[Epistemic status: Writing off-the-cuff about issues I haven't thought about in a while - would welcome pushback and feedback]
Thanks for this post, I found it thought-provoking! I'm happy to see insightful global development content like this on the Forum.
My views after reading your post are:
You're probably right that it doesn't make sense for all studies to be benchmarking their intervention against cash transfers;
I still think there are good reasons for practitioners to think hard about whether their programs do more good than bduget-equivalent cash transfers would;
Your post raises issues that challenge the usefulness of RCTs in general, not just RCTs that compare interventions to cash transfers.
Why I like cash benchmarking
You write:
That’s the role that a cash arm plays: rather than just check if a program is better than doing nothing at all (comparing to a control), we index it against a simple intervention that we know works well: cash.
The reason I find a cash benchmark useful feels a bit different than this. IMO the purpose of cash benchmarking is to compare a program to a practical counterfactual: just giving the money to beneficiaries instead of funding a more complicated program. It feels intuitive to me that it's bad to fund a development program that ends up helping people less than just giving people the cash directly instead. So the key thing is not that 'we know cash works well' - it's that giving cash away instead is almost always a feasible alternative to whatever development program one is funding.
That still feels pretty compelling to me. I previously worked in development and was often annoyed, and sometimes furious, about the waste and bureaucratic bs we had to put up with to run simple interventions. Cash benchmarking to me is meant to test whether the beneficiaries would be better off if, instead of hiring another consultant or buying more equipment, we had just given them the money.
Problems with RCTs
You write:
I am most familiar with our own program but I expect this applies to many other international development programs too: your medicine/training/infrastructure/etc program will very likely deliver benefits over a different timeline to cash, making a direct RCT comparison dependent more on survey timing than intervention efficacy.
This is a really good point. In combination with the graph you posted, I'm not sure I've seen it laid out so clearly previously. But it seems like you've raised an issue with not just cash benchmarking, but with our ability to use RCTs to usefully measure program effects at all.
In your graph, you point out that the timing of your follow-up survey will affect your estimate of the gap between the effects of your intervention and the effects of a cash benchmark. But we'd have the same issue if we wanted to compare the effects of your interventions to all the other interventions we could possibly fund or deliver. And if we want to maximize impact, we should be considering all these different possibilities.
More worringly: what we really care about is not the gap between the effects at a given point in time. What we care about is the difference between the integrals of those curves. The difference in total impact (divided by program cost).
But, as you say, surveys are expensive and difficult. It's rare to even have one follow-up survey, much less a sufficient number of surveys to construct the shape of the benefits curve.
It seems to me people mostly muddle through and ignore that this is an issue. But the people who really care fill in the blanks with assumptions. GiveWell, for example, makes a lot of assumptions about the benefits-over-time of the interventions they compare. To their eternal credit you can see these in their public cost-effectiveness model. They make an assumption about how much of the transfer is invested;[1] they make an assumption about how much that investment returns over time; they make an assumption about how many years that investment lasts; etc. etc. And they do similar things for the other interventions they consider.
All of this, though, is updating me further against RCTs really providing that much practical value for practitioners or funders. Estimating the true benefits of even the most highly-scrutinized interventions requires making a lot of assumptions. I'm a fan of doing this. I think we should accept the uncertainty we face and make decisions that seem good in expectation. But once we've accepted that, I start to question why we're messing around with RCTs at all.
More worringly: what we really care about is not the gap between the effects at a given point in time. What we care about is the difference between the integrals of those curves. The difference in total impact (divided by program cost).
Yes. I don't think the issue is with cash transfers alone. It's that most RCTs (I'm most familiar with the subjective wellbeing / mental health literature) don't perform or afford the analysis of the total impact of an intervention. The general shortcoming is the lack of information about the decay or growth of effects over time.
But I don't quite share your update away from using RCTs. Instead, we should demand better data and analysis of RCTs.
