Comments
Edit: I was contacted by the author of many unresolved AI questions on Metaculus, who tells me he intends to resolve up to 40 overdue questions on the AI subdomain in the next few weeks. I will update this post if/ when that happens
Further edit 18 months later: this did not happen
Introduction
Metaculus is a forecasting website which aggregates quantitative predictions of future events. One topic of interest on Metaculus is artificial intelligence. Here I look at what we might be able to learn from how the questions on this subject have gone so far, in particular, how the predictions of the Metaculus community have performed. If they have done poorly, it would be of value to making future predictions and interpreting existing ones to know if there are any patterns to this which might reveal common mistakes in making AI related predictions.
Summary
There are three main types of questions I looked at - Date based questions, numeric range questions, and binary questions.
- For date questions, slightly fewer than the Metaculus community expected have resolved by now, but the sample size is small.
- For numeric questions, it did not seem like the community was biased towards predicting faster or slower timelines than the question resolution implied, but it did look like the community was quite overconfident in their ability to predict the resolution.
- For binary questions, it looked like the community expected more developments to occur than actually happened, but they were appropriately not very confident in their predictions.
Overall it looked like there was weak evidence to suggest the community expected more AI progress than actually occurred, but this was not conclusive.
Data I used
I got data from all 259 questions on Metaculus with the category “Computer Science - AI and Machine Learning” (169 questions) or on the AI subdomain (90 extra questions, there was some overlap). This was quite a manual process; see the appendix for an explanation of the process. The data came in the form of a json object containing both current and historical data for each question.
I took the community prediction 25% of the way through the question lifetime for each question (i.e., 25% of the way from when the question is opened to when it closes). This was to avoid the cases where resolution becomes obvious one way or another and goes to 1% or 99%, and in order to only count each question once. The AI subdomain questions generally had fewer predictions on them (at the 25% mark) with 12 vs 39 predictions in the median case. I did not differentiate them in this analysis.
The questions were in 3 formats:
- Date continuous - “when will [event] occur?”, resolving as a date.
- Numeric continuous - resolving as a number within a specified range, or as being above or below the range bounds. These were quite varied and included questions like “How many papers will be published in [field]?” or “What score will the best published algorithm get on [test] by [date]?”
- Binary - “Will [event] occur?”, resolving positively or negatively.
In the case of continuous questions, the viable range, resolution, and medians/quartiles were mapped by default to values in [0,1] . The scale was provided in the question json, but I didn’t use this at any point. Metaculus permits both linear and log scales, I did not differentiate between questions using either format.
I manually inspected the binary and numeric continuous resolved questions in order to more easily permit drawing implications about whether people were "too optimistic" or "too pessimistic", in a very rough sense, about AI safety considerations. This involved reversing the ordering of points on some questions such that 0 on the [0,1] scale consistently corresponded to “faster timelines” or “less safe” and 1 to the opposite. In the case of binary resolution, I did the same thing, but as most were of the form “will development occur” for some benchmark of AI progress there was less to do here. This involved flipping the probabilities for 3 of the questions which were phrased as “this resolves positive if X does not happen” such that positive resolution is treated as negative, and a 10% prediction is taken as 90% of the converse, etc.
For continuous numeric questions, I conflated “positive for AI safety” with “suggests slower timelines” and flipped the top and bottom of the ranges of some questions to make this consistent. There is a link to how I did this in the appendix.
I made no such adjustments to the date questions, as most were of the form “when will [event] occur”, and with the exception of this meta question it seemed clear that early resolution of the resolved questions involved faster timelines implications.
Results for Date Questions
There were 41 date questions, of which 7 have resolved by now.
6/7 resolved date questions resolved early, 5/6 very early (that is, before their predicted 25th percentile time). What can we say from this? An obstacle to drawing inferences from this is that there is clearly a selection effect where the resolved questions out of a bunch of largely long time horizon questions are more likely to have resolved on the early side.
