Comments
Forecasting Newsletter: July 2021

Sign up here or browse past newsletters here.
SimonM (a) kindly curated the top comments from Metaculus this past July. They are (a):
Round 2 of the Keep Virginia Safe Tournament (a) will begin in early August. It'll focus on Delta and other variants of concern, access to and rollout of the vaccine, and the safe reopening of schools in the fall.
Charles Dillon—a Rethink Priorities volunteer—created a Metaculus series on Open Philanthropy's donation volumes (a). Charles also wrote an examination of Metaculus' resolved AI predictions and their implications for AI timelines (a), which tentatively finds that the Metaculus community expected slightly more progress than actually occurred.
Polymarket had several prominent cryptocurrency prediction markets. Will Cardano support smart contracts on Mainnet by October 1st, 2021? (a) called Cardano developers out on missed deadlines (a) (secondary source (a)).
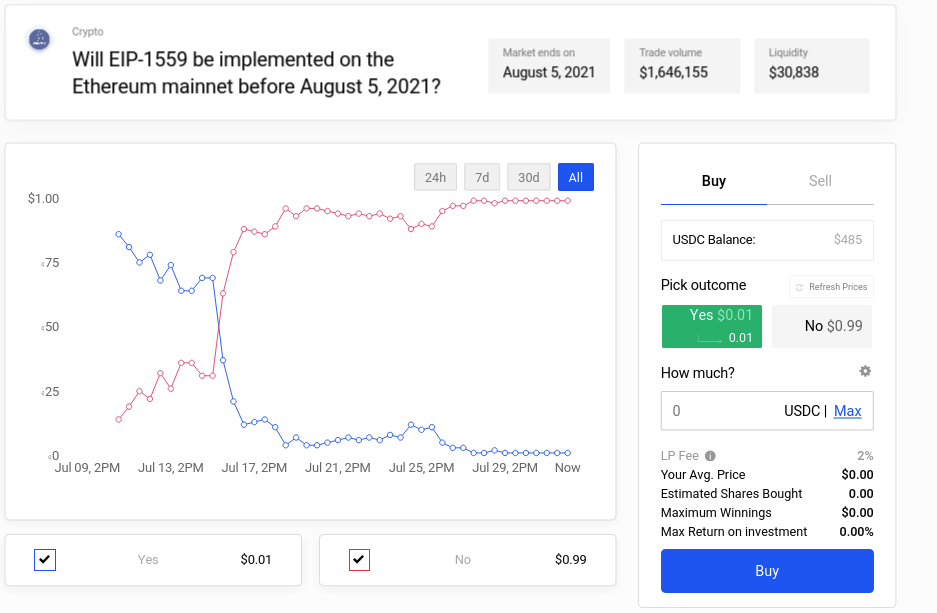
Will EIP-1559 be implemented on the Ethereum mainnet before August 5, 2021? (a) saw Polymarket pros beat Ethereum enthusiasts by more accurately calculating block times. Lance, an expert predictor market player, covers the topic here (a).
Polymarket also started their first tournament, the first round of which is currently ongoing. 32 participants each received $100, and face-off in a sudden-death tournament (a). Participants' profits can be followed on PolymarketWhales (a).
Kalshi (a)—a CFTC (a)-regulated prediction market—has launched, and is now available to US citizens. Kalshi previously raised $30 million (a) in a round led by Sequoia Capital (a). Fees (a) are significantly higher than those of Polymarket.
Reddit added some prediction functionality (a) late last year, and the NBA subreddit has recently been using it (a). See Incentivizing forecasting via social media (a) and Prediction markets for internet points? (a) for two posts which explore the general topic of predictions on social media platforms.
Also on Reddit, r/MarkMyWorlds (a) contains predictions which people want remembered, and r/calledit (a) contains those predictions which people surprisingly got right. Some highlights:

The predictions from r/MarkMyWords about public events could be tallied to obtain data on medium to long-term accuracy, and the correct predictions from r/calledit could be used to get a sense of how powerful human hypothesis generation is.
Hedgehog Markets Raises $3.5M in Seed Funding (a). They also give a preview (a) of their upcoming platform. I'm usually not a fan of announcements of an announcement, but in this case I thought it was worth mentioning:
A No-Loss Competition allows users to make predictions on event outcomes without losing their principal.
It works like this — a user decides they are interested in participating in one of Hedgehog’s No-Loss Competitions. So, they stake USDC to receive game tokens, and use those game tokens to participate in various prediction markets offered within the competition. Regardless of how a user’s predictions perform, they will always receive back their original USDC stake at the end of the competition.
