opera, then they would (probably) not be truthseeking. I think this distinction is important—both ‘failure modes’ produce the same outcome by very different means!
Whether it is bad to expend those resources depends on how you define EA. If EA is truly cause-neutral, then there’s no problem. But I think you and I agree that Actually Existing EA does generally prefer ‘reduce suffering’ as a cause (and is cause-neutral within that), and in this sense it would be a shame if resources were spent on other things. Hence, a bootstrapped version of democratic altruism would probably restrict itself to this and let people choose within it.
That's valid -- I do not have a brain scanner so cannot reliably distinguish someone who merely went through the motions to vote for opera vs. someone who seriously considered the world's most pressing problems and honestly decided that opera was at the top of the list.
In theory, EA principles are cause-neutral, so one could apply them to the belief that the greatest good is introducing people to the Flying Spaghetti Monster and being touched by his noodle-y appendage. And I guess I want opera people to do opera as effectively as possible (my hesitation is based on lack of clarity on what that even means in the opera context)? I'm just not interested in funding either of those, nor am I interested in providing strong incentives for people with those goals to join the existing EA community in significant numbers. They are welcome to start the Effective Opera or Effective FSM movements, though!
The Trump administration has indefinitely paused NIH grant review meetings, effectively halting US-government-funded biomedical research.
There are good criticisms of the NIH, but we are kidding ourselves if we believe that this is to do with anything but vindictiveness over COVID-19, or at best, a loss of public trust in health institutions from a minority of the US public. But this action will not rectify that. Instead of one public health institution with valid flaws that a minority of the public distrust, we have none now. Clinical trials have been paused too, so it’s likely that people will die from this.
I don’t have a great sense of what to do other than lament. Thankfully, there are good research funders globally—in my case, a lot of the research Kaya Guides relies on is funded by the WHO (😔) or the EU. We’re still waiting to see how the WHO withdrawal will affect us, but we’re lucky that there are other global leaders willing to pick up the slack. I hope that US philanthropic funding also doesn’t dry up over the coming years…
It seems like some of the biggest proponents of SB 1047 are Hollywood actors & writers (ex. Mark Ruffalo)—you might remember them from last year’s strike.
I think that the AI Safety movement has a big opportunity to partner with organised labour the way the animal welfare side of EA partnered with vegans. These are massive organisations with a lot of weight and mainstream power if we can find ways to work with them; it’s a big shortcut to building serious groundswell rather than going it alone.
See also Yanni’s work with voice actors in Australia—more of this!
The IHME have published a new global indicator for depression treatment gaps—the ‘minimally adequate treatment rate’.
00317-1/asset/ef0b5d6a-8e80-46df-813f-1696fe5b9204/main.assets/gr3_lrg.jpg)
It’s defined using country-level treatment gap data, and then extrapolated to missing countries using Bayesian meta-regression (combined with other GBD data; there’s already a critique paper on this methodology FWIW).
It seems like this should be normalized by total population. If a country only had one depressed dude, and he was untreated, I would say this is a small gap, but the map as it is would suggest it was the largest possible gap. Conversely, if every single person in the country was depressed, and only 33% were treated, this map would suggest the gap was very small.
2 weeks out from the new GiveWell/GiveDirectly analysis, I was wondering how GHD charities are evaluating the impact of these results.
For Kaya Guides, this has got us thinking much more explicitly about what we’re comparing to. GiveWell and GiveDirectly have a lot more resources, so they can do things like go out to communities and measure second order and spillover effects.
On the one hand, this has got us thinking about other impacts we can incorporate into our analyses. Like GiveDirectly, we probably also have community spillover effects, we probably also avert deaths, and we probably also increase our beneficiaries’ incomes by improving productivity. I suspect this is true for many GHD charities!
On the other, it doesn’t seem fair to compare our analysis on individual subjective wellbeing to GiveDirectly’s analysis that incorporates many more things. Unless we believed that GiveDirectly is likely to be systematically better, it’s not the case that many GHD charities got 3–4× less cost-effective relative to cash transfers overnight, they may just count 3–4× less things! So I wonder if the standard cash transfers benchmark might have to include more nuance in the near-term. Kaya Guides already only makes claims about cost-effectiveness ‘at improving subjective wellbeing’ to try and cover for this.