To try to get around this, I have looked at all unresolved questions, to check how many the Metaculus community would have expected to resolve by now. Of all 41 date questions, 4 were predicted to be 25%-50% to resolve by now (1 did), 2 were predicted to be 50%-75% to resolve by now (1 did), and 5 were predicted to be at least 75% to resolve by now (2 did).
This suggests that predictors were somewhat overconfident that things would happen, if anything, though the sample size is small. I am hesitant to put much weight on this, however, as it seems one of the >75% to resolve by now questions which did not resolve perhaps should have, according to the comments on the question, and if this is the case then 3 out of 5 of the >75% predictions coming true would be considerably weaker evidence.
Of the remaining 30 questions, which were all predicted as <25% to resolve by now, 3 did, which is difficult to interpret as some of these were probably <1% to resolve by now and others may have been higher (I don’t have more granularity than the quartiles to test this).
Results for Numeric Questions
I looked at only the resolved numeric and binary questions as I did not think that the selection effects which worried me on date questions applied here.
Of 16 resolved numeric questions with obvious implications for faster/slower timelines or safer/less safe (henceforth I'm conflating faster with less safe and slower with safer), 8 resolved as faster/less safe than the Metaculus algorithm predicted, 8 as slower/more safe.
Of these 16 questions, only 2 (both resolving as slightly slower progress than expected) resolved within the 25%-75% confidence interval, with the other 14 resolving outside this. The two which resolved within this interval were both of the form "how many papers will be published on [topic] in [year]" (here and here). To me, that seems intuitively easier to forecast (I guess straightforward extrapolation from trends will get you most of the way there) than e.g. "How many Machines will produce greater than or equal to 900 GTEPs on the Graph500 BFS benchmark?" which requires both projecting the number of machines capable of meeting the benchmark, and the continued use of that benchmark.
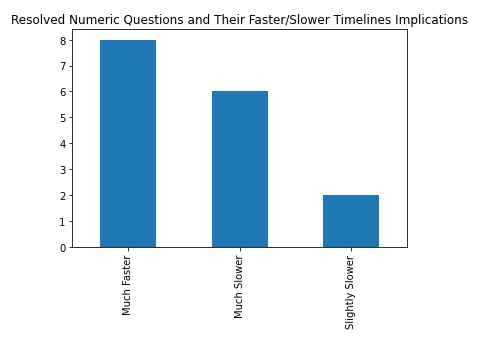
This suggests that for these questions the predictors were too confident in their understanding of the various questions, and were surprised in both positive and negative directions.
Results for Binary Questions
For the binary questions, there were 41 questions which were of the form "will [development] occur by [date]?", and four other questions which did not seem to have much bearing on AI timelines (“will a paper suggesting we are in a simulation be published?”, “will this particular named bot win this tournament for AIs?”, “Will there be some kind of controversy surrounding the OpenAI Five Finals? “ and “Will the number of people who have joined a Metaculus AI workshop double in the next 6 weeks? “) which I excluded.
A standard way of looking at performance on binary predictions is to use Brier Scores. The Brier Score is a scoring rule for probabilistic forecasts. It is equivalent to the mean squared error of forecasts for binary forecasts, so a lower score is better. Predicting 50% on every question will yield a Brier score of 0.25, predicting the correct resolution with 100% confidence will score 0, and predicting the wrong resolution with 100% confidence will score 1.
The Brier Scores of the community AI predictions were 0.2027, with an overconfidence score of -0.57%. This means that on average, moving a prediction slightly away from 50-50 would improve it, but this is a pretty negligible overconfidence score compared to the scores I found in my previous work. Had the predictors been perfectly calibrated, they would have expected to score 0.2032, so the community appeared for these questions to be aware of their own uncertainty. Note that this does not mean they were very well calibrated, as we shall see.
Brier scores do not give us much insight into whether there was a bias towards predicting positive or negative resolution, however. I look at this next.
