AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
Adapted from my Substack, Funding Anthropalypse.
Short version: if you want a share of the coming Anthropic and OpenAI windfall - the $37bn+ that could be in play next year - the way in is to become 'legibly excellent', so the evaluators and donors that frontier lab staff already trust point them to yo...
Browse past newsletters here, or view this newsletter on substack here. If you have a content suggestion or want to reach out, you can leave a comment or find me on Twitter.
Kalshi applied to the CFTC for permission to host a market on which party will control the US Congress after the 2022 mid-term elections. The CFTC asked the public for comments (a) (secondary source, (a)).
There has been a range of newspaper articles (a) commenting on the PredictIt spat (e.g., 1, 2, 3, 4, etc.), and on Kalshi’s. I particularly liked this article (a) on the Chicago Tribune on how prediction markets are an antidote to degraded public discourse.
Kalshi has an interesting newsletter issue (a) in which they briefly report on how the Obama administration used prediction markets for their decision-making. Note that these would have probably been PredictIt's markets.
Metaculus
Per their newsletter, Metaculus reached 1 million predictions. They have also reorganized as a public benefit corporation (a), i.e., a for-profit entity that aims to pursue some positive impact, as distinct from shareholder value. I think this leaves Metaculus in a better position, and decreases the (already pretty small) chance that Metaculus starts doing some damaging gatekeeping, etc.
Manifold continued having a high development speed, e.g., they added a Twitch bot (a) and ran their first tournaments (a), which I was really glad to see. They have an experimental projects page at manifold.markets/labs (a) And they have added a few reputational features:
If a resolved market receives enough reports relative to the number of traders, it will be considered a “bad” market. Creators with enough bad markets will have a warning next to their name on any of their markets. This is just a first step towards reputational features which is a highly requested feature.
Manifold Markets removed and deprioritized their numeric markets (a), citing difficulties in user usage. But from the post, the decision to do so seems like it was evaluated on the wrong grounds: It's not that numeric markets will immediately prove popular and intuitive, it's that experimenting with them is a public good that could unlock value in the medium term.
More generally, as I’ve been seeing in these past few years, I think that there is a huge attractor of sports and wall-street-type bets. And new prediction-market startups tend to flirt with these a bit. I think this is a mistake, because it’s hard to differentiate oneself from competitors on the basis of better sports betting: traditional sports betting houses like Betfair in Europe or DraftKings in the US are already catering to a similar user base. Instead, my recommendation would be to target virgin communities, to which already existing betting houses don’t already cater.
We also announced a larger $5k challenge to quantify the impact of 80,000 hours' top career paths. I think that participation in this contest has a fairly high value, but also a fairly high expected monetary value: I invite readers to do a quick estimation, e.g.: the contest will have 3 to 15 participants, implying each participant will get between ~$300 and $1.6k.
The FTX Future Fund announces a $1M+ prize (a) for arguments that shift their probabilities around AGI timelines and dangers.
Friend of the newsletter Walter Frick has started a newsletter (a) that combines analysis of a newsworthy topic with an invitation and a prompt for readers to forecast on a related event. The newsletter then reports readers’ forecasts and resolves them when time comes due. Readers might remember Walter from his excellent coverage of the shutdown of Facebook’s Forecast platform (a) at Quartz.
The Autocast competition (a) offers $625k in prizes for improving the forecasting abilities of machine learning models. This builds on the Autocast (a) paper. It might be that the contest has a connection to AI safety, but I'm not really seeing it. The deadline to submit results for the warmup round is February 10th.
Adam Sherman reports on his frustrations with the UMA project (a). These rhyme somewhat with previous complaints about Kleros (a). Abstracting away from the specifics, the UMA oracle is a Keynesian Beauty Contest, meaning that consensus is valued over truth. In this case, a powerful but not dictatorial participant announced that he was going to vote one way, and because the protocol rewards people who vote with the consensus, he convinced others to vote with him. My sense is that a Keynesian Beauty Contest might still be a worthy tradeoff for some crypto protocols because of the added decentralization. But if too many of these events happen, the tradeoff might stop being worth it.
The Social Science prediction platform has added some large-for-graduate-students forecaster incentives (a). They are offering $100 per 10 surveys completed—a survey is usually just a set of predictions that will be used in a future paper. I welcome this development. I used to view it as annoying that participation was restricted to graduate students and faculty. But the thought came to mind that restriction to academics is just a socially acceptable—if coarse—way of selecting for intelligence without saying as much.
