This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
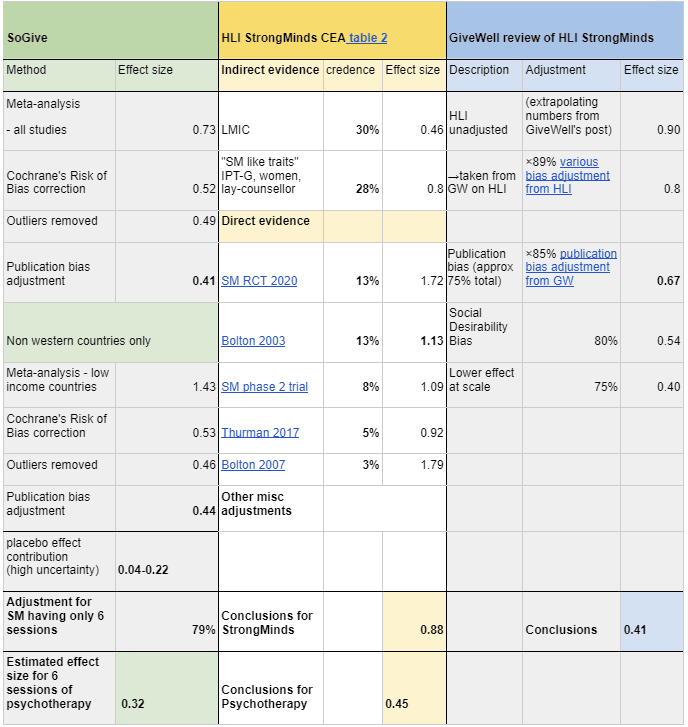
We estimate that the effect size of administering 6 sessions of psychotherapy has an effect size of Hedges g=0.32 on depression severity per person treated. For comparison HLI's assessment was 0.88 and GiveWell's assessment was g=0.41 .
The pooled effect size for psychotherapy for all randomised controlled trials included in our meta-analysis was g=0.41.
We estimate StrongMind's impact on each client at g=0.32, because the average study in our meta-analysis does 9 sessions of psychotherapy, whereas StrongMinds does 6. We're uncertain about this estimate.
The main difference from previous analysis comes from Cochrane's Risk of Bias corrections, which account for effect size inflation due to bad study designs. We also do corrections for publication bias.
Unlike the HLI analysis, we don't think intervention-specific factors like country, or type of therapy, or patient demographic matter much, and that g=0.41 applies to most psychotherapies. Insofar as this might have produced a different result, the difference shrinks after risk of bias correction.
Unlike GiveWell's analysis, due to a notable absence of evidence regarding what constitutes high quality psychotherapy, we don't think StrongMind's implementation is worse than the typical RCTs, and so we do not apply a discount for implementation at scale aside from number of sessions.
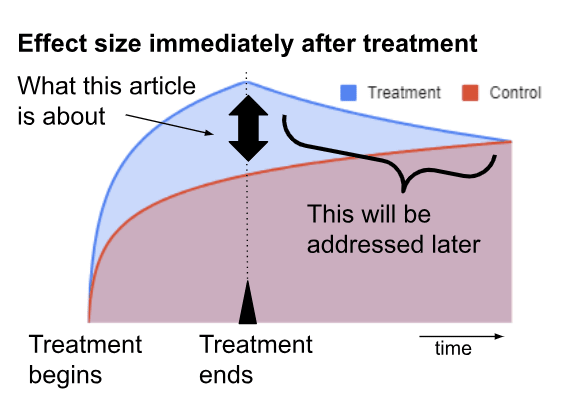
This document reflects only the effect size immediately at the conclusion of psychotherapy. This is just one component of our Cost Effectiveness Analysis. We will cover costs, duration effects, and family spillover effects in subsequent articles.
Introduction
How effective is psychotherapy for depression? We investigated the effect size of psychotherapy on depression immediately after treatment. This is one of several components that will go into our impact analyses of mental health interventions in general, as well as our cost-effectiveness analysis of StrongMinds more specifically.
Previously, we introduced the concept that the impact of psychotherapy on depression can be analysed in two parts: The first, quantifying the impact of psychotherapy on depression immediately after the administration of treatment, and the second, quantifying the long term effects of psychotherapy after treatment is over. This article quantifies the immediate impact of psychotherapy.
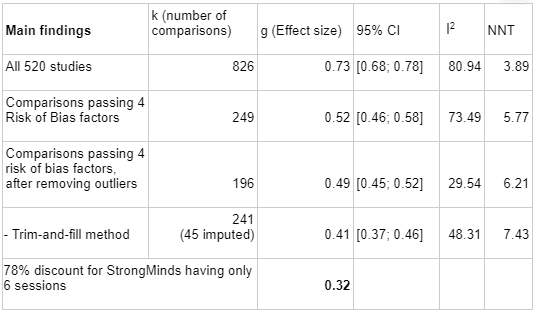
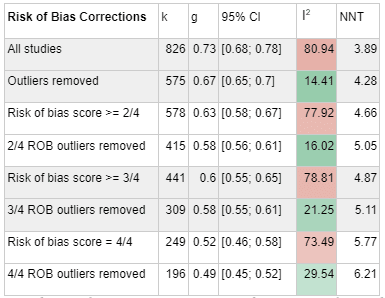
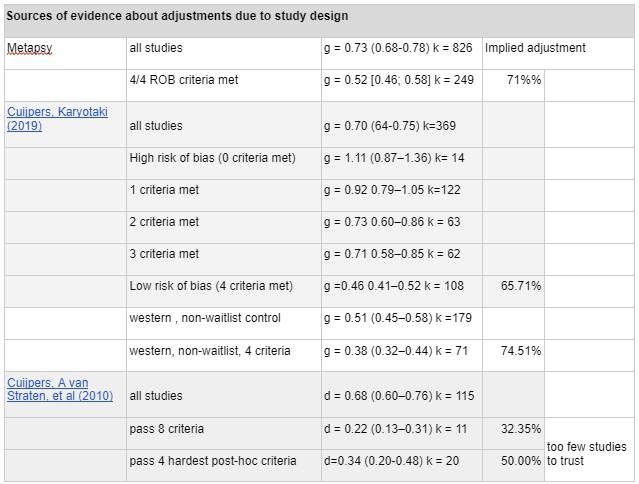
We base our estimate on meta-analysis using the METAPSY dataset, which is the largest database we could find on psychotherapy interventions on depression, and which comes built in with useful meta-analysis tools. Starting from an aggregated effect size of g = 0.73, after removing studies which did not pass four criteria assessing risk of bias factors in study design (g= 0.52), removing outliers (g = 0.49), and adjusting for publication bias (g=0.41), we found that the overall effect size of therapy is Hedge's g = 0.41, on a basis which excludes our final adjustments for the number of therapy sessions. Further restricting the analysis to low-income countries increases it to Hedge's g = 0.44; we chose not to focus on this number for the reasons set in the section on Extreme global poverty. We think these estimates reflect the current state of academic knowledge regarding the impact of psychotherapy, including those in low-income contexts which are similar to StrongMinds. We've reviewed some academic meta-analyses which come to different conclusions, and after accounting for differences in which populations they are analysing and which adjustments they choose to make, we can give an account of which methodological choices cause the difference.
Risk of bias factors: METAPSY has graded every paper in the dataset using Cochrane's Risk of Bias tool (version 1), which ascertains sources of bias stemming from study design. We restricted our analysis to studies which met all four out of four criteria.
Removing Outliers: METAPSY considers studies with a 95% confidence interval which lies outside the 95% confidence interval of the pooled effect as an outlier. We chose to remove outliers in order to keep heterogeneity (I2) low - publication bias correction techniques can give unusual results when heterogeneity is high.
Publication bias: METAPSY offers several methods for correcting for publication bias. We went with Duval and Tweedie Trim and Fill.
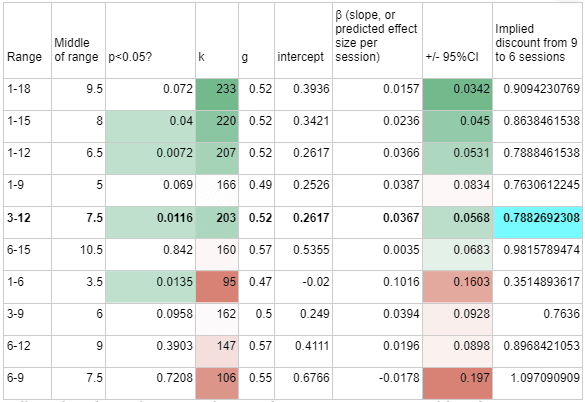
We are highly uncertain regarding how much psychotherapy is required to achieve a given result. The average study in our analysis had 9 sessions, whereas the StrongMinds intervention has 6 sessions. The evidence suggests diminishing returns - that the first few sessions have more impact than later sessions. Using number of sessions as a predictor in a mixed-effects meta-regression on psychotherapy studies which ran between 3 and 12 sessions and pass all four Cochrane's risk of bias in study design (g=0.52) returned a slope of 0.036 and intercept of 0.26. We therefore estimated that shortening the number of sessions from 9 to 6 might theoretically adjust the effect size by a factor of by (0.52-0.036×3)/0.52 = 79%, which would bring our final number to 0.41×79%= 0.32, though we think anything from 66% to 90% could plausibly be justified.
We believe there is significant uncertainty about how to think about "placebo effects". Estimates of placebo effects in psychotherapy range from 0.04-0.21. We think that a genuine placebo effect, reflecting benefits stemming from the expectations of the patient, should "count" as impact, but there may be other sources of bias masquerading as placebo effects, and literature on the size of placebo effects both in mental health and in general is scarce. We also think that in the spirit of making equal comparisons, it's best to consider placebo effects separately, because whether one wishes to subtract placebo effects may change depending on whether one is comparing psychotherapy to a placebo controlled intervention (e.g. analyses regarding the effect of cash transfers aren't placebo controlled, whereas analyses regarding impacts of deworming pills draw from placebo controlled literature).
We will defer discussions of the duration of the effect, the cost of the program, household spillovers, and the interpretation of moral weights to be published in subsequent posts.
Acknowledgements
We'd like to thank Joel McGuire and HLI for their feedback and for laying the groundwork for EA research into mental health, Prof Cuijpers, and Gregory Lewis for their advice and criticism, and the builders of the metapsy project designing the tools and databases that enable this analysis. This article is primarily the work of Ishaan from SoGive, with substantial input and support from Sanjay and Spencer.
How our work compares to previous analyses
Previously, the Happier Lives Institute (HLI) did two meta-analyses, which suggested effect size of 0.46 for psychotherapy in general, and 0.80 for studies with "StrongMinds-like-traits". They combined with this with direct evidence from StrongMind's internal RCT (SM RCT 2020), StrongMind's phase 2 trial, from Bolton 2003 which StrongMinds intervention was modelled off of, and from Bolton 2007 and Thurman 2017, two studies with contexts similar to StrongMinds to arrive at an estimate of 0.88.
[Update: HLI has recently put out an updated analysis which revises the initial effect estimate to 0.7, whereas this document refers to an analysis from 2021.]
Subsequently, starting with the 0.80 figure of studies with "StrongMinds like Traits'', GiveWell subtracted an additional 15% to HLI's pre-existing 10% cut for publication bias, a 20% cut for social desirability bias, and a 25% cut for lower cost-effectiveness at scale outside of trial contexts, which would bring the estimate for the initial effect down to 0.41 . Our analysis of the effect size of therapy was made before we knew that GiveWell was also doing an assessment, so ours can be thought of as somewhat independent analyses.[1]
MetaPsy has study design bias correction: HLI estimates do have some form of correction for risk of bias in study design, but their methodology is centred around finding the ratio of bias between cash transfer studies and therapy studies using a subjective assessment of its relative importance. They determined that discounting psychotherapy studies by 89% would put psychotherapy and cash on an even footing McGuire, (2021a).
In contrast, we use MetaPsy tools to eliminate studies with various risk of bias factors in order to estimate the absolute number, using only objective assessments. We think this is the biggest contributor to the differences between our assessment and HLIs.
SoGive favours broader evidence over more contextually specific evidence, when it comes to assessing the impact of therapy: The 0.80 figure which GiveWell took as a starting point from McGuire, J. (2021b), table 1b p. 13, is drawn from studies with "StrongMinds-Like-Traits", which included variables to indicate that a study was primarily psychotherapy, delivered to groups, women, and by non-specialists. Additionally, HLI’s analysis was restricted to low income countries, and evidence which most directly pertains to StrongMinds was weighted higher. Based on our review of literature, we think that without risk of bias correction, a lot of the variation in these datasets will be entirely due to bias arising from differences in study design. We also don't think there's sufficient evidence that these factors matter to justify filtering the dataset in this way. Therefore, our dataset includes all countries, all psychotherapy types, and all delivery modalities.
SoGive's publication bias adjustment is similar to GiveWell's 75%, probably by coincidence: GiveWell's 75% publication biasadjustment is based on a paper by Driessen (2015) which empirically determined the discount by identifying 20 published studies which got NIH grants, and then contacting grant awardees who did not publish to collect their manuscripts. Adding 6 unpublished studies made the effect size drop by 75%.
