This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
This post is by Metaculus's Sylvain Chevalier, with input provided by Molly Hickman, and Deger Turan.
Forecasting should lead to smarter decisions on consequential issues. This is challenging, and no one knows the best way to do it, but we’re committed to making it happen at Metaculus.
Below are preconditions we’ve identified:
Forecasts should be trustworthy
Our forecasts should be calibrated. They should be robust to manipulation. They should also be accurate—but this prompts the question: “accurate compared to what other forecast?” We’ve recently published a methodology on how to rigorously compare two forecasters on a set of questions.
Forecasts should be interpretable
The barrier to entry for using forecasts is very high. Newcomers do not know what to do with a 75% forecast. This is partly a user interface problem (Metaculus is too nerdy for many people), and partly a fundamental problem of interpretability, explainability, and transparency. One needs to understand where a forecast comes from to make good use of it.
Questions should be relevant
None of the above matters if we’re not asking the right questions. Is the question confounded in a way that makes the forecast useless? Are we using a good proxy? Would a definite answer actually change anyone’s mind? To solve for these we need to work closely with the people seeking the answers.
How will we achieve all this? When the best approaches are uncertain, it's time to experiment. In the coming months, we will run quick experiments, build prototypes, and make bold changes—both on Metaculus.com and off-platform. To succeed, the most promising ideas will need you: the forecasters, the readers, the commenters, and the decision-makers. We hope you'll help us identify what works, iterate on the best ideas, and bring them to life.
To enable this fast iteration, we’ve fully rewritten our site. Metaculus launched in 2016, and our codebase was old. To build the sense-making tools we want, and to go open source, we knew a fresh start was needed. The rewritten site is nearly feature-complete, with some less-used features cut or simplified, and with some new ideas introduced.
So, what experiments, prototypes, and big changes are we planning? There are many, but we especially want to hear from you on these:
Writing Questions Together
In recent years, the forecasting ecosystem has harnessed the collective abilities of skilled forecasters to co-create accurate predictions and insightful commentary. However, in the current model, forecasting questions and markets are presented fully formed to predictors, offering little opportunity for collaborative development.
We want to develop a process for cooperative and adversarial co-creation of forecasting questions. This would bring together forecasters, stakeholders, and decision-makers to identify and craft the most enlightening and impactful questions, building on work by the Forecasting Research Institute. To scale, this process should be online, decentralized, fast-paced, and more flexible than traditional forecasting—intentionally so—to allow for rapid exploration.
Decision Making Support
Decision-making under uncertainty is notoriously difficult. One vision would have decision-makers continuously iterate with predictions to make better decisions. While this is possible, it is hard to measure and improve. Instead, we are seeking better mechanisms for forecasting to help improve decision-making.
The simplest approach, which we have started to explore already, is using simple conditionals. The challenge is identifying conditionals that are not confounded. Whether non-confounded conditionals are expressive and flexible enough to be useful is an active area of inquiry.
A promising use case we’ve been working on, is what you could call “Consequences forecasting”: a collection of long-term outcomes, all based on a binary short-term decision. Think “What will be the UK GDP in 2030 if it votes to leave the EU in 2016?”, “Will the UK have a hard border by Northern Ireland in 2030 if it votes to leave the EU in 2016?”, etc.
We are also considering a two-tiered approach of Policies→Outcomes, or a three-tiered approach of Interventions → Short-term Proxies → Outcomes. Policies with credible commitments are less confounded than later interventions, since they are further removed from the measured outcomes. Proxies somewhat shield the interventions from the outcomes, but also introduce a degree of separation between them.
Finding high-impact interventions, and short-term proxies is difficult, and we would like to crowd-source their discovery. An exciting possibility is to run “Conditional writing tournaments” where forecasters and experts compete to find interventions and proxies that result in widely differing conditional forecasts for an important outcome while still being plausible (aka “high-value-of-information” questions, for the information theorists out there).
To sidestep the confounding issue completely, we could also elicit non-resolvable causal relationships. Instead of asking “What will be outcome X if we do intervention Y?”, we would ask “What is the causal impact on Y of doing X?” Now, obviously, such questions may not be resolvable or scorable, but crucially they would still benefit from the wisdom of the crowd, and from our aggregation algorithms, including giving more weight to better forecasters.
Intervention Modeling & Conditional Trees to probe our branching future. We always saw Conditional Pairs as a first step toward much more powerful tools. One possibility is to link several conditions into a tree structure. This is great for visualizing the relationships between possibilities, but also for probing futures by setting some nodes to True or False, and observing the impact on the whole tree. Which scenarios are the riskiest? What emerge as the most important early warning signs?
The Forecasting Research Institute recently conducted a study where domain experts and skilled forecasters generated trees of their most informative cruxes, with resolution dates ranging from 2030 to 2070. We’re excited to build on this work!