Despite the limited change-over-time data on many interventions, we often don't need to guess what happens over time (if by "requires making a lot of assumptions" you mean more of an educated guess rather than modelling something with empirically estimated parameters). At the Happier Lives Institute, we estimate the total effects by first evaluating an initial effect (what's commonly measured in meta-analyses) and then empirically estimating how the effect changes over time (which is rarely done). You can dig into how we've done this by using meta-analyses in our cash transfers and psychotherapy reports here.
While not perfect, if we have two-time points within or between studies, we can use the change in the impact between those time points to inform our view on how long the effect lasts, and thus estimate the total effect of an intervention. The knot is then cut.
FWIW, from our report about cash transfers, we expect the effect on subjective wellbeing to last around a decade or less. Interestingly, some studies of "big push" asset transfers find effects on subjective wellbeing that have not declined or grown after a decade post-intervention. If that holds up to scrutiny, that's a way in which asset transfers could be more cost-effective than cash transfers.
Note to reader: Michael Plant (who commented elsewhere) and I both work at HLI, which is related to why we're expressing similar views.
One concern you seem to have is about timelines. Isn't the solution to collect more long-term data of both the cash and non-cash arm? I understand that's more work, but if you don't collect the long-term data, then we're unfortunately back to speculation on whether the total impacts across time are bigger for cash or not-cash.
If the concern is about which measure of impact to use - you cite issues with people remembering their spending - then the (I think) obvious response is to measure individuals' subjective wellbeing, eg 0-10 "how satisfied are you with your life nowadays?" which allows them to integrate all the background information of their life when answering the question.
I agree with you that you don't need a cash arm to prove your alternative didn't work. But, if you already knew in advance your alternative would be worse, then it raises questions as to why you'd do it at all.
I agree that longer term data collection can help here in principle, if the initial differences in impact timing wash out over the years. One reason we didn't do that was statistical power: we expected our impact to decrease over time, so longer term surveys would require a larger sample to detect this smaller impact. I think we were powered to measure something like a $12/month difference in household consumption. I think I'd still call a program that cost $120 and increased consumption by, say, $3/month 10 years later a "success", but cutting the detectable effect by 1/4 takes 16x the sample size. Throw in a cash arm, and that's a 32x bigger sample (64,000 households in our case). We could get a decent sense of whether our program had worked vs control over a shorter (smaller sample) timeline, and so we went with that.
If the concern is about which measure of impact to use - you cite issues with people remembering their spending - then the (I think) obvious response is to measure individuals' subjective wellbeing, eg 0-10 "how satisfied are you with your life nowadays?" which allows them to integrate all the background information of their life when answering the question.
The subjective wellbeing idea is interesting (and I will read your study, I only skimmed for now but I was impressed). It isn't obvious to me that subjective wellbeing isn't also just a snapshot of a person's welfare and so prone to similar issues to consumption e.g. you might see immediate subjective welfare gains in the cash arm but the program arm won't start feeling better until they harvest their crops. I'm not really familiar with the measure, I might be missing something there.
I agree with you that you don't need a cash arm to prove your alternative didn't work. But, if you already knew in advance your alternative would be worse, then it raises questions as to why you'd do it at all.
Agreed-- I'm sure they expected their program to work, I just don't think adding a cash arm really helped them determine if it did or not.
It isn't obvious to me that subjective wellbeing isn't also just a snapshot of a person's welfare
Life satisfaction score is a snapshot, while WELLBY is its integral over time, so it's WELLBY you want. The World Happiness Report's article on this is a good primer.
When we eventually told the cash arm participants that we had given other households assets of the same value, most said they would have preferred the assets, “We don’t have good products to buy here”. We had also originally planned to work in 2 countries but ended up working in just 1, freeing up enough budget to pay for cash.
I'm intuitively drawn to cash transfer arms, but "just ask the participants what they would want" also sounds very compelling for basically the same reasons. Ideally you could do that both before and after ("would you recommend other families take the cash or the asset?")
Have you done or seen systematic analysis along these lines? How do you feel about that idea?
Asking about the comparison to cash also seems like a reasonable way to do the comparison even if you were running both arms (i.e. you could ask both groups whether they'd prefer $X or asset Y, and get some correction for biases to prefer/disprefer the option they actually received).