For SoGive, post-risk-of-bias correction at g = 0.52, the combination of correcting for outliers (to reduce heterogeneity) and correcting for publication bias brings us down to 0.41, which is a 78% adjustment.
However, Driessen (2015)'s dataset mixes placebo controlled trials and head-to-head antidepressant and therapy-vs-therapy comparisons in a way that make the characteristics of their dataset quite different from both METAPSY's and HLI's dataset, so we're not sure whether to consider this an independent convergence on the same conclusions or a coincidence.
GiveWell gives a 75% discount for implementation at scale, whereas SoGive is optimistic about implementation at scale - our 79% discount is specifically about number of sessions: GiveWell has a general expectation that programs implemented as part of randomised trials are higher quality than similar programs implemented at scale outside of trial settings.
However, we found a conspicuous lack of evidence that things like "type of therapy" or "therapist experience" or "therapist training" matters, despite a fair amount of academic research on the topic. The only factor that we found reliably associated with therapy effectiveness is roughly whether the client likes the therapist. This is known as the “therapeutic alliance” in the literature. Since we can't empirically support the hypothesis that some types of therapy are better than others, we don't think there's any particular reason to believe that therapy administered in RCTs is better than therapy administered by implementation organisations. The evidence that some implementations are particularly better than others in a systematic way is severely lacking. That's not to positively claim that there aren't differences in therapy quality - common sense suggests there must be some, but there is not much reason to think that academic studies are doing a better job of it.
One common-sense quality modifier is total therapy time. Based on a metaregression analysis, we did give StrongMinds a 79% discount from the average RCT, for having six sessions against the average RCT’s nine. We didn't actually find strong support from the academic literature about the amount of therapy or number of sessions mattering (e.g. Cuijper, 2013 was unable to find a statistically significant effect) but the idea that number of sessions is irrelevant seemed too contrary to common sense not to discount it.
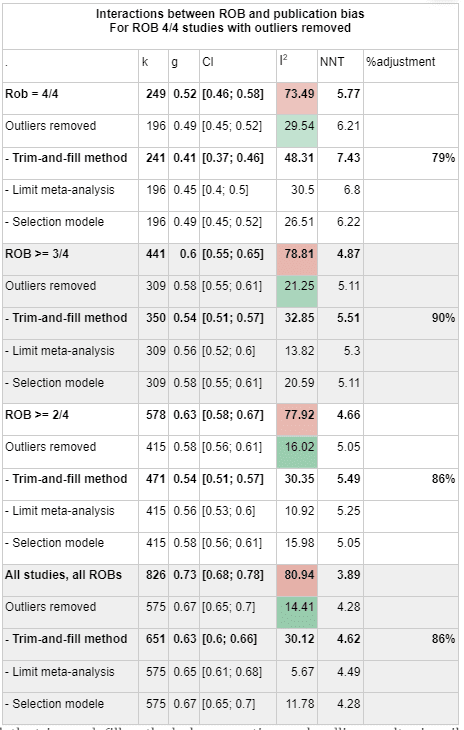
MetaPsy has more data: We think HLI's initial meta-analysis of indirect evidence is probably methodologically valid, but METAPSY brings much more data to the table: HLI "extracted data from 39 studies that appeared to be delivered by non specialists and/or to groups" (McGuire, 2021a) whereas the METAPSY database aggregates 520 studies containing 826 comparisons, with 196 comparisons making it to the final analysis after outliers and studies with risk of bias factors in study design were removed.
SoGive is in agreement with HLI's overall framework for aggregating longitudinal impact across many patients: As previously discussed, we generally agree with and plan to use HLI's overall methodology of integrating effect size with decay rate to find total effect, and think it's superior to methods like number needed to treat or comparing remission rates.
SoGive doesn't correct for Social Desirability Bias: Because we started our analysis before seeing GiveWell's, social desirability bias wasn't on our radar and we have not devoted much time to it. The issue was first raised by StrongMinds Phase II impact evaluation (P16) and followup (p2).
We're not sure whether GiveWell's choice to add this discount stems from StrongMind's raising of the issue, but we think that while the authors of the StrongMinds Phase II trial settled on "social desirability bias" as an explanation for the unrealistically high results, there were likely several additional sources of bias that could explain it - including an absence of evaluator blinding, lack of intention to treat analysis, and inadequate randomization of study arms.
Our risk of bias in study design corrections rule out any RCTs without adequate blinding - which means the person or instrument evaluating the patient should not know whether the patient received therapy. This should rule out at least some of the common sense risk factors for social desirability bias.
Our short review of literature made us sceptical of social desirability bias inflating the results by 20%, and we're not sure there's any principled way to arrive at the 20% guess. However, we have not spent much time on this and may change our view in the future.
We do think that if social desirability bias did influence high quality RCTs, it might fall under "apparent (false) placebo effects", especially those involving sham therapy, since successfully placebo blinded participants should also be vulnerable to the bias. This means we might use placebo controlled data to place upper bounds on the effect.
What would happen if GiveWell and SoGive's pessimistic adjustments were added together?: If an 80% social desirability bias adjustment was added to our results, it should lower effect size to .41*80%=.33. If an additional 75% adjustment was added for lower effectiveness at scale, it would become 0.41*80%*75%=0.25. After adjusting for lower session counts, this would become 0.25*75%=0.20
Interpreting practical significance
What is the practical significance of an effect size of around g=0.0.41, (or of 0.22, if placebo controlled)?
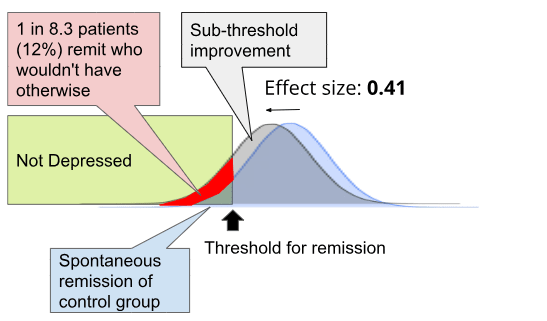
Traditionally, 0.2 is considered a "small" effect, 0.5 is considered a "medium" effect, and 0.8 is considered a "large" effect. Using Furukawa (2011)'s methodology as explained previously, an effect size of 0.41 for this dataset corresponds to a number needed to treat of 8.3, which means that for every person you treat, there is a 1÷8.3=12% chance that they become in full remission from depression due to your intervention and would not have remitted otherwise, ignoring sub-threshold improvements.
From another angle, a model which runs simulated changes on real-world RCT trial data by Hieronymus (2021) suggests that if 20% of treated depressed patients were to magically be cured (no partial effects as you would see in the real world), with the remainder of patients showing only placebo effects, the effect size of that would be 0.22 against a pill-placebo (check out this blog post by AstralCodexTen for an accessible review which also discusses effect sizes for other common treatments).
The scores of the average RCT participant from our METAPSY database who took the PHQ-9 had a standard deviation of 4.2, which means that each point of improvement on the PHQ-9 would correspond to an effect size of 0.24. Accordingly, an effect size of 0.41 means that patients can attribute about 2 points of improvement on the PHQ-9 to psychotherapy.
In a subsequent article, we will expand more deeply on what a given effect size means for our moral intuitions, especially when combined with assessments for how long the effect lasts.
Meta-Analysis - a more detailed overview
We conducted our analysis using the metapsy R package, which among other things contains built-in functionality to correct for outliers, Cochrane's risk of bias, and publication bias.
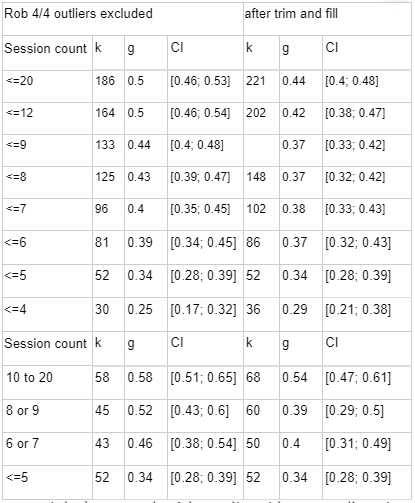
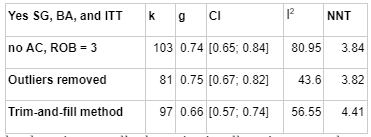
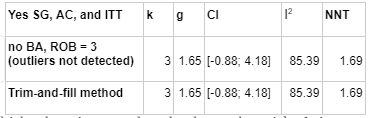
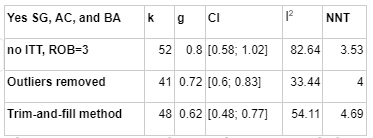
Risk of Bias correction represents the most pessimistic adjustment on our analysis, reducing our effect size estimate from g = 0.72 (95% CI 0.66-0.78) to g = 0.53 (95% CI 0.46; 0.58), a 71% adjustment. The following illustrates how more stringent risk of bias correction tends to decrease our estimate.
In this table, k refers to the number of "comparisons" in the meta-analysis. The number of comparisons is a bit like the number of studies, except that some studies involve more than one "comparison" (for instance, studies that looked at two different types of psychotherapy).
I2 is a measure of heterogeneity, which aims to quantify the degree to which variation in study outcomes is not due to statistical chance but rather due to underlying differences in study design, populations, and similar factors. Having low heterogeneity is crucial for the validity of our next step, which is correcting for publication bias. Using tools to correct for publication bias tends to only work if heterogeneity is low. <25% is considered low and >75% is considered high for I2. We've highlighted how the decision to remove outliers helps reduce I2. We don't know whether or not this genuinely addresses the "true" underlying heterogeneity.
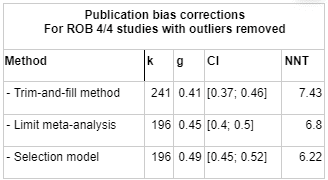
To get to our final number, we corrected non-outlier studies which passed all four risk of bias measures corrections for publication bias. We went with the number given by the Trim-and-fill method, which creates a funnel plot which estimates where unbiased results would fall, trims results that fall outside that funnel plot, and "imputes" or fills in the missing data that it thinks went unpublished. k=241 means that 45 studies were "imputed".
We don't think that it would be a good idea to generalise this result into an estimate, because it involved inadequate controls and several risks of bias, and generally seems "too good to be true" in terms of the magnitude of the effect. If we trusted this data, then we might think that 6 sessions has 99% of the benefit of 9 sessions.
Cuijpers (2013)analyses effect sizes by studies according to how much therapy occurred and estimated a Hedges' g = +0.10 increase in effect size per 10 sessions and g =+0.13 increase per 10 hours of therapist-client contact, but the data was didn't look at studies with fewer than 4-6 Sessions, had wide bins, and looked at the number of sessions in a given study as a whole (rather than the effect of each session within a study). Additionally, the findings weren't statistically significant.
When we plotted effect size against number of sessions in MetaPsy, no clear patterns emerged (meta-regression β = 0.005 (95% CI -0.006-0.017, p= 0.341). We tried doing a bunch of post-hoc changing around variables such as risk of bias, or restricting it to specific countries to remove sources of noise that might obscure effects relating to number of sessions, or changing the range of number of sessions analysed, but we didn't find any patterns that we considered meaningful..
When we tried restricting the analysis to studies with a smaller number of sessions, some potential patterns began to emerge, where studies with higher session counts did report higher effect sizes, as expected.
A quick and unsystematic look at a couple of the studies with very small session count revealed that they were having much longer sessions, which is probably confounding everything.
To arrive at an estimate, we ran a meta-regression on studies which ran between 3 and 12 sessions, and then calculated the likely discount that going from 9 to 6 sessions would bring using the formula [g-3β]/g=1-3*0.0367/0.52=79%. This calculation is shown below highlighted in blue, with similar calculations for other ranges shown alongside it.
Overall, we don't have a lot of confidence in this part of our estimate. Although it is quite important for practical decision making in this area, we are currently relatively clueless about how many sessions are needed in psychotherapy, or what the dose-response curve of psychotherapy might look like.
We generalise our findings to low income countries and non-western cultures
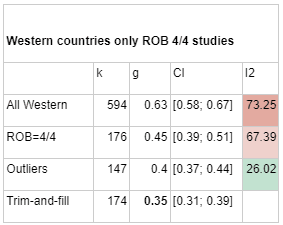
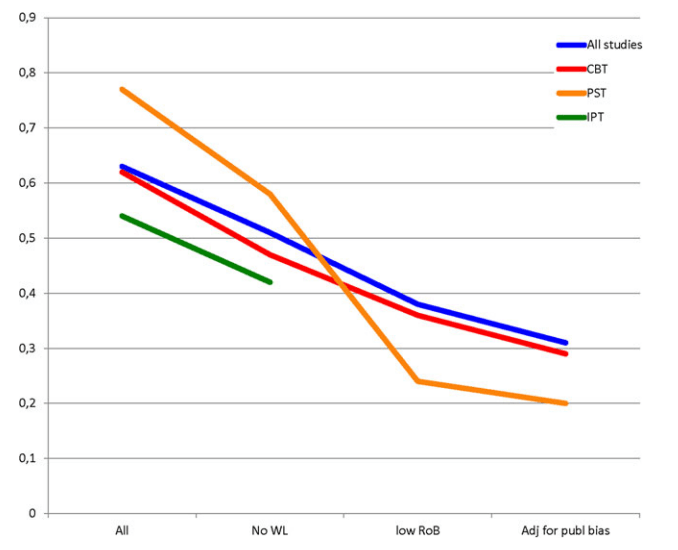
When we began this analysis, one of our biggest uncertainties in evaluating the effectiveness of psychotherapy interventions from the global poor was how much to weigh data from everywhere vs data which specifically involved low income countries and the global poor. After doing the meta-analysis, we found that after risk of bias correction, restricting the sample to non-Western countries countries did not give meaningfully different answers relative to using data from all studies (though data that is restricted to non-Western countries remains meaningfully different from data restricted to Western countries even after all corrections).