The problem this solves is that within the DeFi ecosystem, the time value of money—the amount of interest one can earn from money by letting it sit idle, e.g., by lending it to other people or by lending liquidity to stable-coin pools—is fairly high. So once one is willing to get one's money into a blockchain, it's not clear that betting offers the best return on investment. But with Hedgehog Market's proposed functionality, one can get the returns on betting plus the interest rate of money at the same time.
In practice, the proposed design isn't quite right, because Hedgehog contests unnecessarily consist of more than one question, and because one can't also bet the principal. But in the long run, this proposal, or others like it, should make Polymarket worried that it will lose its #1 spot as the best crypto prediction market.
Biatob (a)—an acronym of "Betting is a Tax On Bullshit"—is a new site for embedding betting odds on one's writing. Like: I (bet: $20 at 50%) (a) that this newsletter will exceed 500 subscribers by the end of 2021. Here (a) is a LessWrong post introducing it.
Hypermind launches a new contest on the future of AI (a), with 30,000€ at stake for prizes. An interview with Jacob Steinhardt, a UC Berkeley professor who selected the questions, can be found here (a). Hypermind's website has also undergone a light redesign.
I've added Kalshi and Betfair to Metaforecast.
Unfortunately, Fabs Won’t Fix Forecasting (a) gives a brief overview of the state of the semiconductor manufacturing industry. The recent chips shortage has led to more fabrics being built to serve anticipated demand, and to tighter coordination between buyers and manufacturers. The article then makes a point that "...companies are looking for ways to mitigate shortages. Building fabs is part of the answer, but unless OEMs (original equipment manufacturers (a)) and the supply chain can improve the accuracy of their forecasts, the chip industry's next problem could be be overcapacity."
Malta is in trouble over betting & fraud: Malta faces EU sports betting veto withdrawal (a) & Malta first EU state placed on international money laundering watch-list (a). H/t Roman Hagelstein. From the first article:
As one of Europe’s most prominent gambling hubs – online gambling accounts for 12% of the island’s GDP, generating €700 million and employing 9,000 people – and providing a base to over 250 betting operators including Betsson, Tipico and William Hill, the new stipulations could have a substantial impact on the day-to-day functions of Malta’s economy.
The European Central Bank seems to systematically over-predict inflation (a).

Forecasting Swine Disease Outbreaks (a)
For many years, production companies have been reporting the infection status of their sow farms to the MSHMP. So now we have this incredible dataset showing whether any given farm is infected with porcine epidemic diarrhea (PED) virus in a given week. We combine these data with animal movement data, both into the sow farms as well as into neighboring farms, to build a predictive, machine-learning algorithm that actually forecasts when and where we expect there to be high probability of a PED outbreak
The forecasting pipeline has a sensitivity of around 20%, which means that researchers can detect one out of every five outbreaks that occur.
That’s more information than we had before... so it’s a modest improvement,” VanderWaal said. “However, if we try to improve the sensitivity, we basically create more false alarms. The positive predictive value is 70%, which means that for every 10 times the model predicts an outbreak, it’s right seven of those times. Our partners don’t want to get a bunch of false alarms; if you ‘cry wolf’ too often, people stop responding. That’s one of the limitations we’re trying to balance.
Thinking fast, slow, and not at all: System 3 jumps the shark (a): Andrew Gelman tears into Kahneman's new book Noise; Kahneman answers in the comments.
Something similar seems to have happened with Kahenman. His first book was all about his own research, which in turn was full of skepticism for simple models of human cognition and decision making. But he left it all on the table in that book, so now he’s writing about other people’s work, which requires trusting in his coauthors. I think some of that trust was misplaced.
Superforecasters look at the chances of a war over Taiwan (a) and at how long Kabul has left after America's withdrawal from Afghanistan (a).
In Shallow evaluations of longtermist organizations (a), I look at the pathways to impact for a number of prominent longtermist EA organizations, and I give some quantified estimates of their impact or of proxies of impact.
Global Guessing interviews Juan Cambeiro (a)—a superforecaster known for his prescient COVID-19 predictions—and goes over three forecasting questions with him. Forecasters who are just starting out might find the description of what steps Juan takes when making a forecast particularly valuable.
Types of specification problems in forecasting (a) categorizes said problems and suggests solutions. It's part of a broader set of forecasting-related posts by Rethink Priorities (a).