Maybe direct comparison surveys also give you a bit more hope of handling timing issues, depending on how biased you think participants are by recency effects. If you give someone an asset that pays off over multiple years, I do expect their "cash vs asset" answers to change over time. But still people can easily imagine getting the cash now and so if nothing else it seems like a strong sanity check if you ask asset-recipients in 2 years and confirm they prefer the asset.
At a very basic intuitive level, hearing "participants indicated strong preference for receiving our assets to receiving twice as much cash" feels more persuasive than comparing some measured outcome between the two groups (at least for this kind of asset transfer program where it seems reasonable to defer to participants about what they need/want)
I really like the idea of asking people what assets they would like. We did do a version of this to determine what products to offer, using qualitative interviews where people ranked ~30 products in order of preference. This caused us to add more chickens and only offer maize inputs to people who already grew maize. But participants had to choose from a narrow list of products (those with RCT evidence that we could procure), I'd love have given them freedom to suggest anything.
We did also consider letting households determine which products they received within a fixed budget (rather than every household getting the same thing) but the logistics got too difficult. Interestingly, people had zero interest in deworming pills, oral hydration salts or Vitamin A supplements as they not were aware of needing them-- I could see tensions arising between households not valuing these kinds of products and donors wanting to give them based on cost-effectiveness models. This "what do you want" approach might work best with products that recipients already have reasonably accurate mental models of, or that can be easily and accurately explained.
At a very basic intuitive level, hearing "participants indicated strong preference for receiving our assets to receiving twice as much cash" feels more persuasive than comparing some measured outcome between the two groups (at least for this kind of asset transfer program where it seems reasonable to defer to participants about what they need/want)
Very interesting suggestion: we did try something like this but didn't consider it as an outcome measure and so didn't put proper thought/resources into it. We asked people, "How much would you be willing to pay for product X?", with the goal of saying something like "Participants valued our $120 bundle at $200" but unfortunately the question generally caused confusion: participants would think we were asking them to pay for the product they'd received for free and either understandably got upset or just tried lowballing us with their answer, expecting it to be a negotiation.
If we had thought of it in advance, perhaps this would have worked as a way to generate real value estimates:
We randomise participants into groups
The first group is offered either our bundle (worth $120) or $120 cash
If >50% take the bundle, we then adjust our cash offer upwards and offer it to another group (or the opposite if <50% take the bundle)
We repeat this process of adjusting our price offer until we have ~50% of participants accepting our cash offer: that equilibrium price is then the "value" of the bundle
I'm not sure what the sample size implications would be but a big advantage would be the timeline: this could be done in a few weeks, not years
I bet proper economists have a way to do this but it's interesting to brainstorm on
I can see a few issues with this:
We still have to assume people "know what's best for them": that's a really patronising statement, but as above, people need reliable mental models to make these decisions, and won't have that for novel products
We need to have donors who will accept this measure: the data only really matters when it informs decisions
I'm very open to other thoughts here, I really like the concept of a cash benchmark and would love to find a way to resurrect the idea.
We bought our products at large scale on global markets, which meant our money went way further than our recipients’ could and we had access to quality products they couldn’t buy locally.
How does the time and monetary cost of buying these products compare to the time and monetary cost of giving cash?
In the Vox article at the start of this post, the cash-benchmarked nutrition program failed to improve nutrition at all (cash failed too). You shouldn’t need a cash comparison arm to conclude that that program either needs major improvements or defunding. So even in the case presented by supporters, I don’t see the value of cash benchmarking in RCTs.
But obviously the researchers didn't know beforehand that the programs would fail. So this isn't an argument against cash benchmarking.
How does the time and monetary cost of buying these products compare to the time and monetary cost of giving cash?
The total value of the bundle ($120) includes all staffing (modelled at scale with 100k recipients), including procurement staff, shipping, etc. This trial was a part of a very large nonprofit, which has very accurate costs for those kinds of things.
But obviously the researchers didn't know beforehand that the programs would fail. So this isn't an argument against cash benchmarking.