In the beginning, there were hints that interventions aimed in less resource-rich contexts have better effects, and a reasonable narrative about how this might be because of greater struggle or less general exposure to and access to mental health assistance. We think this is why HLI used mostly data from low income countries to make their estimate.
MetaPsy's "Country" categorises group studies by whether they are in the United States, Canada, United Kingdom, Australia, the European Union, in East Asia, or in "other". All studies in "other" are "non-Western" countries, with a possible ambiguity exception in Israel. Other than Israel, some higher income non-Western countries (Turkey, Chile, Brazil, Colombia, South Africa) are part of the dataset, but the majority of the studies are done in low and middle income countries.
When we ran these countries through the same meta-analysis process that we used for all studies, we arrived at g=0.44 which was similar to what we got when we used all data (g =0.41).
We considered using g = 0.44 instead of g = 0.41 for our headline estimate of StrongMinds, which takes place in a low-income country, except that in the case of this dataset, I2 heterogeneity remained high, and our understanding is that publication bias correction becomes unreliable under such conditions. Therefore, we decided to stick with g = 0.41.
We still think that it's possible that treatments in non-Western countries are more effective than treatments in Western countries. When we restrict our meta-analysis to Western countries, we do get lower numbers (g=0.35) after publication bias correction and outlier removal.
However, given the smaller number of studies passing all four risk of bias criteria in low income settings, and the heterogeneity issue described above, we still opted to use the pooled effect size of all studies rather than restricting the analysis to non-Western ones.
Academic estimates of effects in low income and non-western countries: Why did we initially think that the effect size would be higher in non-western countries?
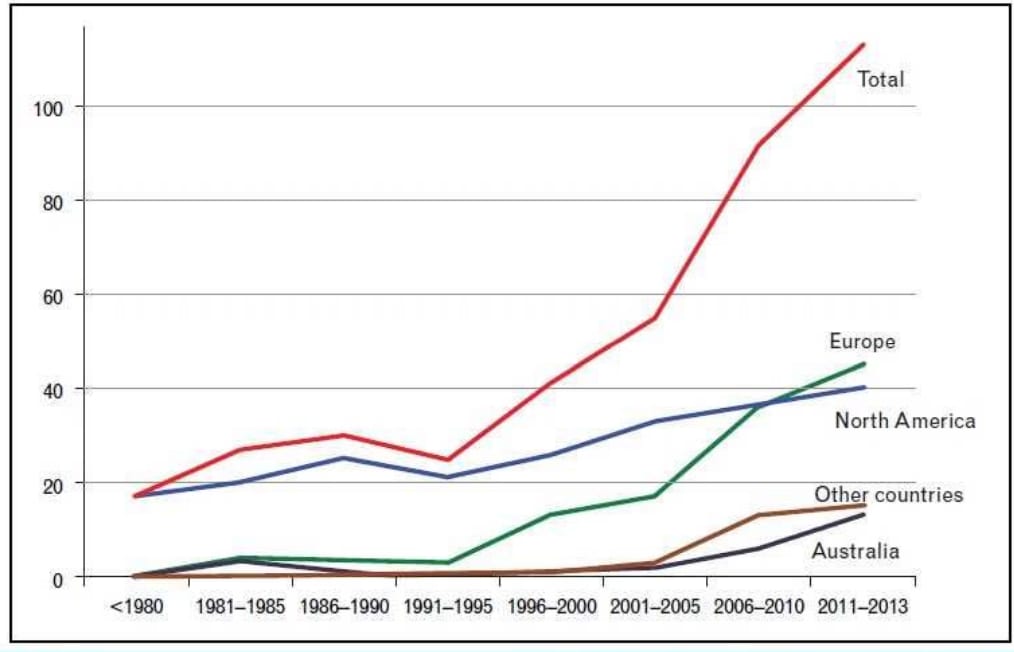
Most psychotherapies have been developed in high-income Western countries in places like North America, Europe and Australia, as have most RCTs regarding their effectiveness. A growing number of more recent RCTs have been conducted in other countries, and they tended to show higher effects.
Figure: The number of psychotherapy RCTs by year and country (Cuijpers 2017). Most are in Western countries, but in recent years it is changing.
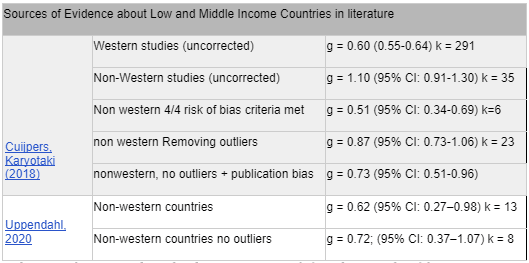
Analysing 32 non-western studies with 4,607 patients, Cuijpers, Karyotaki (2018) found that psychotherapy effect sizes were higher, with g = 1.10 (95% CI: 0.91-1.30), dropping to g=0.87 (95% CI: 0.73-1.06) after removing outliers and effect sizes of g>2. After Duval and Tweedie’s trim and fill procedure for publication bias, effect sizes dropped from g=1.10 to g=0.73 (95% CI: 0.51-0.96). Studies which achieved the highest quality score on the Risk of Bias quality assessment tool (Higgins 2011) had an effect size of g=0.51 (95% CI: 0.34-0.69). In comparison, the 221 western studies in the sample had a much lower effect size of 0.60; (95% CI: 0.55-0.64), an effect which persisted after controlling for bias and quality.
A smaller but more recent analysis of 13 studies (2626 patients) which looked at depression and anxiety and PTSDptsd (Uppendahl, 2020) found and effect size of g = 0.62 (95% CI: 0.27–0.98), which rose to g = 0.72; (95% CI: 0.37–1.07) after excluding outliers.
Based on these findings, we thought there was a possibility that we should give interventions from non-Western countries a boost. However, after doing our own meta-analysis we decided it was better to go with the pooled effect size of all studies instead.
Extreme global poverty
Cuijpers (2018) and (Uppendahl, 2020) look at non-western and low-income countries, and the MetaPsy "other" category mostly contains low-income-countries. However, studies done in low-income countries often include higher income populations such as university students, internet users, or people who have a referral from a primary care physician. Since we are particularly interested in evaluating StrongMinds, and as effective altruists more generally, we are most interested specifically in demographics experiencing extreme global poverty.
The MetaPsy dataset includes breakdowns by region. The dataset categorises studies into "UK, US, CAN, AUS, EU, East Asia, and Other" so I looked up the studies and manually broke down "other" into additional regions. Any errors in that regard are my own. First, we broke the data up by country, in order to exclude high income countries that had fallen under the "other" category. Then, we briefly reviewed each paper to identify whether it described a population in global poverty. See our accompanying spreadsheet for details.
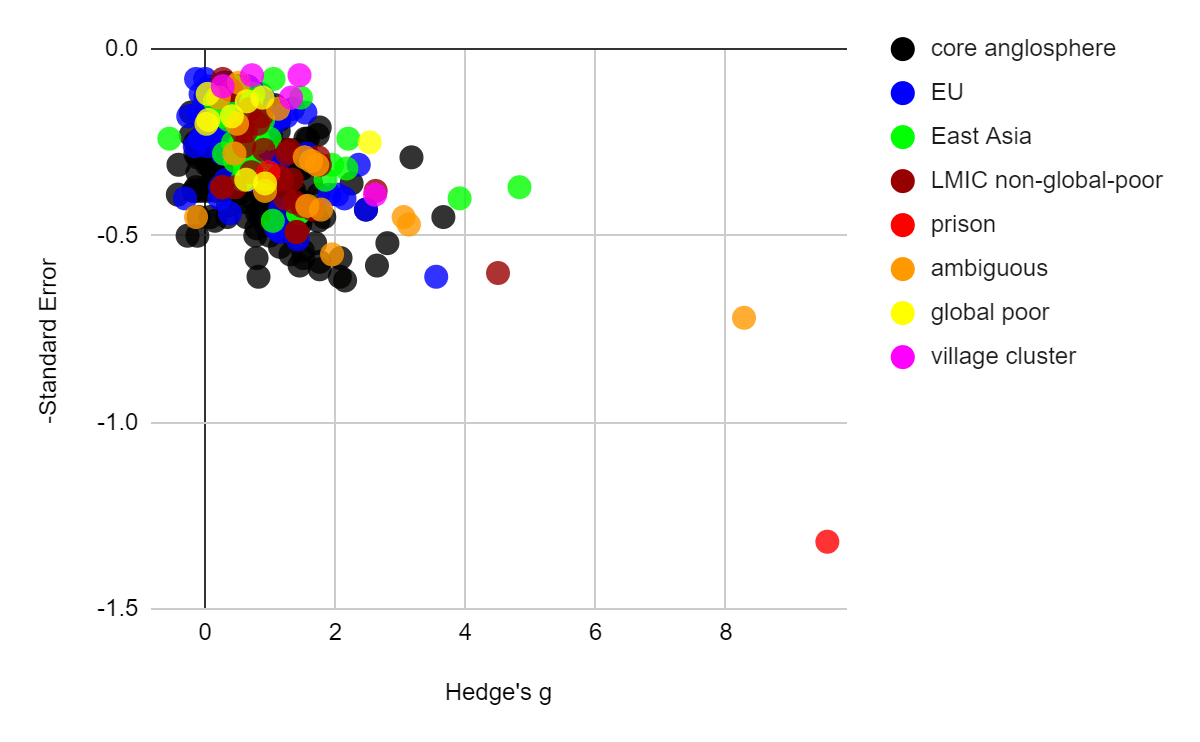
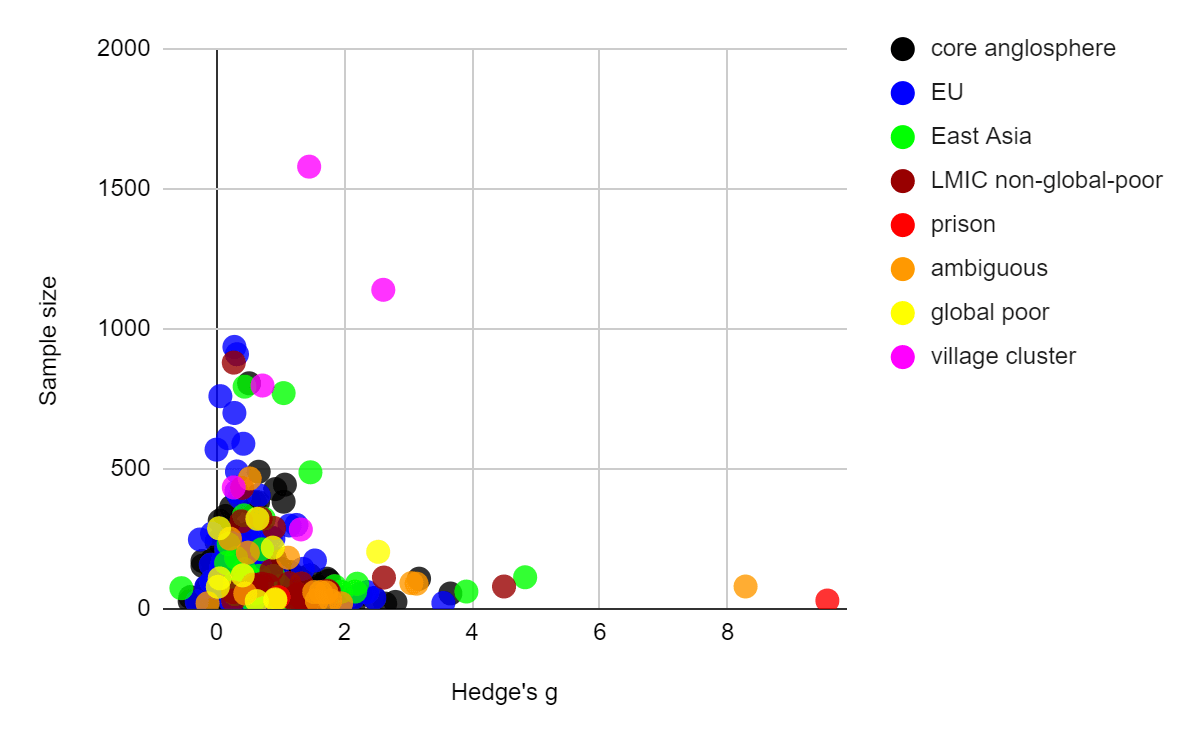
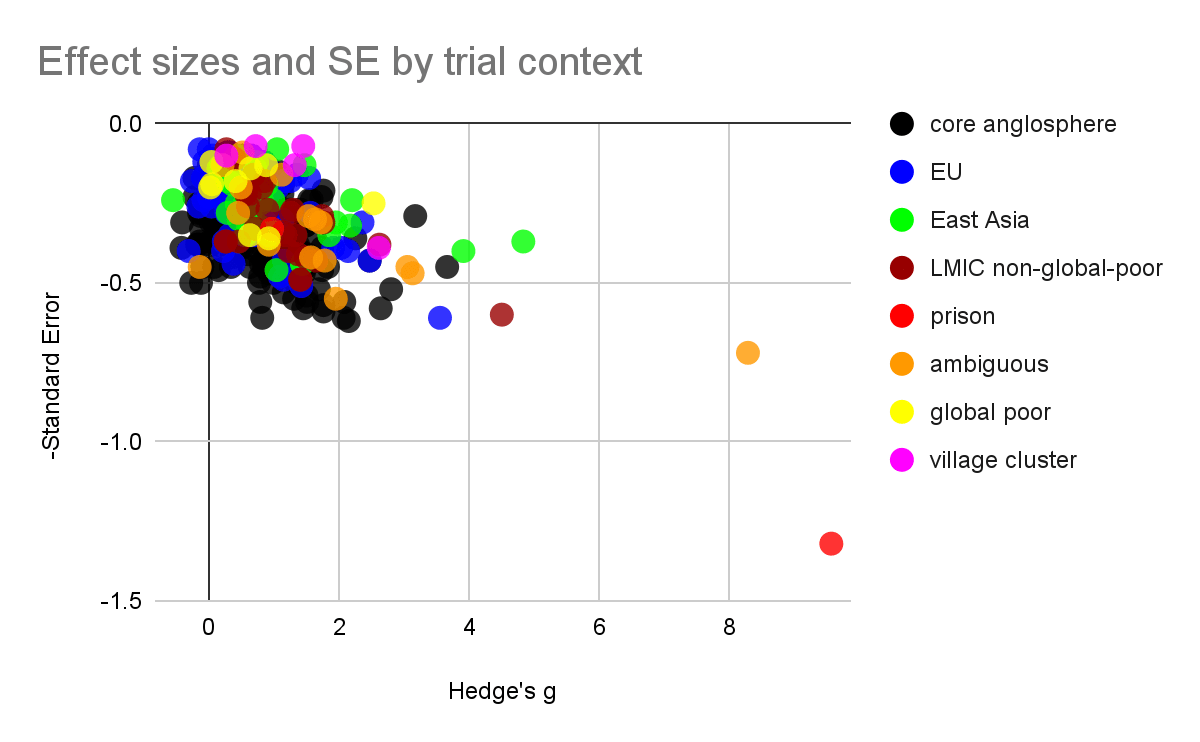
Figure: Effect sizes plotted[2] against standard errors (left) and sample sizes (right) for all psychotherapy interventions in the MetaPsy dataset. Populations within the "other countries" category are manually coded.