Reddit has r/polls/predictions (a), an embryonic implementation of a prediction market tournament inside Reddit. This builds on Reddit's past prediction functionality, as reported previously (a) in this newsletter (a). It would be useful to talk to whoever is building this functionality at Reddit. They probably have some different goals, more geared towards being a social media site. But some cross-pollination might still be interesting.
Craze (a) is a Y-Combinator-funded company which brings predictions markets to India.
I was surprised to see that famous rapper Nicki Minaj has partnered (a) with a sports (a) betting site (a). Curious
INFER continues to have small-money incentives for forecasters, and sending me mildly cringy emails (a), and talking about a "Global AI Race" (a). I'd continue to recommend it for university students, because it's one of the few sites that have a team functionality, though.
Nostalgebraist looks at AI forecasting one year in (a) and warns against taking it as a stylized fact (a) that AI progress is going faster than forecasters expected.
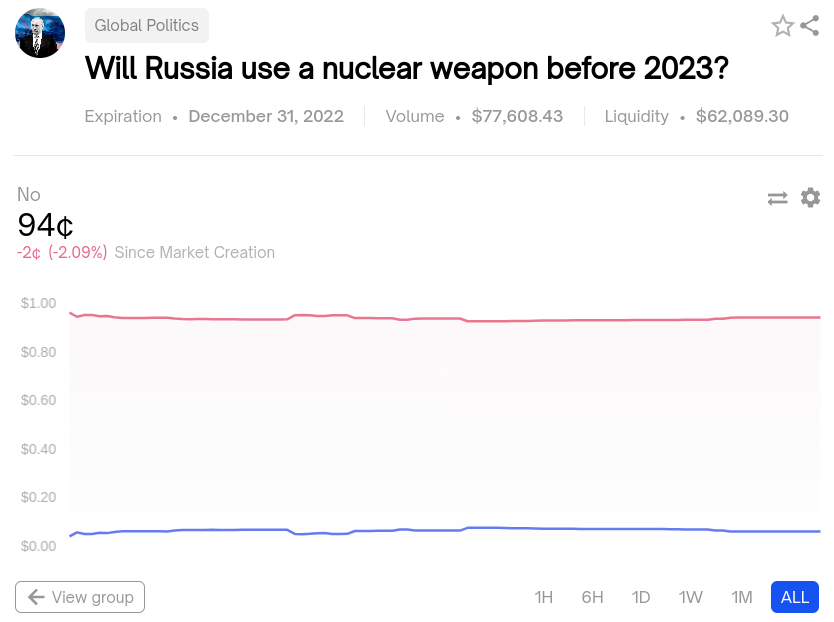
Taken from Polymarket. Note that money is worth less in the event of a nuclear war.
Some researchers at the University of Pennsylvania are looking for forecasters to predict replication outcomes (a). They are paying a $20 base incentive and $25 per market. This is low in absolute terms, but high if you enjoy doing this kind of thing anyways. h/t Ago Lajko.
Richard Hanania argues that the problem with polling might be unfixable, i.e,. that Republican nonresponse bias might be very hard to estimate. I left a comment with some suggestions, but I agree that the situation looks grim (a).
Two (a) old posts (a) from ten years ago look at the lessons learnt by someone who was participating in the IARPA forecasting tournament which led to the Superforecasting book.
Longform
Dan Luu looks at the track record of futurists, and finds that their track record is generally poor. Readers of this newsletter should read the post (a).
For some background points:
The AI safety community has been advocating that future artificial intelligence systems (AI) might be so intelligent as to be world-ending dangers.
Open Philanthropy, a large foundation, is giving some weight to AI safety, and has been donating large amounts of money to that cause.
The CEO of Open Philanthropy later used that analysis (a), as well as other research Open Philanthropy had been doing, to justify and explain Open Philanthropy's investments in AI Safety.
In his own analysis of futurists' track record, Dan Luu seems to point out that this process has some characteristics of a shit show. Here is a long extract from Luu's post, minimally edited for readability:
We've seen, when evaluating futurists with an eye towards evaluating longtermists, Karnofsky heavily rounds up in the same way Kurzweil and other futurists do, to paint the picture they want to create.
There's also the matter of his summary of a report on Kurzweil's predictions being incorrect because he didn't notice the author of that report used a methodology that produced nonsense numbers that were favorable to the conclusion that Karnofsky favors.