That's true, I don't think I made my point well/clearly with that paragraph. I was trying to say something like, "The Vox article points to how useful the cash comparison study had been, but the usefulness (learning that USAID shouldn't fund the program) wasn't actually due to the cash arm". That wasn't really an important point and didn't add much to the post.
It seems that developping cheap and accurate ways of measuring consumption and well-being across time is an important step to better estimate the total impact of interventions. Are there any promising solutions?
Appreciate the post! A similar topic came up in a recent DC global health & development discussion
Could another argument for skipping the cash arm be having more resources for other RCTs?
Ideally, we'd study the cash arm and the asset transfer program simultaneously at multiple time periods. But each extra treatment arm and time period costs extra. I imagine one could use the savings for other RCTs instead.
Against cash benchmarking for global development RCTs
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
I think right now EAs might be making a significant mistake by paying insufficient attention to the political realm. As EAs we tend to figure out what’s most impactful for us to work on and focus hard. That’s great! But there are various actions that are ‘non-delegatable’ - the extent to which an individual can do the action is limited (like voting, going to a protest, making hard money contributions to particular campaigns). It might be useful if we were all more in the habit of doing variou...
New Video from AI in Context: The Fall and Rise of Sam Altman
If you want to skip straight to the video, here it is!
AI in Context is excited to be back with our fourth video! For those just hearing from us, we make videos for 80,000 Hours, telling stories about transformative AI...
Should you fund an expensive program to help people or just send them cash? Using a randomised controlled trial (RCT) to directly compare international development programs to cash transfers was the Cool New Thing a few years back, with Vox calling it a “radical” idea that could be a “sea change in the way that we think about funding development". I spent 2 years on an RCT of a program that wanted to be radical and sea-changey, so naturally we considered using a cash comparison arm.
We didn’t use one. Throughout the process my mind was changed from “cash comparison arms are awesome” to “cash comparison arms probably rarely make much sense”. This change of perspective surprised me, so I wanted to think out loud here about why this happened.
The program I was evaluating
Asset transfer programs, such as giving people goats or fertiliser, have been found to work well at reducing poverty, but they also cost a lot, like over $1,000 per household. They also often have high staff costs from training and are difficult to massively scale. We wanted to try a super cheap asset transfer program that cost about $100 per household with minimal staffing, to see if we could still achieve meaningful impacts. We designed this as an RCT with 2,000 households in rural Tanzania and we'll hopefully have a paper out this year. We gave treatment households a bundle of goods including maize fertiliser, seed, chicks, mosquito bed nets, and a load of other things.
Why someone might suggest a cash arm
Much smarter people than me are in favour of directly comparing development programs to cash. There are arguments for it here and here. My favourite argument comes from a financial markets analogy: imagine you are considering investing in a fund. “We consistently make more money than we lose” is… good to hear. But much better would be, “We consistently beat the market”. That’s the role that a cash arm plays: rather than just check if a program is better than doing nothing at all (comparing to a control), we index it against a simple intervention that we know works well: cash. The fairest, most direct way to do this is to simply add an extra arm to your RCT, comparing treatment, control, and cash arms.
Why we wanted a cash arm at first
We really wanted to be compared to cash. Being able to say “give us $100 and we’ll do as much good as a $300 cash transfer” would be a powerful donor pitch. We were pretty confident that our program was better than cash, too. We bought our products at large scale on global markets, which meant our money went way further than our recipients’ could and we had access to quality products they couldn’t buy locally.
We even ran a small cash trial with 40 households. They all spent the cash well (mostly on home repairs) but no one seemed able to find investment opportunities as good as the ones in our asset bundle. When we eventually told the cash arm participants that we had given other households assets of the same value, most said they would have preferred the assets, “We don’t have good products to buy here”. We had also originally planned to work in 2 countries but ended up working in just 1, freeing up enough budget to pay for cash.