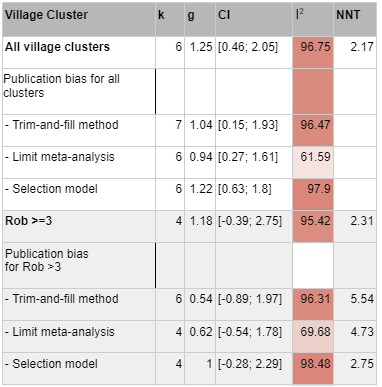
Data that was coded as "village cluster" represents studies that are highly similar to Bolton 2003, which take place among very rural village environments and which use a statistical method called "cluster randomization" which randomises villages rather than participants and generally treats villages as a random effect, which is thought to be well suited to socially close knit village environments
Data coded as "global poor", a category which also includes all village cluster studies, is either a highly rural village context, or if urban, contains descriptions such as "slum", "impoverished", and "low resource". Only low-income countries were coded this way, e.g. an impoverished urban setting in Brazil was excluded because Brazil is not a low income country.
Data that was coded as non-global poor[3] tended to mention "university", "family doctors", or expensive intensive care situations that the global poor likely cannot access.
Data that was coded "ambiguous" tended to say "clinic sample" without further description, and be located in regions which might plausibly house both rich and poor residents (e.g. big cities, or higher income regions like Goa)
Where the paper itself didn't make it clear, we made some subjective judgments about the wealth of participants in unfamiliar geographic locations by quickly reading about the neighbourhoods mentioned on Wikipedia.
Prison populations were excluded from "global poor" because the demographics were diverse. In each case the demographic descriptions of the prisoners revealed that some prisoners had advanced degrees, even while others couldn't read.
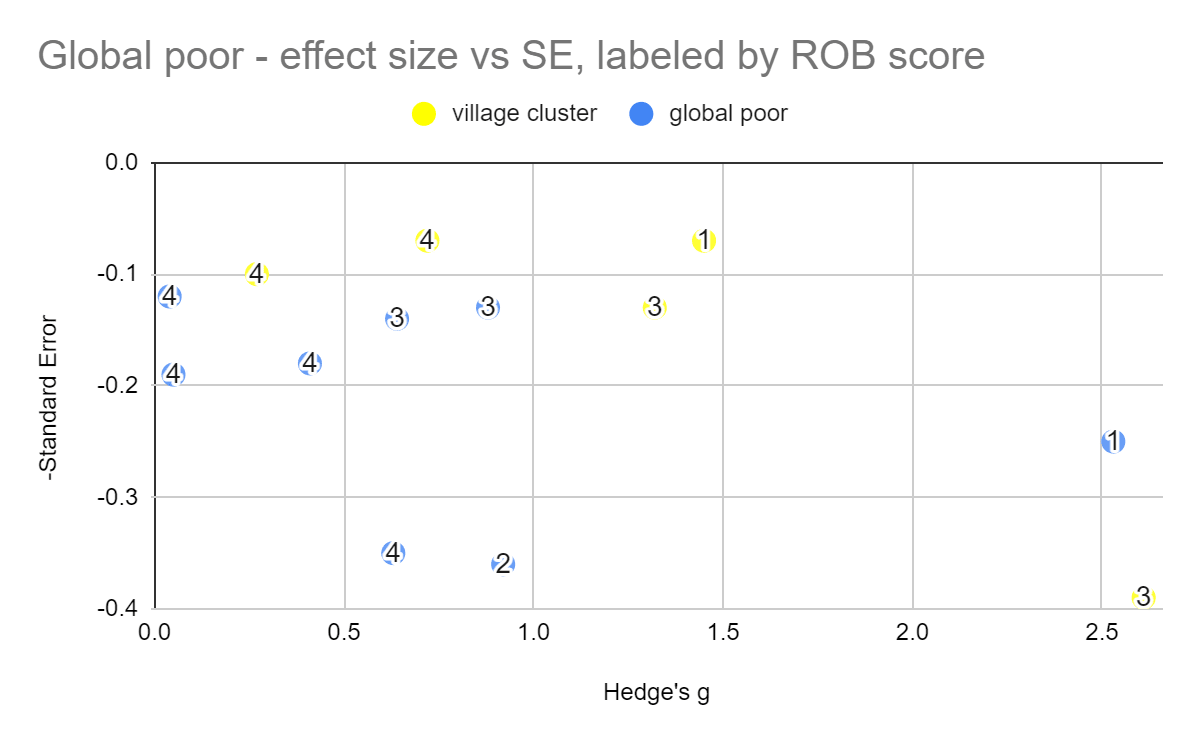
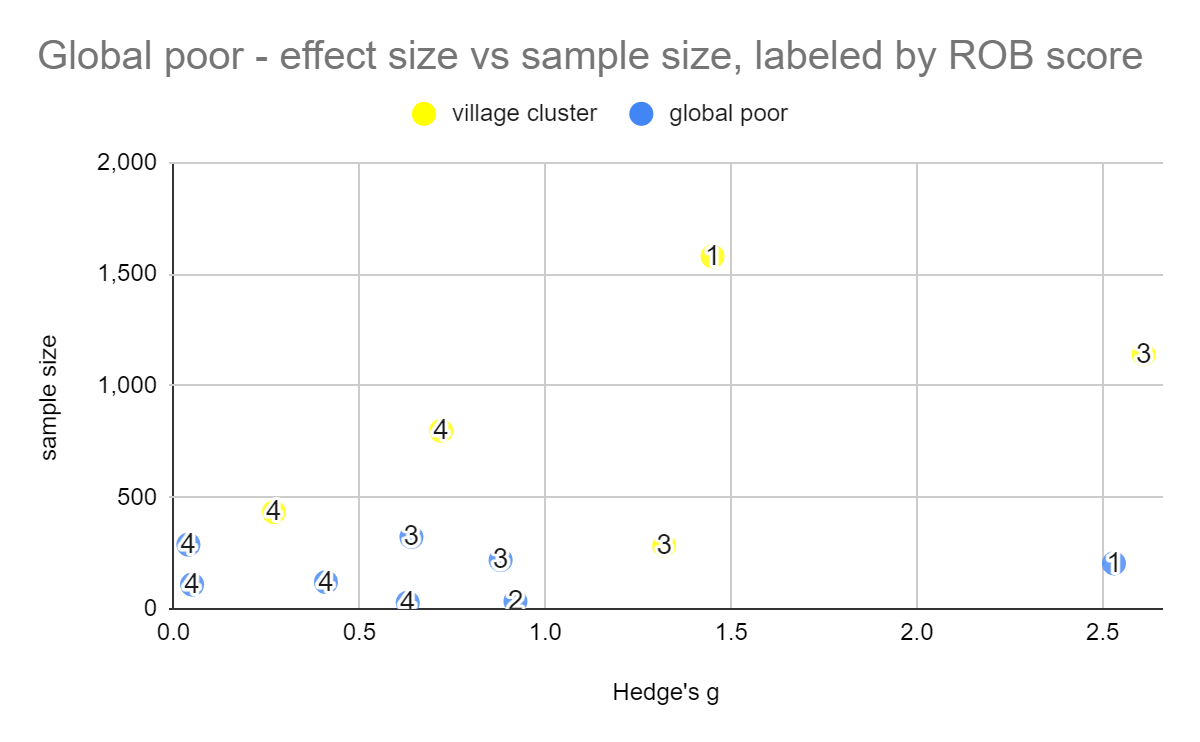
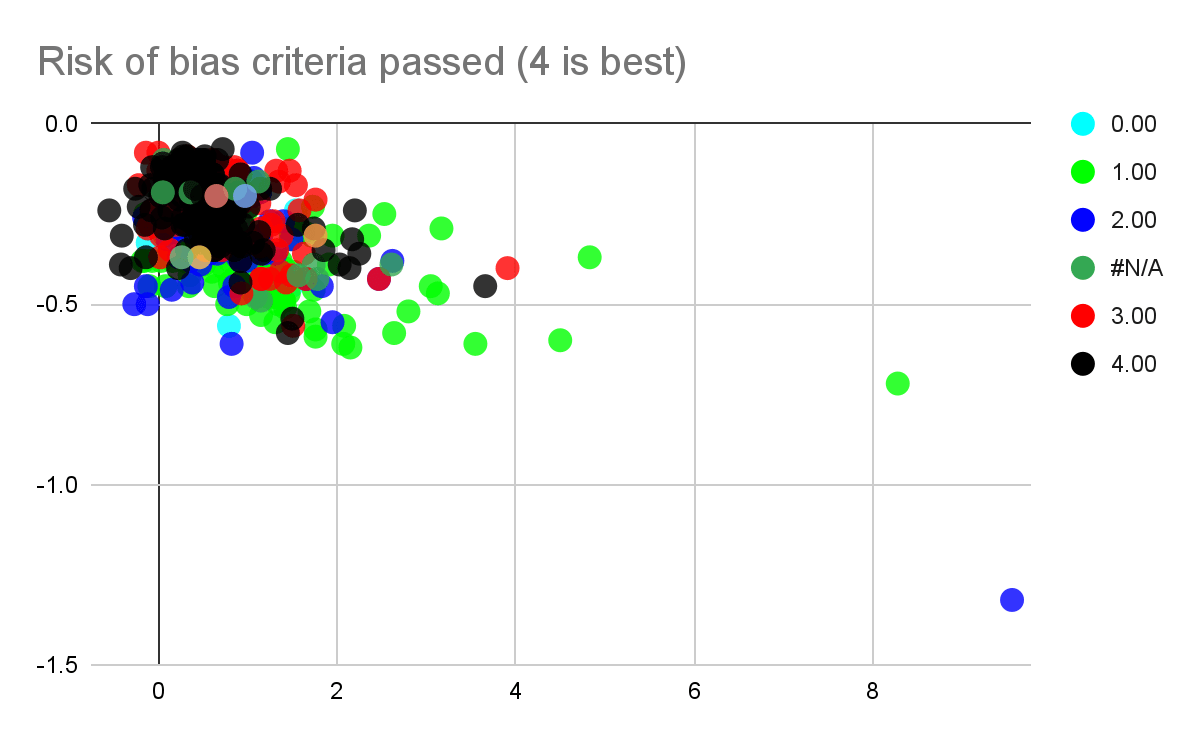
Figure: Effect sizes of studies pertaining to the global poor, against standard error (left) and sample size (right). Numerical labels represent Risk of bias scores (with 4 being the best score).