Reasoning Transparency & World Model Elicitation
Non-forecasters, when presented with a point forecast, are often left wanting. To trust the prediction, they need to examine assumptions, inferences, deductions. In other words they need reasoning transparency. After all, one wouldn’t trust a scientific article that only provided results and didn’t discuss methods, sources, or limitations. We have several ideas:
Publishing Forecasting Indexes to tackle complex, hard-to-operationalize questions. Sometime we want to ask “Will the EU be thriving in 2030?” or “Will we achieve AGI by 2040?” Operationalized forecasting questions tend to be either too narrow to provide useful answers or too poorly specified to forecast. Indexes resolve this tension. They gather related, precise forecasting questions about the state of the world in a given year, then combine and weight them into a single integrated metric. Indexes address difficult, big-picture questions while preserving transparency by making the underlying questions and computations public.
Eliciting not just predictions, but also base rates, arguments, considerations, etc. in a structured way. This lets us aggregate much richer data across forecasters, extract the best, and present it in a palatable format. This would be a good alternative to the current solution of “please go and read 30 comments, 5000 words each.
This would be LLM-augmented, both for aggregation across soft categories, and for seeding low-traffic questions with reasonable defaults.
While it is costly and repetitive for forecasters to enter this information, it is much easier to dispute information and enrich a world model through reactive thinking — in fact, most discourse on Metaculus comments takes this form. We are interested in developing this into structured information.
Building quantitative modeling directly into Metaculus. This could include using our best forecasters’ judgments as input into expert models, collaborative creation of custom quantitative models, or even letting forecasters define models to forecast in their place.
Models are brittle, but with the correct interface they can be extremely legible and interpretable. This lets forecasters stress-test their assumptions and spot flaws in their reasoning, and helps decision makers understand where a given forecast comes from.