How my mind changed on cash
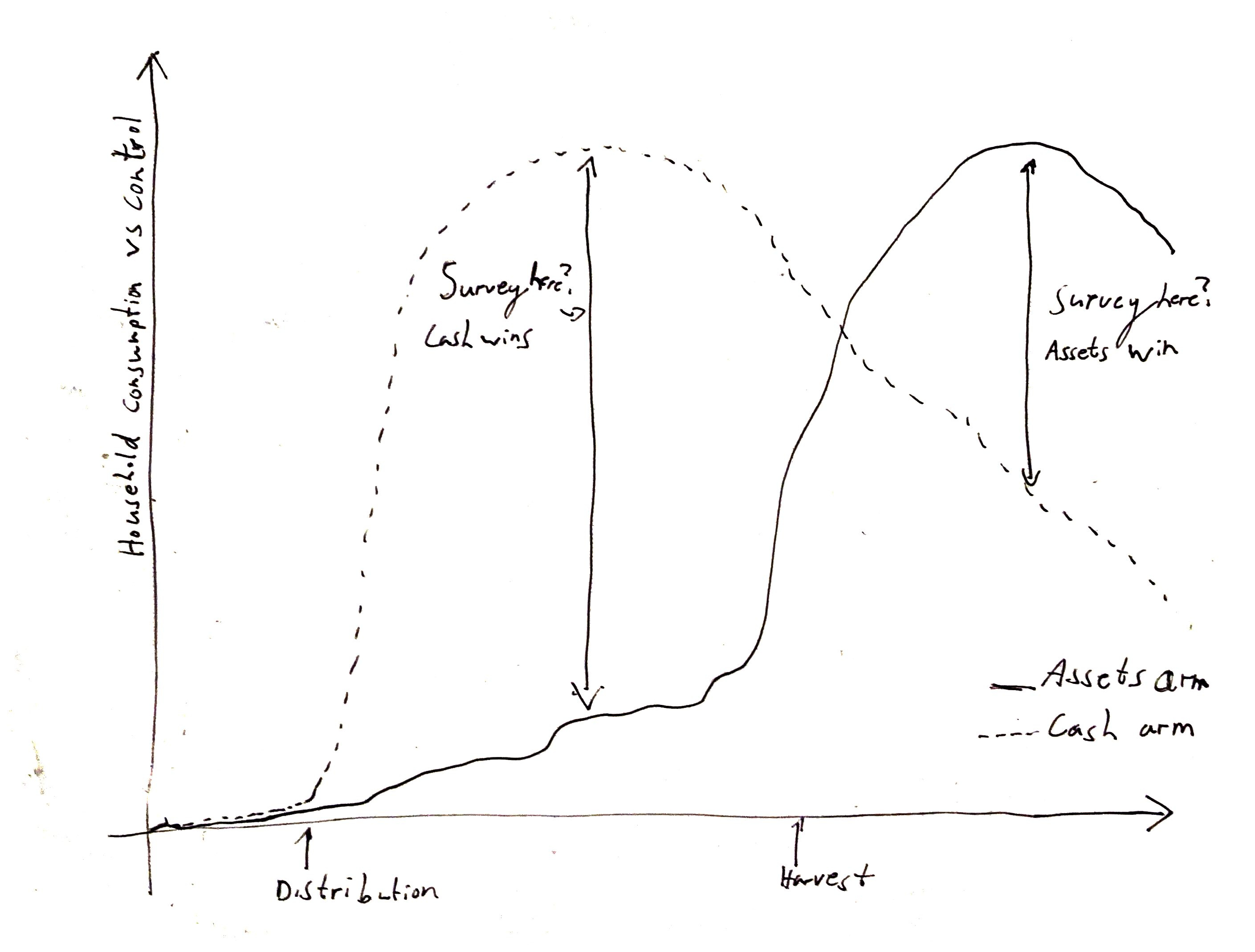
In short: Different programs will have impacts over different horizons, so the timing of when you collect your impact measurements will heavily skew whether cash or your program looks better.