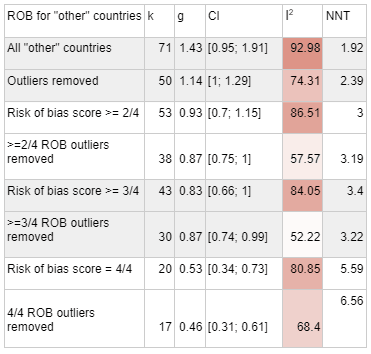
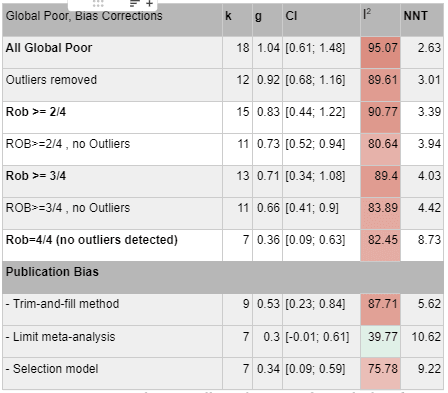
Our meta-analysis of the global poor had very few studies and was vulnerable to noise, even removing a single study would dramatically change the effect size, in part due to changing which studies were excluded as outliers. The heterogeneity stayed high. We'd consider this mild evidence that psychotherapy at least works for the global poor, rather than becoming ineffective, although we do note that a few ROB 4/4 studies did find null effects and we don't think this means that the possibility that psychotherapy doesn't work for the global poor can be completely ruled out.
We tried to do an even narrower analysis of village cluster studies only, but there were too few studies to do a meta-analysis for 4/4 risk of bias criteria met, so we don't think it's too meaningful other than to provide more slight evidence that the intervention does work in these settings.
Comparison of our work to bias corrections in academic Literature
We reviewed the academic literature to see what effect sizes other researchers arrived at, and how they corrected for various sources of bias.
The first[4] meta-analysis on the effect size of psychotherapy (Smith and Glass, 1977) looked at 500 controlled studies and found an effect size of 0.68 across all outcome measures. The outcome measures were unstandardized - some were based on self-reported symptoms and questionnaires and others of which were rooted in work or school performance, and most of the studies were not randomised trials. Based on their data, Smith and Glass concluded that all psychotherapies had roughly similar effect sizes, and there was no particular reason to suppose that one was superior to another.
Since that time, there has been a lot more information and analysis - including 400+ randomised controlled trials. However, aggregated unadjusted effect sizes tend to converge around the same numbers that Smith and Glass (1977) originally found. Large meta-analyses show similar unadjusted effect size. Further, there is still not much evidence that any type of therapy (such as cognitive behavioural, or psychodynamic, etc) is better than any other. Nor does it seem that any basic demographic characteristics (eg. age, gender, health-status…) particularly matter (Cuijpers 2017).
Unadjusted effect sizes from recent large meta-analyses
However, these effect sizes tend to get less optimistic when more scrutiny is applied. The largest meta-analysis on our list, Cuijpers, Karyotaki (2019), examined 359 studies, with an unadjusted effect size of g=0.7 ((95% CI 0.64–0.75). After excluding studies from non-western countries, the remaining 325 studies had an effect size of g=0.63 (95% CI 0.58–0.68). After excluding studies with waiting list control groups, the remaining 179 studies had effect sizes of g = 0.51 (95% CI 0.45–0.58). After excluding studies that did not get a 4/4 on the Cochrane risk of bias assessment tool, the remaining 71 studies had an effect size of 0.38 (95% CI 0.32–0.44). In the final analysis, after correcting for risk of bias, and publication bias, the effect size fell to g=0.31 (95% CI 0.24–0.38). We think this represents the most complete[5] meta-analysis on psychotherapy and depression to date. [Update: We have since become aware of Cuijpers (2023) , a more comprehensive meta analysis.]
publication bias corrected, western, non waitlist, 4 criteria
g = 0.31 (0.24–0.38) k= 84
81.58%
Vs western, non-waitlist, 4/4 RoB criteria
Figure: Cuijpers, Karyotaki (2019) displays how effect sizes systematically regress as increasingly stringent controls such as waitlist control exclusion, risk of bias assessments, and publication bias adjustments are accounted for.
Academic outlier correction: Most large meta-analyses do outlier correction. In MetaPsy, outliers are defined as studies with a 95% confidence interval which lies outside the 95% confidence interval of the pooled effect. We've also shown how the other two large meta-analyses fell in response to the outlier protocol their authors chose.
After correcting for outliers, the effect size for the METAPSY dataset falls in the middle of the range of effect sizes found in meta-analyses summarised by (Cuijpers 2017).
Unlike these academic analyses appear to, METAPSY handles outlier correction after risk of bias adjustments and other filtering criteria, and datasets with better risk of bias scores tend to have a smaller amount of outlier correction. This means that some studies are considered outliers within certain datasets but not others. For instance, the RCT that StrongMinds is modelled from, Bolton 2003, is considered an outlier relative to all studies. However, it is not considered an outlier when the sample is restricted to non-Western countries, and it becomes an outlier again among non-Western countries which meet >3 Risk of Bias criteria.
Academic correction for biassing study design variables - Risk of Bias and Control Groups: The following table illustrates how study design bias correction has been done in other academic literature.Cuijpers, Karyotaki (2019) also use Cochrane risk of bias criterion, and reported it in a similar manner as we did, so it's possible to see how the effect size drops as the study quality increases. The differences in the final numbers are due to a) restricting to Western samples b) restricting to non-waitlist controls.
An earlier paper, Cuijpers, A van Straten, et al (2010) argued that poor study quality may be inflating effect size. After comparing 115 studies totalling 8140 participants with an effect size of d = 0.68 (95% CI 0.60–0.76), they graded the studies according to 8 markers of quality: 1) patients were evaluated by strict diagnostic criteria for depression 2) the therapy used a treatment manual 3) the therapists were trained 4) the therapists were supervised or recorded 5) the study used intention to treat analysis 6) the study involved more than 50 patients 7) Sequence generation randomisation of patients was accomplished via third party assessor or a computer 8) blinding of assessors Only 11 studies met these criteria, with an effect size of d=0.22 (95% CI 0.13–0.31). Criteria 4 through 8 were found to significantly reduce the effect size, and after a post-hoc relaxation of the criteria to include only those four, the number of qualifying studies increased to 20, with an effect size of d=0.34, 95% CI 0.20-0.48. While we think the authors are rightly concerned about the trend towards higher study quality leading to lower effect sizes, because of the small number of studies that met the stringent quality criteria, this estimate is noisy.
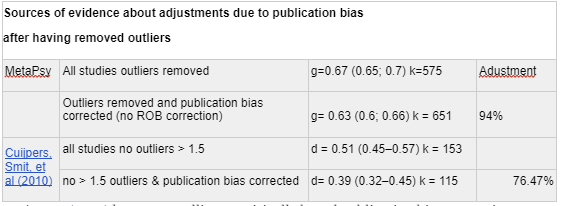
Academic corrections of publication bias: In line with most meta-analyses, Cuijpers, Smit, et al (2010) reported an effect size of d=0.67 (95% CI 0.60–0.76) when aggregating across 117 studies with 175 comparisons. However, this value fell to d=0.42 (95% CI 0.33–0.51) after adjusting for publication bias using Duval & Tweedie’s trim and fill procedure, with 51 comparisons excluded. These unadjusted and adjusted figures fell further to d= 0.51 and 0.39, respectively, after removing d>1.5 outliers. These findings suggest that most meta-analyses are inflating the effect size of psychotherapy.
Following up, Driessen (2015) used NIH grants awarded from 1972–2008 to identify unpublished RCTs and requested the data from the authors. Whereas the 20 included published studies had an effect size of g = 0.52 (95% CI 0.37-0.68), including six additional unpublished studies (g = 0.20; 95% CI -0.11~0.51) resulted in a 25% reduction to the point estimate (g = 0.39), but with notably wide confidence intervals (95% CI 0.08-0.70). This study was the justification for GiveWell's 75% publication bias adjustment.
While Driessen (2015) has a compelling empirically based publication bias correction methodology, their dataset mixes therapy vs no treatment trials with placebo controlled trials and head-to-head antidepressant and therapy-vs-therapy comparisons (See Driessen (2015), table 2) . We are therefore unsure whether the findings can generalise to our database of entirely therapy vs no-treatment trials. We also are concerned that the lower number of studies and the very wide confidence intervals (0.08-0.70) mean that the estimate is noisy and less reliable.
We can find an example of correction for both publication bias and study design (but not outliers) in Cuijpers, Karyotaki (2019), which we were also able to approximately replicate in MetaPsy (which likely uses the same dataset, but with some studies added).
Sources of evidence about adjustments due to publication bias after adjustments due to study design
publication bias corrected, western, non waitlist, 4 criteria
g = 0.31 (0.24–0.38) k= 84
81.58%
This adjustment is more optimistic than the one we used in our main model, because the comparison is restricted to western and waitlist controlled studies, whereas ours draws from studies from all countries using all control groups.
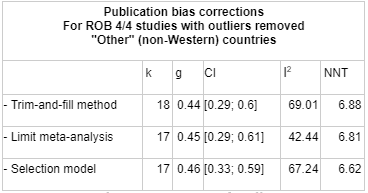
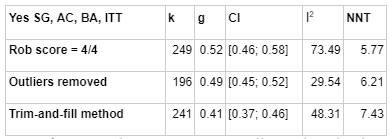
We decided to do publication bias corrections directly on the dataset, rather than try to estimate the discount due to publication bias from the literature. When restricted to studies which scored 4/4 on the risk of bias assessment, with outliers removed, doing trim-and-fill caused the effect size to drop from to, an adjustment.
How SoGive handled publication bias
Metapsy
Studies scoring 4/4 on ROB,
g = 0.0.52 (0.46- 0.58) k = 249
adjustments
Studies scoring 4/4 on ROB, outliers removed
g = 0.49 [0.45; 0.52] k=196
94%
Total
Studies scoring 4/4 on Rob, outliers removed, trim and fill
g = 0.41 [0.37; 0.46] k=241
84%
79%
Conclusions from review: Based on this literature, we concluded that in addition to Cochrane's risk of bias assessments and publication bias assessments which correct for small study effects, it was also important for us to look into the choice of control group.
After further analysis, we decided to keep all four of Cochrane's Risk of Bias assessments (most pessimistic choice), use trim and fill for publication bias correction (most pessimistic choice in most cases), and to include waitlist controls (more optimistic choice).
Which of our methodological choices are potentially controversial?
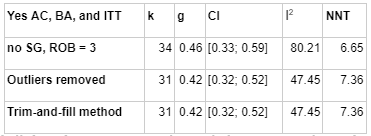
We asked Prof Pim Cuijpers, a leading expert in psychotherapy meta-analysis and a developer of the METAPSY database, to spend a few minutes quickly looking over our analysis. His overall impression (personal communication) was that our estimate was more pessimistic than the ones in academic meta-analyses. He said that if he were doing the analysis, he would not have excluded outliers (which we found would make the estimate more optimistic, but ultimately would lead to a more pessimistic result due to causing a more severe trim-and-fill publication bias adjustments), and would have excluded studies using waitlist controls (which would make the estimate more pessimistic). If we would have followed this advice, we would have found that the aggregate effect size of all non-waitlist controlled studies which passed all four risk of bias criteria was g=0.48, which fell to 0.34 after trim-and-fill.
[Update: See Cuijpers 2023 for the latest comprehensive meta-analysis on the effect size of therapy by Prof Cuijpers.]
Why we excluded outliers: MetapsyTools considers an effect size an outlier when it falls outside of the 95% confidence interval of the aggregated effect size. Excluding outliers involves repeatedly excluding and recalculating the aggregate effect size until no outliers remain. It's controversial to remove outliers in this way, without knowing the reason for the outlying result. We think this is a valid concern, but decided to remove outliers anyway primarily because failure to do so caused the publication bias correction tools to return implausible results, which we think is due to the outliers increasing heterogeneity.
Why we included waitlist controls: A waitlist-controlled trial is one in which the control group is promised care at a later date. Including waitlist controls is controversial because some consider them to create a "negative placebo effect", as patients may become frustrated with waiting, or may procrastinate seeking alternative forms of care. We decided to include waitlist controls anyway because our analysis suggested the real reason that waitlist controls have higher effect sizes is because the alternative, "care-as-usual" samples, tend to take place in clinical contexts where patients are receiving non-psychotherapy forms of care from medical staff which may nonetheless be therapeutic, and excluding clinical samples removes the disparity. We also don't think individuals in a low-income context are likely to get alternate forms of care or be inpatients at a clinic.