Looking at the distribution of predictions, the 25th, 50th and 75th percentile of predictors expected 13.65, 17.48 and 21.16 propositions to resolve positively, and 11 occurred, suggesting somewhat slower than expected progress. How surprising is this? I estimate this using a Poisson Binomial Distribution, using the discrete Fourier transform approximation for the probability mass function.
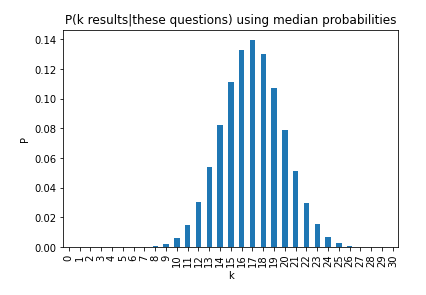
11 or fewer positive resolutions has probability 2.48%. What if we took the 25th percentile of predictors probabilities?
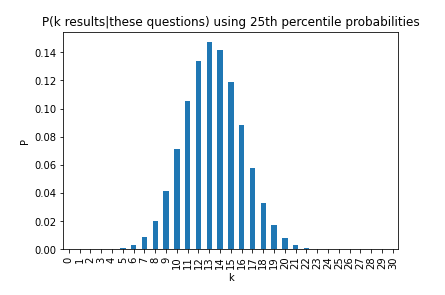
Now 11 or fewer positive resolutions has 25.05% probability.
So it seems plausible that the community was somewhat biased to think events will happen when predicting on these questions. This is similar to what I previously found for longer time horizon questions, though the time horizons here on the resolved binary questions were all less than 1 year, with a median of 77 days.
A caveat: it is unlikely that these questions are totally independent of each other, which this distribution assumes is the case. I expect “progress in AI” to be correlated, such that we could expect an acceleration in progress to enable several questions which are running concurrently to resolve positively, or a slowdown to affect many questions, so these probabilities are more like lower bounds. I think this is relatively weak evidence in light of this.
What caused predictions to be off?
A somewhat benign seeming occurrence which occasionally threw people off was performance on a task not improving as much as expected because it looked like nobody had tried (e.g here) or the technical specifications had been met but not submitted to a journal, as required by this question. Sometimes unexpected factors threw the result way off, such as when spiking GPU prices due to bitcoin mining sent this question way outside expectations.
These sorts of unknowns suggest that predictors were generally overconfident of their ability to accurately guess these questions, and would have been better off making less confident predictions.
I don’t think there were any slam dunk conclusions to take from this study. There was weak evidence that Metaculus forecasters were biased towards thinking AI things will happen sooner than they actually did, and that they were particularly overconfident about numeric questions, suggesting these questions were harder to predict on.
I say weak evidence, because I don’t endorse a confident takeaway from this data from a faster/slower timelines perspective, as the question set is not particularly suited to aggregate this info and the errors in the continuous questions seem to be in both optimistic and pessimistic directions.
As well as this, in a reasonable attempt to address this it seems likely that some questions should carry much more weight than others, and I made no attempt to do this.
Appendix
All code for this post is contained in this GitHub repository, available under a GNU General Public License v3.0.
Getting the questions from Metaculus is explained in the readme here.
The python notebook and links to the google sheets I used are also in that repository. Please feel free to contact me if you have any questions about this.
Credits

This essay is a project of Rethink Priorities.
It was written by Charles Dillon, a volunteer for Rethink Priorities. Thanks to Peter Wildeford for the idea to look into this topic, and Michael Aird and Peter Wildeford for advice and feedback on this post. If you like our work, please consider subscribing to our newsletter. You can see all our work to date here.


re: the edit at the top of the article, were the unresolved questions resolved? I'd be interested in seeing an updated version of this post! (either with just those questions or also including more questions from the past year and half)
Unfortunately not - the person never followed up and when I asked them a few months later they did not respond.