In the past, few such models were built, but they tended to generate a great deal of feedback and discussion. While creating a quantitative model from scratch is very high effort for most forecasters, LLMs could infer the models directly from existing text and bootstrap the process. Integration with Squiggle seems like the obvious choice here.
General platform improvements
While we experiment and build, we aren't going to neglect the core Metaculus experience. We've come a long way with Question Groups, Tournaments, Medals, and more, but we still have many ideas for improving forecasting and learning from forecasts. The full list is too long to share, but here's a preview of some ideas we're especially excited about:
Introducing a new forecast aggregation method that’s simple, legible, accurate, and robust to manipulation and noise.
Creating a “Consumer view”: an alternative way to access content on Metaculus, putting much greater emphasis on reasoning transparency. This view would exist in parallel to the current “Forecaster view” and would be informed by ideas from the reasoning transparency track described above.
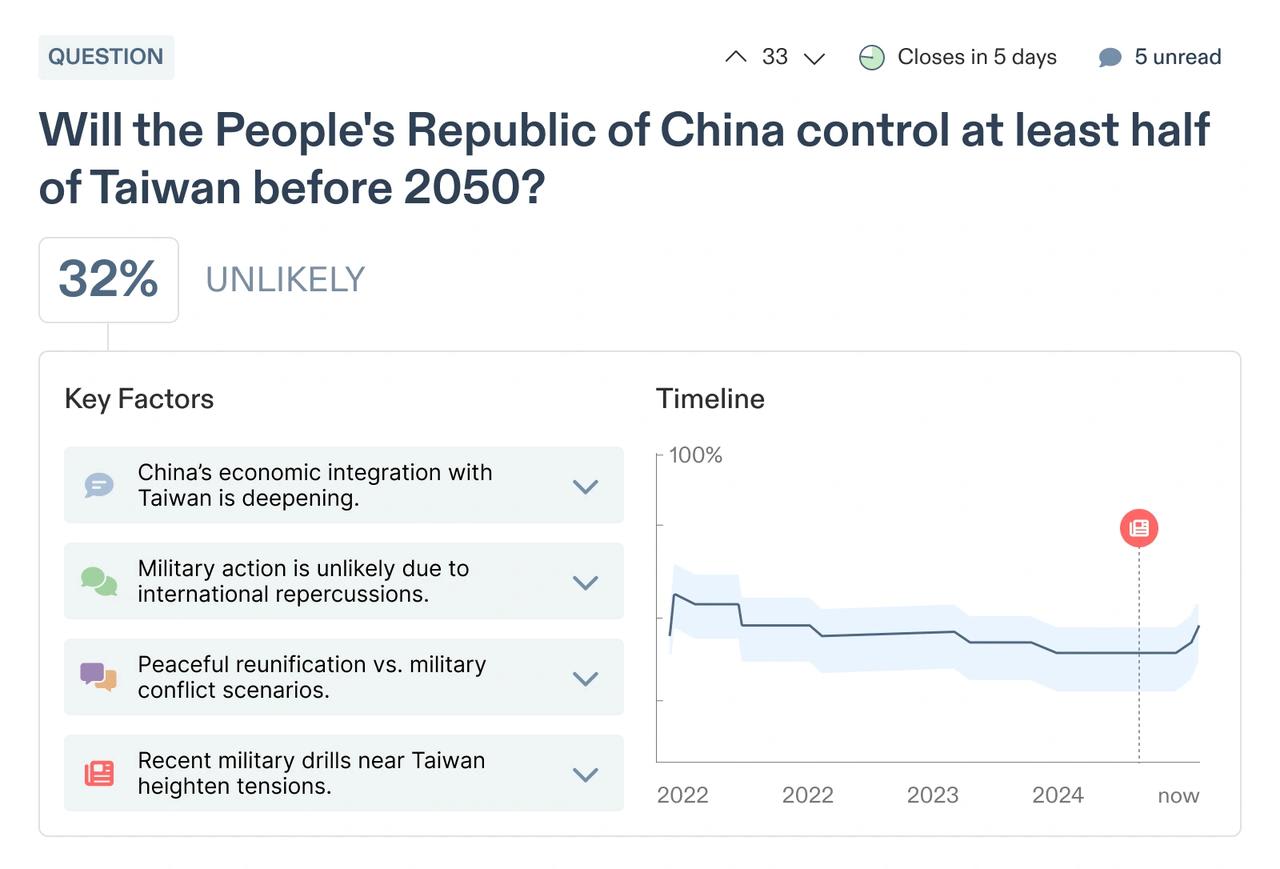
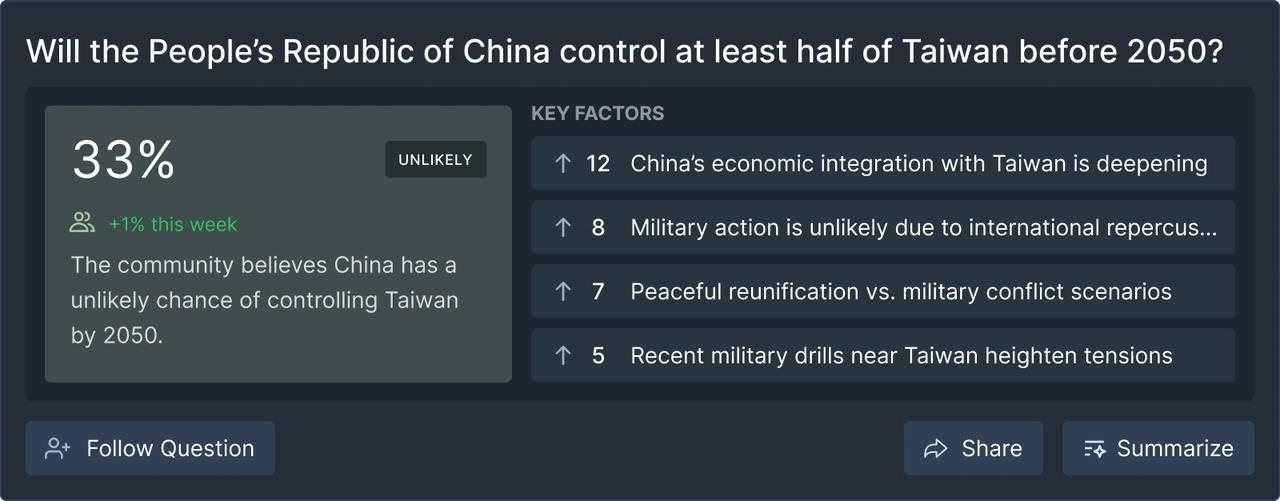
(Note: dummy data, not a real forecast.)
Massively improving our comment sections, separating comment types, and automatically extracting and surfacing base rates, key claims, and arguments made by forecasters.
Improving our onboarding, tutorials, and generally lowering the barrier of entry to forecasting. Also reintroducing global leaderboards, so new and veteran users have clear long-term objectives to strive for.
And much more, including withdrawing from questions you’re no longer interested in, inputting continuous predictions using percentiles, and shareable lists of questions.
If any of this resonates with you, if you have ideas for improving anything you see above, then we want to hear from you! The comment section below is open, or you can reach out to deger at metaculus dot com.



I feel like the bulk of this is interesting, but the title and opening come off as more grandiose than necessary.
(The opening line was removed)
Hey Ozzie, I'll add that it's also a brand new post. But yes, your feedback is/was definitely appreciated.
Ah, I didn't quite notice that at the time - that wasn't obvious from the UI (you need to hover over the date to see the time of it being posted).
Anyway, happy this was resolved! Also, separately, kudos for writing this up, I'm looking forward to seeing where Metaculus goes this next year +.