We also asked Dr. Gregory Lewis, who has been engaging with HLI's work on the EA forum to look over a draft of this document. He concurred with Prof. Cuijpers about excluding waitlist controls. He also suggested that maybe instead of doing a meta-analysis about the effect of psychotherapy, it would make more sense to go off of the direct evidence of the upcoming StrongMinds RCT, and that if the StrongMinds RCT didn't give a positive result, and if the internal evidence from StrongMinds and the evidence from Bolton 2003 (an RCT after which STrongMinds is modelled) was "too good to be true", we might stop the analysis and rule out this intervention.
In a somewhat related vein, when HLI estimated the impact of psychotherapy, they (optimistically, in our view) put more weight on direct evidence such as StrongMinds internal data and data from Bolton 2003, and from studies with "StrongMinds-like-traits" than they did on the general psychotherapy literature, whereas we haven't explicitly given any additional weight to direct evidence in this analysis.
Why we don't rely on more "direct evidence": We're sceptical of putting too much weight on a single RCT, whether positive or negative, even where it constitutes direct evidence.
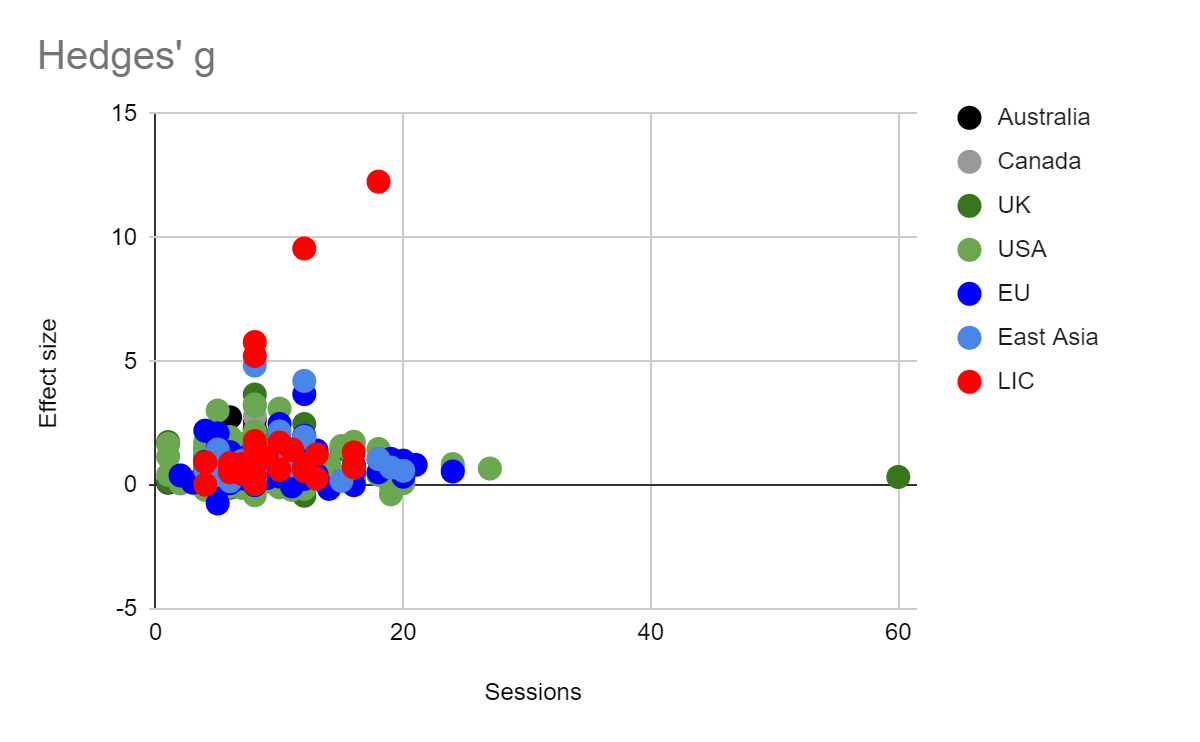
The figure above includes all effect sizes included in the meta-analysis, arranged by Hedge's g and standard error. On the left, they are colour-coded by trial context. On the right, they are colour-coded by study design factors. The range of effect sizes is implausibly wide, from negative 0.55 to positive 9.56. It seems a bit implausible that most of this variation reflects true underlying differences in the particular interventions that occurred, even after accounting for things like risk of bias, country, populations, or control group.
We're not sure what generates such wide variation, but seen from this perspective, we get the sense that a single study is incredibly noisy data. We hesitate to dismiss a promising intervention because a direct RCT fails to demonstrate an impressive effect, as well as to get too excited about interventions which are backed by promising RCT.
MetaPsy make use of four items on the Cochrane's Risk of Bias Tool. To see if it was possible to drop any of the factors, we checked what happened to the effect size when each one was missing while the others were present. We concluded that a lack of allocation concealment and a lack of intention to treat analysis was a particular concern, but all factors were important.
Sequence generation: Making sure that participants are allocated randomly to the treatment arm and the control arm.
RCTs which fulfilled all the other ROB criteria but failed at sufficiently random allocation didn't seem to have unusual results.
Allocation concealment: Concealing which patients are allocated to which arm (at least until the therapy starts and it becomes obvious) to prevent it from messing with enrollment, initial assessment, etc.
Among studies which otherwise met all other criteria, allocation concealment was the most commonly overlooked study design factor, and it seems to be associated with a large amount of bias.
Blinding of Assessors: If a human is assessing the patient outcomes, they should not know who got treated and who was in the control group, so that their evaluations are unbiased and they don't prompt the patient in any direction.
Nearly all studies which otherwise scored on the three other Risk of Bias assessments blinded assessors - only three comparisons were found which did not.
Intention to Treat analysis: When someone drops out of the study, their last assessment should be used to fill in the missing data, rather than removed. Dropouts from studies often are doing worse than non-dropouts, inflating effect sizes. Intention to Treat analyses creates a conservative assumption that any dropouts are counted as experiencing no no improvement at all.
Some studies did not do intention to treat analysis, and it represented a large source of bias.
Bolton 2003, the study which the StrongMinds intervention was primarily modelled on, failed to do allocation concealment, but did pass all other Risk of Bias criteria, for a total score of 3/4. We're not as experienced at grading papers on Risk of Bias criteria, but as far as we can tell the internal StrongMinds phase 1 and phase 2 and followup evaluations do not pass any of the risk of bias criteria (they explicitly don't do intention to treat analysis, and implicitly don't mention anything that would allow us to confirm that they pass the other criteria), for a total score of 0/4. We aren't basing our estimate off of these more direct pieces of evidence, so this doesn't impact the headline findings of this document. We will publish a separate document evaluating more direct sources of evidence for StrongMinds in more detail.
We think that it's reasonable to restrict ourselves to studies that meet all four risk of bias criteria. With respect to the first three criteria, proper randomization and blinding of participant and assessor seem uncontroversially necessary. We were initially most uncertain about intention to treat, but decided that it was also necessary.
Does intention to treat analysis skew towards pessimism? (likely no): Intention to Treat Analysis (McCoy, 2017) is when subjects in the treatment group are counted regardless of whether they actually received the treatment, as opposed to a "per-protocol analysis" where only treated subjects are compared to controls and the data from subjects who did not actually do the intervention is removed. The purpose of Intention To Treat Analysis is to avoid the problem where dropouts systematically differ from people who continue on with treatment, typically in ways that correlate with worse outcomes. Since the control group does not similarly "drop out", this ruins the randomization element of a controlled trial and artificially inflates effect sizes.
We were initially worried that because StrongMinds reports cost per person treated (rather than cost per person who signs up for treatment), that this would artificially deflate effect sizes, especially where dropout is high. In Intention to Treat analysis, where patients drop out and it is impossible to get post-treatment data from them, their pretreatment data is used as post-treatment data. We worried that this would create extra-conservative assumptions where not only would the treatment have had no effect, but that any spontaneous improvement would not have shown up in the dataset, which would cause them to be modelled as doing worse than the control group. However, we don't have evidence for this worry, and seeing the lower effect sizes in placebo-controlled trials (which may offer a more like-to-like comparison on dropout rates between treatment and control) and thinking in more detail about factors that could lead to potential inflation in apparent placebo lead us to believe that the pessimism of intention to treat analysis is mostly justified. (This is discussed in more detail in the section on placebo effects). Either way, the alternative - per-protocol-analysis skews very optimistic, which isn't acceptable.
Methodologies for estimating publication bias and small study effects
Duval and Tweedle trim and fill: this is the most widely used method, which detects funnel plot asymmetry, and then imputes in the data that it predicts would have been published without publication bias to calculate what the effect size would have been.
Limit meta-analysis: This method accounts only for small study effects, not publication bias per se
Step function selection model: Operates on the assumption that studies with p<-.1 are more likely to get published
None of these methods provide valid results when between-study heterogeneity is high, but eliminating outliers to reduce the heterogeneity can be a practical workaround. (Harrer, 2021)
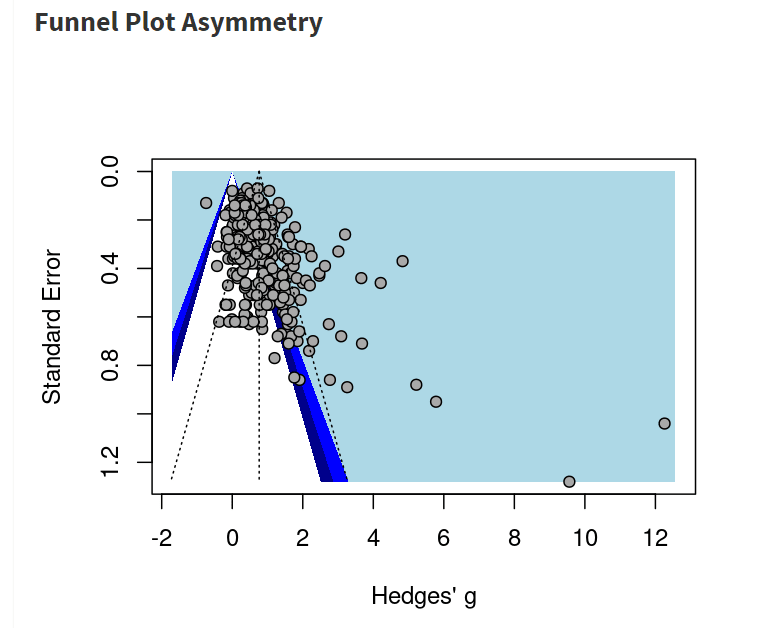
Figure: A funnel plot of all studies generated by MetaPsy. The shape of the data strongly suggests the presence of both unrealistic outliers and of publication bias. Duval and Tweedle's trim and fill can impute data on the other side of the funnel.
Pictured below are the three possible publication bias corrections with different levels of stringency in risk or bias correction, with outliers removed. Studies which had more risk of bias weren't particularly more susceptible to publication bias. Note how dropping outliers and increasing risk of bias stringency tends to decrease the heterogeneity
We went with the trim-and-fill method when reporting our headline result primarily because it gave the most conservative answers, in addition to being the method that most people are familiar with.
Failure to remove outliers tended to cause all the different publication bias methods to give wildly different results, presumably in part because the methods break down if heterogeneity is high. We think such results aren't meaningful. We ran a large variety of meta-analysis combinations involving Risk of Bias x Publication Bias (as well as all combinations involving different countries, control groups, and other factors) which informed our overall intuitions about this. We've placed one example here to demonstrate how the three methods start diverging.
Why we didn't restrict to non-waitlist control groups
One of the particular challenges in psychotherapy effectiveness research is deciding what constitutes an appropriate "control" group.
A "waiting list control group" is when the control group is promised care at a later time than the intervention group. Cuijpers (2017) says that "Waiting list control groups typically have the largest effect sizes (usually g > 0.8)" Critics of waiting list control groups argue that they inflate the difference between intervention and control groups, perhaps creating negative placebo (Furukawa, 2014), or because promising future care actively encourages the control group to procrastinate seeking forms of treatment that they may have otherwise counterfactually acquired.
"Care-as-usual" describes the situation where patients are not waitlisted and receive whatever care they would normally receive otherwise. "Care-as-usual has an effect size of about g=0.5" (Cuijpers, 2017).
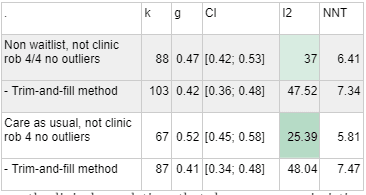
If we had chosen to exclude waiting list controls or restricted ourselves only to care as usual, our data would look a bit more pessimistic:
.
k
g
CI
I2
NNT
Non-waiting list, ROB 4/4 outliers removed
133
0.42
[0.38; 0.47]
33.36
7.27
- Trim-and-fill method
164
0.34
[0.29; 0.39]
53.23
9.21
Care as Usual rob 4 outliers removed
102
0.46
[0.41; 0.51]
33.87
6.61
- Trim-and-fill method
131
0.36
[0.3; 0.42]
53.08
8.57
However, what constitutes care-as-usual "varies considerably across settings and health care systems, making comparisons very heterogeneous" (Cuijpers, 2019, page 22). For example, studies on inpatient settings find effect sizes of g = 0.29 (95% CI 0.13 - 0.44), and studies of primary care patients find effect sizes of g=0.31 (95% CI 0.17 - 0.45), and Cuijpers (2017, page 11) speculates that this is because in this context, "usual care…typically involves quite intensive care in inpatient settings, including psychological support and therapy".