Are other GHD charities starting to think the same way? Do people have other angles on this?
Don't know if this is useful, but years ago HLI tried to estimate spillover effects from therapy in Happiness for the whole household: accounting for household spillovers when comparing the cost-effectiveness of psychotherapy to cash transfers, and already found that spillover effects were likely significantly higher for cash transfers compared to therapy.
In 2023 in Talking through depression: The cost-effectiveness of psychotherapy in LMICs, revised and expanded they estimated that the difference is even greater in favour of cash transfers. (after feedback like Why I don’t agree with HLI’s estimate of household spillovers from therapy and Assessment of Happier Lives Institute’s Cost-Effectiveness Analysis of StrongMinds)
I wouldn't update too strongly on this single comparison, and I don't know if there are better analyses of spillover effects for different kinds of interventions, but it seems that there are reasons to believe that spillover effects from cash transfers are relatively greater than for other interventions.
I agree to your general analysis. Just some quick thoughts (if you have other ideas, I'd be excited to hear them!)
For us at ACTRA, communicating our benefits in terms of x times cash has been very helpful, because we do not have the typical "one outcome measure makes up for 80% of the effect" situation: Crime reduction leads to reduced interpersonal violence like homicides (DALYs), averts economic damage ($) and has wellbeing benefits (WELLBYs). Our current analysis suggests, that each of those three is about 1/3 of our total effect. So having something, where we cann sum these benefits up and then compare to other charities that might focus on only one of these is very helpful for us.
If we want to keep using cash estimates I see us either
1) incorporating best guesses for our spillover effects etc. in our CEA based on the scientific literature available, discounting them somewhat but not too heavily, to be comparable to the Give Directly estimate
2) Consciously deciding not to include spillover effects etc. and then comparing "apples to apples". So if there was a simple table saying "this is the direct Give Directly effect, this is the additional spillover effect and this is X, Y, and Z", then we can basically produce the same table for our charity with some fields saying n/a and that would make it comparable somehow...
OpenAI have their first military partner in Anduril. Make no mistake—although these are defensive applications today, this is a clear softening, as their previous ToS banned all military applications. Ominous.
OpenAI appoints Retired U.S. Army General Paul M. Nakasone to Board of Directors
I don't know anything about Nakasone in particular, but it should be of interest (and concern)—especially after Situational Awareness—that OpenAI is moving itself closer to the U.S. military-industrial complex. The article itself specifically mentions Nakasone's cybersecurity experience as a benefit of having him on the board, and that he will be placed on OpenAI's board's Safety and Security Committee. None of this seems good for avoiding an arms race.
Microsoft have backed out of their OpenAI board observer seat, and Apple will refuse a rumoured seat, both in response to antitrust threats from US regulators, per Reuters.
I don’t know how to parse this—I think it’s likely that the US regulators don’t care much about safety in this decision, and nor do I think it meaningfully changes Microsoft’s power over the firm. Apple’s rumoured seat was interesting, but unlikely to have any bearing either.
Lina Khan (head of the FTC) said she had P(doom)=15%, though I haven't seen much evidence it has guided her actions, and she suggested this made her an optimist, suggesting maybe she hadn't really thought about it.
Greg Brockman is taking extended leave, and co-founder John Schulman has left OpenAI for Anthropic, per The Information.
For whatever good the board coup did, it’s interesting to observe that it largely concentrated Sam Altman’s power within the company, as almost anyone else who could challenge or even share it is gone.
As a scientist who writes NSF grants, I think the stuff that you're labeling woke here makes up a very percentage of the total money that actually gets spent in grants like these. Labeling that grant as woke because it puts like 2% of its total funds towards a K-12 outreach program seems like a mistake to me. (And in an armchair-philosophy way, yes the scientists could in principle just resubmit the grants without the last part -- but in practice nothing works like this. Much more likely is that labeling these as "woke" leads people, like the current administration, to try to drastically reduce the overall funding that goes to NSF, with a strong net negative effect on basic science research.)