Risk Premiums vs Prediction Markets (a) explains how risk premiums might distort market forecasts. For example, if money is worth less when markets are doing well, and more when markets are doing worse, a fair 50:50 bet on a 50% outcome might have negative expected utility. The post is slightly technical.
Leaving the casino (a). "Probabilistic rationality was originally invented to choose optimal strategies in betting games. It’s perfect for that—and less perfect for other things."
16 types of useful predictions (a) is an old LessWrong post by Julia Galef, with some interesting discussion in the comments about how one can seem more or less accurate when comparing oneself to other people, depending on the method of comparison.
The Complexity of Agreement (a) is a classical paper by Scott Aaronson which shows that the results of Aumann's agreement theorem hold in practice.
A celebrated 1976 theorem of Aumann asserts that Bayesian agents with common priors can never “agree to disagree”: if their opinions about any topic are common knowledge, then those opinions must be equal. But two key questions went unaddressed: first, can the agents reach agreement after a conversation of reasonable length? Second, can the computations needed for that conversation be performed efficiently? This paper answers both questions in the affirmative, thereby strengthening Aumann’s original conclusion.
We show that for two agents with a common prior to agree within ε about the expectation of a [0, 1] variable with high probability over their prior, it suffices for them to exchange O(1/ε^2) bits. This bound is completely independent of the number of bits n of relevant knowledge that the agents have. We also extend the bound to three or more agents; and we give an example where the “standard protocol” (which consists of repeatedly announcing one’s current expectation) nearly saturates the bound, while a new “attenuated protocol” does better
This paper initiates the study of the communication complexity and computational complexity of agreement protocols. Its surprising conclusion is that, in spite of the above arguments, complexity is not a fundamental barrier to agreement. In our view, this conclusion closes a major gap be- tween Aumann’s theorem and its informal interpretation, by showing that agreeing to disagree is problematic not merely “in the limit” of common knowledge, but even for agents subject to realistic constraints on communication and computation
In Section 4 we shift attention to the computational complexity of agreement, the subject of our deepest technical result. What we want to show is that, even if two agents are computationally bounded, after a conversation of reasonable length they can still probably approximately agree about the expectation of a [0, 1] random variable. A large part of the problem is to say what this even means. After all, if the agents both ignored their evidence and estimated (say) 1/2, then they would agree before exchanging even a single message. So agreement is only interesting if the agents have made some sort of “good-faith effort” to emulate Bayesian rationality.
The blog post The Principle of Indifference & Bertrand’s Paradox (a) gives very clear examples of the problem of priors. It's a chapter from a free online textbook (a) on probability.
What’s the problem? Imagine a factory makes square pieces of paper, whose sides always have length somewhere between 1 and 3 feet. What is the probability the sides of the next piece of paper they manufacture will be between 1 and 2 feet long?
Applying the Principle of Indifference we get 1/2
That seems reasonable, but now suppose we rephrase the question. What is the probability that the area of the next piece of paper will be between 1 ft2 and 4 ft2? Applying the Principle of Indifference again, we get a different number, 3/8
But the answer should have been the same as before: it’s the same question, just rephrased! If the sides are between 1 and 2 feet long, that’s the same as the area being between 1 ft2 and 4 ft2.
The infamous Literary Digest poll of 1936 (a) predicted that Roosevelt's rival would be the overwhelming winner. After Roosevelt instead overwhelmingly won, the magazine soon folded. Now, a new analysis finds that (a):
If information collected by the poll about votes cast in 1932 had been used to weight the results, the poll would have predicted a majority of electoral votes for Roosevelt in 1936, and thus would have correctly predicted the winner of the election. We explore alternative weighting methods for the 1936 poll and the models that support them. While weighting would have resulted in Roosevelt being projected as the winner, the bias in the estimates is still very large. We discuss implications of these results for today’s low-response-rate surveys and how the accuracy of the modeling might be reflected better than current practice.
Proebsting's paradox (a) is an argument that appears to show that the Kelly criterion can lead to ruin. Its resolution requires understanding that "Kelly's criterion is to maximise expected rate of growth; only under restricted conditions does it correspond to maximising the log. One easy way to dismiss the paradox is to note that Kelly assumes that probabilities do not change."
Note to the future: All links are added automatically to the Internet Archive, using this tool (a). "(a)" for archived links was inspired by Milan Griffes (a), Andrew Zuckerman (a), and Alexey Guzey (a).


TYPO: This belongs to the section on Aumann's agreement, but is listed in the problem of priors section
Thanks