In long:
Cash impact hits roughly immediately after distribution as households start to spend it
Our program’s impact took much longer to hit:
Our program included chicks that wouldn’t lay eggs or be eaten until they were 6 months old
We also gave maize inputs that would generate income only at harvest time, 9 months after distribution
Our tree seedlings would take years to grow and produce sellable timber or firewood
Household consumption surveys only give a short snapshot of household wellbeing:
Surveys generally only cover household consumption over the past 1-4 weeks
Imagine trying to remember how much you spent on groceries, rent and electricity the week of the 2nd of January and you’ll see why these surveys can only go so far back
Survey timing would then end up as the key driver of which program looked better:
If we timed our survey to be 3 months after distribution, we would likely see pretty good cash impact and almost no program impact.
If we timed the survey to be after 9 months, immediately after harvest, we would see massive program impact, picking up the big influx of income right at harvest, while cash impact will have started to fade away.
Illustration of different arm impact timings (the X-axis is time). This graph conclusively demonstrates that I am not good at hand-drawing graphs.
Conducting surveys every single month is one solution, but it’s impossibly expensive for most studies. So when is the right time to survey? There probably wasn’t one for our study, not one that made sense for both arms, and there likely wouldn't be for many other interventions either. We risked massively overstating or understating the impact of our program relative to cash based on when we happened to time our surveys, rather than any true difference in the benefits of either intervention. To continue the financial analogy: it’s like comparing an investment portfolio to the performance of the market but you can only use data taken from one specific day. Eventually I concluded that we simply couldn’t trust any final numbers.
I am most familiar with our own program but I expect this applies to many other international development programs too: your medicine/training/infrastructure/etc program will very likely deliver benefits over a different timeline to cash, making a direct RCT comparison dependent more on survey timing than intervention efficacy.
So is there any case for cash benchmarking?
Honestly, I’m not sure there is, at least not in an RCT arm, but I’m open to being wrong. In the Vox article at the start of this post, the cash-benchmarked nutrition program failed to improve nutrition at all (cash failed too). You shouldn’t need a cash comparison arm to conclude that that program either needs major improvements or defunding. So even in the case presented by supporters, I don’t see the value of cash benchmarking in RCTs.
I can see a case for cash benchmarking as a way of modelling program impact, rather than as an RCT arm. For example, if a non-profit spent $2,000/household delivering $300 of agricultural equipment (it happens), a pretty simple financial model in Excel should tell you the required rate of return needed on the equipment to be more efficient than just giving $2,000 cash. Then a trial or literature review should tell you if your program can meet that rate of return or not. If you can't beat cash, then you might want to just give cash.
GiveWell uses cash as a benchmark for health interventions in a way that seems sensible: using “moral weights” to convert lives saved into equivalent financial benefits for poor households. Because they are comparing separate studies that were designed to get the most accurate measure for their specific intervention, this conversion approach seems fair in principle, although I'm not familiar enough with the particular studies they use. They can then compare the value of doubling a person’s consumption for a year to the value of saving a life in a way that wouldn’t really make sense in a single RCT.
What I learned from this experience
My views on cash benchmarking changed entirely when I actually tried to write down a hypothetical results table, forcing me to clarify when our results would be collected. This has been a useful technique to take forward to future projects: I find that actually sketching out potential table of results, ideally under a few scenarios, really sharpens my thinking.
Some reasons why I might be wrong
There might be programs that have similar impact timelines to cash, making comparisons fair
There might be some important impact measures where there is a clear optimal measurement time e.g. "Not pregnant before age 16", "Votes in the 2025 election"
There might be use cases for cash-benchmarking RCTs other than "this program was 2x better than cash' that I haven't considered
Cash benchmarking might make sense over very long timelines (e.g. 5-10+ years), at which point the differences in initial impact timing might be washed out
... and maybe many more. This is my first Forum post, I'm very open to feedback on what I've missed!


[Epistemic status: Writing off-the-cuff about issues I haven't thought about in a while - would welcome pushback and feedback]
Thanks for this post, I found it thought-provoking! I'm happy to see insightful global development content like this on the Forum.