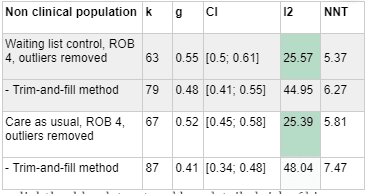
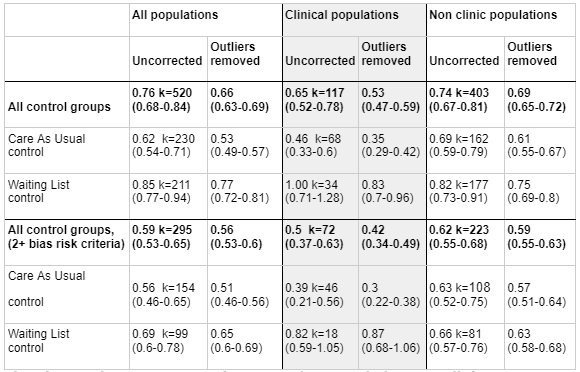
We think that this explanation is likely true, because when we exclude clinical samples, restricting waiting list controls or using only care as usual control groups stops looking pessimistic. In other words, it is mostly clinical populations that show more pessimistic effect sizes when waitlists are excluded or the sample is restricted to care as usual. We think that this is evidence against the hypothesis that being placed in a waiting group control group has a negative effect on patients - it seems more likely that the difference is only that "care as usual" means something better in a clinic sample contexts where lots of caregivers are pleasant.
In non-clinical populations, the difference between waiting list and care as usual controls is much smaller, compared to the very large gap in clinical populations.
Here's a table using a slightly older dataset and less detailed risk of bias correction that illustrates the point[6]. The clinical populations show a big difference between care and usual vs waitlist, but the non-clinical populations don't show much difference between the two.
Based on these findings, our guess is that waiting list controls don't actually have a negative effect on patient populations. Therefore, we think it's reasonable not to exclude waiting list control groups when we aren't looking at a clinic sample, especially when we are estimating impact for a population where their options for "care as usual" would likely be slim. If we are wrong about waitlist controls not having a negative effect, or if waitlist controls have higher effect sizes for some other reason, we would need to revise this.
Navigating real and apparent placebo effects in psychotherapy
The placebo effect refers to when psychological factors related to a person's expectations have a causal impact on their treatment outcomes. Studies generally account for this by giving control groups a placebo, in an attempt to hide from subjects whether or not they have received a real treatment. However, not all improvement which occurs in a placebo controlled trial should be considered a placebo effect.
Figure: Dumbo the elephant holds a "magic" feather, which the crows have claimed will allow him to fly. In reality, the feather is not magical, but belief in the magic feather gives him the confidence to take the leap and fly using his oversized ears. However, Dumbo may have eventually figured out how to fly even without the placebo feather - other factors are at play.
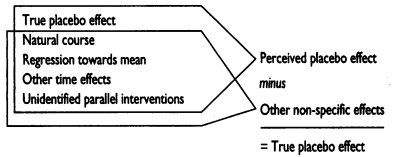
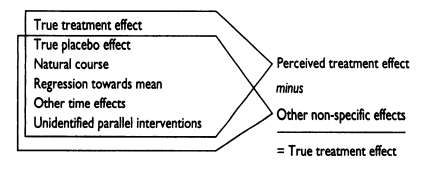
What seems like a placebo effect is generally a combination of the true placebo effect, and various other factors which would have happened to the control group regardless of the placebo effect.
A figure by Ernst (1995) demonstrates how true treatment effects can be found by subtracting the effect of true placebo as well as other non-specific factors which may influence the control group.
Having "placebo" control groups is a good practice for more reasons than just accounting for placebo effects. For example, there may be
Selection effects: The demands of active participation in therapy may have selection effects that the demands of being in a passive waitlisted or care-as-usual control group do not. We do think that with the assumption that study dropouts are sicker than study completers, and with the assumption that placebo adherence would be lower than waitlist adherence, intention-to-treat analysis adequately corrects for such selection-effects in a manner that errs towards pessimism, as fewer dropouts in the control group would only makes estimates more pessimistic.
Better blinding: It's difficult to fully blind experimenters and participants for the duration of the experiment - people may feel the effects of psychoactive medications, or guess at whether they are getting a sham therapy. But active placebos may help improve blinding, both for the experimenter and the participant.
Other sources of bias which are not yet well understood by researchers, which might go away when you go through the motions of putting the control group through active placebo.
In 2009, a then-controversial meta-analysis by Kirsch and Sapirstein raised the possibility that only 25% of antidepressant drugs effects were genuinely due to the drug, with 25% being due to active placebo and 50% being due to other non-specific factors (Kirsch 2009). More recent meta-analyses regarding placebo effects suggest similarly large placebo effects for psychotherapy.
Sources of evidence about placebo effects in depression
A meta analysis of ten studies by Cuijpers, Turner (2013) suggests that comparing therapy to pill placebo has an effect size of 0.25 (95% CI 0.14–0.36, 10 studies), which fell to g = 0.21 (95% CI 0.10–0.32, 8 studies) after Duval & Tweedie’s trim-and-fill procedure. Though caution must be used in generalising from such a low number of studies, this suggests that against pill-placebo, therapy has an effect comparable to antidepressants, an idea which is supported by head to head comparisons between therapy and antidepressants and finding them equally effective (Cuijpers, Sijbrand 2013) - but see Cristea (2017) regarding how excluding studies with conflicts of interests tied to pharmaceutical companies significantly shifts this result to g=0.10 (95% CI 0.09 to 0.29) in favour of psychotherapy.
How much of a placebo effect should we expect in the treatment of depression? A meta-analysis by Fernández‐López (2022) comparing active placebos (sham pills and sham psychotherapies) with passive controls (usual care or no treatment) showed an effect in favour of placebo (25 studies, g =0.24, 95% CI 0.06–0.42) for all disorders, as well as for depression specifically (9 studies, g = 0.22, 95% CI 0.04–0.39). However, the studies had high risk of bias[7] and heterogeneity, so these results should be interpreted with caution.
Related to the concept of "sham psychotherapy", the experimenter allegiance effect is the impact of the experimenter being invested in and believing in a specific type of therapy and either delivering it or supervising the delivery of it. Dragoti (2015) estimated that the relative odd's ratio of the experimenter allegiance effect is 1.31, which corresponds to an effect size of ln(1.31)/1.81=0.15 Chin (2000). That's when "real" psychotherapies, one of which the therapist or their supervisor is more invested in than the others, go head to head.
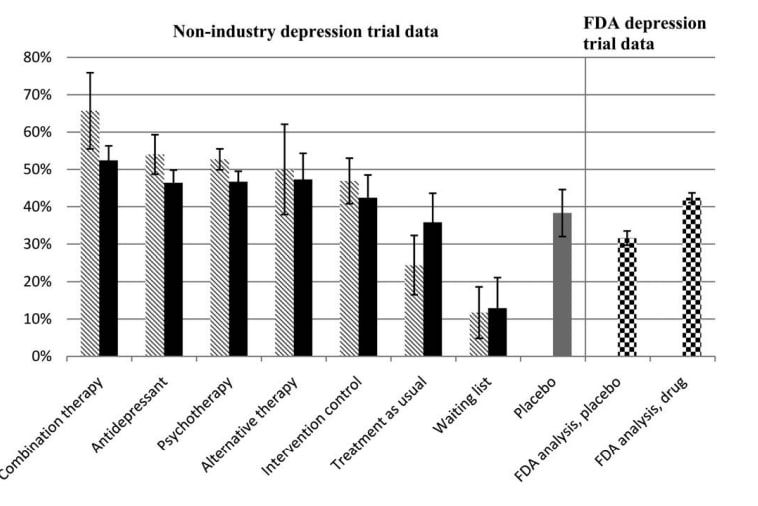
Figure: Khan (2015) charts the remission rates of various interventions against depression, in an article which gives a high level overview of antidepressants vs placebo.
It's difficult to know the contribution of genuine placebo effect vs forms of bias to these figures. It's also important to bear in mind that whereas our estimate of effect size of therapy has gone through numerous bias-correcting adjustments, measures of placebo have not.
We've attempted to map out what each of these sources of evidence are probably pointing to, but we consider this highly speculative.
In accounting for placebo effects in psychotherapy, we note that there are some interventions where placebo controls are used (such as deworming, malaria chemoprevention) and some in which they are not (such as cash transfers and malaria nets, although the effects of insecticide treatment on malaria nets are evaluated along untreated or "placebo-treated" control nets). One might imagine that an intervention aimed at reducing mortality needs no placebo controls, but apparent "placebo effects" can have striking and large effects on mortality - see review by Wilson (2010). Therefore, the question of when accounting for placebo effects is appropriate may need to be made somewhat on a case by case basis, to ensure like-to-like comparisons.
Social desirability bias
We were not initially planning on including social desirability bias in our assessment, but after seeing that GiveWell included an adjustment on it, we did a very brief overview of the literature in order to form a view on it.
Social desirability bias traditionally refers to the phenomenon where a research participant changes their self report based on which response might be viewed more favourably by others.
In GiveWell's adjustment, there were some more specific concerns raised about participant conflict of interest raised under this heading in footnote 52.
One concern was that the participant may inflate their self-reported subjective well being after the trial in order to reward the therapist who has put effort into helping them. We think that this is partially but not completely addressed by blinding assessors - if the assessor does not know whether the participant got the treatment, or if the assessor is a machine, there is less social pressure on the participant to act like they have been helped. Blinding assessors is one of the four items included in MetaPsy's Cochrane's risk of bias assessment, so we consider this concern partially but not wholly accounted for.
Another concern was that participants would inflate well being in order to prove treatments effective, if they believe in the treatment and are told that the control group will only receive the treatment if it proves effective. We don't think it's typical for participants to be told this, but to the extent that this is a problem, it's possible that active placebo may control for this, to the extent that participants are tricked by placebo and wish to reward it or prove it as correct. But the sparseness of placebo data and the difficulty of untangling genuine placebo-effects (which reflect genuine improvement due to therapy and so might morally "count") from pseudo placebo effects such as this, make it difficult to know for sure. We don't consider this concern accounted for.
A third concern was that the participant may inflate their self-reported depression before the trial in order to be included and receive treatment. We think that If participants are adequately blinded, in theory this should influence both intervention and control equally at baseline, and post-intervention this conflict of interest should disappear, and so both the intervention and the control group should be equally inflated. Adequate blinding is one of the four items included in Cochrane's risk of bias tool, used by the MetaPsy database, so we consider this concern fully accounted for in our analysis.
We did a very quick, non-systematic skim of the literature on social desirability bias. Here is what we found:
Luciano (2011) found no meaningful difference in scores on Marlowe-Crowne Social Desirability scale between responders (mean = 20.58, sd - 5.05) and non-responders (mean = 19.70 sd = 4.18) to psychoeducation therapy for fibromyalgia. This study constituted the most direct measure of what we are looking for - whether people are more likely to behave as "responders" due to social desirability bias when being given psychotherapy - and found that they didn't.
McCarney (2007) shows that intensive clinician follow ups had a very slight negative effect on participant-rated quality of life among Alzheimer's patients (short assessments at months 0 and 6 vs comprehensive assessments at months 0, 2, 4, 6). This would suggest that mere attention doesn't improve quality of life ratings. However, these interactions consist of doctors doing cognitive tests on patients rather than giving them therapy, so patients may not appreciate it as much. There was also a slight improvement in an objective (non-self report) cognitive assessment, but this is confounded by more practice in the comprehensive group.
Reese (2013) shows that client's ratings of therapist performance were correlated with measures of "therapeutic alliance" (how much they like the therapist), but not to social desirability bias scales. Sabourin (1989) and Gaston (1992) also affirm that client ratings and social desirability scales have negligible correlation.
A meta analysis by Berkhout (2022) finds the Hawthorne effect (observer effect) has an odd's ratio of 1.41 (95% CI: [1.13; 1.75], but that this disappears in "well designed RCTs or quasi-experimental studies" .
These findings make us a bit sceptical that social desirability bias could have effects large enough to justify an 80% adjustment even after accounting for risk of bias in the ways that we have already done.
There are lots of factors that surprisingly, may not matter
The remaining sections will discuss the factors that we looked into but didn't include in our analysis due to lack of sufficient evidence that they matter. Some of these factors are surprising - there isn't much evidence that type of therapy, therapist experience, and most patient demographic variables make any difference. All therapy modalities seem to be somewhat equivalent, with the caveat that therapy which uses apps and books may be more effective if there is a person there to guide and occasionally check in with the client to provide support and accountability.
That said, it's possible that some of these do matter, but that the existing research hasn't been high powered or sophisticated enough to measure it. For instance, we weren't even able to find strong evidence from the existing literature that the number of therapy sessions or amount of time spent in therapy matters - even though common sense suggests that this obviously has to matter. A meta-analysis byCuijpers, Cristea (2019) of studies which attempted to break down therapies into component parts suggests that "The currently available component studies do not have the statistical power nor the quality to draw any meaningful conclusion about key ingredients of psychotherapies for adult depression".