It's true that Karnofsky and the reports he cites do the superficial things that the forecasting literature notes is associated with more accurate predictions, like stating probabilities. But for this to work, the probabilities need to come from understanding the data.
If you take a pile of data, incorrectly interpret it and then round up the interpretation further to support a particular conclusion, throwing a probability on it at the end is not likely to make it accurate.
Although he doesn't use these words, a key thing Tetlock notes in his work is that people who round things up or down to conform to a particular agenda produce low accuracy predictions. Since Karnofsky's errors and rounding heavily lean in one direction, that seems to be happening here.
We can see this in other analyses as well. Although digging into material other than futurist predictions is outside of the scope of this post, nostalgebraist has done this and he said (in a private communication that he gave me permission to mention) that Karnofsky's summary of Could Advanced AI Drive Explosive Economic Growth? is substantially more optimistic about AI timelines than the underlying report in that there's at least one major concern raised in the report that's not brought up as a "con" in Karnofsky's summary.
And nostalgebraist later wrote this post (a), where he (implicitly) notes that the methodology used in a report he examined in detail is fundamentally not so different than what the futurists we discussed used. There are quite a few things that may make the report appear credible (it's hundreds of pages of research, there's a complex model, etc.), but when it comes down to it, the model boils down to a few simple variables.
In particular, a huge fraction of the variance of whether or not TAI is likely or not likely comes down to the amount of improvement will occur in terms of hardware cost, particularly FLOPS/$. The output of the model can range from 34% to 88% depending how much improvement we get in FLOPS/$ after 2025. Putting in arbitrarily large FLOPS/$ amounts into the model, i.e., the scenario where infinite computational power is free (since other dimensions, like storage and network aren't in the model, let's assume that FLOPS/$ is a proxy for those as well), only pushes the probability of TAI up to 88%, which I would rate as too pessimistic, although it's hard to have a good intuition about what would actually happen if infinite computational power were on tap for free.
Conversely, with no performance improvement in computers, the probability of TAI is 34%, which I would rate as overly optimistic without a strong case for it. But I'm just some random person who doesn't work in AI risk and hasn't thought about too much, so your guess on this is as good as mine (and likely better if you're the equivalent of Yegge or Gates and work in the area).
I'm sympathetic to both sides of this.
On the one hand, I worry that the side concerned about AI safety acts like a machine that predictably surfaces and amplifies arguments in favor of its side, and predictably discounts arguments for the other side.
On the other hand, I also see Luu's analysis as perhaps too harsh, e.g.:
not giving partial credit for predictions that are missed by a few years or that only happen in rich countries rather than worldwide,
considering predictions that have a "may" as unfalsifiable (instead of e.g., assigning a probability of 50% and looking at the resulting Brier or log score),
evaluating two propositions connected by an "and" as one failed prediction instead of one correct and one incorrect prediction.
evaluating predictions about the "twenty-first century" as having already failed
generally being on the harsh side of things
Overall, it seems like there is a garden of forking paths with regards to the more specific question of how accurate past futurists were, but also with regards to the more general question about the degree to which it is possible to make predictions about future events, particularly about transformative technologies.
One way to navigate that garden of forking paths would be an adversarial collaboration (a). Funding for this would probably be available, if not from Open Philanthropy itself then from the FTX Future Fund (a), from Nonlinear (a), or even from myself. I mention funding because I personally view cold hard cash as an honest signal that some work is truly perceived to be valuable. But one could also choose to carry out an adversarial collaboration pro bono, for the sake of curiosity, etc.
from averaging the different pieces of information that each participant has
from traders which are able to individually do more research than everyone else, and profit from this.
They have a method I'm not completely convinced by in order to identify "price sensitive" traders, whom they identify with informed traders, and they use their dataset to conclude that hypothesis 2 is mostly what’s going on. They use data from Almanis (a), one of the smaller prediction market sites that still have some liquidity.
The paper has some interesting elements. And for all I know, it's better than 99% of the papers in its field. But I'm left with the impression that the topic of research is a bit of a bad fit for academic investigation, because one could get a better idea of the dynamics of prediction markets by listening to the Star Spangled Gamblers (a) guys.
Note to the future: All links are added automatically to the Internet Archive, using this tool (a). "(a)" for archived links was inspired by Milan Griffes (a), Andrew Zuckerman (a), and Alexey Guzey (a).
— What are you waiting for? — I don't know... Something amazing, I guess. — Me too, kid




{kind=link}
{kind=link}