My views after reading your post are:
Why I like cash benchmarking
You write:
The reason I find a cash benchmark useful feels a bit different than this. IMO the purpose of cash benchmarking is to compare a program to a practical counterfactual: just giving the money to beneficiaries instead of funding a more complicated program. It feels intuitive to me that it's bad to fund a development program that ends up helping people less than just giving people the cash directly instead. So the key thing is not that 'we know cash works well' - it's that giving cash away instead is almost always a feasible alternative to whatever development program one is funding.
That still feels pretty compelling to me. I previously worked in development and was often annoyed, and sometimes furious, about the waste and bureaucratic bs we had to put up with to run simple interventions. Cash benchmarking to me is meant to test whether the beneficiaries would be better off if, instead of hiring another consultant or buying more equipment, we had just given them the money.
Problems with RCTs
You write:
This is a really good point. In combination with the graph you posted, I'm not sure I've seen it laid out so clearly previously. But it seems like you've raised an issue with not just cash benchmarking, but with our ability to use RCTs to usefully measure program effects at all.
In your graph, you point out that the timing of your follow-up survey will affect your estimate of the gap between the effects of your intervention and the effects of a cash benchmark. But we'd have the same issue if we wanted to compare the effects of your interventions to all the other interventions we could possibly fund or deliver. And if we want to maximize impact, we should be considering all these different possibilities.
More worringly: what we really care about is not the gap between the effects at a given point in time. What we care about is the difference between the integrals of those curves. The difference in total impact (divided by program cost).
But, as you say, surveys are expensive and difficult. It's rare to even have one follow-up survey, much less a sufficient number of surveys to construct the shape of the benefits curve.
It seems to me people mostly muddle through and ignore that this is an issue. But the people who really care fill in the blanks with assumptions. GiveWell, for example, makes a lot of assumptions about the benefits-over-time of the interventions they compare. To their eternal credit you can see these in their public cost-effectiveness model. They make an assumption about how much of the transfer is invested;[1] they make an assumption about how much that investment returns over time; they make an assumption about how many years that investment lasts; etc. etc. And they do similar things for the other interventions they consider.
All of this, though, is updating me further against RCTs really providing that much practical value for practitioners or funders. Estimating the true benefits of even the most highly-scrutinized interventions requires making a lot of assumptions. I'm a fan of doing this. I think we should accept the uncertainty we face and make decisions that seem good in expectation. But once we've accepted that, I start to question why we're messing around with RCTs at all.
They base this on a study of cash transfers in Kenya. But of course the proportion of transfer invested likely differs across time and locations
You beat me to commenting this!
I've always thought the question of "when should we measure endpoints?" is the biggest weakness of RCTs and doesn't get enough attention.
Yes. I don't think the issue is with cash transfers alone. It's that most RCTs (I'm most familiar with the subjective wellbeing / mental health literature) don't perform or afford the analysis of the total impact of an intervention. The general shortcoming is the lack of information about the decay or growth of effects over time.
But I don't quite share your update away from using RCTs. Instead, we should demand better data and analysis of RCTs.
Despite the limited change-over-time data on many interventions, we often don't need to guess what happens over time (if by "requires making a lot of assumptions" you mean more of an educated guess rather than modelling something with empirically estimated parameters). At the Happier Lives Institute, we estimate the total effects by first evaluating an initial effect (what's commonly measured in meta-analyses) and then empirically estimating how the effect changes over time (which is rarely done). You can dig into how we've done this by using meta-analyses in our cash transfers and psychotherapy reports here.
While not perfect, if we have two-time points within or between studies, we can use the change in the impact between those time points to inform our view on how long the effect lasts, and thus estimate the total effect of an intervention. The knot is then cut.
FWIW, from our report about cash transfers, we expect the effect on subjective wellbeing to last around a decade or less. Interestingly, some studies of "big push" asset transfers find effects on subjective wellbeing that have not declined or grown after a decade post-intervention. If that holds up to scrutiny, that's a way in which asset transfers could be more cost-effective than cash transfers.
Note to reader: Michael Plant (who commented elsewhere) and I both work at HLI, which is related to why we're expressing similar views.