The factor for which the most convincing evidence has been collected seems to be that the client likes the therapist. Due to the finding that most types of therapies have comparable effects, attempts have been made to figure out which factors common to all therapies are important. Though various frameworks have been made, according to a review by Cuijpers, Reijnders (2019), "no common or specific factor … can be considered an empirically validated working mechanism". However, "of all the common factors that have been proposed, the therapeutic alliance or therapeutic relationship is championed by many as the most important". The term "therapeutic alliance" means, roughly, "does the patient like the therapist". A meta-analysis by Flückiger (2018) found that the therapeutic alliance correlates with good outcomes at r = 0.278 (95% CI 0.256 - .299) for face to face therapy and r = .275 (95% CI 0.205 - 0.344) for internet-based teletherapy.
Our takeaway is that the beneficial effects of therapy probably derive from the client going through some sort of systematic process to feel better, whether that be talking to someone who they like regularly, working through a therapy book with occasional check-ins, or attending a large group meeting, and that not much else about what works is known behind that.
In excluding these factors, we diverge from HLI's analysis, which considered therapies with "Strong Minds-like-traits"- interpersonal group psychotherapy studies involving a higher percentage of women, administered by lay counsellors rather than trained psychotherapists- to hold higher weight. This decision might have made HLI's analysis more optimistic, because these studies had higher effect sizes, which we suspect is probably due to risk of bias factors in study design rather than a true effect.
GiveWell gave StrongMinds analysis a pessimistic 75% adjustment in anticipation of lower implementation quality outside of trial contexts. We agree with some aspects of this logic - we did give a 79% adjustment for lower session number - but given the conspicuous absence of evidence for any benefits on therapist training, experience, or any specific technique over any other, we suspect that considerations such as how exactly the lay counsellors are trained aren't too important.
Meta-regression of therapy type, modality, gender produced no significant results
After filtering for passing 4/4 criteria for risk of bias in study design, we did a meta-regression comparing all therapy types, modalities, and gender and found that only one result - using "life review therapy" reached significance (P>0.05). We don't think that this is because life review therapy is better, this is most likely due to running multiple comparisons. Running the meta-regression without filtering for risk of bias produces stronger effects, but only the "life review" and "other" categories reach significance. We've displayed the meta-regression results for variables of interest related to StrongMinds in the table below.
All studies, outliers not removed
estimate
95% CI lower
95% CI upper
df
p
intercept
0.9923
0.2329
1.7518
797
0.0105
%women
0.0003
-0.0038
0.0045
797
0.88
Group therapy
-0.1224
-0.8601
0.6153
797
0.7447
Telehealth
-0.3835
-1.1567
0.3897
797
0.3306
Interpersonal Psychotherapy
-0.1928
-0.4745
0.0888
797
0.1794
All studies, Outliers not removed, All four Risk of Bias criteria passed[8]
estimate
95% CI lower
95% CI upper
df
p
intercept
0.6066
0.3508
0.8624
234
< .0001
%women
0.001
-0.0038
0.0057
234
0.6823
Telehealth
0.1374
-0.1729
0.4477
234
0.384
Interpersonal Psychotherapy
-0.3664
-0.7743
0.0415
234
0.0781
Therapy modality (e.g. group therapy vs tele-therapy vs bibliotherapy…)
Therapy can be delivered in a variety of formats. For example, StrongMinds offers in person group therapy as well as telehealth programs, while other organisations such as Canopie and Talk-It-Over chatbot offer app-based solutions. Some modalities are dramatically cheaper than others, so it's helpful to know how well each modality works.
We don't think therapist training or experience matters much: Experienced therapists do not appear to be better than inexperienced therapists. The most recent paper on therapist experience, Leon (2005), finds that therapist prior experience may help when their patients are clinically and demographically very similar and not spaced too far apart, but this is an exception to the general trend in the literature. An excerpt from the review:
"As part of the classic meta-analysis by Smith and Glass (1977) demonstrating the overall effectiveness of psychotherapy, these researchers examined whether years of experience as a therapist correlated with outcome. The authors found that years of experience correlated -0.01 with effect size (Smith & Glass, 1977). In their 1980 meta-analysis of 485 studies, the correlation was again zero (Smith, Glass, & Miller, 1980). Shapiro and Shapiro (1982) conducted another meta-analysis in response to the criticisms made of the meta-analyses of Smith et al. Sample therapists had an average of three years of experience. Despite improvements in their meta-analysis, these researchers again failed to find a correlation between years of experience and effect size. After multiple studies suggesting that experience plays a minimal to non-existent role in psychotherapy outcome and the inability to effectively criticize this literature (Nietzel & Fisher, 1981), therapist experience as a research topic has waned in popularity. Some recent evidence suggests that experience effects can be found under more controlled treatment conditions that use treatment manuals and homogenous patient samples (e.g. Blatt, Sanislow, Zuroff, & Pilkonis, 1996; Hupert et al., 2001). However, the majority of the extant literature still points to a null effect for experience"
We think that the fact that neither a therapist's level of experience nor the school of therapy that they apply seem to influence patient outcomes in easily measurable ways is optimistic news for the viability of using trained laypersons, peers, and volunteers to deliver psychotherapy of similar quality.
A meta analysis by Connolly (2021) found an effect size of g = 0.616 (95% CI 0.366 - 0.866) for therapy using lay counsellors. A meta analysis by Karyotaki (2022), which used some but not all of the same studies, found an effect size of g = 0.48; 95% CI, 0.26-0.68; P < .001), which fell to g= 0.32 (95% CI 0.26 to 0.38) when they did an individual patient data meta-analysis (which extracts raw patient data rather than summarising effect sizes, and is therefore higher quality). Both meta-analyses reported low risk of bias and no evidence of publication bias.
Group Therapy is probably comparable to individual therapy: The MetaPsy database reports higher effect sizes for group therapy over individual therapy, though we are hesitant to draw conclusions from this as our meta regression did not show a significant difference.
METAPSY Therapy Modality
Uncorrected
No outliers
3+ risk of bias criteria met
3+ criteria; no outliers
Group
0.91 k = 162 (0.77-1.05)
0.77 (0.71-0.83)
0.75 k = 68 (0.59-0.91)
0.65 (0.58-0.72)
Individual
0.69 k = 185 (0.58-0.79)
0.61 (0.56-0.67)
0.51 k = 104 (0.41-0.61)
0.46 (0.4-0.52)
Guided
0.58 k = 106 (0.51-0.65)
0.6 (0.55-0.65)
0.54 k = 83
(0.47-0.62)
0.55 (0.49-0.6)
Unguided self help
0.35 k = 7 (0.05-0.66)
0.35 (0.05-0.66)
0.39 k = 6 (0.06-0.71)
0.39 (0.06-0.71)
Telephone
0.7 k = 20 (0.43-0.96)
0.54 (0.37-0.72)
0.96 k = 9 (0.46-1.46)
0.89 (0.48-1.31)
In the academic literature, there is one meta-analysis suggesting that group therapy, which is used by StrongMinds, were somewhat less effective (Cuijpers, P., van Straten, 2008), but as it was written a long time ago it drew from only 15 studies.
Overall, our main takeaway from this is that there's a conspicuous lack of evidence to suggest that group therapy is worse than individual therapy, which is important because group therapy can be delivered at much lower prices.
Guided self help - the evidence is sparse, but promising: A meta-analysis by Cuijpers (1997) found an effect size of 0.82 (95% CI 0.50-1.15) for bibliotherapy, but using only six studies and with no risk of bias quality assessments or analysis of publication bias.
A meta-analysis by Andrews (2010) found an effect size of g = 0.78, (95% CI 0.59–0.96) for computerised cognitive behavioural therapy on depression, and meta-analyses of head to head comparisons between internet based cognitive behavioural therapy therapy with face to face cognitive-behavioural therapy on mental health disorders have found no difference (Cuijpers, Donker, 2010; Carlbring, 2017; Anderson, 2014))
However Anderson (2009) reports that computerised CBT works better when it's paired with some form of personal support, finding d = 0.61 (95% CI: 0.45–0.77) for "supported" treatments and d = 0.61 (95% CI: 0.45–0.77) for "unsupported" treatments (d= 0.41; 95% CI 0.29–0.54 for all studies).
Qualitative interviews of 36 patients undergoing computerised therapy by Knowles (2015) reveal that 10 were negative, 17 were neutral, and 9 were positive about their computerised therapy experience as compared to a traditional therapist-led experience. Negative reviews cited a lack of accountability making it easy for them to not do it, feeling like being on a computer was work, a lack of warm companionship, and a lack of customised personalised touch. Positive reviews cited greater privacy, more autonomy, and better control over session timing and length.
Patient characteristics (diagnosis, gender etc) and therapy effectiveness
Diagnosis matters: As summarised in Cuijpers (2017) page 12, patients with subthreshold depression tend to receive less benefit (g 0.35; 95% CI [0.23, 0.47], which is unsurprising due to their being less room for improvement".
Patients with chronic (2+ years) depression and dysthymia also tend to benefit less (g 0.23; 95% CI [0.06, 0.41]), and these patients responded better to antidepressants and combination treatments. Cuijpers (2017) mentions that this finding is "fully attributable to dysthymic patients." Dysthymia refers to long-lasting but mild depression often accompanied by bouts of major depression, rather than an active bout of major depression, so this might mean they may also have less room for improvement.
Gender and race likely don't matter: Demographic factors such as race (Ünlü Ince, 2014), gender (Cuijpers, Weitz, 2014), age and medical status (Cuijpers 2017 page 11) do not appear to make a difference to the efficacy of psychotherapy.
Study inclusion criteria matters: As mentioned in the discussion control groups, studies on inpatient and primary care patients find lower effect sizes, but it is speculated because the control group receives intensive care rather than because of underlying patient characteristics (Cuijpers, 2017, page 11).
Therapy type (CBT vs psychodynamic vs DBT etc) may not matter
There are many forms of psychotherapy, each with different schools of thought and systematic approaches to helping patients. The Dodo Bird Verdict is the hypothesis that most forms of psychotherapy are equally effective. The hypothesis takes its name from the Dodo bird in Alice in Wonderland, who oversees a competition with no consistent rules and announces that "Everybody has won, and all must have prizes". This hypothesis has been hotly debated since the 1980s (Elliott, 2015) and remains contentious.
A recent meta-analysis by Cuijpers, Quero (2021) found that "standardised mean differences compared with care-as-usual ranged from -0.81 for life-review therapy to -0.32 for non-directive supportive counselling. Individual psychotherapies did not differ significantly from each other, with the only exception of non-directive supportive counselling, which was less efficacious than all other therapies. The results were similar when only studies with low risk of bias were included. Older meta-analyses showed similar findings: Cuijpers (2008) compares seven different psychotherapies and finds them all equivalent except for interpersonal therapy (IPT), which was slightly higher (d=0.20 95% CI 0.02, 0.38). Barth (2013) found all psychotherapies equivalent, but noted that cognitive-behavioural therapy, interpersonal therapy, and problem-solving therapy had a more robust evidence base. Cuijpers, Berking (2013) found all psychotherapies equivalent as well, but noted that cognitive behavioural therapy was the most well studied.
Though the search for underlying factors which might make some therapies more effective than others continues, we think it's safe to say that there's insufficient evidence to support any one widely adopted school of therapy over another at this time.
Supplementary R code
You can independently replicate our work using the METAPSY's R package. To make it easier, we've provided R code templates for each type of analysis, which can be copied and lightly modified to quickly replicate any of the findings we report here. Note that results may fluctuate slightly as new studies are regularly added to the METAPSY database
We weren't aware of GiveWell's planned publication while working on this analysis, so all the numerical analysis and about half of the writing was done before we saw GiveWell's work. Our assessments and methodology choices can therefore be considered independent of GiveWell's work.
MetaPsy added some additional studies while we were working on this, so some charts are a bit outdated but didn't seem worth the time to redo. Tables and numbers otherwise reflect the latest.
The graph has mistakenly rolled LMIC non-global poor and non-LMIC non-western countries together and we didn't fix it because it would take too long, but they're coded differently in the spreadsheet
A fun historical fact: This paper could be considered among the first ever meta-analyses in any subject. The term "meta-analysis" was coined by one of the authors, Gene Glass (of "Glass's delta") only a year prior to study, though many of the statistical methods had been in general use before.
A review of meta analysis aiming to compare psychotherapy with pharmacotherapy by Leichsenring (2022) "selected meta-analyses that formally assessed risk of bias or quality of studies, excluded weak comparators (waiting list controls instead of placebo or treatment as usual)" and reported the largest "corrected" meta analysis for each disorder. In the report, Cuijpers, Karyotaki (2019) was considered the largest high quality and well corrected meta-analysis for psychotherapy and depression. Unless we both missed something, this suggests that it's the largest high quality meta-analysis as of at least Jan 2022.
This table was made using the METAPSY browser tool before learning how to use R. It hasn't been updated with the latest studies, In the interest of time, we have not redone the table.